Geometry of Human Perceptual Domains Emerges Transiently in LLM Representations
Abstract: While LLMs are trained purely on textual data, prior work has shown that their internal representations can exhibit rich geometric structure in embedding space. Building on this line of work, we investigate whether such structure is similar to human perceptual organisation across different domains (e.g., color, pitch, emotion, and taste). Specifically, we study the layer-wise emergence of intrinsic geometrical structure corresponding to perceptual modalities within the residual streams of multiple open-weight transformer architectures. Our results reveal three key findings. First, we observe the emergence of layer-wise geometric structure across multiple perceptual domains, despite the absence of any direct perceptual supervision during training. Second, these perceptual domains exhibit distinct emergence profiles, with both geometric structure and its alignment with human baselines following domain- and model-specific trajectories across depth. Third, this emergence follows a consistent representational trajectory: geometry is weak or diffuse in early layers, becomes progressively organised in intermediate layers, and is attenuated in later layers, suggesting that perceptual geometry arises transiently as part of the model's internal transformation pipeline. This provides new insight into how and where human-like perceptual geometry arises in LLMs, offering a principled pathway for mechanistic analysis of internal representations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Explanation of “Geometry of Human Perceptual Domains Emerges Transiently in LLM Representations”
Overview: What is this paper about?
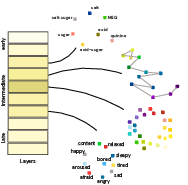
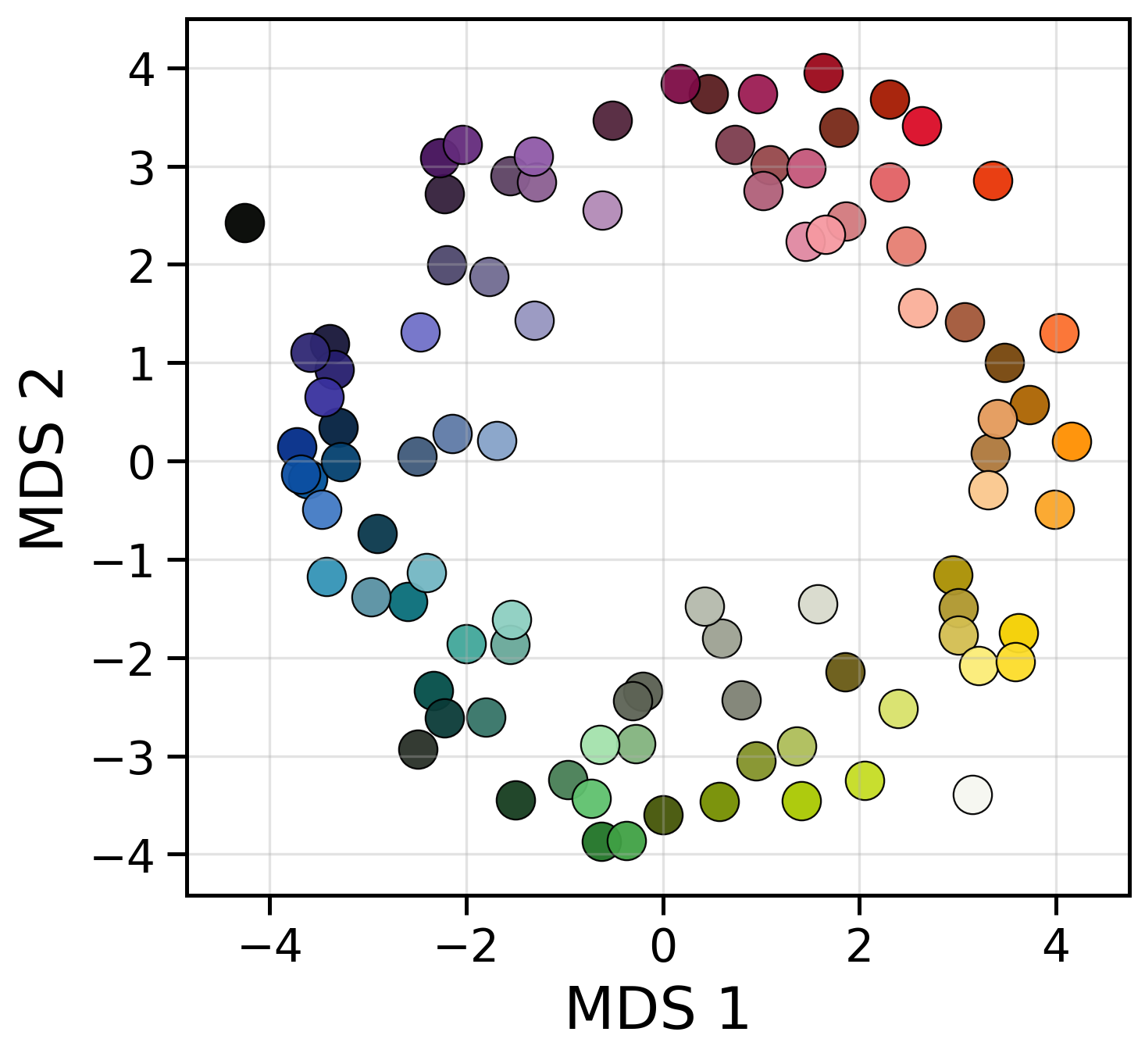
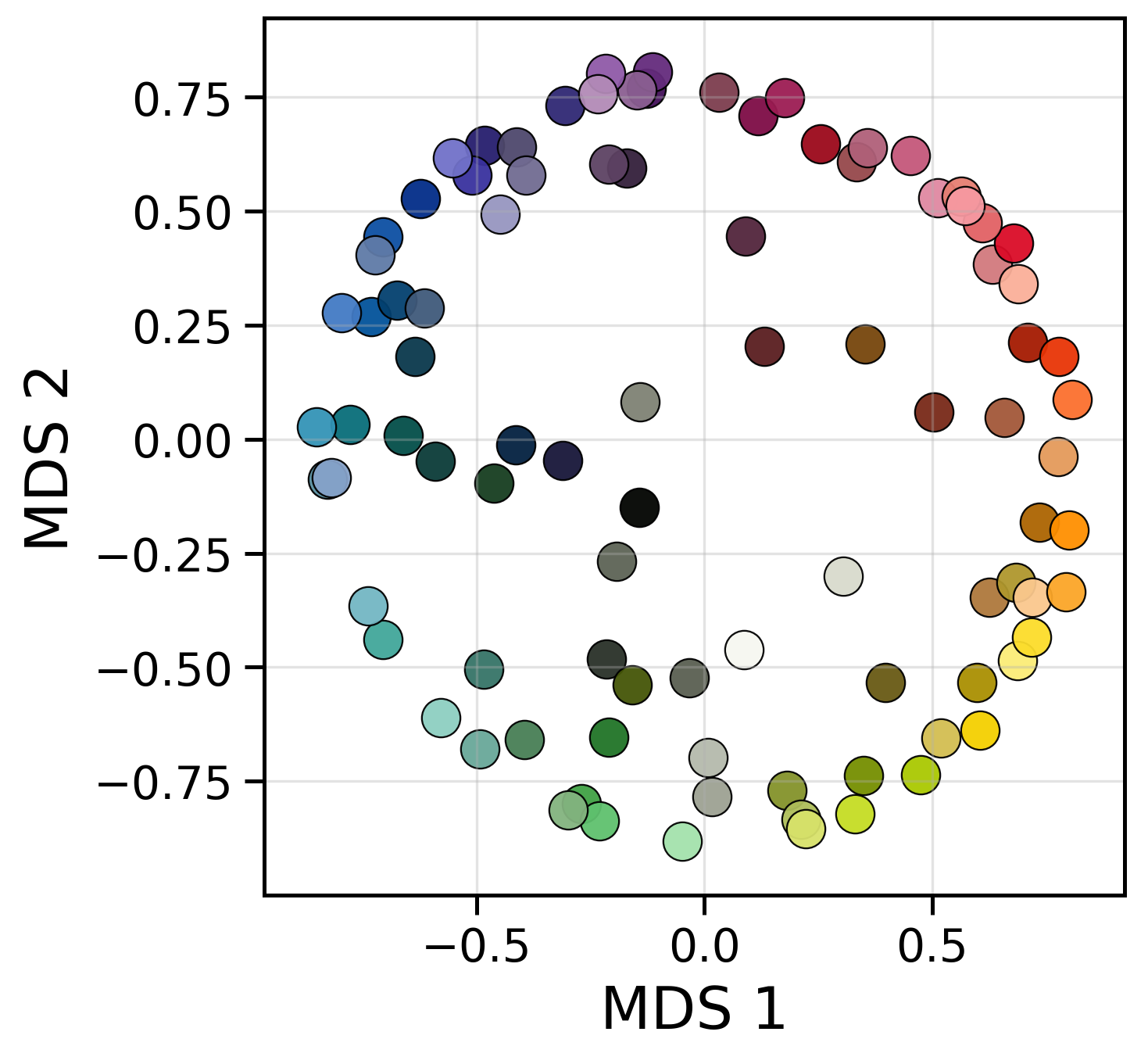
