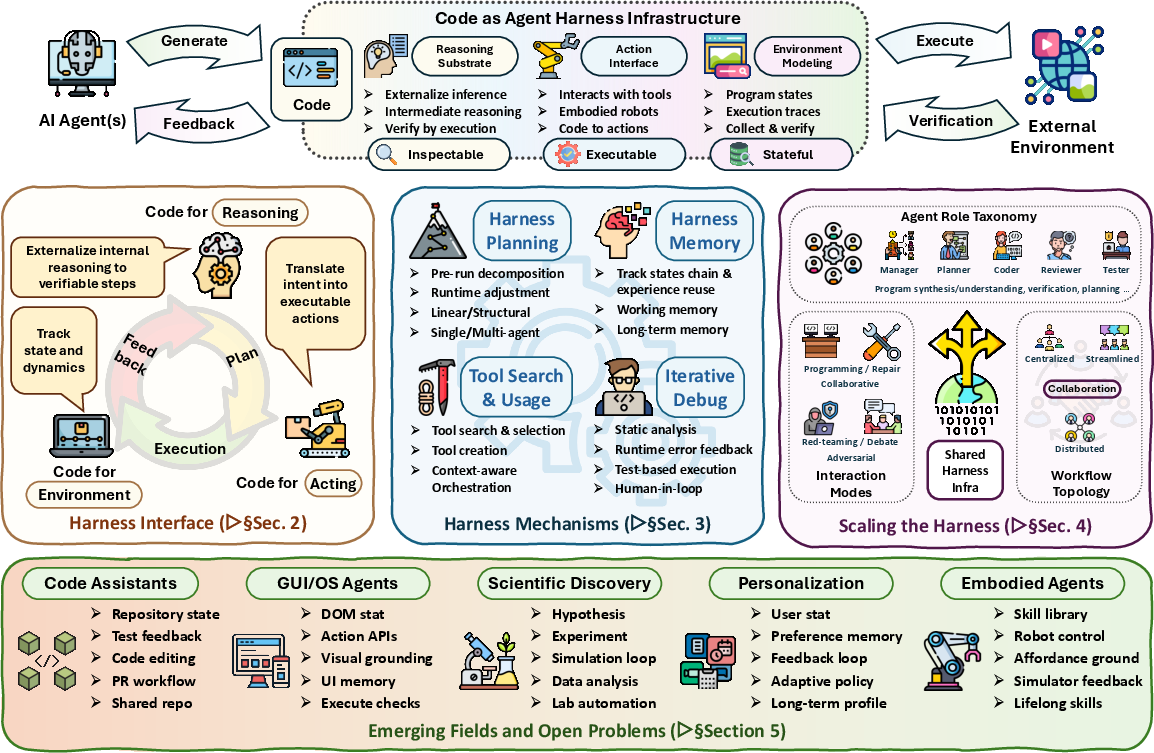
Code as Agent Harness
Abstract: Recent LLMs have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is a big-picture guide to a new way of building AI “agents” (computer programs that can plan and act). The authors say that code shouldn’t just be something an AI writes at the end of a task. Instead, code should be the main “harness” that connects the AI’s thoughts to real actions, keeps track of what’s going on, and lets us check if the AI is doing the right thing. In short: use code as the AI’s seatbelt, control panel, and notebook—all at once.
What questions does it ask?
The paper looks at simple, practical questions:
- How can we make AI agents not just “talk” about plans, but actually do things safely and correctly?
- What’s the best way to let an AI think step-by-step, act in the world, and remember progress?
- How do we organize all this so one agent or even teams of agents can work together without getting confused?
How do the authors study it?
This is a survey paper. That means the authors read lots of recent research and organize it into a clear map. They explain a three-layer “harness” that puts code at the center:
- Layer 1: Interface — code as the way an agent thinks, acts, and understands its environment.
- Layer 2: Mechanisms — planning, memory, tools, and feedback loops that keep the agent reliable over time.
- Layer 3: Scaling — how multiple agents share code, review each other, and coordinate.
They also connect this map to real applications (like coding helpers, robots, and operating-system automation) and list open problems that still need solving.
What are the main ideas and why do they matter?
Layer 1: Code as the interface for thinking, acting, and seeing the world
- Thinking (Reasoning): Instead of only writing out long explanations in plain language, the agent writes small programs to do the tricky parts (like math). Because the programs run, we can check the results. “Executable” means you can press “run.” “Verifiable” means we can test if it worked.
- Acting: The agent turns its plans into code that calls tools, clicks buttons, controls robots, or uses apps. This makes actions precise and checkable. If a step fails, the harness can notice and ask the agent to fix it.
- Seeing the world (Environment modeling): The agent treats the world like a set of code objects—files, tests, logs, simulations—so it can store what happened, replay it, and compare outcomes. “Stateful” means the agent remembers its history instead of starting from zero each time.
Why it matters: Code makes the agent’s thoughts and actions concrete and testable. That means fewer guesswork mistakes and better safety.
Layer 2: The mechanisms that keep agents dependable
To keep going on long tasks, an agent needs structure. The paper highlights four helpful pieces:
- Planning: Breaks a big goal into smaller steps and decides the order.
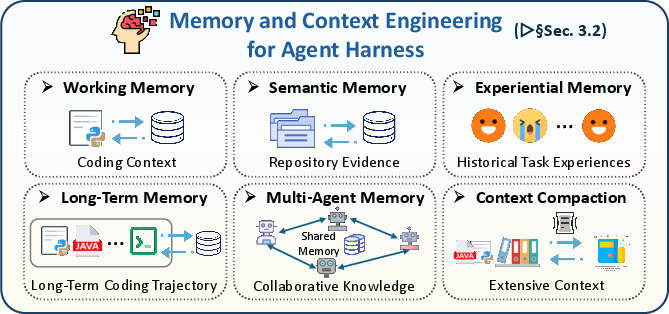
- Memory: Keeps notes, past attempts, useful snippets, and results so the agent doesn’t repeat mistakes.
