Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
Abstract: Harnesses have become a central determinant of coding-agent performance, shaping how models interact with repositories, tools, and execution environments. Yet automating harness engineering is hard: a heterogeneous action space, sparse and noisy evaluation signal, multi-million-token trajectories, and edits whose effect is hard to attribute to the next round's outcomes. We introduce Agentic Harness Engineering (AHE), a framework that automates harness-level evolution by instrumenting the three stages of any engineering loop (component editing, trajectory inspection, and decision making) with matched observability pillars: (1) component observability gives every editable harness component a file-level representation so the action space is explicit and revertible; (2) experience observability distills millions of raw trajectory tokens into a layered, drill-down evidence corpus that an evolving agent can actually consume; and (3) decision observability pairs every edit with a self-declared prediction, later verified against the next round's task-level outcomes. Together, these pillars turn every edit into a falsifiable contract, so harness evolution proceeds autonomously without collapsing into trial-and-error. Empirically, ten AHE iterations lift pass@1 on Terminal-Bench 2 from 69.7% to 77.0%, surpassing the human-designed harness Codex-CLI (71.9%) and the self-evolving baselines ACE and TF-GRPO. The frozen harness transfers without re-evolution: on SWE-bench-verified it tops aggregate success at 12% fewer tokens than the seed, and on Terminal-Bench 2 it yields +5.1 to +10.1pp cross-family gains across three alternate model families, indicating the evolved components encode general engineering experience rather than benchmark-specific tuning. These results position observability-driven evolution as a practical pathway to keep coding-agent harnesses continually improving.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making “coding agents” better at solving long, multi-step programming tasks. A coding agent is an AI that can read and edit code, run commands in a terminal, and fix issues in software. The authors focus on the “harness,” which is the surrounding setup that tells the agent what tools it can use, how to interact with files and the terminal, and how to remember important information. They propose a new way—called Agentic Harness Engineering (AHE)—to automatically improve this harness over time using clear, trackable evidence.
Objectives and Research Questions
The paper asks a simple but important question: How can we let an AI agent automatically improve all parts of its harness (not just the main prompt) in a stable, reliable way?
More specifically, it aims to:
- Make the agent’s “action space” clear: exactly what parts of the harness can be edited.
- Turn messy, very long logs of agent activity into useful evidence the agent can understand.
- Connect every harness edit to a prediction, then check whether that prediction came true later.
Methods and Approach (in everyday language)
Think of the harness as the agent’s gear and toolbox. AHE is like giving the agent:
- a clean parts list,
- a readable diary of what happened, and
- a scoreboard that checks whether changes help or hurt.
The approach has three “observability pillars”:
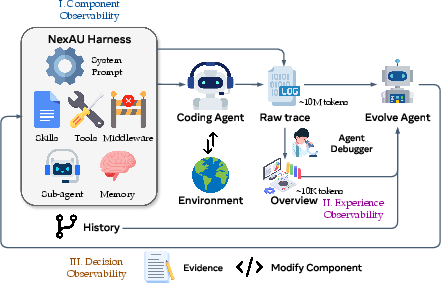
- Component observability: Every editable part of the harness (like the system prompt, tools, middleware, skills, long-term memory) is a separate file. This is like a labeled drawer for each tool—clear, trackable, and easy to undo if needed.
- Experience observability: Agent runs produce millions of tokens (basically very long chat logs). AHE distills these into a layered evidence pack: short summaries of what went wrong or right, plus drill-down access to the original logs. Think of it like turning an entire messy diary into a neat “case report” you can open if you need details.
- Decision observability: Every change to the harness comes with a short, written prediction: “This edit should fix tasks A and B; it might break task C.” In the next round, the system checks whether those predictions were true. If not, it can roll back that specific file. This is like signing a simple contract for each edit and testing it.
How the loop works (each iteration):
- Run the agent on the tasks.
- Clean and summarize the logs into evidence.
- Attribute which past edits helped or hurt and undo bad ones.
- Make new evidence-driven harness edits, each with a prediction.
- Save the edits and repeat.
Importantly, the base LLM is fixed. Only the harness changes, so improvements are clearly due to the harness, not a different model.
