Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
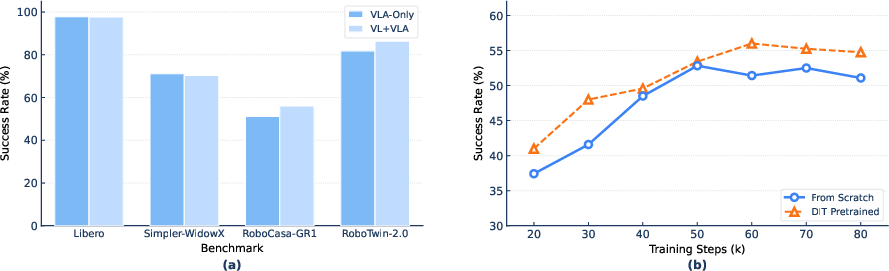
Abstract: Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fragmented capabilities and limited generalization across tasks, environments, and robot embodiments. In this work, we study whether heterogeneous embodied decision-making problems can be unified within a single vision-language-action model. We present Qwen-VLA, a unified embodied foundation model that extends Qwen's vision-language modeling stack from perception, understanding, and reasoning to continuous action and trajectory generation through a DiT-based action decoder. Qwen-VLA is trained with a large-scale joint pretraining recipe over diverse data sources, including robotics manipulation trajectories, human egocentric demonstrations, synthetic simulation data, vision-and-language navigation data, trajectory-centric supervision, and auxiliary vision-language data. To support multiple robot platforms, we introduce embodiment-aware prompt conditioning, where robot-specific textual descriptions specify the current embodiment and control convention. We further cast manipulation, navigation, and trajectory prediction into a unified action-and-trajectory prediction framework, enabling transferable visual grounding, spatial reasoning, and continuous action generation across robot morphologies, task families, and environments. Experiments on manipulation, navigation, and trajectory-centric benchmarks show consistent multi-task performance and out-of-distribution generalization under variations in scene layout, background, lighting, object configuration, and robot embodiment. Qwen-VLA-Instruct achieves 97.9% on LIBERO, 73.7% on Simpler-WidowX, 86.1%/87.2% on RoboTwin-Easy/Hard, 69.0% OSR on R2R, 59.6% SR on RxR, 76.9% average OOD success in real-world ALOHA experiments, and 26.6% zero-shot success on DOMINO dynamic manipulation.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments”
1) What is this paper about?
This paper is about teaching robots to see, understand language, and move—all in one model. Instead of building separate systems for each task (like one for grabbing objects and another for walking around), the researchers build a single “unified” model called Qwen-VLA that can handle many tasks, different environments, and even different robot bodies.
Think of it like a universal remote for robots: one brain that can read instructions, look at the world, and then figure out what to do next, no matter which robot it’s controlling.
2) What questions are the researchers asking?
They’re mainly asking:
- Can one model handle many different robot jobs—like manipulating objects, navigating spaces, and predicting movement paths?
- Can the same model work on different robot bodies (like a small arm on a desk and a bigger mobile robot)?
- Will this model still work well when things change (like different rooms, lighting, object layouts, or camera views)?
3) How did they do it?
They designed a system that connects three skills—vision, language, and action—into one pipeline.
- Vision and language backbone: The model starts with a strong “seeing and understanding” core (from the Qwen family). This part looks at images or video and reads instructions (like “pick up the red cup”) to figure out what’s going on.
- Action decoder: They added a special “movement generator” that turns understanding into precise robot moves. It’s based on a technique called a diffusion transformer (DiT) with flow matching.
In everyday terms:
- Diffusion/flow matching: Imagine starting with a noisy, messy scribble and repeatedly refining it into a clean drawing. Here, the model refines a rough guess into a smooth, safe sequence of robot actions in a few steps.
- Action decoder: It’s like a translator that turns words and images into a step-by-step “dance” for the robot’s joints and grippers.
Two key ideas make the model work across many robots and tasks:
- Embodiment-aware prompts: Before each task, the model gets a short text hint that says what robot it’s using and how that robot accepts commands (for example, “single arm, 20 actions per second, predict the next 8 moves”). This is like telling a driver whether they’ll be using a car, a bike, or a truck before giving directions.
- Unified action format: Different tasks (grabbing, walking, driving, etc.) all boil down to “predict a sequence of numbers over time” (positions, angles, waypoints). The model uses one shared format for these sequences and a simple mask to ignore parts that don’t apply to a given task. That way, a single decoder works for everything.
