Recursive Multi-Agent Systems
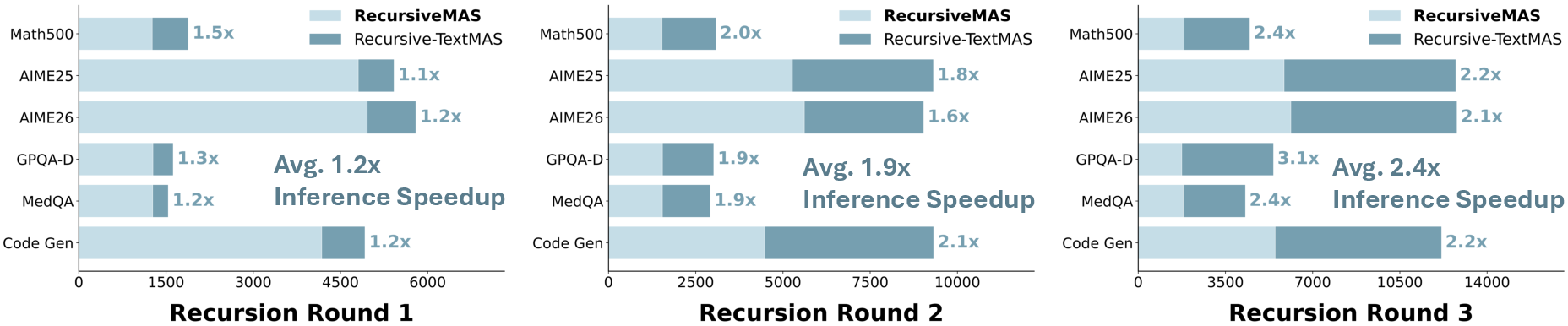
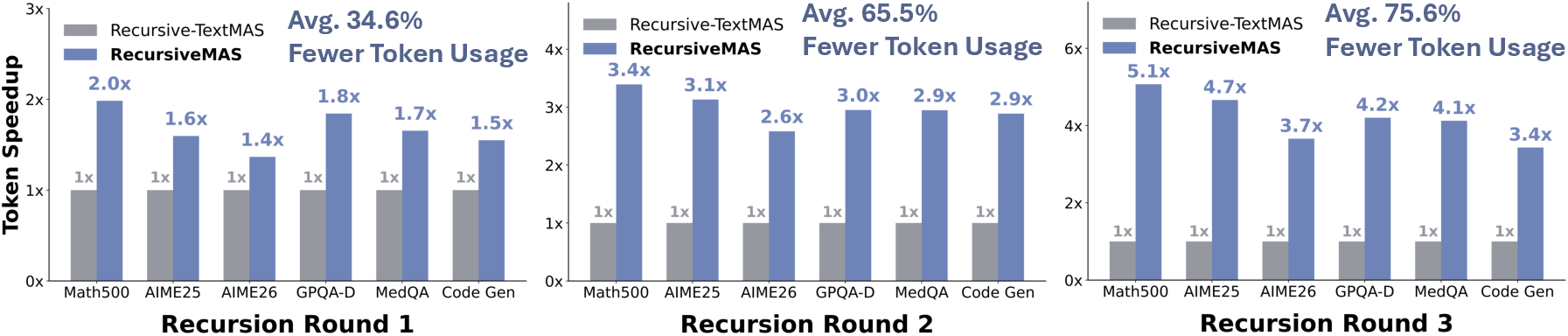
Abstract: Recursive or looped LLMs have recently emerged as a new scaling axis by iteratively refining the same model computation over latent states to deepen reasoning. We extend such scaling principle from a single model to multi-agent systems, and ask: Can agent collaboration itself be scaled through recursion? To this end, we introduce RecursiveMAS, a recursive multi-agent framework that casts the entire system as a unified latent-space recursive computation. RecursiveMAS connects heterogeneous agents as a collaboration loop through the lightweight RecursiveLink module, enabling in-distribution latent thoughts generation and cross-agent latent state transfer. To optimize our framework, we develop an inner-outer loop learning algorithm for iterative whole-system co-optimization through shared gradient-based credit assignment across recursion rounds. Theoretical analyses of runtime complexity and learning dynamics establish that RecursiveMAS is more efficient than standard text-based MAS and maintains stable gradients during recursive training. Empirically, we instantiate RecursiveMAS under 4 representative agent collaboration patterns and evaluate across 9 benchmarks spanning mathematics, science, medicine, search, and code generation. In comparison with advanced single/multi-agent and recursive computation baselines, RecursiveMAS consistently delivers an average accuracy improvement of 8.3%, together with 1.2$\times$-2.4$\times$ end-to-end inference speedup, and 34.6%-75.6% token usage reduction. Code and Data are provided in https://recursivemas.github.io.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces a new way to make AI “teams” work better together. Instead of having one big AI do everything, the authors build a group of smaller AIs (called agents) with different skills that help each other. Their key idea is to let these agents “think together in a loop,” quietly sharing their internal thoughts (numbers inside the models) rather than writing long messages to each other. They call this system RecursiveMAS (Recursive Multi-Agent Systems).
