Meta-Harness: End-to-End Optimization of Model Harnesses
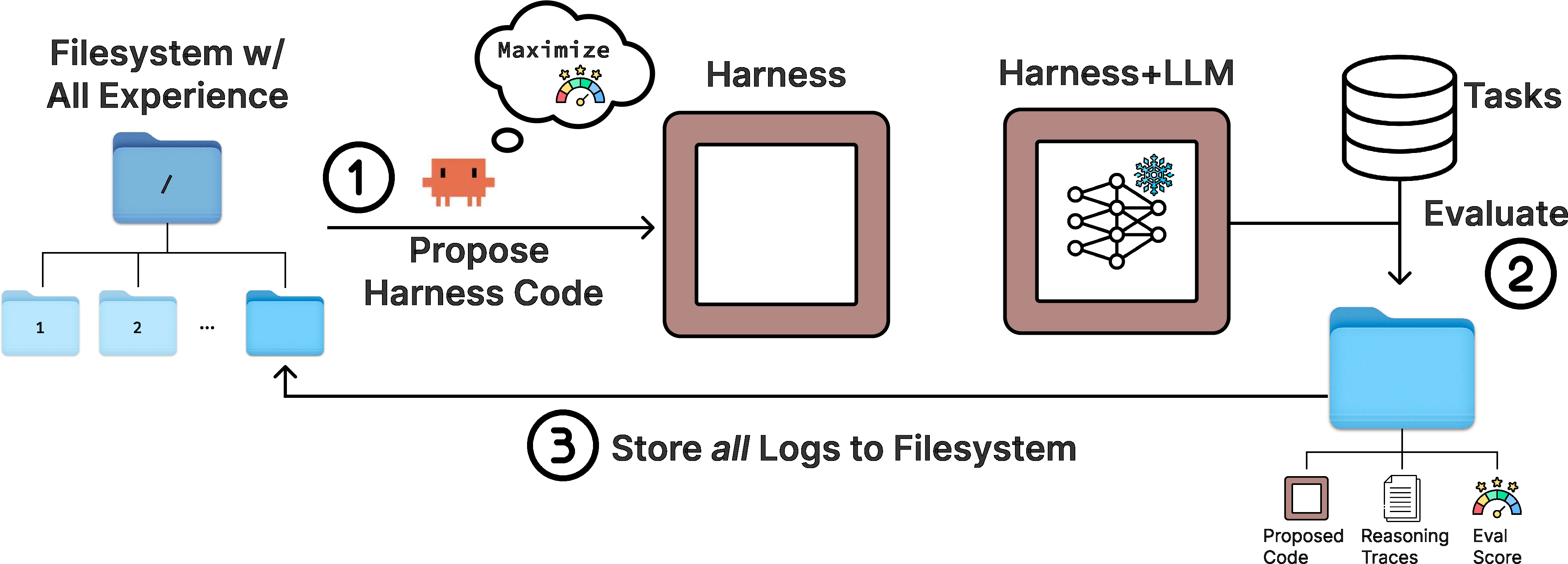
Abstract: The performance of LLM systems depends not only on model weights, but also on their harness: the code that determines what information to store, retrieve, and present to the model. Yet harnesses are still designed largely by hand, and existing text optimizers are poorly matched to this setting because they compress feedback too aggressively. We introduce Meta-Harness, an outer-loop system that searches over harness code for LLM applications. It uses an agentic proposer that accesses the source code, scores, and execution traces of all prior candidates through a filesystem. On online text classification, Meta-Harness improves over a state-of-the-art context management system by 7.7 points while using 4x fewer context tokens. On retrieval-augmented math reasoning, a single discovered harness improves accuracy on 200 IMO-level problems by 4.7 points on average across five held-out models. On agentic coding, discovered harnesses surpass the best hand-engineered baselines on TerminalBench-2. Together, these results show that richer access to prior experience can enable automated harness engineering.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about improving the “harness” around AI LLMs. A harness is the code and rules that decide what information to save, what to look up later, and what to show the AI before it answers. The authors show that this harness can matter as much as the model itself. They introduce Meta‑Harness, a system that automatically designs better harnesses by reviewing past attempts like a careful detective and then rewriting the code to fix what went wrong.
