GazeVLA: Learning Human Intention for Robotic Manipulation
Abstract: Embodied foundation models have achieved significant breakthroughs in robotic manipulation, yet they still depend heavily on large-scale robot demonstrations. Although recent works have explored leveraging human data to alleviate this dependency, effectively extracting transferable knowledge remains a significant challenge due to the inherent embodiment gap between human and robot. We argue that the intention underlying human actions can serve as a powerful intermediate representation for bridging this gap. In this paper, we introduce a novel framework that explicitly learns and transfers human intention to facilitate robotic manipulation. Specifically, we model intention through gaze, as it naturally precedes physical actions and serves as an observable proxy for human intent. Our model is first pretrained on a large-scale egocentric human dataset to capture human intention and its synergy with action, followed by finetuning on a small set of robot and human data. During inference, the model adopts a Chain-of-Thought reasoning paradigm, sequentially predicting intention before executing the action. Extensive evaluations in simulation and real-world settings, across long-horizon and fine-grained tasks, and under few-shot and robustness benchmarks, show that our method consistently outperforms strong baselines, generalizes better, and achieves state-of-the-art performance.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
GazeVLA: A simple explanation
What is this paper about?
This paper is about teaching robots to use human-like “intentions” to do hands-on tasks better. The authors build a system called GazeVLA that first figures out what a person (or robot) intends to do by looking at where the eyes would focus, and then uses that intention to guide the robot’s actions. The big idea is: people look at what they’re about to touch; if a robot can learn that pattern, it can plan and act more accurately.
What questions are the researchers trying to answer?
Here are the main goals, in everyday terms:
- Can a robot learn “what to do next” by first learning to guess where a person would look before acting?
- Can learning from lots of first-person human videos (which are easier to collect than robot data) help robots perform better with only a small amount of robot practice?
- Does explicitly thinking in two steps—first intention (where to focus), then action (what to do)—make robots more reliable and better at new, unseen situations?
How did they do it?
The approach uses a simple, human-like reasoning chain: see → intend → act.
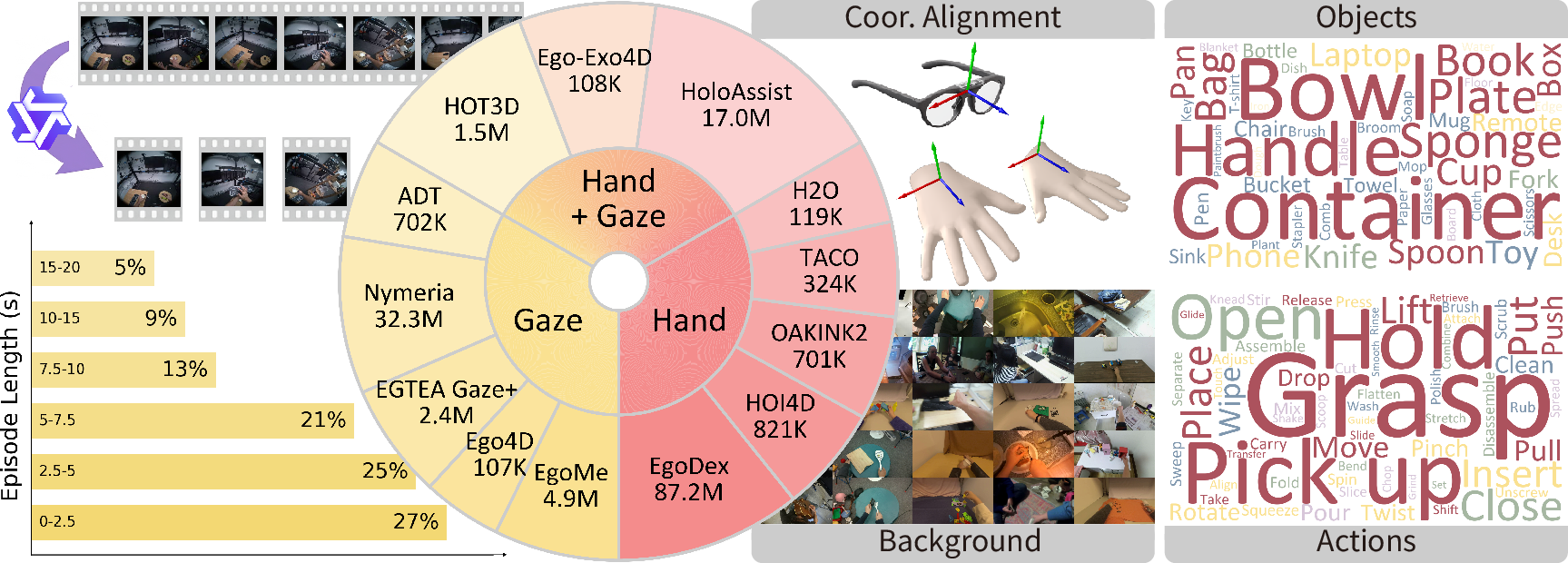
- Learning from human videos:
- The team gathered a huge collection of first-person (egocentric) videos—think of footage from glasses or head-mounted cameras—where people use their hands to do tasks. Many of these videos include “gaze” data, which tells where the person’s eyes were looking on the screen.
