- The paper introduces an 80-dimensional canonical state-action mapping that unifies diverse robotic modalities, improving OOD generalization by up to 21.5 points.
- It employs a novel camera-frame delta pose parameterization and in-context adaptation to enable cross-embodiment transfer and zero-shot instruction following.
- The study shows that unified alignment and scalable human-to-robot data synthesis yield robust performance across both simulated settings and real-world robotic benchmarks.
Qwen-RobotManip: Alignment-First Scaling for Vision-Language-Action Robotic Foundation Models
Qwen-RobotManip investigates whether scaling strategies proven effective in LLMs and multimodal foundation models—unifying heterogeneous data under a common formulation followed by large-scale training—can be leveraged to achieve genuine generalization in robotic manipulation. The work presents a technical blueprint for addressing the unique challenges posed by robotics: observation/action heterogeneity, embodiment diversity, and high demonstration cost. This essay synthesizes core contributions, methodologies, empirical validation, and the theoretical/practical implications of Qwen-RobotManip.
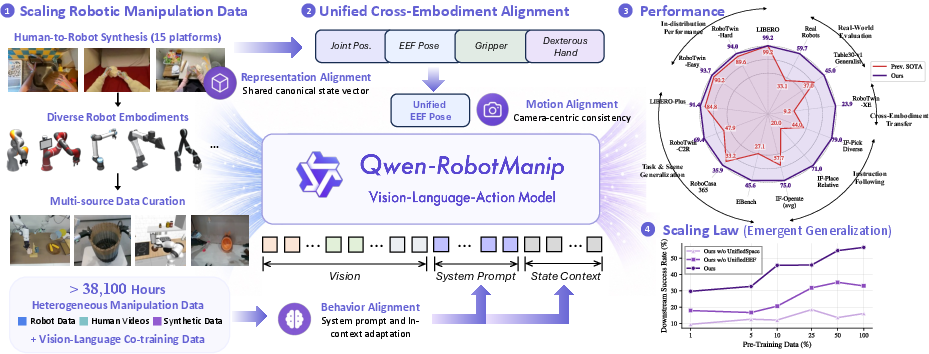
Figure 1: Qwen-RobotManip enables large-scale absorption and alignment of manipulation data, resulting in emergent generalization along key axes including OOD robustness, cross-embodiment transfer, and zero-shot instruction following.
Unifying Alignment Across Representation, Motion, and Behavior
Canonical State-Action Alignment
Robotic manipulation datasets encode state and action with robot-dependent conventions; naive mixture impedes scaling and creates optimization conflicts. Qwen-RobotManip introduces an 80-dimensional canonical state-action vector per sample with per-dimension binary masking, accommodating heterogeneous morphologies and hardware. Joint, end-effector, gripper, and dexterous hand slots are unified by semantic mapping; zero-padding and mask exclusion prevent spurious gradients.
Camera-Frame Delta Pose Parameterization
To further unify across hardware modalities, Qwen-RobotManip parameterizes end-effector actions as camera-frame delta poses, ensuring that visually similar motions have numerically close encodings regardless of embodiment, coordinate frame, or control interface. Camera extrinsics are injected into the action expert via specialized geometric positional encoding, making the action space observation-centric and promoting cross-embodiment transfer.
In-Context Policy Adaptation
Beyond explicit alignment, intra-episode behavioral signatures are captured by augmenting the input with a history window of recent observation-action tuples. This mechanism enables implicit embodiment identification and behavioral adaptation without any parameter update. Stochastic context randomization during training prevents trivial action copying, enforcing robust extraction of episode-level execution profiles.
