GS-Playground: A High-Throughput Photorealistic Simulator for Vision-Informed Robot Learning
Abstract: Embodied AI research is undergoing a shift toward vision-centric perceptual paradigms. While massively parallel simulators have catalyzed breakthroughs in proprioception-based locomotion, their potential remains largely untapped for vision-informed tasks due to the prohibitive computational overhead of large-scale photorealistic rendering. Furthermore, the creation of simulation-ready 3D assets heavily relies on labor-intensive manual modeling, while the significant sim-to-real physical gap hinders the transfer of contact-rich manipulation policies. To address these bottlenecks, we propose GS-Playground, a multi-modal simulation framework designed to accelerate end-to-end perceptual learning. We develop a novel high-performance parallel physics engine, specifically designed to integrate with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to ensure high-fidelity synchronization. Our system achieves a breakthrough throughput of 104 FPS at 640x480 resolution, significantly lowering the barrier for large-scale visual RL. Additionally, we introduce an automated Real2Sim workflow that reconstructs photorealistic, physically consistent, and memory-efficient environments, streamlining the generation of complex simulation-ready scenes. Extensive experiments on locomotion, navigation, and manipulation demonstrate that GS-Playground effectively bridges the perceptual and physical gaps across diverse embodied tasks. Project homepage: https://gsplayground.github.io.
First 10 authors:






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper introduces GS-Playground, a super-fast, super-realistic “video game” world made for training robots. It combines:
- a powerful physics engine (the rules of the world: gravity, friction, collisions)
- a photorealistic renderer (what the robot “sees” through cameras)
- tools that turn real photos into ready-to-use virtual scenes
The goal is to help robots learn from vision (camera images) at high speed, then work well in the real world.
What questions the researchers asked
In simple terms, they wanted to know:
- Can we build a simulator that is both very fast and very realistic, so robots can learn from camera images without needing huge computers?
- Can we automatically turn a single real photo of a scene into a realistic, physically accurate virtual scene for training?
- Will policies (robot “skills”) learned in this simulator work on real robots (sim-to-real)?
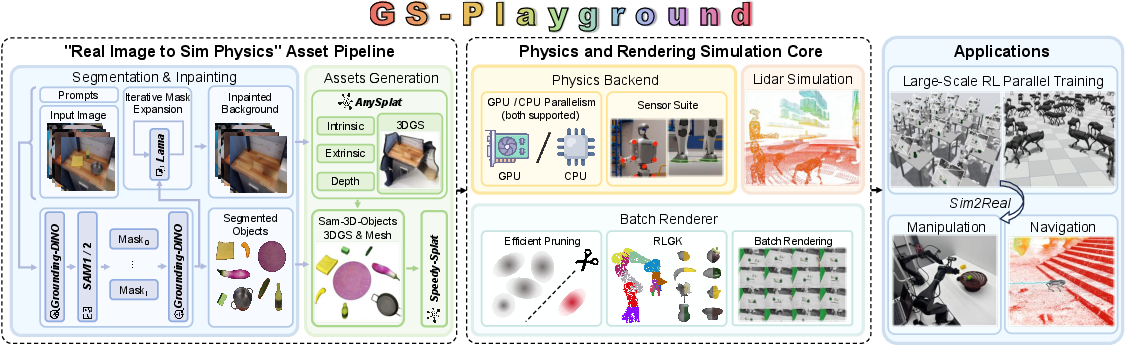
How they built it (methods, explained simply)
To answer these questions, they created three main pieces that work together.
1) A fast, stable physics engine
- Think of the physics engine as the rules of a game that make objects fall, collide, and slide correctly.
- They use a “velocity–impulse” method to handle contact and friction. Imagine nudging objects the exact right amount each tiny step so they don’t sink into each other or slide unrealistically.
- They solve contacts with an iterative method (Projected Gauss–Seidel): like adjusting many small dials over and over until everything fits perfectly.
- Two speed tricks:
- Constraint islands: split the world into independent groups of touching objects and solve them in parallel (divide-and-conquer).
- Warm-starting: reuse last frame’s solution as a smart starting point (like continuing yesterday’s homework instead of starting from scratch).
