GRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors
Abstract: Scaling humanoid loco-manipulation requires robot-compatible demonstrations across diverse objects, whole-body motions, and scene geometries, but teleoperation and motion capture are difficult to scale because each collection depends on physical setups, instrumented actors, and robot operation. We present GRAIL, a digital generation pipeline that remains fully virtual until deployment: it composes 3D assets, simulator-ready scenes, and priors from video foundation models (VFMs) to synthesize interactions without rebuilding physical environments or teleoperating the robot. Rather than reconstructing unconstrained in-the-wild videos, GRAIL starts from fully specified 3D configurations in which object geometry, camera parameters, metric scale, environment depth, and a robot-proportioned character are known before video generation and reused during reconstruction. This privileged setup better conditions 4D recovery, allowing model-based object tracking, human motion estimation, and interaction-aware optimization to reconstruct metric 4D human-object interaction (HOI) trajectories with reduced depth ambiguity and morphology mismatch. We retarget the recovered motions to a humanoid robot and train complementary task-general trackers: an object-aware latent adaptor for manipulation and a scene-aware tracker for terrain traversal. GRAIL produces over 20,000 sequences spanning pick-up, object manipulation, sitting, and terrain traversal. Using only GRAIL-generated data, we train egocentric visual policies through a sim-to-real pipeline and deploy them on a Unitree G1 humanoid, achieving 84\% real-world success on diverse object pick-up and 90\% success on stair-climbing.
First 10 authors:





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
GRAIL: Making Humanoids Walk and Use Their Hands by Learning From Fully Virtual Worlds
What is this paper about?
This paper introduces GRAIL, a way to teach humanoid robots to both move around and use their hands (called “loco-manipulation”) without filming people in special studios or teleoperating real robots. Instead, everything is first created in a computer: 3D objects, rooms, cameras, and a human-shaped actor that’s sized like the robot. Then an AI video model suggests how the human should interact with the objects. From that video, the team rebuilds the full 3D motion over time and teaches a real robot to copy it. The big idea is: practice entirely in a “virtual movie set,” then send what was learned to the real robot.
What questions did the researchers ask?
They focused on three simple questions:
- Can we create lots of realistic “robot-ready” demonstrations completely in virtual scenes, without building physical sets or wearing motion-capture suits?
- If we already know the exact 3D scene (object shapes, room layout, camera, real-world size), can we turn an AI-made video into accurate 3D motions that a robot can actually perform?
- Using only these generated motions, can a robot learn general skills like picking up different objects and climbing stairs, and succeed in the real world?
How did they do it?
They followed a four-step process. Think of it like directing a movie in a game engine, then using that movie to train an athlete.
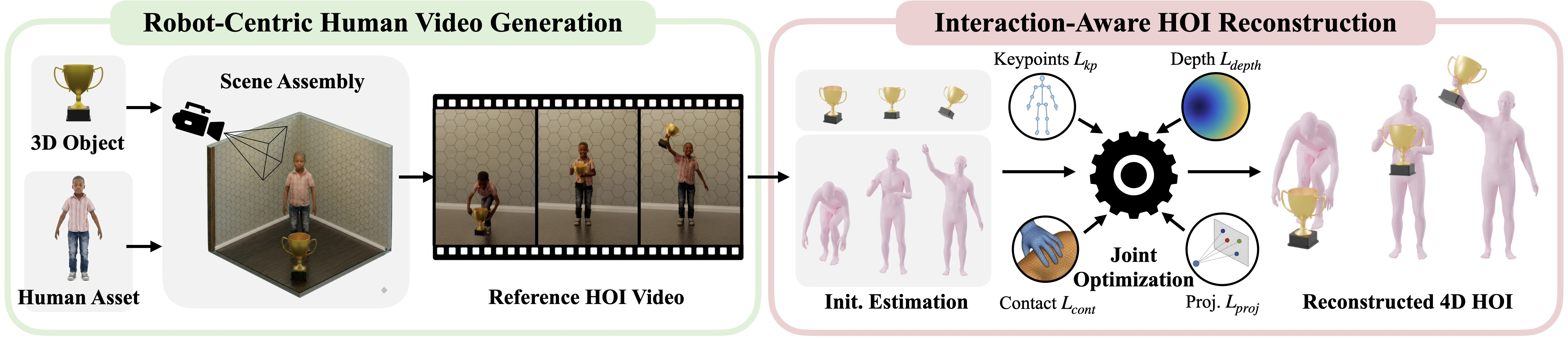
- Build the virtual scene first
- They load a 3D object (like a box or a bottle), put it in a 3D environment, and place a human character that is shaped and sized like the target robot.
