Recursive Language Models
Abstract: We study allowing LLMs to process arbitrarily long prompts through the lens of inference-time scaling. We propose Recursive LLMs (RLMs), a general inference strategy that treats long prompts as part of an external environment and allows the LLM to programmatically examine, decompose, and recursively call itself over snippets of the prompt. We find that RLMs successfully handle inputs up to two orders of magnitude beyond model context windows and, even for shorter prompts, dramatically outperform the quality of base LLMs and common long-context scaffolds across four diverse long-context tasks, while having comparable (or cheaper) cost per query.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Summary of “Recursive LLMs”
1. What is this paper about?
This paper is about helping AI LLMs handle really, really long inputs—much longer than they were originally built to read all at once. The authors introduce a new way to run a model, called a Recursive LLM (RLM), so it can “look at” huge documents piece by piece, think about them, and even call smaller versions of itself to help, all without stuffing everything into its limited memory at once.
2. What questions did the researchers ask?
They focused on a few big questions:
- Can we make LLMs understand inputs far longer than their normal “context window” (their reading limit)?
- Can this be done without expensive retraining—just by changing how the model is used at inference time (when it’s answering you)?
- Will this approach work better than common tricks like summarizing long text or simple search-and-retrieve?
- How does performance change as inputs get longer and tasks get more complicated?
3. How did they do it? (Methods explained simply)
Most LLMs can only read a certain number of tokens at once. Tokens are tiny pieces of text—like chunks of words. The “context window” is the maximum number of tokens the model can look at in a single go. When the text gets longer than that, performance usually drops—a problem the paper calls “context rot,” meaning the model’s answers get worse as the input grows.
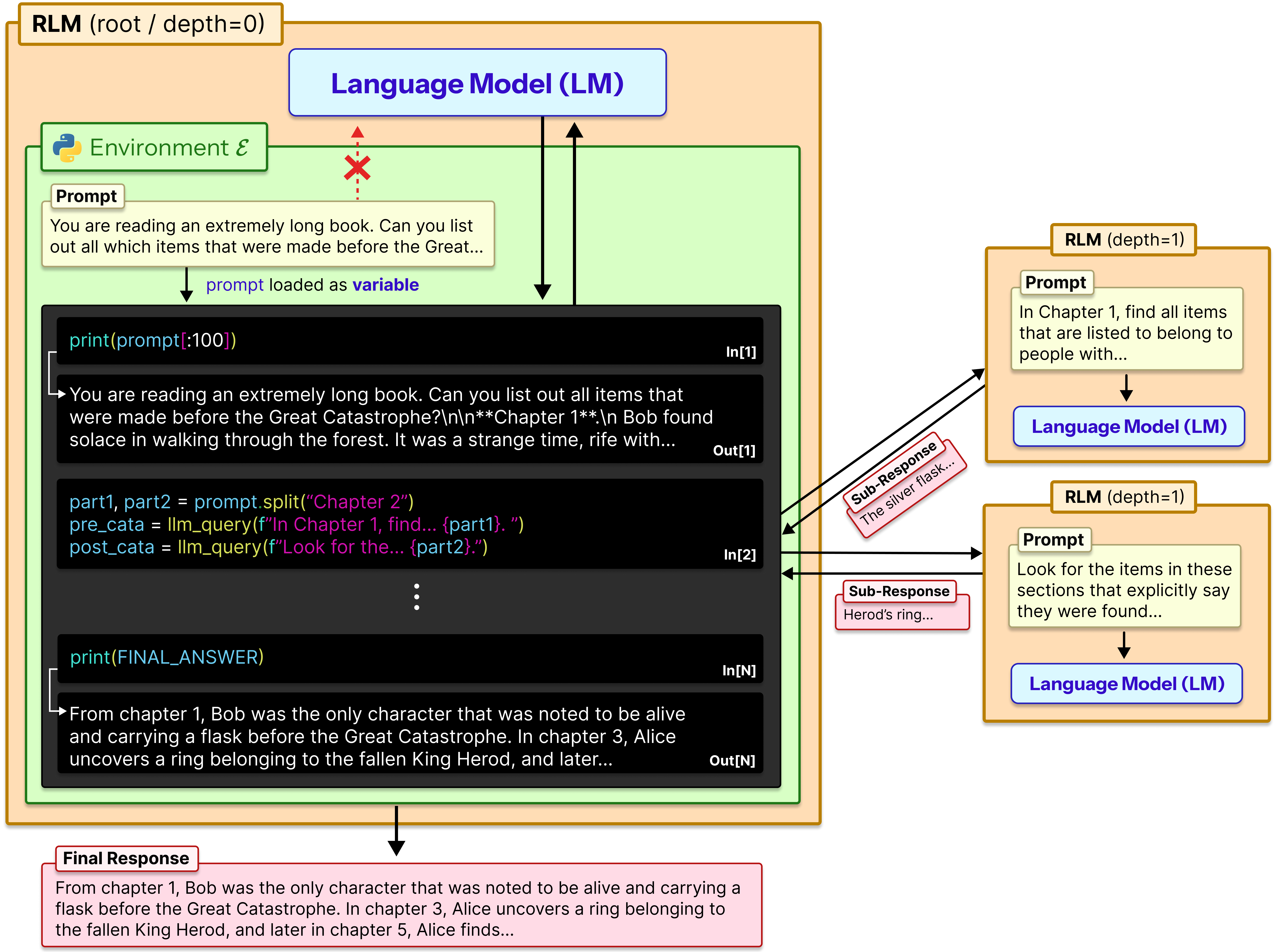
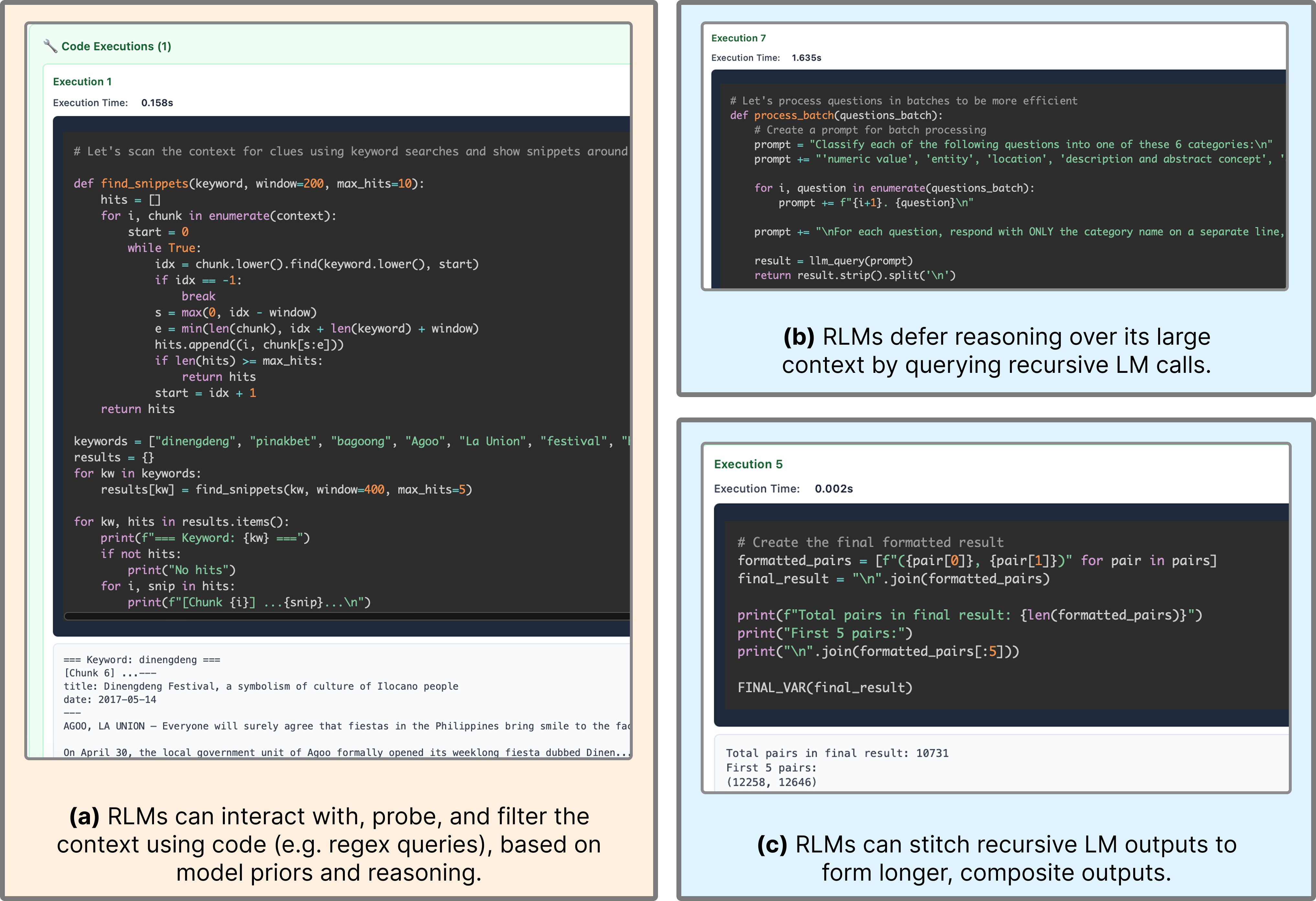
The authors’ idea: don’t feed the giant text directly into the model. Instead, treat the text like an external object the model can interact with using tools.
Here’s the setup in everyday terms:
- Imagine you have a giant scrapbook (the long prompt). Instead of trying to memorize the whole thing, the model sits at a computer with that scrapbook saved as a file.
- The model opens a Python REPL. A REPL is like an interactive coding notepad or calculator: you type code, it runs instantly, and you see the result.
- The entire long prompt is stored as a variable in this REPL. The model writes small bits of code to peek into specific parts, search for keywords, split the text into chunks, and keep track of notes or partial answers.
- When needed, the model can recursively call a helper model (a sub-model) on just a small snippet. This is like asking a friend to read a single page and summarize it for you.