This paper asks a surprising question: even though LLMs learn only from text, do they build “mental maps” inside themselves that look like how humans sense things like color, sound pitch, taste, and emotions? The authors show that, inside the layers of several LLMs, the arrangement of internal representations briefly forms shapes that match human perception—for example, colors arranged in a circle like a color wheel.
Key questions the researchers asked
- Do LLMs naturally organize different kinds of human experiences (color, pitch, taste, emotion) in their internal representations, even without seeing or hearing them?
- If they do, when and where inside the model do these human-like shapes appear?
- Are these shapes steady or do they appear and disappear as the model processes text?
How they did it (in everyday terms)
Think of the inside of an LLM as a big workspace where it turns words into numbers that act like locations on a map.
Here’s the basic approach:
- The authors gave the model very simple prompts for items in four areas:
- Color (e.g., “The description of the color given as #9B081A”)
- Pitch (e.g., “The description of sound of musical tone 440 Hz”)
- Taste (e.g., “The description of taste on tongue given by salty”)
- Emotion (e.g., “Describe the person who is feeling joy”)
- At every layer inside the model, they collected the internal vector for each item. You can imagine each item getting a “pin” dropped somewhere on that layer’s map.
- They measured how far apart each pair of pins was. The idea is simple: items that are “more similar” should be closer together.
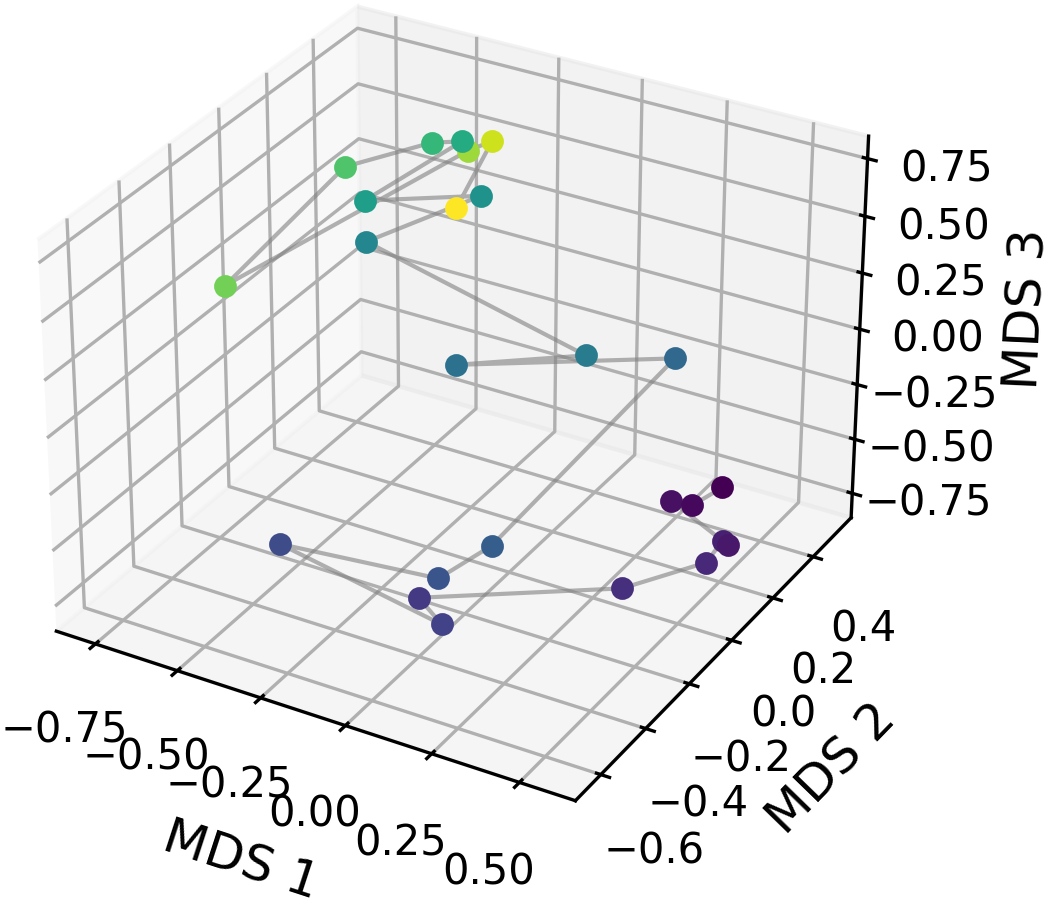
- They then used a tool called multidimensional scaling (MDS) to arrange these pins in 2D (like laying them out on a table) to see the shape that best fits the measured distances.
