ROMA: Recursive Open Meta-Agent Framework for Long-Horizon Multi-Agent Systems
Abstract: Current agentic frameworks underperform on long-horizon tasks. As reasoning depth increases, sequential orchestration becomes brittle, context windows impose hard limits that degrade performance, and opaque execution traces make failures difficult to localize or debug. We introduce ROMA (Recursive Open Meta-Agents), a domain-agnostic framework that addresses these limitations through recursive task decomposition and structured aggregation. ROMA decomposes goals into dependency-aware subtask trees that can be executed in parallel, while aggregation compresses and validates intermediate results to control context growth. Our framework standardizes agent construction around four modular roles --Atomizer (which decides whether a task should be decomposed), Planner, Executor, and Aggregator -- which cleanly separate orchestration from model selection and enable transparent, hierarchical execution traces. This design supports heterogeneous multi-agent systems that mix models and tools according to cost, latency, and capability. To adapt ROMA to specific tasks without fine-tuning, we further introduce GEPA$+$, an improved Genetic-Pareto prompt proposer that searches over prompts within ROMA's component hierarchy while preserving interface contracts. We show that ROMA, combined with GEPA+, delivers leading system-level performance on reasoning and long-form generation benchmarks. On SEAL-0, which evaluates reasoning over conflicting web evidence, ROMA instantiated with GLM-4.6 improves accuracy by 9.9\% over Kimi-Researcher. On EQ-Bench, a long-form writing benchmark, ROMA enables DeepSeek-V3 to match the performance of leading closed-source models such as Claude Sonnet 4.5. Our results demonstrate that recursive, modular agent architectures can scale reasoning depth while remaining interpretable, flexible, and model-agnostic.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ROMA, a way to organize and run teams of AI “agents” so they can handle big, complex tasks that take many steps. Think of ROMA like a smart project manager: it breaks a big goal into smaller parts, makes sure those parts are done in the right order (and in parallel when possible), and then pulls all the pieces back together into a clear final result. The authors also present GEPA+, a method to improve the instructions (prompts) that each agent follows, without needing to retrain the AI models.
What questions did the researchers ask?
They wanted to solve three main problems with current AI agent systems:
- How can we make AI agents better at long, multi-step tasks (like researching online, writing long documents, or building solutions with code) without getting lost?
- How can we organize these agents so the process is clear, easy to debug, and re-usable for different kinds of tasks?
- How can we keep the amount of text and data the AI must remember manageable, and improve the agents’ instructions without retraining?
How did they approach the problem?
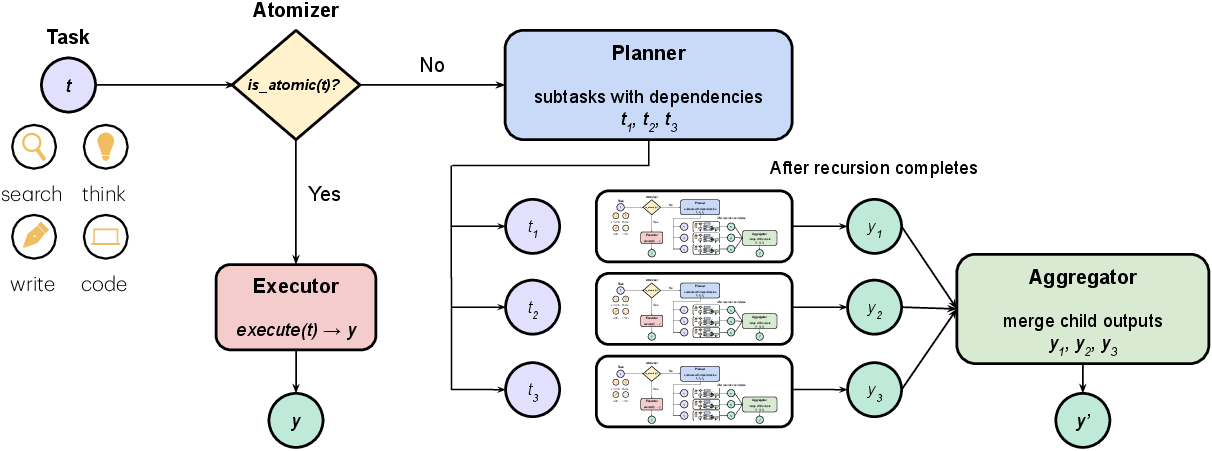
The authors created ROMA, a framework that runs the same simple loop at every step: decide if a task is small enough to do now, otherwise split it into parts, do the parts, and then combine the results.
