- The paper introduces a simulation framework that eliminates teleoperation by leveraging photorealistic 3D Gaussian Splatting for VLA fine-tuning in humanoid tasks.
- It decouples physics and appearance, enabling rapid, operator-free data generation and re-rendering, significantly reducing labor costs.
- Experimental results show that LEGS achieves state-of-the-art sim-to-real transfer with superior task success compared to traditional teleoperated methods.
LEGS: Fine-Tuning Teleop-Free VLAs for Humanoid Loco-manipulation in an Embodied Gaussian Splatting World
Introduction
Humanoid loco-manipulation requires both high-fidelity perception and robust control, yet current VLA fine-tuning protocols are fundamentally bottlenecked by the cost and inflexibility of teleoperated data collection. Traditional simulation-based approaches have been inadequate due to visual domain gaps, especially when mesh-only renderers are used. "LEGS: Fine-Tuning Teleop-Free VLAs for Humanoid Loco-manipulation in an Embodied Gaussian Splatting World" (2606.01458) presents a simulation framework that leverages photorealistic rendering—via 3D Gaussian Splatting (3DGS)—to synthesize large-scale training data without reliance on teleoperation or real robot data collection.

Figure 1: LEGS produces photorealistic, procedurally generated humanoid loco-manipulation data, facilitating robust sim-to-real transfer for VLA models.
The LEGS Simulator Architecture
LEGS is predicated on a dual decoupling which is pivotal for its data transfer properties:
- Physics–Rendering Decoupling: LEGS employs a MuJoCo backend for physically plausible motion and a separate visual frontend that composites mesh-based dynamic foregrounds over a scanned, photorealistic 3DGS background.
- Motion–Appearance Decoupling: Demonstrations, generated procedurally, are independent of visual context, permitting the same motion traces to be re-rendered under arbitrary backgrounds and object appearances with trivial computational cost.
Figure 2: LEGS pipeline overview: scene and object asset creation, physical simulation, procedural demonstration generation, and final rendering with color calibration.
The visual frontend achieves deployment-level photorealism by reconstructing backgrounds with 3DGS optimized from handheld scans and meshes (objects, robot) extracted with SAM3D. A two-stage color calibration procedure precisely matches the composited observations’ statistics to the target robot camera, eliminating residual ISP-induced domain gaps.
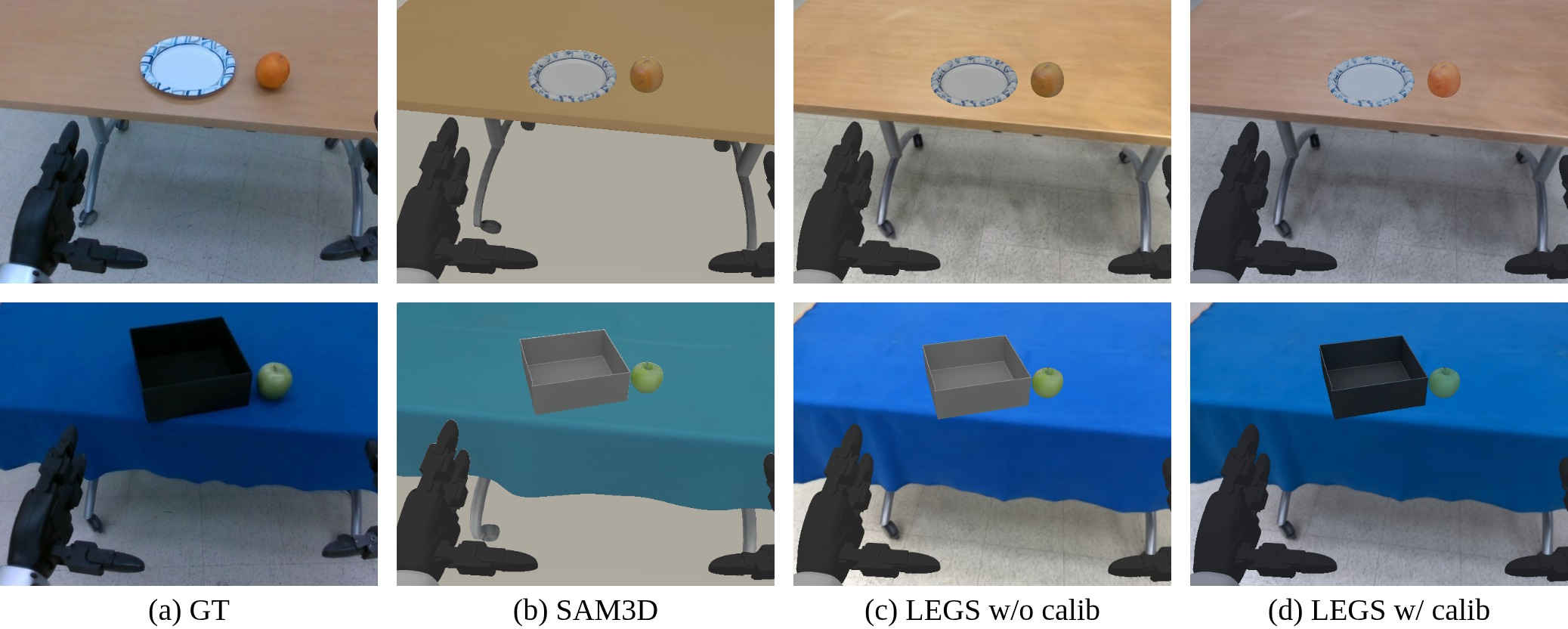
Figure 3: Comparison of egocentric images: real on-robot view, mesh-only baseline, and calibrated LEGS renders. Re-rendering under new assets is trivial and low-cost.
