- The paper introduces a unified language-to-video world model that predicts physically consistent trajectories across varied embodied tasks.
- It leverages a three-part architecture combining a frozen vision-language model, video VAE, and a 60-layer multimodal diffusion transformer.
- The model demonstrates superior performance in benchmarks for robotic manipulation, autonomous driving, and human-to-robot transfer.
Qwen-RobotWorld: Unifying Embodied World Modeling through Language-Conditioned Video Generation
Introduction
The paper "Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation" (2606.17030) proposes and demonstrates a scalable framework for embodied world modeling conditioned on natural language. The model operates as a language-conditioned video generator capable of predicting physically consistent visual trajectories from current observations and textual instructions, with generalization across robotic manipulation, autonomous driving, indoor navigation, and human-to-robot transfer. The approach leverages large-scale multi-domain video-text data, a unified annotation/meta-data formalization, and a highly structured curriculum for training. The architecture fuses a frozen large vision-LLM (MLLM) with video VAE latents through a 60-layer double-stream Multimodal Diffusion Transformer (MMDiT), enabling precise grounding of semantics, geometry, and physically consistent scene evolution.
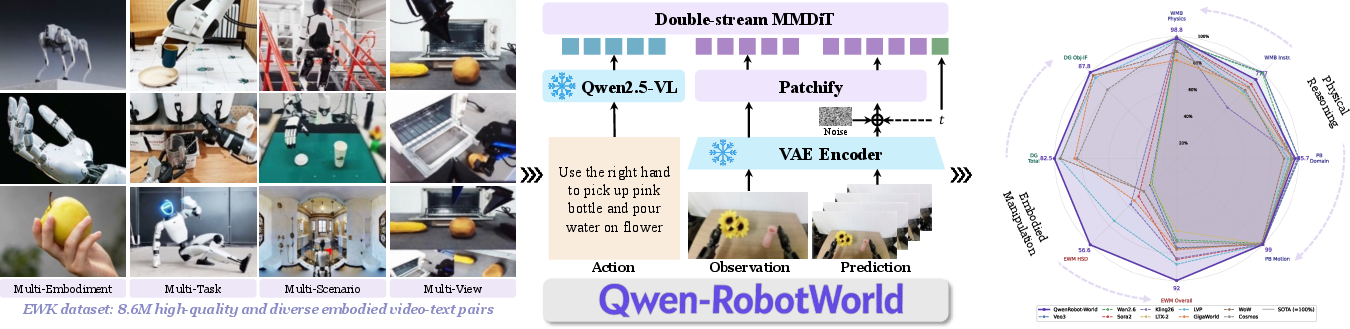
Figure 1: Qwen-RobotWorld provides a language-to-video world model that supports policy learning, environment simulation, and task planning for diverse embodied AI.
Data Construction: Embodied World Knowledge Dataset
Robust world models for embodied AI hinge critically on the diversity and coverage of data. The Embodied World Knowledge (EWK) training corpus is constructed to resolve heterogeneity in domain, embodiment, scene, viewpoint, and action representation. EWK consists of 8.6 million aligned video-text pairs (200M+ frames) spanning over 20 robotic morphologies, 500+ action categories, driving platforms, mobile navigation agents, and human hands. Coverage axes include:
- Multi-Embodiment: Human hands, dexterous robots, grippers, mobile agents, autonomous vehicles.
- Multi-Task: Atomic skills, long-horizon manipulative planning, locomotion, and HRI.
- Multi-Scenario: Reality-first, sim-augmented combinations bridging real captures and simulator-rendered data.
- Multi-View: Main, wrist, and multi-view streams with spatially and temporally aligned observations.
The action interface is standardized via a hierarchical five-layer annotation protocol, mapping low-level, scenario-specific actions across domains to a natural language interface with strictly enforced objectivity, viewpoint specificity, and verifiability.
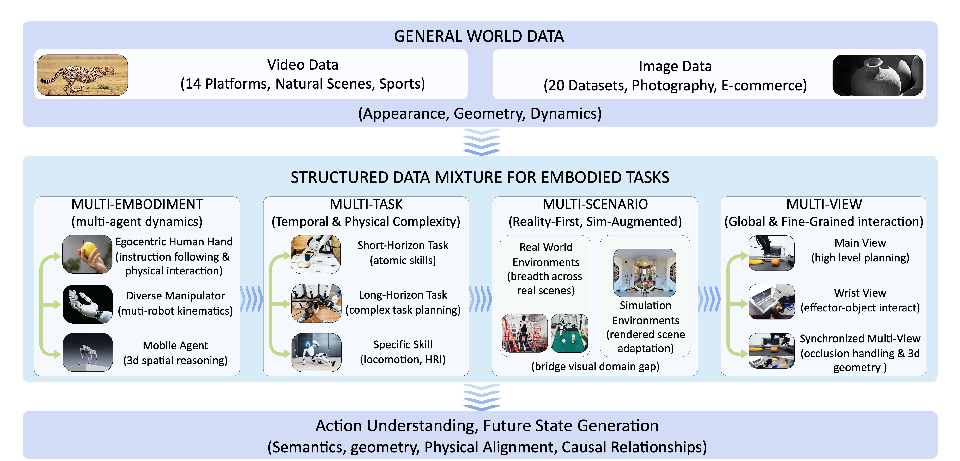
Figure 2: EWK covers foundational general world data and structured embodied data with orthogonal axes spanning embodiment, scenario, task, and multi-view.
The raw heterogeneous video streams are processed through a pipeline of temporal segmentation, multi-camera synchronization, and caption generation/refinement, resulting in highly structured training data supporting both detailed (comprehensive, 50–100 words) and concise (15–30 words) captions.
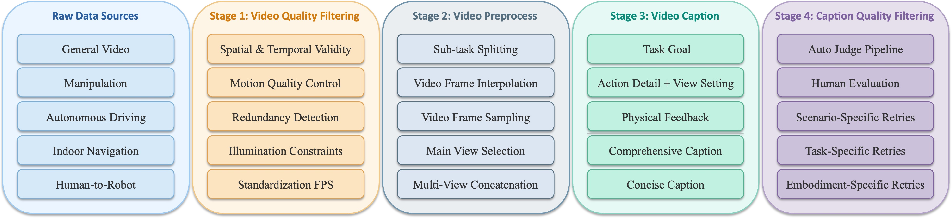
Figure 3: Unified data pipeline for structured video collection, preprocessing, hierarchical annotation, and iterative prompt refinement ensures alignment and generalization for downstream tasks.
Model Architecture
Qwen-RobotWorld utilizes a three-part model architecture:
- MLLM Action Encoder: A frozen Qwen2.5-VL encodes textual instructions into semantic tokens, supplying world priors and precise mapping from language to action.