The ROMA framework: four roles
ROMA standardizes agents around four roles. You can think of them like a well-organized team working on a school project:
- Atomizer: Decides if a task is small enough to do directly or needs to be split. Like asking, “Can I finish this now, or do I need a plan?”
- Planner: Breaks a big task into smaller, non-overlapping pieces that cover everything (this is called MECE: Mutually Exclusive and Collectively Exhaustive). It also sets dependencies—what must happen before something else.
- Executor: Does the actual work on the small tasks—searching the web, thinking through steps, writing, or coding.
- Aggregator: Combines and cleans up the pieces, checks them, and makes a useful summary or final product (like a polished paragraph, table, or answer).
How ROMA works step-by-step
- Start with a big goal.
- Atomizer: If the goal is simple, just do it (Executor). If not, send it to the Planner.
- Planner: Split the goal into smaller tasks and mark any “must happen before” links. Tasks that don’t depend on each other can run in parallel, saving time.
- Executors: Work on the small tasks using the right tools (search, reasoning, writing, or coding).
- Aggregator: Summarize, verify, and compress the results so they’re easy to pass upward without overwhelming memory.
- Repeat this process recursively (like breaking a problem into subproblems again and again) until everything is solved.
This creates a clear “execution tree” showing every decision and step, which makes debugging much easier.
Keeping information manageable
AI models have a “context window,” like a limited memory. If you keep stuffing more text into it, performance can drop (the paper calls this “context rot”). ROMA avoids this by:
- Doing work locally at the leaf tasks (Executors focus on small chunks).
- Compressing and validating results at each level (Aggregators send up concise summaries instead of full transcripts). This keeps the overall process scalable and stable, even for long tasks.
GEPA+: improving agent instructions
Prompts are the instructions we give AI models. GEPA+ is a way to improve these prompts for each ROMA component (Atomizer, Planner, Executors, Aggregator) without retraining:
- It proposes multiple prompt edits in parallel (like brainstorming several changes).
- Judges and verifiers score these edits (quality checks and quick tests).
- It merges the best parts into one safe, compatible update that still follows the rules and interfaces. This tends to boost performance with fewer evaluation attempts than older methods.
What did they find?
Across several benchmarks, ROMA improved results compared to other systems:
- SEAL-0 (reasoning over conflicting web evidence): Using the GLM-4.6 model, ROMA reached about 46% accuracy—around 10 percentage points higher than a strong open-source research agent (Kimi-Researcher) and clearly better than closed-source systems tested.
- FRAMES (multi-hop reasoning with Wikipedia): ROMA scored about 82%, beating other open- and closed-source systems.
- SimpleQA (short factual questions): ROMA achieved about 94%, matching the best open-source results and close to top closed-source tools.
- EQ-Bench (long-form writing): With DeepSeek-V3 and GEPA+ prompt optimization, ROMA scored about 80%, matching leading closed-source models like Claude Sonnet 4.5.
- AbGen (designing scientific ablation studies): ROMA achieved the best overall scores among tested systems, showing it can structure complex scientific reasoning well.
These results suggest ROMA’s structure—splitting tasks smartly, running parts in parallel, and aggregating cleanly—really helps on deep, multi-step problems.
Why does it matter?
- Reliability: Clear, structured traces make it easier to find where something went wrong (planning vs. execution vs. aggregation).
- Scalability: Managing context by summarizing as you go lets the system handle long tasks without getting bogged down.
- Flexibility: ROMA is model-agnostic—you can mix different AI models and tools for different roles (cheaper ones where speed matters, stronger ones where accuracy matters).
- Upgradability: GEPA+ improves prompts component-by-component, so teams can adapt ROMA to new tasks quickly without expensive retraining.