- They treat gaze as a stand-in for intention. For example, before you pick up a cup, your eyes usually look at the cup. So “gaze” becomes a clear, trackable clue about the goal.
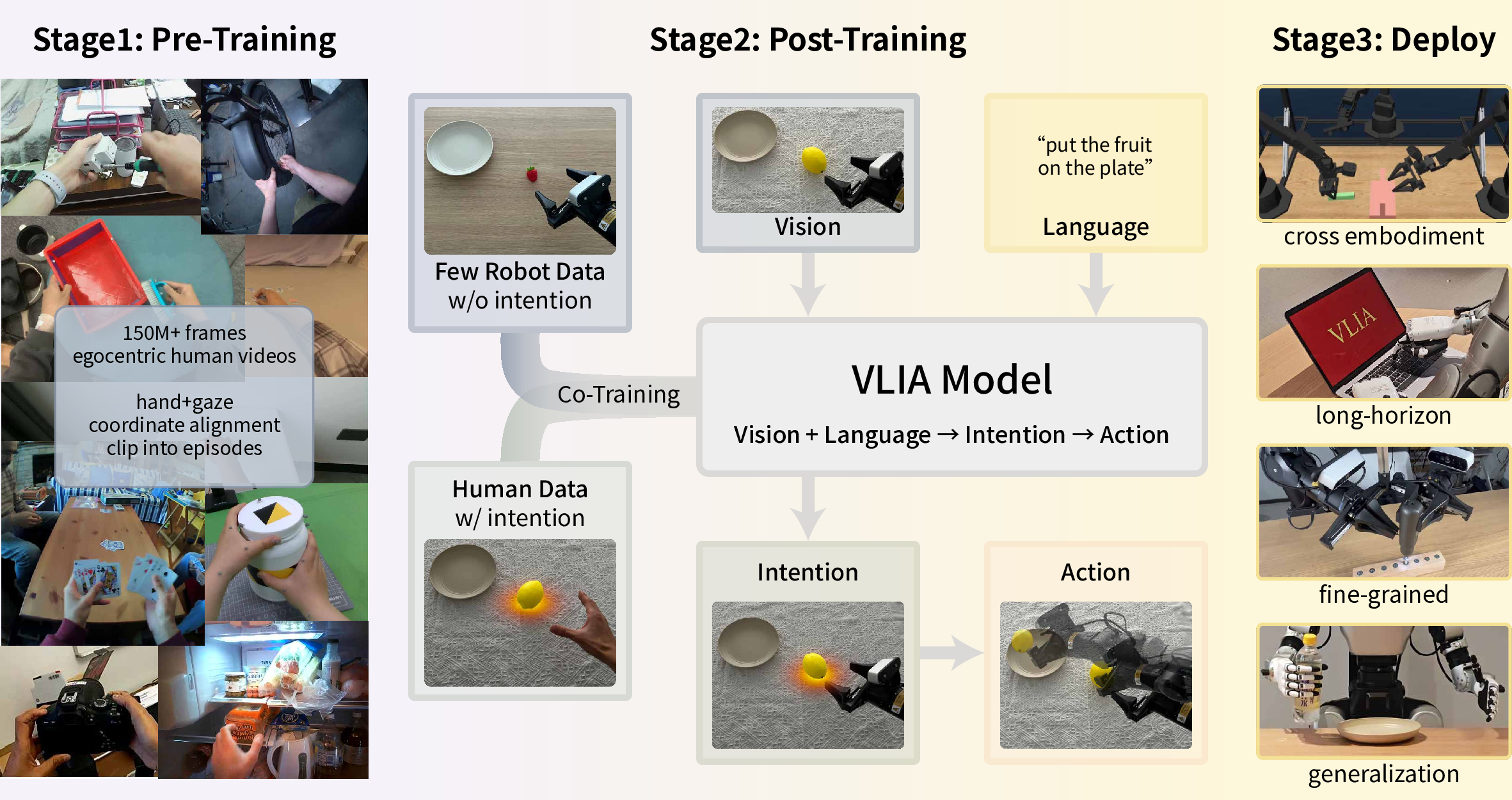
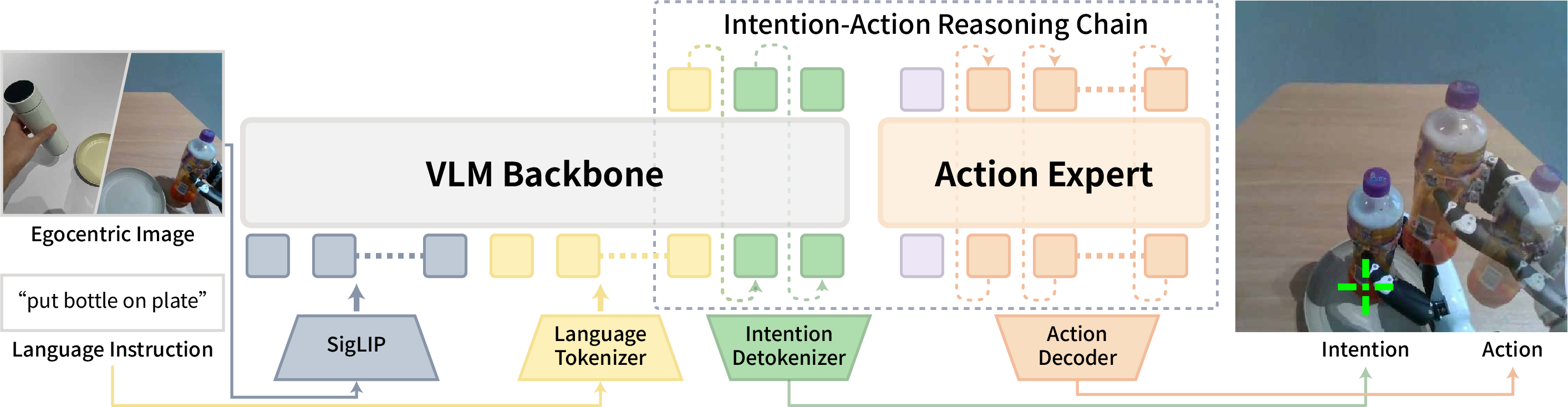
- The model (VLIA: Vision–Language–Intention–Action):
- Inputs: a camera image, a short text instruction (like “put the apple on the plate”), and the current robot or hand state.
- Step 1: Intention prediction. The model predicts a point in the image that marks where attention should go next (like the cup, the plate, or the knob).
- Step 2: Action generation. Using that intention point as guidance, it produces the hand/arm motions needed to carry out the next part of the task.
- Think of it like how you plan: you look at your target first (intention), then move your hand to do the action.
- Training in two phases:
- Pretraining: The model practices on large human video datasets to learn how gaze (intention) and hand movements (actions) go together.
- Post-training (fine-tuning): It then trains on a small amount of robot data plus some human data. Importantly, the robot data don’t need gaze labels—the model transfers what it learned about intention from humans to robots.
- A few technical ideas, in simple terms:
