- The paper presents the Recursive Agent Harness paradigm that recurses over the full agent harness rather than mere model calls, enabling advanced long-context reasoning.
- The methodology employs parallel spawning via code execution and JSON tool calls, effectively decomposing complex tasks with full tool integration.
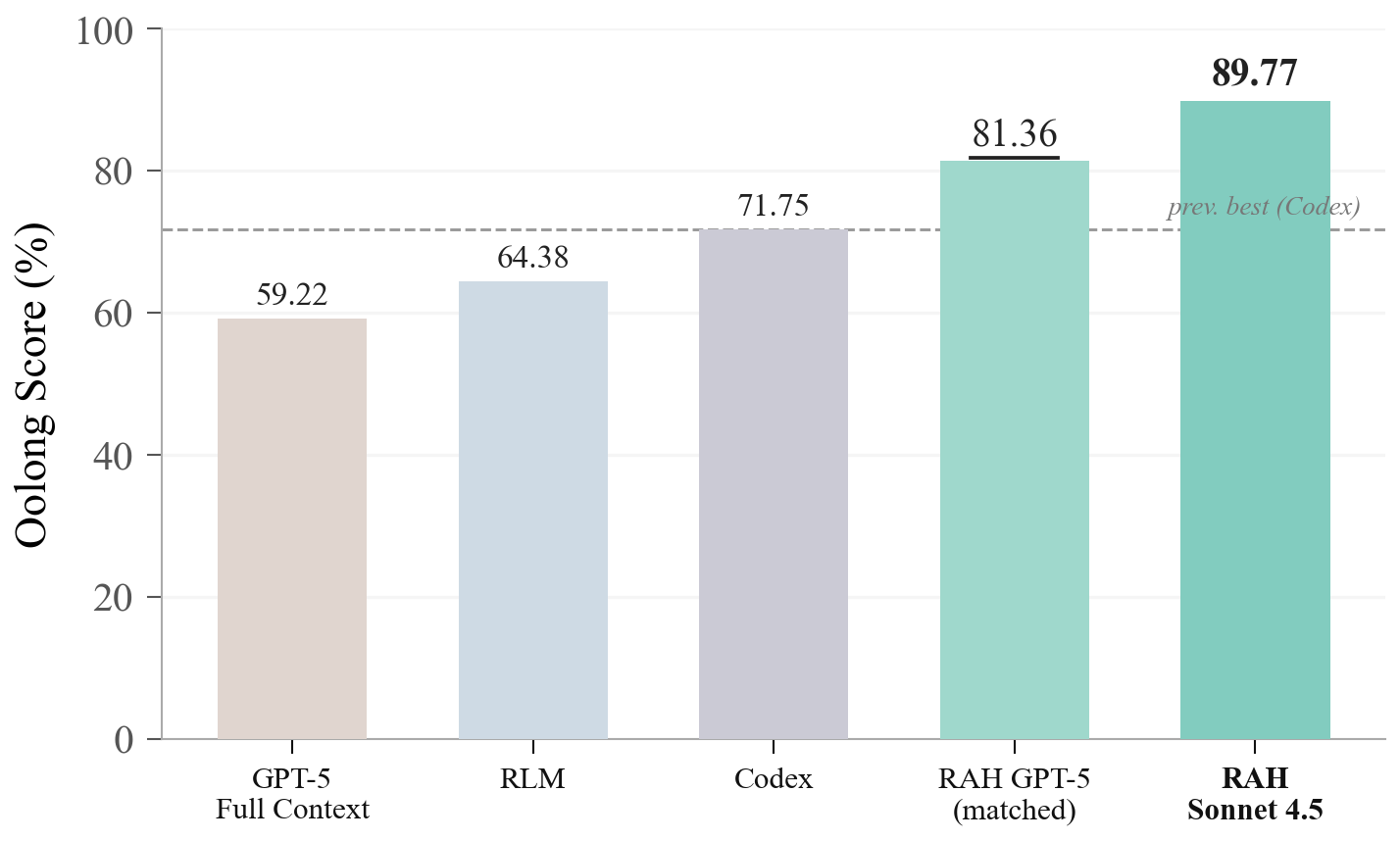
- The study demonstrates significant performance gains on Oolong-Synthetic benchmarks, showing improvements of up to 9.61 points over prior coding agents.