Takeaway and impact
ROMA shows that better organization beats brute force. By treating big problems like well-managed projects—deciding when to split, planning dependencies, executing focused jobs, and carefully recombining results—AI systems can think deeper, stay understandable, and perform well across very different tasks. GEPA+ adds a practical way to fine-tune the instructions those agents follow, boosting performance without changing the underlying models. Together, they point toward future AI systems that are:
- More trustworthy (transparent and debuggable),
- More efficient (parallel where possible, compact summaries where needed),
- And more universal (easy to adapt to new domains).
For students and builders, the core idea is simple: organize your thinking like a tree of small steps, do them well, and combine them smartly. ROMA turns that idea into a reusable blueprint for AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved by the paper and can guide future work:
- Heterogeneous role–model assignment: The paper defers a systematic study of assigning different models to Atomizer, Planner, Executor, and Aggregator. What policies (e.g., per-task-type, confidence-aware, budget-aware) yield the best cost–quality–latency trade-offs, and how should routing be learned or optimized online?
- Atomicity decision quality: There is no quantitative evaluation of the Atomizer’s is_atomic() accuracy, calibration, or its downstream effect on performance. How do false positives/negatives impact overall outcomes, and can atomicity be validated or corrected automatically?
- MECE and DAG validity guarantees: The Planner is expected to produce MECE, acyclic dependency graphs, but there is no formal checking or metrics for coverage, redundancy, or cycles. What automated validators and penalties (beyond prompt-level contracts) robustly enforce MECE and DAG invariants at scale?
- Component-level ablations: The paper lacks controlled ablations isolating each role’s contribution (e.g., flat vs recursive execution, with/without Aggregator compression, different Planner strategies). Which components drive gains on which task families and at what compute cost?
- Aggregation fidelity and verification: While aggregation compresses and “validates” intermediate results, there is no measurement of information loss, faithfulness, or hallucination rates introduced by aggregation. What task-agnostic metrics and verifiers can ensure fidelity of compressed summaries to child artifacts?
- Context-rot mitigation quantification: Claims about mitigating context rot are not supported by quantitative studies (e.g., performance vs. context growth curves). How does ROMA’s compression affect accuracy as recursion depth and intermediate artifacts scale?
- Scheduling and parallelism: Dependency-aware parallel execution is described but not studied formally. What scheduling strategies minimize critical-path latency under variable subtask costs, and how do queueing, batching, and speculative execution affect throughput and reliability?
- Failure handling and robustness: The framework does not detail retry policies, rollback semantics, or idempotency for failed subtasks/tools. How should ROMA detect, contain, and recover from partial failures or timeouts, and what are best practices for fault localization and remediation?
- Security and tool safety: Although code runs in a sandbox, there is no empirical evaluation against prompt injection, tool abuse, data exfiltration, or cross-subtask contamination. What red-teaming protocols and guardrails are needed for safe tool use and artifact handling?
- External search dependence and reproducibility: SEAL-0 and other search-heavy tasks rely on GPT-5-mini search results, raising replicability and fairness concerns. How sensitive is ROMA to search provider quality, ranking variance, and temporal drift, and can ensembles or normalization strategies improve stability?
- Evaluation bias from LLM judges: Results rely heavily on LLM-as-a-judge (including Claude-family models), with potential bias—especially where judges also assist in GEPA+. How do outcomes change under cross-judge evaluation, calibration with human raters, or judge-robust metrics?
- GEPA+ generality and stability: GEPA+ is only applied on EQ-Bench. How well does it transfer to reasoning, code, and retrieval-heavy tasks? What are optimal k (proposers) and n (merges) settings, and how does it avoid overfitting to judge preferences or breaking cross-module contracts over many rounds?
- Contract-preserving merge reliability: The merger claims to preserve interfaces but lacks stress tests on complex, conflicting edits across modules. What automated conformance checks and regression tests reliably prevent subtle contract violations or drift over optimization cycles?
- Multi-episode memory and artifact lifecycle: ROMA stores artifacts but does not address cross-episode memory, eviction, deduplication, or privacy. How should long-term memory be managed (e.g., indexing, TTLs, access control) to balance reuse, footprint, and compliance?
- Mixed-modality and code-heavy tasks: Evaluations focus on text-centric benchmarks. How does ROMA extend to multi-modal inputs/outputs (images, tables, audio) and more intensive code/tool chains (e.g., data science workflows, robotics), including typed artifacts and validation?