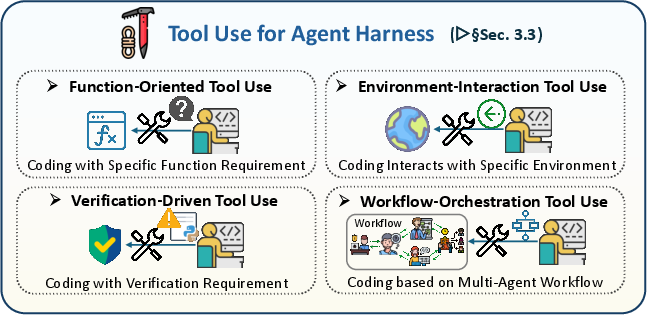
- Tool use: Connects the agent to calculators, databases, APIs, apps, robots, and test suites through code.
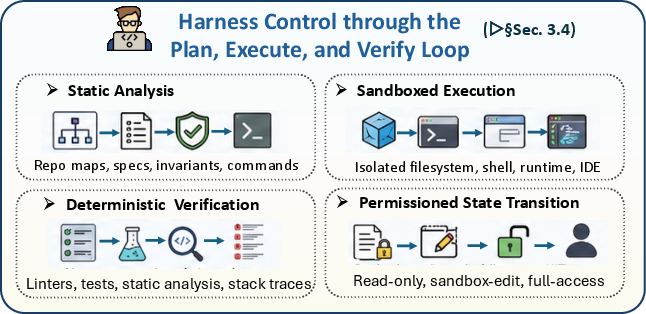
- Feedback and optimization: Runs the code, reads errors or test failures, and uses that feedback to fix the plan or rewrite code.
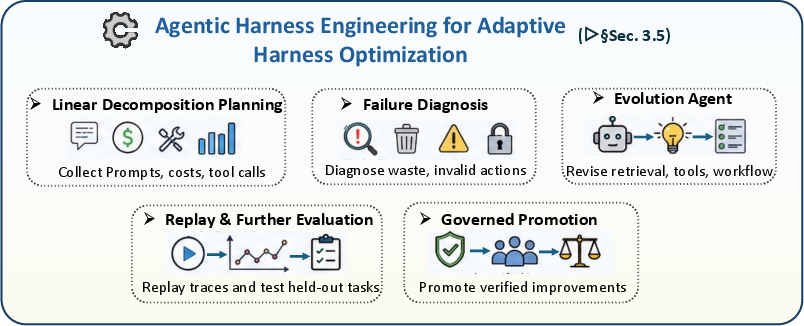
Why it matters: This turns an AI from a one-shot answer machine into a steady worker that improves through trial, error, and repair.
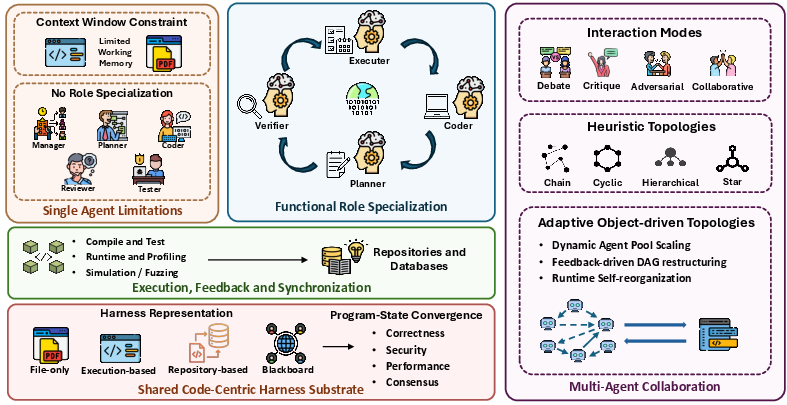
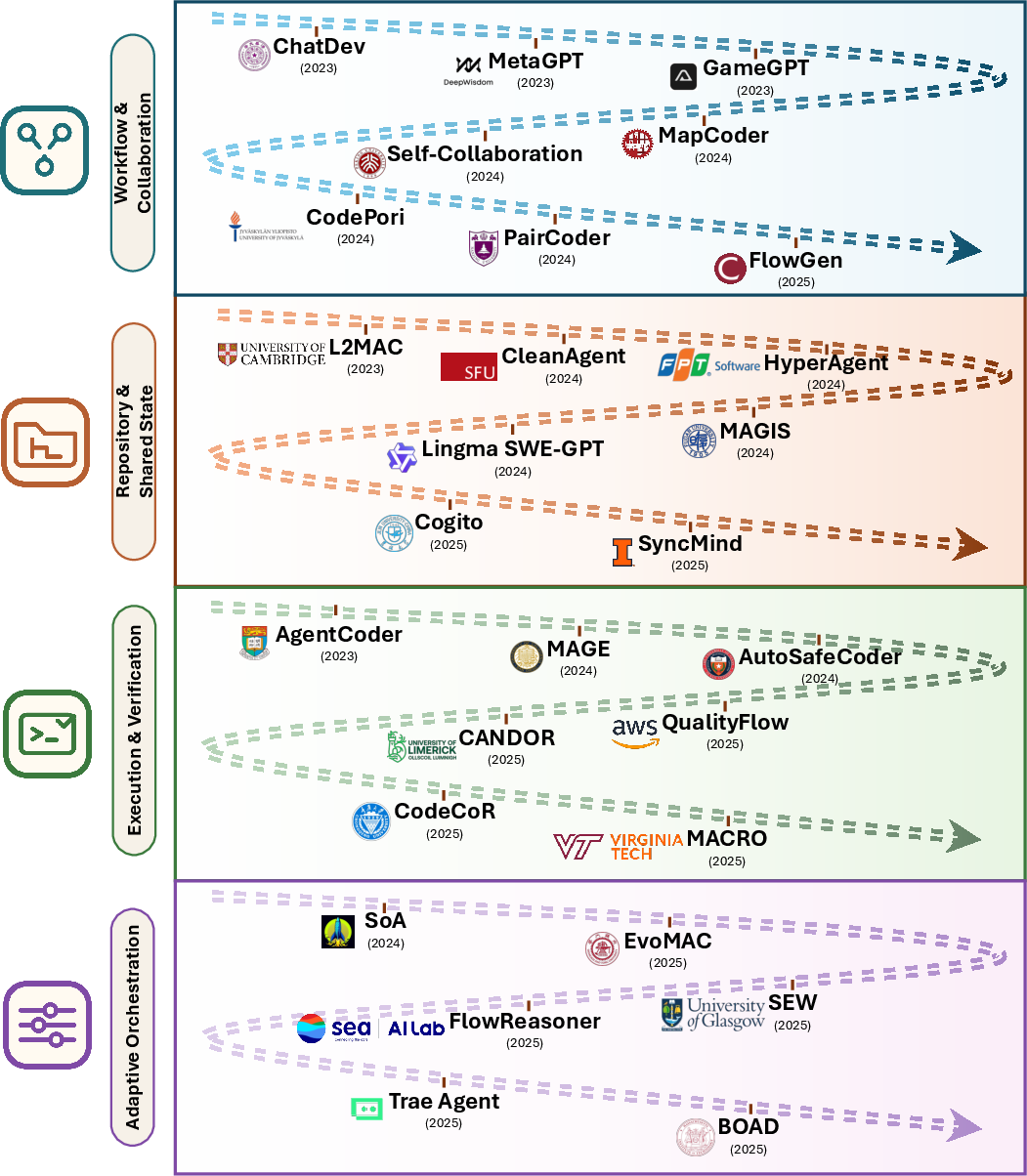
Layer 3: Scaling up to teams of agents
