Recursive Agent Optimization
Abstract: We introduce Recursive Agent Optimization (RAO), a reinforcement learning approach for training recursive agents: agents that can spawn and delegate sub-tasks to new instantiations of themselves recursively. Recursive agents implement an inference-time scaling algorithm that naturally allows agents to scale to longer contexts and generalize to more difficult problems via divide-and-conquer. RAO provides a method to train models to best take advantage of such recursive inference, teaching agents when and how to delegate and communicate. We find that recursive agents trained in this way enjoy better training efficiency, can scale to tasks that go beyond the model's context window, generalize to tasks much harder than the ones the agent was trained on, and can enjoy reduced wall-clock time compared to single-agent systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to train AI “agents” (smart programs powered by LLMs) to split big problems into smaller pieces and ask fresh copies of themselves to solve those pieces. This is called a recursive agent, like a team where each member can spin up mini-teams as needed. Their training method is called Recursive Agent Optimization (RAO). The goal is to help agents handle very long, complex tasks by using divide-and-conquer, fresh memory for each sub-task, and parallel work.
What questions are the researchers trying to answer?
- How can we train an AI agent to decide when to split a task, what sub-tasks to create, and how to combine the results?
- Can training specifically for recursion make agents solve longer, harder problems—especially ones that don’t fit in the model’s limited “short-term memory” (context window)?
- Does this approach help agents learn faster, generalize to harder tasks, and sometimes run faster in real time by doing work in parallel?
How does their method work?
Recursive agents in plain terms
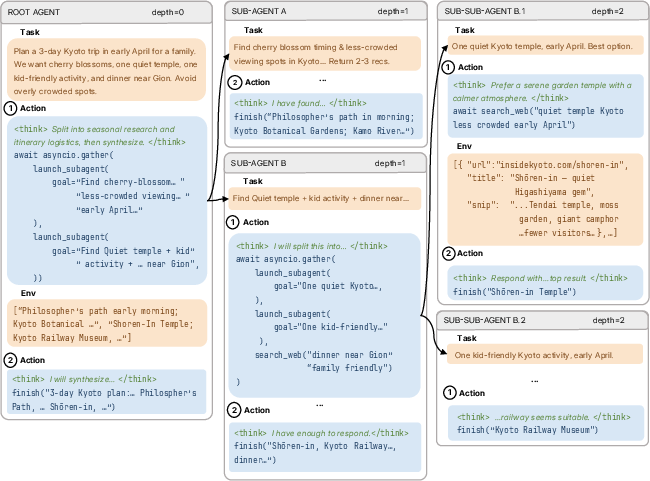
Imagine you’re asked to plan a complex trip. Instead of doing everything yourself, you:
- Break the job into smaller parts (flights, hotels, sights).
- Ask a helper (a copy of you) to handle each part.
- If one part is still big (e.g., “find the best sights”), that helper can create more helpers to research neighborhoods, opening hours, and ticket prices.
- You then collect the results and build the final plan.
That’s a recursive agent: the agent can launch sub-agents (copies of itself) with fresh, uncluttered “notebooks” (new context windows). This avoids running out of space when tasks are long.
In the code, the agent works in a small Python environment (a “REPL”) and can call a special function like launch_subagent(...) to start a sub-agent. Sub-agents can run one after another or at the same time (concurrently) when tasks are independent. Parents can tell children exactly what to do and what format to return.
Training them to be good at delegation (RAO)
The key is to teach the agent not just to solve tasks but also to use delegation wisely. RAO adds a simple “grading” system for each node (each agent copy) in the delegation tree:
- Local success: Did this node solve the sub-task it was given?
- Delegation bonus: Did the sub-tasks it created succeed?
This encourages smart delegation without rewarding the agent for just spawning lots of children. Think of it like grading a team lead on their own work plus how well their team did, but measuring quality, not team size.
To train fairly and stably, RAO also:
- Trains one shared model across all levels (root agent and all sub-agents are the same policy), so the model learns to handle both solo work and delegation.