What questions were the researchers asking?
They mainly asked:
- Can we automate the job of “harness engineering,” instead of having people hand‑tune prompts, memory, and tools around an AI?
- If we give an AI coding agent access to rich feedback (like past code, scores, and detailed step‑by‑step logs) instead of only short summaries or final scores, will it discover better strategies faster?
- Will the harnesses it discovers actually help on different kinds of tasks (text classification, hard math problems, and long computer‑use tasks)?
How did they do it? (Methods in simple terms)
Think of training a sports team:
- A basic approach only looks at the final score of each game.
- A better coach watches the full game footage, pauses at key moments, and changes the playbook based on what really happened.
Meta‑Harness is like that better coach:
- After each attempt, it saves everything in a big project folder (a filesystem): the harness code used, the results (scores), and “execution traces” (the play‑by‑play logs showing what the AI was shown, what it answered, which tools it called, and what changed over time).
- A coding agent (an AI that can read files, search through them, and write code) browses this folder using developer tools (like searching text in files), studies many previous attempts, and proposes new code changes to the harness.
- Each new harness is tested on tasks. The results and logs go back into the folder. Repeat.
Why this matters:
- Earlier “text optimizers” usually saw only tiny bits of feedback (like a single score or a short summary). That’s like reading the scoreboard but not watching the game.
- Harnesses affect long chains of decisions (what to store, when to retrieve, how to present info). You often need to trace a mistake backwards to the earlier choice that caused it.
- Meta‑Harness lets the coding agent read as much history as it needs and target precise fixes, not just tweak a template.
Two extra ideas made this practical:
- The system keeps track of trade‑offs, like accuracy versus how many input tokens (context) it uses, so it can find “sweet spots” that are both accurate and efficient.
- The outer loop is simple on purpose: let the coding agent do the diagnosis and the editing, and just keep everything it needs neatly stored.
What did they find, and why is it important?
Across three very different areas, Meta‑Harness found harnesses that beat hand‑built systems and prior optimizers:
- Online text classification (deciding categories from text)
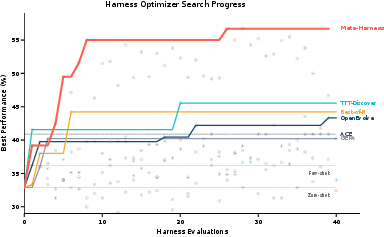
- It beat a strong hand‑engineered system (ACE) by 7.7 percentage points while using about 4× fewer context tokens (so it’s cheaper and faster).
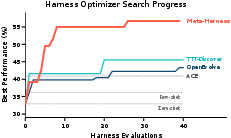
- It reached the next‑best method’s final accuracy after only 4 evaluations instead of ~60 (about 10× faster).
- On nine brand‑new datasets it hadn’t seen before, it also did best on average.
- Retrieval‑augmented math reasoning (IMO‑level problems)
- Meta‑Harness discovered a better way to retrieve relevant solved examples and present them to the model.
- On 200 hard math problems and across five different AI models, it improved accuracy by an average of 4.7 points compared to using no retrieval, and matched or beat other retrieval baselines.
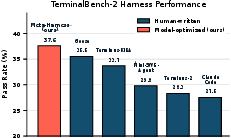
- Agentic coding (TerminalBench‑2, long, tricky computer tasks)
- It automatically found harnesses that outperformed strong hand‑built agents.
- With one model (Claude Haiku 4.5), it ranked #1 among reported agents; with a stronger model (Claude Opus 4.6), it ranked #2 and beat several expert systems.
Why this matters:
- These tasks are very different (short answers vs. long reasoning vs. long‑running computer use), so the success suggests the approach is broadly useful.