Main Findings and Why They Matter
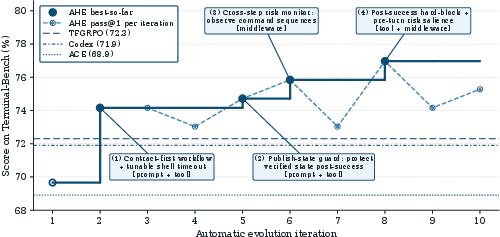
The authors tested AHE on a tough benchmark called Terminal-Bench 2 (lots of long terminal-based tasks). Results:
- Pass@1 (the fraction of tasks solved in one try) improved from 69.7% to 77.0% after ten AHE iterations.
- AHE beat both human-designed harnesses (like Codex-CLI at 71.9%) and other self-evolving approaches that mainly tune prompts.
- The improved harness “transferred” well:
- On SWE-bench-verified (another large set of real code tasks), it matched or exceeded the original setup while using fewer tokens (meaning less cost and faster runs).
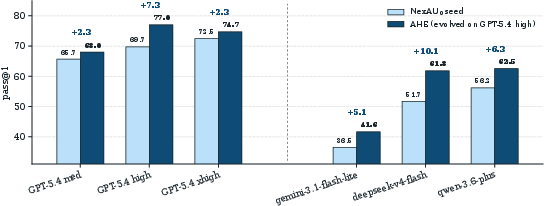
- It also gave positive gains across several different model families, especially for models that aren’t already very strong.
What carried the gains? Not the prompt alone. When they swapped individual parts into the original setup:
- Tools, middleware, and long-term memory each helped on their own.
- The system prompt alone actually made things slightly worse. This suggests that concrete, executable structure (like tools and memory) transfers better than just changing strategy text.
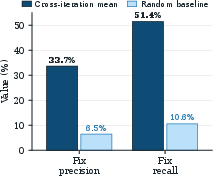
They also checked the reliability of the “prediction contracts”:
- The agent’s “this edit will fix these tasks” predictions were much better than random.
- But predicting which tasks might regress (get worse) was only slightly better than random, showing a blind spot that future work should improve.
Implications and Potential Impact
This research shows a practical way for coding agents to learn from experience at test time without changing the underlying model weights. By:
- Making every part of the harness explicit,
- Turning huge logs into useful evidence, and
- Treating each edit as a prediction you can verify,
AHE helps agents steadily improve and produce harnesses that generalize across tasks and model types. This could:
- Reduce the need for expensive manual harness design,
- Make agent behavior more auditable (you can see exactly what changed and why),
- Lower token costs by moving logic into tools/middleware rather than long prompts,
- Provide a safer path for continuous improvement through rollback and per-edit accountability.
The authors note limits: results are focused on specific benchmarks, regression prediction needs work, and the loop adds compute overhead. Still, AHE is a promising blueprint for keeping coding-agent harnesses improving over time in a controlled, evidence-driven way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Pillar-level causality: No ablation isolating each observability pillar (component, experience, decision) to quantify its standalone contribution and interactions.
- Statistical robustness: Single campaign results without multiple random seeds, confidence intervals, or significance testing for pass@1 and transfer gains.
- Rollout budget sensitivity: k=2 rollouts/task may be too low; no study of how larger k impacts stability, attribution accuracy, and final performance.
- Compute and cost accounting: Missing wall-clock, token, and hardware cost per phase (rollout, distillation, evolution) and cost–benefit comparisons to human/manual baselines.
- Regression prediction reliability: Low precision/recall for regression forecasts; no mechanism to proactively catch regressions (e.g., canary suites, counterfactual tests) before a full iteration.
- Interaction-aware evolution: Non-additive component effects cause Hard-tier regressions; no optimizer that models component interactions (e.g., factorial designs, BO over combinations).
- Timeout/step-budget coupling: Generalization depends on timeouts and step budgets tuned for one model; no method to auto-adapt budgets across bases/tasks.
- Evaluator/model bias: Agent Debugger and Evolve Agent share the same base model as the Code Agent; unclear how shared blind spots affect evidence quality and edit choices.