- The model repeats this “look → think → code → check → call helper if needed” loop until it’s confident about the final answer.
This approach is called a Recursive LLM (RLM) because it can call itself (or a smaller model) on sub-tasks, over and over, as needed.
4. What did they find, and why is it important?
The authors tested RLMs on several long-context tasks, including:
- “Needle in a haystack” tasks (find one key item in a huge text).
- Tasks that require combining information from many documents (deep research).
- Tasks that require reading and processing almost every line (very information-dense).
- Code understanding tasks across many files.
- A tougher version where answers depend on pairs of items, not just single items.
Key takeaways:
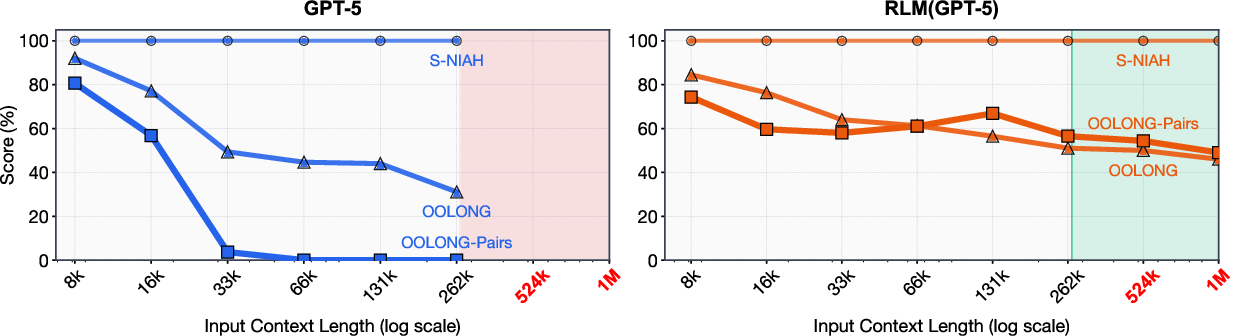
- RLMs handled inputs way beyond normal limits, even into the 10+ million token range.
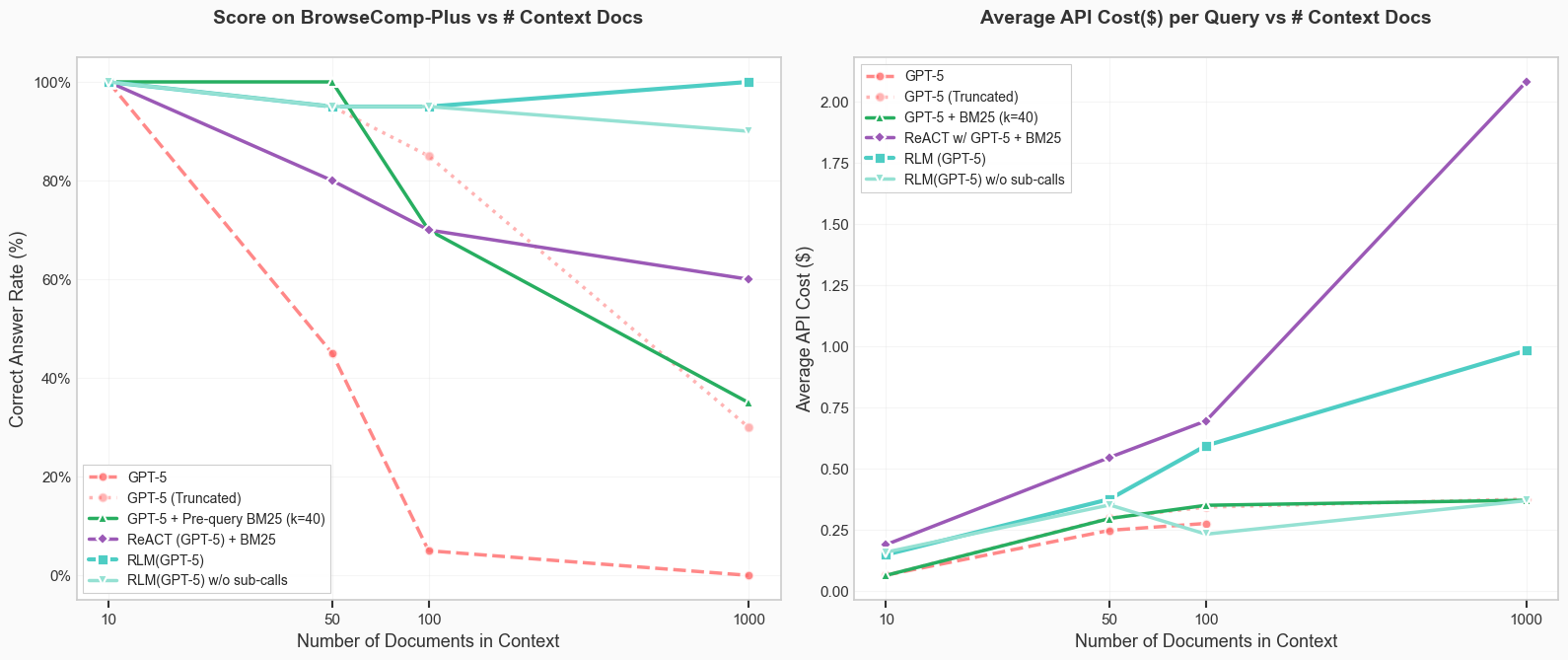
- They often beat the base models and common methods like summarizing the text or simple retrieval tools—sometimes by large margins.