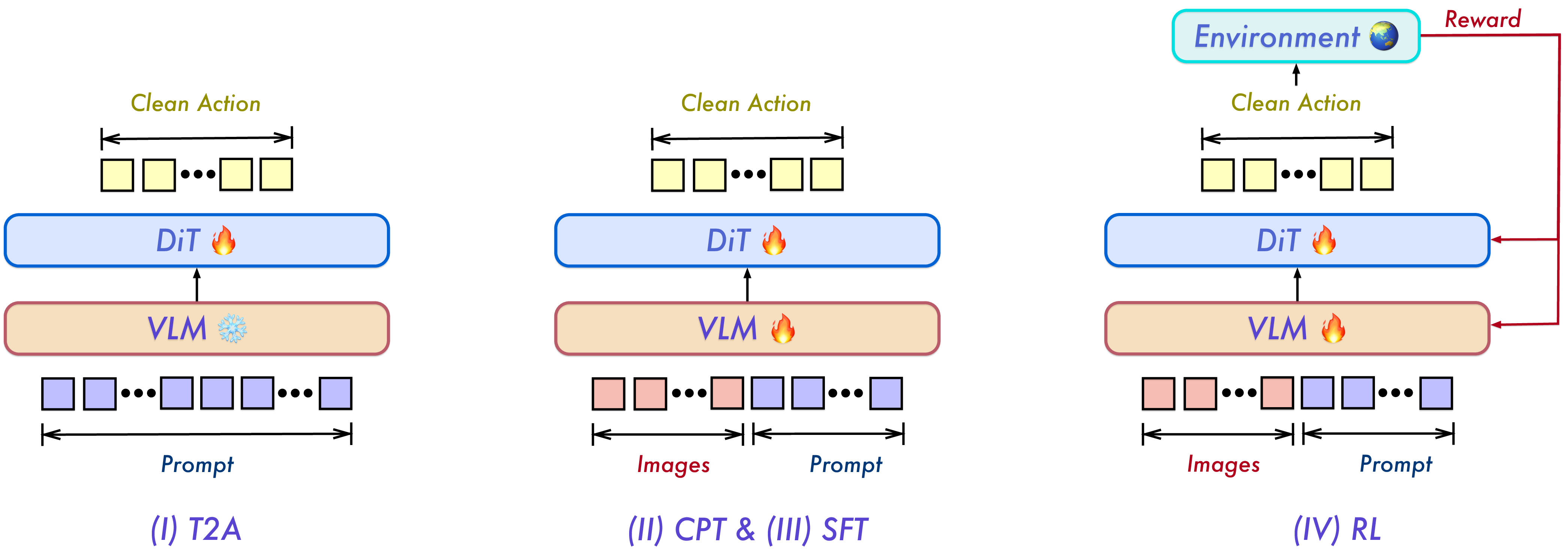
They trained the model in four stages (like building a skill step-by-step):
- Stage I: Text-to-action pretraining (T2A)
- The model learns to turn language instructions into action sequences without using images.
- Analogy: Learning the basic “moves” of a dance from written steps before seeing a demonstration.
- Stage II: Continued pretraining (CPT)
- Now add images/video so the model can connect what it sees with how to act.
- Analogy: Watching the dance performed and adjusting your moves to match the real situation.
- Stage III: Supervised fine-tuning (SFT)
- Practice on carefully chosen examples for multiple tasks and for real robots.
- Analogy: Focused coaching sessions to polish specific skills.
- Stage IV: Reinforcement learning (RL)
- Let the model try actions in a simulator and reward it for success, so it learns what actually works.
- Analogy: Practicing in a safe sandbox where you learn from trial and error.
They trained on a very mixed “diet” of data so the model doesn’t get stuck on one narrow task:
- Real robot manipulation data from many labs and robot types
- Human egocentric videos (first-person recordings of hands doing tasks) to learn rich, natural manipulation patterns
- Vision-and-language navigation data (following instructions to move around)
- Synthetic simulation data (massive, varied, automatically checked tasks in virtual worlds)
- Extra vision-language tasks (like question answering) to keep language and perception strong
4) What did they find, and why is it important?
Main results:
- The single Qwen-VLA model can control different robots and do different types of tasks, all from one system.