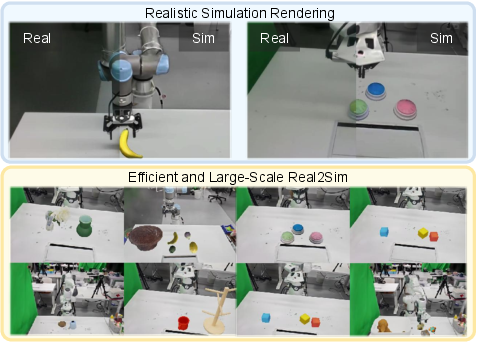
2) A photorealistic, memory‑efficient renderer using 3D Gaussian Splatting (3DGS)
- 3DGS represents a scene as lots of soft, colored blobs (“Gaussians”) that together look like a real photo from any angle. It’s much faster than heavy movie-style rendering.
- They prune (trim) unnecessary blobs to save memory while keeping the image almost indistinguishable from the original.
- Batch rendering: they render many scenes at once efficiently (like an assembly line).
- Rigid-Link Gaussian Kinematics (RLGK): they “attach” groups of blobs to moving objects, so visuals follow physics perfectly with almost no extra cost.
3) An “Image-to-Physics” pipeline (Real2Sim)
- From a single photo of a real scene:
- Detect and cut out objects (using modern vision models).
- Inpaint the background (fill in what was behind objects).
- Rebuild both the background and each object in 3D using 3DGS and meshes.
- Align and scale objects so they match the scene’s depth and size.
- Prune the Gaussians to save memory.
- Result: a “digital twin” that looks real and has correct physical shapes for collisions and manipulation.
They also include simulated sensors (RGB cameras, depth, LiDAR, contact forces) so robots can practice with many types of inputs.
What they found (main results and why they matter)
Here are the highlights from their experiments and benchmarks:
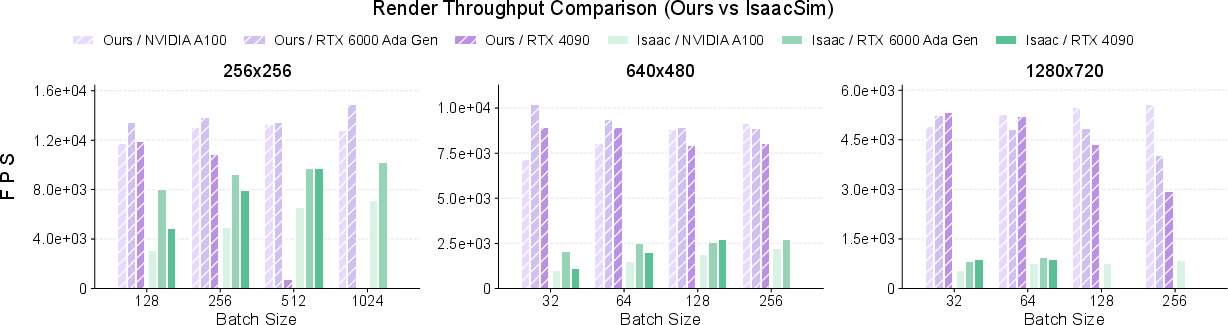
- Very high speed with realistic visuals:
- Up to about 10,000 frames per second at 640×480 on one GPU (that’s extremely fast).
- Stronger throughput than a popular ray-tracing simulator (which often ran out of memory at higher resolutions or large batches).
- After pruning, scenes kept high visual quality while using much less memory.
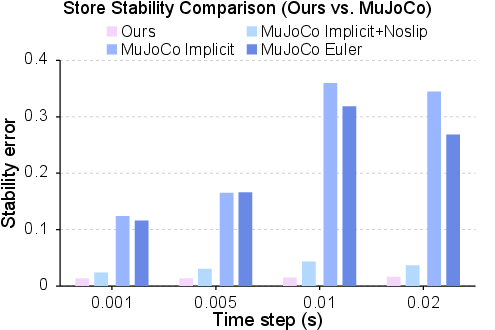
- Stable, accurate physics under tough conditions:
- In “Newton’s Cradle” tests, it preserved timing and momentum better than some baseline simulators (less fake damping).
- With a quadruped robot standing still at larger time steps, there was less drift (more stability).
- In crowded, contact-heavy scenes (like stacked shelves), it converged to stable resting states without jitter.
