Context Structure Reshapes the Representational Geometry of Language Models
Abstract: LLMs have been shown to organize the representations of input sequences into straighter neural trajectories in their deep layers, which has been hypothesized to facilitate next-token prediction via linear extrapolation. LLMs can also adapt to diverse tasks and learn new structure in context, and recent work has shown that this in-context learning (ICL) can be reflected in representational changes. Here we bring these two lines of research together to explore whether representation straightening occurs \emph{within} a context during ICL. We measure representational straightening in Gemma 2 models across a diverse set of in-context tasks, and uncover a dichotomy in how LLMs' representations change in context. In continual prediction settings (e.g., natural language, grid world traversal tasks) we observe that increasing context increases the straightness of neural sequence trajectories, which is correlated with improvement in model prediction. Conversely, in structured prediction settings (e.g., few-shot tasks), straightening is inconsistent -- it is only present in phases of the task with explicit structure (e.g., repeating a template), but vanishes elsewhere. These results suggest that ICL is not a monolithic process. Instead, we propose that LLMs function like a Swiss Army knife: depending on task structure, the LLM dynamically selects between strategies, only some of which yield representational straightening.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Context Structure Reshapes the Representational Geometry of LLMs — A simple explanation
1. What’s this paper about?
This paper looks inside a LLM to see how its “thoughts” (its internal signals) change when you give it different kinds of context. The main idea: sometimes the model’s internal activity forms a smoother, straighter path as it reads a sequence of words, and that straightness seems to help it predict the next word. But the authors show this isn’t always true—what the model does inside depends on the kind of task it’s trying to do. They argue an LLM works like a Swiss Army knife: it picks different internal strategies depending on the situation.
2. What questions were the researchers asking?
They asked:
- Do LLMs make their internal paths straighter when they learn from the context you give them (known as “in‑context learning”)?
- Does this straightening happen across different types of tasks, or only in some?
- Is straightening linked to better predictions, and if so, when?
In simple terms: When you show an LLM more examples or a longer story, does it reshape its internal “path” to make next words easier to guess—and does that depend on what the task looks like?
3. How did they study it?
They opened up a big model (Gemma‑2‑27B, a standard pre‑trained LLM) and watched how its internal signals changed as it read different kinds of inputs. Think of the model’s internal activity as a path drawn through a very high‑dimensional space—like tracking a point moving through the air as each new word arrives.
They focused on two ingredients:
- Task types (the kinds of context the model sees):
- Natural stories where predicting the next word depends on long‑range context (LAMBADA).
- “Grid world” sequences: hidden maps turned into word paths, where the model must learn the map’s structure from the sequence.
- Few‑shot question‑answer prompts (like “Q: Country → A: Capital”) and riddles, where examples teach a rule or help solve a puzzle.
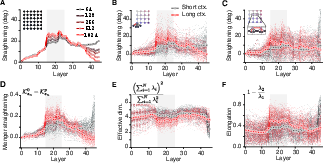
- Geometry measures (how the internal path looks):
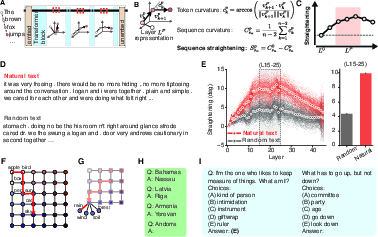
- Straightening: Does the path become more straight (like a line) as it goes through the model’s layers? Straighter paths make “keep going in the same direction” a good strategy—helpful for predicting the next token.
- Menger curvature: Another way to see how bendy the path is (lower curvature = straighter).
- Effective dimensionality: How many directions the path really uses; lower means it’s collapsed onto a simpler shape.
- Elongation: How stretched the path is along a main direction (more stretched = more line‑like).
They also tracked behavior: did the model actually predict better? For example, they compared its internal scores (called “logits,” basically how much it “likes” each next word) for correct next steps versus wrong ones.
4. What did they find?
The big picture: whether the path straightens depends on the task’s structure.