- The REPL setup (treating the prompt as a variable and using code to explore it) was crucial for long inputs.
- Recursive sub-calls (asking a helper model to process small chunks) gave big gains on the most information-dense tasks, where you can’t just summarize and forget details.
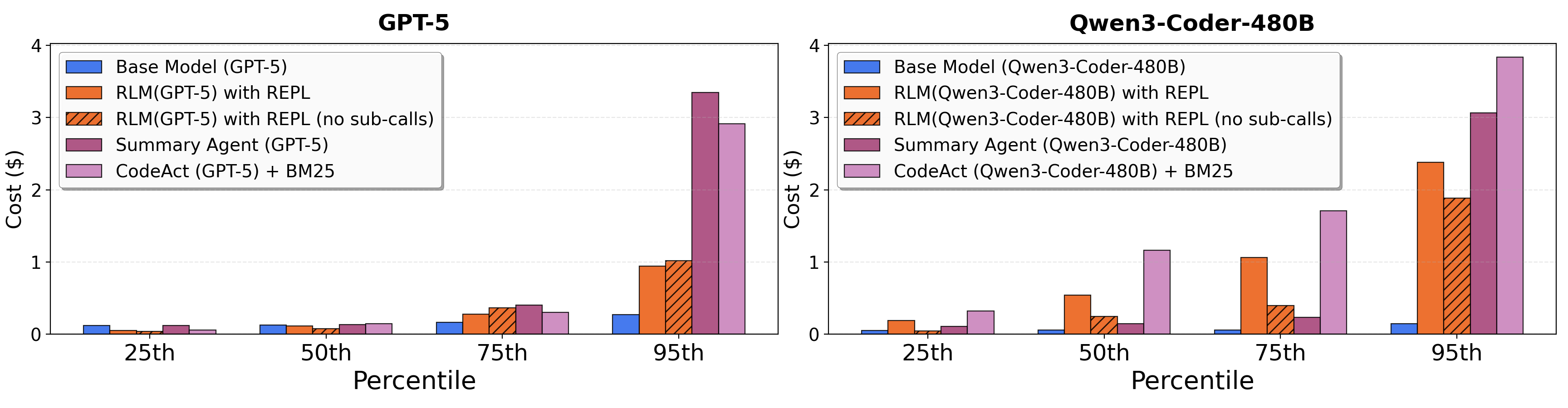
- Cost was usually similar to or cheaper than other methods at the median, though sometimes the RLM took longer and cost more in tricky cases (because it explored many steps).
- As inputs got longer and tasks got harder, regular models got worse more quickly. RLMs still degraded, but much more slowly.
- For very short inputs, a plain model can be fine or slightly better; RLMs shine as inputs and complexity grow.
Why this matters: It shows we can scale what models can handle by changing how we use them, not just by making bigger models.
5. What’s the impact and what could come next?
Implications:
- RLMs are a general way to let models tackle huge documents, long research projects, or big codebases without losing important details.
- This could power better AI assistants for research, law, software engineering, or any job that involves digging through massive amounts of information.
- It suggests a new “axis of scaling”: not only bigger models or longer built-in context windows, but smarter inference-time strategies that mix code, tools, and recursive planning.
Possible next steps:
- Make RLMs faster and cheaper by running helper calls in parallel or using better sandboxes.
- Train models specifically to be good at making these step-by-step decisions inside the REPL.
- Explore deeper recursion and smarter chunking strategies, so the model becomes an even better “project manager” over its own process.
In short, the paper’s big idea is to let the model act like a careful researcher with a computer: open the big file, write small programs to explore it, ask for help on tricky parts, and stitch together a strong final answer. This makes long, complex tasks much more manageable—and often more accurate—than trying to cram everything into the model’s memory at once.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several aspects unresolved; future work could address the following:
- Formal scaling analysis: provide theoretical bounds on RLM compute and cost as functions of input length and task complexity, including break‑even conditions where RLMs outperform base LMs.
- Adaptive policy for sub-calls: design and evaluate learned or optimized policies that decide when to peek, chunk, and recursively call sub-LMs, rather than relying on emergent heuristics.
- Recursion depth and convergence: explore deeper recursion levels, termination criteria, stack/trace management, and the risk of non-terminating or oscillatory trajectories.
- Environment design choices: compare Python REPL to alternative environments (e.g., sandboxed interpreters, typed DSLs, streaming IO, memory-mapped files) and quantify their impact on performance, safety, and scalability.
- Security and sandboxing: systematically assess risks of executing LLM-generated code (e.g., code injection, resource abuse, data exfiltration) and implement/benchmark sandboxing, quotas, and isolation mechanisms.