Key questions the paper asks
The researchers focus on simple, practical questions:
- Can AI teamwork get better if the teammates pass ideas back and forth several times (a loop) before giving an answer?
- Is it faster and more accurate to share “hidden thoughts” (internal signals) instead of full-blown text messages?
- Can we improve the way the team works together without retraining all the big models from scratch?
How it works (in everyday language)
Think of a team solving a tough puzzle:
- Each teammate has a role (like Planner, Critic, Solver).
- Instead of writing long notes to each other after every step, they pass short, secret signals that capture what they’re thinking.
- They go through several rounds of this, refining their shared plan each time, and only write the final answer at the end.
Here are the main pieces of their approach, explained with analogies:
- “Latent space” = the AI’s internal “thoughts.” These are numbers inside the model that summarize meaning, like a mental sketch instead of a full paragraph.
- Recursive loop = a do-improve-do-again cycle. The team repeats short rounds of thinking and sharing to refine their solution.
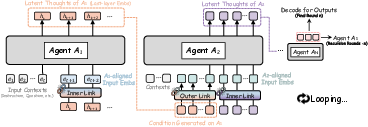
- RecursiveLink = a tiny “translator” that helps teammates pass these internal thoughts smoothly.
- Inner link: helps a single agent “talk to itself” from one step to the next, like keeping a running thought process.
- Outer link: helps one agent pass its thoughts to another agent, even if they use different “dialects” (different model sizes or types).
- Residual connection (inside the tiny translator): this is like keeping the original message and adding a small tweak on top, so meaning isn’t lost.
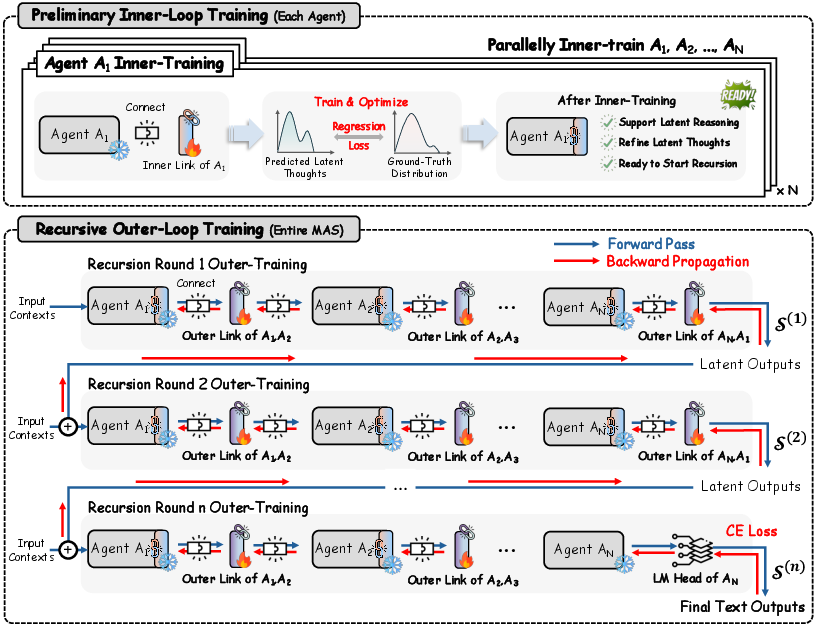
- Training in two simple phases:
- Inner loop “practice”: each agent learns to keep its internal thoughts consistent over steps.
- Outer loop “team practice”: the entire team learns to pass and refine thoughts together over several rounds, so everyone contributes to the final answer.