The paper explains how multiple agents can share the same code “workspace”:
- Different roles (like manager, coder, reviewer, tester) can work together.
- Shared artifacts (like tests, logs, and pull requests) help everyone stay on the same page.
- Coordinated workflows prevent chaos and let agents check each other’s work.
Why it matters: Complex jobs often need teamwork. Shared code and tests give a common language for collaboration and quality control.
Where can this be used?
Here are a few places where this approach is already helpful:
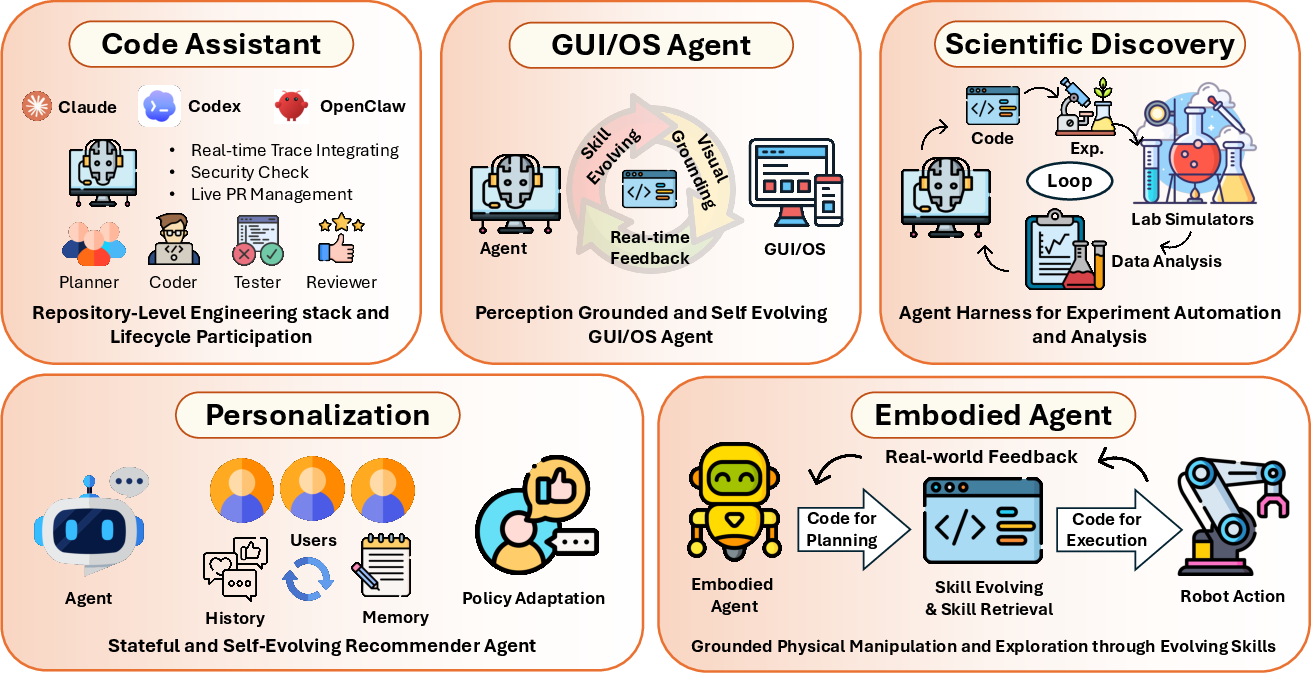
- Coding assistants: Agents write fixes and tests in real software projects.
