- The paper introduces a scalable teacher-student framework that leverages privileged RL and vision-based policy distillation for zero-shot transfer in complex humanoid loco-manipulation tasks.
- The methodology employs a delta action space and comprehensive domain randomization, resulting in robust sequential task performance across 59 real-world trials.
- The approach achieves near expert-level performance by integrating large-scale simulation, precise camera calibration, and system identification to bridge the sim-to-real gap.
VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
Overview and Motivation
The paper "VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation" (2511.15200) introduces a scalable framework for enabling autonomous humanoid loco-manipulation using pure onboard RGB vision and large-scale simulation. Existing approaches in humanoid robotics either focus on blind locomotion, static tabletop manipulation, or require extensive teleoperation and external sensing. VIRAL bridges these paradigms by leveraging privileged-state @@@@2@@@@ (RL) in simulation, followed by vision-based policy distillation, yielding zero-shot deployment capability for complex sequential tasks such as walking, grasping, placing, and turning with real hardware.
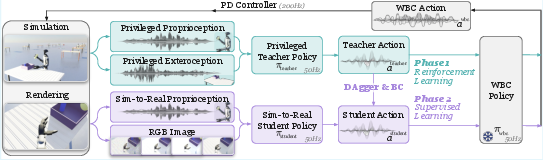
Figure 1: Teacher-student pipeline illustrating Phase 1 (privileged teacher RL on full-state simulation) and Phase 2 (student policy distillation using onboard vision and proprioception).
Teacher-Student Framework and Simulation Methodology
The VIRAL framework employs a two-stage pipeline:
- Privileged RL Teacher: The teacher policy uses a goal-conditioned RL formulation, operating in the full privileged state space (proprioception, exteroception). It outputs delta commands for a robust whole-body controller (WBC), significantly increasing reliability and alleviating low-level reward engineering. The use of delta action space, rather than absolute motor commands, is empirically shown to accelerate learning and stabilize training for long-horizon loco-manipulation. Critical components such as reference state initialization (borrowing states from demonstration buffers) facilitate exploration and are essential for high final success rates.

Figure 2: Reference state initialization mechanism, sampling from teleoperated demonstration buffers to diversify RL resets and accelerate learning.
- Vision-Based Student: The student policy observes only RGB images and proprioceptive signals available on real hardware. Distillation occurs via a hybrid online DAgger and behavior cloning regime, interpolating between teacher and student rollouts for robust error correction. High-capacity image encoders (DINOv3) are fused with proprioceptive inputs. Training occurs at scale (up to 64 GPUs, 65k parallel environments) with extensive tiled renderings and large-batch distributed simulation.
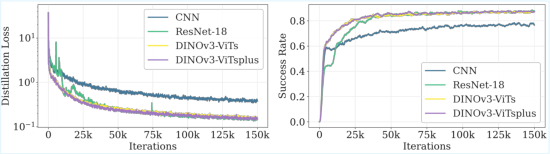
Figure 3: Ablation of the student policy's vision backbone, highlighting significant gains with state-of-the-art representation learning.
Sim-to-Real Bridging: Randomization and System Alignment
To mitigate the sim-to-real gap, VIRAL integrates exhaustive domain randomization and physical alignment:
- Visual and Material Randomization: Scene assets, lighting, material, image effects, camera pose, and sensor delay are randomized during training to maximize robustness and generalization.

Figure 4: Examples of visual domain randomization over image, lighting, material, and camera extrinsics to enhance transfer robustness.
- System Identification & Camera Alignment: The Unitree G1’s dexterous hand (high gear ratios) is aligned via trajectory-matching system identification. Camera intrinsics and extrinsics are calibrated to match simulated renderings to real hardware, compensating for mechanical tolerances and drift.

Figure 5: Outcome of SysID alignment: improved correspondence between simulated and real joint trajectories of the dexterous hand.