- Finally, they compared the model’s shape to known human “perceptual maps” using two checks:
- RSA (Representational Similarity Analysis): compares how pairs of items relate in both maps. Think of it as comparing two distance charts.
- GPA (Generalized Procrustes Analysis): tries rotating and resizing one map to see how well it can line up with the other. Think of overlaying two maps and moving one until it matches the other shape.
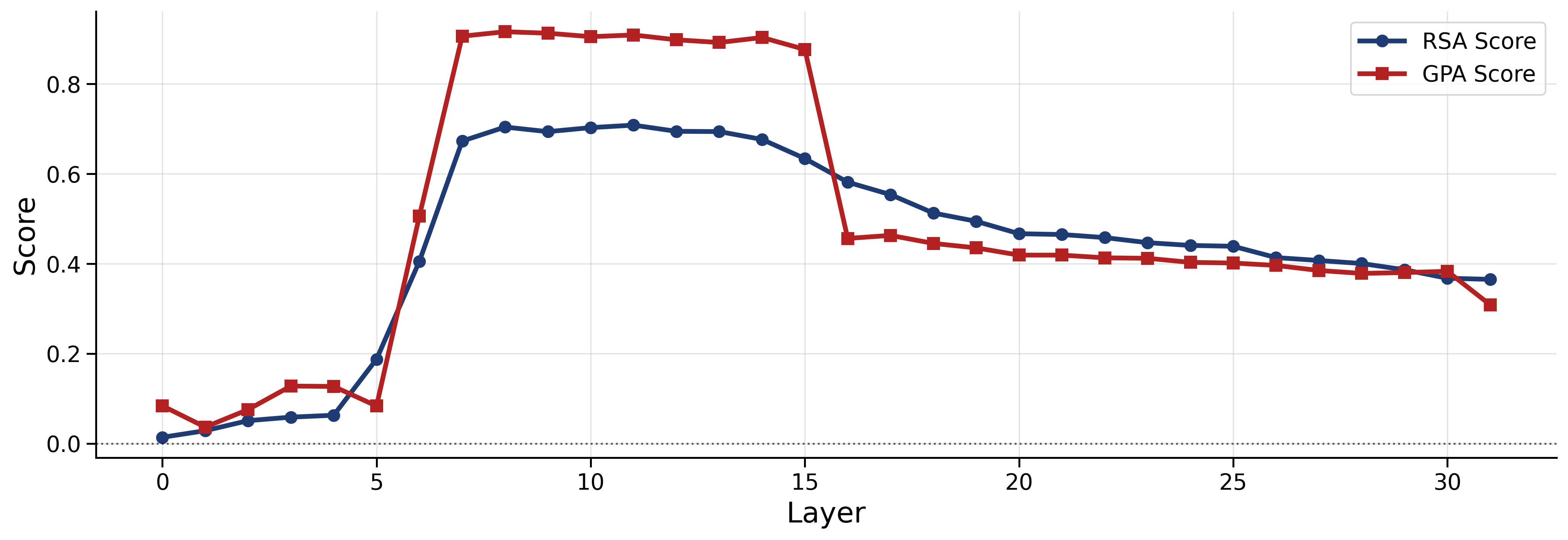
This was done layer-by-layer to see how the internal “maps” change as information flows through the model from early to late layers.
Main findings and why they matter
The authors report three big findings:
- Human-like “geometry” appears inside LLMs—even though they only see text
- Color: The model’s internal map forms a circle, similar to the human color wheel.
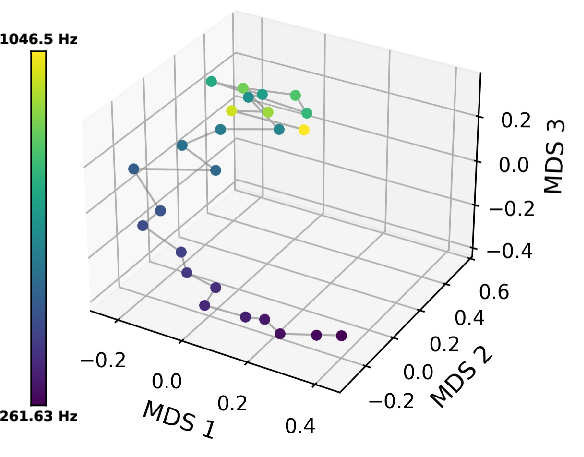
- Pitch: The model arranges tones smoothly by frequency (like a curve or spiral), not as unrelated points.
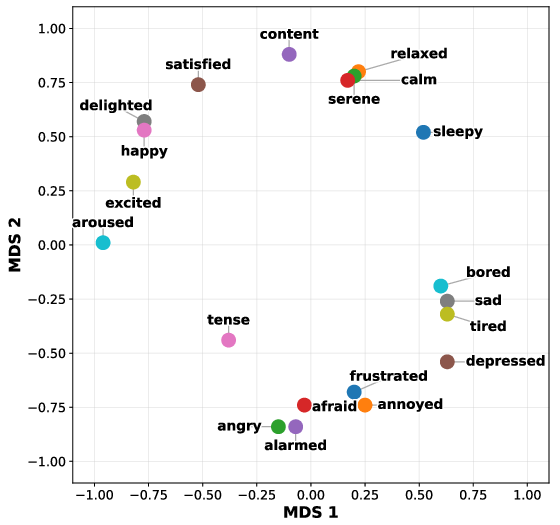
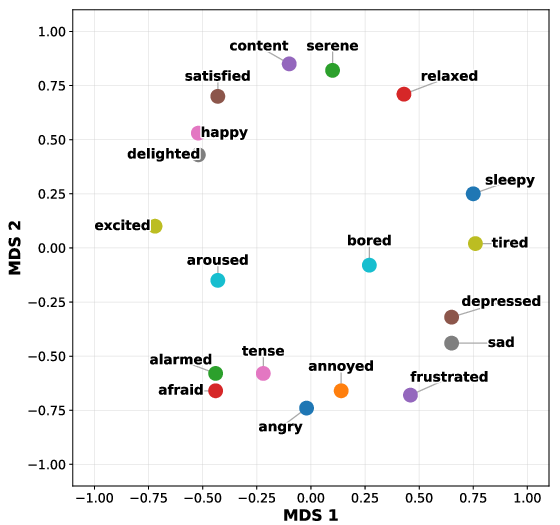
- Emotion: The model’s shape matches the well-known “valence–arousal” space (happy vs. sad, calm vs. excited).