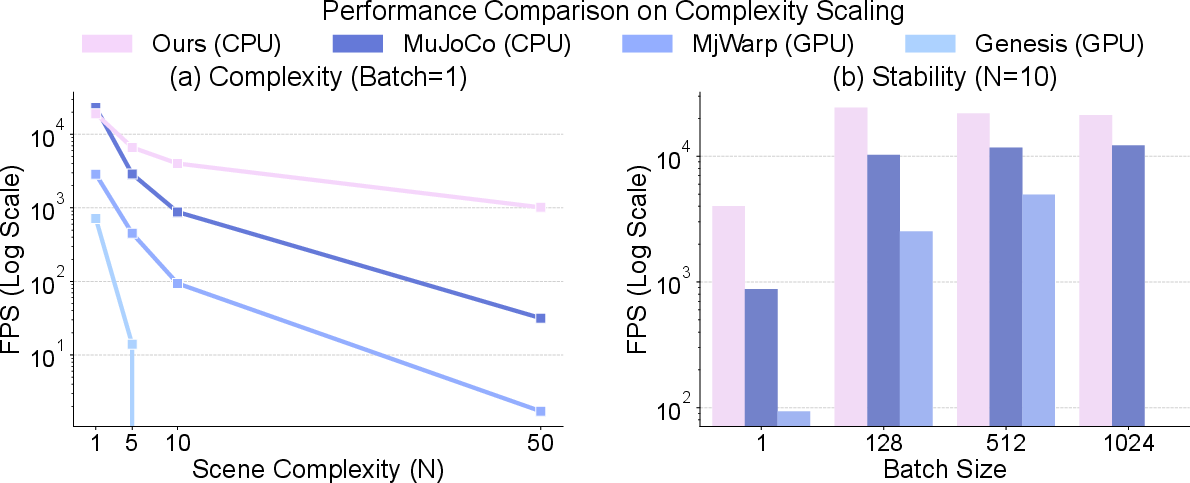
- Scales better as scenes get more complex:
- When increasing the number of humanoid robots in one scene, competing GPU-based solvers slowed down or failed to converge.
- GS-Playground stayed fast and stable, especially on CPU, showing it handles dense contact graphs well.
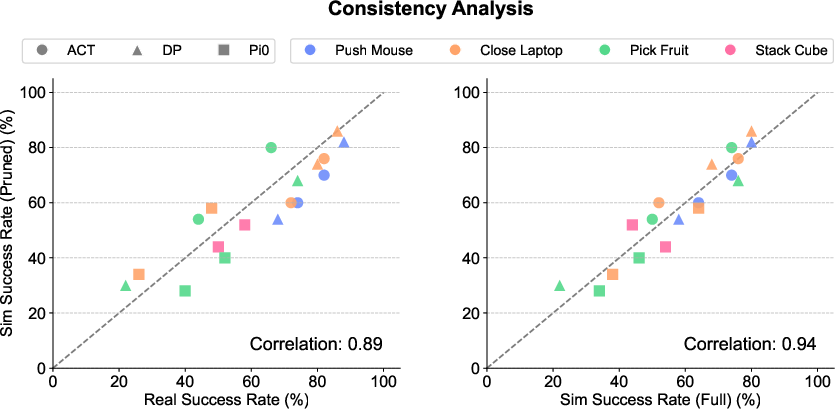
- Real robots learned faster and transferred well (Sim2Real):
- Quadruped (Unitree Go2) and humanoid (Unitree G1) locomotion policies trained quickly and worked on real robots.
- Vision navigation: a Go2 learned to find and go to a cone using only camera images, then did it in the real world without extra tuning.
- Vision manipulation: a robot arm learned to grasp blocks from raw RGB images and reached about 90% success in real tests—trained using the Real2Sim digital twin, with randomization for robustness.
Why this matters:
- Vision-based training usually needs both high-quality images and fast simulation. Most tools force a trade-off. GS-Playground delivers both, lowering the cost and time to train capable vision-informed robots that can move into the real world more reliably.
What this could change (implications and impact)
- Faster research and development: Teams can train vision-based robot skills much quicker without massive hardware.
- Better Sim2Real: More realistic visuals plus stable physics help policies work in real life with fewer surprises.
- Easier content creation: Turning a single photo into a training-ready virtual scene speeds up building diverse datasets and tasks.
- Broad use: Supports many robots (legs, arms, humanoids) and many tasks (walking, navigating, manipulating) with sensors (cameras, LiDAR, contact).
- Future directions: They plan to improve lighting and shadows (3DGS depends on the original photo’s lighting) and add deformable objects (like cloth), which are harder. They also aim to generate large datasets for vision-language-action/navigation models.
In short, GS-Playground is like a high-speed, high‑realism “playground” where robots learn from what they see, and those lessons carry over to the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances high-throughput photorealistic simulation but leaves several concrete issues unresolved. Future work could address the following gaps:
- Rendering generalization under varying illumination:
- 3DGS currently struggles with randomized lighting and shadows; no method is provided for scene relighting, cast-shadow modeling, or time-of-day/weather variation while preserving realism and efficiency.