- Video VAE: A compressor-decompressor for visual observations, facilitating high-resolution and length-efficient latent manipulation.
- Double-Stream MMDiT: A 60-layer transformer, with two streams interacting via blockwise joint attention: one for semantic understanding, the other for generative denoising of video latents.
The transformers are equipped with asymmetric 3D rotary position encoding, balancing the representation between temporal and spatial axes.
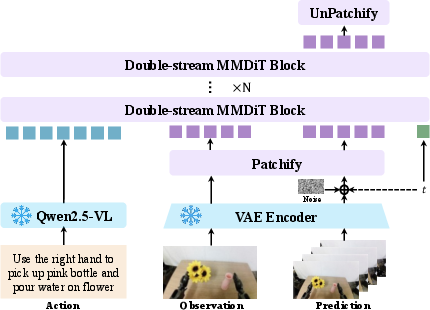
Figure 4: Double-stream MMDiT architecture fuses semantic language and video latents for language-conditioned generation.
A key component is the Scene2Robot conditioning mechanism, which enables multi-segment input (scene, robot reference, and frames-to-generate) facilitating cross-embodiment transfer, such as translating human demonstration videos into photorealistic robot executions.
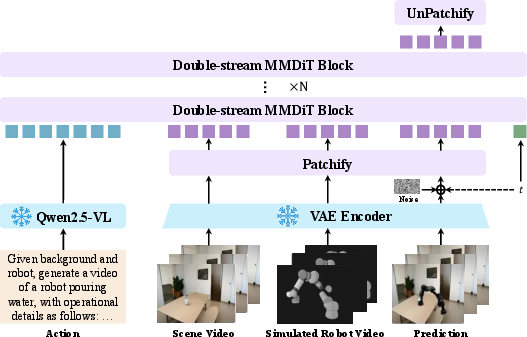
Figure 5: Scene2Robot facilitates multi-modal, cross-embodiment generation by simultaneous conditioning on human demonstrations, robot kinematics, and desired visual outcomes.
Training Paradigm
Training follows a general + expert progressive curriculum:
- Stage 1 (Pretraining): Learning from general text-to-image (T2I), text-to-video (T2V), and text+image-to-video (TI2V) with broad visual data forms the foundational prior.
- Stage 2 (SFT): Embodied data is incrementally introduced, starting with single-view manipulation, evolving to multi-view and cross-domain settings, exploiting human demonstration as a bridge.
Task ratios are non-uniform—manipulation tasks are upsampled during SFT for deep action grounding, while driving and navigation maintain breadth. General world data is always present to maintain visual and physical robustness.
The primary training objective is flow matching in latent space via the VAE (2606.17030), with adaptive log-normal timestep sampling. The architecture supports up to ∼48k video tokens per sequence.
Benchmark Evaluation and Empirical Results
Qwen-RobotWorld is evaluated across major embodied world modeling benchmarks, both open and closed-source.
- EWMBench: 1st overall—strongest in motion fidelity (HSD: 0.566, +33% over runner-up) and scene consistency (SceneC: 0.914).
- DreamGen Bench: 1st overall—high in instruction following (IF), especially strong for object-level compositional generalization (IF: 0.878).
- PBench: Best open-source performance (0.804 total), 3rd overall in domain understanding (0.857), top-tier in temporal motion smoothness.
- WorldModelBench: Highest among open-source (8.99), perfect physics adherence across Newton, mass, fluid, penetration, and gravity, strong instruction following (2.33/3.0).
These metrics are significant as they emphasize both perceptual realism and physically consistent temporal scene progression for downstream policy learning.
Qualitative Generalization: Language Grounding, Embodiment, and Cross-Domain Synthesis
The qualitative analysis highlights:
- Fine-Grained Language Conditioning: The model differentiates subtle instruction variations—distinguishing target object, destination, or manipulation type—for otherwise identical initial scenes.
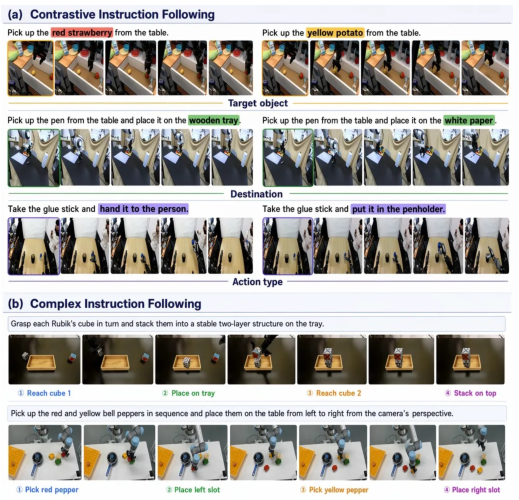
Figure 6: (a) Precise discrimination for minimal keyword differences; (b) Multi-step, abstract goal following with temporally coherent execution.
- Embodiment Generalization: One model can produce consistent, instruction-conditioned motions for single-arm, dual-arm, humanoid, and dexterous hand robots without explicit low-level control adaptation.
- Multi-Task and Scenario Flexibility: The model generalizes across atomic skills, long-horizon compositions, and dynamic activities in diverse environments.