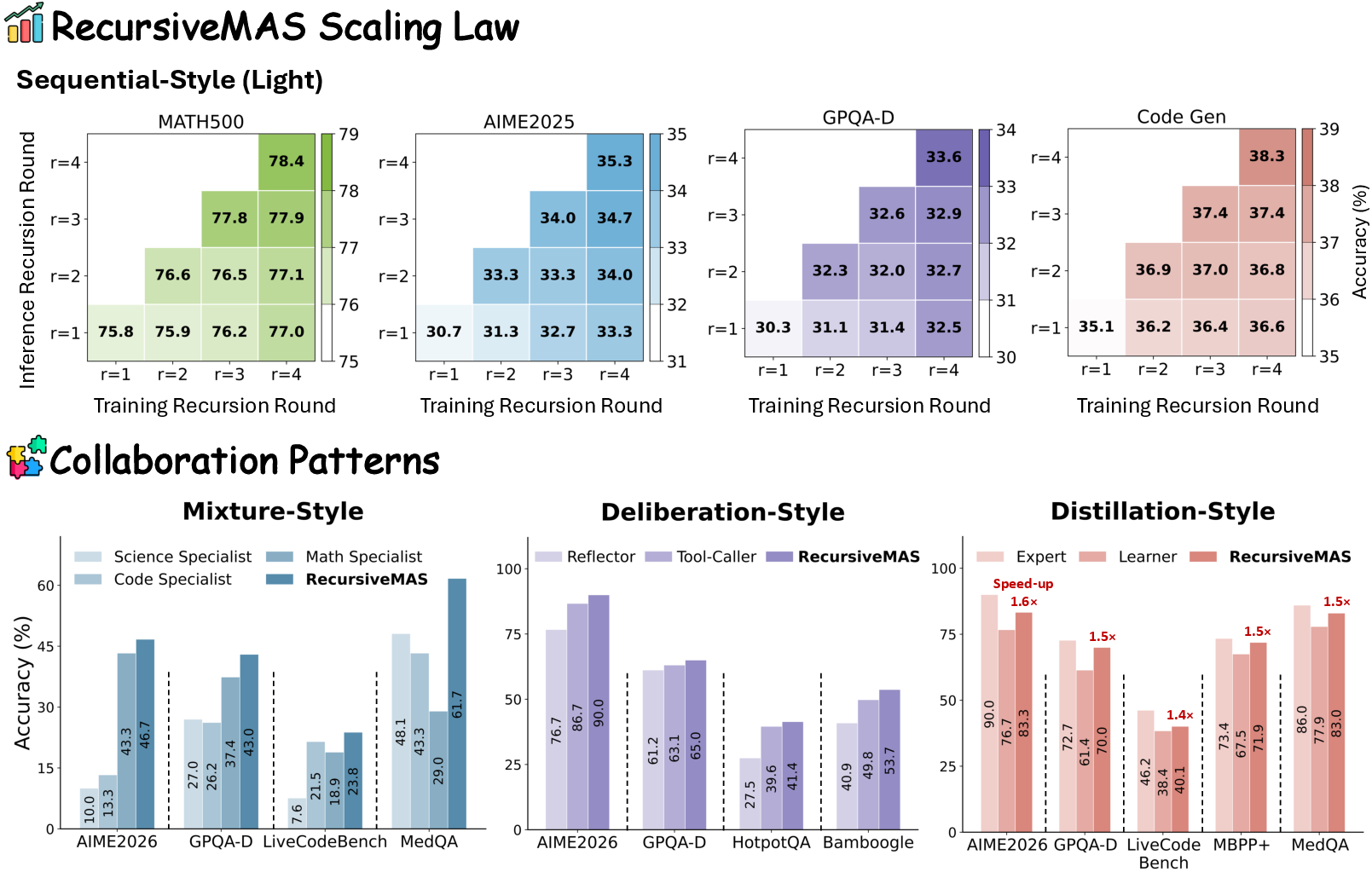
The paper also tries four teamwork styles to show the idea is flexible:
- Sequential: Planner → Critic → Solver, step by step.
- Mixture of experts: Math, Science, and Code experts think in parallel; a Summarizer blends their ideas.
- Distillation: a small, fast Learner improves by working with a larger Expert.
- Deliberation with tools: one agent thinks; another calls tools like Python or a search engine.
What they found and why it matters
In tests across 9 benchmarks (math, science, medicine, search, and coding), their method:
- Was more accurate on average: about an 8% improvement compared to strong alternatives.
- Was faster: about 1.2× to 2.4× speedup.
- Used fewer tokens (less text generated, which saves cost/time): 35% to 76% fewer tokens.
Why this happens:
- Sharing internal thoughts is faster than writing and reading long text at every step.
- Training the small “translator” modules (not the entire big models) lets the whole team improve together without huge compute costs.
- Their math analysis shows two advantages:
- Runtime: passing internal signals avoids expensive “decoding to words” over and over.
- Learning stability: training through these internal links keeps gradients (learning signals) healthy, while text-based loops can make gradients fade, slowing or breaking learning.
