- The paper presents a minimalist VLA system using a powerful pretrained VLM and a lightweight MLP, showing that simple action modeling can rival complex architectures.
- The study demonstrates that a unified data pipeline and cross-benchmark integration yield robust, reproducible performance across diverse robotic tasks.
- Empirical findings reveal that further robot-specific pretraining and complex action parameterizations offer diminishing returns, advocating for controlled, standardized evaluation.
StarVLA-α: Reducing Complexity in Vision-Language-Action Systems
Motivation and Context
The Vision-Language-Action (VLA) paradigm is fundamental to the development of general-purpose robotic agents. Despite recent advances enabled by large-scale VLMs and robotic policy learning, the field is characterized by significant methodological heterogeneity: disparate architectures, benchmark-specific pipelines, non-standardized action representation, and diverse training protocols confound empirical analysis and comparison. The lack of methodological consensus leads to empirical improvements that are difficult to attribute to core architectural progress rather than to dataset composition, engineering decisions, or task-specific tuning.
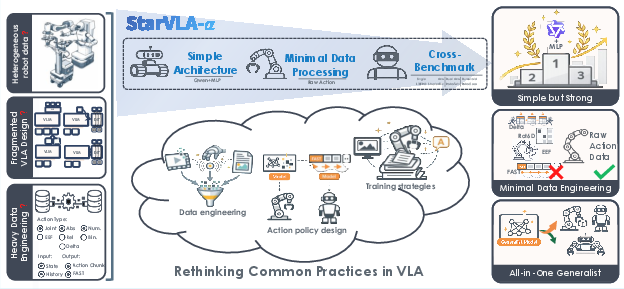
Figure 1: Current VLA systems are challenging to compare due to heterogeneous robot datasets, fragmented architectures, and heavy benchmark-specific engineering; StarVLA-α removes these confounders with a simple VLM-based architecture, minimal data processing, and unified cross-benchmark training.
Against this background, "StarVLA-α: Reducing Complexity in Vision-Language-Action Systems" (2604.11757) directly addresses these confounding factors by introducing an intentionally minimalist yet performant VLA baseline, enabling rigorous analysis of modeling and engineering interventions under strictly controlled conditions.
Methodology and Framework
StarVLA-α is derived from the minimal-sufficiency hypothesis: a strong, pretrained VLM (Qwen3-VL) coupled with a lightweight MLP action head, under a unified and minimal data processing pipeline, suffices to reach or exceed the state-of-the-art across a suite of diverse manipulation benchmarks, without the need for embodiment-specific engineering, recurrent structures, auxiliary inputs, or architectural complexity.
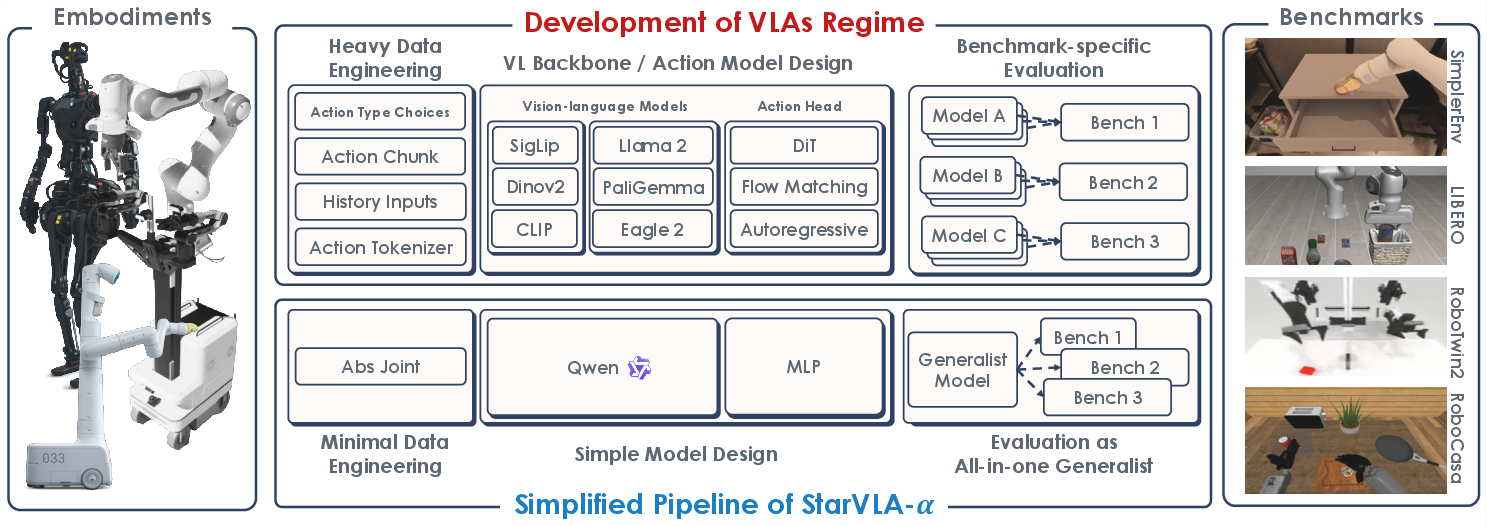
Figure 2: Overview of StarVLA-α—a unified VLM backbone (Qwen3-VL) with a minimal lightweight MLP action head, nominal preprocessing, and a consistent pipeline for multi-benchmark robotic policy learning.