- Compares performance within small groups of runs to reduce randomness (a simple “baseline” trick in reinforcement learning).
- Balances updates from different depths (root vs. deep sub-tasks) so training doesn’t get skewed toward whichever level produces the most data.
In simple terms: the agent practices solving trees of sub-tasks, gets feedback at every level, and learns a natural curriculum (easy sub-parts often appear when breaking hard tasks), which speeds up learning.
What did they test, and what happened?
They tested on three kinds of tasks:
1) TextCraft-Synth (like crafting in Minecraft, but text-based)
- The agent crafts a target item by chaining recipes (deep, branching steps).
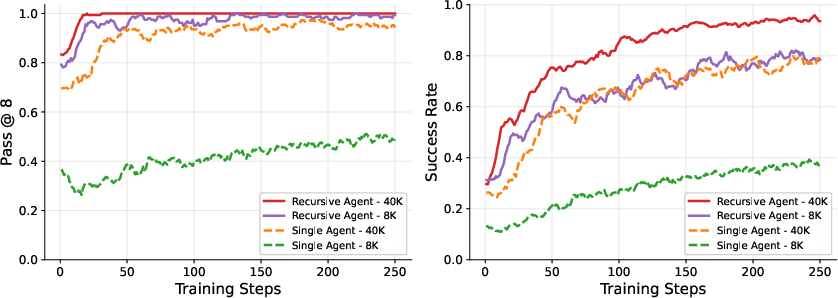
- Results: The recursive agent crushed hard tasks, even when its context window was tiny (8K tokens). For example, on hard problems, the recursive agent succeeded about 88% of the time, while the non-recursive “single agent” baseline got around 0–20% depending on setup.
- Speed: On harder tasks that can be split into independent parts, recursion was up to about 2.5× faster in wall-clock time because it could run sub-agents in parallel.
Why it matters: This shows recursion can beat “memory limits,” handle deeper tasks, and even run faster by parallelizing.
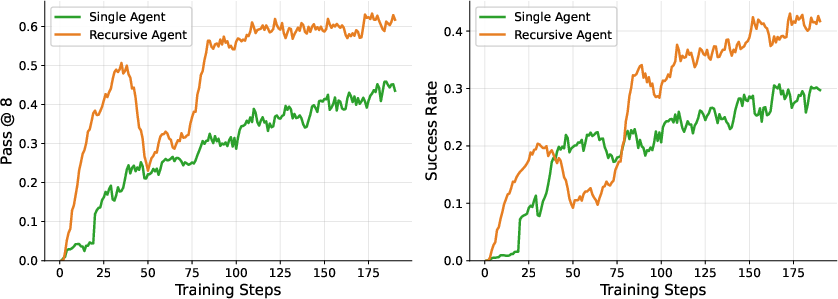
2) Oolong-Real (answering questions about very long Dungeons & Dragons logs)
- Inputs are very long (55K–175K tokens), longer than the 32K training memory limit.
- Results: The recursive agent scored much higher on average because it split the huge text into chunks and delegated reading to sub-agents with fresh memory. The single agent often relied on quick-but-weak tricks (like simple string matching) because it couldn’t fit the whole text, making it fast but inaccurate.
- Note: The recursive approach was slower here because it actually read the content; the single agent was faster but missed many answers.
Why it matters: Recursion helps handle real-world long documents that don’t fit in memory.
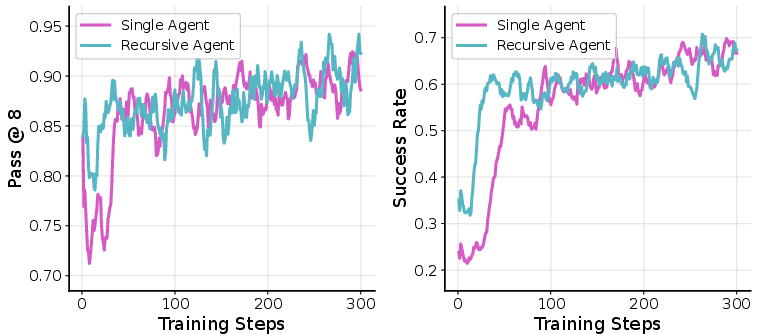
3) DeepDive (deep research questions requiring multi-step web searches)
- The agent must plan a chain of dependent searches and synthesize results.