- Doing more with fewer context tokens can save money and make systems faster.
- Automatic harness discovery can keep up as tasks change and models improve, without endless manual tinkering.
What’s the impact, in simple terms?
- Faster progress with less trial‑and‑error: Instead of people constantly guessing better prompt rules, an AI coding agent learns from detailed “replays” and improves the harness itself.
- Better reliability on long tasks: Because it reads full logs, the agent can find which earlier choices caused later failures and fix the right thing.
- Cheaper and more efficient systems: Meta‑Harness often reaches higher accuracy while using fewer input tokens.
- Reusable strategies: The discovered harnesses are just code—readable and transferable—so they can work across different models and new datasets.
- A path to the future: As coding agents get smarter, this approach should get even better. One next step is co‑evolving the harness and the model together so each helps the other improve.
Overall, the big idea is: Don’t just tune what the AI says—tune the entire “setup” around it. And to tune that setup well, give your fixer (the coding agent) the full game footage, not just the final score.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that are missing, uncertain, or left unexplored in the paper. Each point is phrased to be actionable for future research.
- Proposer dependence: Results hinge on a single proprietary coding agent (Claude Code Opus‑4.6). It is unclear how performance changes with other agentic coders (open-source, weaker models) or without specialized “max reasoning” modes.
- Agent vs. non-agent ablation: No comparison to a high-context, non-agent LLM that ingests curated logs directly. The unique contribution of tool-use (grep/cat/FS navigation) versus larger-context prompting remains unquantified.
- Log access method: The proposer queries logs via plain filesystem operations (grep/cat). It is unknown whether index-backed retrieval (e.g., vector DBs, structured log stores) yields better search efficiency or outcomes.
- Compute and cost transparency: There is no detailed accounting of token usage, runtime, and dollar cost per search iteration/task. Scaling behavior as logs grow to tens or hundreds of millions of tokens is not characterized.
- Robustness to prompt injection in logs: The proposer consumes raw execution traces, which could contain adversarial strings. Defenses (sandboxing, content sanitization, permissioning) are not specified or evaluated.
- Overfitting on TerminalBench-2: Search and evaluation occur on the same benchmark with only manual/regex audits for leakage. Lack of a held-out split or cross-benchmark validation leaves generalization uncertain.
- Stability and variance: No report of run-to-run variability, seed sensitivity, or confidence intervals for discovered harness performance across domains.
- Causal attribution of improvements: Evidence for “credit assignment” is qualitative. There is no systematic analysis (e.g., controlled ablative replays) linking specific code edits to measured gains.
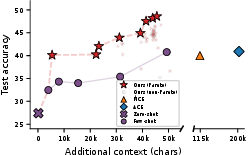
- Multi-objective control: While Pareto curves are shown for accuracy vs. context, there is no method to enforce hard constraints (latency, memory, dollar cost) or to reliably target user-specified trade-offs during search.
- Cold-start capability: The search is initialized from strong baselines. It is unknown whether Meta-Harness can discover competitive harnesses from scratch or from weak/incorrect seeds.
- Domain scope: The evaluation covers three domains. Missing tests in settings like multi-agent coordination, tool-rich RAG with external APIs, streaming/continuous tasks, or safety-critical applications.
- Retrieval optimization limits: In math, the discovered policy operates atop BM25. The system does not explore co-optimizing the retriever class (dense/hybrid), retriever parameters, or learning task-specific embeddings.
- Data contamination checks: Math decontamination relies on string-based filtering and manual spot checks. Near-duplicate/paraphrase leakage and pretraining contamination of base LLMs are not ruled out.
- Cross-model transfer (classification): The discovered text-classification harness is not tested on different base LLMs, so its portability across models is unknown.
- Baseline fidelity: Some leaderboard baselines could not be reproduced (e.g., ForgeCode). Tuning parity and implementation fidelity for all compared methods are not established.
