- The paper presents MindVL, which efficiently trains multimodal LLMs on Ascend NPUs using a native-resolution ViT architecture and a three-phase training pipeline.
- It introduces MindSpeed-MLLM, a distributed framework that employs operator fusion and system-level scheduling to optimize multimodal data processing.
- Empirical results demonstrate state-of-the-art performance on OCR and document tasks while utilizing only one-tenth of the training data compared to prior models.
MindVL: Efficient Multimodal LLM Training on Ascend NPUs
Introduction
The paper presents MindVL, a multimodal LLM (MLLM) designed for efficient and effective training on Ascend NPUs. MindVL leverages a native-resolution Vision Transformer (ViT) architecture, enabling direct processing of images at their original resolutions and aspect ratios. This approach circumvents the limitations of fixed-resolution tiling, preserving both fine-grained details and global spatial layouts, which is critical for tasks involving visually dense content such as charts, tables, and documents. The work addresses two major gaps in the current MLLM landscape: the lack of high-performance models trained on non-NVIDIA hardware and the challenge of achieving competitive performance with reduced training data.
Model Architecture and Training Pipeline
MindVL's architecture consists of three primary components: a native-resolution ViT visual encoder, a two-layer MLP projector, and a LLM backbone. The ViT employs 2D RoPE positional encoding and processes images by patching with a stride of 14, followed by spatial grouping and projection to the LLM embedding space. The visual encoder is initialized from Qwen2.5ViT weights, while the LLM backbone utilizes Qwen3 or DeepSeek V3-0324.
The training pipeline is structured into three phases:
- Warm-up Phase: Only the MLP adaptor is trained to align the ViT and LLM, using curated image captions, visual grounding, OCR, and STEM data.
- Multitask Training Phase: All model parameters are unfrozen, and the model is exposed to diverse multimodal data, including interleaved image-text, video, VQA, mathematics, and agent-based tasks.
- Supervised Fine-tuning (SFT) Phase: Targeted instruction optimization is performed to bridge the gap between pretraining and downstream task requirements.
The data curation process involves extensive filtering, clustering, and annotation to maximize diversity and relevance, particularly for long-tail visual concepts and text-rich content.
Ascend NPU Training Infrastructure: MindSpeed-MLLM
To facilitate efficient training on Ascend NPUs, the authors introduce MindSpeed-MLLM, a distributed multimodal training framework. MindSpeed-MLLM integrates optimizations from MindSpeed-Core, MindSpeed-LLM, and MindSpeed-MM, with additional enhancements for multimodal data processing, operator fusion, and system-level scheduling.
Key features include:
- Distributed Multi-Modal Data Loader: Supports group-wise data loading and online packing to minimize I/O bottlenecks and balance pipeline stages.
- Operator Fusion Replacement: Implements hardware-friendly fused operators (e.g., RMSNorm, SoftMax, FlashAttention) and replaces inefficient Conv operations with Matmul.
- System-Level Scheduling: Employs fine-grained core binding and operator deployment overlap to reduce NUMA overhead and improve throughput.
Precision alignment experiments demonstrate that MindSpeed-MLLM achieves loss curves and benchmark results comparable to mainstream NVIDIA-based frameworks, with mean absolute and relative errors within acceptable bounds.
