Words That Make Language Models Perceive
Abstract: LLMs trained purely on text ostensibly lack any direct perceptual experience, yet their internal representations are implicitly shaped by multimodal regularities encoded in language. We test the hypothesis that explicit sensory prompting can surface this latent structure, bringing a text-only LLM into closer representational alignment with specialist vision and audio encoders. When a sensory prompt tells the model to 'see' or 'hear', it cues the model to resolve its next-token predictions as if they were conditioned on latent visual or auditory evidence that is never actually supplied. Our findings reveal that lightweight prompt engineering can reliably activate modality-appropriate representations in purely text-trained LLMs.
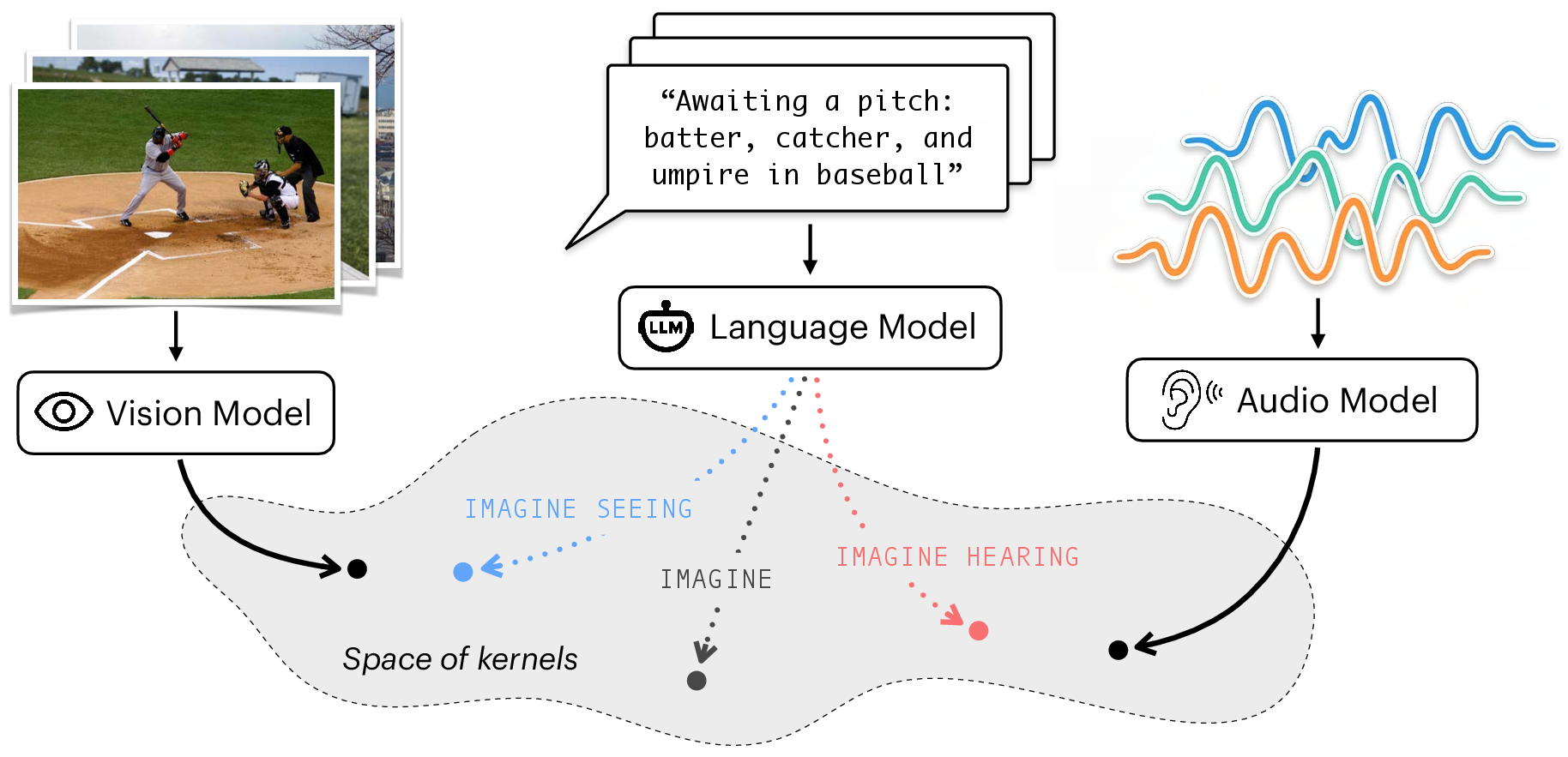



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but surprising question: can a text-only AI “pretend to see or hear” just by being told to, and then think more like a vision or audio system? The authors show that adding tiny cues like the word “see” or “hear” to a LLM’s prompt can push its internal thinking to line up with expert models that were trained only on images or only on sounds.