- Robustness to adversarial/noisy inputs: evaluate susceptibility to prompt injection within the context variable and to adversarially crafted long prompts; develop defenses and detection mechanisms.
- Long-output evaluation: quantify output-length scalability (quality, consistency, correctness) when returning large variables, and study strategies for incremental writing, chunked outputs, and post-verification.
- Tail latency and cost variance: investigate scheduling, caching/memoization, batching, and asynchronous sub-calls to reduce the high-variance cost and runtime observed in long trajectories.
- Cost fairness and reproducibility: standardize cost accounting (same providers/models), release code/prompts, and provide sensitivity analyses to sampling parameters (temperature, reasoning modes), to enable apples-to-apples replication.
- Model coverage: extend beyond two frontier models to smaller/open models, multilingual settings, and multimodal tasks (text+code+images), assessing cross-model generality of RLM benefits and behaviors.
- Benchmark breadth: evaluate on realistic long-horizon, multi-turn, streaming tasks (e.g., web-scale research, large codebases with 100k+ files, legal/medical corpora), not just static single-turn long-context datasets.
- Stronger baselines: compare against modern memory/RAG systems (vector indexes, hierarchical memory, monotonic/infini-attention LMs, structured retrieval), not only summarization and BM25-based agents.
- Chunking and indexing strategies: ablate semantic vs uniform chunking, regex vs structured parsing, and integrate symbolic indexes (suffix arrays, inverted indexes) to improve selective access.
- Failure-mode taxonomy: conduct systematic error analysis of RLM trajectories (e.g., redundant verification loops, incorrect stitching, sub-call misalignment) and develop recovery/rollback mechanisms.
- Metrics beyond accuracy/cost: measure reliability, calibration, robustness to perturbations, repeatability across runs, and human-rated reasoning quality; include confidence estimates in outputs.
- Privacy/compliance: analyze risks of sending snippets to external APIs during sub-calls, propose policies (local inference, encryption, differential privacy), and measure data leakage.
- Programmatic verification: integrate formal checks, property tests, or executable oracles to validate intermediate and final outputs; quantify their cost-performance trade-offs.
- LM–RLM switching: define and validate a meta-controller that decides when to use base LM vs RLM based on input length, information density, and budget constraints.
- Memory/IO limits: characterize the REPL memory footprint and IO overhead for 10M–100M+ token contexts; develop streaming/out-of-core mechanisms with bounded memory.
- Retrieval/index integration: systematically study RLMs that build and query auxiliary indexes (vector databases, BM25, structured stores) and quantify gains over pure REPL peeking.
- Prompt sensitivity: analyze how the fixed system prompt affects behavior and performance; develop robust prompts or prompt-tuning procedures tailored to RLM use.
- Determinism and variance: report variance across seeds and sampling parameters; explore mechanisms (e.g., planner modules, constrained decoding) to stabilize trajectories.
- Structured inputs: compare raw strings vs structured representations (JSON, tables, ASTs) to improve symbolic manipulation and reduce token peeking needs.
- Training for RLM behavior: prototype and evaluate explicit training (supervised/RL) for root/sub-LMs on RLM trajectories to improve decision-making and reduce inefficiency.
- Theory connections: formalize RLMs using out-of-core and external-memory algorithm frameworks; derive complexity bounds and optimal strategies for selective access.
- Budgeted termination: develop principled early-stopping criteria and budget-aware planning that optimize the cost–performance frontier for different task classes.
- Tool portfolio: explore integration with non-LM tools (retrievers, compilers, databases, code analyzers) within RLM loops and quantify their complementary benefits.
Practical Applications
Immediate Applications
The following opportunities can be deployed now by wrapping existing LLMs with an RLM scaffold (REPL environment + programmatic prompt access + optional recursive sub-calls), using standard sandboxing and orchestration.
- Enterprise document QA over “too-long” inputs (sectors: software, legal, finance, compliance)
- What: Ask precise questions across thousands of pages (contracts, 10-K/10-Q filings, policies, audit manuals) without retraining the base LLM or truncating.
- Tools/workflow: “LongDoc QA” service that loads uploads as memory-mapped files; RLM uses regex/structured parsing to peek, filter, and aggregate; optional BM25 for pre-filter; budget-aware recursion.
- Assumptions/dependencies: Secure sandbox for code execution; memory/file streaming to avoid loading entire docs into RAM; audit logging of code + reads; model with reliable code-writing ability.
- Monorepo and codebase understanding at scale (software engineering)
- What: Cross-file API usage analysis, dependency impact assessment, refactoring scope discovery, license scanning across very large repos.
- Tools/workflow: “Repo Copilot for Mega-Repos”; RLM scans file trees programmatically (glob, AST, grep-like filters), delegates semantic summaries of selected files to sub-LMs, stitches a long-form report.
- Assumptions/dependencies: Sandboxed file access; language-aware parsers; rate limits on sub-calls; optional CI/CD integration for PR comments.
- Log and incident analysis for SRE/DevOps (software, cloud/infra)
- What: Root-cause analysis by sifting terabytes of logs incrementally; anomaly pattern extraction without naive summarization loss.
