Natural-Language Agent Harnesses
Abstract: Agent performance increasingly depends on \emph{harness engineering}, yet harness design is usually buried in controller code and runtime-specific conventions, making it hard to transfer, compare, and study as a scientific object. We ask whether the high-level control logic of an agent harness can instead be externalized as a portable executable artifact. We introduce \textbf{Natural-Language Agent Harnesses} (NLAHs), which express harness behavior in editable natural language, and \textbf{Intelligent Harness Runtime} (IHR), a shared runtime that executes these harnesses through explicit contracts, durable artifacts, and lightweight adapters. Across coding and computer-use benchmarks, we conduct controlled evaluations of operational viability, module ablation, and code-to-text harness migration.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about the “playbook” that surrounds an AI agent—the rules and routines that tell it how to break a big task into steps, use tools, remember things, check its work, and stop at the right time. The authors call this playbook a harness. They propose writing this harness in clear natural language so it’s easy to read, edit, and share, and then running it with a shared system that knows how to follow those instructions. They introduce:
- Natural-Language Agent Harnesses (NLAHs): the playbook written in everyday language.
- Intelligent Harness Runtime (IHR): the “referee + coach” system that reads that playbook and makes the agent follow it.
What questions did the researchers ask?
The team focused on three simple questions:
- Do shared rules and a clear playbook actually change how an AI agent behaves and how well it does? (RQ1)
- If the playbook is broken into modules (like “memory,” “checking,” or “search”), can you add or remove these pieces and see clean, fair differences? (RQ2)
- If a harness was originally written as code, can you rewrite it as natural language without losing what it does—and maybe even make it better? (RQ3)
How did they do it? (Explained simply)
Think of the agent as a student doing a project. The harness is the student’s project plan, and the runtime is the teacher making sure the plan is followed.
- Natural-Language Harness (NLAH): The plan is written in plain language and includes:
- Contracts: a checklist of what must be produced, in what format, and when to stop.
- Roles: who does what (like “solver,” “checker,” “researcher”) so the responsibilities don’t mix.
- Stages: the steps (for example: plan → do → verify → fix).
- Adapters/Scripts: the tools and tests the agent can run (like a test suite or a web search).
- State: how to remember progress (what to save and where).
- Failure types: named problems (like “missing file” or “timeout”) and how to recover.
- Intelligent Harness Runtime (IHR): This is the system that reads the natural-language plan and enforces it. It:
- Uses an AI model in the loop to choose the next action.
- Provides safe access to tools (terminal, web, child agents).
- Follows a “charter” (shared rules about what contracts mean, how to manage state, and when to spawn helpers).
- File-backed state: To avoid forgetting, the agent writes important info to files (like keeping a notebook). Later steps reopen those exact files by path so nothing gets lost when the context scrolls away.
They tested this on two types of tasks:
- Coding: fixing real software issues (SWE-bench Verified).
- Computer use: completing tasks on a real desktop (OSWorld).
What did they find, and why does it matter?
RQ1: Do shared rules and a clear playbook change behavior?
Yes. With the full runtime and harness in place, the agent didn’t just change its final score a little—it changed how it worked a lot:
- It made more deliberate steps, used tools more often, and took more time to explore and verify.
- Most tasks didn’t flip from fail to pass or vice versa; instead, the differences showed up on a smaller set of tricky cases.
- More structure didn’t always mean better scores—sometimes it led the agent to spend effort on thorough but off-target work that the benchmark didn’t reward. This shows the harness isn’t just fancy prompting; it really shapes behavior.
Why it matters: The “how” (process) can change a lot even when the “what” (score) changes a little. That means harnesses need to be studied as real system components, not ignored as boilerplate.
RQ2: Can modules be added/removed cleanly?
Yes. Because the harness is explicit, they could turn modules on or off and see targeted effects:
- Helpful modules:
- Self-evolution (a disciplined “try again if checks fail” loop) helped the agent close tasks more reliably.
- File-backed state (writing and reopening files) improved organization and made runs more robust.
- Sometimes harmful or mixed:
- Heavy verification and multi-candidate search added overhead and didn’t always increase the final score, especially when their idea of “success” didn’t match what the benchmark accepts.
- Dynamic orchestration changed which tasks were solved but didn’t uniformly increase the total solved set.