What questions did the researchers ask?
They focused on four easy-to-understand questions:
- If you tell a LLM to “see” or “hear” before it writes, will its internal thoughts look more like those of a vision or an audio model?
- Does letting the model write longer answers make that effect stronger?
- Do bigger LLMs show clearer “visual” vs “auditory” modes when prompted?
- Do the specific words it uses (like describing colors, shapes, or noises) actually matter, or is the effect just word fluff?
How did they test their idea?
Here’s the basic approach, with simple analogies for the technical parts:
- Two kinds of expert models: One vision model (trained only on images) and one audio model (trained only on sounds). Think of them as specialists: the “eye” and the “ear.”
- One text-only LLM (no images or audio in training): This is the “reader” that only knows words.
- Paired data: They used sets of image–caption pairs and sound–caption pairs. Each caption describes either an image or a sound.
- Prompts with tiny cues: Before the LLM continued each caption, they added short instructions like “Imagine you can SEE this” or “Imagine you can HEAR this,” then let it write a continuation (a few sentences).
- Measuring “alignment” with an analogy:
- Imagine each model arranges all the captions as points on a big table. Captions that feel similar (e.g., two food photos) sit closer together; very different ones sit far apart. This arrangement is the model’s “representation.”
- If two models place the same captions near the same neighbors, their “maps” are aligned.
- The authors measured this by comparing each caption’s “top-k friends list” (nearest neighbors). The more overlap in friends between two models, the higher the alignment.
- “Generative representation” explained: Instead of taking a single snapshot of the LLM’s internal state from the prompt alone, they also watched how its internal state evolves as it writes each next word. Think of it as “measuring the model’s thoughts while it thinks out loud.” Averaging those internal states across the generated text gave a richer “generative” representation.