- GUI/OS automation: Agents control apps and operating systems by generating and running commands safely.
- Robots and embodied agents: Agents write control code and skill libraries to move, pick, build, and adapt.
- Science and data work: Agents build and run analysis pipelines, simulations, and experiments.
- Enterprise workflows: Agents coordinate tasks like DevOps, data pipelines, and recommendations with verifiable steps.
What are the main takeaways?
- Big idea: Treat code as the core harness for AI agents. Code is how they think (compute), act (execute), and remember (state).
- Organized roadmap: A three-layer framework (interface, mechanisms, scaling) that ties together lots of recent methods.
- Practical focus: Many examples across real-world tasks.
- Open challenges: The authors list important problems that still need work:
- Better evaluation than just “final score” (e.g., check each step, not only the end).
- Verification even when feedback is incomplete or delayed.
- Improving the harness without breaking what already works (“no regressions”).
- Keeping shared state consistent when many agents edit the same workspace.
- Human oversight for risky actions.
- Handling multimodal environments (text, images, code, sensors) together.
Why does this matter for the future?
Putting code at the center makes AI agents more trustworthy. Because their plans and actions are executable and testable, we can catch errors early, track progress, and enforce safety rules. It also makes teamwork—between agents and with humans—much easier, since everyone can look at the same code, tests, and logs.
If these ideas grow, we could see agents that:
- Are safer and more reliable in the real world.
- Learn from experience without forgetting.
- Work together smoothly on complex projects.
- Are easier to audit and control.
In simple terms: this paper lays out a plan for building AI helpers that don’t just talk about what they’ll do—they write it down in code, run it, check it, remember it, and improve next time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, actionable list of what remains missing, uncertain, or unexplored in the paper’s proposed “code as agent harness” agenda.
- Formalization of the harness concept: precise semantics, minimal primitives, and interface contracts for “code as harness” (e.g., types, invariants, pre/postconditions) that yield safety/liveness guarantees across generate–execute–revise loops.
- Process-level evaluation beyond final success: standardized, domain-agnostic metrics for intermediate-state correctness, trace quality, recovery from failure, retry budgets, sample efficiency, time-to-fix, and stability over long-running sessions.
- Verification under incomplete, noisy, or delayed feedback: principled ways to combine static analysis, unit/property tests, runtime monitors, and probabilistic conformance checks when oracles are partial or absent.
- Regression-free harness optimization: methods for safe online improvement (e.g., RL, bandits, BO) with canarying, shadow execution, counterexample generation, and proofs/CI guarantees that critical behaviors do not regress.
- Reproducible, stateful evaluation at scale: benchmarks and harnesses that track persistent state across hours/days of operation, measure drift, and reproduce long-horizon trajectories under tool and environment non-determinism.
- Shared-state consistency in multi-agent settings: concurrency control, merge policies, CRDT/transactional semantics for code artifacts, provenance tracking, and conflict resolution strategies that preserve correctness under parallel edits.
- Trust, roles, and isolation among agents: formal models and systems for capability scoping, sandboxing, data isolation, and cross-agent trust/review when many agents share code, tools, and memory.
- Human oversight for safety-critical actions: actionable designs for permissioning, escalation, plan explainability, pre-execution validation, rollback, and HCI workflows that keep humans in control without prohibitive latency.
- Multimodal extensions: unified interfaces for incorporating continuous perception streams (vision/audio/sensors) into code-centric harnesses, with real-time constraints and deterministic replay for debugging.
- Security and adversarial robustness of code-centric agents: defenses against prompt/tool injection, API misuse, sandbox escapes, dependency supply-chain attacks, data exfiltration, and compromised tool backends; artifact signing and reproducible builds.
- Standardized tool and DSL ecosystems: typed schemas, ABI/SDKs, and versioned protocols for tools, validators, tests, and workflows to ensure portability of harness modules across platforms.
- Dataset gaps for harness research: open, privacy-preserving corpora of execution traces, tool I/O, failure/recovery episodes, and multi-agent coordination logs with consistent schemas for training and evaluation.
- Resource- and cost-aware harness control: methods that trade off latency, compute cost, and correctness (e.g., caching, incremental execution, speculative planning, budgeted search) with formal performance guarantees.
- Theoretical foundations of closed-loop stability: models of error propagation, convergence conditions for iterative repair, bounded regret/safety under partial observability, and off-policy evaluation for harness updates.
- Process-reward design for code-grounded RL: general recipes for defining, learning, and validating process rewards that avoid reward hacking and preserve long-horizon credit assignment.
- Generalization and transfer of executable skills: mechanisms to package, parameterize, and port skills/tests/workflows across tasks, environments, and embodiments, with criteria for when reuse helps or harms.
- Bridging formal methods with practical environments: scalable pathways to integrate proof assistants and formal verification into OS/GUI/robotics workflows where specifications are partial and dynamics are stochastic.
- Handling API churn and “skill rot”: automated detection of breaking changes, migration of generated skills/workflows, and test-suite evolution to keep long-lived harnesses healthy.
- Debuggability and observability of agent harnesses: standardized telemetry, structured logs, causal tracing, and postmortem tooling for root-cause analysis across planning, memory, tools, and execution layers.
- Robustness to non-determinism: techniques for determinization, seeding, replay, and statistical comparison when tools, simulators, or environments exhibit variability.
- Multi-agent benchmarking: tasks and metrics that quantify coordination quality, shared-state consistency, reviewer/tester effectiveness, adversarial resilience, and productivity vs. overhead under different orchestration topologies.
- Governance, compliance, and audit: policy-as-code for permissions, redaction, data retention, secret management, accountability trails, and regulatory reporting integrated into the harness.