Why it matters: Clear modules make it possible to study what really helps. The best wins came from modules that tightened the path to the benchmark’s acceptance criteria, not just from adding more steps.
RQ3: Can a code harness be rewritten as natural language?
Often, yes—and sometimes it’s better. For a computer-use system (OS-Symphony) on OSWorld:
- The natural-language version scored higher (about 47% vs. 30%).
- Behavior shifted from fragile GUI tweaks to more reliable, file- and artifact-based steps (for example, creating a file and reopening it to prove success).
- Logs were denser and more auditable, not because of random extra actions but because the runtime carefully recorded starts, finishes, and artifacts.
Why it matters: Migrating to a readable, shareable harness didn’t break the system. It often made it more reliable and easier to inspect.
What does this mean for the future?
- Harnesses as first-class objects: Writing the agent’s playbook in natural language—and running it under shared rules—makes it easier to compare systems, reuse good ideas, test one module at a time, and fairly evaluate what works.
- Better science and engineering: With explicit contracts, roles, and state, researchers can run cleaner experiments and automate searching for better harness designs.
- Practical benefits: Teams can transfer harnesses across projects and runtimes, reduce glue code, and debug agents with clearer traces.
- Limits and risks:
- Natural language is less precise than code, so some tricky behaviors are hard to capture exactly.
- The shared runtime itself can influence results, so it must be kept stable for fair tests.
- Easier sharing of harnesses also means risky workflows could spread; good safeguards (review, permissions, sandboxing) are important.
In short, the paper shows that turning an agent’s control logic into clear, executable natural language is not only possible but useful. It helps us see, swap, and improve the pieces that make long, tool-using agents actually work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased as concrete, actionable gaps for future work.
- External validity across tasks: The evaluation covers only two task families (coding and computer use) on small subsets (125 SWE-bench Verified, 36 OSWorld). It remains unknown how NLAHs/IHR generalize to other long-horizon domains (e.g., research, web-browsing, data science notebooks, robotics, planning).
- Scale sensitivity: Results are reported on one random seed and budget; there is no analysis of variance across seeds, larger samples, or full-benchmark runs, limiting statistical confidence and reproducibility.
- Model dependence: All experiments use a single proprietary model (GPT-5.4, “reasoning effort xhigh”). Robustness to model families (open-source vs. closed), smaller/cheaper models, and model-version drift is untested.
- Runtime dependence: Claims of portability are not validated across diverse runtimes. IHR is realized via Codex CLI 0.114.0; the behavior under other execution substrates (different tool stacks, sandboxes, schedulers) is unknown.
- Runtime–harness boundary: “Runtime contamination” is acknowledged but not quantified. Which portions of behavior/performance are attributable to the runtime charter vs. NLAH text remain under-identified.
- Charter design ablations: The runtime charter is treated as a monolith. There is no fine-grained ablation of charter components (e.g., child lifecycle rules, budget governance, permission semantics) to identify which policies drive behavior.
- Determinism and reproducibility: With an in-loop LLM interpreting natural language, the stability of NLAH execution across runs, seeds, and model updates is unmeasured.
- Formal semantics of NLAHs: The “structured natural language” format is not specified as a machine-checked schema or DSL. There is no validation tooling for type/format checking, dead-stage detection, or static analysis of contracts.
- Ambiguity handling: The system’s robustness to ambiguous or conflicting instructions in NLAHs (e.g., inconsistent contracts, overlapping roles) is not evaluated.
- Security and enforcement: Although risks are acknowledged, there is no empirical assessment of permission boundary enforcement, prompt-injection resistance, tool grafting attacks, or supply-chain contamination under IHR.
- Cost–benefit trade-offs: Full IHR substantially increases tokens, calls, and runtime, while success rates change modestly. There is no systematic exploration of where added structure yields net gains per unit cost.
- Budget and effort tuning: Sensitivity to runtime budgets, reasoning effort settings, and step limits is unexplored, leaving unclear how to configure NLAHs/IHR for different cost/performance envelopes.
- Verifier alignment: Verifier stages sometimes diverge from benchmark acceptance. There is no method to align harness-level verification signals with external evaluators or to learn evaluator-aligned verifiers.
- Module interactions: RQ2 adds modules one at a time. Full factorial studies, interaction effects, and ordering sensitivity (e.g., verifier before/after self-evolution) are not analyzed.