- In continual prediction tasks, the internal path gets straighter as the context grows—and predictions improve.
- Natural language (stories): In the middle layers of the model, the path becomes noticeably straighter for real text than for shuffled (nonsense) text. This suggests the model reshapes its representation to make the next word more predictable.
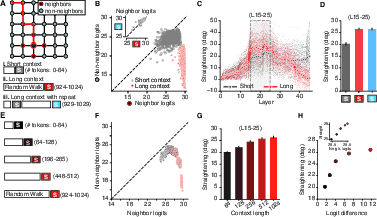
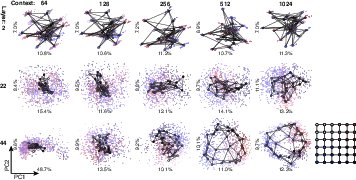
- Grid worlds (learning hidden maps from sequences):
- With longer context, the model becomes better at preferring valid next steps on the grid and worse at picking invalid ones.
- At the same time, the internal path for the test sequence straightens, uses fewer dimensions, and becomes more line‑like.
- This holds even when the exact test sequence appeared earlier (so it’s not just copying) and even when some transitions were never seen directly (the model infers them from the hidden structure). The same straightening appears, meaning the model learned the underlying map.
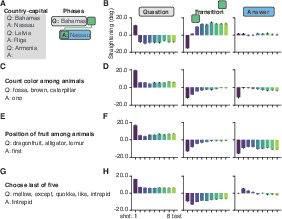
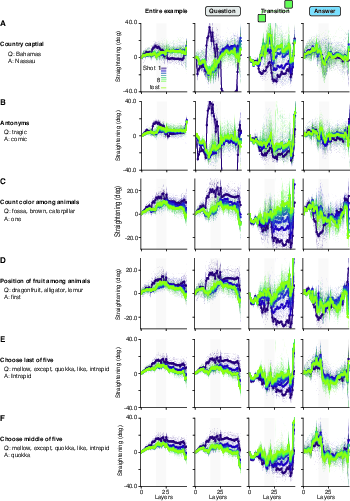
- In structured prediction tasks (few‑shot Q&A and riddles), the pattern is mixed—straightening is not a universal signal of learning:
- Few‑shot tasks (e.g., country→capital, counting, simple algorithms):
- The “template” parts (like the formatting tokens “A:” or the repeated structure) do get straighter with more examples—because they’re predictable and repetitive.
- But the actual answer segments (where the model applies the learned mapping to produce the correct output) do not show consistent straightening as shots increase.
- The question segments often show a quick change after the first example and then stop changing much.
- Riddles:
- The list of choices (a highly structured part) gets straighter with more examples—again, it’s a predictable template.
- The answer part actually gets less straight with more examples.
- The question text (natural language clues) shows little or no straightening effect.
What this means: Straightening is strong and tightly linked to better predictions when the task is like “continuing a sequence” (stories, map walks). In contrast, when the task is “apply this rule to new inputs” (few‑shot mappings, riddles), the model seems to use different internal tools that don’t necessarily make the path straighter during the actual reasoning/answering step.
5. Why is this important?
- It shows that in‑context learning doesn’t come from a single, always‑on mechanism. The model adapts its internal style to the task’s structure—like choosing the right tool from a Swiss Army knife.
- For tasks that are about ongoing prediction (like reading a story), making the internal path straighter seems to be how the model gets better at guessing the next word.
- For tasks that are about learning a rule and applying it (few‑shot prompts, riddles), the model’s “reasoning” may rely on different internal patterns that don’t show up as straightening.
Takeaways and potential impact
- For researchers and engineers:
- Don’t assume one geometric signature (like straightening) explains all in‑context learning. Use multiple measures and test across different task types.
- When probing or steering a model, consider the task’s structure. If it’s continual prediction, straightening might be a good health check. If it’s rule application, look for other signals.
- For improving models and prompts:
- Repetitive, predictable formatting helps the model form clean internal patterns—useful for stable prompting.