- It performs strongly on standard tests for manipulation and navigation. For example, it reports high success on benchmarks like LIBERO and R2R/RxR navigation.
- It handles “out-of-distribution” changes—meaning it stays reliable when the room, lighting, object positions, or robot body change compared to training.
- In real-world tests (like with the ALOHA robot), it succeeds a large fraction of the time even on new setups.
Why this matters:
- Instead of building and maintaining many separate models, teams can use one general model that adapts across tasks and robots—faster to deploy and easier to improve.
- The model learns general skills like grounding language to objects (“the red cup”), spatial reasoning (where things are), and planning actions over time—skills that transfer between different jobs and robot bodies.
- Better generalization means robots can be more useful in messy, changing real-world settings, not just in carefully prepared labs.
5) What’s the impact?
This work is a step toward “generalist” robot brains that can:
- Follow natural instructions,
- See and understand their surroundings,
- And act correctly across many tasks and hardware types.
Potential benefits include:
- Quicker robot training for new tasks—just describe the robot and provide some examples.
- Easier use in new places (homes, hospitals, warehouses) where every environment and tool is a bit different.
- More reliable performance when conditions change, which is crucial for real-world use.
In short, Qwen-VLA shows that seeing, understanding, and acting can be trained together in one model. That makes robots more flexible learners and moves us closer to robots that can help in everyday, unpredictable situations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, uncertainties, and untested assumptions that future work could address:
- Embodiment-aware prompt conditioning
- Sensitivity to prompt wording, tokenization, and formatting is not evaluated; robustness to mis-specified or ambiguous embodiment prompts is unknown.
- Generalization to completely unseen robot embodiments or control conventions (e.g., new DOF counts, torque control) is not assessed; minimal data or prompt-only adaptation strategies are unspecified.
- How much of cross-embodiment transfer comes from prompts versus visual-language grounding remains unablated.
- Unified action-and-trajectory representation
- The masking/zero-padding scheme assumes a fixed horizon and channel dimension ; effects of varying horizons and control frequencies on stability and performance are not quantified.
- Per-dataset quantile normalization can distort physical scales across embodiments; its impact on calibration, safety, and cross-embodiment consistency is not measured.
- No mechanism is provided to reconcile heterogeneous physical semantics (e.g., joint vs Cartesian actions) beyond prompts; whether a shared latent action space would improve transfer is untested.
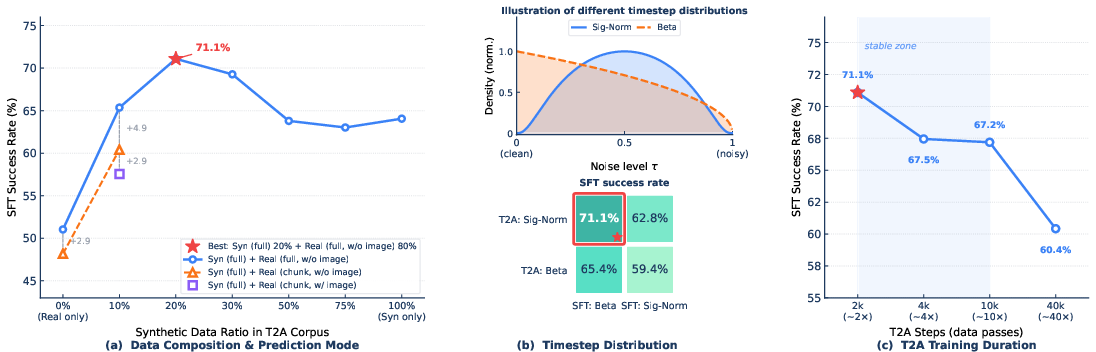
- Text-to-action pretraining (T2A) stage
- The extent to which language-only T2A improves downstream grounding and task success is not ablated; comparisons to training without T2A are missing.
- Risk of learning language priors that produce kinematically plausible but visually/motion-context inappropriate trajectories is not analyzed.
- Handling of ambiguous, underspecified, or contradictory instructions during T2A is unspecified.
- Continued pretraining and multi-task balancing
- The choice of sampling ratios and loss weights (λ_act, λ_vl) is not justified by sensitivity analyses; their influence on catastrophic forgetting vs. motor learning is unclear.
- Impact of data family proportions (e.g., 74.2% manipulation, 6% egocentric) on final policy behavior and generalization is not ablated.