- Dynamic photometry and materials:
- No support/analysis for transparent, reflective, or highly specular materials, view-dependent effects, or emissive/lighting sources that are critical for many photometric tasks.
- Domain randomization with 3DGS:
- Lack of principled, scalable appearance randomization strategies compatible with 3DGS (e.g., global/locally consistent color shifts, BRDF variation, lighting changes) and their quantified impact on policy robustness.
- Sensor realism gaps:
- Cameras: no modeling of lens distortion, rolling shutter, motion blur, exposure, or sensor noise characteristics; no ablation on how such effects influence learned policies.
- LiDAR: no intensity/reflectivity simulation, beam divergence, multi-echo returns, or realistic noise models; no validation against real LiDAR data.
- Validation of LiDAR with 3DGS:
- How ray-casting interacts with anisotropic Gaussians is unspecified; no quantitative benchmark versus real-world scans (e.g., point-to-mesh error, distribution of returns, intensity histograms).
- Dynamic scene fidelity:
- Only PSNR/SSIM/LPIPS for static scenes are reported; no quantitative metrics for dynamic sequences (e.g., temporal consistency, flicker, motion artifacts) or their effect on control performance.
- Effect of pruning on control:
- Pruning is evaluated perceptually (PSNR/SSIM), but its impact on downstream visuomotor policy success, sample efficiency, and robustness is not measured.
- Multi-camera scalability:
- Throughput and memory scaling with multiple cameras per environment (a common robotics setup) are not reported.
- Latency characterization:
- End-to-end motion-to-photons latency, synchronization jitter between physics and rendering, and their influence on closed-loop RL stability are not quantified.
- Memory/VRAM scaling and limits:
- VRAM usage per environment/camera and scaling curves up to OOM are not provided; no guidance on memory-performance trade-offs across GPUs or batch sizes.
- Physics accuracy and parameter identification:
- No quantitative validation against ground-truth system identification (e.g., friction coefficients, restitution, stiffness) or real-world force/torque trajectories; reliance on qualitative comparisons (e.g., Newton’s cradle images).
- Solver convergence and edge cases:
- PGS convergence behavior, failure modes (e.g., high friction, near-jamming, large mass ratios), and sensitivity to step size/iteration budget are not benchmarked or theoretically bounded.
- Long-horizon energy behavior:
- Energy drift/conservation in rigid-body stacks or pendulum-like systems over long horizons is not measured; only short qualitative demonstrations are shown.
- Contact-rich manipulation breadth:
- Vision-based manipulation is demonstrated on a single block-grasp task; no evaluation on more challenging scenarios (e.g., insertion, tool use, clutter clearing, deformable object handling, bimanual tasks).
- Deformable/soft-body interactions:
- RLGK assumes rigid bodies; there is no current support or evaluation for cloth, cables, fluids, or soft objects, nor a concrete design for coupling particle/continuum methods with 3DGS for photorealistic rendering.
- Coupling between visual and collision geometry:
- The alignment accuracy between 3DGS surfaces and physics colliders (meshes/primitive approximations) is not quantified; the effect of misalignment on contact dynamics and policy transfer is unknown.
- Real2Sim pipeline accuracy from single images:
- Metric scale, depth accuracy, and pose estimation errors (especially with occlusions/inpainting) are not validated against ground truth; no analysis of how single-view ambiguities affect physics or policy performance.
- Generalization of Real2Sim assets:
- Dependence on source-image lighting and inpainting quality is acknowledged, but there is no measure of how visual artifacts or lighting biases degrade policy transfer across varied real scenes.
- Robustness and OOD testing:
- Sim2Real evaluations are limited in scope (single scenes/robots); sensitivity to distractors, lighting changes, camera pose shifts, and background clutter is not systematically tested.
- Comparative training efficiency:
- While throughput is reported, sample efficiency (reward per environment step) and convergence speed for vision-based RL versus baselines (e.g., Isaac Lab, GaussGym) are not compared.
- Hierarchical policy ablations:
- For navigation, the benefits of the proposed hierarchical decomposition versus flat policies are not quantified; the effect of sensor choices (RGB-only vs. RGBD/LiDAR) is not ablated.
- Multi-agent/complexity limits:
- Although single-environment complexity scaling is shown, there is no study of multi-agent interactions across many environments with communication, collisions, or shared resources.