What this could mean in the future
This approach suggests a practical path to smarter, faster AI teams:
- Teams of smaller models can collaborate efficiently, saving time and money.
- Different teamwork styles (pipeline, expert groups, teaching, tool use) all benefit from quiet, internal coordination.
- It could improve applications like tutoring (math/science step-by-step), coding assistants, medical Q&A, and research tools.
- Because only small add-on modules are trained, it’s easier to adapt to new tasks and mix different models.
In short, the paper shows that getting AI models to “think together” in multiple short, quiet rounds—by sharing internal thoughts instead of long messages—can make teams both smarter and faster.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of specific gaps and unresolved questions to guide future research.
- Theoretical assumptions and coverage
- Gradient stability proof relies on low-entropy token assumptions and “Realistic Assumptions” deferred to the appendix; it remains unknown how gradient behavior changes under high-entropy decoding, high-temperature sampling, or noisy tool outputs.
- The analyses focus on vanishing gradients; potential exploding gradients, noise amplification, or bias accumulation across many recursion rounds are not characterized.
- Runtime complexity omits practical factors such as KV-cache reuse, memory bandwidth, inter-agent data movement, and GPU/TPU parallelization overhead; a tighter, hardware-aware analysis is missing.
- Training methodology and optimization
- The framework freezes all LLMs and trains only the links; it is unclear how much performance is left on the table versus jointly fine-tuning (e.g., LoRA on selected layers) and how to safely co-train links and agents without instability.
- Credit assignment through long recursive traces may be memory-intensive; strategies like truncated backpropagation, gradient checkpointing, or synthetic gradients are not explored.
- The inner-loop target uses ground-truth text fed through the model’s input embeddings, which requires access to proprietary embedding layers; applicability to API-only or closed-weight LLMs is not addressed.
- Outer-loop learning in the presence of non-differentiable components (e.g., external tools, retrieval, code execution) is under-specified—how are gradients handled or approximated when tools participate in the loop?
- No ablation on training data composition, scale, and curriculum; sensitivity to domain mix and data quantity, and potential for overfitting or domain bias, are unknown.
- Architecture and RecursiveLink design
- Only shallow MLP residual projections are evaluated; alternatives such as cross-attention adapters, gating/routing layers, normalization schemes, or deeper projections are not systematically explored.
- Robustness of the links to mismatched tokenizers, positional encodings, and architecture idiosyncrasies (e.g., RoPE variants, embedding normalization) across heterogeneous models is untested.
- The method assumes direct access to last-layer hidden states and input embedding layers; a general mechanism for models that do not expose these internals is not provided.
- The combination strategy E_A2 ⊕ R_out(H_A1) lacks detailed handling of sequence length alignment, positional offsets, and segmentation—potential position drift or interference is not analyzed.
- The “last agent only decodes” design creates a single-point decoding bottleneck; potential gains from multi-agent decoding, ensemble decoding, or late fusion are not explored.
- Recursion schedule and adaptivity
- Recursion depth is fixed a priori; criteria for adaptive halting (confidence-based stopping, utility thresholds) and their effects on accuracy/efficiency trade-offs are not studied.
- Stability and performance for deeper recursion (beyond r=3) are unknown—risks of representational drift, oscillations, or limit cycles are unexamined.
- Asynchronous or event-driven interaction (non-synchronous updates, variable-length per-agent steps) is not considered; the framework assumes synchronous, looped rounds.
- Scalability and systems aspects
- Scalability to many agents (N≫4), larger backbones (e.g., 70B+), and distributed multi-GPU/TPU settings is unevaluated; memory footprint and communication costs of latent transfers are not reported.
- The effect of KV-cache reuse, batching, and pipeline parallelism on speedups is not detailed; wall-clock breakdowns (model compute vs. link compute vs. data transfer) are missing.
- Robustness to quantization and compression (e.g., 4/8-bit weights, low-precision activations) of agents and links, and resulting impacts on accuracy and gradient flow, are untested.
- Generalization and applicability
- Transferability of learned links is unclear: if an agent is replaced or upgraded, does the outer link require full retraining, or can it adapt with few-shot updates?
- Applicability to multimodal agents (vision, audio) and cross-lingual tasks is not evaluated; whether the same latent-link approach works for heterogeneous modality encoders/decoders remains open.
- Tasks are primarily short-form QA and coding; effectiveness on long-form generation, step-by-step explanations, interactive dialogue, and planning tasks is untested.
- Tool-integrated settings are included but without granular analysis of tool latency, failure modes, or API constraints (rate limits, partial failures) and how recursion interacts with them.