- Human factors and developer experience: studies and tooling for oversight burden, cognitive load, explainability, and effective UX for authoring/reviewing harness policies, tests, and agent-generated artifacts.
- Cross-lingual and multilingual harnesses: consistency of tool schemas, error messages, and code artifacts across languages/locales, and the impact on reasoning, acting, and evaluation.
- Open-source reference harnesses: end-to-end, well-instrumented baselines with pluggable components, ablations, and recipes that enable controlled comparisons and rapid reproducibility across domains.
Practical Applications
Below are practical, real-world applications that follow from the paper’s “code as agent harness” perspective. Each item summarizes what the application does, the most relevant sectors, likely tools/products/workflows that could emerge, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Coding copilots that write, run, and verify code changes (Software/DevOps)
- What: Repository-level agents that propose patches, generate tests, execute them in sandboxes/CI, and open PRs with artifacts (patch + tests + logs).
- Tools/workflows: IDE plugins with execution sandboxes; “harness-aware” CI runners; PR bots that attach execution traces and regression tests; policy-as-code guardrails for permissions.
- Assumptions/dependencies: Good unit/integration test coverage; safe sandboxing; permission boundaries; robust telemetry; model competency for target stack.
- Autonomous bug triage and issue resolution (Software/DevOps, Enterprise IT)
- What: Agents link issues to code, reproduce failures in a sandbox, author fixes and tests, and iterate via execution feedback until tests pass.
- Tools/workflows: Issue-to-PR pipelines; defect reproducer harness; failure-minimization playbooks; multi-agent roles (planner/coder/tester/reviewer).
- Assumptions/dependencies: Deterministic repro harnesses; reliable error logs; test oracles; human approval checkpoints for risky repos.
- GUI and OS automation with verification loops (RPA, Back-office Ops)
- What: Desktop/web agents generate executable UI/OS commands grounded in DOM/A11y trees; actions are verified by render/state checks before committing.
- Tools/workflows: Browser automation with DOM diffs; “preflight” validators; permission brokers; audit logs of actions plus screenshots/state deltas.
- Assumptions/dependencies: Stable selectors/DOM; app-specific APIs; least-privilege permission model; safe rollback capability.
- Data/ETL pipeline authoring and maintenance with tests (Data Engineering, Finance, Healthcare IT)
- What: Agents synthesize and maintain ETL code, schema validations, and unit tests; run pipelines in staging, verify metrics, and promote changes.
- Tools/workflows: Declarative pipeline DSLs; data quality test suites; lineage-aware execution logs; promotion gates tied to test thresholds.
- Assumptions/dependencies: Clear data contracts; staging environments; monitoring for drift; access control and PII governance.
- Reproducible scientific workflows and notebooks (Academia, R&D, Pharma)
- What: Agents compose hypothesis-testing pipelines (simulation, analysis, visualization) as code; execute, capture traces, and package reproducible notebooks.
- Tools/workflows: Workflow engines (e.g., Nextflow/Snakemake-style harnesses); containerized environments; auto-generated unit tests for analyses.
- Assumptions/dependencies: Accessible datasets/simulators; compute budgets; clear evaluation oracles; human oversight for scientific validity.
- Education: executable tutoring and assessment (Education, Workforce Upskilling)
- What: Tutors generate code exercises and tests, provide execution-grounded feedback, and adapt curricula using results from sandbox runs.
- Tools/workflows: Auto-graders; trace-based hints; versioned student skill libraries; “explain-then-run” pedagogy.
- Assumptions/dependencies: Safe sandboxing; calibrated hints; curriculum alignment; anti-plagiarism/academic integrity policies.
- Runbook and SRE automation with guardrails (IT Ops, Cloud)
- What: Agents encode runbooks as executable workflows, simulate changes, and execute with approval gates; include rollback scripts and postmortem logs.
- Tools/workflows: IaC/PaC (“policy-as-code”) validators; change windows; blast-radius estimators; progressive rollout orchestrators.
- Assumptions/dependencies: Strong observability; staging/canary infra; explicit approval thresholds; incident response integration.
- Regulatory and compliance checks as code (Finance, Healthcare, Public Sector)
- What: Agents translate policies into machine-checkable rules/tests; run them on data/processes and produce auditable evidence.
- Tools/workflows: Policy-as-code repositories; evidence bundling (rules + logs + data snapshots); change control for rule updates.
- Assumptions/dependencies: Unambiguous policy translation; structured access to systems; regulator-accepted audit trails; privacy safeguards.
- Personal RPA: end-user task automation with safe previews (Daily Life, SMBs)
- What: Agents automate email triage, spreadsheet ops, billing, and web forms; actions previewed, verified, then executed.
- Tools/workflows: “Dry-run” mode; per-app permissions; explain-why prompts; one-click revert.
- Assumptions/dependencies: Stable app APIs/DOM; user consent and clear UI affordances; local sandboxing for sensitive data.
- Multi-agent code review and governance (Software, Enterprise Platforms)
- What: Manager/planner/coder/tester/reviewer agents coordinate over shared repositories and tests to raise code quality and reduce regressions.
- Tools/workflows: Role-based workflows; debate/red teaming for risky code; automated gatekeepers for test and security thresholds.
- Assumptions/dependencies: Orchestrator reliability; consistent shared state; clear escalation to humans for tie-breakers.
- Domain tool-use via standardized harness interfaces (Cross-industry)
- What: Agents call structured APIs (databases, CRMs, ERPs) defined by schemas and validators; execution grounded in code-defined tools.
- Tools/workflows: Tool registries with contracts; schema-evolving adapters; telemetry on tool outcomes; fallback/repair loops.
- Assumptions/dependencies: Accurate API schemas; backward-compatible tool changes; robust error handling; access controls.