- Tools/workflow: RLM-driven “Log Investigator” that streams time-chunked logs; uses regex/time filters and sub-calls to explain spikes; emits playbooks.
- Assumptions/dependencies: Streaming adapters (e.g., S3, Kafka); privacy and retention policies; cost guardrails on recursion depth.
- Literature triage for research and IP (academia, R&D, biotech/pharma)
- What: Answer multi-hop questions across thousands of papers/patents; track conflicting evidence; produce traceable syntheses.
- Tools/workflow: “RLM Research Assistant” that peeks into candidate PDFs/CSVs; iteratively refines a reading list; verifies claims with line/figure references.
- Assumptions/dependencies: PDF parsing quality; stable offline corpora; citation extraction; sandbox to disable network egress.
- E-discovery and due diligence (legal, M&A, compliance)
- What: Find obligations, exceptions, indemnities, and change-of-control clauses across large corpora; reconcile definitions across documents.
- Tools/workflow: Clause-first regex filters + sub-LM semantic checks; cross-document stitching of obligations into a diligence memo with citations.
- Assumptions/dependencies: Strong auditability (store code, file offsets, matches); redaction policies; human-in-the-loop validation.
- Regulatory mapping and policy QA (public sector, finance, healthcare)
- What: Map internal policies to external regulatory requirements (e.g., SOX, HIPAA, GDPR) across thousands of pages; gap analysis with evidence.
- Tools/workflow: RLM “Policy Mapper” that constructs requirement-to-policy indices; programmatically probes definitions; outputs traceable conformance matrix.
- Assumptions/dependencies: Up-to-date regulatory text; rigorous logging; domain prompts; approval workflows.
- Customer-support and knowledge-base mining (enterprise CX)
- What: Resolve tickets using tens of thousands of pages of product docs, forum posts, and changelogs without lossy condensation.
- Tools/workflow: RLM “Answer Composer” that filters by product/version keywords; verifies candidate answers against source snippets; generates step-by-step resolution.
- Assumptions/dependencies: Version-aware indexing; guardrails to avoid over-calling sub-LMs; feedback loops from solved tickets.
- Financial analysis across long horizons (finance)
- What: Multi-year trend analysis over earnings calls, filings, and investor presentations; footnote-level justification.
- Tools/workflow: Time-bucketed streaming into RLM; factor-specific regex seeds (e.g., guidance, capex, risks); verification sub-calls for metric reconciliation.
- Assumptions/dependencies: High-quality transcript/filing parsers; data licensing; caching to reuse prior slices.
- Clinical operations and medical coding QA (healthcare)
- What: Cross-episode chart review, coding/claims consistency checks, protocol compliance across lengthy records.
- Tools/workflow: RLM “Chart Auditor” that scans for ICD/CPT inconsistencies; maps protocol milestones; compiles a long output with provenance.
- Assumptions/dependencies: PHI security, HIPAA/GDPR compliance; medical ontologies; robust de-identification; clinical LLMs preferred.
- Long-form authoring beyond token limits (all sectors)
- What: Draft compliance manuals, SOPs, technical specs, or program plans exceeding model output limits by composing verified subsections.
- Tools/workflow: RLM writes sub-sections via sub-calls, stores text variables, and stitches final artifacts; includes self-check steps on cross-references.
- Assumptions/dependencies: Style guides; section-level quality checks; version control for generated content.
- Risk and control evidence gathering (audit, GRC)
- What: Collect and justify control evidence across tickets, docs, and logs; produce audit trails with exact locations.
- Tools/workflow: RLM “Evidence Harvester” that programmatically queries sources; logs code + matches; compiles an evidence binder.
- Assumptions/dependencies: Centralized access patterns; immutable logs; separation of duties.
- RAG+RLM hybrid workflows (software, data platforms)
- What: Use retrieval for coarse pre-filter, then RLM to conduct dense, programmatic reading and recursive reasoning on retrieved slices.
- Tools/workflow: Add an “RLM post-retrieval reader” stage to existing pipelines (LangChain, Haystack, Semantic Kernel).
- Assumptions/dependencies: Retriever quality; chunk metadata; resource budgets for sub-calls.
- Auditable agent trajectories for regulated settings (finance, healthcare, public sector)
- What: Provide transparent, replayable trails (code, parameters, file spans) for each answer.
- Tools/workflow: Persist REPL code, execution outputs, sub-call prompts/responses, and file offset references.
- Assumptions/dependencies: Storage for logs; privacy classification of traces; organizational retention rules.
- Cost-optimized “budgeted” assistants (general)
- What: Maintain accuracy under strict cost ceilings by selectively peeking, early-stopping, and capping recursion.
- Tools/workflow: Budget-aware step controller; metering dashboard; caching of intermediate transforms.
- Assumptions/dependencies: Tuned policies for cutoffs; business-acceptable recall/precision tradeoffs.
Long-Term Applications
These opportunities benefit from further research into asynchronous sub-calls, deeper recursion, specialized training for RLM-style reasoning, and production-grade sandbox/runtime engineering.