- Robustness, safety, and interpretability
- Susceptibility to adversarial latent perturbations, distribution shifts, and noisy cross-agent signals is not studied; defenses or regularizers for robust latent transfer are absent.
- The latent interaction reduces intermediate text, improving efficiency but sacrificing human-auditable traces; methods for interpretability, attribution, or auditing of latent exchanges are not provided.
- Privacy/security implications of passing rich hidden states across agents (potential leakage of sensitive info or model internals) are not discussed; mechanisms for redaction, encryption, or differential privacy in latent space are missing.
- Calibration, hallucination rates, and factuality under recursion are not measured; trade-offs between efficiency gains and reliability are unclear.
- Evaluation scope and fairness
- Benchmarks do not include real-world, noisy, or out-of-domain scenarios; robustness and generalization under covariate shift are unknown.
- Statistical significance across tasks and strong baselines is only lightly reported; more rigorous tests, larger runs, and hyperparameter sweeps for baselines are needed to confirm gains.
- The comparison set omits latent-communication alternatives (e.g., cross-attention fusion between agents, router-based MoE across models) beyond a few baselines; a broader comparison would clarify where the gains come from.
- Design choices and ablations
- No ablation on the number of latent steps per agent (m), per-agent contribution, or the impact of varying N; how performance/efficiency scale with these choices remains unclear.
- Link parameter counts, training time, and energy consumption are not quantified; the true cost of training links versus returns in speed/accuracy is not established.
- Sensitivity to temperature, nucleus sampling, and decoding strategies (especially for code and long-form tasks) is not explored.
These gaps suggest concrete next steps: develop adaptive halting, robust and interpretable latent-transfer mechanisms, hardware-aware training/inference, broader task coverage (multimodal, long-form), scalable/distributed implementations, and deeper theoretical analysis under realistic, high-entropy and tool-mediated conditions.
Practical Applications
Below is a concise mapping from the paper’s findings to concrete applications. Each item names possible sectors, sketches a viable tool/product/workflow, and lists key dependencies and assumptions that affect feasibility.
Immediate Applications
These are deployable with current open-weight LLMs and common serving stacks (e.g., HuggingFace Transformers, vLLM, TensorRT-LLM), by training the lightweight RecursiveLink modules and leaving base model weights frozen.
- System-level acceleration and cost reduction for existing multi-agent assistants
- Sectors: software, customer support, education, healthcare (non-diagnostic), finance (research), enterprise search
- What: Replace text-based agent-to-agent messaging in current frameworks (e.g., AutoGen, LangGraph/LangChain) with latent-space links. Expect 1.2×–2.4× end-to-end speedups and 35%–75% token reduction at recursion depth r=1–3, cutting latency and API bills while improving accuracy on reasoning-style workloads.
- Tools/workflow:
- A “RecursiveLink Adapter” library for Transformers that exposes last-layer states and injects inner/outer links; drop-in wrappers for agent orchestration stacks.
- A “Recursion Depth Scheduler” that sets r by SLA/cost targets.
- Assumptions/dependencies:
- Access to hidden states and input embedding layers (typically feasible for open-weight models).
- Agents must run on infrastructure allowing custom forward passes; closed APIs without latent access limit applicability.
- Cross-model hidden-size mismatches resolved by the outer link’s learned projection.
- Parameter-efficient system co-adaptation on proprietary data
- Sectors: enterprise AI platforms, regulated industries, SMBs with limited fine-tuning budgets
- What: Fine-tune only RecursiveLink modules (tiny parameter count) to adapt a multi-agent stack to domain-specific corpora (e.g., support tickets, internal wikis) while keeping all base LLMs frozen.
- Tools/workflow:
- “Inner-Outer Loop Trainer” that warms up inner links (latent-thought matching via cosine loss) and then co-optimizes outer links end-to-end with cross-entropy on final outputs.
- MLOps support for versioning link weights per department or product line.
- Assumptions/dependencies:
- Representative training data reflecting real tasks.
- Legal ability to use open-weight models with internal data; adherence to data governance.
- Low-latency coding copilots with mixture-style latent collaboration
- Sectors: software engineering, data science
- What: Mixture-of-specialists (code, math, reasoning) that interact in latent space and are summarized by a lightweight aggregator agent. Demonstrated gains on MBPP+/LiveCodeBench-like tasks.
- Tools/workflow:
- IDE plugins (VS Code/JetBrains) that route prompts through latent-linked specialists; optional Python tool-calling in deliberation style.
- CI bots that use r=1 for fast checks and r=2–3 for “slow mode” gatekeeping.