- Heavy-module overheads: Multi-candidate search and dynamic orchestration often add cost without gains. The conditions (task features, budgets, tooling) under which they become beneficial are unspecified.
- Long-horizon stress tests: Claims about file-backed state improving robustness are not stress-tested under extreme context growth, restarts, branch merging, or long-running multi-day tasks.
- Concurrency and scaling: IHR supports spawning child agents, but there is no evaluation of concurrent workloads, resource contention, scheduling strategies, or failure cascades in multi-agent settings.
- Migration methodology: The code-to-text migration process is not described (manual vs. automated), and there is no fidelity metric (e.g., coverage of control logic, role/contract preservation, inter-annotator agreement).
- Migration generality: RQ3 only migrates OS-Symphony. It remains unclear how well the approach migrates other harness families (e.g., TRAE, Live-SWE, research agents) and how migration cost scales with harness complexity.
- Attribution in RQ3: The “Code” vs. “NLAH” comparison may conflate harness representation with runtime differences. A clean study running the code harness under the same runtime charter (or matching runtime features) is missing.
- Tooling for adapters/scripts: Adapters and deterministic scripts are central but under-specified; there is no benchmark of adapter correctness, portability across environments, or failure-mode coverage.
- Observability benefits: File-backed state is argued to improve auditability and handoff discipline, but there is no quantitative measurement of debugging time, investigator effort, or failure triage efficiency.
- Human factors: The usability of NLAH authoring (learning curve, time to author/maintain, error-proneness), and its effects on team workflows, versioning, and review processes are unstudied.
- Governance of harness artifacts: There is no discussion or evaluation of versioning, provenance, compatibility management, or schema evolution for NLAHs across teams and releases.
- Automated harness search: While proposed as future direction, there is no implementation or evaluation of automated search/optimization over harness modules, objectives, or constraints.
- Domain-specific constraints: How NLAHs express and enforce domain-specific policies (e.g., compliance, safety-critical protocols in healthcare/finance) is not demonstrated.
- Cross-runtimes interoperability: Concrete adapters or translation layers enabling the same NLAH to run across different runtimes (beyond IHR) are not provided or evaluated.
- Failure taxonomy utility: The paper defines a failure taxonomy but does not measure whether taxonomy-driven recovery materially improves resolution rates or recovery speed.
- Dataset and artifact release: It is unclear whether NLAH artifacts, charters, and logs will be released to support replication, independent ablations, and community comparisons.
- Latency and practicality: OSWorld runs take long wall-clock times (e.g., >2 hours). There is no analysis of latency constraints, user-facing responsiveness, or strategies to meet real-time requirements.
- Evaluation breadth: Beyond success rates and process metrics, other quality dimensions (robustness to environment drift, fairness, stability over updates, catastrophic failure rates) are not reported.
- Standardization prospects: There is no proposed standard or reference schema for contracts, roles, stages, adapters, or state semantics to enable ecosystem-wide comparability and tooling.
Practical Applications
Immediate Applications
The following opportunities can be deployed with current models and tooling by adopting the paper’s Natural-Language Agent Harnesses (NLAHs) and Intelligent Harness Runtime (IHR), which execute harness logic expressed in editable natural language with explicit contracts, roles, stages, adapters, and file‑backed state.
- [Industry | Software/DevOps] Repository‑grounded code repair agents with portable harnesses
- Workflow: Use NLAH contracts (required artifacts, verification gates) and file‑backed state to run TRAE/Live‑SWE–style multi‑stage coding agents across repositories; version harnesses alongside code and run under IHR for consistent semantics and auditing.
- Tools/products: Harness authoring templates; harness CI with module ablations; artifact-ledger storage for patches/tests; “harness registry” per org.
- Dependencies/assumptions: In‑loop LLM with tool access; reliable verifier/test adapters; repo sandboxing; evaluator alignment to acceptance criteria.
- [Industry | IT Ops/RPA] Robust desktop and IT runbooks that close on artifact‑backed evidence
- Workflow: Express runbooks as NLAHs (roles: operator/verifier; stages: plan→act→verify→repair) for tasks like software installs, configuration changes, spreadsheet generation; use artifact paths and explicit validation (e.g., service status, file hashes).
