- The paper introduces a novel framework that amplifies a few human demonstrations into diverse loco-manipulation datasets using hybrid control and whole-body planning.
- It leverages skill segmentation with precedence and coordination constraints to synthesize realistic humanoid trajectories, achieving a policy success rate of up to 0.89.
- Experimental results show significant gains in simulation and real-world tasks through sim-and-real co-training and strategic data randomization.
HumanoidMimicGen: Data Generation for Humanoid Loco-Manipulation via Whole-Body Planning
Introduction and Motivation
Humanoid robots promise seamless integration into human environments by leveraging bipedality and dexterous manipulation. Recent Vision-Language-Action (VLA) architectures have enabled impressive policy learning for stationary robotic manipulation. However, applying these approaches to humanoid loco-manipulation, which requires coordinated whole-body locomotion and manipulation in high-dimensional action spaces, remains challenging due to the scarcity and high cost of collecting diverse teleoperated demonstrations at scale. Simulated and synthetic data generation offer an alternative, but existing techniques designed for fixed-base or mobile manipulators do not address the stability and sequencing complexities inherent in humanoids.
HumanoidMimicGen introduces a comprehensive system for automatically generating large-scale, diverse demonstration datasets for legged humanoid loco-manipulation by integrating hybrid control, whole-body skill adaptation, and task-aware sequencing. The generated data supports both simulation-based benchmarking and sample-efficient real-world deployment through sim-and-real co-training.
Methodology
HumanoidMimicGen employs a demonstration adaptation framework that amplifies a small set of human teleoperated expert demonstrations into thousands of synthetic trajectories distributed across diverse initial states and object layouts.
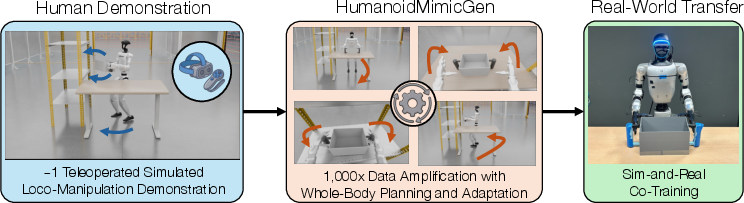
Figure 1: HumanoidMimicGen synthesizes thousands of loco-manipulation demonstrations by adapting local skill segments from human demonstrations via whole-body planning and control, enabling high-quality policy training.
Hybrid Action Space and Hierarchical Control
To address the infeasibility of task-space independent limb control on humanoids, HumanoidMimicGen implements a hybrid control architecture where:
- Upper body (arms, torso, hands) is controlled via joint-space targets.
- Lower body (legs) is controlled via a reinforcement-learned locomotion policy (e.g., Homie [ben2025homie]) providing dynamically feasible base velocities.
This architecture decouples manipulation from locomotion, facilitating interleaved planning.
Skill Segmentation, Precedence, and Coordination
Demonstrations are segmented into object-centric skills, each associated with specific end-effectors and referenced objects. Skills are annotated with precedence (ordering) and coordination (concurrent execution) constraints, forming a Directed Acyclic Graph (DAG) over skill execution.
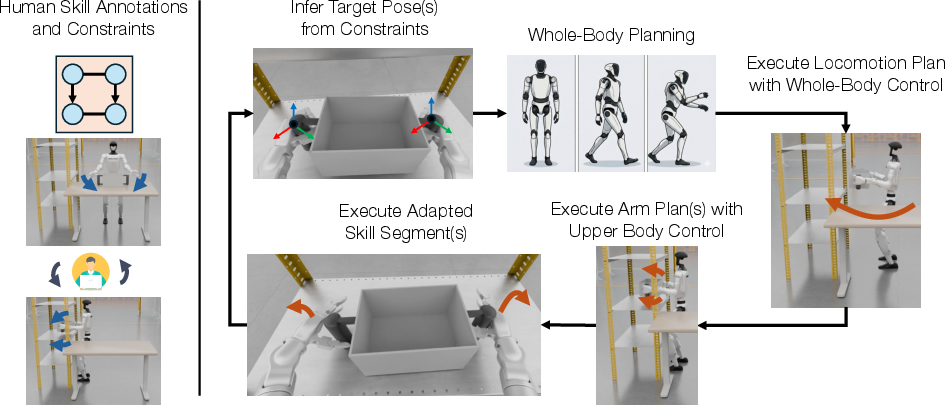
Figure 2: HumanoidMimicGen method pipeline; per-arm skill annotations and constraints guide the decomposition of the demonstration into ordered whole-body execution plans.
Whole-Body Planning and Data Generation Process
Given a sampled initial state and the set of skills with their execution constraints:
- The system greedily selects executable skill subsets according to the topological ordering imposed by the constraints.
- For each batch of skills, it computes target end-effector poses by spatially transforming the original targets to the new object configurations.