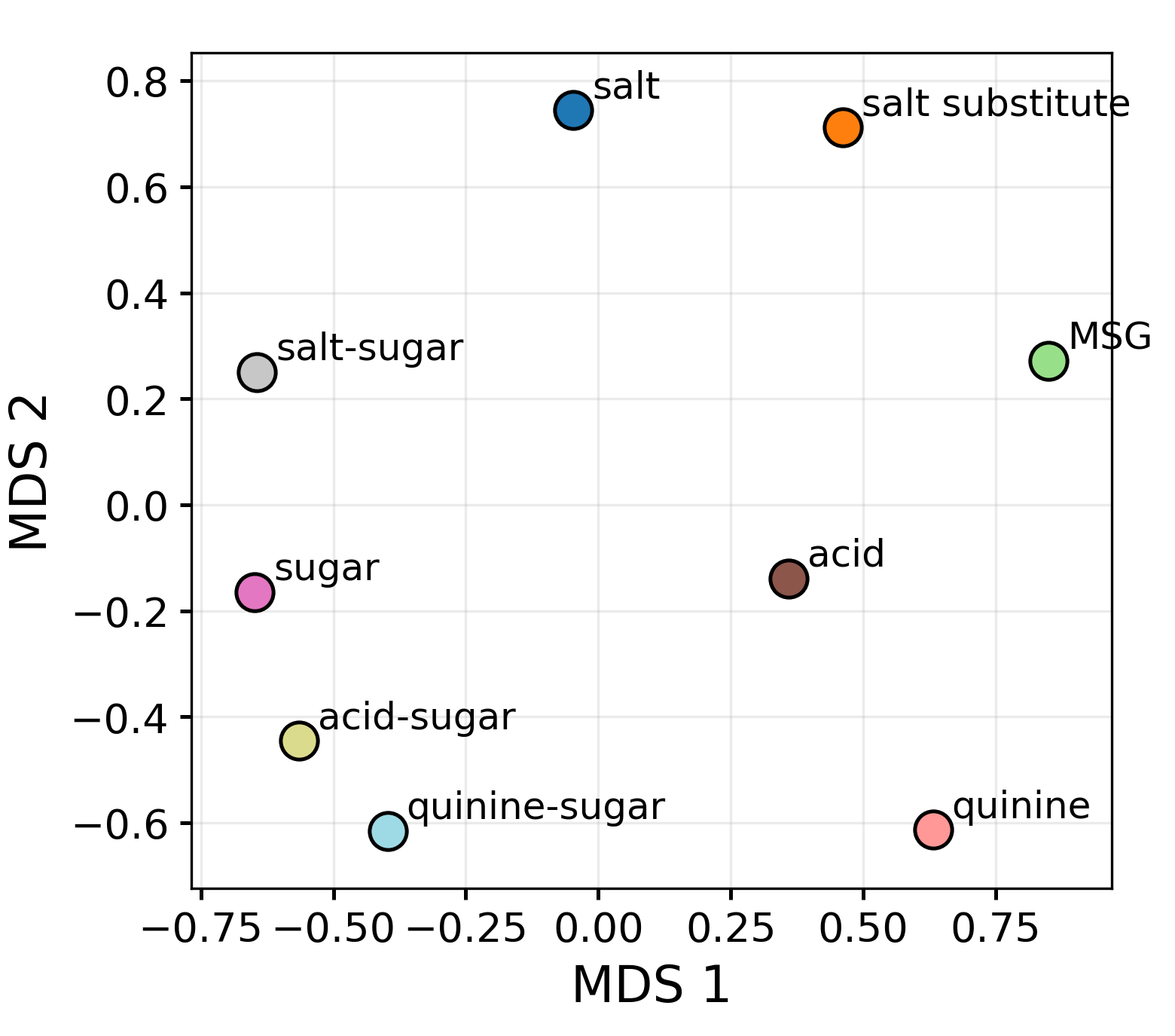
- Taste: The model recovers an organized taste layout (e.g., salty vs. sweet relationships), though this is noisier and less stable.
Why it matters: This suggests that patterns you can read about in language (like how people talk about colors or emotions) are enough for LLMs to