- Human-in-the-loop workflows: Despite claims of transparency, no user studies measure whether hierarchical traces reduce debugging time or improve trust. How should ROMA surface explanations and checkpoints to support interactive correction, approvals, and preference alignment?
- Theoretical scaling laws: There is no analysis of returns vs. recursion depth, branching factor, or aggregation granularity. What are the compute–accuracy scaling laws, and where are diminishing returns or instability regions?
- Robustness to adversarial or conflicting evidence: SEAL-0 shows gains on naturally conflicting evidence, but adversarial settings (targeted misinformation, poisoning, adversarial retrieval) are not studied. What defenses (e.g., consistency checks, provenance tracking) improve robustness?
- Cross-model coherence: ROMA supports heterogeneous roles but does not quantify cross-model coherence issues (e.g., style drift, schema drift). What normalization, canonicalization, or agreement protocols mitigate inconsistencies when different models populate different roles?
- Determinism and reproducibility: There is no discussion of controlling stochasticity (seeds, decoding, caching) for repeatable plan/execute/aggregate traces. What configurations ensure reproducible runs across time and infrastructure?
- Cost and latency profiling beyond writing: Only long-form writing provides a cost/latency breakdown. How do cost, token usage, and wall-clock time scale across benchmarks and with different recursion depths and degrees of parallelism?
- Fair baselines and compute parity: Baseline selection varies per benchmark and compute budgets are not normalized. How do ROMA’s gains compare under matched token/compute budgets and identical retrieval conditions against strong agentic and non-agentic baselines?
- General DAG topologies and non-tree coordination: ROMA uses DAGs but focuses on tree-like decompositions; lateral communication and cross-branch negotiation are underexplored. Can more general coordination patterns (e.g., graph message passing, consensus) improve performance on interdependent subtasks?
- Privacy and compliance: Persisting artifacts to object stores raises questions about PII handling, retention, and auditing. What mechanisms (redaction, encryption, data lineage) are required for regulated domains?
- Lifecycle of prompts and drift: Long-running systems may experience prompt drift after repeated GEPA+ updates. What monitoring and rollback strategies prevent regression and maintain stability over time?
Glossary
- Ablation study: a controlled experiment that removes or varies components to determine their impact on outcomes. "prompts the agent to propose an ablation study design."
- Aggregator: a component that synthesizes and compresses the outputs of subtasks into a coherent result for the parent task. "after which an Aggregator merges the outputs of all descendants to produce the final result."
- Agentic systems: systems that coordinate LLMs, tools, and memory in multi-step workflows to solve complex tasks. "LLMs have enabled rapid progress in agentic systems"
- Atomizer: a module that decides whether a task is atomic (handled directly) or should be decomposed further. "An Atomizer determines whether a task is atomic."
- Best-of-N: a test-time scaling strategy that generates multiple solution attempts and selects the best one. "parallel scaling (e.g., majority voting or Best-of-N~\citep{snell2025scaling,brown2025large}, which generate multiple solution attempts in parallel and select the best one)"
- Chain-of-Thought (CoT): a prompting strategy that elicits step-by-step reasoning before producing final answers. "chain-of-thought (CoT)"
- CodeAct: a prompting/execution strategy that interleaves reasoning with code writing and execution. "CodeAct~\citep{wang2024executable}"
- Context rot: performance degradation as accumulated context grows, leading to weaker reasoning over long inputs. "reduces context rot~\citep{hong2025context}"
- Contract-preserving merger: a method that fuses multiple prompt edits while maintaining module interface contracts. "via a contract-preserving merger that performs:"
- Critical path: the sequence of dependent tasks that determines overall latency in parallel execution. "latency-efficient execution along the critical path"
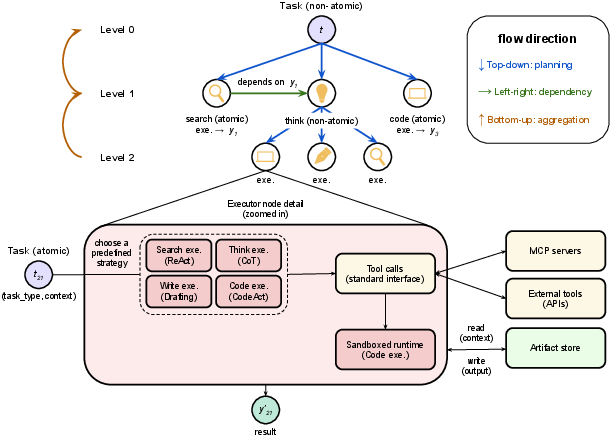
- Dependency-aware (subtask graph): a task decomposition that encodes explicit execution dependencies between subtasks. "a dependency-aware subtask graph "