- Evidence validity: No human audit of debugger reports; need precision/recall against human-labeled root causes to calibrate trust in the distilled evidence.
- Granular attribution: Task-level pass/fail deltas are coarse; lacking micro-metrics (tool success rates, command failure taxonomies, diff quality) for causal attribution of edits.
- Guardrail adequacy: Although some surfaces are read-only, the harness could still attempt indirect shortcuts; no red-team tests or formal security audit of the governance layer.
- External validity: Evaluation centered on Terminal-Bench 2 and SWE-bench-verified; no tests on other domains (e.g., SWE-bench Pro, MLE-Bench, GUI/web agents, different languages/OSes).
- Environment portability: Unclear robustness of the evolved tools/middleware to OS, shell, and dependency variations; no portability stress tests.
- Baseline coverage: Missing comparisons to structure-search/evolution methods (e.g., program graphs, workflow search) and to expert human harness engineers under matched compute.
- Token/latency Pareto: Limited analysis of the accuracy–efficiency trade-off; no Pareto frontier or per-component token cost breakdown on Terminal-Bench 2.
- Long-term memory governance: No policies for growth, pruning, deduplication, or contamination control; unclear long-horizon effects on cost and stability.
- Edit granularity and rollback: Rollback is file-level but multi-file edits and merge conflicts are common; no study of partial rollback or conflict resolution strategies.
- Overfitting diagnostics: Need formal anti-overfitting protocols (hold-out task subsets, rolling-window eval, leave-one-repo-out) to detect benchmark-specific tuning.
- Hard-tier underperformance: Root causes of lag vs Codex on Hard tasks are hypothesized (redundant verifications) but not experimentally confirmed or mitigated.
- Predictive manifest design: Predictions are binary sets; no uncertainty estimates, effect-size forecasts, or learning-to-predict modules trained on iteration history.
- Hyperparameter sensitivity: No analysis of sensitivity to iteration count, component edit limits, cleaning heuristics, or explore-agent seeding choices.
- Human–agent complementarity: Missing study benchmarking AHE against, or in collaboration with, skilled human harness engineers (quality, speed, edit types).
- Reproducibility artifacts: Code is released, but full traces, manifests, and git histories for all iterations are not documented for third-party reproduction.
- Ethical and safety risks: Limited discussion of misuse, sandbox escape attempts, or unintended self-modifications; no systematic mitigation or monitoring plan.
- Theoretical framing: Lacks a formal model (e.g., POMDP/bandit over harness configurations) and any regret/convergence guarantees under reasonable assumptions.
Practical Applications
Immediate Applications
Below are deployable use cases that can be implemented now, leveraging the paper’s AHE framework (component/experience/decision observability), NexAU-style decoupled harnesses, and the Agent Debugger.
- Continuous improvement of enterprise coding agents (Software, LLMOps)
- Use AHE to automatically evolve prompts, tools, middleware, and long‑term memory for in-house code assistants, repo maintenance agents, and CI/CD bots based on production trajectories.
- Potential products/workflows: “HarnessOps CI” pipeline step that runs k‑rollouts on a representative task suite each sprint, distills evidence, proposes harness PRs with a change manifest, and auto‑rolls back failed edits.
- Dependencies/assumptions: Access to a decoupled harness (e.g., NexAU or equivalent), reproducible sandboxes and verifiers, version control for harness files, k≥2 rollouts per task to stabilize pass-rate signals, budget for iterative runs.
- Auditable self-modification for regulated agent deployments (Finance, Healthcare, Enterprise IT)
- Adopt “decision observability” by attaching a machine-readable change manifest to every harness edit with predicted fixes/regressions and per-edit rollback.
- Potential products/workflows: “Change Manifest Auditor” that gates promotion of harness versions across environments; compliance dashboards linking predictions to next-round outcomes.
- Dependencies/assumptions: Clear separation of writable surfaces (harness only) and protected surfaces (model, verifier, budgets); organizational policy for review/approval of changes.
- Agent Debugger–driven triage of long-horizon failures (QA/Test Automation, LLMOps)
- Deploy the layered evidence corpus to turn multi‑million‑token trajectories into per-task root-cause reports that engineers or evolve agents can act on.