build internal structures that resemble human perception.
- Each sense has its own “emergence profile”
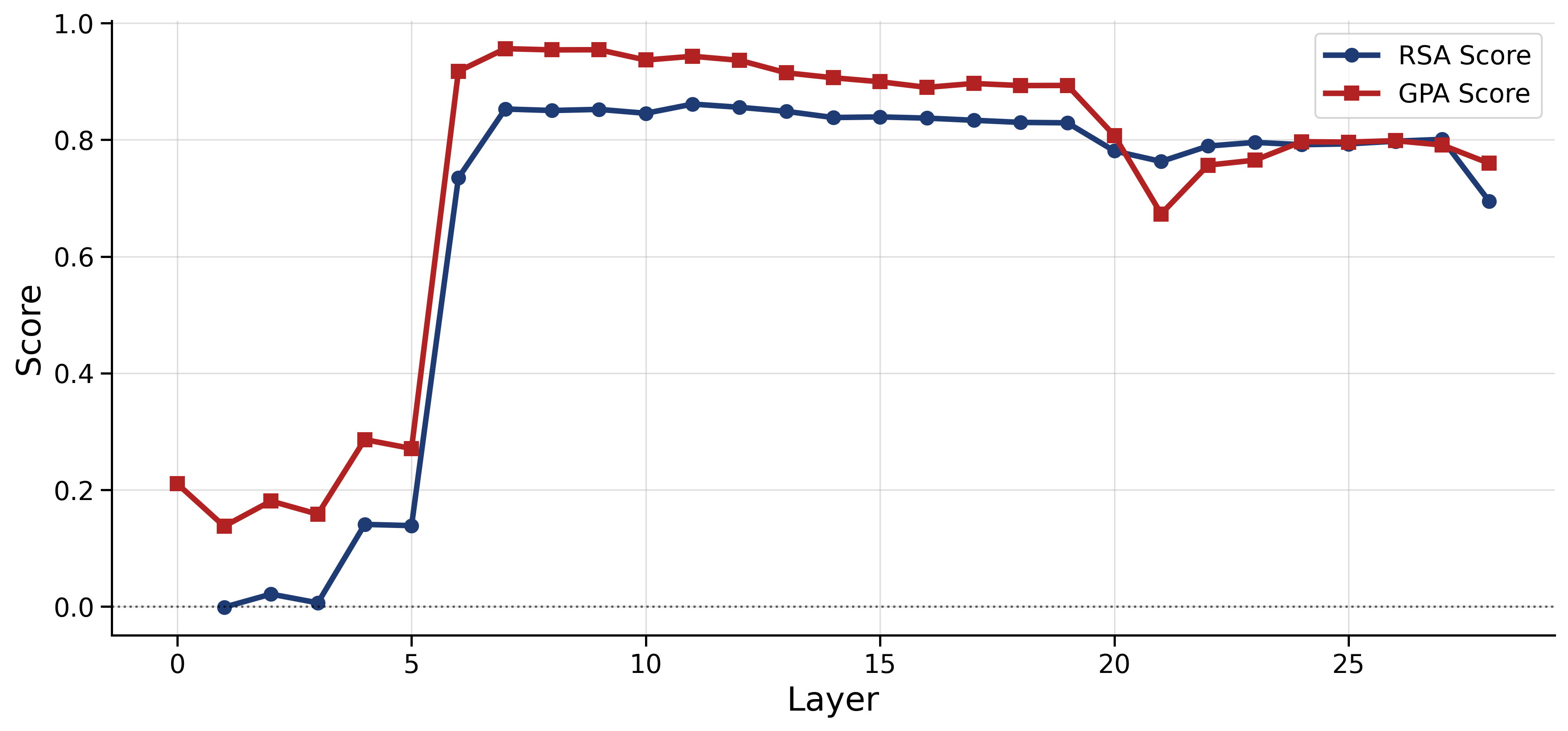
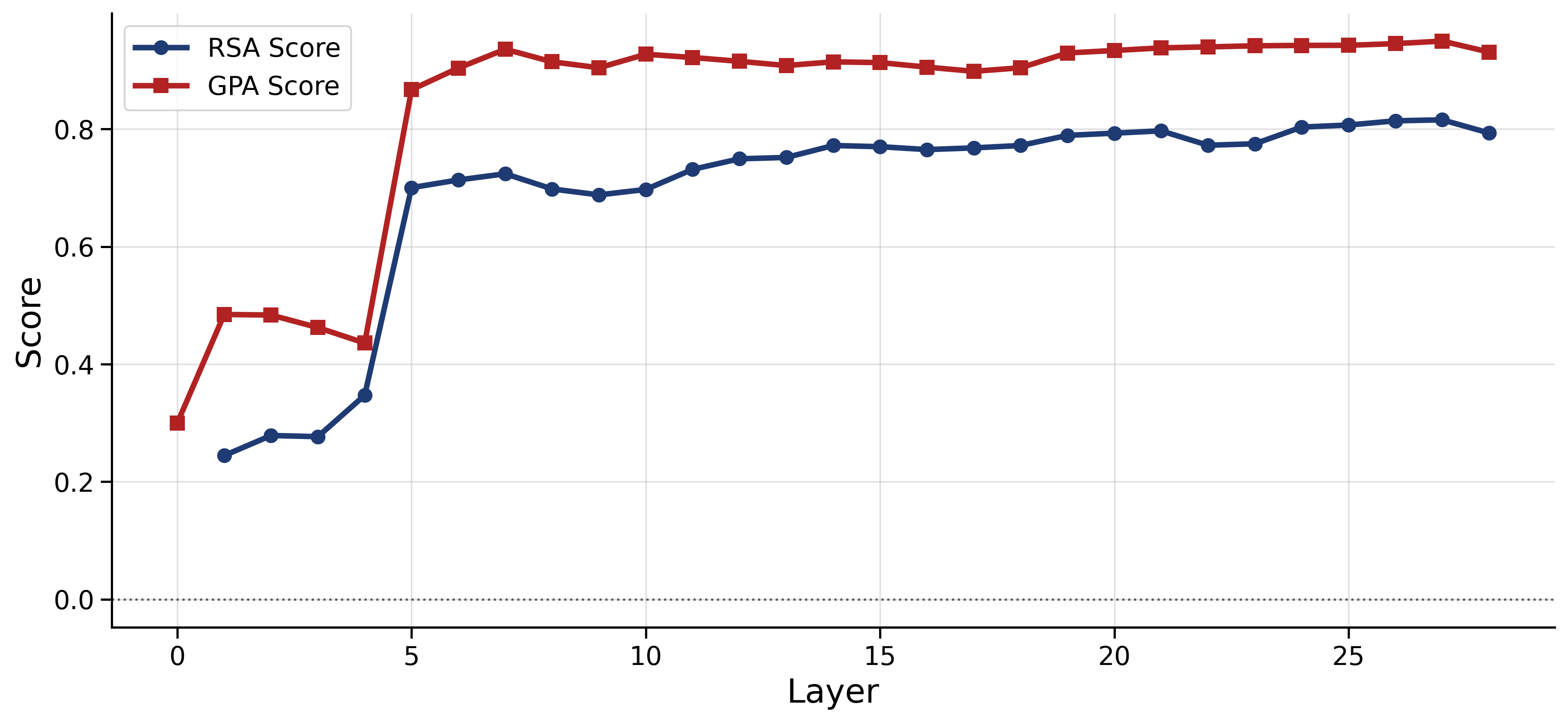
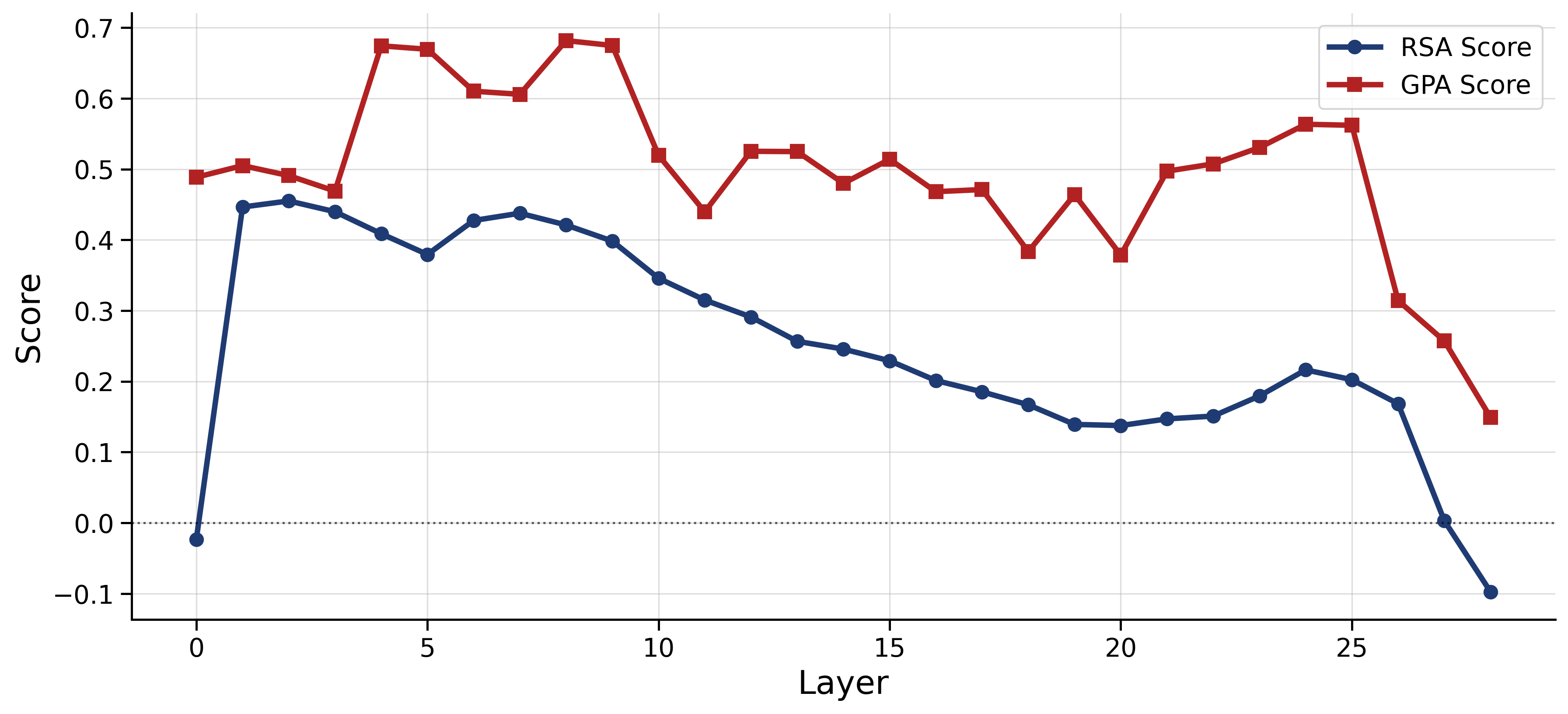
- Color and pitch: Their geometry gets clear in the middle layers and then fades in later layers.