- Directed acyclic graph (DAG): a graph with directed edges and no cycles, used to represent task dependencies. "which can be seen as a directed acyclic graph (DAG)"
- DSPy: a framework for modular, typed LM programs with optimization hooks for prompts and weights. "DSPy's ``programming-not-prompting'' abstractions allow these components to be declared as executable modules"
- Executor: a role that carries out atomic subtasks using type-specialized strategies or tools. "atomic tasks are handled directly by Executors"
- GEPA: Genetic-Pareto prompt evolution, a method for improving prompts via iterative proposal and selection. "GEPA-style prompt evolution~\citep{agrawal2025gepa}"
- GEPA+: an extension of GEPA that uses parallel diverse proposals, judges/verifiers, and a merger to update prompts safely. "we further introduce GEPA+, an improved Genetic-Pareto prompt proposer"
- Guided beam search: a search strategy that steers beam expansion using evaluative guidance signals. "guided beam search~\citep{xie2023selfevaluation}"
- Heterogeneous multi-agent systems: systems that mix different models and tools across roles to exploit varied strengths. "heterogeneous multi-agent systems that mix models and tools according to cost, latency, and capability."
- Hierarchical Task Networks (HTN): a planning formalism that decomposes tasks into subtasks with hierarchical structure. "inspired by Hierarchical Task Networks~\citep{sacerdoti1975structure,georgievski2015htn}"
- Likert scale: an ordinal rating scale (e.g., 1–5) used for subjective evaluation. "using a Likert scale from 1 to 5"
- LLM-as-a-Judge: using an LLM to score or evaluate outputs according to rubrics. "LLM-as-a-Judge~\citep{zheng2023judging}"
- Model Context Protocol (MCP): a standard interface for tool interaction and context exchange with models. "Model Context Protocol (MCP)~\citep{anthropic2024introducing}"
- Monte Carlo Tree Search: a tree-based exploration method that balances exploration and exploitation via randomized rollouts. "Monte Carlo Tree Search~\citep{zhang2023planning,zhou2024language}"
- Mutually Exclusive and Collectively Exhaustive (MECE): a decomposition where parts do not overlap and together cover the whole. "mutually exclusive, collectively exhaustive (MECE) subtask graph"
- Object store: a storage system for persisting intermediate artifacts outside of prompts for reuse. "are persisted to an object store"
- Orchestration: the control logic and protocols that coordinate planning, execution, and communication among agents. "hard-coded into prompts or orchestration logic"
- Plan--execute--aggregate loop: ROMA’s core control flow that decomposes tasks, executes leaves, and synthesizes results. "This plan--execute--aggregate loop is the sole control flow in ROMA"
- Prompt drift: unintended changes in model behavior due to accumulated or overly large prompt edits. "avoids prompt drift."
- Recursive LLMs (RLMs): models that can invoke themselves to perform recursive reasoning without an external meta-agent. "Recursive LLMs (RLMs)~\citep{zhang2025recursive}"
- Retrieval-augmented generation: techniques that integrate external evidence retrieval with generation to improve factuality. "specialized benchmarks for retrieval-augmented generation"
- Sandboxed runtime: an isolated environment for safely executing generated or user-provided code. "uses a sandboxed runtime to execute user- or model-generated code"
- Test-time scaling: improving performance by allocating more compute during inference via parallel or sequential strategies. "Test-time scaling methods show that allocating more compute"
- Typed input/output signatures: explicit type specifications for module interfaces to ensure compatibility and safety. "typed input/output signatures"
- Verifier: an automated check that validates proposals or outputs against task-specific constraints or tests. "Verifiers run fast, task-specific checks"
Practical Applications
Practical Applications of ROMA and GEPA+
Below is a structured analysis of actionable, real-world applications enabled by the ROMA framework (recursive, dependency-aware task decomposition with transparent aggregation) and the GEPA+ multi-component prompt optimization method. Applications are grouped into Immediate and Long-Term, with sector tags, prospective tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed with today’s models, tools, and infrastructure.