- On-device/edge deployment feasibility:
- Performance on resource-constrained hardware (e.g., laptop GPUs, embedded platforms) is not characterized; no guidance on minimal hardware for practical training/inference.
- Reproducibility and release status:
- The promised Bridge-GS dataset and full framework release details (licensing, asset counts, coverage, benchmarks) are not provided; reproducibility of results cannot yet be verified.
- Safety and failure analysis in real deployment:
- No systematic evaluation of failure cases, safety constraints, or risk mitigation strategies when transferring policies to real robots.
- Support for online scene editing:
- It remains unclear how efficiently objects can be added/removed, rearranged, or retextured at runtime in 3DGS without re-optimization, and how that impacts throughput/fidelity.
- Evaluation breadth of benchmarks:
- Comparisons against additional high-throughput simulators (e.g., Brax/MJX, Madrona-based renderers) and broader tasks (navigation with obstacles, vision-language grounding) are absent.
- Differentiability for gradient-based learning:
- The physics solver is non-smooth and the renderer is non-differentiable in the presented setup; support for differentiable physics/rendering to enable gradient-based policy optimization or system ID is not discussed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with the methods, tools, and artifacts described in the paper.
- Vision-informed locomotion policies with fast Sim2Real (Robotics; field deployment)
- Train and deploy quadruped/humanoid locomotion controllers (e.g., Unitree Go2/G1) using high-throughput physics and camera-based observations; demonstrated convergence in minutes–hours and successful zero-shot transfers.
- Tools/workflows: GS-Playground physics + Batch-3DGS renderer; PPO or similar RL; MJCF robot models; on-robot deployment pipeline.
- Assumptions/dependencies: Accurate robot CAD/MJCF, calibrated actuation limits, rigid-body contacts, NVIDIA GPU for high throughput; safety validation prior to field use.
- End-to-end visual grasping for pick-and-place (Manufacturing, Warehousing, Service Robotics)
- Train RGB-based policies for block or object grasping (e.g., Airbot Play) in photorealistic digital twins; deploy without extensive visual engineering.
- Tools/workflows: Image-to-Physics Real2Sim pipeline (SAM-3D, AnySplat, pruning), contact sensing, domain randomization of camera pose/lighting.
- Assumptions/dependencies: Mainly rigid objects; friction/material parameters identifiable; lighting baked into 3DGS affects generalization.
- Vision-centric AMR navigation in indoor facilities (Logistics, Healthcare)
- Train hierarchical navigation policies from onboard RGB (and/or LiDAR) for corridor, aisle, or ward navigation; demonstrated cone-seeking on Unitree Go2.
- Tools/workflows: Hierarchical RL (high-level vision → motion command + low-level control), Real2Sim scene construction, Batch-LiDAR for sensor fusion.
- Assumptions/dependencies: Reliable camera/LiDAR calibration; scene variations within photorealistic twin; limited robustness to drastic lighting changes without relighting.
- Rapid digital twin generation of workspaces from minimal capture (Digital Twins, Robotics Ops)
- Convert one or a few RGB images into sim-ready environments for prototyping, validation, and what-if testing; add robot and tasks to the twin.
- Tools/workflows: Automated segmentation + inpainting → AnySplat + SAM-3D → alignment + pruning → RLGK binding to physics.
- Assumptions/dependencies: Static scenes with predominantly rigid elements; image quality; lighting is baked (limited relighting).
- Scalable visual RL research and benchmarking (Academia, R&D labs)
- Run large-batch, photorealistic RL experiments (104 FPS at 640×480) to study perception-control algorithms, sample efficiency, and robustness.
- Tools/workflows: Cross-platform engine (Windows/Linux/macOS), CPU/GPU physics, MJCF compatibility; Bridge-GS dataset for immediate use.
- Assumptions/dependencies: NVIDIA GPUs for peak throughput; standardized benchmarks and seeds for reproducibility.
- Synthetic data generation for VLA/VLN and perception (Software/AI)
- Produce labeled RGB/Depth/LiDAR data at scale from photorealistic 3DGS scenes to train/finetune foundation models and downstream perception modules.
- Tools/workflows: Batch rendering + LiDAR simulation; scripted camera trajectories; scenario randomization; Bridge-GS assets.
- Assumptions/dependencies: Domain coverage and diversity; license compliance for datasets/models; limited controllable lighting.
- Safety/regression testing of contact-rich behaviors (Safety Engineering, QA)
- Run high-fidelity, stress-test scenarios (e.g., dense contact stacks, Newton’s cradle, time-step stress) to detect regressions in control policies.