Key elements of the framework include:
- Minimal data processing: Only raw RGB and textual instructions, shared normalization, and no benchmark-specific augmentation or formatting.
- Unified architecture: Fixed VLM backbone, replaceable lightweight action heads for continuous control, no auxiliary state/history.
- Cross-benchmark integration: Universal adapters for action/interface normalization without per-benchmark or per-robot customization, supporting robust, reproducible joint training and cross-embodiment evaluation.
Systematic Dissection of VLA Design Choices
Action Head Parameterization
The study evaluates four canonical action parametrizations using the same VLM backbone: discrete token prediction (FAST), continuous MLP regression (OpenVLA-OFT style), dual-system flow matching (GR00T), and diffusion-based prediction (π0-style).
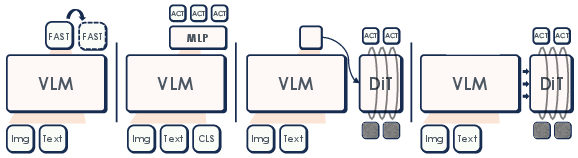
Figure 3: Action expert designs in StarVLA-α: discrete token (FAST), lightweight MLP regression, dual-system flow matching, diffusion-style flow matching.
Empirically, continuous action prediction is strictly superior to discrete tokenization. Among continuous heads, differences are statistically insignificant across major benchmarks. The simplest configuration—MLP regression—delivers maximal efficacy per parameter, indicating that commonly adopted action decoding alternatives (e.g., diffusion, dual-system) do not contribute generalizable improvements when the backbone is strong and the pipeline is standardized.
Data and Pretraining Complexity
The benefit of additional large-scale action-specific pretraining is rigorously interrogated. When the VLM backbone is sufficiently pretrained (Qwen3-VL-4B) and training data is adequately aligned with evaluation distribution, introducing heterogeneous action data—such as Open X-Embodiment (OXE) or InternData-A1—provides no consistent gain. Actually, out-of-domain pretraining can harm cross-embodiment generalization. Only when the pretraining data precisely matches the task distribution do modest improvements emerge, and only in the low-data regime. In general, the report is unambiguous: beyond VLM pretraining, further robot-specific pretraining does not guarantee performance improvements and may induce negative transfer.
Data Engineering and Auxiliary Modalities
Proprioceptive inputs, history frame stacking, and alternative action representations (delta, relative) are assessed. In low-data regimes, some minor improvements are detected, but once the demonstration count per task is reasonable, these interventions are irrelevant to overall performance. The conclusion is that a clean RGB+instruction input is a sufficient interface for generalist VLA control given a powerful backbone and consistent normalization.
Multi-Embodiment Action Unification and Generalist Models
Real-world robotic deployment requires transferring across variable action spaces. StarVLA-α evaluates complex action unification mechanisms—such as RDT and Multi-Action Heads—against simple zero-padding. The simple padding strategy yields equal or better cross-embodiment performance, even on humanoid-style benchmarks (RoboCasa-GR1), demonstrating that "specialized" parameterizations are unnecessary under unified architectures.

Figure 4: Comparison of action parameterization strategies—RDT Action, Multi-Action Head, Simple Padding—the latter suffices for high performance across multiple robot embodiments.
Furthermore, unified generalist training (joint across LIBERO, SimplerEnv, RoboTwin 2.0, RoboCasa-GR1) is explored. StarVLA-α delivers compelling results: generalist models achieve SOTA or near-SOTA numbers on virtually all benchmarks, with no per-task adaptation.