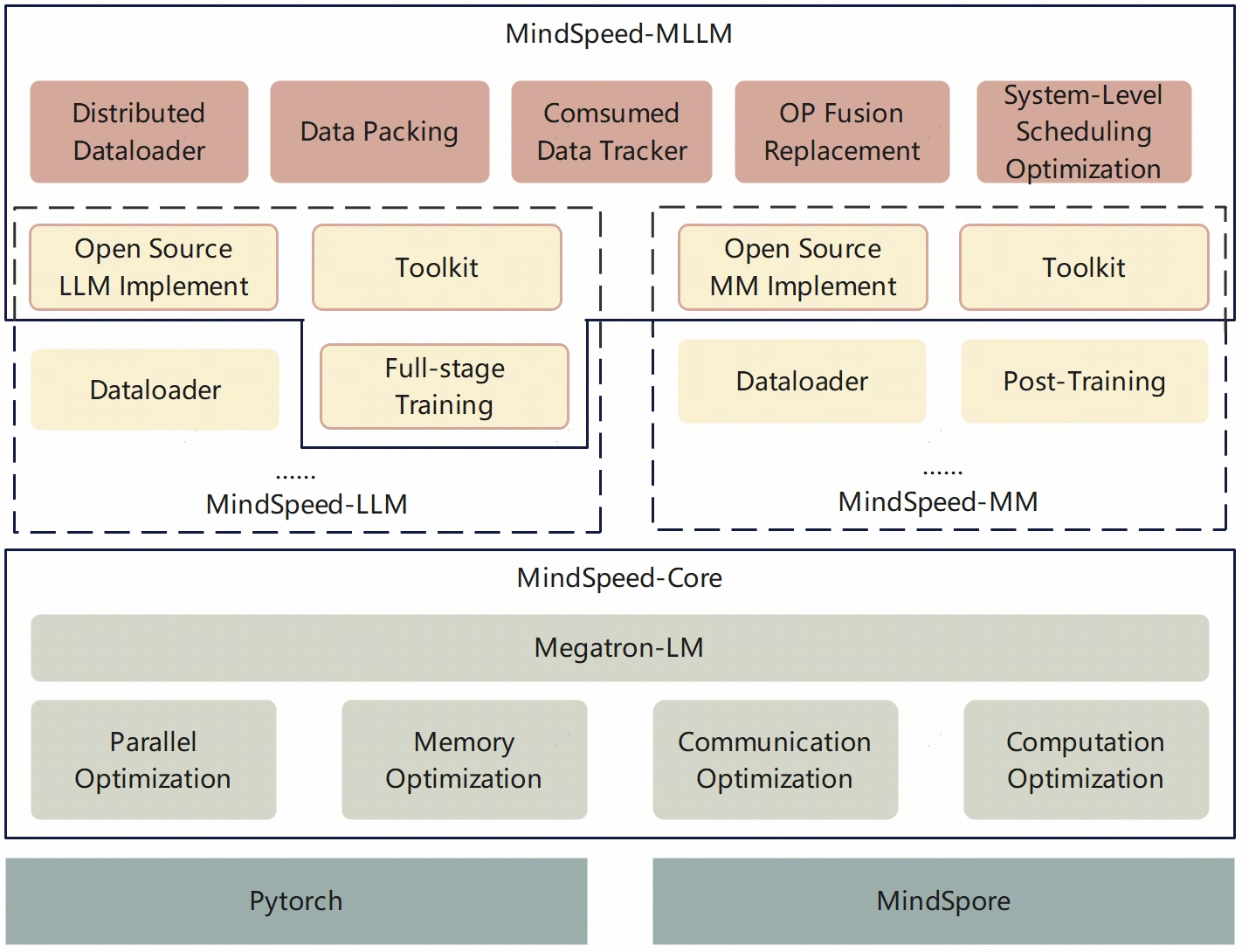
Figure 1: The hierarchical architecture of MindSpeed-MLLM, integrating core optimizations and multimodal data processing for Ascend NPUs.
Data Efficiency and Model Enhancement Techniques
MindVL achieves competitive performance using only 447B training tokens—approximately one-tenth the data required by Qwen2.5-VL. This is enabled by two key strategies:
Experimental Results
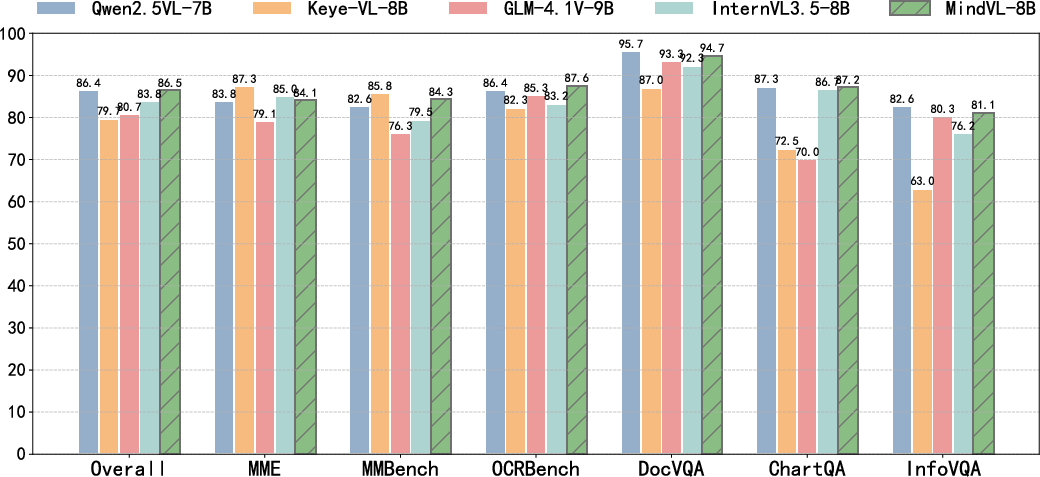
MindVL is evaluated on a suite of multimodal benchmarks, including MMBench, MME, OCRBench, DocVQA, ChartQA, and InfoVQA. The model consistently outperforms leading open-source and closed-source models, including Qwen2.5-VL 7B, GLM-4.1V 9B, Keya-VL 8B, and InternVL3.5 8B, despite its reduced training data budget. Notably, MindVL achieves state-of-the-art results in OCR-related tasks, demonstrating superior handling of text-rich visual content.