- Evidence-grounded web research and due diligence [Finance, Legal, Enterprise, Media]
- What it enables: Breaks complex research questions into MECE subtasks, retrieves conflicting or noisy web evidence in parallel, and synthesizes it with explicit, auditable aggregation (demonstrated gains on SEAL-0 and FRAMES).
- Potential tools/products/workflows:
- “ROMA Research Copilot”: a traceable research assistant that outputs source-cited reports and a hierarchical execution map.
- Competitive intelligence and vendor due-diligence reports with dependency-aware evidence reconciliation.
- Assumptions/dependencies:
- Reliable search APIs and permissioned access to content; adherence to data licensing and compliance policies.
- LLMs robust enough for retrieval synthesis; Aggregator prompt quality and verification checks affect factuality.
- Fact-checking and evidence synthesis for editorial workflows [Media, Academia, Policy]
- What it enables: Structured triangulation of claims across multiple sources with transparent execution traces that support editorial review.
- Potential tools/products/workflows:
- Newsroom fact-check pipelines that output structured claims, sources, contradictions, and a merge rationale.
- Academic literature triangulation assistants for systematic reviews.
- Assumptions/dependencies:
- Access to reliable corpora (news, journals); institutional sign-off on LLM-assisted verification.
- Clear policies for handling conflicting or low-quality sources.
- Long-form content planning and generation with quality control [Marketing, Publishing, Education]
- What it enables: Planner-driven outlines; type-specific Executors for “write/think/search”; Aggregator for coherence and compression. GEPA+ raises quality without model fine-tuning (EQ-Bench parity with leading closed models).
- Potential tools/products/workflows:
- “ROMA Writer” for blog posts, whitepapers, lessons, or narratives with chapter/section plans and per-section audits.
- GEPA+-powered PromptOps that iteratively improve tone/structure for a brand or domain.
- Assumptions/dependencies:
- Brand/style guidance and guardrails; editorial human-in-the-loop for final publication.
- Content policies for originality and attribution; costs tied to long-form token usage.
- Scientific ablation-study ideation and review support [Academia, R&D]
- What it enables: Decomposes a paper’s contributions and proposes structured ablations with importance/soundness improvements (AbGen results).
- Potential tools/products/workflows:
- “Ablation-Designer”: given a paper’s methods/results, returns prioritized ablations, controls, and expected outcomes with traceable rationale.
- Lab QA workflow that records planned changes and links to tracked experiments.
- Assumptions/dependencies:
- Domain context availability (papers, datasets); human oversight to validate feasibility/ethics.
- LLM-as-a-judge scoring and verifiers for sanity checks; may need domain-specific rule templates.
- Debuggable enterprise agents with audit-grade execution traces [Finance, Healthcare, Regulated industries]
- What it enables: Hierarchical, typed traces for planning, execution, and aggregation that can be logged, versioned, and inspected.
- Potential tools/products/workflows:
- “Agent Audit Trail” for compliance reviews, model risk management, and SOP alignment.
- Postmortem analysis tools that pinpoint failure nodes (planner vs. executor vs. aggregator).
- Assumptions/dependencies:
- Governance frameworks that accept structured LLM traces; secure storage for artifacts/logs.
- PII/PHI handling, redaction, and data residency controls.
- Retrieval-augmented analytics and report generation [Business Intelligence, Operations]
- What it enables: DAG-based decomposition over multiple data sources (docs, wikis, BI queries), with bottom-up aggregation into executive summaries or dashboards.
- Potential tools/products/workflows:
- KPI explainer that decomposes “why did metric X move?” into sub-analyses and composes an annotated report.
- Meeting-brief synthesizer with cited evidence and action lists.
- Assumptions/dependencies:
- Connectors to data warehouses/BI tools and access rights; MCP-compatible tool adapters.
- Sandbox safety for any code execution against production systems.