- Tools/products: Desktop IHR runner; permission-scoped tool adapters (shell, package managers, office file APIs); runbook library as NLAHs.
- Dependencies/assumptions: OS sandboxing; deterministic adapters for validation; reliable substrate switching (GUI→API/file) as supported by environment.
- [Industry | Governance/Compliance] Auditable AI agent operations via contracts and charters
- Workflow: Enforce runtime charters (budgets, permission scopes, stop rules) and NLAH contracts to produce durable logs, manifests, and artifacts for audits and incident response.
- Tools/products: Governance console for charter management; artifact-backed audit trails; approval workflows around harness changes.
- Dependencies/assumptions: Clear permission boundaries; provenance tracking; change control for harness text and adapters.
- [Industry | Platform/AgentOps] Fair A/B testing and ablations of agent scaffolds
- Workflow: Evaluate alternative harness modules (e.g., self‑evolution, evidence‑backed answering) under a shared runtime to isolate harness effects on behavior and outcomes.
- Tools/products: Harness ablation matrix in CI; standardized reporting of tokens, calls, runtime, and flip sets; benchmark packs for SWE/OS tasks.
- Dependencies/assumptions: Comparable runtime charters; budget caps; consistent tool stacks across runs.
- [Industry | Knowledge Work] Multi‑agent workflows with explicit role boundaries and artifact handoffs
- Workflow: Use NLAH roles (researcher, solver, verifier) and IHR child‑agent APIs for literature reviews, market scans, due diligence pipelines with artifact‑backed closure.
- Tools/products: Spawn/wait child‑agent adapters; evidence manifests; cross‑task reusable role prompts.
- Dependencies/assumptions: Reliable tool adapters (web search, retrieval, parsing); data access policies; cost controls.
- [Industry | LLMOps/SRE] Better observability and recovery for long‑running agents
- Workflow: Adopt the file‑backed state module to externalize intermediate state (paths/manifests), enabling restart, branching, and delegation without context loss.
- Tools/products: Workspace conventions; artifact role mapping; failure taxonomy dashboards for triage.
- Dependencies/assumptions: Persistent storage; naming/path conventions; long‑context truncation handling by design.
- [Academia] Scaffold‑aware, reproducible agent evaluation
- Workflow: Publish harnesses as NLAHs with module toggles; run under a shared IHR to enable clean comparisons, flips analysis, and trajectory‑level archives.
- Tools/products: Public harness repositories; ablation sheets; dataset loaders with IHR shims.
- Dependencies/assumptions: Community‑agreed runtime charter; benchmark acceptance criteria documented as adapters.
- [Academia | Education] Teaching agent design patterns as executable artifacts
- Workflow: Students author NLAHs demonstrating reason–act, retrieval, verification, memory, and orchestration, executed in sandboxed IHR labs.
- Tools/products: Classroom harness templates; safe tool adapters; graded rubrics for module use.
- Dependencies/assumptions: Campus or cloud sandboxes; cost‑bounded LLMs.
- [Policy/Regulatory] Procurement and risk controls based on explicit agent contracts
- Workflow: Require vendors to supply NLAHs and runtime charters specifying permissions, outputs, and validation; review failure taxonomies and adapter provenance.
- Tools/products: NLAH/charter submission standards; review checklists; approval gates tied to permissions and verifiers.
- Dependencies/assumptions: Standardized schema; reviewer expertise; secure artifact pipelines.
- [Daily Life] Personal desktop automations with reliable closure
- Workflow: Express home/office tasks (e.g., assembling tax docs, generating reports) as NLAHs that finish only after writing/verifying concrete outputs.
- Tools/products: Local IHR “personal agent” runner; templates for common tasks; simple approval prompts for permissions.
- Dependencies/assumptions: Local sandboxing; privacy‑preserving storage; dependable office file adapters.
- [Industry | Content/Docs] Evidence‑backed answering for reports and summaries
- Workflow: Embed “evidence‑backed answering” modules that require citations or attached sidecars before completion.
- Tools/products: Citation extraction adapters; sidecar artifact policies; editorial verification gates.
- Dependencies/assumptions: Access to sources; citation formatting; anti‑hallucination verifiers.