- But boosting reasoning in few‑shot tasks may require different strategies than those that help with next‑word prediction.
- For science and safety:
- This work cautions against one‑size‑fits‑all interpretations of how LLMs “think.” Better interpretability will likely need a toolbox of analyses tailored to different task structures.
In short: LLMs don’t learn from context in just one way. When the context is a flowing sequence, they tend to straighten their internal paths to predict what comes next. When the context teaches a rule to apply, they often switch to other internal tricks. Understanding which “tool” the model is using helps us interpret, evaluate, and improve them more effectively.
Knowledge Gaps
Below is a single, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions.
- Causality of straightening: Is representational straightening necessary or sufficient for improved prediction? Design causal interventions (e.g., targeted projections that increase/decrease curvature or elongation in specific layers/subspaces) and test their impact on logits and accuracy without leaving the natural data manifold.
- Model generality: Results are shown only for Gemma-2-27B (base). Replicate across families (e.g., Llama, Mistral, GPT-NeoX), scales, and training stages (pretrained vs instruction-tuned vs RLHF) to test whether the “Swiss Army knife” pattern and straightening–performance coupling are universal.
- Mechanistic attribution: Which modules (attention heads vs MLPs) and which specific heads drive straightening or the structured ICL strategy? Perform component-level ablations/patching and attention-pattern analyses to map circuits to geometric changes.
- Late-layer “unembedding” hypothesis: The claim that reduced straightening in final layers reflects unembedding is untested. Measure curvature directly in logit space (logit lens), vary/replace the unembedding matrix, or project out the unembedding subspace to test this explanation.
- Alternative geometry/topology: Only a narrow set of metrics (angle-based straightening, Menger curvature, participation ratio, elongation) were used; these were not applied to few-shot/riddle tasks. Evaluate additional and task-sensitive metrics (e.g., geodesic curvature, torsion, subspace rotations, Procrustes alignment, CCA/CKA drift, persistent homology) and apply them to the structured ICL settings.
- Per-instance predictivity in structured tasks: For few-shot/riddles, assess whether any geometric measure (beyond straightening) predicts per-example correctness, confidence, or calibration. Include incorrect trials rather than filtering to only correct generations to avoid selection bias.
- Prompt-structure confounds: Straightening increases in transition/template tokens, but its dependence on formatting is untested. Systematically vary delimiters (“Q:”, “A:”, newlines), template complexity, and noise/reordering to determine which structural features induce straightening.
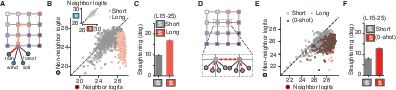
- Scope of grid-world generalization: The grid uses common English words (single tokens) and a fixed lattice. Remove lexical semantics (e.g., random strings/byte tokens), vary graph topology (directed edges, hubs, small-world, trees), degree, and size, and test multi-token and multilingual nodes to rule out surface-statistics confounds.
- Latent grid emissions: Only uniform 4-child emission noise was studied. Vary emission distributions, overlap between child vocabularies across latent nodes, and noise rates to characterize when latent-structure straightening/learning breaks.
- Context length boundaries: Behavior and geometry were probed up to 1024/2048 tokens. Test longer contexts, memory interference, and recency effects, and vary the relative position of the test window to map straightening dynamics vs. distance.
- Baseline choice for straightening: Straightening is computed relative to “L0.” Clarify L0 (input embeddings vs first residual state) and test alternative baselines (embeddings, early layers) to ensure the effect is not an artifact of baseline selection or layernorm scaling.
- Statistical rigor: Many t-tests across layers/conditions lack multiple-comparison control and independence checks (tokens within sequences are not independent). Reanalyze with hierarchical/mixed-effects models, nonparametric tests, and FDR/Bonferroni corrections; provide CIs and effect sizes throughout.
- Token-type heterogeneity: Curvature is averaged across tokens. Disaggregate by token class (content vs function, punctuation, delimiters) to identify where straightening originates and whether it differs by lexical/positional properties.