- Emotion: Its geometry is strong and stays more stable across later layers.
- Taste: It pops up early but is less precise and becomes noisy quickly.
Why it matters: Not all kinds of knowledge are treated the same by the model. Some “maps” are more stable, some are brief and fragile.
- The geometry is transient: strong in the middle, weaker at the ends
- Across models, early layers are messy, middle layers become well organized, and late layers fade or shift the geometry.
- One model (Qwen) even showed a brief rebound for color late in the network, hinting that different models may have different internal pipelines.
Why it matters: This gives a practical roadmap for interpretability—if you’re looking for where the model captures human-like relationships, the middle layers are often the best place to look.
What this could mean going forward
- Better interpretability: Knowing where and when these shapes show up helps researchers inspect and understand what a model “knows.”
- Model design and control: If we want models to keep or use these human-like structures, we might design training or decoding strategies that preserve them instead of letting them fade.
- Bridging language and perception: This work suggests that language alone carries a lot of structure about human experience. That said, the authors caution that matching geometry does not mean the model “sees” or “feels” like a human—it just organizes information in a similar shape.
- Future research: The study is descriptive (it shows what happens, not exactly why). Understanding the exact mechanisms that create these shapes, expanding to more senses, and trying more comparison methods are important next steps.
In short, the paper shows that inside LLMs, human-like “maps” of color, pitch, taste, and emotion briefly appear and are most clear in the middle layers—an encouraging sign for understanding and guiding what these models learn from language.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so that future work can act on it.
- Mechanistic cause: Which specific architectural components (attention heads, MLPs, layer norms) and circuits create, maintain, and attenuate the observed perceptual geometries across depth?
- Residual-stream exclusivity: Do similar emergence patterns occur in attention-only outputs, MLP outputs, or token-embedding spaces, or are they unique to the residual stream?
- Token/position dependence: How sensitive are the findings to which token’s hidden state is analyzed (e.g., first/middle/last token, BOS/EOS) and to the position of the stimulus within the prompt?
- Prompt sensitivity and lexical confounds: Do alternative phrasings, languages, or removal of words like “color/emotion/taste/sound” (and units like “Hz”) change the geometry, indicating reliance on surface lexical cues?
- Numeric/code-format artifacts: For pitch (Hz) and color (hex), does geometry persist when stimuli are expressed without numbers/codes (e.g., note names, color names) or under perturbations (e.g., shuffled number–stimulus mappings) that break trivial textual similarity?
- Context effects: Does perceptual geometry survive in more naturalistic sentences, varied syntactic frames, or longer contexts versus the minimal prompts used?
- Cross-lingual robustness: Are the layer-wise emergence profiles invariant across languages and in multilingual models, given cultural/linguistic variation in perceptual vocabularies?
- Model family and scaling laws: How do emergence timing, strength, and transience vary systematically with model size within a single family and across pretraining recipes (base vs instruction-tuned vs RLHF)?
- Training dynamics: At what pretraining stage (training steps or data volumes) do these geometries first appear, and how do they evolve during continued training or fine-tuning?
- Causality and necessity: Are these geometries functionally used for downstream predictions (e.g., do targeted ablations or activation patching that disrupt geometry impair related outputs)?
- Persistence vs task specialization: What computations in later layers attenuate or deform geometry, and are there tasks or heads that specifically suppress or preserve these structures?
- Generality across modalities: Do the reported transience and modality-specific profiles extend to other perceptual domains (e.g., brightness, timbre, texture, shapes, temperature, pain)?
- Dataset–stimulus coverage: How do results change with denser sampling (e.g., more hues, multiple octaves for pitch to reveal spirals), continuous gradients, or alternative human baselines?
- Topology vs geometry: Are there topological invariants (e.g., circularity for hue, helical/spiral for pitch across octaves) preserved in high-dimensional representations beyond 2D/3D projections?
- Dimensionality reduction bias: How robust are conclusions to embedding choices (MDS vs Isomap vs UMAP/t-SNE), hyperparameters, and random seeds, especially when GPA requires coordinate embeddings?
- Distance metric and anisotropy: Do conclusions hold under alternative representational measures (e.g., Euclidean, Mahalanobis, CKA, centered cosine) and after de-anisotropization/whitening?
- Noise ceiling and chance baselines: What is the attainable upper bound given human inter-rater variability, and how far above permutation/shuffled-label baselines are the RSA/GPA scores?
- Multiple comparisons and uncertainty: Were statistical corrections applied across many layers/models, and how do conclusions change under stricter control of false discovery rates?
- Human baseline alignment: For emotions, does using VAD-only capture the relevant human geometry, or do alternative affective models (e.g., discrete categories, PAD variants) alter alignment outcomes?
- Cross-dataset consistency: Do results replicate with independent human datasets per modality (e.g., different color spaces, pitch similarity matrices, taste taxonomies)?