Ablation studies confirm the importance of interleaved image-text data and multitask training for overall performance. The three-phase training pipeline yields the best results, and model merging across sequence lengths further improves accuracy and robustness to input resolution variations.
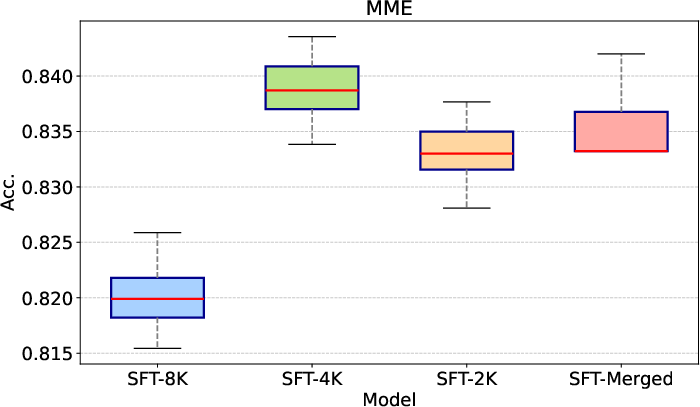
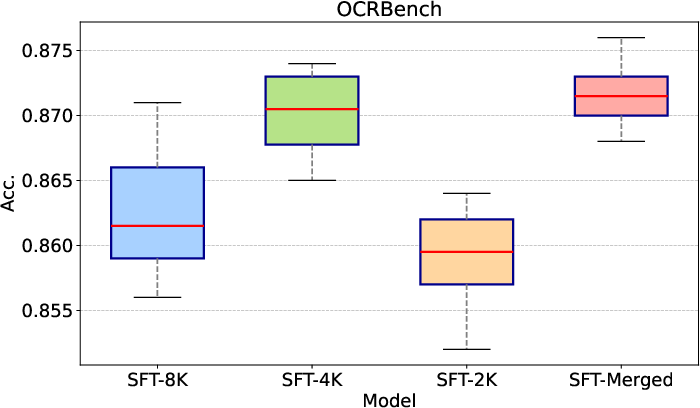
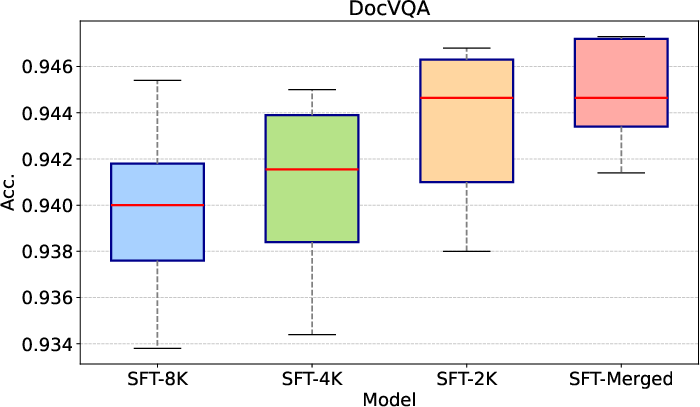
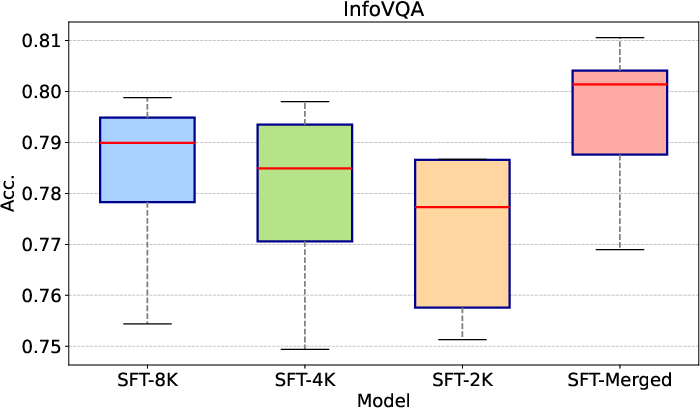
Figure 3: Box plots of accuracies for different models across varying input image resolutions, illustrating MindVL's robustness and superior median scores.