- Whole-body inverse kinematics (using GPU-accelerated variants) is solved for feasible configurations, separating leg movements (for base navigation) from upper-body manipulation.
- Locomotion and manipulation motions are planned and executed in sequence, with feedback adaptation to handle execution imperfections from the RL locomotion controller.
- Synthetic motion noise and initialization randomization are injected to increase policy robustness by exposing learning to off-nominal states.
Coordination and precedence constraints enable the composition of complex behaviors requiring concurrent or sequential action (e.g., bimanual lifting and subsequent placing tasks).
Loco-Manipulation Simulation Benchmark
To systematically evaluate the data generation and policy learning regimes enabled by HumanoidMimicGen, the paper introduces a G1 Humanoid loco-manipulation benchmark suite comprising nine tasks. These range from single-arm tasks to long-horizon, bimanual, and contact-rich scenarios.
Simulation environments are instantiated with randomized robot and object placements, forcing policies to solve variations requiring precise locomotion and manipulation coordination.
Experimental Results
Evaluation is conducted on both simulated and real-world platforms. Key findings include:
- Superior Policy Performance: Policies trained on HumanoidMimicGen-generated data, starting from a single real human demonstration, achieve a mean policy success rate (PSR) of 0.89, compared to 0.33 for baseline generative approaches (DexMimicGen+) and 0.26–0.48 for few-to-many human demonstration baselines. The improvement is consistent across all tasks, especially pronounced for long-horizon and whole-body coordination tasks.
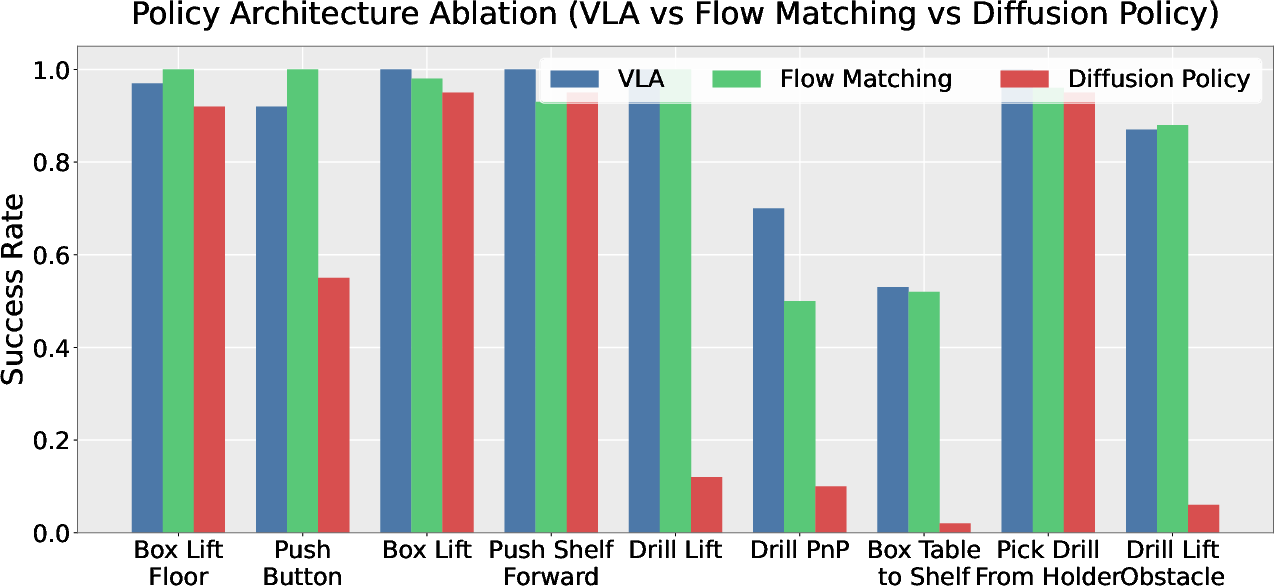
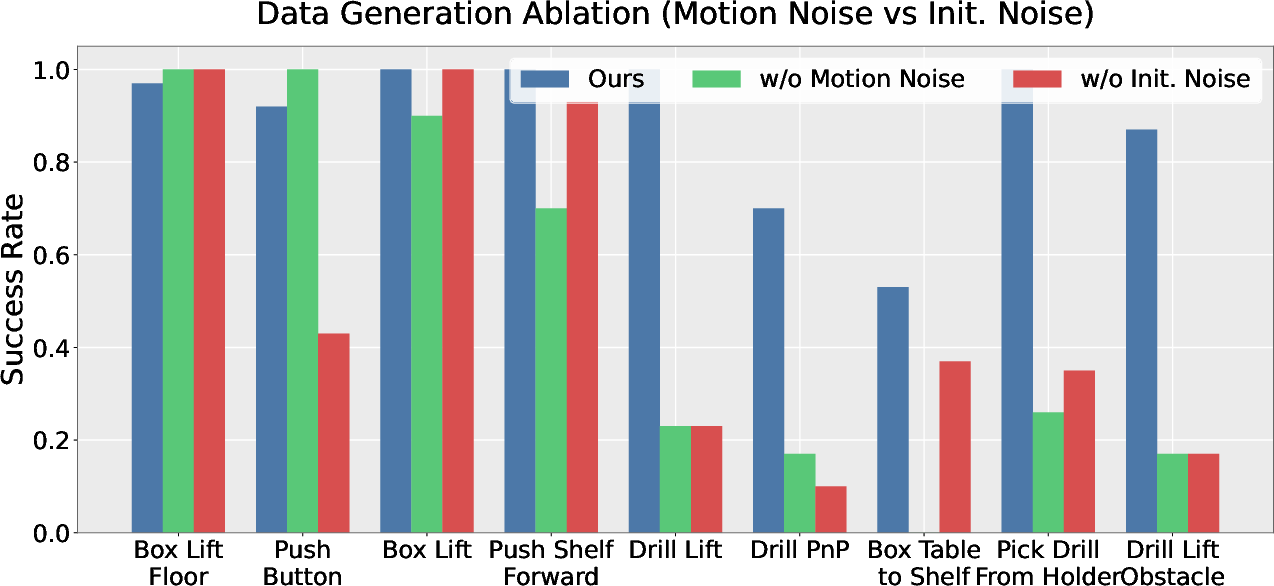
Figure 3: Policy architecture ablation shows VLAs trained on HumanoidMimicGen data outperform flow matching and diffusion policy baselines; ablation studies underscore the importance of noise and randomization in data generation for robust policy learning.
- Impact of Data Randomization: Ablations show that removing motion noise or robot pose initialization randomization during generation reduces average PSR by 0.4, demonstrating these strategies are essential for transferability and generalization.
- Policy Architecture Analysis: VLA models fine-tuned on HumanoidMimicGen data outperform both AdaFlow-based flow-matching and diffusion policy baselines across all tasks.
- Whole-Body Skill Adaptation and Constraint Handling: Skill decomposition and constraint annotation enable systematic and scalable data amplification for tasks with complex interleaving and concurrency requirements.

Figure 4: Precedence and coordination graph for Table-to-Shelf task: HumanoidMimicGen compiles annotated coordination and ordering constraints into explicit execution DAGs for flexible sequencing.