- Interference between tasks (navigation vs manipulation vs trajectory-centric) and mitigation strategies (e.g., adapters, task routing) are not studied.
- Reinforcement learning stage
- RL is conducted only in a single simulated environment with sparse binary rewards; transferability of RL gains to real-world and other simulators is not quantified.
- Safety, sample efficiency, and stability of RL fine-tuning, especially under distribution shift and with continuous actions, are not reported.
- No exploration of reward design beyond sparse success, nor comparison to alternative RL/IL hybrids (e.g., DAgger, implicit Q-learning, policy constraints).
- Data quality, bias, and reproducibility
- Heterogeneous public datasets with varying annotation quality may introduce label noise and bias; filtering effectiveness and residual noise levels are not reported.
- The contribution of proprietary data to final performance and generalization is not isolated; reproducibility without private data is uncertain.
- Language–action alignment filtering criteria are not quantified; failure modes from misaligned captions remain uncharacterized.
- Egocentric human demonstrations
- The mapping from human wrist/hand trajectories (e.g., MANO + eigengrasps) to diverse robot hand kinematics is unspecified; policies may learn human priors not transferable to robot hardware.
- Impact of PCA-based eigengrasps (10D) on expressiveness for fine manipulation and contact-rich tasks is not evaluated.
- Domain gap between egocentric sensors (viewpoints, motion) and robot-mounted cameras/control loops is not quantified; adaptation strategies are not provided.
- Synthetic simulation pipeline
- Scene diversity appears limited (e.g., 20 scenes × 10 layouts); coverage of long-tail object geometries, deformables, and clutter is unclear.
- Physics realism for contact dynamics is not discussed; many trajectories are kinematically planned without physics for text-only data, potentially limiting contact-rich skill learning.
- The benefit of subtask segmentation and domain randomization is not quantified via ablations.
- Perception and observation modeling
- Temporal modeling of long video histories and action-condition video inputs is not detailed; how history length affects performance is unreported.
- The approach relies on RGB images; contributions of depth, tactile/force, LiDAR/point clouds, or proprioception to control performance are unexplored.
- View-token tagging is proposed, but robustness to missing, desynchronized, or degraded camera streams is not evaluated.
- Action expert and inference
- Real-time latency, throughput, and memory footprint of the 1.15B DiT action decoder on typical robot hardware are not provided.
- Trade-offs among number of Euler integration steps, control frequency, and stability are not explored.
- Uncertainty estimation and risk-sensitive control (e.g., sampling multiple trajectories, confidence thresholds) are not addressed.
- Navigation formulation and limits
- Navigation is parameterized as planar ; extension to full 3D, dynamic obstacles, and outdoor or multi-floor environments is untested.
- Lack of explicit mapping or memory modules; how the model handles long-horizon partial observability and revisitation is unclear.
- Integration with low-level closed-loop collision avoidance or safety layers is not described.
- Closed-loop control and horizon management
- The policy predicts action chunks; strategies for receding-horizon control, replanning frequency, and error recovery are not specified.
- Stability under distribution shifts in control rates or delays (e.g., network latency, actuator lag) is not evaluated.
- Safety, constraints, and compliance
- Handling of torque/velocity limits, self-collisions, and workspace boundaries during policy execution is not detailed.
- There is no discussion of safe exploration during RL or guardrails against unsafe actions during deployment.
- Evaluation coverage and diagnostics
- Failure mode analysis (e.g., by scene complexity, lighting, object shape, embodiment novelty) is missing.
- Generalization to highly dynamic, contact-rich, or deformable-object tasks appears limited; reported zero-shot performance on DOMINO suggests headroom but lacks causal analysis.
- Multilingual instruction following is claimed, but cross-lingual embodied performance and ambiguity handling are not evaluated.
- Task and architecture ablations
- No comparisons to alternative action parameterizations (e.g., waypoint + impedance, torque control) or policy families (e.g., autoregressive vs diffusion vs flows with different noise schedules).
- Effects of model size (backbone and action expert) on performance and data efficiency are not studied.
- Role of the optional task identifier z and its necessity across datasets/tasks is not ablated.
- Continual learning and adaptation
- Methods for online adaptation, rapid embodiment onboarding, or continual learning without catastrophic forgetting are not considered.