Procedural Motion Generation and Dataset Scalability
Instead of operator-driven teleoperation or per-task human retargeting, LEGS utilizes a procedural motion primitive system. High-level commands (such as Walk, Pick, Place) are parameterized with task-level arguments (e.g., relative object transformations), and successful episodes are programmatically validated before inclusion, guaranteeing only feasible and successful trajectories are used for policy fine-tuning.
Crucially, decoupled dynamics and rendering allow each verified motion trajectory to be re-rendered with arbitrary swapped asset sets, enabling rapid generation of robust, scene-diverse training corpora.
Experimental Protocol and Task Suite
LEGS is evaluated on a Unitree G1 humanoid platform across three pick-and-place tasks:
For each task, policies based on three SOTA VLA backbones (ψ0, π0.5, GR00T N1.6) are fine-tuned using four conditions: Teleop~(50), LEGS~(50), LEGS~(200), and a mesh-only synthetic baseline (SAM3D~(200)). All fine-tuning is performed with identical SONIC whole-body controllers, ensuring comparability.
Key Results
Teleoperation Elimination and Superior Data Efficiency
Policies fine-tuned solely on LEGS data (either (50) or (200)) consistently match or surpass those trained on teleoperated trajectories across all tested backbones and tasks. Notably, on the most difficult Task~3, Teleop~(50) yields zero successes for all backbones, while LEGS~(200) achieves 2–6/10, and LEGS~(50) achieves 1–5/10, demonstrating robustness under extreme embodied control.
Photorealism’s Crucial Role in Sim-to-Real Transfer
Ablation against the mesh-only baseline demonstrates that photorealistic rendering is essential: SAM3D~(200) achieves only 33% mean task completion, whereas LEGS~(200) reaches 67%. The performance gap emerges predominantly in visually demanding, close manipulation stages, as documented by stage-wise success curves.
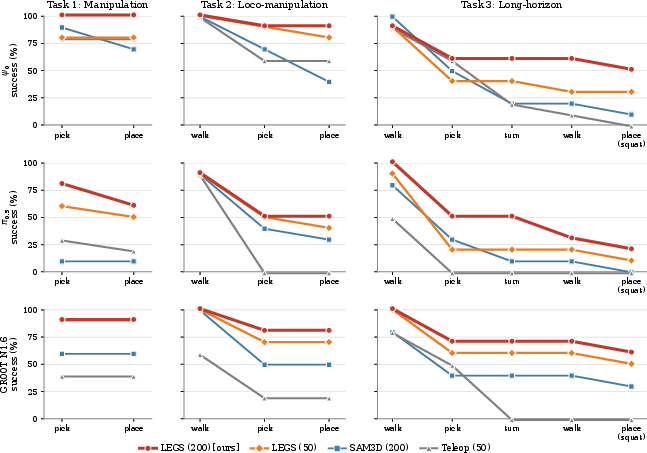
Figure 5: Stage-wise cumulative success rates reveal that photorealism in observation streams substantially boosts success in close-proximity tasks.
Re-Rendering Enables Cheap, Operator-Free Appearance Adaptation
Motion–appearance decoupling allows the entire training corpus to be re-rendered under new objects, backgrounds, and prompts in ∼0.1 hour of compute per condition, a >15-fold reduction in labor compared to teleop. In appearance generalization experiments, only policies trained on appropriately re-rendered (augmented) data maintain high TSR on compositional object-and-scene shifts; all other baselines collapse.