- Assumptions/dependencies:
- On-device or on-prem inference for small 2–10B models, or cost-effective cloud serving.
- Guardrails for code execution tools.
- Distilled “expert→learner” deployments for production SLAs
- Sectors: finance (quant research pre-checks), healthcare ops (non-clinical triage), enterprise analytics
- What: Pair a larger “expert” with a smaller “learner” agent using outer links to retain accuracy while preserving the learner’s latency advantage (≈1.5× faster than expert alone in the paper).
- Tools/workflow:
- Canary deployments comparing expert-only vs. RecursiveMAS-distilled learner; rollout learners to most traffic with auto-escalation to experts on low-confidence cases.
- Assumptions/dependencies:
- Confidence estimation or risk triggers for expert escalation.
- Monitoring for distribution shifts.
- Tool-integrated latent deliberation for retrieval, search, and calculators
- Sectors: enterprise search, customer support, education (math tutoring), BI dashboards
- What: Couple a “Reflector” (inner thinking) with a “Tool-Caller” (Python, retrieval/search APIs). Latent exchanges reduce chatter while improving tool-use quality; demonstrated on HotpotQA/Bamboogle-like tasks.
- Tools/workflow:
- “Latent Tool Router” that passes tool inputs/outputs through outer links; batch tools for throughput.
- Assumptions/dependencies:
- Reliable tool sandboxes and API quotas.
- Proper joining of tool results into latent streams.
- Educational tutoring for math/science with sequential latent reasoning
- Sectors: education, EdTech apps
- What: Planner–Critic–Solver chains in latent space to provide step-wise solutions with fewer tokens and better accuracy on math/science benchmarks; surface explanations at the end of the final round.
- Tools/workflow:
- On-device 3–5B models for privacy-preserving homework assistants; optional cloud fallback for hard problems (higher r).
- Assumptions/dependencies:
- Clear UI affordances for showing final rationale if intermediate latents are not human-readable.
- Age-appropriate safety filters.
- “Green AI” cost/carbon controls in procurement and ops
- Sectors: policy, public sector IT, sustainability programs, cloud FinOps
- What: Use token reduction and speedup as procurement KPIs; integrate recursion depth and token budgets into SLOs; quantify carbon savings from reduced decoding throughput.
- Tools/workflow:
- Dashboards that track “tokens saved,” “speedup at r,” and “cost per correct answer.”
- Assumptions/dependencies:
- Carbon accounting models for inference workloads.
- Consistent measurement protocols across vendors.
- Research instrumentation for recursion scaling and gradient stability
- Sectors: academia, industrial research
- What: Benchmarks and ablation studies on inner/outer link designs; analyze training-vs-inference recursion scaling; replicate gradient stability advantages vs. text-based recursion.
- Tools/workflow:
- Open evaluation harness that varies recursion at train/infer time and logs accuracy/latency/tokens; plug-in link architectures (residual 1–2 layers, etc.).
- Assumptions/dependencies:
- Access to diverse open models (Qwen, Llama, Gemma, Mistral) and tasks.
Long-Term Applications
These require further research, engineering, standardization, or regulatory clearance to be production-ready at scale.
- Cross-vendor latent interoperability standard
- Sectors: software, cloud, model providers, standards bodies
- What: A spec for exposing/consuming latent states (shape, normalization, positional conventions) and negotiation for outer-link alignment across different model families.
- Potential products:
- “Latent Interop SDK” with calibration suites and conformance tests.
- Assumptions/dependencies:
- Vendor buy-in; legal/privacy considerations for sharing internal representations.
- Multi-modal recursive agent systems (vision, speech, action)
- Sectors: robotics, autonomous vehicles, assistive tech, AR/VR
- What: Extend inner/outer links to vision encoders, speech decoders, and control policies so perception–planning–control agents collaborate in latent space with stable gradients and low latency.
- Potential products:
- “Latent Sensor Hub” bridging image/audio embeddings to planners; safety monitors for control loops.
- Assumptions/dependencies:
- Robust cross-modal projection learning; real-time constraints; safety certification.
- Federated/edge–cloud recursive collaboration
- Sectors: mobile, IoT, automotive, healthcare
- What: Small learner agents on-device with periodic cloud expert assists via outer links; privacy-preserving distillation and on-device inference for responsiveness.
- Potential products:
- “Recursive Edge Runtime” with adaptive r based on battery/network; encrypted latent exchange.
- Assumptions/dependencies:
- Efficient secure transport of latents; on-device accelerators; privacy regulation compliance.