- Temporal granularity within layers: Geometry is measured at layer outputs only. Track sub-layer updates (post-attention vs post-MLP) and KV-cache dynamics to localize when within a layer/block straightening occurs.
- Mode-switch detection: The “Swiss Army knife” hypothesis is descriptive. Develop quantitative detectors for mechanism switching (e.g., change-point detection in geometry, clustering of layerwise dynamics, mixture-of-mechanisms models) and identify the contextual cues that trigger each mode.
- Few-shot rule representation: If answer-phase straightening does not track learning, what representation carries the learned mapping? Probe for linear task vectors, input–output alignment matrices, or low-rank adapters emergent in-context; test linear-readout predictability from Q to A subspaces.
- Robustness to adversarial/misaligned context: Test how contradictory, misleading, or noisy shots affect straightening and performance across phases; identify failure modes where straightening correlates with degraded accuracy.
- Calibration and entropy: The grid-world link between straightening and neighbor logits suggests a confidence relation. Measure relationships to entropy, calibration error, and margin, and test whether straightening predicts over/under-confidence.
- Reproducibility and resources: The paper lacks details on code/data release, random seeds, and exact preprocessing/tokenization constraints (e.g., single-token guarantees). Provide artifacts to enable replication and to test sensitivity to these preprocessing choices.
- Beyond text: Straightening analogies are drawn from vision. Evaluate whether analogous context-structure effects arise in multimodal or code/math settings, and whether geometry differs for chain-of-thought vs direct-answer prompting.
- Extend geometry to riddles/few-shot: Participation ratio, elongation, and Menger curvature were validated in grid tasks only. Apply them (and additional subspace-drift metrics) to riddles and few-shot tasks to test whether other geometric signatures, not plain straightening, track structured ICL.
- Saturation and nonlinearity: The straightening–performance link in grid worlds is nonlinear. Fit mechanistic or phenomenological models (e.g., saturating or threshold functions) and identify regimes where additional context no longer increases straightening or accuracy.
Practical Applications
Overview
Below are actionable, real-world applications that follow from the paper’s findings and methods on how context structure reshapes the representational geometry of LLMs. They are grouped by deployment timeline and, where relevant, linked to sectors and potential tools/workflows. Each item notes key assumptions or dependencies that may affect feasibility.
Immediate Applications
These can be deployed now using open-weight models and standard engineering practices.
- ICL Geometry Profiler for model debugging and evaluation (software, AI research)
- Use case: Compute and track straightening, Menger curvature, effective dimensionality, and elongation across layers and contexts to diagnose LLM behavior in continual prediction settings (e.g., long narratives, streaming data).
- Potential tools/workflows: “Geometry Dashboard” plugins for inference servers; per-layer activation sampling; CI pipelines that flag geometry regressions across model versions.
- Assumptions/Dependencies: Requires access to residual stream activations (open weights or instrumented APIs) and compute for PCA/curvature; current correlations strongest in continual prediction tasks; study done on Gemma-2-27B base (generalization to other families and RLHF-finetuned models may vary).
- Context-length tuning and prompt hygiene for continual prediction (software, education, content generation)
- Use case: Adjust context length until middle-layer straightening saturates to maximize predictive performance; craft prompts that maintain coherent narrative flow to induce straightening.
- Potential tools/workflows: “Context Budgeter” that stops adding examples once straightening plateaus; narrative scaffolders for RAG pipelines to improve sequence predictability.
- Assumptions/Dependencies: Straightening correlates with performance in narrative/grid tasks; diminishing returns beyond certain lengths; may not help structured Q→A tasks.
- Template-aware prompt design for few-shot tasks (software, education)
- Use case: Leverage the finding that “transition” tokens (e.g., newline + “A:”) reliably straighten, while answer-phase geometry does not; design prompts emphasizing clean, consistent formatting and external tool calls for algorithmic mapping.