- They also fix the camera and set true-to-life scale (so one meter in the computer is one meter in reality).
- This setup is like a carefully measured movie set: nothing is guessed later.
- Ask a video AI to “act” the interaction
- They render the first frame and give it to a video foundation model (a powerful AI that makes videos).
- The AI generates a short clip of the human interacting with the object (picking up, sitting, walking on stairs, etc.) from the fixed camera.
- Rebuild the 3D motion from the video (“4D” = 3D over time)
- Using the known camera, object geometry, and scene scale, they recover the full 3D motion of the human and the object for every frame of the video.
- Imagine tracing a dancer’s positions not just on screen but in real space, second by second.
- They combine:
- Body and hand pose estimators (to get the person’s joints and fingers),
- An object tracker (to get the object’s exact position and rotation),
- An optimization step that fixes mistakes by enforcing contact (hands touching objects, feet on ground), smooth movement, and correct depth.
- Because the scene was specified beforehand, there’s less guessing and fewer errors (for example, no confusion about how far away things are).
- Teach the robot to follow the motion and act in the real world
- “Retargeting”: they convert the human motion into the robot’s joint angles, like translating dance steps from a human coach to a robot athlete.
- They adapt a powerful pre-trained whole-body controller (think of it as the robot’s “movement brain”) in two ways:
- Object-aware adaptor: adds smart hand use for grasping and moving objects, without breaking the robot’s good walking skills.
- Scene-aware tracker: uses a height map (a simple 3D map of nearby ground and steps) so the robot’s whole body adjusts to curbs, slopes, and stairs.
- Finally, they train simple camera-based policies that look through the robot’s own head camera (“egocentric”) so it can act in the real world, not just a simulator.
What did they find, and why is it important?
Using only data generated by GRAIL (no robot teleoperation, no special motion-capture suits), they achieved strong results:
- Scale: Created over 20,000 realistic “loco-manipulation” sequences across picking up items, whole-body manipulation, sitting, and terrain traversal (steps, slopes, etc.).
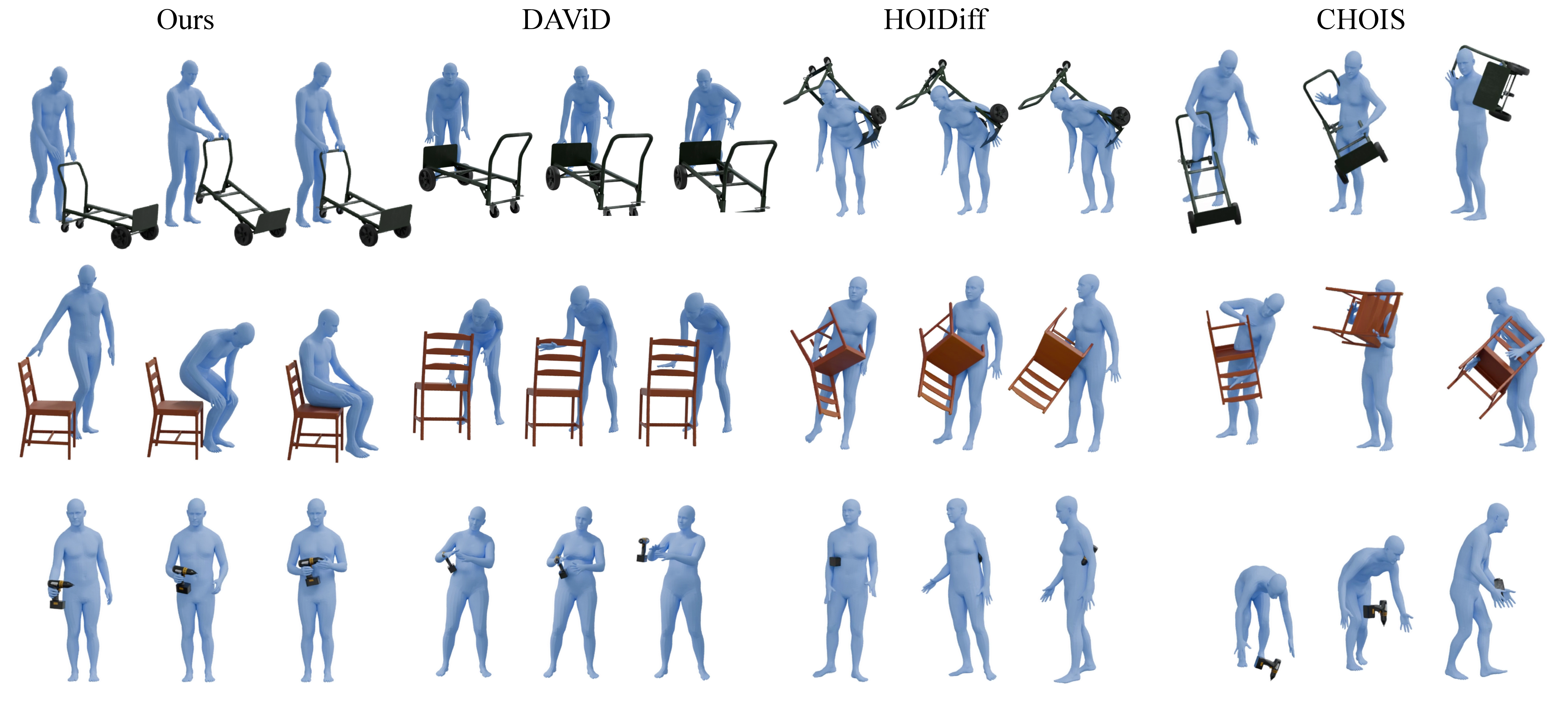
- Quality of generated motions: Compared to prior methods, their sequences had better contact (hands and feet actually touch surfaces), less body–object penetration, smoother motion, and much higher success when reproduced in physics simulation.
- Real robot success:
- Object pick-up: 84% success across a range of everyday items (and 80% on unseen objects).