- Statistical significance: Reported gains lack confidence intervals or hypothesis tests, especially for OOD classification and math pass@1 results, leaving uncertainty about robustness of improvements.
- Environmental nondeterminism: The method assumes reliable tool invocations and deterministic environments. Robustness to flaky tools, timeouts, or version drift is not studied.
- Safety constraints on edits: “Interface validation” is mentioned but unspecified. There is no documented use of unit tests, static analysis, or security scans to prevent harmful or brittle code changes.
- Log selection strategy: The proposer reads a median of ~82 files/iteration, but there is no analysis of which selection policies (e.g., prioritization heuristics, sampling strategies) are most effective.
- Search hyperparameters: Sensitivity to number of proposals/iteration, population size, and number of iterations is not explored. Budget–performance scaling curves and diminishing returns remain unknown.
- Comparisons to alternative optimizers: No direct comparisons to Bayesian optimization over code-level knobs, program synthesis with formal constraints, or RL approaches to harness tuning.
- Regression management: While qualitative notes mention regressions, there is no quantitative tracking of regression frequency, rollback strategies, or safeguards to bound worst-case degradation during search.
- Ethics and benchmark gaming: The method could be used to overfit public leaderboards. No guidelines or detection mechanisms are offered to mitigate misuse or ensure scientific validity.
- Repository complexity: Harnesses are single-file Python programs. It is unclear whether the method scales to multi-module, production-scale repositories with complex dependency graphs.
- Persistent memory settings: The paper focuses on per-episode harnesses. How the approach extends to harnesses with persistent, cross-episode memory (and associated evaluation protocols) is not addressed.
- Human oversight and selection: The role and standardization of human oversight (e.g., selecting from the Pareto frontier, vetoing unsafe edits) are not formalized; reproducibility of selection criteria is unclear.
- Cost metrics completeness: The context-cost metric excludes output tokens, retrieval latency, and tool costs. A comprehensive operational cost model for multi-objective optimization is missing.
- Privacy risks: Storing and exposing execution traces to the proposer can surface sensitive data in real applications. Privacy-preserving logging and access control strategies are not discussed.
- Co-evolving weights and harnesses: The approach fixes model weights. How to jointly optimize model and harness (and design stable outer–inner training loops) remains an open research direction.
- Fairness and bias: Harness edits may shift biases in classification tasks. There is no analysis of subgroup performance or fairness impacts introduced by discovered harnesses.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s coding agents and LLM stacks by integrating Meta-Harness-style outer-loop search (propose–evaluate–log) into existing workflows.
- Optimized RAG (retrieval-augmented generation) pipelines for enterprise assistants
- Sectors: software, enterprise IT, knowledge management, customer support
- Tools/products/workflows: “Harness Optimizer for RAG” that runs nightly sweeps to improve retrieval, memory pruning, and prompt construction; integrates with agent frameworks (e.g., LangChain/LlamaIndex), search engines (BM25/ES/OpenSearch), and CI for regression checks; cost-aware “Pareto sweeps” to minimize context tokens at fixed accuracy
- Assumptions/dependencies: access to execution traces and evaluation sets; a capable coding agent (e.g., Claude Code–class); standardized logging of prompts/tool-calls/outputs; permissioned filesystem access; privacy controls for logs
- Cost-efficient, higher-accuracy text classifiers in production
- Sectors: customer support (ticket routing), e-commerce (taxonomy tagging), content moderation, document processing
- Tools/products/workflows: online text-classification harness search that jointly optimizes accuracy and context cost, using stream-based evaluation; automated deployment guardrails with A/B harness testing and rollback; real-time memory curation policy discovery
- Assumptions/dependencies: labeled historical streams or proxy objectives; token-cost telemetry; safe editing and deployment pipeline; privacy for PII in logs
- Agentic coding assistants for CI/CD, DevOps, and data engineering