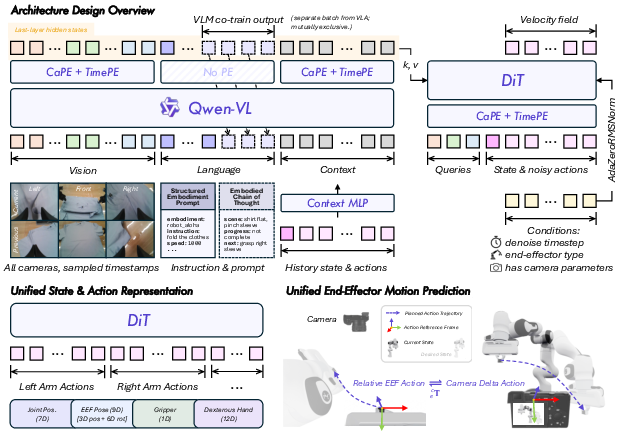
Figure 3: Model architecture overview: Qwen-RobotManip couples a Qwen-VL backbone with a flow-matching Diffusion Transformer action head, canonicalized states/actions, and camera-aware conditioning to yield robust, scalable cross-embodiment policies.
Scalable Multi-Source Data Synthesis and Rigorous Curation
Human-to-Robot Synthesis for Data Scaling
Demonstration diversity is bottlenecked by expensive robot data collection. Qwen-RobotManip employs a scalable pipeline that maps egocentric human hand videos into physically plausible, visually rendered robot trajectories across 15 morphologies. This method bridges both action and visual domain gaps via trajectory retargeting, visual inpainting, kinematic base pose optimization, and depth-guided compositing.

Figure 4: Human-to-robot pipeline: Egocentric videos are segmented, retargeted, inpainted, IK-optimized, and rendered across robot morphologies, yielding a large-scale, scalable demonstration dataset.
Unified Curation Pipeline
A five-stage signal filtering regime—sudden change, trend alignment, extreme value, FK consistency, and base/orientation frame alignment—systematically eliminates corrupt or misaligned data. These are coupled with cross-modal checks for instruction-video alignment, video-state consistency, and high-fidelity frame selection, delivering a high-quality 38,100-hour open-source corpus spanning simulated, real-world, and synthesized data.
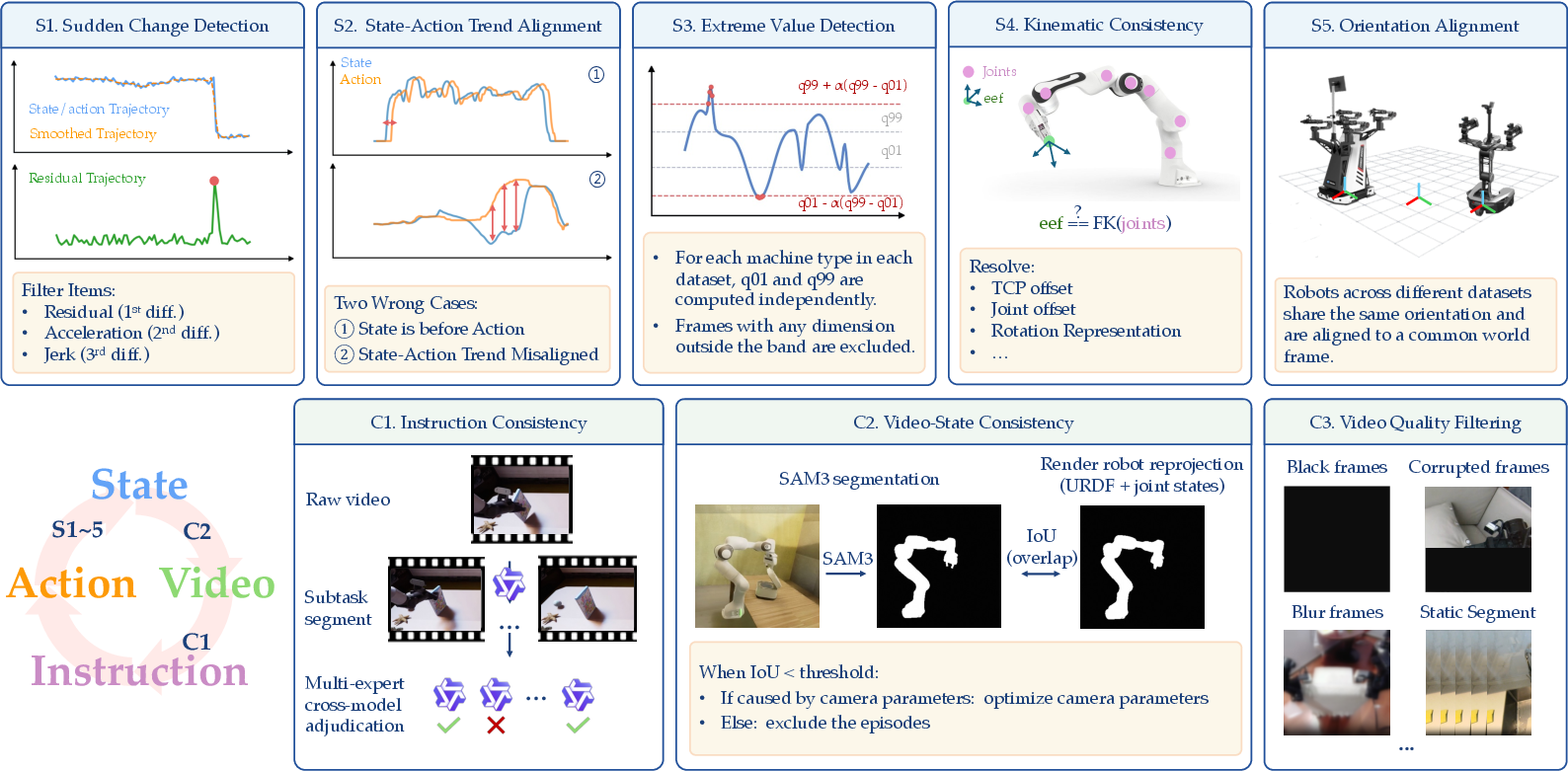