- [Cross‑sector] Migration of existing code harnesses to portable NLAHs
- Workflow: Reconstruct existing agent controllers into NLAHs to standardize behavior (e.g., OS‑Symphony migration) and improve durability via artifact‑backed closure.
- Tools/products: Harness migration playbooks; diff tools for behavior/trace comparison; performance dashboards.
- Dependencies/assumptions: Adapter parity with original systems; acceptance criteria alignment; willingness to refactor brittle GUI logic to deterministic substrates.
Long‑Term Applications
These opportunities will benefit from further research, scaling, standardization, or productization beyond the current prototypes and benchmarks.
- [Industry | Platforms] Harness marketplaces and interoperability standards
- Vision: Distribute vetted NLAH modules (roles, verifiers, file‑backed state) across orgs; click‑to‑compose harnesses with certified adapters.
- Potential products: Harness app store; signed harness packages; compatibility badges.
- Dependencies/assumptions: Standard schemas and charters; security/provenance infrastructure; ecosystem adoption.
- [Industry/Academia] Automated harness search and optimization (AutoHarness at scale)
- Vision: Learn and tune harness modules from trajectory archives to optimize success/efficiency per task family.
- Potential products: Harness optimizers; data‑driven module recommenders; reinforcement loops on frontier cases.
- Dependencies/assumptions: High‑quality logs; robust metrics; guardrails against overfitting and unsafe behaviors.
- [Industry | Enterprise KM] Organization‑wide SOPs as executable NLAHs
- Vision: Encode standard operating procedures (onboarding, vendor setup, compliance checks) as auditable, executable harnesses.
- Potential products: SOP libraries; policy‑linked charters; analytics on SOP conformance and drift.
- Dependencies/assumptions: Integration with IAM, ticketing, and DLP; change management practices.
- [Policy/Regulatory] Regulatory‑grade agent oversight with formalized charters
- Vision: Charter templates with machine‑enforced permission scopes, budgets, and stopping conditions; certify safety/quality for high‑risk sectors (healthcare, finance).
- Potential products: Certifiable runtime profiles; regulator‑approved verifier suites; red‑team harness packs.
- Dependencies/assumptions: Consensus on standards; liability frameworks; secure sandboxes and supply‑chain controls.
- [Industry | Productivity Suites] Substrate‑aware automation that prefers deterministic APIs over GUI
- Vision: Agents automatically select file/API operations when possible for reliability, falling back to GUI with repair loops if needed.
- Potential products: Substrate switchers; office/EHR/ERP adapter kits; reliability scoring per action type.
- Dependencies/assumptions: Rich API surfaces; permissioned access; robust detection of state and success signals.
- [Research] Long‑horizon autonomy via file‑backed state and context folding
- Vision: Combine compaction‑stable artifacts with adaptive context folding to sustain multi‑hour/day tasks.
- Potential products: Context managers attuned to harness paths/manifests; resumable job controllers.
- Dependencies/assumptions: Storage policies; continuity across restarts; long‑context model capabilities.
- [Industry | Multi‑tenant Infra] Shared harness runtimes in data centers
- Vision: Multi‑tenant IHR services with quotas, billing, and isolation for internal teams and external customers.
- Potential products: Runtime as a managed service; per‑tenant charter enforcement; usage analytics.
- Dependencies/assumptions: Strong isolation; cost governance; adapter lifecycle management.
- [Academia | Benchmarks] Scaffold‑aware benchmark suites with harness tracks
- Vision: Benchmarks that require explicit harness submission and report scaffold‑aware metrics and flips under ablations.
- Potential products: New benchmarks (coding, computer use, research) with harness leaderboards and trace archives.
- Dependencies/assumptions: Community buy‑in; standardized logging; compute budgets.
- [Industry | Tooling] Harness IDEs, linters, and static analyzers
- Vision: Authoring environments that validate contracts, roles, failure taxonomies, and adapter bindings; detect ambiguous or overlapping responsibilities.
- Potential products: NLAH language servers; harness QA gates in CI; converter to/from code harnesses.
- Dependencies/assumptions: Mature NLAH schemas; best‑practice rulesets; test harnesses.
- [Cross‑sector] Compile‑to‑code backends for performance‑critical harnesses
- Vision: Author in natural language, then compile to a typed IR/code for deterministic, low‑latency execution while preserving contracts and artifacts.
