- The paper demonstrates that harness-level design is a crucial bottleneck for achieving persistent and reliable agentic AI performance.
- It decomposes system scaling into six components—reasoning, memory, context, skills, orchestration, and governance—to rigorously assess AI behavior.
- Comparative analysis of harnesses like Claude Code, OpenClaw, and CheetahClaws reveals diverse strategies for memory verification, dynamic skill routing, and safe evolution.
From Model Scaling to System Scaling: An Authoritative Analysis of Harness-Level Design in Agentic AI
Introduction and Core Thesis
The paper "From Model Scaling to System Scaling: Scaling the Harness in Agentic AI" (2605.26112) reframes the advancement of agentic AI as a dual challenge: one of scaling foundation models and, critically, scaling the surrounding system—the harness. The harness incorporates persistent memory, context construction, skill routing, orchestration, and governance that together mediate between the model, user intent, and external environments. The authors assert that once foundation models reach a threshold of capability, further gains in agentic behavior depend as much on harness architecture as on advances in model scaling. The harness thus emerges as a primary bottleneck for long-horizon, reliable agentic AI performance.
System Scaling Framework and Architecture
The paper formalizes system scaling by decomposing agentic systems into six interacting components: reasoning substrate (R), memory store (M), context constructor (C), skill-routing layer (S), orchestration loop (O), and verification-and-governance layer (G). Agent performance over a horizon H is not a function of the base model alone, but of the integrated performance of these components. The framework treats each as a distinct axis of design, intervention, and evaluation.
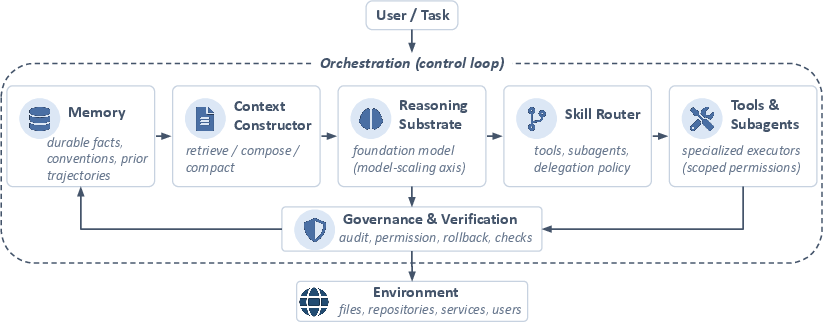
Figure 1: A six-component view of an agentic system, demonstrating the decomposition of agentic AI performance across structured system elements: PH=Φ(R,M,C,S,O,G).
The decomposition is intentional: research and engineering changes to any component—such as memory verifiability or orchestration policies—can significantly alter long-horizon agentic behavior even with a fixed foundation model. This modular clarification is foundational for reproducible harness engineering and explicit systems-level research.
Comparative Harness Analysis: Claude Code, OpenClaw, and CheetahClaws
Three harnesses, Claude Code, OpenClaw, and CheetahClaws, exemplify the diversity of harness-level design, each projecting similar model capabilities onto divergent system priorities: vendor-scale reliability, multi-channel personal assistance, and research transparency, respectively. For instance, CheetahClaws operationalizes memory trust via per-entry confidence and recency metrics, while Claude Code and OpenClaw derive trust implicitly from access patterns. This comparative analysis underscores that harness-level variables—such as memory representation, orchestration policies, and context governance—are decisive for practical agentic capability.
Temporal Layers: Prompt, Skill, and Memory
The paper establishes prompt, skill, and memory as three temporal axes of system scaling and adaptation. Prompting provides immediate control, skills offer reusable execution templates, and memory underwrites longitudinal persistence. Skills, recently operationalized in coding agent harnesses, demand dynamic routing and composability, while memory requires rigorous mechanisms to prevent drift, pollution, and overgeneralization. System reliability depends on explicit coordination of these layers, governed by orchestration and verification.
Bottlenecks in System Scaling
Context Governance
The challenge in context is not the sheer window size, but governance—ensuring relevance, compactness, traceability, and freshness. Larger context windows dilute signal and can expose privacy drift or misallocate token salience. The harness must select context via policy-driven relevance weighting, provenance tracking, and just-in-time refresh mechanisms.
Trustworthy Memory
Agent memory must be precise, durable, retrievable, and verifiable. The dominant failure mode is stale-but-confident: agents may act destructively on outdated yet accessible memory. Reliable harnesses mitigate drift by coupling memory retrieval with environment-grounded re-verification—persistent prior knowledge is continually cross-validated with live state.
Dynamic Skill Routing
Possession of skills alone is inadequate; the harness must selectively route, compose, and verify skill invocations. Pipeline failures often result from unchecked outputs across subagents or specialized skill layers. Robust harnesses dynamically allocate skill use based on adaptive policies, confidence escalation, and explicit postcondition checks.
Evaluation and Agent Evolution
Benchmarking Beyond Outcome Metrics
Current benchmarks—SWE-bench, AgentBench, WebArena, Terminal-Bench—have moved agent evaluation toward multi-step, executable protocols. However, single-episode success conflates model capability with harness design. Harness-level evaluation requires process metrics: trajectory efficiency, memory hygiene, risk cost, and recovery from mistakes. System factors (M, C, M0, M1, M2) must be measured longitudinally.
Longitudinal and Multi-Agent Evaluation
Analysis of multi-agent systems (Claude Opus 4 + Sonnet 4) demonstrates that harness architecture profoundly impacts aggregate performance, with tool allocation and orchestration explaining significant performance variance. True collaborative agent systems require reliable shared state, uncertainty communication, and explicit auditability across repeated tasks and evolving harness states.
Standards for Safe Evolution
Persistent agentic adaptation must distinguish which states (memory, skills, preferences, guardrails) are allowed to evolve, and under which policies. Safety mandates periodic auditability, partitioned update protocols, and explicit longitudinal evaluation of drift and regression, especially given adversarial failure modes such as reward gaming and sleeper agent survival documented in recent literature.
Counterarguments and Implications
The authors address critical objections: stronger foundation models may reduce but not eliminate the need for explicit harness mechanisms; modularity remains essential for auditability, permission control, and safe deployment even under end-to-end policies; and the cost and environment-specificity of harness-level evaluation reflect the operational consequences that benchmarks must account for in responsible agentic systems research.
Practical and Theoretical Implications
By foregrounding system scaling as a first-class research agenda, the paper influences both engineering practice and theoretical inquiry. Harness-level design determines agent reliability, memory trust, skill adaptability, and safe evolution in realistic deployment. As foundation models saturate benchmark performance, longitudinal harness evaluation—including memory hygiene and communication fidelity—becomes indispensable for mature agentic systems. Future developments in AI should thus prioritize system-level benchmarks, modular and auditable harness implementations, and explicit mechanisms for safe, adaptive agent evolution.
Conclusion
This work defines the next major bottleneck in agentic AI as harness-level system scaling. Advances in foundation model capability must be complemented by structured, modular, auditable agent harnesses to deliver persistent, reliable, and verifiable long-horizon agentic behavior. Claude Code, OpenClaw, and CheetahClaws demonstrate that harness choices directly shape agent trajectory quality and longitudinal memory hygiene. The field must now develop benchmarks, standards, and engineering practices that treat memory, context governance, skill routing, orchestration, verification, and agent evolution as primary objects of design and evaluation, moving beyond one-shot task accuracy toward persistent systems reliability.