- Software engineering assistants for planning, code actions, and documentation [Software]
- What it enables: Task-type routing (code/write/think) and sandboxed
codeExecutors with MCP tools for linters, tests, and repo access. - Potential tools/products/workflows:
- Issue decomposers that produce minimal PRs with linked tests and change rationales.
- Architecture RFC generators with dependency-aware design steps and consolidated decisions.
- Assumptions/dependencies:
- Secure sandbox and repo/tool access; reliable unit/e2e test oracles to verify changes.
- Limits on tool invocation cost/latency for large repos.
- What it enables: Task-type routing (code/write/think) and sandboxed
- Customer support triage and resolution with knowledge bases [E-commerce, SaaS, Telecom]
- What it enables: Decomposes user issues, retrieves KB articles/logs, proposes steps, and aggregates fixes with traceability for handoff to agents.
- Potential tools/products/workflows:
- Triage bot that outputs structured RCA, repro steps, and candidate fixes; human agent reviews via trace.
- Assumptions/dependencies:
- Fresh KB and log access; guardrails to avoid unsafe instructions.
- Clear escalation protocols and deflection thresholds.
- Education: structured tutoring and study planning [Education, Consumer]
- What it enables: Planner creates topic trees and problem decompositions; Executors solve/guide; Aggregator produces summaries and practice plans.
- Potential tools/products/workflows:
- Course/unit planners, step-wise solution explainers, and error-analysis reports by node.
- Assumptions/dependencies:
- Curriculum alignment; pedagogical oversight to prevent misleading reasoning steps.
- Accessibility and fairness considerations for learners.
- PromptOps/AgentOps: GEPA+ for safe, multi-component prompt optimization [Software, MLOps]
- What it enables: Parallel proposal generation, judge+verifier reranking, and contract-preserving merges for Atomizer/Planner/Executor/Aggregator prompts.
- Potential tools/products/workflows:
- CI/CD gates for agents: regression suites, interface checks, and automatic prompt rollouts with rollback plans.
- Assumptions/dependencies:
- Budget and latency constraints for judges/verifiers; maintaining stability across updates.
- Dependence on LLM-as-a-judge quality and bias; test set representativeness.
- Evidence reviews for clinical guidelines (non-diagnostic support) [Healthcare]
- What it enables: Structured synthesis of clinical guidelines and studies with explicit citation and conflict resolution; audit-ready traces.
- Potential tools/products/workflows:
- Guideline overview digests for clinicians that highlight consensus vs. controversy and data gaps.
- Assumptions/dependencies:
- Strict non-diagnostic use and human oversight; medical safety policies and disclaimering.
- Access to up-to-date, licensed medical literature; strong verification prompts.
Long-Term Applications
These require further research, scaling, tooling, or standardization before broad deployment.
- Cost-/latency-aware heterogeneous model orchestration per role [AI Platforms, Cloud]
- What it enables: Dynamic assignment of different models/tools to Atomizer/Planner/Executor/Aggregator based on capability, price, and SLA, beyond single-base-model setups.
- Potential tools/products/workflows:
- Orchestrators that “route by role” and autoscale across providers with real-time health/quality signals.
- Assumptions/dependencies:
- Reliable cross-model calibration and guardrails; vendor-agnostic interfaces; monitoring for drift.
- Autonomous scientific workflows from hypothesis to experiment execution [Academia, Pharma, Materials]
- What it enables: ROMA DAGs spanning literature synthesis → hypothesis generation → code/execution steps → analysis → aggregation; tight loops with lab automation.
- Potential tools/products/workflows:
- “AutoLab Planner” integrating ELN/LIMS, simulators, and instrument APIs with safety interlocks.
- Assumptions/dependencies:
- Robust toolchains, physical lab integration, and strict safety oversight; validated evaluators beyond LLM judges.
- Policy analysis and decision support with auditable reasoning [Government, NGOs]
- What it enables: Transparent, dependency-aware policy briefs that synthesize conflicting evidence and quantify assumptions.
- Potential tools/products/workflows:
- Regulatory impact assessments that preserve data lineage and rationale per assumption.
- Assumptions/dependencies:
- Trusted datasets and provenance; formal inclusion of uncertainty and bias audits; public sector standards for AI documentation.