- Stair-climbing: 90% success.
- All real-world policies were learned from GRAIL-generated data only. Why it matters: Collecting real robot demos is slow and expensive. GRAIL speeds things up by creating large, realistic, robot-compatible data in a purely virtual pipeline. That means faster training, lower cost, and safer iteration.
What does this mean for the future?
- Faster progress: Teams can prototype new tasks by dragging in new 3D objects and environments instead of building physical sets.
- Broader skills: Because the pipeline handles many object types and terrains, robots can learn general skills instead of narrow tricks.
- Safer and cheaper: More practice in simulation reduces wear on robots and the need for human teleoperation.
- A new data source: Alongside real demos, GRAIL-style virtual data can become a standard way to train robots at scale.
Limitations and what’s next
- Requires good 3D assets and a cooperative video model. If the video AI produces odd or inconsistent frames (like sudden object changes), the reconstruction can fail and the sample is discarded.
- Heavy occlusion or very fast movement makes reconstruction harder.
- While the learned controllers are “task-general” within a family (like many types of pick-ups), very different tasks still need new training or fine-tuning.
Overall, GRAIL shows that starting from a well-specified virtual world and using AI videos as “acting hints” is a powerful, scalable way to teach humanoid robots to move and manipulate in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps that remain unresolved and could guide future research.
- Scene specification and camera constraints
- The pipeline assumes a static camera with known intrinsics/extrinsics; it is unclear how to extend reconstruction to moving or handheld cameras while preserving metric consistency and stable contacts.
- Compliance of current VFMs with fixed-camera constraints is not quantified; methods to enforce or verify static-camera adherence during generation are missing.
- Extension to multi-view or multi-camera video priors (and fusion in reconstruction) is unexplored.
- Object and environment diversity
- Interactions are limited to mostly rigid objects; reconstruction and policy learning for articulated (e.g., doors, drawers), deformable (cloth, bags), transparent/reflective, or textureless objects are not addressed.
- Physical properties (mass, friction, compliance) of objects and terrain are not estimated or randomized from video; robustness to mismatched properties in the real world is untested.
- Terrain diversity in deployment is narrow (stairs); generalization to uneven, compliant, slippery, or outdoor terrains (weather, debris) is not evaluated.
