- The paper introduces a novel co-training framework that leverages egocentric human and robot teleoperation data to bridge the embodiment gap for loco-manipulation.
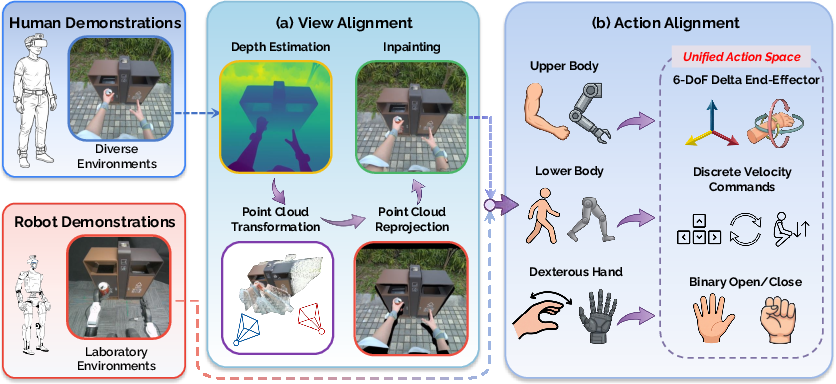
- It employs a two-stage alignment pipeline—view and action alignment—to transform human observations and actions into robot-compatible training signals.
- Experimental results demonstrate substantial improvements, with generalization gains up to 51% over robot-only approaches in diverse real-world settings.
EgoHumanoid: Human-to-Humanoid Transfer for Loco-Manipulation via Egocentric Demonstration
Motivation and Problem Statement
The challenge of equipping humanoid robots with robust loco-manipulation skills—requiring coordinated navigation and dexterous manipulation across complex human environments—is constrained by the scarcity and homogeneity of robot-collected training data. Existing frameworks rely almost exclusively on robot teleoperation, a process limited by cost, logistical complexity, and the necessity of controlled environments. Meanwhile, large-scale collections of egocentric human demonstration data are possible with portable hardware, offering environmental diversity and naturalistic behaviors unattainable by traditional robot-centric pipelines.
EgoHumanoid proposes the first comprehensive approach to co-training humanoid controllers on both egocentric human and teleoperated robot data, enabling VLA (vision-language-action) policies to generalize well beyond the lab and into genuinely diverse, in-the-wild settings. The key obstacle in leveraging human data is the embodiment gap: humans and robots differ in appearance, viewpoint, kinematics, and control affordances. Overcoming these gaps to facilitate human-to-humanoid transfer for whole-body loco-manipulation is the main technical contribution of the work.
A unified, portable VR-based system was developed for both human and robot data collection, prioritizing scalability and agility. For human demonstrations, a PICO VR headset, motion trackers, and a head-mounted egocentric camera capture full-body and hand pose trajectories synchronized with RGB observations. Robot data is generated via teleoperation of a Unitree G1 (1.3m, 29-DoF humanoid) through the same VR interface, with synchronized egocentric vision.
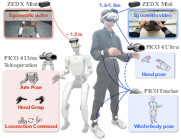
Figure 1: Hardware configuration enables rapid, matched collection of human and robot demonstrations via a portable, integrated VR and vision system.
This portable system allows for the swift gathering of human data in unconstrained, naturalistic settings—homes, stores, outdoor spaces—substantially expanding the domain diversity relative to robot-only datasets.
Human-to-Humanoid Embodiment Alignment Pipeline
EgoHumanoid introduces a two-stage embodiment alignment pipeline to address cross-morphology generalization challenges:
This systematic approach allows VLA policies to be co-trained on two disparate sources while minimizing the adverse effects of inherent differences in morphology and perception.
Experimental Evaluation: Task Suite and Benchmark Design
Four real-world, whole-body loco-manipulation tasks were designed to stress both navigation and dexterous manipulation across diverse scenarios, e.g., Pillow Placement, Trash Disposal, Toy Transfer, and Cart Stowing. In each, laboratory environments provided robot data while human demonstrations were collected in various, diverse settings. Generalization was tested in novel environments covered only by human data.