- Hardware/software co-design for latent recursion
- Sectors: semiconductors, cloud accelerators
- What: Kernels and memory layouts optimized for repeated forward passes on the same layers with small residual adapters; caching of attention/MLP activations across rounds.
- Potential products:
- “RLM/MAS-optimized” inference stacks in TensorRT-LLM, vLLM, or custom ASIC features (adapter-friendly dataflows).
- Assumptions/dependencies:
- Stable operator-level APIs; evidence of at-scale adoption.
- Safety, auditing, and compliance for latent communications
- Sectors: policy, regulated industries, AI governance
- What: Methods to audit or summarize latent exchanges without defeating efficiency gains; red-team tools for latent-channel misuse; differential privacy for latents.
- Potential products:
- “Latent Audit Layer” that periodically reconstructs proxy text summaries from latents for logging.
- Assumptions/dependencies:
- Reliable, low-overhead interpretability; regulatory guidance for non-text agent communication.
- Adaptive recursion controllers and learning-to-recur online
- Sectors: platform engineering, A/B experimentation, RL for reasoning
- What: Policies that choose recursion depth and agent routing per query based on confidence, cost, or time budgets; reinforcement learning over inner/outer links with real feedback.
- Potential products:
- “Recursion Policy Server” integrated with feature stores and bandit/RL pipelines.
- Assumptions/dependencies:
- Accurate confidence estimation; safe exploration; guardrails for degenerate loops.
- High-assurance decision support (e.g., clinical, legal) with certified performance
- Sectors: healthcare, legal, compliance
- What: Latent-recursive systems that pass prospective trials and meet regulatory standards for specific, bounded tasks (e.g., guideline retrieval + reasoning with human-in-the-loop).
- Potential products:
- “Certified Triage Copilot” using distillation-style learners with escalation-to-expert and full audit trails.
- Assumptions/dependencies:
- Clinical validation, post-market surveillance, liability frameworks; human oversight.
- Organizational AI operating systems using hierarchical recursive MAS
- Sectors: enterprises, research labs
- What: Multi-level Planner–Critic–Solver graphs where teams of agents operate with latent loops across departments (R&D, Legal, Finance), sharing calibrated outer links.
- Potential products:
- “OrgGraph” platforms that provision agent teams, links, and governance at the business-unit level.
- Assumptions/dependencies:
- Data boundaries and access control over latents; change management and training.
Notes on feasibility across applications:
- The reported gains (accuracy, speed, token savings) were demonstrated on reasoning/search/code benchmarks with 1.5B–10B models. Scaling behavior and stability on much larger or highly domain-specific models require validation.
- Gradient stability advantages hinge on assumptions (e.g., confident tokens) and may vary with task distribution.
- Closed-source LLM APIs that don’t expose hidden states limit immediate deployability; the strongest fit is with open-weight models and modifiable serving stacks.
- Latent-space communication reduces textual logs by design; governance and observability solutions are important for regulated settings.
Glossary
- Agentic recursion: A recursive process applied at the system level to improve multi-agent collaboration over iterations. "We call this new system-level agentic recursion framework RecursiveMAS."
- Auto-regressive decoding: Step-by-step generation where each next output is predicted from previous outputs. "In standard auto-regressive decoding, h_t is projected to the vocabulary space to predict the next token."
- Backpropagation: The gradient-based procedure for assigning credit to parameters by propagating errors backward through the computation graph. "Gradient backpropagation assigns each outer link a shared credit signal according to its global contribution to the final prediction"
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "cos(·,·) denotes the standard cosine similarity."
- Cross-agent interaction: Information exchange between different agents during collaborative reasoning. "its latent thoughts H_{A_1} are sent to the next agent A_2 for cross-agent interaction."
- Cross-entropy (CE) objective: A loss function commonly used for classification and sequence prediction that measures the difference between predicted and true distributions. "with the following cross-entropy (CE) objective:"
- Credit assignment: The process of attributing performance gains or errors to specific components or steps in a system. "shared gradient-based credit assignment across recursion rounds."
- Deliberation Style: A collaboration pattern pairing a reasoning-focused agent with a tool-using agent to iteratively refine solutions. "Deliberation Style, where an inner-thinking Reflector is paired with a Tool-Caller"
- Distillation Style: A collaboration pattern where a smaller model learns from a larger expert to gain efficiency while retaining performance. "Distillation Style, where a larger, more capable Expert agent is paired with a smaller, faster Learner agent to distill expert knowledge"
- Entropy: A measure of uncertainty in a probability distribution; lower entropy indicates higher confidence. "if tokens are confident with entropy ≤ ε, where typically ε ≪ 1"
- GELU activation: A smooth, non-linear activation function (Gaussian Error Linear Unit) used in neural networks. "σ(·) is the GELU activation"
- Gradient stability: The property that gradients remain informative (non-vanishing/exploding) throughout training or recursion. "Theorem [Gradient Stability]"
- Gradient vanishing: The phenomenon where gradients shrink toward zero, impeding learning over deep or recurrent computations. "avoiding the gradient vanishing induced by text-based interactions."