- Video-to-4D reconstruction
- Hand poses are held fixed during joint optimization; joint optimization of hands with contact-aware constraints (and uncertainty handling) is left unexplored.
- Contact supervision comes from VLM-derived labels; the reliability of these labels under occlusion and fast motion is not quantified, and alternatives (self-supervised contact discovery, differentiable physics) are not investigated.
- Depth alignment relies on monocular depth (MoGe-2) and background depth from synthetic scenes; robust reconstruction under heavy occlusions, motion blur, severe lighting changes, or complex clutter is not demonstrated.
- The reconstruction objective enforces depth-only alignment for contacts along the viewing direction; full 3D contact consistency (surface-to-surface alignment, friction cones, non-penetration) is not modeled.
- Failure filtering removes a non-trivial fraction of sequences, but the discard rate, biases it introduces, and coverage impact are not quantified.
- VFM generation and content fidelity
- Generated videos can drift in object identity/appearance; mechanisms to enforce object geometry/texture fidelity across frames (e.g., conditioning, tracking-in-the-loop, editing) are not described.
- Prompting coverage and diversity control (e.g., long-horizon, bimanual, tool-use scenarios) are not characterized; no analysis of prompt-to-motion failure modes.
- No metrics or ablations quantify how much the “privileged” 3D setup (assets, camera, scale) reduces reconstruction ambiguity relative to unconstrained VFM videos.
- Retargeting and controller learning
- Only a single humanoid platform (Unitree G1) is tested; cross-morphology generalization (e.g., taller/shorter robots, different hand kinematics, torque limits) is not evaluated.
- Kinematic retargeting fidelity and limits (reachability, joint limits, balance feasibility) are not analyzed quantitatively across tasks.
- The object-aware adaptor maps 2-dim binary hand primitives to 7-DoF hands; this coarse actuation likely limits dexterous manipulation (in-hand regrasping, fine force control) and is not compared against richer hand policies.
- Scene-aware control assumes access to local height maps during training; the gap between simulator height maps and egocentric RGB at deployment (loss of explicit geometry) is not dissected or ablated.
- Policy scope and composition
- “Task-general” policies are trained per family (manipulation vs. terrain); a unified policy that composes object- and scene-awareness (e.g., pick-up on stairs, sit-and-pick) is not attempted.
- Long-horizon sequencing, failure recovery, and behavior switching (approach–grasp–lift–transport–place) are not evaluated; policies are not integrated with higher-level planners.
- Multi-object interactions (stacking, tool-chain use) and contact-rich non-prehensile skills (pushing, pivoting, sliding) beyond brief mentions are not systematically studied.
- Sim-to-real transfer and robustness
- Real-world evaluation is limited (10 trials per object, a small object set); there is no breakdown by lighting, backgrounds, clutter, or occlusion, nor stress tests under domain shifts.
- Inference runs at 10 Hz; impacts of latency, dropped frames, and control rate on dynamic behaviors (e.g., fast stepping, reactive balance) are not analyzed.
- The role and configuration of domain randomization (textures, lighting, camera intrinsics/extrinsics, dynamics) are not ablated to identify critical factors for transfer.
- Safety, reliability, and failure analysis
- Failure modes in the real world (e.g., near-falls, collisions, grasp slips) are not categorized; no safety guardrails, risk metrics, or recovery behaviors are reported.
- External disturbances and robustness to perturbations (pushes, moving objects) are not tested.
- Data scale, bias, and reproducibility
- The overall generation yield, time, and compute costs (64 L40 GPUs, 30k iterations) are substantial; efficiency–quality trade-offs and carbon/compute reporting are missing.
- Potential dataset biases from asset catalogs, scene generators, and failure filtering are not analyzed; no coverage metrics of object categories, sizes, and affordances are provided.
- The extent to which the 20,000-sequence dataset is released, along with assets, prompts, code, and exact VFM versions, is unclear, hindering reproducibility.
- Evaluation methodology
- Comparisons on HOI generation use a small set (20 objects) and include VLM-based “Interaction Score”; sensitivity to rater prompts and inter-rater agreement is not reported.
- Policy baselines do not include methods with dexterous hands or unified policies; broader benchmarks (longer sequences, articulated objects, clutter) are needed.
- Extensions to sensing and feedback
- The system uses RGB-only input; leveraging depth, event cameras, tactile/force sensing, or audio for contact detection and manipulation robustness is not explored.