- Test-first feature prototyping (Product Engineering)
- What: Agents generate tests that capture acceptance criteria before writing code; iterate until tests pass and produce PR bundles.
- Tools/workflows: Spec-to-test generation; ephemeral preview envs; trace-based review summaries; auto-link to product tickets.
- Assumptions/dependencies: Clear specs/user stories; reliable test oracles; human product owner sign-off.
Long-Term Applications
- Autonomously evolving software systems (Software/DevOps)
- What: Agents that plan, implement, test, and refactor large repositories continuously with regression-free improvement guarantees.
- Tools/workflows: Global dependency analyzers; impact-aware change planners; large-scale, synthesis-driven test generation; formal contracts for modules.
- Assumptions/dependencies: High test coverage or formal specs; scalable codebase understanding; robust rollback and canary deployments.
- General-purpose home/industrial robots programmed via code harness (Robotics, Manufacturing, Smart Homes)
- What: Agents generate and verify robot policies as code (behavior trees/constraints), adapt via execution feedback, and share reusable skills across devices.
- Tools/workflows: Safety-certified motion planners; affordance/model-checking layers; standardized skill libraries; fleet-level telemetry and replay.
- Assumptions/dependencies: Reliable perception; strong safety and certification frameworks; standardized hardware abstractions; low-latency control.
- Multi-robot swarms coordinated by shared code artifacts (Robotics, Logistics, Agriculture)
- What: Swarm policies synthesized from declarative goals; coordination through shared state and verifiable protocols.
- Tools/workflows: Distributed execution harnesses; consensus/coordination DSLs; simulation-to-real transfer validators.
- Assumptions/dependencies: Robust wireless/edge infra; formal safety constraints; resilient shared-state consistency.
- Autonomous laboratory systems for closed-loop discovery (Pharma, Materials, Bio)
- What: Agents design experiments, control instruments, analyze results, and refine hypotheses through executable lab protocols.
- Tools/workflows: Robot lab orchestration; protocol/version control; causal/active learning loops; provenance tracking for every step.
- Assumptions/dependencies: Standardized instrument APIs; safety/ethics approvals; strong physical-world verification and redundancy.
- Clinically integrated, verifiable decision support (Healthcare)
- What: Agents generate reproducible analysis pipelines and care-pathway simulations with formal checks and human-in-the-loop gating.
- Tools/workflows: Verified clinical DSLs; evidence bundles for auditors; EHR-integrated preview/approval; post-deployment monitoring.
- Assumptions/dependencies: Regulatory clearance; bias and safety evaluation; strict privacy; alignment with clinical guidelines.
- Enterprise digital twins and process optimization via executable world models (Manufacturing, Energy, Supply Chain)
- What: Agents construct and refine code-based simulators of plants/grids, test interventions, and deploy controlling policies with guardrails.
- Tools/workflows: Model calibration pipelines; scenario test batteries; control-theory constraints as code; audit trails for changes.
- Assumptions/dependencies: High-fidelity models; sensor data integration; fail-safes; operator oversight.
- Formal verification of agent workflows at scale (Cross-industry, Safety-critical)
- What: Use proof assistants and symbolic checkers to certify agent plans, constraints, and end-to-end workflows before execution.
- Tools/workflows: Domain-specific formal DSLs; auto-proof search; human-readable proof summaries; certification pipelines.
- Assumptions/dependencies: Mature formal methods tooling for domains; cost-performance tradeoffs; skilled oversight.
- Policy-as-code for AI agents with continuous compliance (Public Sector, Finance)
- What: Machine-checkable rules that constrain agent actions (data access, export, safety), monitored and enforced in real time.
- Tools/workflows: Runtime policy engines; effect audits with execution traces; regulator portals for live conformance dashboards.
- Assumptions/dependencies: Clear, unambiguous regulations; standardized attestations; verifiable logs accepted by regulators.
- Secure automation for critical infrastructure (Energy, SCADA, Transportation)
- What: Agents propose and simulate control changes in digital twins, pass formal safety checks, and execute through gated controllers.
- Tools/workflows: DSLs with safety invariants; intrusion-resistant harnesses; staged deployment sequences; kill-switch governance.
- Assumptions/dependencies: Cybersecurity hardening; operator-in-the-loop; exhaustive scenario testing; liability frameworks.
- Multimodal agent harnesses operating across language, vision, and action (Robotics, UI, AR/VR)
- What: Agents that fuse code-grounded reasoning with visual/perceptual state and act across heterogeneous interfaces with consistent shared state.
- Tools/workflows: Multimodal trace stores (text, code, images, sensor logs); cross-modal validators; unified memory for agents.
- Assumptions/dependencies: Consistent state synchronization; robust perception; scalable storage/indexing for multimodal traces.
- Market-facing, audited algorithmic services (Finance, Insurance, Marketplaces)
- What: Agents that auto-build pricing/risk models, run backtests, generate compliance reports, and publish “executable notebooks” as audit evidence.
- Tools/workflows: Data lineage and versioning; risk-policy rule engines; reproducible markets simulators; oversight committees workflows.
- Assumptions/dependencies: Data quality; model risk management; real-time monitoring; legal accountability structures.
- Organization-scale orchestration of heterogeneous agents (Enterprise Platforms)
- What: Companies run ecosystems of specialized agents (planner/coder/analyst/compliance) coordinating through shared code artifacts and state.
- Tools/workflows: Agent OS with role-based orchestration; shared-state registries; governance policies and SLAs; cross-agent regression tests.
- Assumptions/dependencies: Interop standards; consistent shared state; robust conflict resolution; clear escalation paths.
Notes on feasibility across applications:
- Common dependencies: high-quality sandboxes; test oracles; permission and identity management; execution telemetry; cost-aware compute; privacy/security controls; human oversight for safety-critical actions.