- Mechanisms for efficient personalization to new tasks/environments with limited data are absent.
- Interpretability and controllability
- How embodiment prompts and instruction tokens modulate internal representations and action outputs is not analyzed; lack of interpretability tools limits debugging.
- No controllable knobs for precision–speed trade-offs, safety margins, or constraint relaxation are exposed.
- Ethical, legal, and privacy considerations
- Use of large-scale egocentric human data raises privacy concerns; dataset consent, redaction, and on-device inference strategies are not discussed.
- Deployment implications (e.g., safety standards, human-in-the-loop supervision) are not considered.
Practical Applications
Immediate Applications
The following applications can be deployed today using the Qwen-VLA methods, training recipe, and model characteristics, given access to appropriate data, compute, and standard robotics infrastructure.
- Generalist, instruction-following robot control across multiple platforms (Robotics, Manufacturing, Logistics, Service)
- What: Use Qwen-VLA as a single policy that executes natural-language tasks for tabletop manipulation, mobile-base navigation+manipulation, and bimanual actions across robots (e.g., Panda, UR, ALOHA, WidowX) by switching only the embodiment prompt.
- Tools/workflows:
- Embodiment-aware deployment via prompt templates declaring arm configuration, control frequency, and action horizon.
- ROS2 node/plugin that wraps the DiT-based action decoder for low-latency control; integration into existing task-level planners and safety monitors.
- Skill authoring as text prompts (“Place the two green staplers side by side”), removing per-robot policy heads.
- Assumptions/dependencies:
- Well-calibrated kinematics and reliable camera streams; precise action scaling/normalization per embodiment.
- Adequate compute for VLM+DiT inference (edge GPU or on-prem server); safety interlocks and guardrails for physical actuation.
- Domain gap persists for highly specialized tools or extreme conditions; performance varies by embodiment coverage in training data.
- Unified teleoperation and imitation-learning pipeline augmented by egocentric human data (Robotics, Industry, Academia)
- What: Leverage the model’s language-to-action prior (T2A) and egocentric human demonstrations to bootstrap robot skills where robot data is scarce, then fine-tune with a small amount of teleop data.
- Tools/workflows:
- Data collection from staff (e.g., warehouse or lab techs) using head-mounted cameras; automatic extraction of wrist/hand trajectories (MANO/“eigengrasps”) for pretraining.
- Rapid task adaptation: record a handful of teleop trajectories, prompt with embodiment card, and deploy.
- Assumptions/dependencies:
- Privacy/compliance for human data capture; consistent camera calibration and synchronization.
- Quality of automated action alignment from egocentric videos; domain transfer from human to the target robot.
- Mobile manipulation and instruction-guided navigation in indoor spaces (Robotics, Facilities, Hospitality)
- What: Deploy VLA-powered agents for tasks combining movement with manipulation (e.g., fetch-and-carry, restocking, room setup), using the unified waypoint/action format.
- Tools/workflows:
- VLN-style waypoint prediction for corridors/rooms; manipulation at destination via the same decoder.
- Domain randomization in simulation for site-specific fine-tuning; instruction libraries with templates for site operations.
- Assumptions/dependencies:
- Accurate localization (SLAM or fiducials), safety constraints for moving among people, elevator/door integration.
- Scene differences from training (layout/lighting) may require in-situ SFT.
- Rapid skill portfolio consolidation for multi-robot fleets (Robotics, Operations)
- What: Replace fragmented, per-robot policies with a single generalist checkpoint; use prompts to configure embodiment, control frequencies, and horizons for different units.
- Tools/workflows:
- Fleet manager routes high-level instructions to a “skill server” that applies per-robot prompts and streams actions.
- Continuous evaluation using the model’s OOD robustness tests (lighting, object placement) before site rollout.
- Assumptions/dependencies:
- Network reliability for streaming; fallback local inference for safety-critical tasks.
- Hardware diversity exceeding the training distribution may require additional SFT.
- Synthetic data augmentation for robust manipulation (Software for Robotics, Academia, Simulation Vendors)
- What: Use the described RoboInF-style pipeline to generate large-scale VLA supervision with task decomposition, domain randomization, and automatic success checks.
- Tools/workflows:
- IsaacLab + cuRobo pipeline to produce short- and long-horizon tasks; automated segmentation into subtask trajectories for hierarchical learning curricula.