- Online state estimation of object pose during deployment (beyond policy vision) and closed-loop grasp refinement are not addressed.
- Theoretical and algorithmic questions
- Formal guarantees or bounds on metric accuracy improvements due to the privileged setup (vs. unconstrained video) are not provided.
- Joint optimization currently blends learned perceptual losses and geometric terms; incorporating differentiable physics or contact complementarity constraints remains open.
Practical Applications
Practical Applications of GRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors
Below are actionable, real-world applications derived from the paper’s methods and results, grouped by deployment horizon and mapped to relevant sectors. Each item highlights potential tools/products/workflows and notes assumptions or dependencies that affect feasibility.
Immediate Applications
The following use cases can be piloted or deployed now with existing tools (e.g., Blender/Infinigen, Isaac Lab, Unitree G1, VFMs, SONIC-based controllers), leveraging the demonstrated 84% pick-up and 90% stair-climbing success.
Industry
- Asset-to-skill studios for humanoids (Robotics, Software)
- What: Turn 3D object assets/CADs and procedural scenes into train-and-deployable policies for pick-up, carrying, pushing, sitting, and terrain traversal without teleoperation or motion capture.
- Workflow/product: “Asset-to-Skill Studio” that ingests 3D models (e.g., ComAsset, Robocasa, BIM/CAD), autogenerates HOI videos via VFMs, reconstructs 4D HOI, retargets to target robot (e.g., Unitree G1), and trains task-general trackers and egocentric visual policies.
- Dependencies: High-quality, metric 3D assets; known camera parameters for video generation; VFM reliability; Isaac Lab- or equivalent-sim integration; compute resources (multi-GPU PPO training); robot-ready controller (e.g., SONIC) and morphology-prefitted character.
- Digital pre-commissioning for warehouses and facilities (Robotics, Logistics)
- What: Pre-train site-specific skills (e.g., navigating stairs/ramps, lifting/transporting standard totes, manipulating boxes/carts) in digital twins before on-site deployment.
- Workflow/product: “Digital Commissioning” service that uses facility CAD/BIM and object catalogs to generate tasks, train policies with domain randomization, and validate safety/throughput in sim.
- Dependencies: Access to site geometry and assets; coverage of typical objects/terrains; sim-to-real alignment; safety review for on-site trials.
- Controller upgrades via modular adaptors (Robotics Software)
- What: Integrate GRAIL’s object-aware latent adaptor and scene-aware height-map conditioning into existing whole-body controllers to extend capabilities without retraining from scratch.
- Workflow/product: Controller add-on modules that modulate latent tokens for manipulation and inject terrain context via height maps for stairs/sitting.
- Dependencies: Compatible controller APIs and latent representations; hand actuation support; calibration of scaling factor for latent residuals.
- “Robot-ready” 3D asset certification and marketplaces (Software, 3D Content)
- What: Certify and sell assets with correct metric scale, textures, and physical properties to ensure smooth tracking and policy training.
- Workflow/product: Asset validation toolchain (geometry checks, stable placement via rigid-body settle, canonical camera configs) and a “robot-ready” badge on asset stores.
- Dependencies: Widespread adoption of metadata standards (scale, mass, inertia); consistent textures/materials for vision models.
- QA and safety regression in simulation (Robotics, Compliance)
- What: Build standardized test suites (e.g., stair variability, surface friction, clutter) to validate locomotion/manipulation policies before field deployment.
- Workflow/product: “Terrain & Interaction Packs” (curbs, stairs, slopes, seated scenarios) with scripted evaluations and success metrics for continuous integration.
- Dependencies: Agreement on pass/fail thresholds; synchronization of sim physics with expected field conditions (friction, compliance).
Academia
- Scalable, reproducible HOI and loco-manipulation datasets (Education, Research)
- What: Generate large, metric, physically executable 4D HOI datasets for benchmarking perception, reconstruction, control, and sim-to-real.
- Workflow/product: Open-source pipelines with asset-conditioned generation, depth-aligned reconstruction, and retargeting to canonical humanoids.
- Dependencies: Licensing for assets/VFMs; compute; community standards for metadata (contacts, depth, morphology).
- Benchmarking and ablation testbeds (Research)
- What: Systematic evaluations of 4D HOI reconstruction methods, controller adaptation strategies, and VFMs for interaction priors.