Figure 7: Multi-axis generalization—including cross-embodiment, cross-task/environment, and synchronized multi-view synthesis.
- Zero-shot Robustness: Outperforms strong open-source (LVP, Cosmos2.5-14B) baselines in RoboTwin-IF zero-shot settings, especially in complex, novel tasks with maintained multi-view coherence.

Figure 8: Zero-shot side-by-side: Qwen-RobotWorld maintains language-action alignment and multi-view coherence beyond SOTA baselines.

Figure 9: RoboTwin-IF—correct task completion and cross-view consistency in previously unseen, compositionally challenging scenarios.
- Human-to-Robot Transfer: Translates first-person human demonstrations into physically valid, robot-specific executions spanning multiple embodiments—no robot-specific prompting required.

Figure 10: Human demonstration (left) mapped to kinematically valid robot execution (right) across a range of platforms.
- Autonomous Driving and Navigation: Robust large-scale motion synthesis (urban driving, navigation) grounded in language, with generalization to spatially extended trajectories, 3D consistency, and multi-agent interaction.

Figure 11: Mobility: Text-to-trajectory generation for both vehicle and indoor navigation domains.
Practical and Theoretical Implications
Qwen-RobotWorld establishes that a single, language-conditioned video model, when appropriately architected and trained, can unify heterogenous embodied simulation without domain- or platform-specific control signals. The framework provides a software backbone for several real-world robotic and embodied AI applications:
- Synthetic Data Engines: Unlimited, fast generation of physically consistent, instruction-conditioned visual data for policy pretraining or augmentation.
- Simulation for Evaluation: Closed-loop, scalable, and scenario-rich environments for benchmarking embodied control without hardware risk or reset overhead.
- Language-Conditioned Action Planning: Natural-language planning and intent transfer—such as human-instructed robot redeployment or skill translation—across morphologies and tasks without interface redesign.
Theoretically, the work demonstrates that with sufficient data structuring and annotation fidelity, language can serve as a universal control interface, breaking away from rigid, domain-specific representations and promoting true joint training across manipulation, mobility, and perceptual world modeling. The explicit decoupling of semantics (MLLM), perception (VAE), and transition (transformer) is validated at scale, supporting modular future upgrades and expansion.
Conclusion
Qwen-RobotWorld achieves a high-performance, generalist language-to-video world model framework with demonstrated superiority on multiple embodied intelligence benchmarks and qualitative axes. Its architectural and data-centric innovations establish a convergent path forward for unifying physically grounded, multi-embodiment policy learning, simulation, and planning within a single model backbone. The implications for embodied AI are substantial—not only for multimodal policy learning in robotics but also for general advances in bridging language, perception, and action.
(2606.17030)