- “Egocentric videos” = first-person videos from head-worn cameras.
- “Embodiment gap” = humans and robots have different bodies, so their motions look different. Intention (where to focus) is more universal and easier to share across bodies.
- “Chain-of-Thought” = explicitly reason in steps: predict intention first, then actions.
- “Flow matching” for actions = a way to learn smooth, precise motions, like practicing how to steadily move from a rough guess to the correct movement.
What did they find, and why is it important?
The researchers tested GazeVLA in both simulated environments and on real robots, across short and long tasks, simple and very precise ones.
Key findings:
- Better performance with fewer robot examples:
- After learning from human videos, the robot needs fewer robot demonstrations to perform well.
- Stronger generalization:
- The robot handled new lighting, extra distracting objects, different object positions, and new scenes better than other methods. In other words, it didn’t get confused as easily when things changed.
- More precise actions:
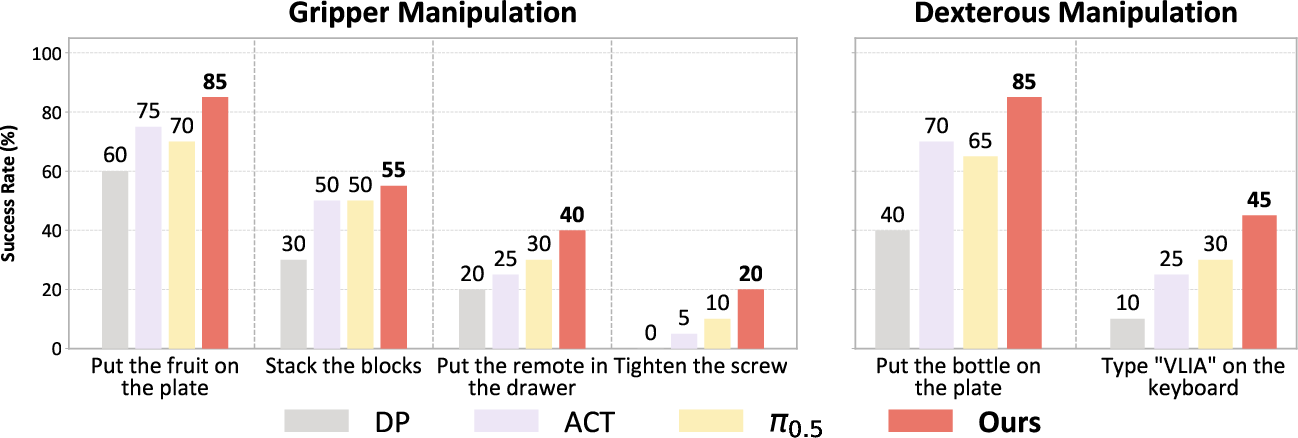
- Tasks that demand fine control (like threading a needle, tightening a screw, or placing a bottle steadily) worked better when the robot first predicted intention. It focused on the right spot and moved more accurately.