- Cross-modal task orchestration for embodied systems [Robotics, Industry 4.0]
- What it enables: Extending task decomposition to include perception/planning/control modules with verifiable pre-/post-conditions.
- Potential tools/products/workflows:
- High-level ROMA Planner delegating to motion planners and perception stacks; Aggregator verifies task completion and safety logs.
- Assumptions/dependencies:
- Reliable perception and control interfaces; real-time constraints; formal safety verification and certification.
- Formal verification hooks and process-level guarantees [Aviation, Healthcare, Autonomous Systems]
- What it enables: Verified contracts at each node (types, invariants, pre/post-conditions) with theorem-proving or property-checking augmenting Aggregators.
- Potential tools/products/workflows:
- “Verified Agent Pipelines” that gate deployment on passing formal checks on plan DAGs and artifacts.
- Assumptions/dependencies:
- Mature formal methods libraries for natural-language-to-spec translation; performance overhead budgets.
- Industry-wide schema standardization for agent traces and interfaces [Standards, Ecosystems]
- What it enables: Common ROMA-like typed interfaces for plans, subtasks, dependencies, and artifact stores to improve interoperability and benchmarking.
- Potential tools/products/workflows:
- Open schema/SDKs, trace viewers, and cross-vendor evaluation harnesses; agent trace exchange formats.
- Assumptions/dependencies:
- Community consensus across vendors; governance of versions and compliance tests.
- Edge/on-device agents using bounded aggregation for limited contexts [Mobile, IoT]
- What it enables: Hierarchical compression and localized Executors to fit small context windows and constrained compute.
- Potential tools/products/workflows:
- On-device personal assistants that schedule cloud offloads only for non-atomic or heavy tasks.
- Assumptions/dependencies:
- Efficient small models and distillation; privacy-preserving offload mechanisms; battery/latency budgets.
- Component marketplaces and reusable role libraries [Software Ecosystems]
- What it enables: Curated Atomizer/Planner/Executor/Aggregator modules for domains (law, healthcare, code, finance) with interface contracts and quality metrics.
- Potential tools/products/workflows:
- “Agent App Store” with plug-and-play modules, test suites, and GEPA+-compatible optimization packs.
- Assumptions/dependencies:
- Reputation systems, licensing, and security reviews; contract and schema stability.
- Data engineering/ETL and knowledge-graph construction via ROMA DAGs [Data Infra, Energy, Enterprise IT]
- What it enables: Decomposition of ingestion, normalization, entity resolution, and consistency checks with aggregation into schemas/graphs.
- Potential tools/products/workflows:
- Auto-curation pipelines that produce provenance-tagged KBs with periodic re-aggregation and drift alerts.
- Assumptions/dependencies:
- Robust tool connectors; strong validators for schema conformance; ops budgets for continuous runs.
- Personal “chief-of-staff” assistants orchestrating multi-step life admin [Consumer]
- What it enables: Travel planning, home projects, finance comparisons broken into parallel subtasks with summarized options and rationales.
- Potential tools/products/workflows:
- Planner-first assistants that maintain running traces and artifacts (itineraries, budgets, checklists).
- Assumptions/dependencies:
- Secure integration with calendars, email, and financial APIs; privacy controls and user consent.
Notes on Feasibility
- Performance and generalization: Reported gains are benchmark-based and may not uniformly transfer to high-stakes domains without domain-specific prompts, verifiers, and human oversight.
- Data access and compliance: Many applications depend on licensed data, enterprise permissions, and adherence to privacy/security policies.
- Tooling maturity: MCP connectors, sandboxed execution, and artifact stores must be production-hardened for regulated settings.
- LLM dependency: Quality, latency, and cost are sensitive to underlying model capabilities; heterogeneous orchestration and GEPA+ can mitigate but not remove this dependency.
- Evaluation bias: GEPA+ and some benchmarks rely on LLM-as-a-judge; bias and stability must be monitored and complemented with human or rule-based verification where feasible.
These applications reflect ROMA’s core strengths—recursive, dependency-aware planning; localized execution with bounded aggregation; transparent, typed traces; tool-centric execution; and GEPA+ for safe, multi-component optimization—mapped to concrete deployment opportunities across sectors.
Collections
Sign up for free to add this paper to one or more collections.