Figure 2: Data curation pipeline stages: state-action filtering and cross-modal checks ensure cross-source consistency and clean supervision for large scale training.
Model Design and Dual-Stream Co-Training
Backbone and Action Expert
Qwen-RobotManip’s architecture comprises a Qwen3.5-4B-based VLM encoding multi-view vision, embodiment prompts, historical context, and textual instructions; this is fused with a 10-block Diffusion Transformer-based action head, trained via flow-matching objectives for robust continuous action generation. Alternating cross-attention layers separately ground actions in spatial and linguistic features.
Dual-Stream Optimization
To prevent perceptual and semantic regression during action training, VLA and vision-language (VL) data are co-trained in a 9:1 ratio—VLA batches optimize policy learning, while VL batches regularize the backbone to retain broad visual, spatial, and language understanding. Specialized embodied chain-of-thought, egocentric video understanding, and future trajectory prediction datasets further bridge perception and action in the pretraining stage.
Empirical Evaluation: Out-of-Distribution Generalization as the Gold Standard
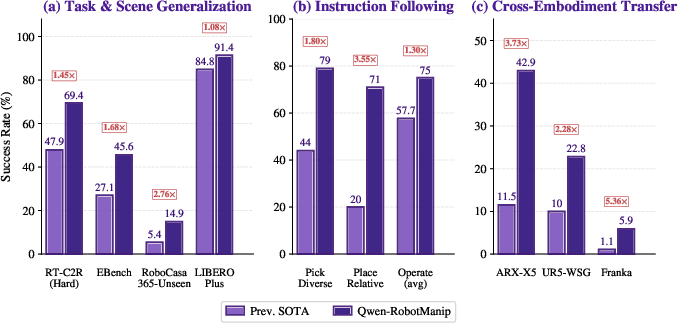
Qwen-RobotManip challenges the community’s over-reliance on in-domain benchmarks, demonstrating that models without large-scale cross-embodiment pretraining often match or exceed pretrained ones on LIBERO and RoboTwin, but collapse on OOD settings. Instead, comprehensive OOD benchmarks are adopted: LIBERO-Plus, RoboCasa365, EBench, RoboTwin-C2R, RoboTwin-IF (instruction following), and RoboTwin-XE (zero-shot cross-embodiment).