- Dependence on tokenization: Do tokenization schemes (e.g., how hex codes, numerals, and rare words are split) influence the emergence profiles, and can retokenization mitigate artifacts?
- Comparative baselines: How do these effects compare to static embeddings (e.g., GloVe, fastText) or small n-gram models to isolate what depth and attention specifically contribute?
- Subspace extraction: Can one identify simple linear/nonlinear subspaces (e.g., valence/arousal axes, hue angle) within layers that predict human dimensions and track their evolution across depth?
- Category sharpening: Does late-layer attenuation reflect categorical sharpening (e.g., discrete emotion clusters) versus loss of structure, and can this be quantified with clustering/linearity metrics?
- Architecture-specific anomalies: What explains model-specific deviations (e.g., Qwen’s late-layer rebound in color), and are these tied to training data, objectives, or architectural hyperparameters?
- Transfer and control: Do layers with strongest geometry improve zero-shot performance on perceptual-language tasks; does probing those layers yield better linear readouts than other layers?
- Robustness to adversarial/counterfactual stimuli: Does geometry persist when stimuli are adversarially constructed (e.g., semantically incongruent descriptors) to decouple text similarity from perceptual similarity?
- Cultural and individual variability: How does alignment change when using human baselines from different cultures or individual-level judgments rather than aggregated norms?
- Reproducibility details: Precise model variants, seeds, and preprocessing choices (e.g., layer indexing, normalization) are not fully specified; can independent labs replicate the reported profiles?
Practical Applications
Immediate Applications
The paper’s findings enable several deployable use cases that exploit transient, mid-layer geometric organization of perceptual domains (color, pitch, taste, emotion) in open-weight LLMs.
- Interpretability and model diagnostics toolkit (AI/ML R&D, policy)
- What: “Perceptual Geometry Profiler” that computes layer-wise RSA/GPA against human baselines and visualizes qualia maps (MDS/Isomap) to locate peak-emergence layers per domain.
- Tools/workflow: Minimal prompts → layer activations → pairwise cosine distances → RSA/GPA with bootstrap CIs → 2D maps dashboard.
- Assumptions/dependencies: Access to hidden states (open-weight or APIs exposing activations); curated stimulus sets; compute for per-layer passes.
- Mid-layer readouts for emotion-aware text analytics and tone control (software, customer support, education)
- What: Extract valence–arousal (VAD) coordinates from peak layers for sentiment/affect scoring and controllable response generation (e.g., style sliders in chat).
- Tools/workflow: Linear readouts on mid-layer residuals; lightweight regressors for VAD; steering vectors to nudge outputs along valence/arousal axes.
- Assumptions/dependencies: Peak layer varies by model; requires calibration and safety controls; VAD baselines (ANEW) are culture- and language-sensitive.
- Color semantics and palette tooling using mid-layer color wheel (design software, e-commerce)
- What: Color naming, similarity search, and palette generation grounded in the emergent circular color manifold.
- Tools/workflow: Mid-layer embedding index for HEX codes; palette clustering and nearest-neighbor retrieval; “semantic color search” in asset libraries.
- Assumptions/dependencies: Minimal prompt templates for color; layer position must be profiled per model; may not capture complex perceptual phenomena (e.g., metamerism).
- Pitch-aware language utilities (music education, tagging, music tech)
- What: Ordering/spacing of pitch descriptors (Hz, notes) and reasoning about intervals using the emergent continuous pitch manifold.
- Tools/workflow: Mid-layer extraction for pitch tokens; mapping to ranked scales, interval descriptions, or practice exercises in education tools.
- Assumptions/dependencies: Text-only; no audio grounding; mid-layer manifold deforms in late layers—must query near peak layer.
- Taste similarity for product description and recommendation (food tech, CPG)
- What: Organize flavor descriptors and map product copy to taste space for consistent labeling and coarse similarity search.
- Tools/workflow: Readouts on early-mid layers; clustering of descriptors; suggestion of adjacent taste descriptors in copywriting.
- Assumptions/dependencies: Taste geometry is noisier and less stable (lower RSA); validate with human panels before production use.
- Adapter placement and efficient fine-tuning (NLP product development)
- What: Place LoRA/adapters on peak-emergence layers per domain to steer emotion tone, color naming, or pitch reasoning with minimal compute.
- Tools/workflow: Run profiler → identify peak layers → attach small adapters → validate with domain tasks.
- Assumptions/dependencies: Emergence profiles are domain- and model-specific; re-profile after any base model update.
- Post-training QA and regression tests (MLOps, governance)
- What: Treat RSA/GPA trajectories as regression checks to detect representational drift after fine-tuning or quantization.
- Tools/workflow: Baseline qualia maps and scores stored per release; CI pipeline flags significant degradation.
- Assumptions/dependencies: Requires stable stimulus sets and thresholds; interpret changes cautiously (not all drift is harmful).
- Teaching and outreach demos (education)
- What: Interactive visualizations of how perceptual manifolds emerge and fade across layers, to teach semantics and representation learning.
- Tools/workflow: Lightweight web app showing layer slider, qualia maps, and correlation metrics.
- Assumptions/dependencies: None beyond open models and compute to precompute maps.
- Finance/social analytics sentiment signal (finance, media analytics)
- What: Use VAD mid-layer features as robust, continuous sentiment inputs to downstream models (e.g., news impact scoring).
- Tools/workflow: Batch inference to extract VAD embeddings; feed as features to risk or event models.
- Assumptions/dependencies: Domain shift and cultural bias risks; requires backtesting and compliance review.
- Prompting guidelines for sensory queries (prompt engineering)
- What: Adopt minimal, structured prompts to reduce confounds when eliciting perceptual representations.
- Tools/workflow: Standardize templates (e.g., “The description of color given as #HEXCODE”, etc.) in internal playbooks.
- Assumptions/dependencies: Prompt variations can shift geometry; keep templates consistent across evaluations.
Long-Term Applications
Several higher-impact directions require additional research, scaling, or productization to realize.
- Multimodal alignment via intrinsic manifolds (multimodal AI, robotics, AR/VR)
- What: Use text-derived color/pitch manifolds as anchor subspaces to align small visual/audio encoders without full joint training (“manifold matching”).
- Tools/workflow: Procrustes alignment between sensory encoder embeddings and LLM mid-layer manifolds; joint fine-tuning or contrastive losses.
- Assumptions/dependencies: Needs robust cross-domain correspondences; risk of “false alignment” without ground-truth supervision.
- Mechanistic steering for affect and style (creative tools, conversational AI)
- What: Develop reliable “perceptual steering vectors” to control tone (VAD), color semantics in generation, or pitch-related textual reasoning, with UI sliders.
- Tools/workflow: Mechanistic mapping of residual directions across depth; guardrails to prevent undesired side effects.