- Workflow/product: Shared tasks with controlled ambiguities (occlusions, fast motions), success metrics (contact distance, penetration, executability).
- Dependencies: Stable baselines (e.g., FoundationPose, SAM2) and reproducible environment seeds.
- Teaching labs with fully digital pipelines (Education)
- What: Hands-on courses where students author tasks from assets to policies, then deploy to lab robots (if available).
- Workflow/product: Course kits (Infinigen/Blender scenes, HOI generation scripts, Isaac Lab configs) and rubrics for sim-to-real checks.
- Dependencies: Lab compute; access to a humanoid or physics-driven digital avatars if hardware is limited.
Policy and Public Sector
- Pre-deployment verification frameworks (Safety, Procurement)
- What: Require digital test reports (stairs, obstacle configurations, manipulation tasks) for public procurement of humanoids.
- Workflow/product: Documentation templates capturing training data provenance, success rates, and sim-to-real validation runs.
- Dependencies: Policy acceptance of synthetic-data-based evidence; guidelines for domain gap and bias reporting.
- Standards for synthetic training data (Regulatory)
- What: Define minimal metadata for asset quality, camera parameters, scale, and contact annotations to support auditability.
- Workflow/product: Draft standards for “robot-ready synthetic data,” aligning with safety and transparency practices.
- Dependencies: Multi-stakeholder consensus (vendors, academia, regulators); versioning and update policies.
Daily Life and Services
- Rapid prototyping of home-assistance skills (Home Robotics, Assistive Tech)
- What: Service providers or integrators build custom pick-and-place and navigation behaviors from household asset libraries (e.g., wet wipes, medicine bottles, stairs).
- Workflow/product: “Home Skill Authoring” kits that map a user’s inventory/house geometry to training scenarios and deploy policies to home robots.
- Dependencies: Availability of household object models and approximate home geometry; careful safety review for human environments; robot hand capability.
- Rehabilitation/elder-care pilots in controlled facilities (Healthcare)
- What: Pilot stair navigation and object retrieval in care facilities using facility-specific assets and scenes for training.
- Workflow/product: Facility digital twin + policy training pack; monitored on-site deployment with fall/interaction safeguards.
- Dependencies: Institutional approvals; clinician oversight; robust fail-safes and emergency stops.
Long-Term Applications
These opportunities require further research, scaling, or ecosystem development (e.g., broader VFM reliability, richer hand dexterity, regulatory maturation, cross-robot standardization).
Industry
- Generalist humanoid skill libraries and marketplaces (Robotics, Platforms)
- What: Curate and share thousands of asset-conditioned skills—downloadable and retargetable across robots and environments.
- Workflow/product: “Humanoid App Store” where vendors publish verified skills with provenance and success statistics; one-click retargeting to site geometry.
- Dependencies: Standardized motion/latent interfaces; cross-robot retargeting reliability; IP/licensing frameworks.
- On-demand, site-adaptive policy generation (Logistics, Retail, Hospitality)
- What: Automatically re-train or fine-tune policies whenever inventory, shelving, or layout changes—no new teleoperation.
- Workflow/product: Continuous integration pipelines that detect asset/layout updates, regenerate tasks, and push OTA skill updates after sim QA.
- Dependencies: Robust change detection from BIM/CAD; fast training loops; safe deployment and rollback mechanisms.
- Dexterous, contact-rich manipulation at scale (Robotics)
- What: Extend beyond binary hand primitives to multi-fingered grasps, tool use, and non-prehensile manipulation with contact planning.
- Workflow/product: Advanced adaptor modules with tactile priors; richer grasp taxonomies; closed-loop perception-control with force feedback.
- Dependencies: High-DOF hands/sensors; better tactile simulation; more reliable hand-video priors and reconstructions.
- Cross-morphology policy distillation (Robotics, OEMs)
- What: Transfer skills across humanoids with different kinematics, using GRAIL’s robot-proportioned reconstruction to reduce morphology gaps.
- Workflow/product: Distillation suites that align latent spaces and automate retargeting across platforms.
- Dependencies: Shared controller abstractions; robust IK/retargeting; generalized trackers.
- Closed-loop self-improvement (MLOps for Robots)
- What: Incorporate real-world logs to synthesize new digital scenes that address failure modes, creating a virtuous train–deploy–collect–retrain cycle.