- Sectors: software development, MLOps, IT operations
- Tools/products/workflows: harness sweeps for repo-specific shell agents (inspired by TerminalBench-style tasks) to improve robustness on environment setup, dependency resolution, build/test flakiness, and scripted incident playbooks; “sandbox-first” execution with artifact diff review
- Assumptions/dependencies: isolated sandboxes; reproducible task suites; strict permissioning for code-writing agents; audit logs for all edits and executions
- Domain-specific retrieval policies for technical reasoning
- Sectors: engineering design, scientific analysis, quantitative research, education (STEM tutoring)
- Tools/products/workflows: discover retrieval and context-construction strategies over large solved-corpus repositories (e.g., internal how-to notebooks, past incident postmortems, solution banks); thin lexical or dual-encoder retrieval stacks with learned harness logic; tutor assistants that surface analogous worked examples
- Assumptions/dependencies: curated and decontaminated corpora; replayable evaluations; simple and auditable retrieval stack; IP/privacy controls
- Model cost and latency optimization via accuracy–context Pareto tuning
- Sectors: SaaS products, contact centers, productivity apps
- Tools/products/workflows: multi-objective harness sweeps that produce a Pareto frontier of accuracy vs. token footprint; policy to auto-select operating point by SLA and budget; continuous monitoring of drift and cost spikes
- Assumptions/dependencies: accurate cost accounting; stable evaluation metrics; change-management for switching harnesses without regressions
- Auditability and compliance for AI systems that depend on harness logic
- Sectors: regulated industries (finance, healthcare, public sector)
- Tools/products/workflows: code-space optimization with full trace logging enables post-hoc audits; “explainable harness diffs” dashboards linking regressions to specific policy edits; approval workflows for production promotion
- Assumptions/dependencies: retention of logs; governance of sensitive content; reproducible evaluation harnesses; separation of duties for approvals
- Research automation for new LLM tasks
- Sectors: academia, applied AI labs
- Tools/products/workflows: reusable Meta-Harness outer loop for rapid, end-to-end harness search on new benchmarks or tasks; artifact archives (code + traces + scores) to support reproducibility and ablation studies
- Assumptions/dependencies: capable coding agent; standardized trace schemas; compute to evaluate candidates; licensing compatible with code edits and data storage
Long-Term Applications
These opportunities require further research, scaling, integration, or regulatory progress before broad deployment.
- Co-evolution of model weights and harness logic
- Sectors: foundation model training, applied AI
- Tools/products/workflows: training loops that jointly learn retrieval/memory policies and fine-tune weights (e.g., RLHF/RLAIF + harness optimization); curricula that use harness changes to shape what models learn
- Assumptions/dependencies: stable online learning pipelines; safety controls for self-modifying systems; evaluation protocols to disentangle harness vs. weight improvements
- Clinical decision support and EHR RAG harness optimization
- Sectors: healthcare
- Tools/products/workflows: discovered retrieval and context policies over de-identified EHRs and clinical guidelines; token-efficient harnesses with strict provenance tracking and evidence presentation
- Assumptions/dependencies: HIPAA/GDPR-compliant data handling; rigorous clinical validation; bias and safety monitoring; model/harness change approval by clinical governance
- High-stakes financial analysis, risk, and compliance agents
- Sectors: finance, insurance
- Tools/products/workflows: harness optimization to improve precision-recall for surveillance, KYC/AML workflows, and reporting; deterministic escalation policies and human-in-the-loop checkpoints embedded in the harness
- Assumptions/dependencies: auditable logs; model risk management frameworks; explainability requirements; approval workflows and kill-switches
- Embodied and robotics agents with long-horizon memory and planning
- Sectors: robotics, logistics, manufacturing
- Tools/products/workflows: harness search for perception-to-action pipelines that retrieve relevant past trajectories and error traces; adaptive memory pruning for on-robot compute constraints