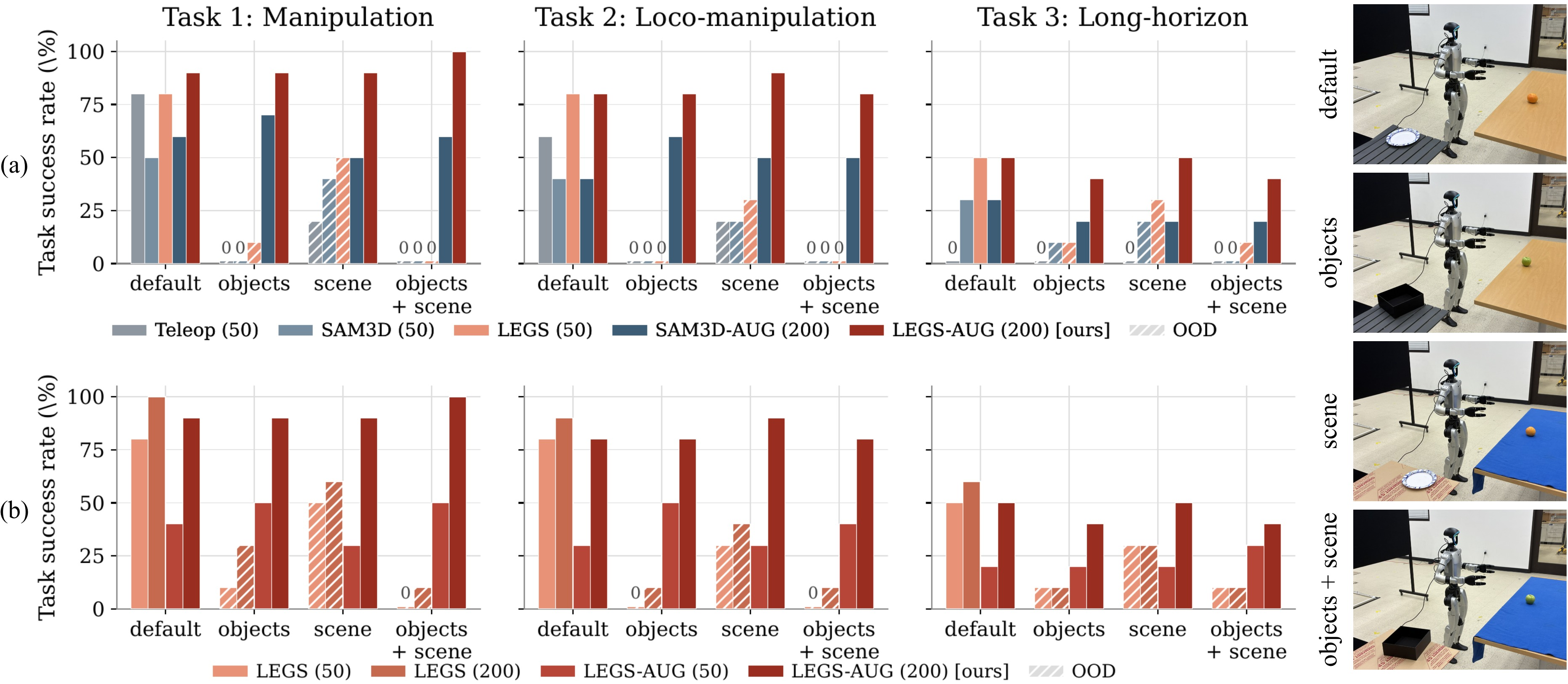
Figure 6: Real-robot transfer success rates vs. appearance variations—LEGS with augmentation remains robust across all conditions, while Teleop and mesh-only baselines fail out-of-distribution.
Limitations
LEGS’ color calibration relies on static camera parameters—deployment in highly dynamic lighting scenarios would require dynamic adaptation. Asset quality for backgrounds is sensitive to the quality of 3DGS scan inputs and static scene assumptions; transient or dynamic objects are not addressed. All evaluations are performed on a single hardware/software stack, and transfer to unseen robot morphologies remains unexamined.
Implications and Future Directions
LEGS fundamentally redefines the data-efficiency frontier for VLA fine-tuning in embodied humanoid loco-manipulation, obviating teleop labor and enabling broad, low-cost domain coverage. The separation of motion and appearance, with compositional re-simulation at scale, offers a template for highly adaptive, robust VLA deployment pipelines. Future extensions should target dynamic/interactive backgrounds, cross-robot and cross-camera generalization, and incorporation of procedural scene generation for more heterogeneous object classes and semantic tasks.
Conclusion
LEGS establishes a rigorous, photorealistic synthetic data pipeline for fine-tuning VLA policies that achieves state-of-the-art sim-to-real transfer in humanoid loco-manipulation—all without teleoperation. By explicitly separating and efficiently recombining physical and visual factors, it enables scalable demonstration generation, compelling sim-to-real transfer performance, and rapid adaptation to novel real-world environments and tasks (2606.01458).