Recursive Agent Harnesses: Harness Recursion as a Paradigm for Long-Context Reasoning
Introduction
This paper systematically defines, implements, and evaluates the Recursive Agent Harness (RAH) paradigm, advancing long-context reasoning for LLM agents by recursing over the agent harness—the orchestration, tools, and context—rather than only recursive model calls as in prior Recursive LLMs (RLMs) (2606.13643). RAH is operationalized as both a conceptual and practical extension to model recursion, augmenting the recursive unit from bare model calls without tool access to the full agent harness, thereby enabling complex decomposition and parallel execution of subtasks with tool affordances. The empirical study on Oolong-Synthetic establishes that the gain in performance derives from the harness recursion architecture, not backbone improvements.
The Recursive Agent Harness Paradigm
The RAH pattern reframes recursion over LLMs from model-function recursion to harness recursion, generalizing the recursive composition to complete agent harnesses possessing filesystem, code execution, and planning capabilities. A parent agent, upon receiving a long-context reasoning task (e.g., thousands of independent document entries), selects between two spawning pathways: code-execution spawning (generating a script to instantiate subagent harnesses in parallel without per-call caps) and JSON tool-call spawning (emitting structured function calls for a small number of subtasks). Each subagent inherits the full toolset and can recursively spawn further harnesses, subject to a configurable recursion depth limit.
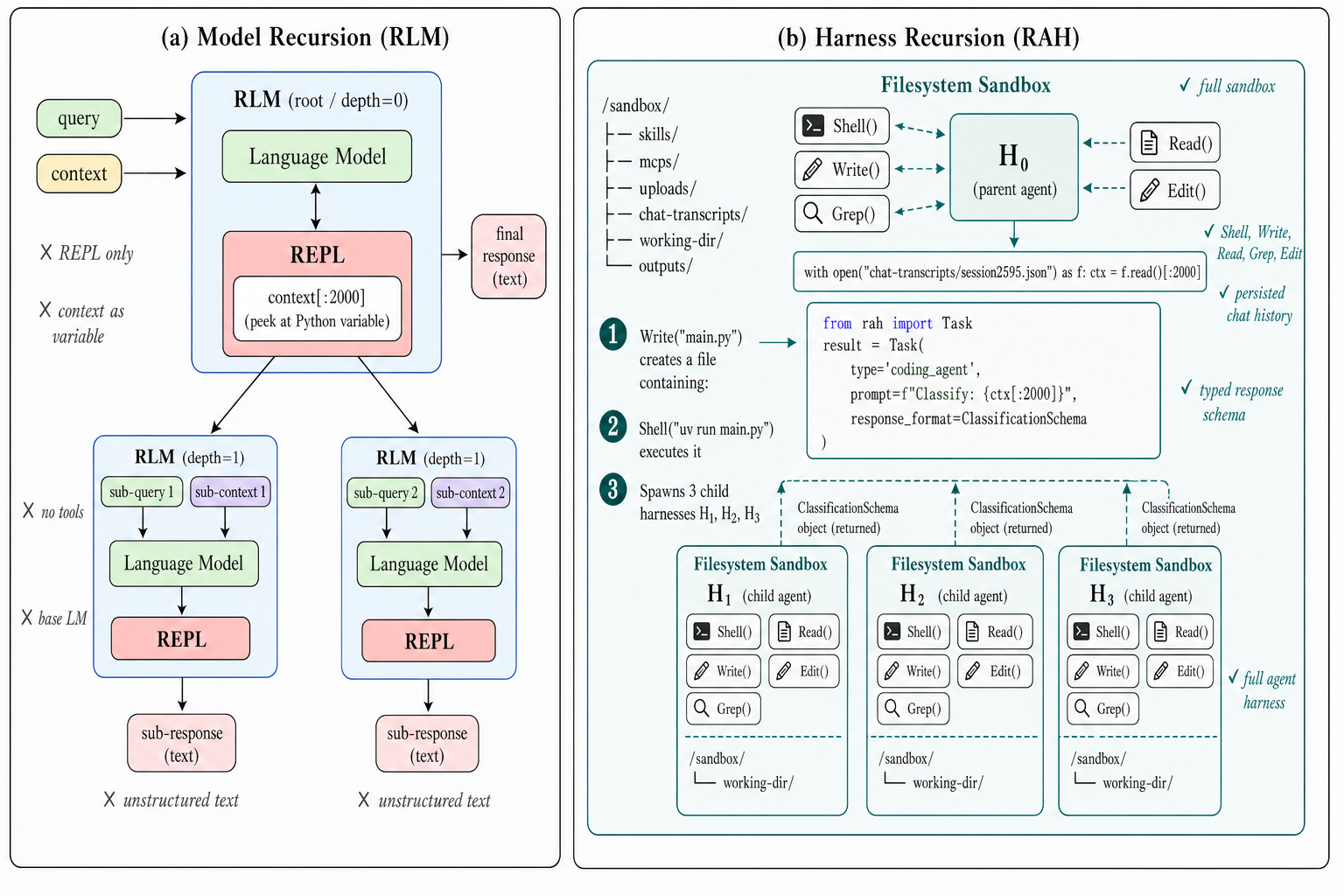
Figure 1: The Recursive Agent Harness (RAH) architecture, supporting code-driven and function-call-driven subagent spawning, with subagents recursively inheriting spawning capabilities up to a bounded depth.