- Key risks: incomplete feedback leading to silent failures; regression from agent changes; distributed state consistency across multi-agent systems; evaluation beyond final-task success (process metrics, safety, data use).
- Enablers: standard tool schemas; policy-as-code; formal verification where critical; trace stores for process rewards and audits; role-based multi-agent workflows.
Glossary
- Accessibility APIs: Operating-system interfaces exposing UI elements and actions for automation and assistive access. "DOM trees, accessibility APIs, and executable evaluators"
- Affordance: The set of feasible actions an environment allows; models estimate which actions are possible for an agent. "affordance or feasibility models estimate which actions are possible"
- Agent harness: The software layer that connects an LLM to tools, execution, state, and feedback, turning it into a functional agent. "An agent harness refers to the software layer that surrounds an LLM with tools, APIs, sandboxes, memory, validators, permission boundaries, execution loops, and feedback channels"
- Agent-initiated code artifacts: Executable code objects created and evolved by agents during tasks to reason, act, verify, and store state. "agent-initiated code artifacts, which remain relatively underexplored, are interactive code objects that agents create, execute, observe, revise, persist, and share within the task execution loop."
- Agentic AI: An AI paradigm framing systems as autonomous agents that act, learn, and adapt within harnesses. "By centering code as the harness of agentic AI"
- Agentic systems: Systems where models operate as agents interacting with environments via reasoning and actions. "In emerging agentic systems, code is no longer only a target output."
- API schema: A machine-checkable specification of API endpoints, parameters, and data types used to validate and invoke tools. "API schemas, tool definitions, tests, repositories"
- Behavior tree: A hierarchical control structure representing agent behaviors with composable nodes and clear execution semantics. "serve as policies, tool calls, behavior trees, or reusable skills"
- Chain-of-thought (CoT): A prompting and reasoning technique that elicits step-by-step intermediate reasoning in text. "pure chain-of-thought (CoT)"
- Closed-loop: A feedback-driven control setup where execution outcomes inform subsequent decisions and revisions. "closed-loop agentic behavior."
- Code as agent harness: The central view that code is the executable, inspectable, and stateful substrate organizing agent reasoning, action, and verification. "we refer to this view as code as agent harness"
- Control-flow structures: Program constructs (e.g., conditionals, loops) that determine the order of execution and branching logic. "execution traces, variable states, control-flow structures, and function-level tests"
- Domain-specific language (DSL): A specialized programming language tailored to a particular domain or task, enabling concise, structured control. "DSL programs, executable workflows, reusable skills"
- DOM tree: The Document Object Model hierarchical representation of a webpage or UI used to ground GUI actions. "DOM trees, accessibility APIs, and executable evaluators"
- Embodied agents: Agents that act in physical or simulated environments through sensors and actuators. "robotic and embodied agents use generated programs as executable policies"
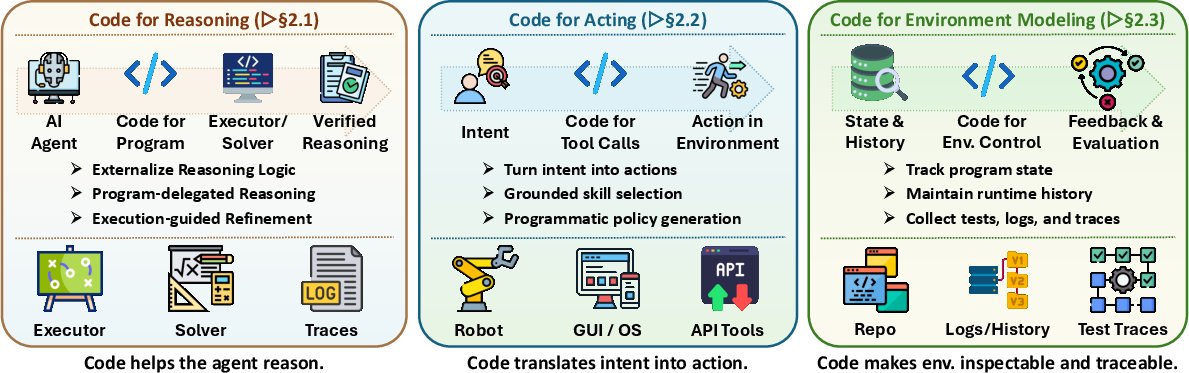
- Environment modeling: Representing state, dynamics, and feedback of the task environment via code, simulators, tests, and logs. "Environment Modeling"