- Mix text-only action data (T2A) with vision-conditioned trajectories to strengthen language–action priors.
- Assumptions/dependencies:
- Simulator–real gap; physics and texture fidelity; coverage of objects and tasks relevant to deployment.
- Engineering effort to tailor randomizations and success metrics to target domains.
- Multi-camera perception integration via view tags (Robotics, Vision Systems)
- What: Use explicit view tokens to fuse ego, wrist, and external cameras without architecture changes, improving grasping and close-range manipulation.
- Tools/workflows:
- Standardize camera topics, wrap images with view tags in the token stream, and let the VLM learn view-specific features.
- Assumptions/dependencies:
- Camera synchronization and low-latency capture; resilience to occlusions; calibration drift must be monitored.
- Academic benchmarking and lab curricula for embodied AI (Academia, Education)
- What: Adopt the unified action-and-trajectory framework to evaluate cross-task generalization, OOD robustness, and embodiment transfer in coursework and research.
- Tools/workflows:
- Course labs featuring shared DiT action head with multiple embodiments; staged training (T2A→CPT→SFT→RL) as reproducible syllabus modules.
- Assumptions/dependencies:
- Access to modest GPUs; curated datasets for safe campus robots or simulators.
- Policy and procurement guidance for “generalist” robot models (Policy, Standards, Public Sector)
- What: Establish capability disclosure and evaluation protocols tailored to unified VLA models (multi-task success rates, OOD tests, embodiment coverage).
- Tools/workflows:
- RFP templates requiring embodiment-aware prompt specifications (“embodiment cards”), data governance for egocentric sources, and safety validation under distribution shifts.
- Assumptions/dependencies:
- Cross-vendor agreement on prompt schemas; access to standardized evaluation scenes and tasks.
- Smart home and office assistants for simple pick-and-place and tidying (Daily Life, Consumer Robotics)
- What: Natural-language instruction following for simple household/office tasks on supported robot platforms (tabletop clearing, object sorting, delivery).
- Tools/workflows:
- Predefined prompt profiles for each consumer robot and room type; optional cloud-assisted planning with local safety envelope.
- Assumptions/dependencies:
- Consumer-grade hardware may lack precision; safety, child/animal interaction policies; privacy for onboard cameras.
Long-Term Applications
These opportunities require further research, scaling, safety validation, or ecosystem development before widespread deployment.
- Universal cross-embodiment robot control as a service (Robotics, Cloud Platforms)
- What: A managed “policy endpoint” that controls heterogeneous robots in factories, hospitals, and retail via embodiment prompts—one foundation model serving many embodiments and tasks.
- Potential products/workflows:
- Embodiment Prompt Specification (EPS) standard and “embodiment cards” published by vendors; auto-configuration wizards for new robots.
- Continual learning from fleet logs with strong privacy and safety guarantees.
- Assumptions/dependencies:
- Reliable low-latency connectivity or efficient edge variants; certification for safety; liability frameworks for generalist policies.
- Assistive and healthcare robotics with natural-language workflows (Healthcare, Elder Care, Rehabilitation)
- What: Home and clinical assistants that generalize across rooms, tools, and tasks (e.g., fetch/organize, environmental controls, basic ADLs).
- Potential products/workflows:
- Clinician-authored instruction libraries; per-patient adaptation using egocentric demonstration of routines; fine-grained safety envelopes and human-in-the-loop overrides.
- Assumptions/dependencies:
- High safety and reliability standards, infection control, HIPAA/GDPR-compliant data handling; robust failure detection and fallback behaviors.
- Household multipurpose robots with long-horizon planning (Consumer Robotics)
- What: End-to-end VLA with co-predicted future visual states (world models) for multi-step tasks (laundry sorting, pantry reorganization) in unseen homes.
- Potential products/workflows:
- Integration of memory and predictive world modeling (as suggested by output-side extensibility) for lookahead planning and recovery.
- Assumptions/dependencies:
- Advances in world modeling and long-horizon credit assignment; durable, affordable hardware; thorough home safety protocols.
- Multi-robot and multi-agent orchestration using a shared VLA policy (Logistics, Warehousing, Agriculture)
- What: Coordinated task allocation where each agent executes with embodiment-specific prompts, sharing a common semantic understanding of instructions and scene context.
- Potential products/workflows:
- Fleet-level planner issues sub-instructions; the VLA handles local execution; explicit conflict resolution and shared map services.