- Real-world success:
- On a two-arm robot with grippers and a robot with dexterous hands, GazeVLA achieved higher success rates than strong baselines. For example, it reached around 85% success on simple pick-and-place and roughly doubled the success of a leading baseline on screw tightening.
- The “think-then-do” design matters:
- When the model skipped the intention step and jumped straight to actions, performance dropped. Predicting intention first made the robot’s behavior more stable and accurate.
Why it matters:
- Human videos are cheap and scalable:
- It’s much easier to collect lots of human first-person videos (even with eye trackers) than to collect thousands of robot demonstrations. Learning intention from those videos saves time and cost.
- A shared “attention” bridge:
- Gaze acts like a universal language between humans and robots. Even if our bodies are different, focusing on the same target makes the robot’s next move clearer and more reliable.
What’s the bigger impact?
This work shows a promising path for teaching robots: instead of only copying what people do, first understand why they do it (their intention), then act. That shift:
- Makes robots better at long, multi-step tasks because they “know what to focus on” at each step.
- Helps robots stay robust when a room, lighting, or objects change.
- Reduces the need for expensive, large-scale robot data by leveraging abundant human videos.
In the future, the authors suggest combining human and robot data even earlier (during pretraining) and refining a shared “action space,” pushing toward robots that can learn a wide variety of tasks more like people do—by seeing, focusing, and then doing.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps and open questions that remain unresolved and could guide future research:
- Validity of gaze as an intention surrogate: when and where gaze diverges from true intent (covert attention, divided attention, social/joint tasks, anticipatory glances) is not quantified.
- Intention representation is limited to a single 2D pixel token; lacks 3D grounding, object-centric semantics, and handling of occlusion or depth ambiguities.
- No modeling of intention uncertainty; the policy does not propagate probabilistic intention (e.g., heatmaps or multi-modal hypotheses) into action generation.
- Temporal structure of intent is under-modeled: predicting a per-step point does not capture multi-step plans, subgoal sequences, or hierarchical intentions over long horizons.
- Human–robot viewpoint/embodiment gap is only implicitly handled via augmentation; effects of camera pose mismatch and different optics between head-mounted and robot cameras are not measured or corrected in 3D.
- Robot-side intention supervision is absent; the minimal amount/type of robot intention data needed (if any) and the benefits of weak robot intention labels remain unexplored.
- Active perception coupling is unclear: whether and how predicted intention guides camera/eye-in-hand motion in platforms with movable sensors (e.g., AV-ALOHA) is not evaluated.
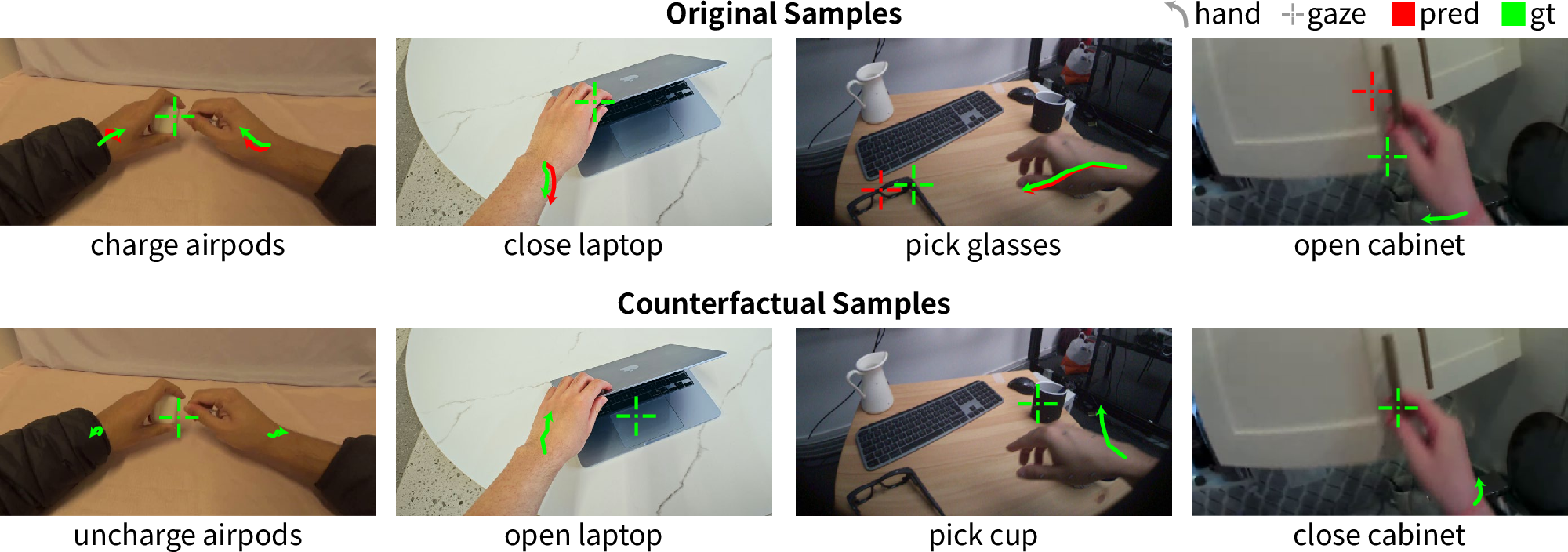
- Counterfactual/causal evaluation of intention is limited: beyond a “w/o CoT” ablation, causal interventions that force intention to specific targets to assess downstream action changes are missing.