- Autonomous deep-research agents at web scale (academia, media, public policy)
- What: Multi-week investigations across millions of pages with provenance, contradiction detection, and periodic self-audits.
- Tools/products: Asynchronous RLM scheduler, distributed file peekers, contradiction-resolving verifiers; “Research OS.”
- Dependencies: Reliable long-horizon planning; deduplication and stance detection; governance for third-party content.
- National-scale regulatory conformance engines (public sector, finance, healthcare)
- What: Continuously reconcile evolving laws with organizational policies, procedures, and evidence repositories.
- Tools/products: “Policy Twin” powered by RLMs trained on compliance reasoning; deep recursion for cross-regime linkages.
- Dependencies: Up-to-the-minute legal corpora; legal-grade explainability; human review boards.
- Continuous codebase refactoring and security scanning (software, cybersecurity)
- What: Ongoing, RLM-orchestrated refactors, vulnerability hunts, and patch proposals in very large codebases.
- Tools/products: “RLM Refactorer/Security Auditor” integrating AST transforms, SAST/DAST hooks, and auto-PRs.
- Dependencies: Strong sandboxing; verifiable tests; approval workflows; integration with build systems.
- Long-horizon planning for robotics and operations (robotics, manufacturing, logistics)
- What: Craft and maintain very long task plans, SOPs, and checklists beyond token limits with closed-loop verification.
- Tools/products: RLM “Plan Composer” with simulation-in-the-loop and sensor log peeking.
- Dependencies: Reliable sim adapters; structured state integration; safety constraints and certification.
- Clinical guideline synthesis and living reviews (healthcare)
- What: Maintain continuously updated clinical guidelines by reconciling trials, RWE, and safety bulletins at massive scale.
- Tools/products: Domain-trained RLM ensembles, evidence grading modules, GRADE-compatible outputs.
- Dependencies: Medical-domain training; bias control; expert panels; legal liability frameworks.
- E2E audit automation with explainable trajectories (audit, GRC)
- What: Plan, execute, and evidence entire audits with traceable code and sub-call logs meeting regulator standards.
- Tools/products: RLM “Audit Conductor” with standardized controls libraries, sampling logic, and evidence binders.
- Dependencies: Standards alignment (e.g., PCAOB, ISO); validation suites; attestations for AI usage.
- Scientific data and methods synthesis (science, pharma)
- What: Programmatically traverse lab notebooks, methods sections, and datasets to produce reproducible, long-form protocols and meta-analyses.
- Tools/products: “RLM Methods Synthesizer” with notebook parsers, data registry connectors, and provenance graphs.
- Dependencies: Structured metadata; data access governance; reproducibility frameworks.
- Personalized longitudinal assistants for lifelog archives (consumer, productivity)
- What: Summarize, search, and reason across decades of emails, notes, photos, and documents without leaking private data.
- Tools/products: On-device or private-cloud RLMs with encrypted stores; proactive insights and reminders.
- Dependencies: Privacy-preserving REPL; secure enclaves; compute constraints; user consent design.
- Long-output policy and legislative drafting with verification (government, NGOs)
- What: Generate and maintain large bills/policies while verifying cross-references, definitions, and amendments against legal corpora.
- Tools/products: “LegisRLM” with citation verifiers and conflict checkers; deep recursion for harmonization.
- Dependencies: Up-to-date legal databases; stakeholder workflows; robust red-teaming.
- Multi-agent RLM systems with hierarchical recursion (general)
- What: Teams of specialized RLMs coordinating via shared artifacts and deeper recursive layers for complex projects.
- Tools/products: Orchestrators for parallel/asynchronous sub-calls; shared memory fabric; conflict-resolution policies.
- Dependencies: Deadlock/loop detection; cost/safety governors; inter-agent protocol design.
- Training LMs explicitly for RLM trajectories (AI model development)
- What: Models optimized to write efficient code-peeks, choose sub-calls judiciously, and verify answers reliably.
- Tools/products: Datasets from RLM traces; RL from trajectory quality; tool-use pretraining.
- Dependencies: Access to high-quality traces; safe tooling; evaluation standards for long-context reasoning.
- Energy and industrial telemetry analytics (energy, manufacturing)
- What: Cross-site, long-horizon telemetry triage and root-cause narratives over massive time-series logs and maintenance text.
- Tools/products: RLM “Telemetry Investigator” combining programmatic filtering, feature extraction, and text reasoning.
- Dependencies: Connectors for time-series stores; downsampling strategies; OT security and isolation.
- FOIA-scale archival exploration and oversight (public sector, journalism)
- What: Investigative analysis across large public records with reproducible, citable findings.
- Tools/products: Public “Civic RLM” portal with transparent trajectories and document offsets for every claim.
- Dependencies: Hosting and moderation; provenance and fairness safeguards; citizen data access norms.
Cross-cutting assumptions and dependencies (for both horizons)
- Secure execution: Strong sandboxing of REPL code (filesystem, network egress restrictions, resource limits), plus audit logs for reproducibility.
- Data handling: Streaming/memory-mapped access for very large inputs; robust parsers for PDFs/HTML/CSV; PII handling and compliance.