- Assumptions/dependencies:
- Reliable inter-robot communication; standardized scene representations; strong safety and collision-avoidance layers.
- Standardized “robot prompt” ecosystems and certification (Policy, Standards)
- What: Sector-wide schema for embodiment-aware prompts and evaluation suites; safety certification tailored to generalist VLA controllers.
- Potential products/workflows:
- Robot Prompt Markup Language (RPML); conformance tests for action scaling, latency, failure modes, and OOD robustness.
- Assumptions/dependencies:
- Broad industry consensus; regulators equipped to assess data, RL fine-tuning, and synthetic-data contributions.
- Personalized robots via lifelong learning from user egocentric video (Daily Life, Workplace Assistants)
- What: Robots that learn a user’s preferences and routines from private egocentric captures, improving instruction following and manipulation habits.
- Potential products/workflows:
- On-device fine-tuning with federated learning; editable “habit profiles” and privacy-preserving action extraction.
- Assumptions/dependencies:
- Strong privacy, consent, and security; bias and safety controls; robust on-device training and compute.
- Cross-domain embodied AI beyond manipulation/navigation (Construction, Field Robotics, Energy, Inspection)
- What: Extend unified action space to drones, legged robots, and inspection crawlers; instruction-guided waypointing and tool operation in unstructured environments.
- Potential products/workflows:
- Expanded training to include locomotion and aerial control signals; world-model-based hazard anticipation; integration with digital twins.
- Assumptions/dependencies:
- New action/channel schemas and safety constraints; high-fidelity simulation for sim-to-real; ruggedized sensing.
- Content creation and virtual agents with unified trajectory control (Gaming, Animation, Telepresence)
- What: Use staged T2A→CPT to drive character animation or telepresence robots from language, benefiting from long-horizon trajectory coherence.
- Potential products/workflows:
- Tooling for story-driven action synthesis; motion libraries conditioned by natural language and scene context.
- Assumptions/dependencies:
- Domain adaptation to character rigs; timing and style constraints; IP and safety for telepresence.
- Autonomous vehicles and micro-mobility assistance via trajectory-centric learning (Transportation)
- What: Adapt the unified trajectory prediction framework (trained with driving VQA and trajectory-centric data) to assistive planning and human–robot interaction in shared spaces.
- Potential products/workflows:
- Co-training with motion forecasting and instruction comprehension for last-mile robots and campus shuttles.
- Assumptions/dependencies:
- Extensive domain-specific data and safety validation; regulatory approval; robust perception stacks.
- Compliance-aware data pipelines using synthetic+real mixtures (Policy, Tooling, Data Platforms)
- What: Scalable, auditable pipelines that mix curated real-world data with controllable synthetic trajectories for capability and safety envelopes.
- Potential products/workflows:
- Synthetic data “nutritional labels”; automated OOD stress tests; dataset governance and versioning for embodied learning.
- Assumptions/dependencies:
- Community best practices for disclosing synthetic contributions; tools for measuring sim-to-real effects.
Notes on cross-cutting dependencies:
- Compute and latency: The DiT-based flow-matching decoder enables few-step inference, but edge GPUs or efficient distillation may be required for real-time deployment.
- Safety and monitoring: Closed-loop controllers must be wrapped with fail-safes, state estimation, and intervention policies; RL tuning in a narrow sim may not cover all real-world corner cases.
- Data coverage and bias: Generalization depends on breadth and quality of pretraining (embodiments, objects, environments, languages); egocentric data raises privacy and fairness considerations.
- IP and licensing: Use of public datasets and foundation backbones must respect licenses; proprietary synthetic pipelines should disclose generation processes where appropriate.
Glossary
- AdaLN: Adaptive Layer Normalization variant that conditions normalization parameters on a timestep or other context to modulate a model’s behavior during generative processes. "AdaLN timestep conditioning"
- action decoder: A model component that generates control actions or trajectories from multimodal context. "through a DiT-based action decoder."
