- The paper introduces a modular ViT–MLP–LLM architecture featuring a Visual Resolution Router that adaptively compresses visual tokens with minimal performance loss.
- The Cascade RL training paradigm, which combines offline MPO and online GSPO, yields up to a 16% improvement in reasoning benchmarks and enhances training efficiency.
- The Decoupled Vision-Language Deployment framework, paired with ViR, enables up to 4.05× faster inference, supporting both dense and MoE configurations in resource-constrained settings.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Model Architecture and Innovations
InternVL3.5 extends the InternVL series with a modular "ViT–MLP–LLM" architecture, leveraging InternViT vision encoders and Qwen3/GPT-OSS LLMs. The model supports both dense and MoE configurations, scaling from 1B to 241B parameters. A key architectural innovation is the Visual Resolution Router (ViR), which adaptively compresses visual tokens based on semantic richness, enabling dynamic trade-offs between computational cost and representational fidelity. This is integrated via a pixel shuffle module, reducing the number of visual tokens by up to 50% with negligible performance loss.
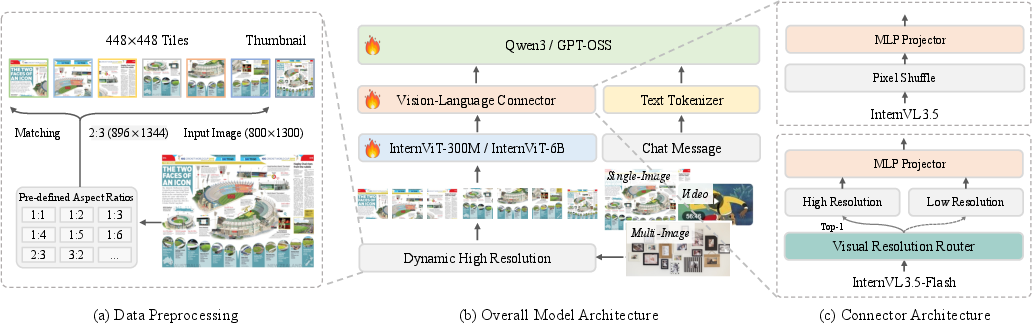
Figure 1: InternVL3.5 architecture with ViR for adaptive visual token compression, supporting efficient multimodal processing.
InternVL3.5-Flash variants incorporate ViR, making them suitable for resource-constrained deployments. The Decoupled Vision-Language Deployment (DvD) framework further optimizes inference by parallelizing vision and language processing across separate servers, maximizing hardware utilization and throughput.
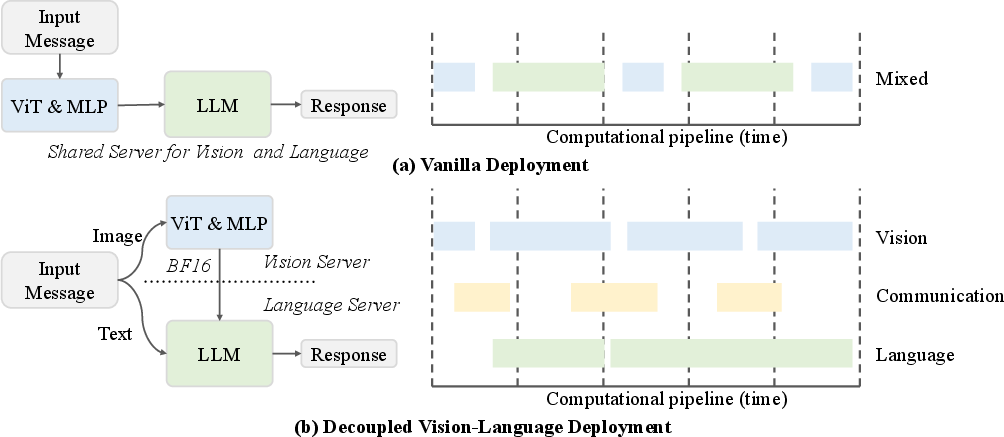
Figure 2: DvD enables parallel, asynchronous execution of vision and language modules, reducing inference latency and resource contention.
Training Paradigm: Cascade Reinforcement Learning
InternVL3.5 introduces Cascade RL, a two-stage RL framework combining offline Mixed Preference Optimization (MPO) and online Generalized Self-Play Optimization (GSPO). The offline stage (MPO) efficiently warms up the model using preference, quality, and generation losses, while the online stage (GSPO) refines output distributions via normalized rewards and importance sampling. This coarse-to-fine approach yields stable convergence, high-quality rollouts, and a higher performance ceiling compared to single-stage RL paradigms.
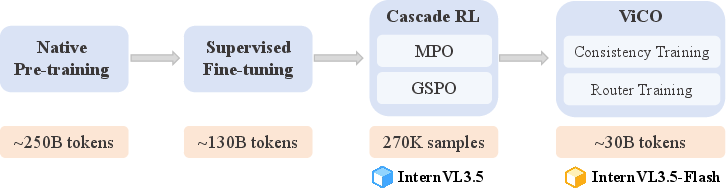
Figure 3: Training pipeline: native pre-training, supervised fine-tuning, Cascade RL, and ViR integration via consistency and router training.
Cascade RL demonstrates strong scalability, with consistent gains from 1B to 241B models. Ablation studies show up to +16.0% improvement in reasoning benchmarks and superior training efficiency—Cascade RL achieves higher performance than GSPO with half the GPU hours.

Figure 4: Cascade RL ablation: progressive gains in multimodal reasoning across model scales and training stages.
Efficiency: Visual Resolution Router and Decoupled Deployment
ViR is trained via Visual Consistency Learning (ViCO), minimizing KL divergence between outputs conditioned on different compression rates. Router training uses cross-entropy loss, with dynamic thresholds based on historical loss ratios. ViR enables InternVL3.5-Flash to maintain nearly 100% of original performance while halving visual token count.