- Results: The recursive agent solved more questions (about 40% vs. 24%). It tended to use deeper delegation for harder questions—a sign it adapts its effort to task difficulty.
- Speed: Slower overall, because these tasks are mostly sequential (you must finish step A before B), so parallelization doesn’t help much.
Why it matters: Recursion helps with planning and multi-step reasoning, even when parallel speed-ups aren’t possible.
Extra: What design choices mattered?
When the agent got feedback at every level (local success for sub-agents) and the training balanced different depths, it learned faster and got better results. This supports the idea that “dense” feedback and careful training setup are important.
Why is this important?
- Bigger problems, better memory use: Recursive agents can handle tasks far longer than their built-in memory by giving each sub-agent a fresh slate.
- Divide-and-conquer that transfers: The model learns a general strategy (break down, delegate, combine) that works on harder tasks than it was trained on.
- Smarter use of compute: On parallel-friendly tasks, recursion can cut real-world time by spreading work across sub-agents.
- Faster learning: Training with RAO provides lots of useful, structured feedback, so agents improve more quickly.
- Practical impact: This could make AI assistants better at coding projects, research, reading long logs or documents, and other complex workflows.
Bottom line and future directions
The main lesson is simple: don’t just wrap a model in a fancy execution scaffold at test time—train it to use that scaffold well. RAO shows that teaching agents to delegate, coordinate, and recombine results unlocks:
- Higher success on tough tasks
- The ability to work beyond memory limits
- Better generalization to harder problems
- Parallel speed-ups when possible
Next steps include:
- Measuring not just accuracy, but how efficiently agents spend computation
- Mixing different models in the tree (e.g., big verifier model plus small specialist workers)
- Building generalist recursive agents that transfer delegation skills across domains
- Designing better training shortcuts when full recursive rollouts are too expensive
In short, RAO is a practical way to make AI agents act more like effective teams: they plan, split, delegate, and reunite the pieces into strong answers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following issues unresolved; addressing them would make RAO more robust, scalable, and broadly applicable.
- Theory of recursive policy optimization: No convergence, regret, or sample-complexity guarantees under the non-stationary, policy-induced task distributions D_d(θ); characterize when RAO converges and how variance scales with tree depth/branching.
- Delegation bonus design: λ is set heuristically (0 or 0.4) without sensitivity analysis or adaptive tuning; study schedules/learned λ, detect and prevent over-/under-delegation, and test for reward hacking via delegating trivial subtasks.
- Credit assignment beyond immediate children: The reward only credits success of direct children; investigate multi-level/path-based credit propagation (e.g., subtree returns, value decomposition) and its effect on learning decomposition quality.
- Baselines and critics: The root-group leave-one-out baseline is acknowledged as not variance-optimal; compare against per-depth baselines, learned critics/value functions, and control variates tailored to tree-structured rollouts.
- Depth-level weighting: The inverse-frequency scheme lacks theoretical justification and broad ablation; evaluate alternative weighting/normalization (e.g., target depth ratios, temperature-based reweighting) under skewed subtree sizes.
- Training stability under non-stationarity: D_d(θ) shifts as the policy changes; explore replay/importance sampling, partial off-policy corrections, or curriculum scheduling to stabilize learning across depths.
- Compute-efficient training surrogates: Full recursive rollouts are costly; develop and evaluate surrogate procedures (partial-tree rollouts, shallow-to-deep curriculum, iterative deepening), and distillation from recursive to compact policies.
- Termination and compute budgeting: Depth and step limits are hard caps; learn explicit stop/delegate actions under cost/latency budgets and optimize joint objectives trading accuracy versus compute.