- Potential products/workflows: An “Evidence Corpus Browser” in your observability stack; automatic issue filing with links to distilled evidence and raw trace drill-downs.
- Dependencies/assumptions: Instrumented tracing (message- and tool-level logs), file-based artifact store, light content cleaning to drop noise (e.g., base64).
- Token/cost reduction via structural harness changes (Software, Cloud)
- Encode reusable behavior in tools/middleware/memory rather than in prompts to cut per-call token usage while maintaining or improving success rates (as observed 12%–32% tokens/trial reduction in transfer).
- Potential products/workflows: “Prompt-to-Component Refactoring” service that lifts stable prompt logic into typed harness components.
- Dependencies/assumptions: Stable task surfaces with repeatable patterns; maintainable tool/middleware interfaces; monitoring to detect regressions.
- Cross-model/cross-project harness packs (Software Platforms, Model Providers)
- Package evolved “tool/middleware/memory” sets as reusable harness packs transferable across LLM families and projects (observed +5.1 to +10.1 pp cross-family gains).
- Potential products/workflows: “Harness Registry” with semver, dependency metadata, and compatibility notes; preflight tests for new models.
- Dependencies/assumptions: Versioned component APIs; portability tests across model families; governance for updates.
- IDE integration for personal coding assistants (Education, Daily Life)
- Local AHE “light” that runs on a user’s projects to evolve an assistant’s harness with audit logs, suggested edits, and one-click rollback in the IDE.
- Potential products/workflows: VS Code/JetBrains plugin to visualize component diffs, evidence summaries, and predicted impacts before acceptance.
- Dependencies/assumptions: Local sandboxing for safe execution; small curated task suite from user’s repo; compute/budget caps.
- Benchmarking and reproducible agent research (Academia)
- Use AHE to establish baseline harnesses for agent benchmarks, publish evolution histories, and run component-level ablations.
- Potential products/workflows: Public artifact bundles: seed harness, iteration tags, change manifests, evidence corpora; classroom labs on observability-driven agent optimization.
- Dependencies/assumptions: Open benchmark environments with verifiers; shared infrastructure for tracing and versioning; IRB/data policies for logs if proprietary code is involved.
- Failure-aware release gating (LLMOps/Platform Engineering)
- Integrate per-edit predicted regression sets into canary pipelines; hold back promotion when predicted-risk tasks overlap with critical paths.
- Potential products/workflows: “Risk Gate” that checks change manifests against org-specific critical-task lists; automatic suppression of high-risk edits.
- Dependencies/assumptions: Maintained mapping from benchmark tasks to production-critical workflows; acceptance criteria; human-in-the-loop oversight.
- Tooling ecosystems for agent harnesses (Software Vendors)
- Commercialize components: robust shell tools (command wrappers with contract hints), middleware finish hooks, and memory packs curated from observed failures.
- Potential products/workflows: Marketplace for “skill libraries” and “middleware adapters” that drop into decoupled harness frameworks.
- Dependencies/assumptions: Clear, stable component interfaces; security review of third-party tools; provenance metadata.
Long-Term Applications
These use cases require further research, scaling, or development (e.g., broader evaluations, stronger guardrails, or cross-domain adaptation).
- Fleet-level autonomous harness evolution (Enterprise, LLMOps)
- Run AHE across a portfolio of agents (coding, RPA, analytics) with shared evidence hubs; propagate proven component edits fleet-wide with staged rollouts.
- Potential products/workflows: “Enterprise Harness Manager” that learns cross-team patterns (e.g., CI/CD middleware) and pushes updates with domain-aware risk models.
- Dependencies/assumptions: Centralized telemetry and privacy-preserving aggregation; multi-environment promotion policies; robust regression prediction (currently weak).
- Risk-aware evolution with regression forecasting (Safety, Policy, Research)
- Extend decision observability to include calibrated uncertainty and counterfactual checks to address “regression blindness” observed in the paper.
- Potential products/workflows: Causal-attribution modules, shadow-testing against holdout tasks, Bayesian or conformal risk estimates in change manifests.