DvD decouples vision and language inference, batching vision features and asynchronously transmitting them to the language server. This design yields up to 4.05× speedup in high-resolution scenarios and scales efficiently with input size and model capacity.
Empirical Results and Benchmarking
InternVL3.5 achieves state-of-the-art results among open-source MLLMs across 35 multimodal benchmarks, including general, reasoning, text, agentic, OCR, chart, document, multi-image, real-world, hallucination, grounding, multilingual, video, GUI, embodied, and SVG tasks.
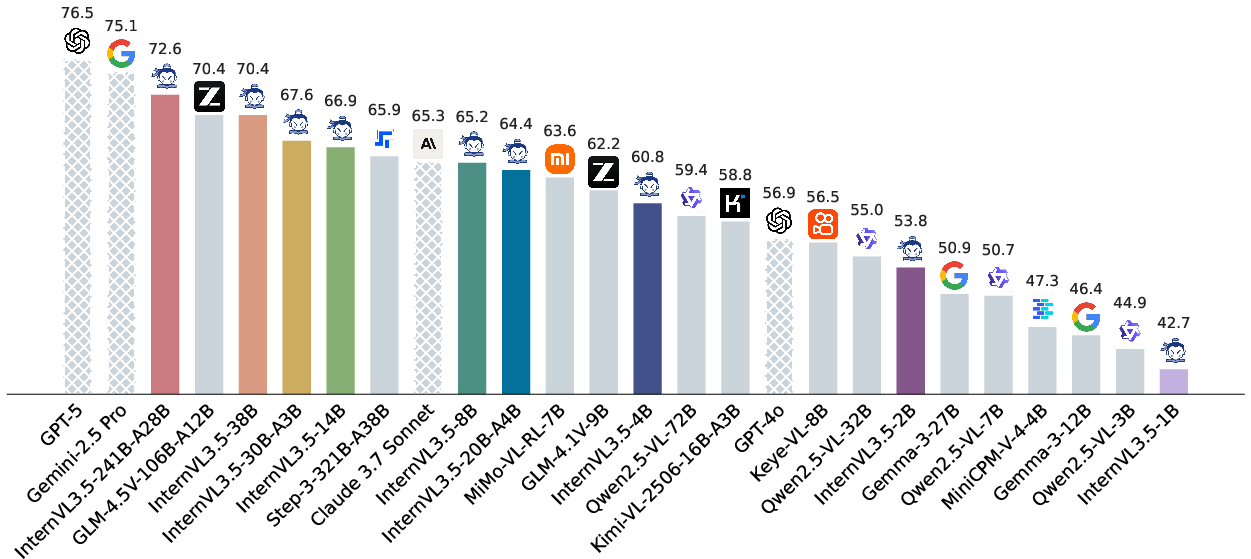
Figure 5: InternVL3.5 outperforms leading open-source and commercial MLLMs across multimodal, reasoning, text, and agentic benchmarks.
- General Multimodal: InternVL3.5-241B-A28B matches GPT-5 on overall score (74.1 vs. 74.0), with strong results on MMVet, MMBench, and LongVideoBench.
- Reasoning: Cascade RL yields scores of 77.7 (MMMU) and 82.7 (MathVista), surpassing open-source baselines and approaching commercial leaders.
- Text: Native pre-training and Cascade RL preserve and enhance language capabilities, outperforming base LLMs and mitigating catastrophic forgetting.
- Agentic/GUI: InternVL3.5 excels in GUI grounding and agentic tasks, outperforming specialized and generalist models on ScreenSpot, OSWorld-G, and WindowsAgentArena.
- Embodied/SVG: InternVL3.5 sets new open-source records on VSI-Bench, SGP-Bench, and SArena-Icon, with competitive SVG generation metrics (FID, SSIM, LPIPS).
- Efficiency: ViR and DvD together yield up to 4.05× inference speedup with minimal accuracy loss, validated across dense and MoE models.
Implementation and Deployment Considerations
- Training: XTuner framework with FSDP, data packing, FP8 training, FlashAttention-3, and TMA-Adaptive FP8 Grouped GEMM for scalable LLM/MoE optimization.
- Inference: DvD supports asynchronous, hardware-optimized deployment; ViR enables adaptive token compression for real-time applications.
- Resource Requirements: Cascade RL is GPU-efficient, with offline RL amortizing rollout costs and online RL leveraging high-quality rollouts for robust convergence.
- Scaling: InternVL3.5 demonstrates linear scalability in reasoning and efficiency across model sizes, with consistent performance improvements in both dense and MoE configurations.
Implications and Future Directions
InternVL3.5 narrows the gap between open-source and commercial MLLMs, particularly in reasoning, agentic, and efficiency domains. The Cascade RL framework provides a scalable, stable RL paradigm for multimodal models, while ViR and DvD offer practical solutions for real-world deployment bottlenecks. The model's versatility across text, vision, video, GUI, embodied, and SVG tasks positions it as a foundational platform for multimodal AI research and applications.
Future work may focus on further reducing hallucination rates, enhancing robustness in long-context and multi-image/video scenarios, and extending agentic capabilities for embodied and interactive environments. The open-source release of models and code will facilitate reproducibility, benchmarking, and community-driven innovation in multimodal AI.
Conclusion
InternVL3.5 advances open-source multimodal modeling through architectural, training, and deployment innovations. Cascade RL, ViR, and DvD collectively yield substantial gains in reasoning, versatility, and efficiency, with empirical results demonstrating state-of-the-art performance across diverse benchmarks. The model's scalability, efficiency, and broad applicability make it a significant contribution to the multimodal AI landscape, providing a robust foundation for future research and deployment.