- Workflow/product: Auto-synthesis of “hard negative” scenarios; continual learning pipelines with safety gating and offline evaluation.
- Dependencies: Data governance and privacy; reliable failure detection; sim fidelity for rare events.
Academia
- Foundational studies on affordances and contact learning (Research)
- What: Use metric, contact-aware synthetic HOI to study physical affordances, generalization, and human–robot interaction principles.
- Workflow/product: Benchmarks for contact inference, affordance prediction, and interaction-aware planning.
- Dependencies: High-quality contact labels; diverse asset libraries spanning edge cases and unusual affordances.
- Physics-informed video generation for interactions (Research)
- What: Co-train VFMs with physical constraints to reduce post-hoc reconstruction and failure filtering.
- Workflow/product: Physics-aware generative models that directly output interaction-consistent 4D sequences.
- Dependencies: Differentiable physics integration; scalable training data; metrics for physical plausibility.
- Standardized digital twin curricula and reproducibility (Education)
- What: Large-scale, shared digital campuses/facilities for robotics education and fair competition.
- Workflow/product: Public digital twins with canonical object sets and benchmark tasks; versioned curricula across institutions.
- Dependencies: Funding and maintenance of shared resources; consensus on tasks/metrics.
Policy and Public Sector
- Certification of synthetic-data–trained robots (Regulatory)
- What: Establish validation regimes where synthetic training is accepted with rigorous sim-to-real evidence (coverage, domain randomization, bias audits).
- Workflow/product: Certification checklists, scenario coverage dashboards, documented sim-to-real gaps and mitigations.
- Dependencies: Regulator buy-in; standardized evidence formats; third-party auditors.
- Data transparency and bias governance (Policy)
- What: Require disclosures on asset sources, scene distributions, and interaction prompts to assess bias and safety risk.
- Workflow/product: Provenance reports and dataset “nutrition labels” for synthetic training pipelines.
- Dependencies: Industry agreement on reporting formats; enforcement mechanisms.
Daily Life and Services
- Personalized home-robot skills from scans (Consumer Robotics)
- What: Consumer-facing tools where a home scan and object list generate personalized policies (e.g., fetching items, climbing custom stairs).
- Workflow/product: “Home Twin” app that builds a digital environment, autogenerates tasks, and updates robot skills over the air.
- Dependencies: Easy home scanning; safety constraints; user-friendly failure handling.
- Patient- and facility-specific healthcare routines (Healthcare)
- What: Tailor navigation/manipulation around mobility aids, furniture layouts, and patient-specific constraints.
- Workflow/product: Secure pipelines integrating clinical constraints, with staff-in-the-loop validation before deployment.
- Dependencies: Regulatory clearance; robust safety monitors; clinical acceptance and workflows.
- Broad K–12 and vocational robotics access (Education)
- What: Low-cost curricula using digital assets and simulation for hands-on learning without costly hardware.
- Workflow/product: Cloud-based training and evaluation; optional deployment bridges for schools with robots.
- Dependencies: Accessible cloud credits; simplified tooling and guardrails for novices.
Notes on cross-cutting assumptions and dependencies
- Technical: High-quality, metric 3D assets; stable VFM outputs for interaction priors; reliable 4D reconstruction (robust to occlusions/fast motion); physics-sim fidelity; controller compatibility and hand DOF availability; significant compute for large-scale training.
- Organizational: Access to CAD/BIM and object catalogs; data governance and licensing for assets and generated videos; safety and compliance processes for sim-to-real deployments.
- Limitations from the paper: Failure filtering remains necessary; performance drops under severe occlusion/fast motions or VFM inconsistencies; new motion families may require fine-tuning; current hand actions are simplified (binary primitives).