Figure 5: Whole-body adaptation for a pick skill; target poses and planning maintain geometric task invariance when synthesizing new trajecories from a reference demonstration.
Real-World Sim-and-Real Co-Training
Sim-and-real co-training is evaluated on a G1 humanoid across four real-world loco-manipulation tasks, including coordinated bimanual pick-and-place and obstacle navigation. Co-training policies with HumanoidMimicGen-generated simulation trajectories and real robot demonstrations improves real-world policy scores by 20% on average compared to real-only regimes.








Figure 6: Real-world deployment results demonstrate co-training with HumanoidMimicGen simulation data enables humanoid performance improvements on real-world manipulation tasks.
Limitations
- Manual Annotation Requirements: Skill segmentation and constraint annotation currently require human intervention, limiting scalability.
- Fixed Skill Structure: The approach presumes a fixed set and sequencing of skills, reducing flexibility for novel task compositions.
- Rigid Object-Frame Mapping: Generalization to tasks involving large geometric variability or unspecified affordances is limited, although extensions such as constraint-preserving generation (e.g., CP-Gen [lin2025cpgen]) may address this.
Implications and Future Directions
HumanoidMimicGen enables scalable, high-diversity data generation for robust humanoid loco-manipulation policy learning without the prohibitive cost of large-scale teleoperation. The methodology demonstrates that simulation data, carefully synthesized with task constraints and realistic control, can significantly advance sample efficiency and transfer. The benchmarking suite also provides a reproducible foundation for evaluating future generative data and policy learning frameworks.
Future developments should focus on automating skill discovery, constraint annotation, and environment creation, possibly leveraging foundation models for task inference. Adaptation to tasks with unstructured or novel skill hierarchies and improved handling of intra-category object variation remain critical for advancing the generalist capabilities of humanoid robots. Extensions integrating semantic or language-guided task specification and multi-modal perception are natural next steps.
Conclusion
HumanoidMimicGen represents a significant advancement in humanoid loco-manipulation data generation, providing a systematic pipeline for scaling policies to challenging, coordinated real-world tasks. The integration of hybrid control, constraint-guided planning, and robust data augmentation achieves strong policy generalization and transfer. The results validate the essential role of simulation-based, task-aware data synthesis in enabling practical large-scale training and deployment of humanoid robots for complex human-centric environments.