Figure 3: Task suite spans varied difficulty levels in navigation and manipulation, supporting systematic evaluation of generalization and transfer.
Main Results: Generalization, Data Scaling, and Transfer Analysis
EgoHumanoid's co-trained policy demonstrates substantial gains over robot-only baselines, especially in generalized, human-centric testbeds. Co-training improves in-domain task success from 59% (robot-only) to 78%, while generalization to unseen environments soars to 82%, compared to only 31% for robot-only—representing a 51% absolute improvement in out-of-domain settings.
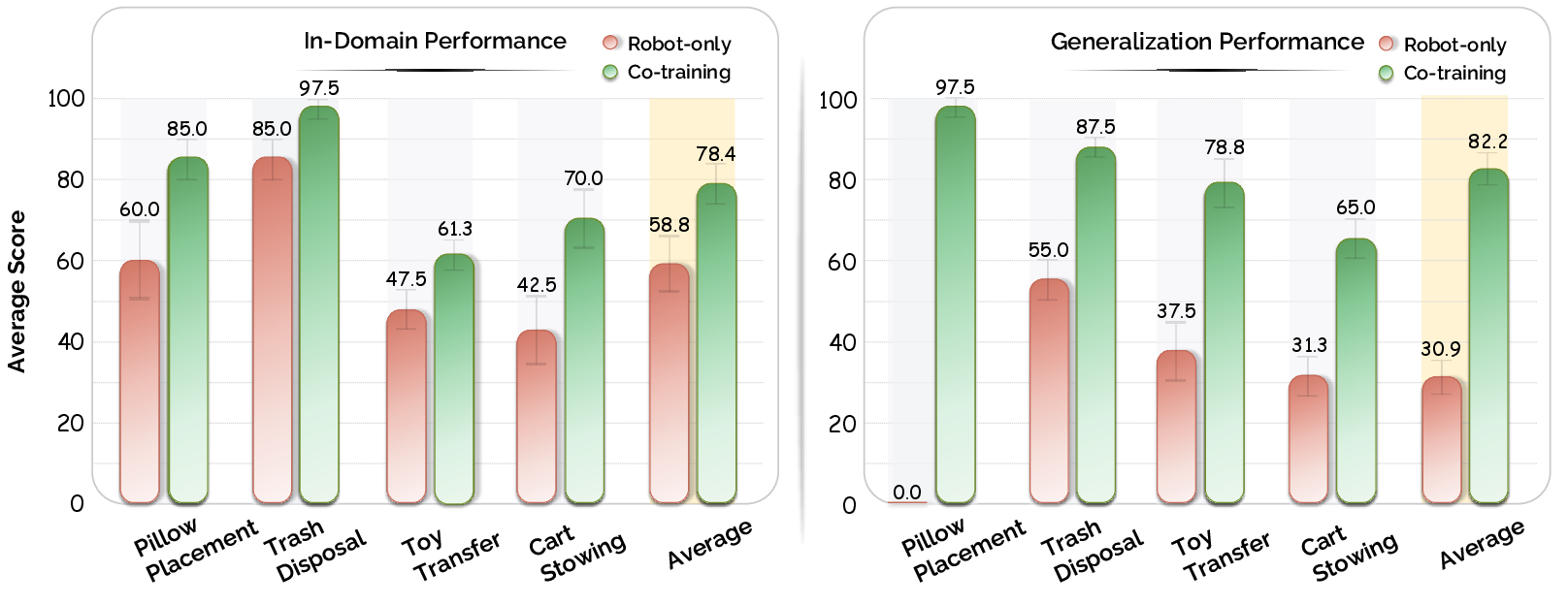
Figure 4: Co-training on human+robot data yields consistent, large performance improvements, especially in generalized scenarios absent from robot data.