- Tools/workflows: Stable velocity-impulse solver, constraint islands + warm-starting for throughput; scripted test batteries.
- Assumptions/dependencies: Accurate physical parameters; scenario libraries; not yet a certified safety standard.
- LiDAR-centric algorithm prototyping (Autonomy/Perception)
- Develop and benchmark SLAM/segmentation/planning with massively parallel LiDAR simulation (including irregular/dynamic objects with 3DGS).
- Tools/workflows: Batch-LiDAR module; scenario sweeps; evaluation harness for perception metrics.
- Assumptions/dependencies: Sensor model fidelity (beam patterns, noise); scene geometry/detail sufficient for downstream algorithms.
- Course labs and hobbyist prototyping on commodity hardware (Education, SMEs)
- Teach visual RL, control, and perception with cross-platform CPU/GPU physics; develop locally and scale on Linux clusters when needed.
- Tools/workflows: MJCF-compatible API; local debug on Windows/macOS; batch training on Linux; small projects using consumer GPUs.
- Assumptions/dependencies: Reduced throughput without high-end GPUs; starter asset packs; curated examples for education.
- Retail shelf-restocking and inventory manipulation pilots (Retail Robotics)
- Train vision-based manipulation for shelf tasks using store aisle digital twins reconstructed from a small image set; validate policy variants quickly.
- Tools/workflows: Image-to-Physics pipeline; grasping/pushing tasks; shelf/product libraries; on-site validation.
- Assumptions/dependencies: Mostly rigid packaging; frequent layout changes require updated twins; real-world occlusions/crowds not fully modeled.
Long-Term Applications
These applications are feasible but require further research, scaling, or productization beyond the current paper’s capabilities.
- Large-scale training of generalist VLA/VLN robots (AI Robotics, Cloud)
- Use photorealistic twins to synthesize massive visuomotor corpora for general robot policies that transfer across tasks and embodiments.
- Tools/products: Cloud-scale GS-Playground clusters; automated asset generation; dataset curation/QA pipelines.
- Assumptions/dependencies: Significant compute budget; diverse scene coverage; strong sim-to-real validation; licensing and privacy safeguards.
- Personalized home digital twins and continual learning (Consumer Robotics, Assistive)
- Build residents’ home twins from quick captures and continuously update to personalize navigation/manipulation policies to user environments.
- Tools/products: Mobile capture app; auto-Real2Sim service; on-device adaptation/edge-cloud loops.
- Assumptions/dependencies: Privacy, data governance; dynamic/cluttered scenes; improved relighting and deformable modeling.
- Reliable deformable-object manipulation in photorealistic sim (Manufacturing, Healthcare)
- Train policies for cloth, cable, tissue, or food manipulation by integrating soft-body physics (PBD/MPM/MPIM) with 3DGS rendering.
- Tools/products: Hybrid rigid–soft solver with RLGK extensions; new GS representations for deformables.
- Assumptions/dependencies: Research breakthroughs in GS + soft-body coupling; higher compute; validated material models.
- Photorealistic relighting and weather/illumination robustness (Graphics + Robotics)
- Decouple appearance from scene lighting to support aggressive domain randomization of lights and shadows in GS-based rendering.
- Tools/products: Relightable GS assets; renderer with controllable light probes.
- Assumptions/dependencies: New relighting methods for 3DGS; efficient shading with minimal VRAM overhead.
- Regulatory-grade digital twins and pre-certification (Policy, Standards)
- Establish scenario libraries and validation protocols where sim evidence contributes to compliance for mobile/service robots.
- Tools/products: Standardized test suites; traceability of physics parameters; audit tools for scenarios and logs.
- Assumptions/dependencies: Engagement with standards bodies; third-party validation; robust uncertainty quantification.
- “Robot Learning as a Service” platforms (Cloud/Software)
- Offer APIs to upload captures, auto-generate twins, train policies, and deliver deployable controllers or synthetic datasets.
- Tools/products: Multi-tenant training service; usage-based billing; privacy-preserving data handling.
- Assumptions/dependencies: IP ownership, data security; SLAs for training throughput; integration with customer robots.
- Hardware–control co-design at scale (Robotics Design, OEMs)
- Optimize robot morphology, actuator placement, and control jointly using fast simulations across thousands of variants and tasks.
- Tools/products: CAD/parametric model integration; automated experiment design; Bayesian optimization/AutoRL loops.
- Assumptions/dependencies: Accurate parametric models; efficient CAD-to-MJCF pipelines; validation rigs.