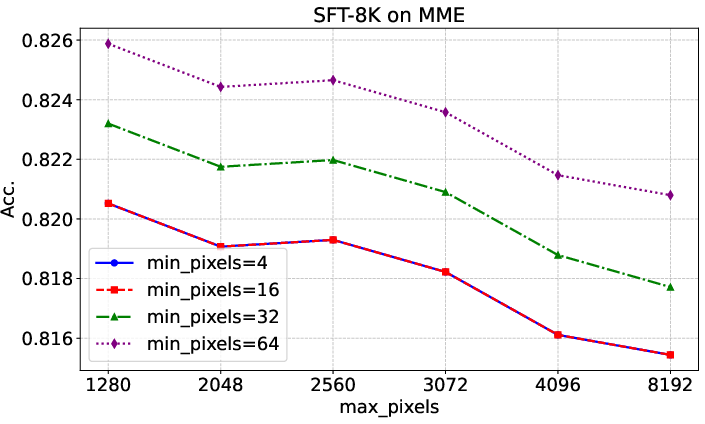
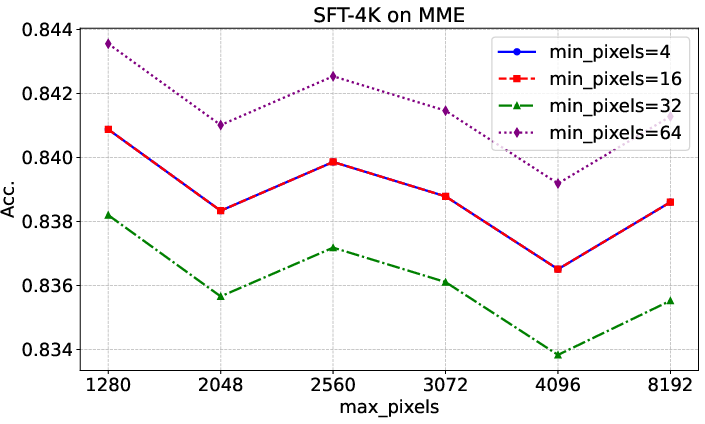
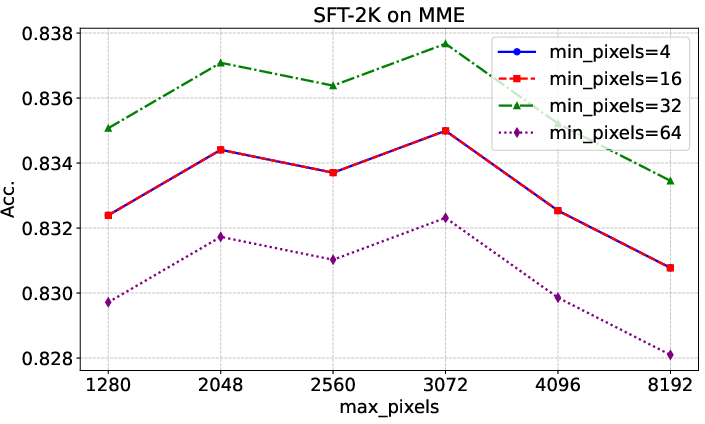
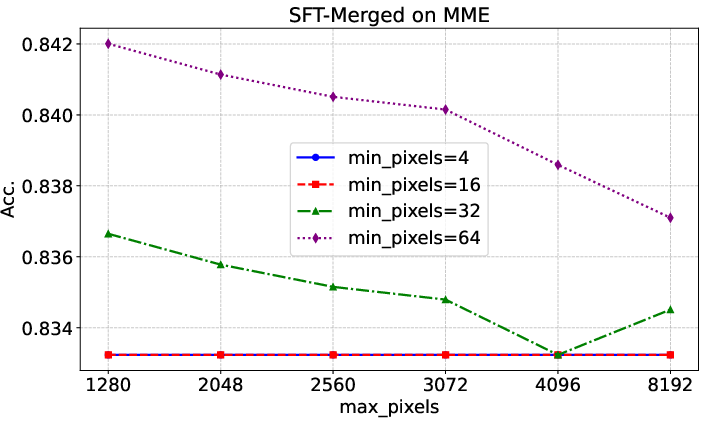
Figure 4: Evaluation results on MME with different input image resolutions, showing consistent performance across scaling parameters.