Glossary
- 4D HOI: Time-varying 3D human–object interaction trajectories that include motion over time (x, y, z, t). "Retargeted 4D HOI trajectories are converted into robot-action data"
- 6-DoF: Six degrees of freedom for rigid-body pose (3D position and 3D orientation). "the 6-DoF tracker is initialized from the known first-frame pose"
- 6D rotation representation: A continuous parameterization of 3D rotations using 6D vectors to avoid singularities. "the 6D rotation representation~\cite{zhou2019continuity} used for continuous parameterization"
- Basis Point Set (BPS): A compact 3D shape encoding computed as distances to a fixed set of basis points. "a precomputed basis point set (BPS) shape encoding"
- Bidirectional Chamfer distance: A symmetric set-to-set distance measuring average nearest-neighbor distances in both directions between point sets. "and is bidirectional Chamfer distance"
- Depth-only bidirectional Chamfer distance: A Chamfer distance computed only along the camera viewing direction to resolve depth discrepancies. "is a depth-only bidirectional Chamfer distance that penalizes the positional difference along the viewing direction"
- Domain randomization: Training-time perturbations of visuals or physics to improve robustness and transfer. "with visual domain randomization"
- Egocentric visual policy: A control policy that takes first-person (onboard camera) observations to output actions. "train egocentric visual policies"
- Finite Scalar Quantization (FSQ): Discretization of continuous latent variables by scalar quantization into finite codebooks. "via finite scalar quantization"
- FoundationPose: A learning-based 6-DoF object pose tracker that uses known object models and camera parameters. "We fine-tune FoundationPose on its proposed synthetic dataset"
- GENMO: A method for video-based human body pose estimation that outputs SMPL-X parameters. "provides per-frame SMPL-X pose parameters"
- GMR: A motion retargeting method used to map human body motions to humanoid robot kinematics. "allows GMR to retarget the SMPL-X motion"
- Height-map encoder: A neural module that embeds local terrain height maps to condition whole-body control. "together with a height-map encoder for terrain-conditioned whole-body control"
- HOI (Human-Object Interaction): Interactions involving human motion and contacted or manipulated objects. "metric 4D human-object interaction (HOI) trajectories"
- Isaac Lab: NVIDIA’s large-scale simulation and reinforcement learning framework for robotics. "We train each stage with PPO in Isaac Lab"
- Inverse Kinematics (IK): Computing joint angles to achieve desired end-effector poses. "wrist inverse-kinematic (IK) alignment"
- Latent adaptor: A learned module that modifies latent representations in a frozen controller to add new capabilities. "an object-aware latent adaptor"
- Latent token: A compact discrete representation used by a controller to decode actions. "a discrete latent token "
- MANO: A parametric hand model used to represent articulated hand shapes and poses. "MANO parameters for the left and right hands"
- Metric-scale depth: Depth estimates aligned to real-world units (meters) rather than relative scale. "recovering metric-scale depth"
- MoGe-2: A monocular depth estimation model used to predict depth maps from images. "estimate a depth map with MoGe-2"
- PPO (Proximal Policy Optimization): A reinforcement learning algorithm that updates policies with clipped objective functions for stability. "We train each stage with PPO"
- Proprioception: Internal robot state measurements (e.g., joint angles, velocities) used as inputs to control policies. "The adaptor observes proprioception"
- Reference state initialization: Resetting environments to states sampled from reference trajectories to stabilize imitation learning. "we apply reference state initialization at every episode reset"
- Residual motion parameters: Small corrective updates added to initial poses to refine trajectories during optimization. "we optimize residual motion parameters"
- Retargeting: Mapping motion from one morphology (human) to another (robot) while preserving key contacts and kinematics. "retarget the SMPL-X motion"
- SAM2: A segmentation model used to obtain object and human masks from images. "SAM2 segmentation masks"
- Savitzky–Golay filter: A smoothing filter that preserves signal features like peaks while reducing noise. "smoothed with a Savitzky-Golay filter"
- Sim-to-real: Training in simulation and transferring learned policies to real robots. "through a sim-to-real pipeline"
- SMPL-X: A parametric 3D human body model that includes expressive face and articulated hands. "SMPL-X parameters"
- SONIC: A pretrained whole-body humanoid controller used as the base policy. "built on SONIC, a pretrained whole-body controller"
- Static-camera setting: A video setup where camera intrinsics and extrinsics remain fixed across frames. "under a static-camera setting"
- Video Foundation Model (VFM): A large generative or predictive video model providing priors for motion and interactions. "video foundation models (VFMs)"
- Vision-LLM (VLM): A model that reasons over images and text to produce descriptions, labels, or prompts. "A VLM generates an interaction prompt"
- WiLoR: A method for precise hand pose estimation used to refine MANO parameters. "WiLoR refines per-frame MANO parameters"
Collections
Sign up for free to add this paper to one or more collections.