- Alternative intention signals are not compared: head motion, hand pre-shape, object proposals, learned visual saliency, proprioceptive cues, or language-inferred goals as substitutes or complements to gaze.
- Scope of generalization tests is narrow: limited OOD scenarios (lighting, distractors, simple position/object/background shifts) without stress-testing heavy clutter, occlusion, deformables, dynamic agents, or multi-task settings.
- Cross-embodiment breadth is limited to two platforms (ALOHA, Unitree G1); transfer to mobile manipulators, single-arm platforms, soft hands, or aerial manipulation is untested.
- Dataset curation quality is under-analyzed: atomic action segmentation via an LLM (Qwen) and multi-source label noise are not audited for accuracy or impact on learning.
- Scaling laws and data efficiency are not characterized: performance vs. amount/diversity of human pretraining and robot finetuning data remains unknown.
- Statistical rigor is limited: success rates lack confidence intervals, variance estimates, or significance testing across seeds/sessions.
- Real-time performance and resource footprint are unreported: latency, throughput, memory/compute on robot hardware, and their effects on control stability are not measured.
- Failure-mode taxonomy is absent: when intention prediction is wrong or ambiguous, how errors propagate to actions and how to recover is not systematically studied.
- Intention binning granularity/design is not analyzed: trade-offs between token resolution, vocabulary size, and manipulation accuracy/speed are unknown.
- No explicit 3D alignment pipeline from predicted 2D intention to robot world coordinates is described or evaluated for calibration error and its impact on grasp precision.
- Flow-matching action generation details (control horizon H, control rate, closed-loop vs. open-loop stability) are not systematically ablated or analyzed.
- Joint pretraining on human and robot in a unified latent action space is acknowledged as missing; concrete alignment mechanisms and benefits remain open.
- Robustness to missing/noisy gaze labels during pretraining and to intention prediction noise at inference is not quantified; masking strategies and denoising efficacy need ablation.
- Bias analysis is limited: center bias, device-dependent biases, and demographic variability in gaze behavior are not measured or mitigated beyond augmentation.
- Cross-device gaze robustness is untested: generalization across different AR/VR eye trackers, calibration drift, slippage, and field-of-view changes is unknown.
- Personalization vs. universality: inter-user variation in gaze–action coupling and whether user-adaptive intention models improve transfer are unexplored.
- Integration with object-centric perception is minimal: explicit object detection/tracking or affordance models that could anchor intention to manipulable entities are not leveraged.
- Human-in-the-loop correction is absent: mechanisms for online correction of mispredicted intention (via gaze, touch, or voice) and their efficacy are untested.
- Negative transfer during joint finetuning is observed but not mitigated: strategies such as domain-balanced sampling, adapters, regularization, or curriculum learning are not explored.
- Ethical and privacy considerations of large-scale gaze collection in the wild (consent, storage, re-identification risk) are not discussed.
- Task diversity is modest: few-shot real tasks focus on pick-place, tool use, and a typing demo; broader task families (assembly, deformable manipulation, force-critical tasks) are not evaluated.
- Comparative ablations on CoT structure are limited: beyond “intention-then-action,” richer multi-step CoT (e.g., subgoal text tokens, temporal waypoints) are not investigated.
- Synergy between gaze and hand cues is claimed but not ablated: contributions of hand pose/trajectory vs. gaze to intention inference and control are not disentangled.