- Wall-clock vs accuracy trade-offs: Systematically chart Pareto fronts; design techniques to speed sequential tasks (e.g., caching/summarization, batching tool calls) that saw large slowdowns (e.g., 18× on DeepDive).
- Systems scaling and determinism: Async execution is limited to Python asyncio; study distributed schedulers, determinism/reproducibility under concurrency, straggler mitigation, and end-to-end throughput/latency on multi-node setups.
- Reliability of subtask supervision: LLM-judge–based subagent rewards are unvalidated; quantify judge error/calibration, leakage biases, and their impact on policy learning; compare to learned verifiers and human-labeled subsets.
- Verifier learning and robustness: Train task-specific verifiers with uncertainty estimates and ensemble agreement; evaluate robustness to adversarial subtasks and noisy labels, and propagate verifier uncertainty into RAO updates.
- Subagent API design: Only one launch_subagent(goal, …) schema is explored; ablate typed schemas, structured I/O (JSON schemas/contracts), and tool-capability declarations on decomposition quality and aggregation reliability.
- Aggregation learning: Parent synthesis of child outputs is not explicitly evaluated; develop metrics (faithfulness, coverage, conflict resolution) and train aggregation strategies (e.g., critique-and-revise, majority/weighted voting).
- Decomposition quality metrics: Define and track granularity, overlap, redundancy, and depth appropriateness of subtasks; correlate with success, cost, and generalization to guide training and debugging.
- Generalization across heterogeneous subproblems: Most subtasks resemble smaller instances of the parent; evaluate and train on rollouts mixing qualitatively different roles (retrieval, coding, verification, debugging) within one tree.
- Heterogeneous agent hierarchies: RAO trains a single shared policy; explore mixed-strength/specialist subagents, teacher–worker and verifier–worker patterns, and learned routing among heterogeneous nodes.
- Scaling depth and breadth: Oolong is limited to depth 2 and TextCraft to ≤12 at eval; characterize performance/failure modes at larger depths/branching (looping, fragmentation, context thrashing) and design safeguards.
- Non-decomposable/tightly coupled tasks: Identify regimes where recursion harms performance; learn when not to delegate and penalize unnecessary delegation; study adaptive switching between flat and recursive strategies.
- Safety and governance: No analysis of recursion-specific risks (runaway spawning, prompt injection propagation, tool misuse); define resource caps, sandboxing, escalation/approval gates, and audit logs for recursive chains.
- External memory and retrieval: Subagents mostly pass raw strings; evaluate shared external memory (vector DBs, key–value caches, scratchpads) across subagents versus deeper delegation for long dependencies.
- Baseline breadth: Compare RAO to Tree-of-Thought, hierarchical planners/options (HIRO/MAXQ), process-supervised RL, and SFT/DPO on recursive traces under matched compute.
- Hyperparameter sensitivity: Systematically study sensitivity to depth/branching caps, concurrency caps, context window, rollout group size G, and per-node step limits; provide auto-tuning or adaptive control.
- Cost and data efficiency reporting: Report token usage, GPU-hours/API costs, and sample efficiency versus single-agent RL and SFT; analyze cost per unit of performance gain.
- Reproducibility and dependencies: Results rely on proprietary services (Tinker, GPT-5-mini judge, Tavily); provide open-source substitutes, full prompts/configs, seeds, and multi-run variance to ensure reproducibility.
- Formalizing curriculum effects: The claimed self-induced curriculum is not quantified; model when policy-induced subtask distributions help or collapse, and how to regularize them toward desirable curricula.
- Diagnostic error analysis: Provide a taxonomy of decomposition/aggregation failures (mis-specified goals, redundant children, aggregation errors) and targeted training or scaffold interventions for each class.
- Resource-aware delegation: Train policies that condition delegation on real-time compute/latency/tool-cost constraints and evaluate responsiveness to changing budgets at inference time.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage RAO’s recursive delegation and training approach today. Each item notes relevant sectors, plausible tools/products/workflows, and feasibility conditions.