- Assumptions/dependencies: Requires deeper causal understanding of transient encoding and interference with other features.
- Regulatory interpretability standards (policy, compliance)
- What: “Perceptual Geometry Audit Reports” as part of transparency documentation; standardized RSA/GPA checks for specified domains.
- Tools/workflow: Open benchmarks and protocols; third-party verification.
- Assumptions/dependencies: Agreement on domains/metrics; access to intermediate activations for audit.
- Clinical-grade affect sensing and intervention support (healthcare, mental health)
- What: Use validated VAD subspaces for early warning of affect shifts and personalized intervention suggestions in digital therapeutics.
- Tools/workflow: Calibrated classifiers on mid-layer features; clinician-in-the-loop oversight.
- Assumptions/dependencies: Requires rigorous clinical validation, bias audits, and regulatory approval; cultural generalization must be tested.
- Language-to-music copilots with pitch reasoning (music production)
- What: Better interpretation of natural-language instructions about tuning, transposition, and scales by anchoring to the pitch manifold; later, connect to audio models.
- Tools/workflow: Hybrid LLM + symbolic/music-theory modules; eventual alignment with audio embeddings.
- Assumptions/dependencies: Stronger grounding in audio needed for professional workflows.
- Flavor and formulation R&D (food science)
- What: Integrate taste manifold with chemical descriptors and sensory panels to guide recipe iteration and novel flavor discovery.
- Tools/workflow: Multimodal embedding fusion; experimental validation loops.
- Assumptions/dependencies: Current text-only taste geometry is coarse and unstable; requires richer datasets and grounding.
- Cross-lingual and cultural manifold alignment (global products)
- What: Build culturally aware VAD and taste/color mappings by profiling models across languages and aligning or adapting subspaces.
- Tools/workflow: Multilingual stimuli; cross-lingual Procrustes alignment; culture-specific baselines.
- Assumptions/dependencies: Human baselines vary by culture; may require localized training/fine-tuning.
- Architecture-agnostic adapter placement automation (LLM tooling)
- What: Auto-detect peak-emergence layers per domain in any new architecture and deploy adapters accordingly.
- Tools/workflow: Profiling-as-a-service; metadata-driven adapter orchestration.
- Assumptions/dependencies: Consistency of transient emergence patterns across future architectures remains to be shown.
- Knowledge distillation of manifolds into compact models (edge AI)
- What: Distill mid-layer perceptual subspaces into small classifiers/regressors for on-device tasks (e.g., lightweight sentiment meters, color taggers).
- Tools/workflow: Manifold-preserving distillation losses; teacher–student training.
- Assumptions/dependencies: Distillation must preserve geometry; performance drops likely without domain adaptation.
- Bias and safety analytics through geometric inspection (safety research)
- What: Extend manifold analysis to detect unwanted couplings (e.g., affect with demographic terms), enabling mitigation strategies.
- Tools/workflow: Correlational and causal probes across layers; counterfactual interventions.
- Assumptions/dependencies: Beyond current domains; requires sensitive data safeguards and robust statistical methods.
Glossary
- Affective manifold: A low-dimensional geometric space capturing structured relations among emotions, often organized by psychological axes. "well-organized affective manifold aligned with the human valence--arousal structure"
- ANEW (Affective Norms for English Words): A standardized dataset providing human ratings of words along affective dimensions. "we use the ANEW benchmark database"
- Bootstrap confidence intervals: Nonparametric uncertainty estimates computed by resampling data with replacement. "we estimate bootstrap confidence intervals for both RSA and GPA scores"
- CIELAB: A perceptual color space designed so that Euclidean distances approximate human-perceived color differences. "color spaces like CIELAB"
- Circular manifolds: Ring-shaped geometric structures in representation space reflecting periodic domains. "organized along circular manifolds"
- Cosine dissimilarities: Pairwise distances defined as one minus cosine similarity, emphasizing angular differences. "we compute pairwise cosine dissimilarities:"
- Dissimilarity matrix: A symmetric matrix of pairwise distances or dissimilarities between stimuli or representations. "This gives a symmetric dissimilarity matrix"
- Embedding space: The vector space in which model representations (embeddings) reside. "geometric structure in embedding space"
- Geodesic distances: Shortest-path distances measured along a manifold rather than through ambient Euclidean space. "preserves geodesic distances on the underlying manifold"
- Generalized Procrustes Analysis (GPA): A method for aligning two point sets by optimal orthogonal transformation and measuring residual mismatch. "Generalized Procrustes Analysis (GPA): GPA measures geometric alignment"
- Isomap: A nonlinear manifold learning method that preserves geodesic distances during dimensionality reduction. "Isomap, a nonlinear dimensionality reduction technique that preserves geodesic distances on the underlying manifold"
- Last token hidden state activation: The internal activation vector for the final token at a given transformer layer. "last token hidden state activation at every transformer layer"
- Mechanistic interpretability: The study of how models internally represent and transform information across layers and components. "Mechanistic interpretability provides a framework"
- Multidimensional Scaling (MDS): A technique that embeds items into a low-dimensional space to preserve pairwise dissimilarities by minimizing stress. "Multidimensional Scaling (MDS): To obtain a low-dimensional geometric embedding"
- Nonlinear dimensionality reduction: Techniques that reduce dimensionality by modeling curved manifolds, not just linear subspaces. "a nonlinear dimensionality reduction technique"
- Orthogonal transformation: A rotation/reflection (length-preserving) mapping used to align two configurations in space. "by finding the optimal orthogonal transformation"
- Qualia map: A geometric arrangement of stimuli intended to reflect subjective perceptual qualities. "forming a qualia map for each layer"
- Representational Similarity Analysis (RSA): A framework that compares representational structures via correlations between dissimilarity matrices. "Representational Similarity Analysis (RSA): RSA measures the correlation"
- Residual streams: The pathways in transformer architectures that carry and accumulate information across layers via residual connections. "within the residual streams of multiple open-weight transformer architectures"
- Spearman rank correlation: A nonparametric correlation measuring monotonic association based on ranks. "We compute RSA as the Spearman rank correlation"
- Stress function: The objective minimized in MDS that quantifies mismatch between target dissimilarities and embedded distances. "by minimizing the following stress function:"
- Translation symmetries: Invariances under shifts that can induce structured geometric organization in learned representations. "translation symmetries in language co-occurrence statistics"
- Valence–arousal structure: A two-dimensional affective model positioning emotions by pleasantness (valence) and activation (arousal). "valence--arousal structure"
- VAD (Valence, Arousal, Dominance): A three-dimensional affective space extending valence–arousal with a dominance/control axis. "valence, arousal, and dominance (VAD) dimensions"
Collections
Sign up for free to add this paper to one or more collections.

