- The paper introduces Kwai Keye-VL, an 8-billion-parameter MLLM that achieves state-of-the-art short-video understanding through a novel training pipeline.
- It employs a four-stage progressive pre-training and two-phase post-training regimen, integrating vision and language models with dynamic resolution support.
- Evaluations demonstrate robust video capabilities, enhanced visual recognition, and improved reasoning performance on public benchmarks.
Kwai Keye-VL: A Technical Overview of a Multimodal Foundation Model for Short-Video Understanding
The paper introduces Kwai Keye-VL, an 8-billion-parameter MLLM designed to excel in short-video understanding while maintaining strong general-purpose vision-language capabilities. Keye-VL's development is rooted in a large-scale, high-quality dataset exceeding 600 billion tokens, with a focus on video data, and a novel training recipe involving a four-stage pre-training process followed by a two-phase post-training regimen. The model architecture, data construction strategy, and training methodology are detailed, offering insights for building future MLLMs tailored for the video era. Evaluations demonstrate state-of-the-art results on public video benchmarks and competitive performance on general image-based tasks.
Model Architecture and Visual Encoding
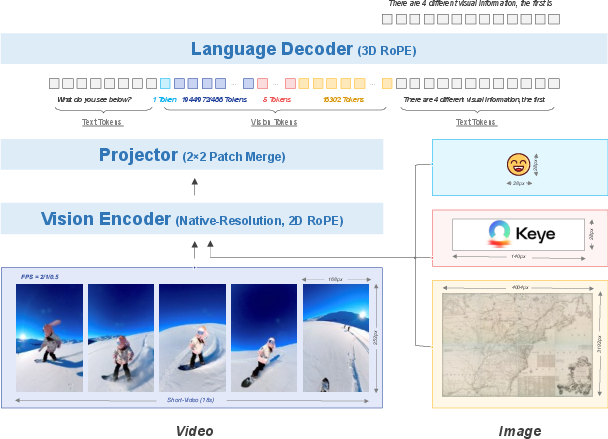
Figure 1: The architecture of Kwai Keye-VL, showcasing the integration of the Qwen3-8B LLM with a SigLIP-initialized vision encoder, and the incorporation of native dynamic resolution support and 3D RoPE.
Keye-VL adopts a classic MLLM architecture, comprising a ViT, an MLP projector, and a language decoder. The ViT leverages the open-source SigLIP-400M-384-14, while the language decoder utilizes Qwen3-8B. A randomly initialized MLP projector is fully pre-trained in the initial stage. The model incorporates a native-resolution ViT to process images at their original resolution, preserving structural integrity. This ViT is initialized with SigLIP-400M-384-14 weights and extended with interpolation techniques to create resolution-adaptive position embeddings. 2D RoPE is introduced to enhance extrapolation capabilities for positional encoding, improving performance on high-resolution images. NaViT packing with FlashAttention techniques are used to train the ViT across images with varying resolutions. For visual encoding, the model employs a dynamic resolution strategy, balancing the number of frames and total tokens for video modeling, with specific token limits per frame. Strict alignment in the time position in 3D RoPE dimensions is ensured during training.
Pre-Training Methodology
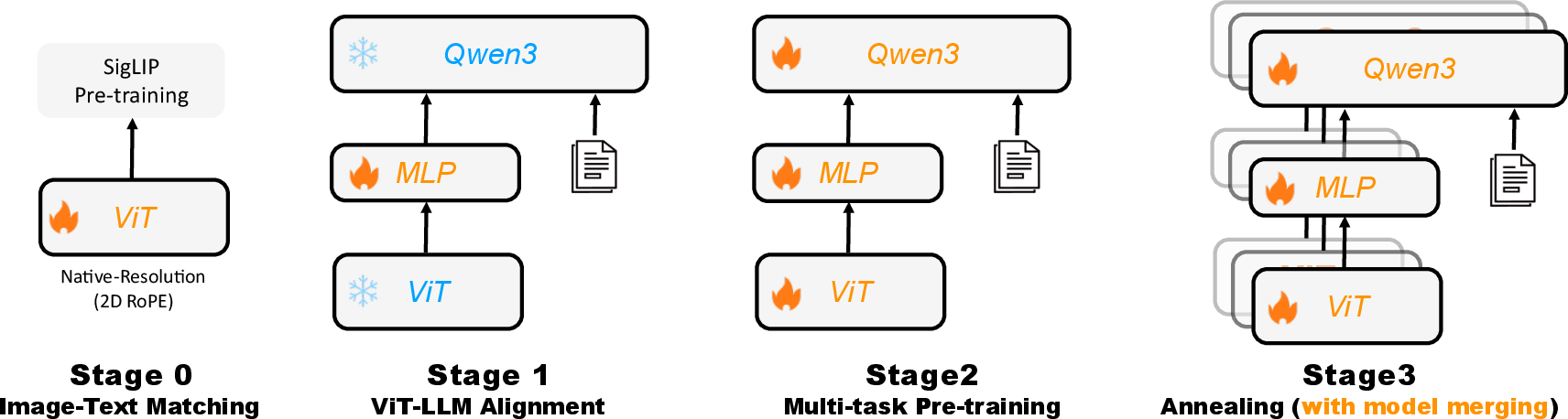
Figure 2: A depiction of the Kwai Keye pre-training pipeline, outlining the four-stage progressive strategy: Image-Text Matching, ViT-LLM Alignment, Multi-task Pre-training, and Annealing with model merging.