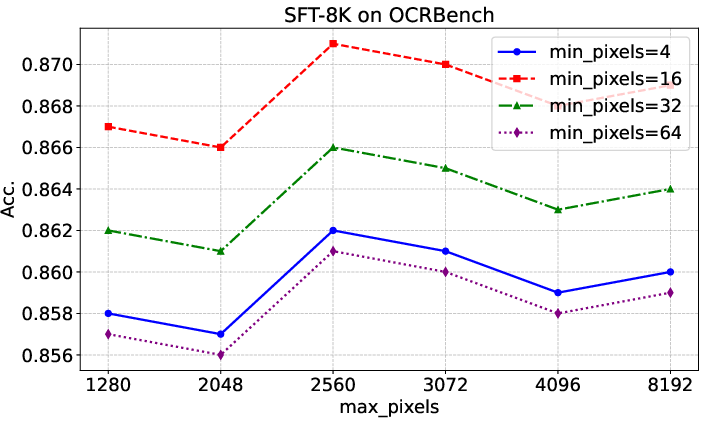
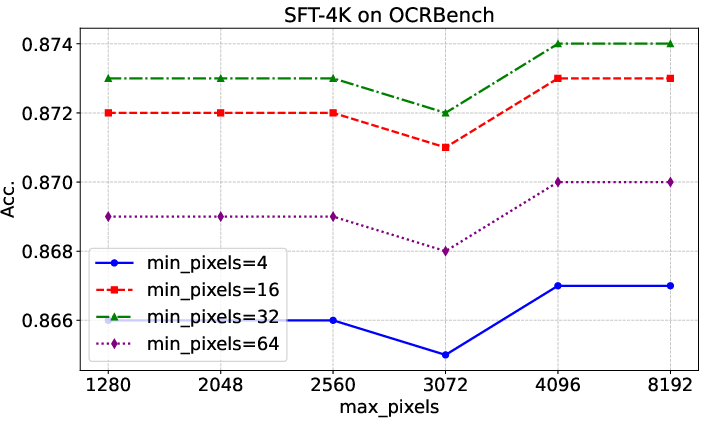
Figure 5: Evaluation results on OCRBench with different input image resolutions, highlighting the impact of resolution search on OCR accuracy.
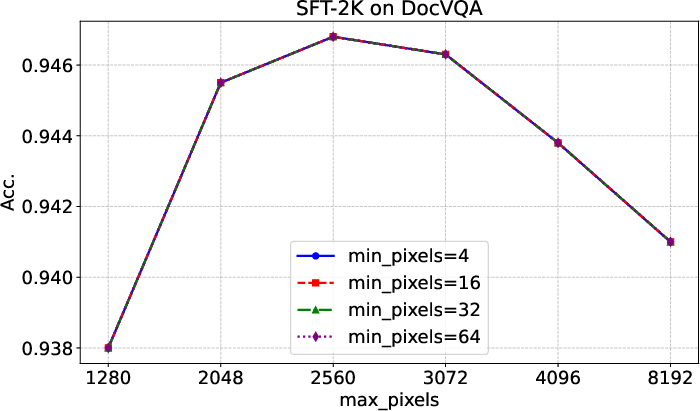
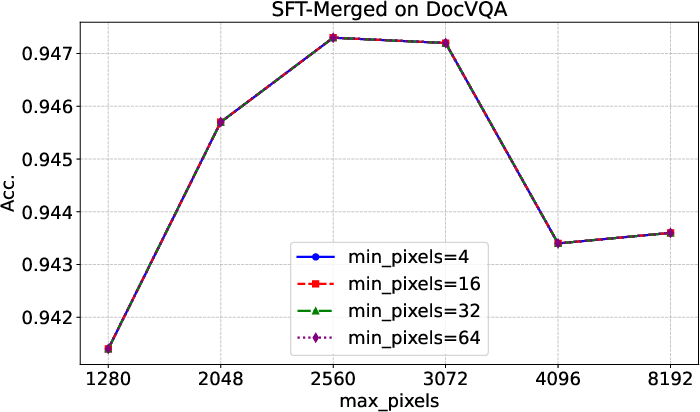
Figure 6: Evaluation results on DocVQA with different input image resolutions, demonstrating stable performance for high-resolution inputs.