- Long-document QA and summarization at enterprise scale
- Sectors: software, knowledge management, legal, finance, customer support
- What it does: Answer questions over or synthesize insights from documents that exceed model context limits by chunking content and delegating sub-analyses to parallel sub-agents, then aggregating results.
- Potential tools/products/workflows: “Recursive Document Analyst” that uses a Python REPL harness, async sub-agent calls, vector stores/RAG, and an LLM judge for sub-answer quality; integrations with SharePoint/Google Drive, eDiscovery tools (Relativity, Disco), and knowledge bases (Confluence, Notion).
- Assumptions/dependencies: Reliable chunking/splitting, access controls for sensitive docs, quality of LLM-based subtask judges, adequate compute/concurrency budget, long-context inference available at deployment.
- Log analysis and incident triage for DevOps/SRE
- Sectors: software/DevOps
- What it does: Split large logs by service/time/window, have sub-agents run pattern detection and heuristics, aggregate root-cause hypotheses faster than a single agent.
- Potential tools/products/workflows: “Recursive Log Triage Bot” integrated with ELK/Datadog/CloudWatch; asyncio-based parallel execution; sub-agent unit tests for regex/heuristics; ticket creation via Jira/ServiceNow.
- Assumptions/dependencies: Secure sandboxed code execution, access to observability stacks, cost controls for bursty parallelism, robust post-hoc validation to prevent hallucinated diagnoses.
- Codebase-wide refactoring and migration assistants
- Sectors: software engineering
- What it does: Decompose large refactors (e.g., API migrations, monolith-to-service changes) into module-level subtasks executed concurrently; aggregate changes and run tests at the root.
- Potential tools/products/workflows: “Recursive Refactor Assistant” with repo checkout, static analysis, launch_subagent per module, and CI integration (GitHub Actions/GitLab CI); test-driven verification as node-local rewards.
- Assumptions/dependencies: Deterministic test suites, safe code execution environment, guardrails for commit quality, developer-in-the-loop approvals.
- Multi-source research assistants (deep web research, due diligence)
- Sectors: education, R&D, policy, finance, consulting
- What it does: Break complex queries into sub-questions, parallelize retrieval/synthesis across sources, and verify claims before aggregation.
- Potential tools/products/workflows: “Parallel Research Assistant” using web search APIs (e.g., Tavily), per-subquery sub-agents, citation tracking, and LLM judges for sub-answers; knowledge graphs for grounding.
- Assumptions/dependencies: API quotas/rate limits for search, claim verification heuristics, prompt security, provenance tracking.
- Compliance, contract, and regulatory scanning
- Sectors: legal, finance, policy, procurement
- What it does: Split large corpora of contracts/filings into sections, have sub-agents detect clauses/risk flags, aggregate a compliance report with supporting excerpts.
- Potential tools/products/workflows: “Recursive Compliance Scanner” with clause detectors, policy-specific rule libraries, and structured outputs; work queue (Ray/Celery) for parallelism; dashboards for execution-tree review.
- Assumptions/dependencies: High-precision clause verification, handling of confidential data, calibrated risk thresholds, defensible audit trails.
- Customer support case resolution and knowledge base triage
- Sectors: customer support/CRM
- What it does: Decompose a ticket into components (history, KB, logs), parallelize lookups and summarization, surface probable resolutions faster than single-agent flows.
- Potential tools/products/workflows: Integrations with Zendesk/Salesforce; KB chunking; sub-agents specialized on different data sources; root aggregation into suggested replies.
- Assumptions/dependencies: Data access and privacy compliance, guardrails against hallucinations, human agent supervision.
- Structured report generation with parallel drafting
- Sectors: business operations, consulting, product management
- What it does: Sub-agents draft sections (exec summary, market, tech, finance) concurrently; root agent merges and harmonizes tone/style.
- Potential tools/products/workflows: Templates + sub-agent style guides, linters, and LLM judges for section completeness; collaborative review UI.
- Assumptions/dependencies: Consistency checks across sections, alignment with brand voice, editorial oversight.