- Potential tools/workflows: Prompt linting/checkers that enforce rigid Q/A templates; auto-insert transitions; decision rules that route answer-phase to calculators, retrieval, or symbolic modules.
- Assumptions/Dependencies: Straightening is inconsistent in few-shot answer phases; formatting helps structural predictability but may not improve the computational core of mapping tasks.
- Layer targeting for adapters and fine-tuning (software, AI research)
- Use case: Place adapters/LoRA modules in middle layers (L15–25 equivalents) where straightening peaks for continual prediction tasks; use geometry metrics to select layers to tune.
- Potential tools/workflows: “Layer Selection Assistant” that scores layers by straightening gains; adapter placement heuristics guided by geometry.
- Assumptions/Dependencies: Observed geometry peaks in middle layers in Gemma-2-27B base; topology may shift in other architectures/scales.
- Generalization vs. copying checks in sequence tasks (software, robotics)
- Use case: Use neighbor vs. non-neighbor logit separation and geometry changes to confirm whether a model has learned latent structure (e.g., graphs, navigation traces) rather than memorizing token pairs.
- Potential tools/workflows: “Structure Inference Audit” that probes zero-shot transitions and logs geometry-based signatures; use in agent navigation scripts or sequence planning evaluation.
- Assumptions/Dependencies: Valid in grid-world sequences and similar structured streams; relies on being able to test novel transitions and measure logits/activations.
- Model update monitoring and QA compliance reporting (policy, software)
- Use case: Track representational geometry as a regression guardrail when rolling out new weights; attach geometry summaries as interpretability documentation.
- Potential tools/workflows: Release checklists with geometry diffs; “Interpretability Cards” that include straightening profiles across common tasks.
- Assumptions/Dependencies: Geometry changes can signal behavioral shifts but are not causal; requires standardization across models to be meaningful for auditors.
- RAG pipeline optimization via narrative stitching (software, enterprise content ops)
- Use case: Reorder and stitch retrieved passages into coherent narratives to amplify continual prediction straightening and improve next-token predictability.
- Potential tools/workflows: “Narrative Stitcher” that sequences snippets for smoother context trajectories; automatic retriever re-ranking by coherence.
- Assumptions/Dependencies: Benefits hinge on narrative predictability; may not help tasks dominated by discrete mappings or ambiguous QA.
- Prompting guidance for end users (daily life, education)
- Use case: Simple heuristics: use coherent story-like context for predictive tasks; use strict Q/A formats and tool invocation for structured problems (math, sorting, counting).
- Potential tools/workflows: Interactive prompt coaches in IDEs or chat UIs explaining when to add examples vs. when to call tools.
- Assumptions/Dependencies: Heuristics reflect geometry findings; effectiveness depends on problem type and model family.
Long-Term Applications
These require further research, scaling, or productization to make robust.
- Geometry-aware training objectives and curricula (software, AI research)
- Use case: Incorporate curvature/elongation penalties or targets to shape continual prediction representations; add synthetic grid-world curricula to pretraining for latent structure inference.
- Potential tools/workflows: “Curvature Regularizers” in training loops; curriculum schedulers mixing narrative corpora with structured random walks.
- Assumptions/Dependencies: Current results are correlational; needs causal validation to ensure benefits without harming generalization.
- Mechanism routers: Swiss Army LLM orchestration (software, robotics, healthcare, finance)
- Use case: Detect task structure via geometry and logits, then route to best mechanism—narrative generation, retrieval, calculators, symbolic planners, or code tools.
- Potential tools/workflows: “Strategy Router” that reads mid-layer geometry signatures and triggers specialized modules; multi-agent orchestration with geometry-based gating.
- Assumptions/Dependencies: Requires reliable, real-time access to geometry signals and validated detectors; potential latency/compute overhead.
- Real-time safety and misuse detection via geometry signatures (policy, trust & safety)
- Use case: Monitor sudden geometry shifts (e.g., loss of straightening or dimensionality spikes) as early-warning signals of adversarial context, jailbreak attempts, or persona flips.