Figure 6: Camera extrinsics alignment: real-world image compared to simulated views before and after calibration.
VIRAL policies achieve high success in continuous real-world loco-manipulation cycles:
- Reliability and Efficiency: Across 59 consecutive trials, the humanoid achieves 54 successful runs, operating faster than a human expert teleoperator and outperforming non-experts in both reliability and speed.
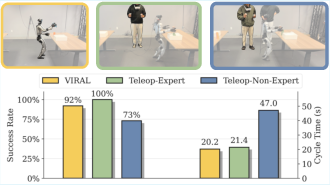
Figure 7: Real-world comparison: VIRAL policy matches expert-level reliability, operates faster than expert teleoperator, and significantly outperforms non-expert human users.
- Generalization: The vision-based student generalizes to substantial variations in spatial configuration, objects, lighting, and environment appearance, requiring no real-world fine-tuning.

Figure 8: Demonstration of generalization under scene, pose, object, and appearance variations.
Ablation Studies and Scaling Laws
Extensive ablations identify the key drivers of policy success:
- Reference State Initialization and Delta Action: Both are crucial for overcoming RL reward engineering bottlenecks and stabilizing long-horizon learning.
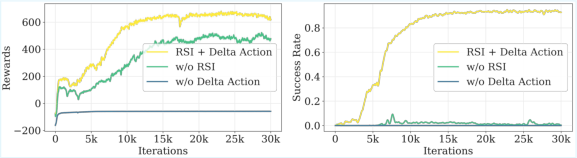
Figure 9: Teacher policy training ablations: both RSI and delta action space are required for high final reward and success rates.
- Randomization: Each randomization variant (material, dome light, camera extrinsics) contributes complementary gains; removing any rapidly degrades success in deployment environments.
- Compute Scaling: Increasing simulation scale from 1 to 16 GPUs for teacher and from 1 to 64 GPUs for student yields faster convergence, higher asymptotic performance, and smoother training dynamics—demonstrating that substantial compute is not optional, but necessary, for robust visual sim-to-real learning.
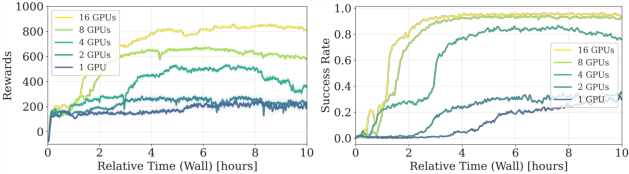
Figure 10: Teacher RL scaling law: more parallel GPUs yield faster convergence and higher asymptotic success.
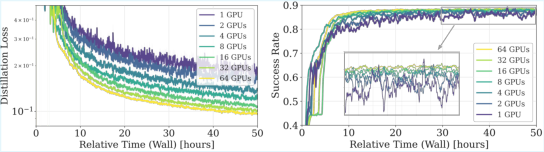
Figure 11: Student policy scaling law: increased GPU count accelerates training and improves both final success rates and optimization stability.
Implications and Theoretical Impact
VIRAL demonstrates that high-fidelity visual sim-to-real, at modern simulation and compute scales, can yield vision-only humanoid policies that operate with near-expert reliability across long-horizon sequential tasks. This addresses historic bottlenecks in symbolic pipeline design, reward engineering, and transfer robustness, shifting the emphasis from manual data collection to scalable simulation. The teacher-student architecture decouples privileged reasoning from deployable vision, suggesting a blueprint for integrating simulation-driven skill discovery with scalable sensory distillation.
However, the authors note significant limitations in scaling these methods to general-purpose open-world tasks: environmental physics complexity, asset coverage for real-world diversity, reward design scaling, and hardware actuation gaps remain critical barriers. They speculate that future progress will require not pure simulation, but synergistic integration with large-scale real-world imitation learning and foundation models—a holistic data-centric ecosystem that leverages both virtual and embodied experience.
Conclusion
VIRAL presents a comprehensive framework for visual sim-to-real humanoid loco-manipulation, empirically validating the effectiveness of privileged RL, large-scale simulation, rigorous system identification, and aggressive domain randomization. The work offers a technical recipe for scaling embodied policy learning beyond tabletop or blind navigation, demonstrates robust zero-shot transfer, and delineates the practical boundaries of simulation-based robotics. The methodology informs future development of scalable, robust, and generalist loco-manipulation systems, while highlighting the enduring necessity for real-world data and multi-modal learning integration.