- Dependencies/assumptions: Larger, diverse task suites; causal/logging instrumentation; acceptance of slower iteration for safer updates.
- Cross-domain agent harness generalization (Healthcare, Finance, Energy, Robotics)
- Adapt observability-driven harness evolution to non-coding, long-horizon agents (e.g., claims processing, EHR RPA, grid dispatch, lab automation, robot task planning) where tools/middleware/memory play analogous roles.
- Potential products/workflows: Domain-specific toolchains (EHR extractors, compliance checkers, SCADA adapters), safety hooks, and verifiable evaluators for each vertical.
- Dependencies/assumptions: High-quality, auditable evaluators; sandboxed execution with strict guardrails; sector-specific compliance (HIPAA, SOX, NERC, ISO 10218/TS 15066 for robotics).
- Standards for auditable self-evolving agents (Policy, Standards Bodies)
- Develop open standards for harness manifests, observability schemas, and rollback requirements; define “writable surface” constraints for autonomous evolution in regulated contexts.
- Potential products/workflows: A “Harness Manifest Standard” and “Agent Observability Profile” for procurement/compliance; certification programs for self-evolving agent systems.
- Dependencies/assumptions: Multi-stakeholder working groups; alignment with existing AI risk management frameworks (e.g., ISO/IEC 42001, NIST AI RMF).
- Formal verification of harness edits (Research, Safety-Critical Software)
- Pair change manifests with formal properties (e.g., no side effects beyond workspace, invariant preservation) and mechanized checks in CI.
- Potential products/workflows: “Harness Contracts” expressed in policy DSLs; static analysis for tools/middleware; formal test generation to validate claims.
- Dependencies/assumptions: Formalizable component interfaces; decidable properties; developer tooling to align agents’ proposed changes with specs.
- Knowledge distillation from harness evolution (Academia, Tool Vendors)
- Extract generalized “engineering lessons” from successful memory/tool/middleware edits to train smaller agent components or guide foundation model finetuning.
- Potential products/workflows: Lesson banks, curriculum for agent training, synthetic tasks reflecting discovered failure modes and fixes.
- Dependencies/assumptions: Curated, de-duplicated corpora of manifests and outcomes; IP/privacy clearance; methodology for avoiding benchmark overfitting.
- Multi-objective harness optimization (Cost/Latency/Safety) (LLMOps, Cloud)
- Optimize harnesses jointly for success rate, tokens, latency, and safety interventions; learn Pareto-efficient configurations per environment.
- Potential products/workflows: “Pareto Harness Planner” that selects component sets conditioned on budget and risk tolerances; dynamic harness selection at runtime.
- Dependencies/assumptions: Rich telemetry including cost/latency; environment-aware evaluators; runtime policy engines.
- Human-in-the-loop governance at scale (Org Change, Policy)
- Build review tools where engineers approve or amend agent-proposed harness edits with traceable rationale; integrate with change management and incident response.
- Potential products/workflows: “Harness Review Board” workflows; auto-generated postmortems linking regressions to manifest predictions.
- Dependencies/assumptions: Organizational processes for AI change control; training for reviewers; integration with ticketing and incident systems.
- Robotic and embodied agent harnesses (Robotics, Manufacturing)
- Translate the decoupled harness pattern to sensor/tool adapters and safety middleware in robots; evolve non-parametric policies (skills, action wrappers) while the base policy/model is fixed.
- Potential products/workflows: Simulation-first AHE loops with high-fidelity evaluators; phased deployment with safety interlocks and compliance logging.
- Dependencies/assumptions: High-quality simulators; deterministic evaluation; extensive safety assurance; domain-specific failure taxonomies.
- Marketplaces and IP around evolved harnesses (Software Ecosystem)
- Commercial ecosystems selling or licensing evolved harness packs targeted to models, tasks, or sectors; support/update subscriptions.
- Potential products/workflows: Compatibility matrices, SLA-backed updates, telemetry-driven customization.
- Dependencies/assumptions: Clear licensing/IP for harness artifacts; compatibility testing infrastructure; trust and security vetting.