- Reproducibility details are partial: preprocessed multi-dataset release, license harmonization, coordinate alignment code, and preprocessing sensitivity analyses are not specified.
- Leveraging reinforcement learning or self-improvement is untouched: whether intention-aware policies benefit from RL fine-tuning, self-play, or autonomous data collection remains an open direction.
Practical Applications
Overview
This paper introduces GazeVLA (VLIA), a vision–language–intention–action framework that uses human gaze as an explicit, intermediate representation of intention to bridge the human–robot embodiment gap. Pretrained on large-scale egocentric human videos with gaze and hand annotations, then post-trained on a small set of robot and human data, the model performs a Chain-of-Thought (CoT) inference: predict intention first (via gaze tokens), then generate continuous actions. It consistently improves success rates, sample efficiency, long-horizon reasoning, fine-grained manipulation, and out-of-distribution robustness versus strong VLA baselines.
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations, grouped by deployment horizon.
Immediate Applications
These can be piloted or deployed now using off-the-shelf AR gaze devices, existing robots, and the released methodology.
- Intention-guided few-shot skill learning for cobots (Robotics/Manufacturing)
- Use case: Rapidly teach assembly subtasks (e.g., screw tightening, peg insertion, hook/slot operations) by collecting ~50 human demos with AR glasses plus ~10 robot demos per task; deploy intention-first policy for robust execution under varying lighting and distractors.
- Tools/workflows: AR gaze capture (e.g., Pupil Labs), unified data processing (segmentation, gaze filtering), VLIA pretrain + 1:1 human–robot post-training, ROS2 integration for action execution.
- Assumptions/dependencies: Egocentric robot camera view aligned with human egocentric data; reliable gaze tracking; on-prem compute or edge GPU for real-time inference; safety cages or force limits for manipulation near humans.
- Robust warehouse picking and placement under visual variability (Logistics/Retail)
- Use case: Reduce mispicks and cycle time degradation when SKUs, backgrounds, or lighting change; intention tokens focus policy on target items amid distractors.
- Tools/workflows: SKU onboarding via AR-assisted human demos; intention-aware policy deployed on existing arms/grippers.
- Assumptions/dependencies: Calibrated cameras; sufficient demonstrations covering typical SKU variations; object handling safety and throughput requirements.
- Operator-in-the-loop teleoperation assistance with intention overlays (Software/Robotics HRI)
- Use case: During teleoperation or remote supervision, show the system’s predicted intention as a visual crosshair to increase trust, reduce cognitive load, and prevent mis-clicks/grasps.
- Tools/workflows: UI plugin overlaying intention estimates in the teleop feed; optional shared control blending.
- Assumptions/dependencies: Low-latency video; calibrated display mapping; human factors validation.
- Assistive home robots taught by caregivers (Daily Life/Assistive Tech)
- Use case: Train household tasks (e.g., place bottle on shelf, set table, pick-and-place) with minimal robot demos; caregivers wear AR glasses to provide scalable intention-labeled demonstrations.
- Tools/workflows: Home demo collection kit; intention-guided policies for bimanual grippers or dexterous hands; fallback safety monitors.
- Assumptions/dependencies: Safety certification and geofenced operation; robust perception in clutter; consent and privacy of all household members.
- Intention-aware QA and benchmarking for embodied AI (Academia)
- Use case: Use the curated 150M-frame egocentric dataset and VLIA to study intention–action causality, reduce shortcut learning, and evaluate generalization under OOD scenes.
- Tools/workflows: Public dataset curation pipeline, gaze tokenization, conditional flow-matching action heads; reproducible baselines for AV-ALOHA and real-robot tasks.
- Assumptions/dependencies: Access to AR datasets with gaze; compute for pretraining; standardized metrics.
- Rapid customization services for integrators (Industry Services/Software)
- Use case: “Intention-Guided Policy Tuning” offering: on-site AR data collection, short post-training cycles, deployment of VLIA as a ROS2 controller plugin for customer-specific tasks.
- Tools/workflows: Intention SDK, dataset ingestion and QA, prebuilt training pipelines, MLOps for fine-tuning and rollback.
- Assumptions/dependencies: Customer approval for data recording; device provisioning; edge or cloud GPUs.
- Privacy-by-design gaze data governance (Policy/Compliance)
- Use case: Draft and enforce internal policies for gaze data handling (collection consent, minimization, on-device filtering of saccades/low-confidence samples, retention limits).
- Tools/workflows: DPIAs (data protection impact assessments), consent flows in AR apps, secure storage with access logging, anonymization of video scenes.
- Assumptions/dependencies: Jurisdictional compliance (e.g., GDPR/CCPA); employee training and audit trails.
Long-Term Applications
These require additional research, scaling, or regulatory approvals to achieve robust, domain-wide deployment.