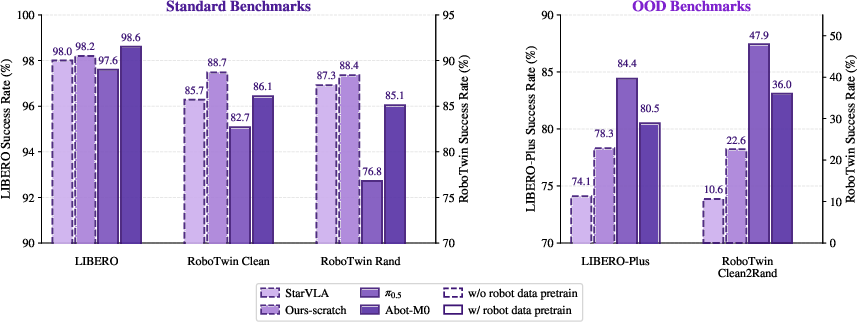
Figure 5: In-domain (left) vs OOD (right) evaluation—OOD benchmarks expose true benefits of large-scale pretraining, which standard benchmarks mask.
Key OOD Generalization Results
Real-World and Simulation Benchmarks
Robustness transfers to real hardware: on the CobotMagic ALOHA and ARX5 platforms, Qwen-RobotManip achieves up to 88.6% (in-domain) and 87.5% (OOD) success, consistently outperforming prior VLAs and training-from-scratch baselines. Extensive evaluation on RoboChallenge Table30-v1 (45% SR, up to 70% on bimanual tasks) confirms strong generalist, retry-capable, and bimanually coordinated manipulation. The model demonstrates emergent reactive behaviors (e.g., retry after failed grasps) and cross-embodiment task composition with no target-task demonstrations.

Figure 9: Bimanual manipulation: Qwen-RobotManip coordinates both arms for multi-step sequences involving stabilization, opening, grasping, and pouring, succeeding where baselines fail.

Figure 6: On RoboChallenge Table30-v1’s hardest long-horizon bimanual/manifold tasks, Qwen-RobotManip outperforms generalist baselines by over 7×.
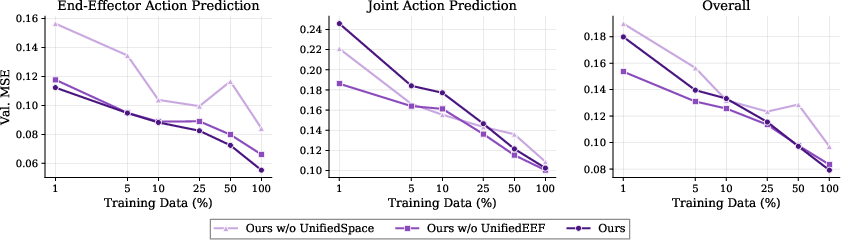
Ablation and Data Scaling Analysis
Alignment is shown to be essential for scaling: only unified state-action mapping and camera-frame EEF parameterization produce log-linear scaling of validation error with data volume. Removing unified action alignment destroys this scaling law. Ablations further confirm:
Theoretical and Practical Implications
Qwen-RobotManip empirically validates that alignment-first scaling is not just a matter of architectural elegance, but a theoretical prerequisite for converting increased data into generalization gains. The demonstration that a ∼38k-hour open-source corpus is sufficient to unlock robust OOD, language-following, and cross-embodiment generalization (with no proprietary data) suggests that data aggregation and synthetic pipelines, when properly aligned, substantially lower the foundational data barrier in robotics. The model’s emergent retry, self-corrective, and bimanual coordination behaviors further indicate that robust inductive bias, not just rote memorization, is induced by alignment-centric cross-domain pretraining.
Conclusion
Qwen-RobotManip articulates a precise, formal alignment-then-scale recipe for robotic foundation models: unify state/action/behavioral representations, harmonize large-scale data at both action and visual domains, and co-train with VL signals to stabilize semantic understanding. Robust OOD generalization emerges only from such alignment-centric pretraining, fundamentally raising the bar for VLA policy evaluation. The paradigm extends naturally to expanding embodiment and task coverage, higher-fidelity simulation, and agentic skill acquisition—charting a systematic, reproducible path toward scalable, generalist robotic manipulation.