- Assumptions/dependencies: safe sim-to-real transfer; standardized robot execution traces; real-time constraints; hardware-in-the-loop testing
- Energy and infrastructure operations copilots
- Sectors: energy, utilities, transportation
- Tools/products/workflows: harnesses that retrieve historical outage/incident patterns and regulatory constraints to inform operator assistants; multi-objective optimization for reliability, cost, and latency
- Assumptions/dependencies: secure data access; strict safety interlocks; verified procedures; incident replay datasets
- Personalized education at scale with policy-learned retrieval of exemplars
- Sectors: education, edtech
- Tools/products/workflows: per-student harnesses that adapt retrieval of examples and prompts based on learning trajectories; token-efficient curricula generation with guardrails against content leakage
- Assumptions/dependencies: privacy-preserving student models; alignment with pedagogy and standards; continuous assessment loops for effectiveness
- Security hardening and red-team/blue-team harness optimization
- Sectors: cybersecurity, enterprise IT
- Tools/products/workflows: automated search for exploit-hardening harnesses (input filters, tool-use restrictions, recovery policies) guided by adversarial traces; dynamic patching via harness updates
- Assumptions/dependencies: safe sandboxes; attack simulation datasets; continuous verification; governance for automated defenses
- Standards and policy for trace-logging and harness governance
- Sectors: policy/regulation, public sector procurement
- Tools/products/workflows: standardized execution-trace schemas, retention guidelines, and audit requirements for agentic systems that self-modify harnesses; procurement checklists emphasizing “inspectable harness changes”
- Assumptions/dependencies: industry consensus; privacy and IP frameworks; interoperability across vendors
- Marketplace and lifecycle management for reusable harnesses
- Sectors: software platforms, AI tooling
- Tools/products/workflows: versioned harness packages with signed artifacts (code + traces + eval reports); dependency and compatibility managers; automated regression testing across model upgrades
- Assumptions/dependencies: package standards; security signing infrastructure; sustainable evaluation compute
- Environmental impact reductions via systematic token-efficiency
- Sectors: cross-industry AI consumers
- Tools/products/workflows: organization-wide harness sweeps to push operations toward the accuracy–context Pareto frontier, reducing token usage and energy; green-compute reporting tied to harness choices
- Assumptions/dependencies: reliable cost/energy telemetry; governance tying SLAs to cost/energy targets; change-management to adopt new harnesses at scale
Glossary
- ACE (Agentic Context Engineering): A hand-designed method that curates and reflects on memory to build context for LLMs over time. "ACE~\citep{zhang2025ace}"
- agentic coding: Using autonomous LLM-based agents to write and execute code to solve tasks. "On agentic coding, discovered harnesses surpass the best hand-engineered baselines on TerminalBench-2."
- agentic proposer: An autonomous agent that proposes new harness code by inspecting prior runs and artifacts. "It uses an agentic proposer that accesses the source code, scores, and execution traces of all prior candidates through a filesystem."
- Best-of-N: A baseline that selects the best result from N independent samples without a search structure. "Best-of-N: independent samples from the seed with no search structure; a compute-matched control for whether search matters at all."
- BM25 retrieval: A sparse, lexical information retrieval method that ranks documents by term frequency and document length normalization. "manually inspected top BM25 retrievals for held-out examples"
- coding agent: A language-model-based system that can invoke developer tools and modify code. "Its proposer is a coding agent, i.e., a language-model-based system that can invoke developer tools and modify code."
- context tokens: The tokens included in the model’s prompt/context, often constrained by cost or window size. "On online text classification, Meta-Harness improves over a state-of-the-art context management system by 7.7 points while using 4 fewer context tokens."
- context window: The maximum number of tokens a model can condition on at once. "The filesystem is typically far larger than the proposer's context window, so the proposer queries it through terminal tools such as grep and cat rather than ingesting it as a single prompt."