- Education: rubric-aligned grading/feedback for long assignments
- Sectors: education/EdTech
- What it does: Split grading by rubric criteria (e.g., content, structure, citations), run sub-agents per criterion, combine into holistic feedback.
- Potential tools/products/workflows: LMS integrations (Canvas/Moodle), criterion-specific judges, plagiarism checks; calibration against human graders.
- Assumptions/dependencies: Fairness and bias monitoring, human moderation, vetted rubric verifiers.
- Data labeling QA in ML pipelines
- Sectors: ML/AI platforms
- What it does: Sub-agents check subsets of labels against rules or weak-labelers; root aggregates quality metrics and proposes fixes.
- Potential tools/products/workflows: Labeling platforms (Labelbox, Snorkel); asynchronous QA sub-agents; node-local rule-based rewards for errors corrected.
- Assumptions/dependencies: Clear labeling policies, cost controls for iterative passes, measurable QA metrics.
- Personal productivity assistants (e.g., trip planning, home projects)
- Sectors: consumer apps
- What it does: Break plans into subtasks (flights, lodging, activities), parallel search, and schedule integration; the paper presents travel-planning examples.
- Potential tools/products/workflows: Calendar/email APIs, booking meta-search, personal knowledge bases, aggregation with preference constraints.
- Assumptions/dependencies: API access and consent, price/availability volatility, preference elicitation.
- Training recipe for domain-specific recursive agents
- Sectors: AI/ML teams in any industry
- What it does: Fine-tune in-house LLM agents with RAO—use node-local rewards (exact or LLM-judged), delegation bonuses when needed, depth-level inverse-frequency weighting, and leave-one-out baselines.
- Potential tools/products/workflows: RL pipelines on GPU clusters, Python REPL harness with async, evaluator services for subtask scoring; templated prompts and verifiers per domain.
- Assumptions/dependencies: Access to domain verifiers or high-quality LLM judges, budget for RL fine-tuning, safe sandboxing for tool execution.
Long-Term Applications
These opportunities build on RAO’s principles but likely require additional research, scaling, or ecosystem maturity.
- Heterogeneous agent swarms (coordinators + specialized workers)
- Sectors: software, enterprise AI platforms
- Vision: Larger coordinators delegate to smaller, specialized sub-agents (retrieval, verification, coding) to improve cost-performance.
- Dependencies: Stable multi-model orchestration, trust calibration among agents, cross-model prompt protocols, robust verifiers.
- Compute-aware and SLA-bound adaptive delegation
- Sectors: enterprise software, cloud platforms
- Vision: Agents learn to trade off accuracy and latency by adapting depth/branching to SLAs and budgets (e.g., “fast mode” vs “thorough mode”).
- Dependencies: New metrics combining success and compute cost, scheduler integration, policy constraints, real-time monitoring.
- Generalist recursive agents that transfer decomposition skills across domains
- Sectors: general AI, enterprise automation
- Vision: Train on mixed domains so the agent learns reusable patterns for splitting, verifying, and aggregating tasks.
- Dependencies: Cross-domain datasets with subtask verifiers, scalable training with surrogate rollouts, curriculum strategies.
- Hierarchical safety and oversight (verifier chains)
- Sectors: regulated industries
- Vision: Dedicated oversight sub-agents verify facts, policies, and safety norms at each level before outputs propagate upward.
- Dependencies: Domain-validated checkers, formal verification hooks where applicable, robust escalation paths to humans.
- Robotics and embodied agents with language-based hierarchical planning
- Sectors: robotics, manufacturing, logistics
- Vision: Natural-language planners decompose long-horizon tasks into skill-level subtasks for control policies; recursive verification of preconditions.
- Dependencies: Reliable low-level controllers, simulation-to-real transfer, safety interlocks, temporal abstraction alignment.
- Ultra-long EHR summarization and care-plan synthesis
- Sectors: healthcare
- Vision: Aggregate across years of patient records, labs, and notes via delegated sub-agents; synthesize care plans with evidence.
- Dependencies: HIPAA/GDPR compliance, clinically validated verifiers, human clinicians in the loop, liability management.