What did they find, and why does it matter?
Here are the main takeaways:
- A single sensory word can steer the model’s thinking:
- Adding a visual cue like “SEE” made the LLM’s map look more like the vision model’s map.
- Adding an auditory cue like “HEAR” made it look more like the audio model’s map.
- This steering worked during generation (as it wrote), not from a single one-shot embedding.
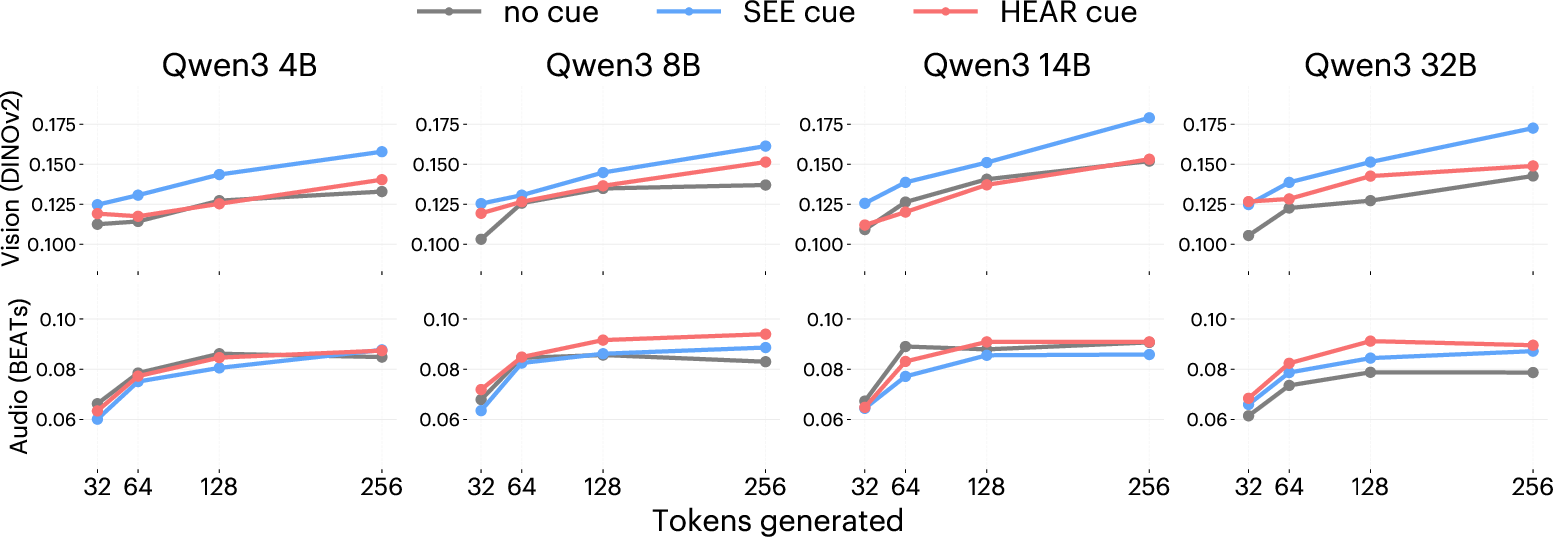
- Letting the model write more helps:
- Longer continuations gave the model more chances to add relevant sensory details (colors, shapes, textures for vision; pitches, rhythms, sources for audio).
- Alignment with the specialist models increased with length—up to a point. If it wrote too long, it sometimes drifted off-topic and alignment dropped.
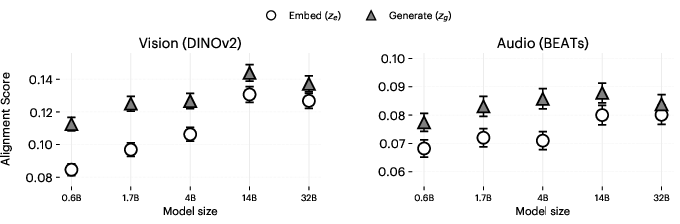
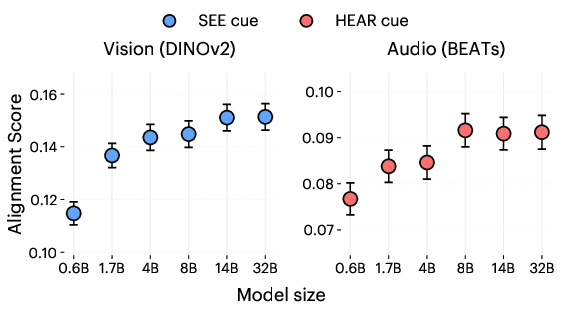
- Bigger models are better at “switching senses”:
- Larger LLMs showed stronger alignment and clearer separation between “visual mode” and “auditory mode” when prompted.
- The right sensory words matter:
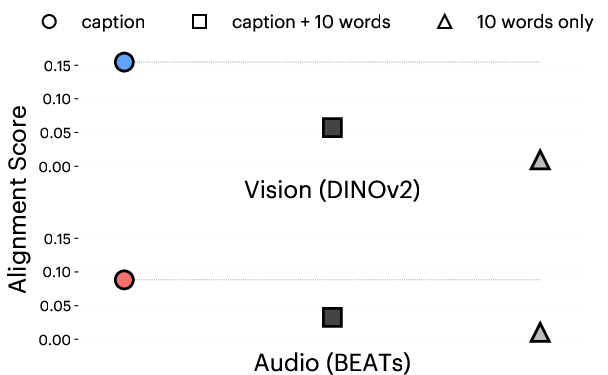
- When the authors edited out sensory words (like “bright red,” “echoing,” “crunchy”), alignment dropped. So the effect isn’t magic—it depends on using scene-appropriate sensory details.
- Stuffing captions with random “visual-sounding” words actually hurt alignment. So it’s not just buzzwords; the details need to fit the specific scene or sound.
- A practical demo: vision questions without the image:
- In a “VQA without V” setup (answering yes/no image questions using only the image’s caption), a simple “visual framing” instruction made the LLM a bit more accurate overall. This suggests sensory prompting can help the model reason about pictures using words alone.