- credit assignment: Determining which components or steps are responsible for observed outcomes to guide improvements. "Meta-Harness brings ideas from the broader literature on credit assignment and meta-learning"
- decontaminated: Cleaned to remove any overlap between training/search data and evaluation benchmarks. "We carefully deduplicated and decontaminated it against both evaluation benchmarks and the search set"
- deduplicated: Processed to remove duplicate items or entries from a dataset. "We carefully deduplicated and decontaminated it against both evaluation benchmarks and the search set"
- dense retrieval: Retrieval using learned embeddings to find semantically similar items. "Dense Retrieval ()"
- evolutionary program search: Optimizing programs by iteratively mutating and recombining candidates guided by performance. "evolutionary program search"
- execution traces: Detailed logs of a program’s run, including prompts, tool calls, model outputs, and state updates. "scores, and execution traces of all prior candidates"
- few-shot prompting: Supplying a prompt with a small number of examples to guide the LLM’s behavior. "As additional baselines, we evaluate zero-shot prompting and few-shot prompting with examples."
- interleaved retrieval and reasoning: A process where retrieval steps are alternated with reasoning steps during inference. "interleaved retrieval and reasoning~\citep{trivedi2023interleavingretrievalchainofthoughtreasoning}"
- lexical retrieval: Retrieval based on exact or token-level matches (as opposed to semantic embeddings). "BM25-based lexical retrieval stack"
- long horizons: Tasks where early decisions affect outcomes many steps later, complicating optimization and diagnosis. "Harnesses act over long horizons: a single choice about what to store, when to retrieve it, or how to present it can affect behavior many reasoning steps later."
- meta-learning: Learning to improve learning procedures, often across tasks, by optimizing higher-level strategies. "Meta-Harness brings ideas from the broader literature on credit assignment and meta-learning"
- outer loop: The higher-level optimization process that proposes and evaluates candidate solutions (here, harnesses). "This section describes Meta-Harness, our outer-loop procedure for searching over task-specific harnesses."
- Pareto dominance: A multi-objective comparison where one solution is better in at least one objective and no worse in others. "we evaluate candidates under Pareto dominance and report the resulting frontier."
- Pareto frontier: The set of non-dominated solutions representing optimal trade-offs among objectives. "Pareto frontier of accuracy vs.\ context tokens on online text classification."
- pass@1: The probability that the top (first) attempt solves the problem, a standard code/reasoning metric. "We show pass@1 averaged over three samples per problem"
- PUCT reuse rule: A selection rule from Monte Carlo tree search variants that balances exploration and exploitation. "proposal selection via the PUCT reuse rule."
- retrieval-augmented generation: Enhancing generation by retrieving and incorporating external information at inference time. "retrieval-augmented generation~\citep{lewis2020retrieval}"
- retrieval-augmented math reasoning: Mathematical problem solving where external worked examples are retrieved to support reasoning. "On retrieval-augmented math reasoning, a single discovered harness improves accuracy on 200 IMO-level problems"
- rollout trajectory: The sequence of states, actions, and outputs generated by running a policy or program on an instance. "we execute a rollout trajectory ."
- sparse baseline: A baseline that uses sparse, lexical retrieval (e.g., BM25) rather than dense embeddings. "on top of the same BM25-based lexical retrieval stack as the sparse baseline"
- stateful program: A program that maintains and updates internal state across steps of execution. "A harness is a stateful program that wraps a LLM and determines what context the model sees at each step."
- TerminalBench-2: A benchmark of long-horizon autonomous coding tasks requiring complex dependency handling and domain knowledge. "On TerminalBench-2, the discovered harness surpasses Terminus-KIRA and ranks #1 among all Haiku 4.5 agents."
- text optimizer: A method that iteratively improves text artifacts (e.g., prompts or code) using feedback from evaluations. "existing text optimizers are poorly matched to this setting because they compress feedback too aggressively"
- zero-shot prompting: Prompting without any in-context examples, relying solely on the task description. "As additional baselines, we evaluate zero-shot prompting and few-shot prompting with examples."
Collections
Sign up for free to add this paper to one or more collections.