Skill Transfer and Failure Mode Analysis
Skill localization analysis establishes that navigation sub-tasks transfer near-perfectly from human-only data. Manipulation subtasks, especially those requiring fine-grained precision or end-effector orientation in cluttered scenes, transfer less robustly owing to residual embodiment and observation ambiguities. Combination with limited robot supervision synergistically improves manipulation outcomes.
Manipulation-heavy tasks still benefit from robot-specific corrections; co-training attains much higher success rates in precision-demanding phases than either human-only or robot-only regimes.
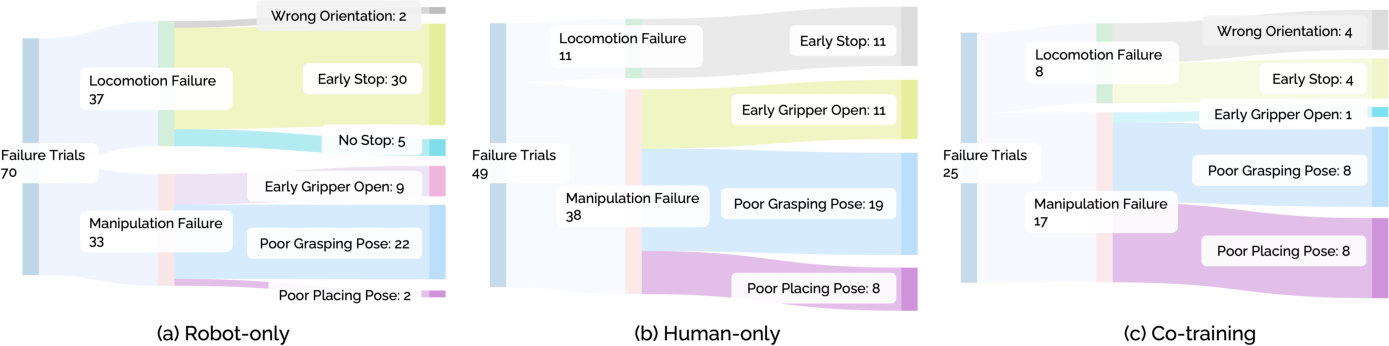
Figure 5: Failure mode breakdown indicates that human data primarily mitigates navigation-related failures, while manipulation errors dominate residual failure cases.
Data Scaling and Sampling Ratio Effects
Co-training demonstrates scaling gains with increased human demonstration quantity, up to 3x robot data, predominantly in generalization but also in in-domain settings. The optimal human-to-robot sampling ratio differs by task: navigation-centric tasks maximize with higher proportions of human demonstrations, while manipulation-heavy tasks maintain demand for robot data to anchor embodiment-specific skills.
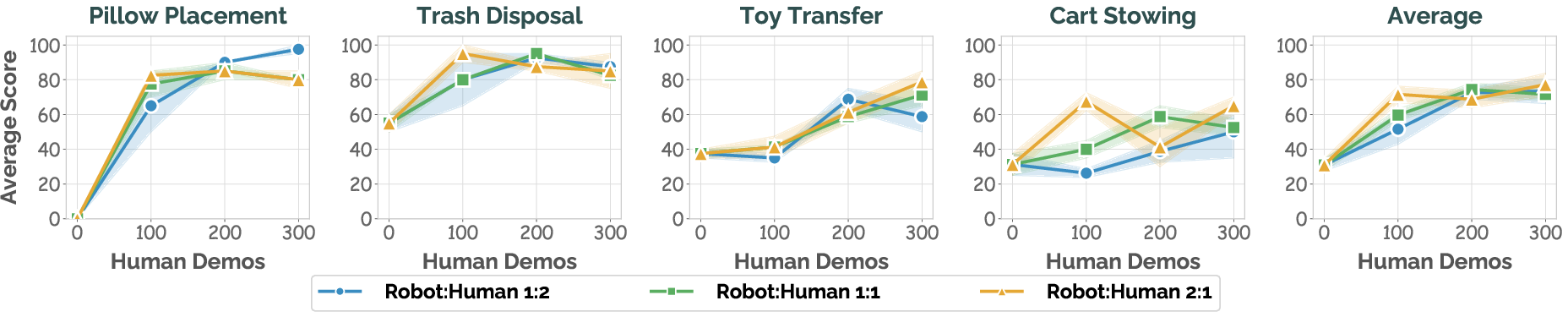
Figure 6: Human demonstration scaling drives steady performance improvement, with task-dependent optimal data balancing strategies.