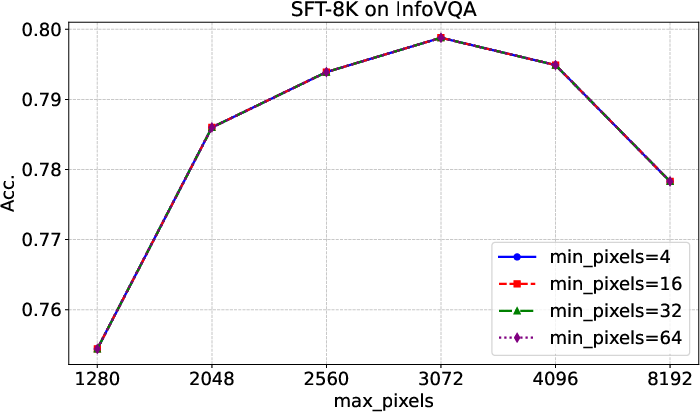
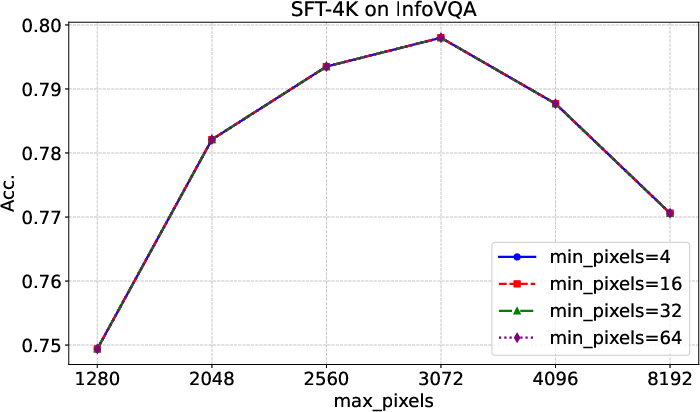
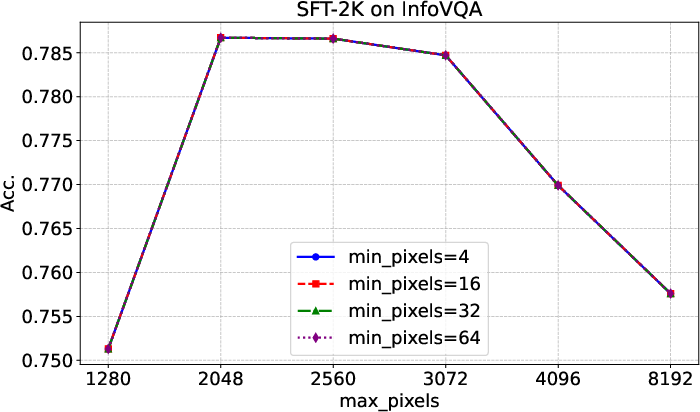
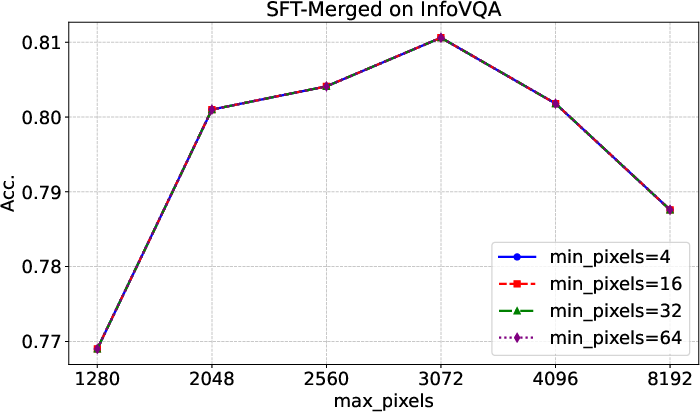
Figure 7: Evaluation results on InfoVQA with different input image resolutions, confirming optimal inference settings for infographic tasks.