- Regulatory impact analysis and public policy synthesis at scale
- Sectors: government, public policy, legal
- Vision: Split a bill or regulation into clauses, delegate analysis of economic, legal, and operational impacts to specialized sub-agents, synthesize stakeholder-ready briefs.
- Dependencies: High-fidelity legal NLP, provenance and chain-of-custody, adversarial robustness to biased sources.
- Autonomous data engineering pipelines (schema mapping, transformations, QA)
- Sectors: data engineering/analytics
- Vision: Sub-agents handle schema inference, transformations, data quality checks, and lineage tracking concurrently; root agent orchestrates end-to-end ETL.
- Dependencies: Access to data stores, declarative transformation specs, unit tests for data quality, staging/sandbox environments.
- Large-scale software maintenance across monorepos and ecosystems
- Sectors: software engineering
- Vision: Dependency upgrades, security patching, and API deprecations coordinated via recursive delegation across repos/orgs.
- Dependencies: Organization-wide CI/CD, cross-repo dependency graphs, standardized code quality gates, approval workflows.
- Scientific discovery workflows (literature → hypotheses → experiments → analysis)
- Sectors: academia, pharma, materials
- Vision: Recursive decomposition across stages with verification agents for data quality and claim consistency, enabling “AI RAs” to scale lab throughput.
- Dependencies: Access to instruments/lab APIs, data integrity checks, reproducibility standards, IP and ethics compliance.
- FOIA-scale and archival processing with provenance
- Sectors: government transparency, journalism
- Vision: Process millions of pages by sharding into sub-agents, extracting entities/events, and building timelines with explicit provenance chains.
- Dependencies: Provenance-preserving pipelines, quality audits, secure handling of sensitive documents.
- Serverless “micro-agent” marketplaces
- Sectors: cloud/DevOps
- Vision: Each subtask is executed by ephemeral, billed micro-agents; root coordinators stitch outputs. Enables elastic scaling of recursive execution.
- Dependencies: Fine-grained metering, robust orchestration (e.g., Ray, Kubernetes), failure containment and retries, cost governance.
- Training surrogates for affordable recursive RL
- Sectors: AI/ML infrastructure
- Vision: New sampling and objective designs that approximate full recursive rollouts to reduce RL cost and latency while preserving transfer.
- Dependencies: Theoretical and empirical validation, open datasets with structured subtasks, benchmark standardization.
- Enterprise knowledge graph population and refresh
- Sectors: enterprise search/knowledge management
- Vision: Recursively extract and verify entities/relations from sprawling corpora; sub-agents handle entity matching, disambiguation, and confidence scoring.
- Dependencies: High-precision extractors, ontology alignment, incremental update strategies, human review for low-confidence nodes.
Notes on Feasibility and Risk Across Applications
- Quality of intermediate supervision: RAO benefits from node-local success signals. Where exact verifiers are unavailable, LLM judges introduce variability; calibration and spot checks are essential.
- Cost/latency trade-offs: Recursive parallelism reduces wall-clock time on parallelizable tasks but can increase compute cost; sequential tasks may slow down without careful depth control.
- Orchestration and concurrency: Productionization requires robust async infrastructure, sandboxed execution, and failure handling for tree-structured rollouts.
- Data governance: Many applications involve sensitive information; ensure access controls, logging, and compliance.
- Guardrails and evaluation: Add process/fact verifiers, unit tests, and dashboards to visualize execution trees; measure both final success and compute efficiency, as suggested by the paper’s discussion.
Glossary
- Advantage: In reinforcement learning, a quantity estimating how much better an action or trajectory is compared to a baseline. "we define its advantage using a leave-one-out baseline over root rewards:"
- AMIGo: A specific method for automatic curriculum learning where goals are proposed to shape a learning curriculum. "automatic curriculum learning methods such as AMIGo"
- asyncio: A Python library for writing concurrent code using the async/await syntax. "or concurrently using standard Python libraries like asyncio"
- Asynchronous function: A non-blocking function that can pause and resume, enabling concurrency. "exposing an asynchronous function"
- Automatic curriculum learning: Techniques that automatically generate progressively challenging tasks to improve learning. "automatic curriculum learning methods such as AMIGo"
- Concurrent sub-agent execution: Running multiple delegated agents in parallel to solve independent sub-tasks. "we support concurrent sub-agent execution by implementing the delegation primitive as an asynchronous function."