Ablation: Efficacy of View Alignment
Removing view alignment results in marked performance degradation, especially in tasks with pronounced viewpoint variability (object height changes). The view transformation module ensures the policy is robust to out-of-distribution camera perspectives when switching from human-collected to robot-deployed scenes.
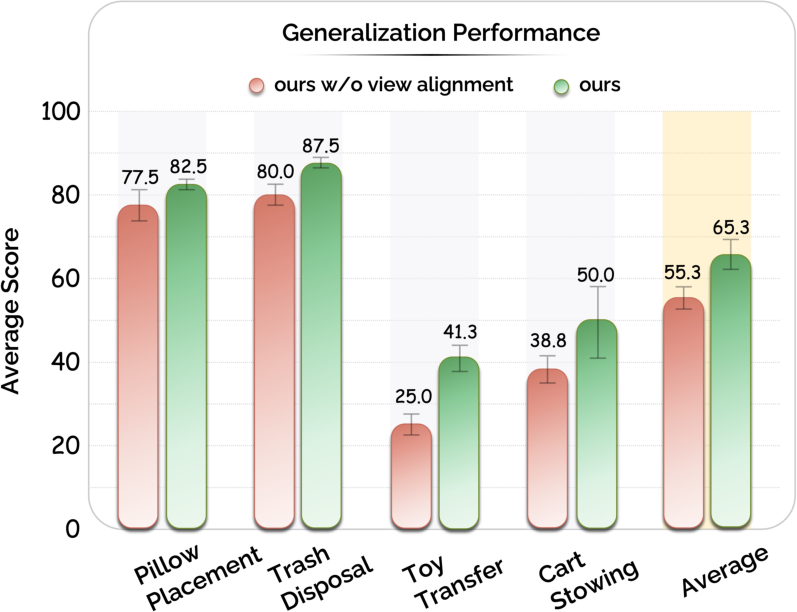
Figure 7: View alignment is crucial for bridging the perspective gap, yielding largest gains in tasks with vertical spatial variation.
Qualitative inspection confirms that reprojected and inpainted images adequately replicate robot views, filling missing regions and standardizing observation space.

Figure 8: The view alignment pipeline accurately simulates robot-like observations from egocentric human videos, supporting effective cross-domain transfer.
Practical and Theoretical Implications
EgoHumanoid demonstrates that effective generalization of whole-body humanoid policies is achievable without costly, scene-specific robot data collection. Leveraging cross-aligned egocentric human demonstration unlocks rich environmental diversity and behavioral priors inaccessible to hardware-bound teleoperation. This supports the hypothesis that high-level strategies—navigation, approach, task decomposition—are transferable by virtue of context and behavior exposure, conditional on robust alignment at the perceptual and action levels.
Practically, this paradigm enables rapid, cost-effective scaling of data collection to environments previously inaccessible to robots. From a theoretical perspective, the results reinforce the utility of unified action representations and viewpoint adaptation in cross-embodiment learning and point to avenues for further research, such as more expressive action spaces, scaling the quantity and diversity of demonstrations, and reducing reliance on explicit proprioceptive state inputs. Refining mapping of fine manipulation remains challenging due to unresolved orientation ambiguities in the absence of proprioception.
Conclusion
EgoHumanoid establishes a rigorous methodology for leveraging in-the-wild egocentric human demonstrations to scale and generalize humanoid loco-manipulation policies. By resolving key challenges in visual and action alignment, empirical results show striking gains in generalization and highlight the differential transferability of skill components. The framework underscores the potential for data-driven, cross-embodiment policy learning and paves the way for future advances in scalable, general-purpose humanoid robotics.