- Potential tools/workflows: “Geometry Sentinel” monitoring middle layers during inference; risk scoring blended with traditional red-teaming.
- Assumptions/Dependencies: Must establish robust mappings between geometry changes and harmful behaviors; false positives/negatives need careful management.
- Representation-level interventions (software, AI research)
- Use case: Causally edit or nudge geometry (curvature, effective dimensionality) to improve specific behaviors while preserving manifold fidelity.
- Potential tools/workflows: Targeted adapters that locally linearize trajectories; topology-preserving editing techniques.
- Assumptions/Dependencies: Hard open problem; interventions risk off-manifold drift and unintended behavior changes.
- Efficiency gains via mid-layer linear extrapolators (software, energy)
- Use case: Exploit straightened mid-layer trajectories for faster predictive modules in streaming tasks, reducing compute without full forward passes.
- Potential tools/workflows: “Linear Head” attached to middle layers to pre-score candidates; dynamic early-exit conditioned on geometry.
- Assumptions/Dependencies: Needs demonstration that extrapolators maintain accuracy; benefits vary by architecture and task; careful engineering to avoid degeneration.
- Domain-specific geometry shaping (healthcare, finance, education)
- Use case: Tailor pretraining/post-training to the domain’s context format (clinical notes, market streams, student dialogues) to improve continual prediction behaviors.
- Potential tools/workflows: EHR-specific narrative curricula; market-report sequence shaping; tutoring dialog scaffolds optimized for straightening.
- Assumptions/Dependencies: Domain data access and privacy; generalization from Gemma-2 results to domain models; regulatory constraints.
- Standards and audits for interpretability reporting (policy, industry consortia)
- Use case: Develop norms that include geometry profiles alongside performance metrics; require geometry-based change logs for major releases.
- Potential tools/workflows: “Geometry Benchmarks” in industry-wide suites; certification pathways that test across narrative and structured tasks.
- Assumptions/Dependencies: Community consensus on metrics and protocols; recognition that geometry is task-dependent and non-universal.
- Cross-model comparability and model selection using geometry (software, procurement)
- Use case: Use geometry signatures to choose models for streaming/narrative tasks vs. structured mapping tasks, improving fit-for-purpose deployment.
- Potential tools/workflows: “Geometry Scorecards” for vendor models; procurement checklists aligning task type with geometry strengths.
- Assumptions/Dependencies: Requires standardized measurement access across vendors; ongoing validation that geometry correlates with task-specific performance.
- Hybrid neuro-symbolic systems guided by geometry (software, robotics)
- Use case: Use geometry to detect when to escalate from learned narrative prediction to symbolic planning (e.g., pathfinding, algorithmic transformations).
- Potential tools/workflows: Geometry-triggered switch to graph planners or program synthesis modules; agent stacks that blend LLM and symbolic cores.
- Assumptions/Dependencies: Stable detection and low-latency routing; integration complexity; application-specific tuning.
Notes on General Assumptions and Dependencies
- Findings are strongest in Gemma-2-27B base and continual prediction settings; structured few-shot tasks show dissociation (transition-phase straightening vs. answer-phase).
- Straightening and related metrics are correlational proxies, not proven causal drivers; safe deployment requires validation per task/model.
- Measuring geometry needs access to internal activations; closed APIs may restrict feasibility.
- RLHF and post-training can alter representational geometry; results may shift across training regimes and scales.
Glossary
- Anisotropy: Directional imbalance in how variance is distributed in a representation or trajectory. "We further characterize the anisotropy of the trajectory using the Elongation metric."
- Autoregressive architectures: Models that generate each token conditioned on previously generated tokens. "These results replicate and extend prior findings, which found similar phenomena across diverse autoregressive architectures and throughout training"
- Circumcircle: The unique circle passing through three points; its radius is used to define Menger curvature. "The local Menger curvature κp_k is the reciprocal of the radius of the circumcircle passing through these three points:"
- Continual prediction: A task format where the model makes ongoing next-token predictions by integrating long context. "The tasks examined so far (natural language and grid worlds) have a continual prediction format: the model predicts the next token by integrating context over many previous observation."