- Potential products: NLAH→IR compilers; hybrid interpreters; performance profilers mapping back to NLAH.
- Dependencies/assumptions: Stable IR; fidelity guarantees; traceability for audits.
- [Education/Assessment] Scaffold‑aware evaluation in learning and certification
- Vision: Exams/labs that grade both outcomes and harness design quality (contracts, verification, state discipline).
- Potential products: Autograding harness checkers; libraries of exemplar harnesses; curriculum modules.
- Dependencies/assumptions: Rubrics for harness quality; secure sandboxes; academic standards.
- [Security] Supply‑chain security for harnesses and adapters
- Vision: Signed harnesses/adapters, SBOMs for tool chains, and automated scans for prompt‑injection or malicious hooks.
- Potential products: Harness security scanners; policy enforcement on imports; runtime attestation.
- Dependencies/assumptions: PKI and signing workflows; scanning rules; organizational policy adoption.
- [Healthcare/Finance] Evidence‑linked, permissioned agent workflows
- Vision: Agents that operate within strict charters and produce path‑addressable evidence trails suitable for audits (e.g., claims processing, KYC).
- Potential products: Domain‑specific verifiers; redaction and PHI handling adapters; regulated runtime profiles.
- Dependencies/assumptions: Compliance mapping (HIPAA, SOX, PCI); data governance; rigorous human oversight.
- [Research/Industry] Cross‑model, cross‑vendor portability of harnesses
- Vision: Run the same NLAH across different LLM backends with consistent behavior via the IHR contract layer.
- Potential products: Adapter packs per vendor; portability test suites; fallback behavior specifications.
- Dependencies/assumptions: Comparable tool capabilities; careful prompt/context normalization; evaluation alignment.
- [Content/Knowledge] Procedural memory and skill evolution at the harness layer
- Vision: Experience‑driven updates to harness modules (e.g., refined verifiers, recovery strategies) captured as versioned, testable edits.
- Potential products: Harness evolution pipelines; change impact analysis; skill transfer across task families.
- Dependencies/assumptions: High‑quality experience logs; safe automated edits; review workflows.
These applications leverage the paper’s core advances—explicit contracts and roles, stage structures, deterministic adapters, file‑backed state, failure taxonomies, and a shared intelligent runtime—to make agent control portable, auditable, and comparable across settings. Feasibility depends on reliable tool adapters, sandboxed execution, evaluator/acceptance alignment, and organizational governance for harness change and provenance.
Glossary
- acceptance-gated attempt loop: A control pattern where new attempts proceed only after passing an explicit success criterion. "its main benefit is not open-ended reflection, but a more disciplined acceptance-gated attempt loop that keeps the search narrow until failure signals justify another pass."
- Adapters and scripts: Deterministic hooks that perform concrete actions (e.g., tests, retrieval) invoked by the natural-language harness. "Adapters and scripts: named hooks for deterministic actions (tests, verifiers, retrieval, parsing)."
- agent call: A higher-level invocation that wraps model completion with explicit inputs, outputs, and policies. "We lift a single completion into an agent call bounded by an explicit execution contract: required outputs, budgets, permission scope, completion conditions, and designated output paths."
- artifact-backed verification: Closing tasks by validating concrete artifacts rather than transient UI states. "Under IHR, the same task family tends to re-center around file-backed state and artifact-backed verification."
- benchmark acceptance: The evaluator-defined criteria for considering a task solved in a benchmark. "in ways that do not always align with benchmark acceptance."
- child lifecycle: The policies governing creation, supervision, and termination of subordinate agents. "a runtime charter that defines the semantics of contracts, state, orchestration, and child lifecycle."
- compaction-stable: A state property ensuring persistence despite truncation, restarts, or delegation. "compaction-stable (state survives truncation, restart, and delegation)."
- context curation: Selecting and structuring contextual information fed to models during runs. "the control stack---including state management, context curation, and context folding---can bottleneck performance"
- context engineering: Designing prompts, evidence, and state across steps to guide long runs. "This shift reframes ``prompt engineering'' into the broader practice of context engineering: deciding what instructions, evidence, intermediate artifacts, and state should be made available at each step of a long run."