This approach contrasts with prior frameworks:
- Coding agents aggregate document-level reasoning using regex or heuristic-based loops but omit entry-level LLM reasoning.
- RLMs perform recursion over input slices using bare model calls, lacking access to tools or an external environment.
- Dynamic workflows in industry (e.g., Claude Code) reflect production adoption, but without systematic benchmarking or analysis.
Implementation and Control Protocol
The RAH design is instantiated on top of LangChain, though the described architecture is implementation-agnostic. The deterministic evaluation protocol fixes the LLM backbone (GPT-5) across RAH and baselines, ensuring that observed performance deltas are attributable to harness recursion rather than to model improvements.
Subagents are fully isolated in workspace and context. For coarse-grained workloads, code-execution scripts spawn thousands of subagents via Python asyncio, each processing a partitioned slice of the context and writing JSON outputs to aggregation files. Fine-grained scenarios route via direct JSON tool function-calls, bypassing script overhead. Recursion beyond the first level is automatically managed given task complexity, and aggregation remains deterministic. No sibling communication is permitted; coordination is solely through output aggregation.
Main Results
Benchmarking on Oolong-Synthetic (199 evaluation instances, up to 4M-token context windows; 13 stratified context-length buckets), RAH posts significant performance gains:
The improvement from 71.75% (coding agent) to 81.36% (RAH), under a fixed LLM backbone, demonstrates that harness recursion resolves context-window limitations prevalent in coding agents while surpassing RLMs by enabling tool access and file system manipulation at every recursive call. Confidence intervals (+9.61 points over Codex, 95% CI [4.2,14.8]) further indicate robustness of the architectural gain.
Per-category analysis reveals superior RAH performance on semantic answer types (USER, COMPARISON, LABEL, all >86%) and identified NUMERIC as the limiting category (due to exponential penalty on small errors), with context-length stratification showing sustained performance up to and including extreme long-context settings.
Failure Modes and Limitations
Observed failure modes are concentrated in:
- Parent agent occasionally defaulting to direct answer generation instead of spawning, especially at the longest contexts.
- Penalization of near-correct outputs on NUMERIC due to scoring function, not agentic reasoning.
- Small sample-induced volatility in rare answer types (e.g., DATE).
The study is limited to Oolong-Synthetic; transfer to more ambiguous or less explicitly structured corpora, such as Oolong-Real or unscripted long-form documents, remains open. Cost, latency, and optimality of recursion parameters (depth, task-to-subagent mapping, spawning mechanism) warrant further systematic investigation.
Theoretical and Practical Implications
Harness recursion forms a lineage parallel to, and strictly more expressive than, model recursion. It enables:
- Arbitrary parallel decomposition at any step, leveraging scripting and full tool access
- Recursion control via standard programming constructs (no reliance on fixed schema or explicit function-call budgets)
- Composable orchestration strategies, extensible to other multi-agent coordination frameworks (AgentHive, Minions) and compatible with prompt caching optimizations
Given that production frameworks (e.g., Anthropic’s dynamic workflows) have adopted analogous patterns, harness recursion is positioned to become the de facto paradigm for long-context, high-parallelism LLM agent tasks, particularly where tool-augmented per-entry reasoning is required.
Future work should consider hybridization with efficient retriever pipelines, better agentic search (cf. Grep-need harnesses), and integration with memory systems for context reuse. Transfer to other benchmarks (CorpusQA, OneMillion-Bench, LOCA-bench) would elucidate regime boundaries and inform agent harness design in open-ended real-world environments.
Conclusion
RAH formalizes and empirically validates harness recursion: recursing over the complete agent harness, not just the model call, unlocks superior performance for long-context reasoning tasks when compared with both traditional coding agents and RLMs under fixed model backbones. The architecture compounds further with backbone advances. It marks a shift from context-window-centric and schema-limited orchestration to programmable, scalable agent decomposition, with immediate implications for practical agent deployments over large corpora and theoretical insights into multi-level agent architecture design.
The clear separation of model and harness effects substantiates the Recursive Agent Harness as a critical abstraction for agent research and real-world AI system development.