These applications draw directly from the paper’s innovations: (1) component observability via decoupled, file-level harnesses; (2) experience observability through layered trajectory distillation; and (3) decision observability with self-declared, falsifiable change manifests and per-edit rollback. Feasibility hinges on reproducible evaluation, clear separation of writable surfaces, adequate telemetry, and governance to manage regressions and prevent benchmark-specific tuning.
Glossary
- Action space: The set of possible actions an agent can take in its environment or over its editable components. "so the action space is explicit and revertible;"
- Agent Debugger: A framework/agent used to analyze rollout trajectories and produce structured, per-task reports. "we apply Agent Debugger~\citep{linAgentDebuggerUnderstanding2026} framework to use an agent to explore trajectories framed as a navigable, file-based environment"
- Agent-computer interfaces: Interfaces that allow agents to interact with software environments (e.g., files, repos, shells) in a controlled way. "custom agent-computer interfaces for repository navigation, file editing, and command execution"
- Agentic Harness Engineering (AHE): A framework that automates the evolution of coding-agent harnesses using observability across components, experience, and decisions. "We introduce Agentic Harness Engineering (AHE), a framework that automates harness-level evolution"
- Attribution: The process of linking observed outcome changes to specific prior edits or decisions. "Attribution runs before distillation, so its verdict lands inside the evidence corpus and binds each prior manifest entry as a contract rather than a rationale."
- Change manifest: A structured record pairing each harness edit with its evidence and a testable prediction. "via a change manifest that pairs every edit with a self-declared prediction"
- Closed loop: An iterative process where outputs of one phase feed back into the next, enabling continuous improvement. "AHE turns harness optimization into a closed loop driven by another agent,"
- Component ablation: An analysis method where individual components are isolated or swapped to quantify their contribution. "A component ablation pinpoints where this gain lives: tools, middleware, and long-term memory each carry the improvement on their own"
- Component observability: Making each editable harness component explicitly visible and manipulable (e.g., as files) for clear analysis and control. "component observability gives every editable harness component a file-level representation"
- Cross-family gains: Performance improvements that hold across different model families rather than only within one. "it yields +5.1 to +10.1\,pp cross-family gains across three alternate model families"
- Cross-model transfer: Reusing a harness evolved with one model on different models without additional evolution. "Cross-model transfer on terminal-bench-long-time, 89 tasks."
- Decoupled harness substrate: A harness design where components are loosely coupled and exposed as separate files to ease targeted edits. "a decoupled, file-level harness substrate that maps each failure pattern to a single component class."
- Decision observability: Recording and later verifying the predicted effects of each edit to make decisions auditable. "decision observability pairs every edit with a self-declared prediction, later verified against the next round's task-level outcomes."
- Drill-down evidence corpus: A structured, layered store of distilled trajectory data that supports progressively deeper analysis. "a layered, drill-down evidence corpus distilled from millions of raw trajectory tokens"
- Evolve Agent: The agent that reads evidence, proposes and applies harness edits, and records predictions for verification. "The Evolve Agent closes the AHE loop."
- Evidence ledger: The structured record (from the change manifest) that links edits to evidence and predictions. "this manifest is the loop's evidence ledger"
- Experience observability: Representing and organizing trajectory experience so it’s consumable and actionable by agents. "experience observability via a layered, drill-down evidence corpus"
- Falsifiable contract: A commitment where each change includes a prediction that the next evaluation can confirm or refute. "turn every edit into a falsifiable contract,"
- Finish-hook: A middleware hook triggered at the end of runs to enforce or verify closure conditions. "Middleware adds a finish-hook that forces one evaluator-isomorphic closure check;"
- Git history: The version-controlled record of edits enabling diffs and rollbacks at file granularity. "Each logical edit becomes one commit on the workspace's git history,"
- GRPO: Group Relative Policy Optimization; an RL method for optimizing policies relative to group performance. "TF-GRPO is a trajectory-feedback variant of GRPO that reinforces successful tool sequences;"
- Harness: The surrounding system (prompts, tools, middleware, memory, etc.) that mediates an agent’s interaction with its environment. "a substantial surrounding harness"
- High reasoning setting: A model configuration favoring deeper reasoning, used here across roles for consistency. "GPT-5.4 at the high reasoning setting."