Scaling and Optimization Analyses
The study dissects scaling phenomena. Moderate backbone capacity (4B Qwen3-VL) is necessary for strong generalization, but further scaling provides diminishing returns above this threshold. Batch size during optimization is critical; larger batch sizes unambiguously lead to higher scores, especially when training generalist policies across highly variable benchmarks. This underlines the necessity to maintain sample diversity per step for robust policy learning.
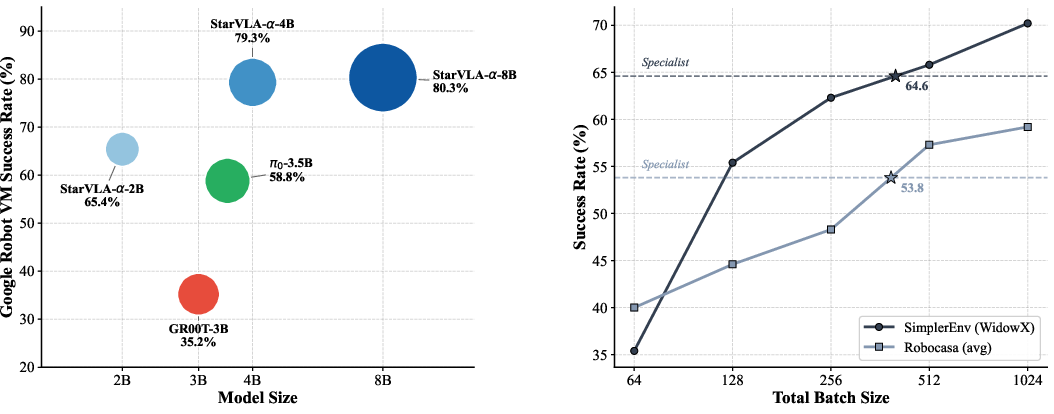
Figure 5: Scaling trends in VLA training—performance as a function of model size and total batch size.
Large-Scale Simulation and Real-World Generalization
StarVLA-α achieves top-tier success rates and average progress on both simulation and physical robot benchmarks, including LIBERO, SimplerEnv, RoboTwin 2.0, RoboCasa-GR1, and the public RoboChallenge. For instance, the generalist StarVLA-α0 model outperforms α1 by an average of 20% on real-world RoboChallenge suite, with significant deltas especially in tasks demanding long-horizon planning or robust visual-language grounding.

Figure 6: Result visualization across simulation benchmarks (SimplerEnv WidowX, RoboCasa-GR1, SimplerEnv Google Robot, RoboTwin 2.0 Hard).

Figure 7: Result visualization for the large-scale real-world RoboChallenge benchmark.
Complementary experiments demonstrate robust OOD generalization: under explicit distribution shifts (novel objects, new spatial configurations, new colors), StarVLA-α2 preserves high absolute success rates with minimal degradation, supporting the framework's viability for practical deployment.

Figure 8: Real-world deployment tasks on Franka Research 3, including egg-carton placement, waste sorting, and colored egg picking.
Impact and Future Directions
The evidence presented challenges the presupposition that architectural complexity, task-specific engineering, or robot-centric pretraining are necessary for robust and generalizable VLA performance. The findings imply that further progress may be stifled less by innovation bottlenecks in modeling and more by preventable confounders in empirical methodology, evaluation, and pipeline design. This calls for an immediate shift towards controlled, standardized, and reproducible recipes, as exemplified by StarVLA-α3.
The results signal key implications for the embodied foundation model community:
- Methodological clarity: Progress should be reported on minimalist systems with controlled experimental variables, as it is only under such conditions that the true impact of novel modeling approaches can be isolated.
- Evaluation convergence: Unified multi-benchmark, multi-embodiment generalist evaluation will accelerate empirical legitimacy and broader translation into practical robotics.
- Resource allocation: Compute and data should preferentially be spent increasing coverage and diversity, not architectural complexity, at least until diminishing returns are empirically observed on vanilla pipelines.
Future developments may focus on robust evaluation under extended OOD shifts, further scaling backbone reasoning, and formalizing the scaling laws and generalization characteristics that underpin high-performing, standardized VLA agents.
Conclusion
StarVLA-α4 provides a rigorous, reproducible, and robust baseline for VLA research, revealing that strong VLM initialization, minimal action modeling, and a unified interface are sufficient for high performance across virtually all contemporary benchmarks and real-world deployments. This work defines a new methodological standard for the field, shifting emphasis away from engineering optimization and towards empirical rigor and consensus-driven evaluation (2604.11757).