- context folding: Compressing or summarizing long interaction histories for reuse within context limits. "the control stack---including state management, context curation, and context folding---can bottleneck performance"
- delegated child agents: Sub-agents spawned to handle subtasks under the parent’s supervision. "occur in delegated child agents rather than in the runtime-owned parent thread."
- dynamic orchestration: Adjusting workflow topology or routing decisions at runtime. "Dynamic orchestration is behaviorally real rather than inert because it changes which SWE instances are solved"
- durable artifacts: Persistent outputs saved to storage that can be reopened for later stages. "explicit contracts, durable artifacts, and lightweight adapters."
- evidence-backed answering: Requiring responses to cite or attach explicit, verifiable evidence artifacts. "file-backed state and evidence-backed answering mainly improve process structure."
- execution contract: A formal specification of outputs, budgets, permissions, and completion conditions guiding an agent call. "bounded by an explicit execution contract: required outputs, budgets, permission scope, completion conditions, and designated output paths."
- failure taxonomy: A named set of failure modes that trigger specific recovery strategies. "Failure taxonomy: named failure modes that drive recovery (missing artifact, wrong path, verifier failure, tool error, timeout)."
- file-backed state: Persisting agent state to files/paths so it can be reliably reopened and audited. "We therefore study an optional file-backed state module"
- harness engineering: The practice of designing and refining the control stack around model calls. "Agent performance increasingly depends on harness engineering"
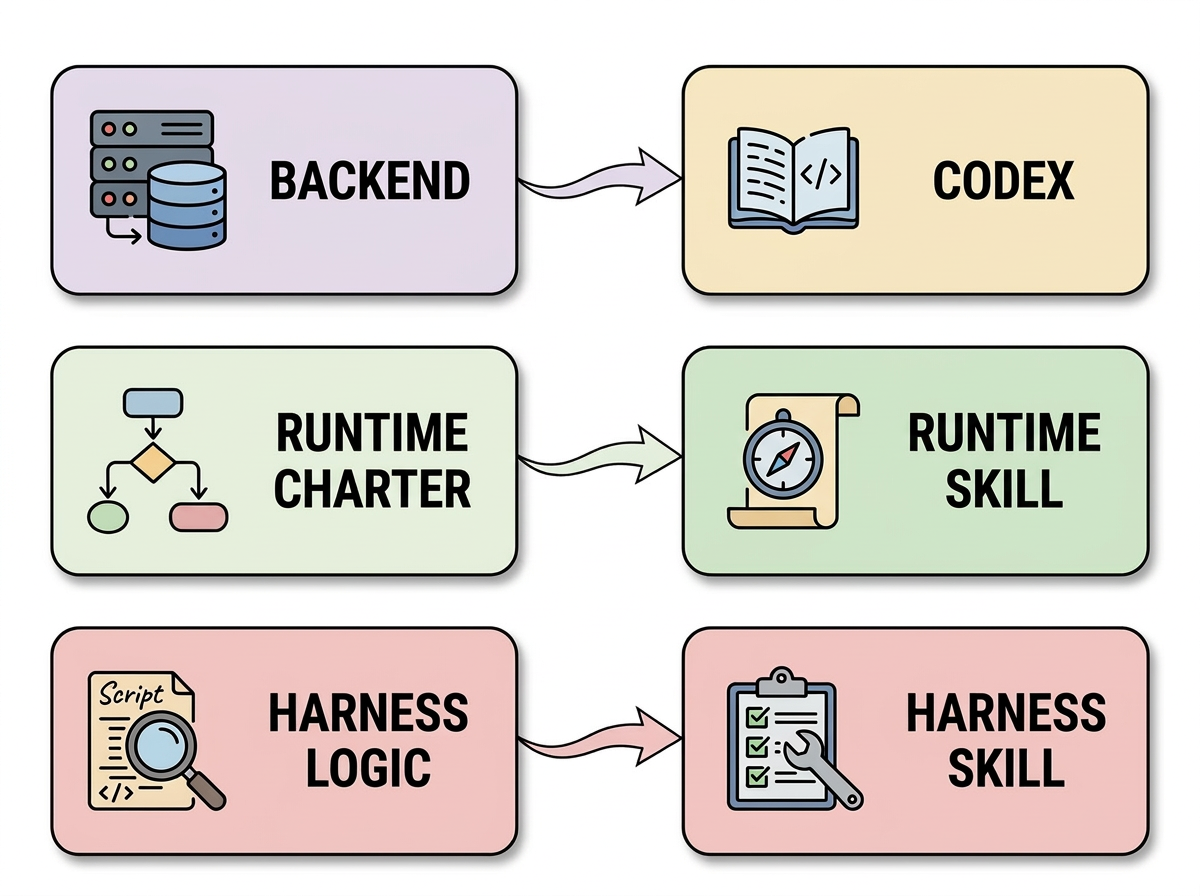
- harness skill: A text artifact that carries benchmark-specific harness logic executed by the runtime. "the harness skill carries benchmark-specific harness logic."