- Execution-based verification: Checking correctness by actually running code and observing outcomes rather than only inspecting text. "execution-based verification"
- Execution loop: The repeated cycle of planning, executing, observing feedback, and revising within an agent harness. "execution loops"
- Execution trace: A structured log of program states, outputs, and control flow produced during execution, used for diagnosis and learning. "execution traces"
- Formal specification: A mathematically precise, machine-checkable description of desired system behavior. "formal specifications, proof scripts, API schemas"
- Formal verification: Use of mathematical proofs and automated checkers to ensure correctness relative to formal specifications. "Formal Verification and Symbolic Reasoning Interfaces"
- GUI: Graphical user interface; visual interactive surfaces that agents can operate programmatically. "GUI/OS automation"
- Harness engineering: The discipline of designing and building the infrastructure that grounds models in tools, state, and safe execution. "forms the main focus of harness engineering"
- Harness interface: The code-centric boundary where an agent’s outputs become executable interactions with the environment. "harness interface"
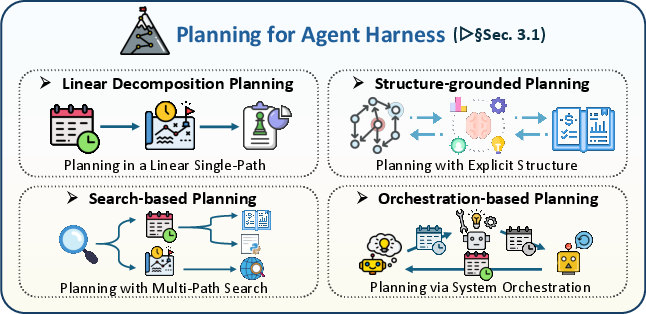
- Harness mechanisms: The planning, memory, tool-use, control, and optimization modules that sustain long-horizon agent operation. "Harness Mechanisms: Planning, Memory, Tool Use, Control, and Optimization"
- Permission boundaries: Enforced limits on what actions or resources an agent can access to ensure safety and governance. "permission boundaries"
- Process rewards: Intermediate signals that score steps of a reasoning or execution trajectory, not just final outcomes. "execution traces, or process rewards"
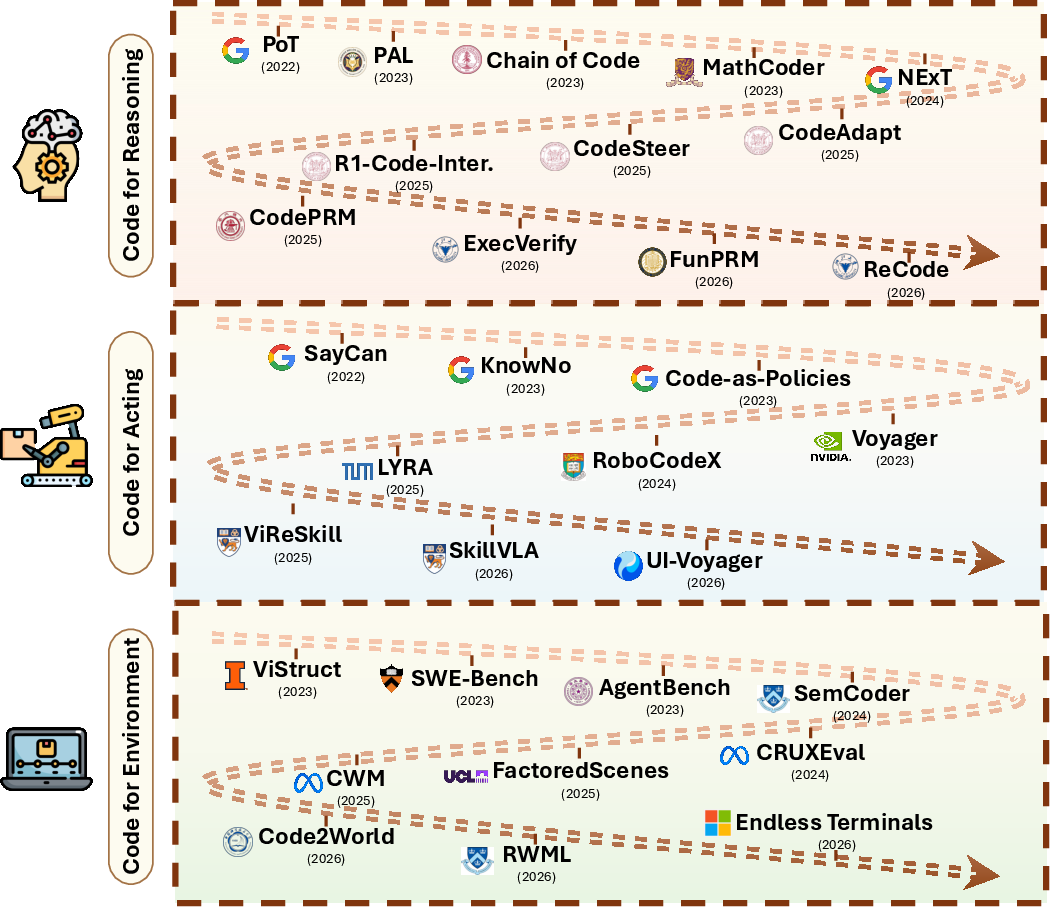
- Program-aided reasoning: Delegating parts of reasoning to executable programs that are run and checked by interpreters or solvers. "Program-aided reasoning methods externalize intermediate computation into executable code"
- Proof assistant: A system supporting machine-checked proof development (e.g., Lean, Coq, Isabelle) used for formal reasoning. "Proof assistants such as Lean~\cite{moura2021lean}, Isabelle~\cite{nipkow2002isabelle}, and Coq~\cite{barras1999coq}"
- Repository-level: Pertaining to whole software repositories, including multi-file context and project-wide dependencies. "repository-level software engineering"
- Sandbox: An isolated execution environment that limits side effects and permissions during code runs. "sandboxes"
- SAT/SMT solving: Satisfiability and satisfiability modulo theories solving used as machine-checkable reasoning backends. "SAT/SMT solving"
- Static analysis: Program analysis without execution to detect issues, enforce constraints, or guide repair. "use static analysis, runtime errors, tests, and human feedback to revise code"
- Symbolic solver: A solver that manipulates symbolic expressions and constraints (e.g., theorem provers, SMT solvers). "symbolic solvers"
- Telemetry: Instrumentation data and logs collected during agent execution for monitoring and control. "telemetry"
- Tool use: The agent’s invocation of external tools and APIs as part of its action space. "planning, memory, tool use, execution, and repair"
- World-modeling: Building executable models of environment dynamics and state transitions to guide planning and control. "World-modeling"
- Workflow orchestration: Structuring and scheduling multi-step processes, dependencies, and tool calls for long-horizon tasks. "trajectory search, or workflow orchestration"
Collections
Sign up for free to add this paper to one or more collections.