- Human-in-the-loop teleoperation training and simulation (Industrial Services)
- Pretrain operators and assistive policies in photorealistic twins; collect demonstrations to bootstrap imitation/diffusion policies.
- Tools/products: High-fidelity sim trainers; dataset logging; policy refinement from human feedback.
- Assumptions/dependencies: Ergonomic interfaces; motion retargeting fidelity; latency constraints for skill transfer.
- Construction and AEC inspection robotics (Construction, Infrastructure)
- Train vision-LiDAR inspection/navigation policies in site-specific twins to handle clutter, scaffolding, and evolving layouts.
- Tools/products: Periodic site capture → Real2Sim updates; inspection task libraries; anomaly detection pipelines.
- Assumptions/dependencies: Outdoor/variable lighting; frequent environment changes; safety coordination with crews.
- Energy and utilities inspection (Energy, Utilities)
- Sim-train policies for plant/warehouse inspection, meter reading, or substation navigation using sensor-accurate twins.
- Tools/products: Asset libraries (valves, gauges); LiDAR/RGB fusion policies; reporting dashboards.
- Assumptions/dependencies: Complex reflective materials; outdoor weather rendering; strict safety requirements.
- Agricultural manipulation and handling (Agritech)
- Extend to crop handling, fruit picking, and packing via deformable modeling and robust relighting for outdoor variability.
- Tools/products: Crop-specific GS assets; soft-body integration; weather/time-of-day simulation.
- Assumptions/dependencies: Deformable/biophysical realism; outdoor illumination/weather; equipment variance.
- Browser-based/edge-accessible robotics labs (Education at scale)
- Deliver interactive labs using WebGPU/WebGL backends and compressed GS assets for broad access without high-end GPUs.
- Tools/products: Hosted lab environments; curriculum-aligned scenarios; lightweight renderers.
- Assumptions/dependencies: Efficient web runtimes for GS and physics; reduced fidelity modes; curriculum integration.
Glossary
- 3D Gaussian Splatting (3DGS): A point-based neural scene representation that renders photorealistic views in real time by projecting anisotropic 3D Gaussians. "integrate with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to ensure high-fidelity synchronization"
- Actuators: Mechanisms that generate forces/torques to drive joints or bodies within the simulator’s dynamics. "It supports various physical constraints, including MJCF-defined contact models (e.g., parameters solref, solimp), tendons, and actuators."
- AnySplat: A method for reconstructing background scenes as Gaussian splats from images, used here for scene-level assets. "the inpainted background is processed by AnySplat \cite{jiang2025anysplat} to generate the background 3DGS"
- Batch 3DGS Renderer: A rendering subsystem optimized to render many Gaussian-splat scenes simultaneously for high throughput. "The updated rigid-body poses are synchronized with the Batch 3DGS Renderer through Rigid-Link Gaussian Kinematics (RLGK)"
- Batch-LiDAR: A parallel LiDAR simulation module that ray-casts across many environments to produce point clouds efficiently. "we integrate a high-performance Batch-LiDAR module utilizing ray-casting to generate high-fidelity point clouds and heightmap scanning"
- Compliance matrix: A positive-definite matrix relating constraint impulses to velocity responses in compliant constraints. "By defining the positive definite compliance matrix $\mathbf{C} = (-\frac{\partial f}{\partial \mathbf{u})^{-1}$"
- Constraint Islands: Independent subsets of bodies and constraints that can be solved in parallel due to lack of cross-dependencies. "termed ``Constraint Islands.''"
- Contact Manifold Tracking: A technique that persists and reuses contact information across timesteps to accelerate solver convergence. "by implementing a Contact Manifold Tracking system."
- Coulomb friction model: The classical friction law bounding tangential forces by the product of normal force and friction coefficient. "The solution must satisfy the bounds defined by the Coulomb friction model:"
- Decimation: Number of physics sub-steps per control step; lower values increase speed but can reduce fidelity. "``deci" denotes the decimation, which refers to the number of physical sub-steps per control step."
- Digital twin: A high-fidelity virtual replica of a physical environment/object used for simulation and transfer. "we reconstructed a high-fidelity digital twin"
- Domain randomization: Training technique that randomizes visual/physical properties to improve sim-to-real robustness. "we incorporated domain randomization of camera poses and lighting conditions during the training phase."