The pre-training pipeline involves a four-stage progressive strategy. The ViT is continuously pre-trained using the SigLIP contrastive loss function to adapt the vision encoder to the internal data distribution. The LLM is initialized from Qwen3-8B. In Stage 1, the parameters of both vision and LLMs are frozen, focusing on optimizing the projection MLP layer. Stage 2 involves unfreezing all model parameters for end-to-end optimization using a diverse set of multi-task training data, including Image Captioning, OCR, Grounding, VQA, and interleaved image-text data. Stage 3 employs an annealing phase, fine-tuning the model on a curated set of high-quality data to address insufficient exposure to such samples during Stage 2. The final phase explores a homogeneous-heterogeneous merging technique, averaging the weights of models annealed with different data mixtures to preserve diverse capabilities and enhance robustness.
Post-Training and Reasoning Enhancement
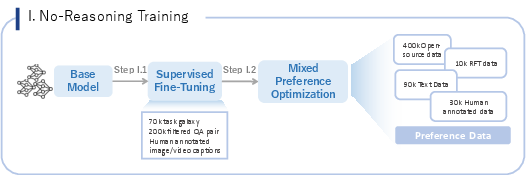
Figure 3: The No-Reasoning Training Pipeline, detailing the progression from a Base model through Supervised Fine-Tuning and Mixed Preference Optimization.
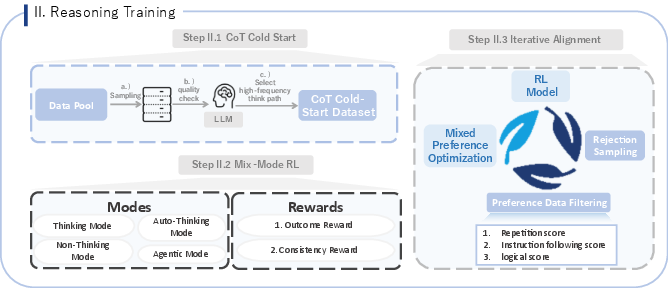
Figure 4: The Reasoning Training Pipeline, outlining the three key steps: CoT Cold Start, Mix-Mode RL, and Iterative Alignment.
The post-training process consists of two stages: establishing foundational performance in natural image understanding and text interaction, and enhancing the model's reasoning abilities. The initial phase involves SFT on a large-scale dataset, followed by MPO to solidify model stability. The subsequent stage introduces CoT capabilities through Cold-Start and refines them via RL. A crucial component is the mix-mode CoT Cold-Start, fine-tuning the model on a mixed dataset comprising non-reasoning, reasoning, automatic reasoning, and agentic reasoning samples. This strategic balance combines "LongCoT/Thinking" data with "Instruct/non-thinking" data. RL is then employed to further enhance the model's abilities, utilizing a Mix-Mode RL strategy with the GRPO algorithm. The final step focuses on iterative alignment, addressing issues like repetitive collapse and flawed reasoning logic.
Evaluation and Results
Keye-VL was evaluated across a range of benchmarks, including general vision-language tasks, Doc and OCR tasks, MATH tasks, and video-specific tasks. Results demonstrate competitive performance across most benchmarks, often achieving SOTA or near SOTA results. Notably, Keye-VL achieves top scores on the video subset of an internal benchmark, demonstrating its robust video capabilities. The model exhibits strong performance in visual element recognition, temporal information understanding, and robustness. Ablation studies demonstrate that training on CoT-Mix data strengthens both perceptual and reasoning abilities and the Mix-Mode RL strategy achieves a comprehensive and synchronous improvement.
Conclusion
Kwai Keye-VL demonstrates strong video understanding capabilities through high-quality data construction and a mix-mode training approach. The model achieves competitive performance in general image-text understanding, logical reasoning, and short video applications. The paper identifies areas for future improvement, including video encoder architecture, perceptual capabilities, and reward modeling strategies.