- in-loop LLM: A LLM embedded within the runtime to interpret and advance harness logic step-by-step. "an in-loop LLM that interprets harness logic;"
- Intelligent Harness Runtime (IHR): A shared runtime that interprets and executes natural-language harnesses under explicit policies. "We introduce Natural-Language Agent Harnesses (NLAHs), which express harness behavior in editable natural language, and Intelligent Harness Runtime (IHR), a shared runtime that executes these harnesses through explicit contracts, durable artifacts, and lightweight adapters."
- long-horizon: Describing tasks that span many steps and require prolonged control and memory. "long-context and long-horizon settings have exposed that the control stack"
- multi-agent interface: Backend capabilities for spawning, managing, and integrating multiple collaborating agents. "a backend that provides terminal tools and a first-class multi-agent interface (e.g., spawning and supervising child agents, ingesting returned artifacts);"
- multi-candidate search: Exploring multiple solution candidates in parallel or sequence before selection. "Multi-candidate search makes search behavior more visible, but under the current runtime and budget it appears too overhead-heavy"
- Natural-Language Agent Harnesses (NLAHs): Structured natural-language representations of harness control logic bound to contracts and adapters. "We introduce Natural-Language Agent Harnesses (NLAHs), which express harness behavior in editable natural language"
- path-addressable artifacts: Saved outputs that can be reopened by precise file paths for later processing. "externalizes durable state into path-addressable artifacts, improving stability under context truncation and branching"
- prompt wrapper: A superficial prompt modification that does not materially change system behavior. "The trajectory-level evidence shows that Full IHR is not a prompt wrapper."
- reason--act loops: Iterative cycles where the agent reasons, acts in the environment, and then re-evaluates. "including reason--act loops"
- retrieval-augmented generation: Generating answers with information retrieved from external sources. "retrieval-augmented generation"
- runtime charter: The policy document specifying semantics for contracts, state, orchestration, and child management. "a runtime charter that defines the semantics of contracts, state, orchestration, and child lifecycle."
- runtime contamination: Attribution confound where runtime policies shape outcomes that may be miscredited to the harness text. "Runtime contamination remains a real risk: a strong shared runtime charter may absorb part of the behavior that one might otherwise attribute to harness text."
- runtime skill: The shared textual charter and policies that the runtime uses across tasks. "the runtime skill carries shared charter;"
- scaffold-aware evaluation: Benchmarks that account for differences in harnesses/scaffolds when assessing model performance. "The same pressure appears in scaffold-aware evaluation and increasingly demanding reasoning settings"
- self-evolution: An agent improving its own procedures or instructions over time based on experience or feedback. "Self-evolution is the clearest example of a module that improves the solve loop itself."
- stage structure: An explicit decomposition of work into ordered phases with clear responsibilities. "Stage structure: an explicit workload topology (e.g., plan execute verify repair)."
- state semantics: Definitions of what state is persisted, how, and how it is reopened across steps and agents. "State semantics: what persists across steps (artifacts, ledgers, child workspaces) and how it is reopened (paths, manifests)."
- test-time scaling: Increasing compute or exploration at evaluation time (e.g., more calls/candidates) to boost performance. "interface-level test-time scaling and native tool execution"
- verification gates: Explicit checks that determine whether a stage’s outputs meet criteria to proceed. "prompts, tool mediation, artifact conventions, verification gates, and state semantics"
- verifier: An independent checking component that evaluates candidate outputs for correctness or acceptance. "Verifier adds a genuine independent checking layer"
- workflow generation: Automatically deriving executable workflows from natural-language descriptions. "workflow generation"
Collections
Sign up for free to add this paper to one or more collections.