Training Framework Validation
Loss curves on public and in-house datasets validate the precision and stability of MindSpeed-MLLM. The framework achieves near-perfect overlap in loss values with MindSpeed-MM when data loading is standardized, and maintains error margins within ±1.5 on general benchmarks compared to Llama-Factory.
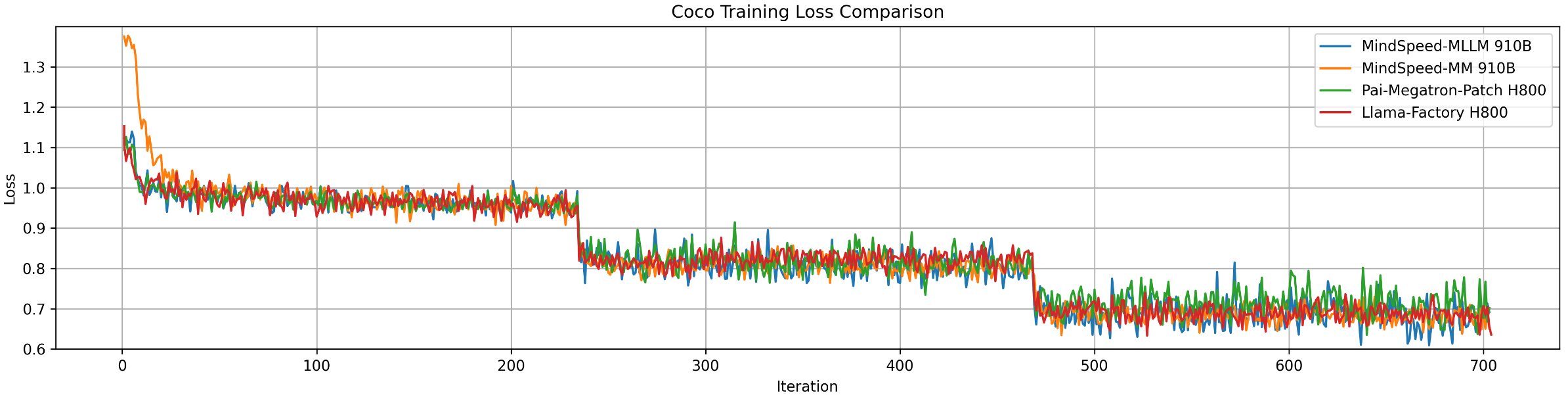
Figure 8: Comparison of loss values among various training tools and platforms on the COCO dataset, demonstrating alignment of MindSpeed-MLLM with established frameworks.
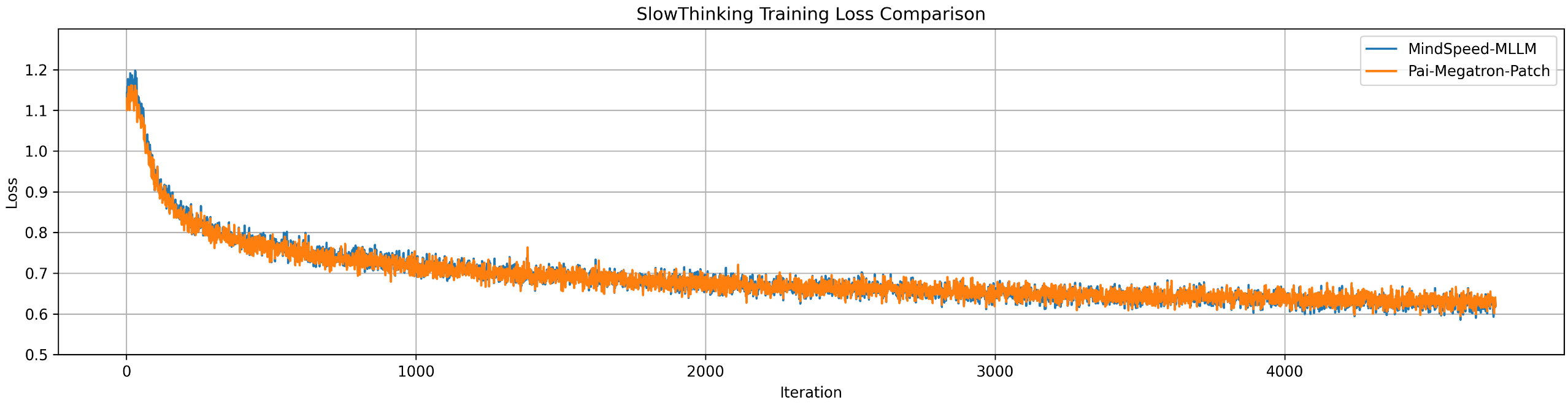
Figure 9: Loss decline trend on the in-house slow thinking dataset, confirming training stability.