- Generalized coordinates: Minimal coordinates describing the configuration of a multibody system used in dynamics and constraints. " utilizes a velocity-impulse formulation in generalized coordinates"
- Grounding DINO: An open-vocabulary object detector used to localize objects for segmentation and asset creation. "Objects are detected using Grounding DINO \cite{liu2023grounding}"
- Jacobians: Matrices mapping generalized velocities to constraint-space velocities, used in contact and joint constraints. "are the Jacobians for equality and inequality constraints"
- LaMa: A deep inpainting model used to fill backgrounds after object removal during asset synthesis. "Background inpainting is performed sequentially using LaMa \cite{suvorov2021resolution}"
- Linear Complementarity Problem (LCP): A mathematical formulation for inequality constraints (e.g., contact) solved here per island. "Since the Linear Complementarity Problems (LCPs) for these islands are mathematically independent"
- LPIPS: A learned perceptual metric assessing visual similarity between images, used to quantify rendering quality. "along with competitive LPIPS performance."
- MJCF: MuJoCo’s XML-based model format for defining robots, joints, contacts, and assets. "our API is compatible with the MuJoCo MJCF format"
- Mixed Complementarity Problem (MCP): A complementarity formulation encompassing both normal contact and friction constraints. "The solver resolves contact and friction as a Mixed Complementarity Problem (MCP)."
- MPIM: A particle-based dynamics method (mentioned alongside PBD) considered for future non-rigid simulation. "like PBD or MPIM"
- Out-of-Memory (OOM): A failure mode where GPU memory is exhausted during rendering or training. "Out-of-Memory (OOM) failures."
- Peak Signal-to-Noise Ratio (PSNR): A signal fidelity metric used to quantify reconstruction/rendering quality. "maintaining a minimal Peak Signal-to-Noise Ratio (PSNR) drop of less than 0.05"
- Position-Based Dynamics (PBD): A constraint-based particle simulation method proposed for future deformable object support. "like PBD or MPIM"
- Projected Gauss-Seidel (PGS): An iterative solver enforcing complementarity and bounds by projection each iteration. "This formulation is solved efficiently using a Projected Gauss-Seidel (PGS) solver"
- Proprioception: Internal sensing of robot states (e.g., joint angles/velocities) used for control and learning. "proprioception-based locomotion"
- Rasterization: A graphics pipeline approach rendering geometry via sampling surfaces into pixels; fast but less realistic than ray tracing. "streamlined rasterization (e.g., Madrona \cite{shacklett2023extensible}, ManiSkill3 \cite{taomaniskill3})"
- Ray-tracing: A rendering technique simulating light transport for photorealism at higher computational cost. "computationally expensive ray-tracing (e.g., Isaac Lab \cite{mittal2025isaac})"
- Rigid-Link Gaussian Kinematics (RLGK): A mechanism binding Gaussian clusters to rigid bodies for artifact-free dynamic updates. "through Rigid-Link Gaussian Kinematics (RLGK), enabling zero-overhead updates"
- SAM1/SAM2: Segment Anything models for mask generation in the object segmentation stage. "segmented with SAM1/SAM2 \cite{kirillov2023segany,ravi2024sam2}"
- Schur complement: A matrix reduction technique used to eliminate equality constraints and form a reduced system. "via the Schur complement method"
- Speedy- splat: A Gaussian pruning approach used to reduce memory footprint while retaining visual fidelity. "we apply Speedy- splat \cite{hanson2025speedy} for 3DGS pruning."
- Strict complementarity: A contact formulation property ensuring exact satisfaction at friction limits for precise rigid contacts. "implements strict complementarity with explicit velocity clamping at the friction limits."
- Tendons: Constraint elements transmitting forces across joints or bodies, common in biomechanical/robot models. "including MJCF-defined contact models (e.g., parameters solref, solimp), tendons, and actuators."
- Velocity-impulse formulation: A dynamics solver strategy updating velocities via impulses to enforce constraints at each time-step. " utilizes a velocity-impulse formulation in generalized coordinates"
- Vision-Language-Action (VLA): Models that map visual inputs and language to actions for embodied tasks. "Vision-Language-Action (VLA) models \cite{kim2024openvla, zhou2025vision, black2410pi0}"
- Vision-Language-Navigation (VLN): Models that use vision and language to guide navigation decisions. "Vision-Language-Navigation (VLN) models \cite{cheng2024navila, cai2025navdp, zhang2024uninavid, zhang2025embodied}"
- Warm-Starting: Initializing iterative solvers with previous solutions to accelerate convergence across timesteps. "2) Warm-Starting with Temporal Coherence:"
Collections
Sign up for free to add this paper to one or more collections.