- In-context playbook: A structured set of instructions/examples injected into the prompt to guide agent behavior without code changes. "or an in-context playbook"
- Layered evidence corpus: A multilevel representation of distilled trajectory data for scalable consumption by agents. "a layered, drill-down evidence corpus distilled from millions of raw trajectory tokens"
- Long-horizon: Tasks requiring many steps or extended interactions to complete. "long-horizon software-engineering tasks,"
- Long-term memory: A persistent component where agents store reusable knowledge or lessons across tasks. "tools, middleware, and long-term memory each carry the improvement on their own"
- Middleware: The execution-time layer that mediates or augments interactions between the agent and tools/environment. "tools, middleware, and long-term memory each carry the improvement on their own"
- Mutation: Evolutionary changes applied to programs or agents to explore improved configurations. "scored program and agent archives evolved through mutation,"
- NexAU framework: The underlying agent framework used to instantiate the editable harness with explicit component files. "We instantiate the harness on the NexAU framework,"
- Observability pillars: The triad of component, experience, and decision observability that enables stable, auditable evolution. "a closed loop driven by three observability pillars:"
- Orchestration support: Infrastructure that coordinates tools and processes to ensure reproducible long-horizon runs. "sandboxed execution and orchestration support that keep long-horizon runs reproducible"
- Pareto-frontier traces: Trajectory data emphasizing trade-offs along a Pareto frontier used to drive reflective updates. "reflective updates driven by Pareto-frontier traces"
- Pass@1: Metric measuring the proportion of tasks solved on the first attempt (per trial). "ten AHE iterations lift pass@1 on Terminal-Bench 2 from 69.7\% to 77.0\%"
- Progressive disclosure: Providing information in layers so agents can request more detail only as needed to save tokens. "All of these content is provided as files allowing progressive disclosure"
- Prompt-only self-evolution: Optimization approaches that modify prompts/playbooks but not the broader harness components. "Prompt-only self-evolution misses the components that carry AHE's gain."
- Reasoning budget: Limits on the amount of model “thinking” (e.g., steps or tokens) allowed during runs. "raising the reasoning budget,"
- Rollback: Reverting changes that do not meet predicted outcomes, generally at file or component granularity. "which yields file-level diffs and rollback granularity for free."
- Rollout: Executions of tasks using the current harness and model to generate trajectories for evaluation and analysis. "We run rollouts per task so each task carries a pass-rate signal"
- Sandboxed execution: Running code or commands in an isolated environment for safety and reproducibility. "sandboxed execution and orchestration support that keep long-horizon runs reproducible"
- Self-evolving baselines: Automated methods that iteratively refine agents/harnesses without human intervention. "surpassing the human-designed harness Codex-CLI (71.9\%) and the self-evolving baselines ACE and TF-GRPO."
- Semantic-advantage priors: Prior knowledge structures that bias agent behavior toward semantically advantageous actions. "semantic-advantage priors"
- Skill: A reusable capability module or script integrated into the harness for specific tasks. "skill"
- Sub-agent configuration: Settings for auxiliary agents within the harness architecture. "sub-agent configuration"
- System prompt: The top-level prompt that provides general instructions and role framing to the agent. "system prompt"
- Tool description: The textual specification of a tool’s purpose and interface within the harness. "tool description"
- Tool implementation: The executable code that realizes a tool’s behavior within the harness. "tool implementation"
- Tokens/trial: The average number of tokens consumed per trial across all model calls. "tokens/trial, the mean per-trial total of prompt plus completion tokens across all LLM calls, in thousands."
- Trajectory: The sequence of messages, tool calls, and observations produced during an agent’s rollout. "distills millions of raw trajectory tokens into a layered, drill-down evidence corpus"
- Verifier: The component that checks whether a task is completed correctly, preventing shortcuts or cheating. "disabling the verifier,"
- Workspace: The editable directory containing the harness components, tracked via version control for audits and rollbacks. "the Evolve Agent writes only inside the harness workspace"
Collections
Sign up for free to add this paper to one or more collections.