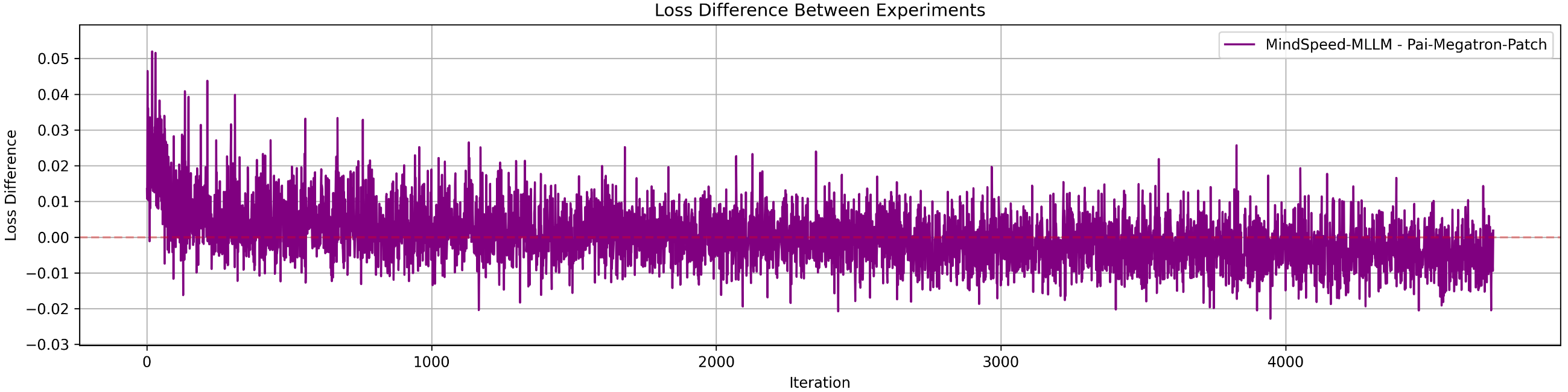
Figure 10: Loss difference between MindSpeed-MLLM and MindSpeed-MM, showing minimal discrepancies attributable to fused operator randomness.
Limitations and Future Directions
The current MindVL implementation is constrained by computational resources, limiting exploration of smaller and larger model variants and Mixture-of-Experts architectures. Data limitations preclude trillion-token scale experiments and comprehensive evaluation across grounding, reasoning, agent-based, and language-focused tasks. Preliminary results with MindVL-DeepSeek-V3 (671B MoE backbone) indicate promising scaling efficiency, with strong performance using only 26B tokens.
Future work will focus on scaling model size and data, expanding evaluation scope, and further enhancing multimodal capabilities, particularly for resource-constrained and edge deployment scenarios.
Conclusion
MindVL demonstrates that high-performance multimodal LLMs can be efficiently trained on Ascend NPUs, achieving competitive results with significantly reduced data budgets. The integration of native-resolution ViT architectures, advanced data curation, model weight averaging, and test-time resolution search collectively contribute to its robustness and versatility. MindSpeed-MLLM provides a validated, high-performance training framework for the Ascend ecosystem, enabling broader accessibility and scalability of MLLMs beyond NVIDIA hardware. The findings have practical implications for cost-effective model development and deployment in diverse hardware environments, and set the stage for future research in efficient multimodal learning and hardware-aware optimization.