- Heterogeneous agents: Agents with different architectures, sizes, or specialties collaborating in a system. "An outer RecursiveLink then bridges hidden representations across heterogeneous agents built on different model types and sizes"
- Inner-Outer Loop training: A two-stage optimization scheme with agent-level warm-up (inner loop) and system-level co-optimization (outer loop). "we pair RecursiveMAS with an Inner-Outer Loop training paradigm"
- Input embedding layer: The layer that maps tokens into continuous vector representations consumed by the model. "the standard input embedding layer Emb_{θ_i} of agent A_i"
- Knowledge distillation: Transferring knowledge from a larger model (teacher) to a smaller one (student). "expert-to-learner knowledge distillation"
- Latent generation: Producing next-step internal representations directly in the continuous space instead of decoding tokens. "latent generation keeps the recurrence entirely in continuous representation space"
- Latent space: The continuous vector space of internal model representations used for reasoning and communication. "casts the entire system as a unified latent-space recursive computation."
- Latent state transfer: Passing internal representations between agents to condition subsequent reasoning. "cross-agent latent state transfer."
- Latent thoughts: Iteratively generated internal hidden states that represent the model’s ongoing reasoning. "We refer to the newly generated latent state h_{t+1} as the model's ongoing latent thought."
- LoRA fine-tuning: A parameter-efficient adaptation method that injects low-rank updates into model weights. "LoRA fine-tuning"
- Mixture Style: A collaboration pattern where domain-specialized agents reason in parallel and are aggregated by a summarizer. "Mixture Style, where a mixture of domain-specialized agents (Math, Code, Science) reasons over the input problem in parallel"
- Mixture-of-Agents (MoA): A baseline framework combining multiple agents’ outputs for improved performance. "Mixture-of-Agents (MoA)"
- Multi-agent system (MAS): A coordinated set of agents that collaborate to solve tasks. "A multi-agent system (MAS)"
- Recursive LLM (RLM): A model that increases reasoning depth by repeatedly applying the same layers across steps. "A recursive LLM (RLM) increases reasoning depth by reusing the same transformation across recurrent steps."
- Recursive Multi-Agent Evolution: The progressive refinement of all agents’ internal states through iterative interactions across rounds. "A recursive evolution is the progressive refinement of ℋ, where each agent adjusts its latent representation through iterative interaction with others and its own reasoning state"
- RecursiveLink: A lightweight residual projection module that preserves and transmits information between latent spaces. "The RecursiveLink ℛ is designed to preserve and transmit this information from one embedding space to another."
- Residual connection: A skip pathway that adds the input to the transformed output to stabilize and ease training. "the residual connection preserves the original latent semantics."
- Residual stream: The flow of representations through residual connections across layers in a Transformer. "the residual stream loops across these layers to increase reasoning depth."
- Runtime complexity: The asymptotic measure of computational cost with respect to input or system parameters. "achieves an end-to-end runtime complexity of Θ(N(md_h2+(t+m)d_h2+(t+m)2d_h))."
- Scaling laws: Empirical relationships showing how performance changes with model or computation scale. "scaling laws with deeper recursion"
- Sequential Style: A collaboration pattern where agents with different roles operate in a pipeline (e.g., Planner, Critic, Solver). "Sequential Style, where we follow the chain-of-agents setting to assign three agents with complementary roles of Planner, Critic, and Solver"
- SFT (Supervised Fine-Tuning): Training a model on labeled data to align outputs with ground truth. "text-based SFT (denoted by \mathcal R_\text{text}(h))"
- Tool-Caller: An agent capable of invoking external tools or APIs during problem solving. "Tool-Caller that can invoke external tools (e.g., Python or search APIs)."
- Transformer: A neural architecture based on self-attention used for sequence modeling. "standard Transformer model"
- Token throughput: The total number of tokens processed or generated by a system during inference. "overall system token throughput"
- Vocabulary-space decoding: Mapping hidden states to token probabilities over the vocabulary to generate text. "per-step vocabulary-space decoding cost m|V|d_h"
Collections
Sign up for free to add this paper to one or more collections.