- Effective dimensionality: A continuous estimate of how many principal components are needed to capture trajectory variance (via participation ratio). "The effective dimensionality is given by:"
- Elongation: A measure of how strongly a trajectory is stretched along its first principal component. "We further characterize the anisotropy of the trajectory using the Elongation metric."
- Few-shot learning: Inferring an input–output mapping from a small number of examples provided in the prompt. "We next focus on emergent in-context capability of the model in structured prediction tasks and study few-shot learning, where the model must induce an algorithmic rule or manipulate semantic knowledge from discrete examples to solve a task"
- In-Context Learning (ICL): Adapting behavior and representations based solely on information contained in the current prompt. "To investigate the diversity of representational mechanisms in In-Context Learning (ICL), we consider three distinct classes of tasks."
- Latent graph structure: Hidden relational topology that must be inferred from observed sequences. "To quantify the model's understanding of the latent graph structure, we evaluate the logits assigned to valid transitions."
- Logits: Pre-softmax scores that indicate model preference for next tokens. "we evaluate the logits assigned to valid transitions."
- Mechanistic interpretability: Explaining model behaviors via identifiable circuits and representational mechanisms. "A central challenge in mechanistic interpretability is thus understanding the relationship between the structure of context and how LLMs reshape their internal representations in response to adapt their behavior"
- Menger curvature: A geometric curvature defined from three consecutive points via the circumcircle radius. "To capture a complementary geometric measure of the trajectory, we compute the Menger curvature"
- Menger straightening: Reduction in Menger curvature across layers, indicating straighter neural trajectories. "We computed the normalized Menger straightening (where $0$=random, $2$=collinear)"
- Non-periodic lattice: A grid arrangement without wrap-around edges (no periodic boundary conditions). "arranged on a non-periodic lattice."
- Participation Ratio: A metric for effective dimensionality based on the eigenvalue spectrum of the covariance. "To quantify the volume of the representation space occupied by the trajectory, we used the Participation Ratio."
- Principal Component Analysis (PCA): A technique that decomposes variance into orthogonal components (eigenvectors/eigenvalues). "We perform Principal Component Analysis (PCA) on to obtain the eigenvalues"
- Random walk: A sequence generated by stochastic transitions over a graph. "Contextual sequences consist of random walks of variable length generated over this graph"
- Reinforcement learning from human feedback (RLHF): Post-training method that aligns model behavior to human preferences via rewards. "reinforcement learning from human feedback (RLHF) and other types of post-training"
- Residual stream: The vector space in a transformer layer where token activations are accumulated and transformed. "Let denote the activations in the residual stream at layer for a sequence of tokens."
- Representational geometry: The geometric structure (e.g., trajectories, manifolds) of internal activations. "exploring how different types of data structure in context change the models' representational geometry."
- Representational straightening: The process by which sequence trajectories become more linear across layers. "We measure representational straightening in Gemma 2 models across a diverse set of in-context tasks"
- Structured prediction: Tasks requiring discrete input–output mappings (often with fixed templates) rather than continuous narrative flow. "Conversely, in structured prediction settings (e.g., few-shot tasks), straightening is inconsistent"
- Transition vector: The difference between consecutive token activations along a trajectory. "We define the transition vector at step as ."
- Unembedding phase: The final stage where high-dimensional representations are projected back to vocabulary logits. "We suspect that this reduction reflects the unembedding phase, where the high-dimensional representation must collapse back into the geometry of the vocabulary space"
- Zero-shot (0-shot) context: Testing behavior on patterns not observed in the provided context. "0-shot context (Hierarchical only): Transitions along specific edges between children of neighboring latent nodes were excluded from the context but presented at test time."
Collections
Sign up for free to add this paper to one or more collections.