- Cost and latency: Budget-aware controllers (step limits, early stopping), caching, and optional asynchronous sub-calls; acceptance of cost variance tails.
- Model capability: Base LLM must write and reason about code; domain-tuned prompts or models improve reliability.
- Governance: Traceable trajectories (code, prompts, offsets) to satisfy audits, legal discovery, and internal review.
- Integration: Connectors to enterprise content sources (DMS, ticketing, VCS, SIEM); human-in-the-loop checkpoints where required.
Glossary
- Ablation: An experimental variant where a component is removed to assess its contribution. "We provide an ablation of our method."
- BM25: A classic probabilistic ranking function used for document retrieval. "we equip this agent with a BM25~\citep{10.1561/1500000019} retriever"
- BrowseComp-Plus (1K documents): A long-context multi-hop QA benchmark with a fixed set of 1,000 documents per task. "BrowseComp-Plus (1K documents)~\citep{chen2025browsecompplusfairtransparentevaluation}."
- CodeAct: An agent framework that uses executable code actions within a reasoning loop. "We compare directly to a CodeAct~\citep{wang2024executablecodeactionselicit} agent that can execute code inside of a ReAct~\citep{yao2023reactsynergizingreasoningacting} loop."
- Context compaction: Summarizing or compressing context to fit within the model’s window. "context condensation or compaction \citep{khattab2021baleen,smith2025openhands_context_condensensation,openai_codex_cli,wu2025resumunlockinglonghorizonsearch}"
- Context rot: Degradation of model performance as context length increases. "context rot~\citep{hong2025contextrot}"
- Context window: The maximum number of tokens a model can process at once. "context window of 272K tokens"
- DeepResearch: An AI research task setting focused on multi-hop reasoning over large corpora. "DeepResearch~\citep{OpenAI_DeepResearch_2025}"
- Effective context window: The practical usable length of context before performance substantially drops. "the effective context window of LLMs can often be much shorter than a model's physical maximum number of tokens."
- F1 score: The harmonic mean of precision and recall used to evaluate prediction quality. "We report F1 scores over the answer."
- Frontier LM: A state-of-the-art LLM at the leading edge of capability. "a frontier LM"
- Inference-time scaling: Increasing or structuring compute during inference to improve capability without retraining. "through the lens of inference-time scaling."
- Information density: How much relevant information must be processed per token or unit of input. "We loosely characterize each task by information density"
- Long-horizon tasks: Tasks requiring extended sequences of steps or very large contexts. "as LLMs begin to be widely adopted for long-horizon tasks"
- LongBench-v2 CodeQA: A long-context code repository understanding benchmark with multiple-choice questions. "LongBench-v2 CodeQA~\citep{bai2025longbenchv2deeperunderstanding}."
- Model-agnostic: Not tied to a specific model; applicable across different LMs. "RLMs are a model-agnostic inference strategy"
- Needle-in-a-haystack (NIAH): Tasks requiring locating a specific target embedded in large irrelevant text. "needle-in-a-haystack (NIAH) problems"
- OOLONG: A benchmark emphasizing long-context reasoning and aggregation over many input entries. "OOLONG~\citep{bertsch2025oolongevaluatinglongcontext}."
- OOLONG-Pairs: A variant of OOLONG requiring pairwise aggregation across entries, increasing complexity quadratically. "OOLONG-Pairs. We manually modify the trec_coarse split of OOLONG to include $20$ new queries that specifically require aggregating pairs of chunks to construct the final answer."
- Out-of-core algorithms: Methods that process datasets larger than main memory by careful data movement. "out-of-core algorithms, in which data-processing systems with a small but fast main memory can process far larger datasets by cleverly managing how data is fetched into memory."
- ReAct: A paradigm that interleaves reasoning and tool use/actions in LLM agents. "a ReAct~\citep{yao2023reactsynergizingreasoningacting} loop."
- Read-Eval-Print Loop (REPL): An interactive environment that reads code, evaluates it, and prints results. "Read-Eval-Print Loop (REPL) programming environment"
- Recursive LLMs (RLMs): An inference paradigm that lets an LM programmatically decompose problems and call itself recursively over parts of the input. "Recursive LLMs (RLMs)"
- Retriever: A component that selects relevant documents from a corpus to support reasoning. "BM25~\citep{10.1561/1500000019} retriever"
- RULER: A benchmark suite for evaluating models’ effective long-context capabilities. "RULER~\citep{hsieh2024rulerwhatsrealcontext}"
- S-NIAH: The single needle-in-a-haystack benchmark variant with a constant-size target. "S-NIAH. Following the single needle-in-the-haystack task in RULER~\citep{hsieh2024rulerwhatsrealcontext}, we consider a set of 50 single needle-in-the-haystack tasks..."
- Sub-LM calls: Invocations of another LM (or the same LM) as a subroutine during problem solving. "is not able to use sub-LM calls."
- Summary agent: An agent that iteratively summarizes context to stay within the model’s window. "Summary agent"
- Trajectory: The sequence of steps, code executions, and sub-calls taken by an agent while solving a task. "RLM trajectories"
Collections
Sign up for free to add this paper to one or more collections.