- Proactive human–robot collaboration via intention anticipation (Robotics/Manufacturing)
- Use case: Cobots that anticipate a worker’s next subgoal (based on gaze + language) to stage tools or parts, hand over items, or pre-align fixtures.
- Potential products: Intention-aware shared autonomy controllers; predictive workcell orchestrators.
- Assumptions/dependencies: High-precision real-time gaze tracking on the shop floor; multimodal intent fusion (gaze, pose, voice); safety standards for proactive behavior.
- Surgical and interventional robotics guided by expert gaze (Healthcare)
- Use case: Training and assistance systems that use surgeon gaze to infer subgoals for instrument manipulation, camera alignment, or tool positioning; intention-aware autonomy in constrained contexts.
- Potential products: Surgeon-assist modules that translate gaze into subgoal tokens for robot controllers; gaze-based skill assessment tools.
- Assumptions/dependencies: Sterile, reliable eye-tracking; rigorous clinical validation; regulatory approval (FDA/CE); medico-legal frameworks.
- Rehabilitation and prosthetics with cross-embodiment intention transfer (Healthcare)
- Use case: Translate user intention (gaze + minimal biosignals) into dexterous prosthetic control for object-centric tasks.
- Potential products: Intention decoders coupled to prosthetic hand controllers; home training kits.
- Assumptions/dependencies: Integration with EMG/EEG for robust intent beyond gaze; personalization loops; safety and comfort.
- Home general-purpose robots with intention-driven long-horizon planning (Consumer Robotics)
- Use case: Household assistants that identify user-intended objects and subgoals from gaze and verbal instructions to sequence multi-step tasks (e.g., cooking prep, tidying).
- Potential products: “Intention-first” planners integrated with VLA policies and household knowledge graphs.
- Assumptions/dependencies: Expanded training across diverse homes; reliable object-state tracking; fail-safe behaviors; affordability.
- Educational and lab automation assistants (Education/R&D Labs)
- Use case: Lab robots that infer student or researcher intention (e.g., which reagent/tool is next) to fetch or prepare materials, reducing task-switching overhead.
- Potential products: Intention-aware bench-top assistants; classroom demonstrators for STEM education.
- Assumptions/dependencies: Fine-grained safety in wet labs; reliable tracking in clutter; curriculum integration.
- Multi-robot teams coordinated via shared intention spaces (Robotics/Autonomy)
- Use case: Teams of manipulators and mobile platforms share intention tokens (current focus of attention/subgoals) for division of labor and reduced communication bandwidth.
- Potential products: “Intention bus” middleware for multi-agent coordination.
- Assumptions/dependencies: Standardized intention token APIs; synchronization and conflict resolution; robust localization.
- Standardization of intention datasets and certification (Policy/Standards)
- Use case: Sector-wide schemas for gaze-intention data collection, storage, and benchmarking; certification for intention-aware robots in public or industrial settings.
- Potential products: Standards for gaze accuracy, calibration, latency; conformance test suites; third-party certification bodies.
- Assumptions/dependencies: Industry consortia participation; alignment with safety regulators; international harmonization.
- Federated and privacy-preserving intention learning (Software/AI Infrastructure)
- Use case: Train intention models across organizations/devices without centralizing raw gaze video using federated learning and on-device tokenization.
- Potential products: Federated “intention head” training frameworks; secure aggregation services.
- Assumptions/dependencies: Edge compute on AR devices; differential privacy; robust on-device calibration.
- Beyond-gaze multimodal intention modeling (R&D)
- Use case: Fuse gaze with hand pose, speech prosody, bio-signals, and environmental context to improve intent estimation for contact-rich tasks and populations with variable gaze behavior.
- Potential products: Multimodal intention encoders; generalized intention-to-action compilers for different embodiments.
- Assumptions/dependencies: Sensor fusion reliability; datasets covering diverse users and tasks; model interpretability.
- Joint pretraining in a shared human–robot latent action space (R&D/Tooling)
- Use case: Address the paper’s stated limitation by co-pretraining on human and robot data in a unified action space to enable faster adaptation and broader generalization.
- Potential products: Foundation VLA models with native intention layers and shared latent actions; plug-and-play adapters for new robot arms/hands.
- Assumptions/dependencies: Large-scale synchronized human–robot datasets; cross-embodiment alignment methods; compute budget and evaluation suites.
Notes on feasibility across applications:
- Data dependencies: High-quality egocentric datasets with calibrated gaze are key; the paper’s pipeline (segmentation with LLMs, gaze filtering, synchronized augmentations) should be replicated.
- Hardware dependencies: AR/VR devices with accurate eye tracking; robot cameras approximating egocentric perspectives; dexterous end-effectors where fine manipulation is required.
- Performance constraints: Real-time intention prediction and action generation under domain shifts; robust handling of occlusions and clutter.
- Safety and compliance: Intention-driven behaviors must be bounded by safety monitors; gaze data are sensitive and require strict privacy handling and consent.