- Credit assignment: The problem of determining which actions in a sequence are responsible for outcomes. "we can take advantage of node-local credit assignment"
- Critic: In actor-critic RL, a learned value function used to reduce variance of policy gradient estimates. "by avoiding the need for a critic"
- Delegation bonus: An auxiliary reward term given to a parent agent based on the success of its immediate children. "In practice, the delegation bonus is most useful in regimes where the initial policy under-utilizes delegation"
- Delegation primitive: A core action enabling an agent to launch sub-agents on sub-tasks. "by implementing the delegation primitive as an asynchronous function."
- Depth-level inverse-frequency weighting: A weighting scheme that downweights gradients from more frequent depths in a recursive rollout to balance learning. "we use depth-level inverse-frequency weighting"
- Divide-and-conquer: A strategy that splits a problem into smaller subproblems that are solved separately and combined. "via divide-and-conquer."
- Execution tree: A tree-structured representation of a recursive rollout where each node is an agent instance solving a subtask. "This produces a dynamically structured and recursive execution tree"
- Heterogeneous recursion: A recursive setup where different model types or sizes play distinct roles across levels. "heterogeneous recursion, where stronger models supervise, verify, or synthesize the work of smaller specialist sub-agents"
- Inference-time scaling: Increasing a model’s effective capability at inference by using procedures (e.g., recursion) without changing parameters. "implement an inference-time scaling algorithm"
- Leave-one-out baseline: A variance-reduction baseline computed by excluding the current rollout when comparing rewards. "a leave-one-out baseline over root rewards"
- LLM-judge: Using a LLM to evaluate or score the correctness of another agent’s output. "instead rely on an LLM-judge using GPT-5-mini"
- Policy-generated descendants: Subtasks created by the current policy during recursive execution, forming deeper levels of tasks. "over both root tasks and policy-generated descendants:"
- Policy gradient estimator: A stochastic gradient estimator that updates a policy by correlating log-likelihoods with returns/advantages. "does not bias the policy gradient estimator"
- Python REPL (read-eval-print-loop): An interactive programming environment where code is read, executed, and results are printed iteratively. "in a Python REPL (read-eval-print-loop)"
- Recursive Agent Optimization (RAO): The proposed reinforcement learning method for training a single policy to use recursive delegation effectively. "Recursive Agent Optimization (RAO)"
- Recursive LLMs (RLMs): Agent frameworks that enable recursive delegation within language-model-based agents. "Recursive LLMs (RLMs)"
- Root task distribution: The distribution over original, non-delegated tasks from which top-level problems are sampled. "Let denote the root task distribution"
- Root-group baseline: A common baseline shared by all trajectories in the same root rollout, used for advantage computation. "We use the same root-group baseline for all trajectories within a rollout tree"
- Rollout: The sequence of interactions between an agent and its environment (or tools) during problem solving. "A rollout no longer resembles a single flat trajectory"
- Self-induced curriculum: A curriculum over subtasks that emerges naturally from the agent’s own recursive decomposition during training. "yielding a self-induced curriculum"
- Success signal: A (possibly noisy or proxy) scalar in [0,1] indicating task completion quality for training. "for the success signal used in training"
- Temporal abstraction: In hierarchical RL, the ability to operate at multiple time scales using higher-level actions or subpolicies. "which studies temporal abstraction and learned subpolicies"
- Test-time scaling: Improvements in performance obtained by allocating more or better-structured computation at inference time. "this stronger test-time scaling comes from teaching the model a divide-and-conquer strategy"
Collections
Sign up for free to add this paper to one or more collections.