- action expert: A specialized module focused on precise action generation separate from the general backbone. "as an action expert for predicting precise actions"
- axis-angle rotation: A 3D rotation representation defined by an axis and a rotation angle. "an axis-angle rotation"
- bimanual: Involving two arms or hands operating together. "bimanual wrist motion"
- conditional flow-matching objective: Training objective that learns a conditional velocity field to transform noise into target data under conditioning inputs. "a conditional flow-matching objective"
- continued pretraining (CPT): A stage that unfreezes modules to further pretrain on broader data and ground priors in inputs. "continued pretraining (CPT)"
- dexterous hand: A multi-degree-of-freedom robotic hand capable of complex in-hand manipulation. "dexterous hand control"
- DiT: Diffusion Transformer architecture used for diffusion-style generative modeling. "text-to-action DiT pretraining (T2A)"
- domain randomization: Technique that randomizes visual and physical factors during training rollouts to improve robustness. "under domain randomization."
- egocentric: First-person viewpoint capturing sensor data from the actor’s perspective. "human egocentric demonstrations"
- eigengrasps: Low-dimensional principal components capturing dominant hand-pose variation patterns. "dubbed eigengrasps"
- embodiment: The physical form, kinematics, and control conventions of a robot platform. "robot embodiments"
- embodiment-aware prompt conditioning: Prepending robot-specific textual descriptions to condition the model on the current platform and control semantics. "embodiment-aware prompt conditioning"
- end-effector (EEF): The robot’s tool center point (e.g., gripper) whose pose/position is controlled. "delta end-effector position ()"
- Euler integration steps: Numerical steps that integrate a learned vector field to produce samples or trajectories. "a few Euler integration steps at inference"
- flow-based policies: Policies that generate actions by transforming noise via learned continuous flows. "diffusion- or flow-based policies"
- flow matching: A generative training paradigm that learns the vector field mapping noise to data. "flow matching policy"
- flow-matching action loss: The loss term applying flow matching to supervise continuous action generation. "Flow-matching action loss."
- gated linear attention: An attention mechanism using linearized attention with gating for efficiency. "gated linear attention"
- grouped-query softmax attention: Attention variant that groups queries to reduce cost while retaining global reasoning. "grouped-query softmax attention"
- MANO: A parametric 3D human hand model commonly used to represent articulated hand poses. "MANO"
- out-of-distribution (OOD): Data or environments that differ from those seen during training. "average OOD success"
- principal component analysis (PCA): Linear dimensionality-reduction technique using eigenvectors of covariance. "principal component analysis (PCA)"
- prediction horizon: The number of future timesteps over which actions or trajectories are predicted. "prediction horizon "
- proprioceptive: Relating to internal robot state sensing such as joint angles and velocities. "proprioceptive state sequences"
- quantile normalization: Scaling procedure using dataset-wise quantiles to normalize action dimensions. "per-dataset quantile normalization"
- quaternion: Four-parameter representation of 3D rotations avoiding singularities. "quaternions"
- referential grounding: Linking language references to specific entities or regions in visual inputs. "referential grounding"
- reinforcement learning (RL): Learning to maximize cumulative reward through interaction and feedback. "Reinforcement learning (RL)."
- RoPE (Rotary Positional Embeddings): Positional encoding method that injects relative rotational phase into attention. "multi-section RoPE"
- SE(3): The group of 3D rigid-body transformations (rotation and translation). "SE(3) transformation"
- supervised fine-tuning (SFT): Post-pretraining optimization using labeled demonstration data for target tasks. "Supervised fine-tuning (SFT)."
- teleoperation: Human remote control of a robot to collect demonstrations or execute tasks. "teleoperation data"
- text-to-action (T2A): Mapping from language instructions (and prompts) to action trajectories. "text-to-action DiT pretraining (T2A)"
- trajectory-centric: Focused on predicting full continuous trajectories rather than single-step actions. "trajectory-centric supervision"
- vision-and-language navigation (VLN): Navigation tasks where an agent follows natural-language instructions grounded in visual observations. "vision-and-language navigation data"
- vision-LLM (VLM): A model jointly trained to process and reason over both images/videos and text. "vision-LLMs (VLMs)"
- vision-language-action (VLA): Models unifying perception, language understanding, and action generation. "vision-language-action model"
- vision transformer (ViT): Transformer architecture applied to images, producing visual token embeddings. "a ViT"
- visual grounding: Associating textual descriptions with visual elements in the scene. "visual grounding"
- waypoint: An intermediate target pose/location used to guide navigation or motion. "per waypoint"
- zero-shot: Evaluation without task-specific fine-tuning on the target dataset. "zero-shot success rate"
Collections
Sign up for free to add this paper to one or more collections.