Glossary
- 2D visual primitives: Structured 2D cues (e.g., keypoints, boxes, trajectories) used as intermediate supervision for learning from videos. "2D visual primitives"
- 6-DoF rotations: A six-parameter representation of 3D orientation (often used as a stable rotation parameterization in learning/control). "6-DoF rotations"
- Action expert: A specialized module that generates the control actions, typically conditioned on other model components. "The action expert is designed to generate high-frequency, continuous actions through conditional flow matching."
- Action space: The set of all permissible actions a robot/controller can output, often characterized by its dimensionality. "a total action space of 21-DoF"
- Affordances: Action possibilities offered by objects or environments, often used to guide manipulation policies. "object-centric affordances"
- Active vision: Controlling camera motion or viewpoint to gather better task-relevant visual information. "active vision"
- Autoregressive tokenization strategies: Converting inputs/outputs to token sequences predicted one-by-one in order. "autoregressive tokenization strategies"
- Bimanual manipulation: Coordinated use of two arms/hands for manipulation tasks. "bimanual manipulation"
- Center bias: The tendency of human gaze to fixate near the image center, which can bias learning. "center bias"
- Chain-of-Thought (CoT): An explicit, step-by-step reasoning process used to improve task decomposition and planning. "Chain-of-Thought (CoT)"
- Conditional flow matching: A training objective for flow models that learns conditional vector fields to generate continuous outputs. "conditional flow matching"
- Counterfactual samples: Inputs modified to test causal reasoning (e.g., change instructions while keeping visuals constant). "Counterfactual samples"
- Degrees of Freedom (DoF): Independent parameters that define configuration of a system (e.g., joints or pose). "7-DoF"
- Dexterous manipulation: Fine, precise object interactions using multi-fingered hands. "dexterous manipulation"
- Diffusion-based policy: A control policy that uses diffusion models to sample or denoise action sequences. "diffusion-based policy"
- Egocentric human videos: First-person-view recordings capturing human actions and context. "egocentric human videos"
- Embodied foundation models: Large pretrained models tailored for agents interacting in the physical world. "Embodied foundation models"
- Embodiment gap: The mismatch between human and robot bodies/sensors/actuators that complicates knowledge transfer. "embodiment gap"
- Exocentric views: Third-person camera perspectives observing the scene from outside the agent. "exocentric views"
- Few-shot: Learning or adapting from a very small number of examples. "few-shot"
- Flow-based generative paradigms: Generative modeling approaches using (normalizing) flows or learned vector fields for continuous outputs. "flow-based generative paradigms"
- Forward kinematics: Computing end-effector/point positions from joint configurations via the kinematic chain. "forward kinematics"
- Gemma-2B: A 2-billion-parameter Gemma family LLM used as part of the multimodal backbone. "Gemma-2B"
- Intention tokens: Discretized representations (tokens) of inferred intentions, e.g., gaze positions, used by the model. "intention tokens"
- KV cache: Transformer key–value memory used to speed up and condition subsequent token generation. "KV cache"
- Latent action space: An abstract, shared action representation that aligns behaviors across embodiments. "latent action space"
- Long-horizon tasks: Tasks requiring multi-step, temporally extended planning and execution. "long-horizon tasks"
- MANO model: A parametric 3D hand model widely used to reconstruct hand pose and shape. "MANO model"
- Multimodal signals: Data combining multiple modalities (e.g., RGB, depth, gaze, pose). "multimodal signals"
- Next-token prediction: Predicting the next symbol in a token sequence, standard in autoregressive models. "next-token prediction"
- Out-of-distribution (OOD): Test conditions that differ from the training distribution, used to assess generalization. "out-of-distribution settings"
- PaliGemma: A multimodal backbone combining a SigLIP vision encoder with a Gemma LLM. "PaliGemma"
- Post-training: A training phase after pretraining, often for adaptation or alignment to new data/distributions. "post-training"
- Representation collapse: Degeneration where a model’s learned features lose diversity or informativeness. "representation collapse"
- Saccades: Rapid eye movements between fixation points; often filtered out in gaze processing. "saccades"
- SigLIP: A vision encoder trained with a sigmoid loss variant for contrastive image–text pretraining. "SigLIP"
- Spatial binning: Discretizing continuous spatial coordinates into a grid of bins for tokenization. "spatial binning"
- Teleoperation: Human remote control of a robot, often used to collect demonstrations. "teleoperation"
- Vision-Language-Action (VLA): Models that jointly process vision and language to output actions. "Vision-Language-Action (VLA)"
- Vision-LLMs (VLM): Models that integrate visual and textual inputs for joint understanding. "Vision-LLMs (VLM)"
- World-model pretraining: Pretraining predictive models of environment dynamics to support planning/control. "world-model pretraining"
Collections
Sign up for free to add this paper to one or more collections.