Why it matters: These results suggest that text-only models quietly learn a lot about the sensory world from language alone. With the right prompt, you can bring that hidden knowledge to the surface—no extra training needed.
What could this change or lead to?
- Easier multimodal tools without retraining: If a text-only model can act more “visual” or “auditory” on command, we can build cross-modal features (like better search or retrieval across text, images, and audio) using simple prompts.
- Better control at inference time: Prompts don’t just ask the model to answer a question—they can shape how it thinks, nudging it to imagine seeing or hearing and produce more grounded descriptions.
- New ways to evaluate and distill models: You could use these “sensory-aware” text embeddings to compare with or teach smaller specialist models.
- Limits and cautions:
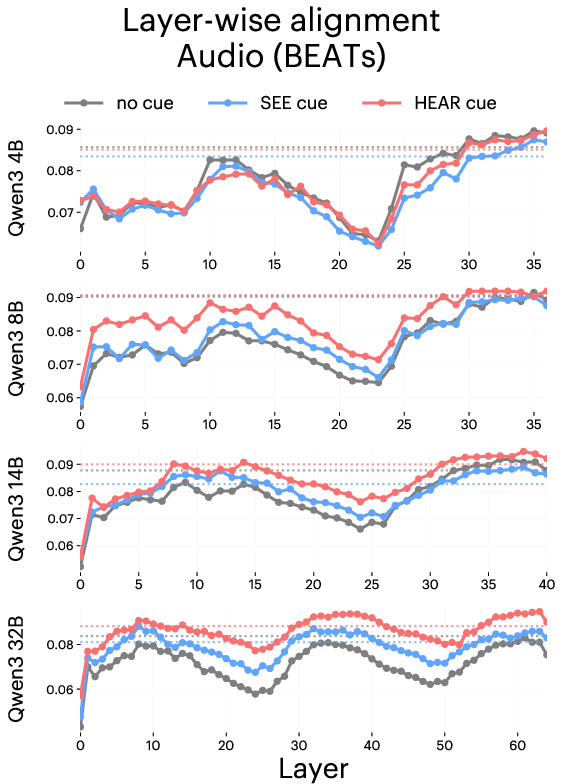
- Audio alignment was generally harder than vision, likely because many sound features (like pitch or timbre) are tough to express in words.
- If the model makes up sensory details not supported by the caption (hallucinations), that can mislead. The improvements rely on correct, scene-appropriate sensory language.
- Very long generations can drift off-topic, reducing alignment.
In short, the paper shows that words like “see” and “hear” can flip a LLM into a mode where it organizes information more like an image or audio expert would. That’s a powerful, low-cost way to make text-only AIs feel more grounded in the sensory world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future work.
- Causal grounding vs. correlational alignment: Does increased mutual‑kNN alignment actually reflect improved perceptual grounding (i.e., correct, sample‑specific visual/audio inference), or is it driven by textual co‑occurrence and category semantics? Design evaluations that measure correctness of generated sensory details against paired images/audio.
- Metric validity and sensitivity: The study relies on mutual‑kNN alignment with cosine kernels; it remains unclear how results depend on k, kernel choice, distance metric, dataset size, and embedding normalization. Systematically vary these to test robustness and establish best practices.
- Decoding policy effects: The generative representation depends on how outputs are produced, but decoding parameters (e.g., temperature, top‑p/k, greedy vs. sampling) are unspecified. Quantify how decoding choices impact alignment, stability, and reproducibility.
- Representation pooling choices: Generative embeddings average hidden states over all layers and tokens, justified heuristically by residual connections. Compare alternatives (e.g., last token, attention‑weighted pooling, learned projections, per‑layer selection) to identify more informative summaries.
- Layer‑wise mechanisms: What layers and attention heads mediate modality shifts under sensory prompting? Conduct mechanistic analyses (e.g., probing, causal ablations, circuit tracing) to localize and explain the inferred sensory framing.
- Hallucination quantification: While random “visual word” injections reduce alignment, the paper does not quantify how often sensory prompts induce incorrect sensory details. Develop automatic metrics (e.g., attribute verification against ground truth) to measure and mitigate hallucination.
- Generalization across LLM families: Results primarily use Qwen3. Test portability across diverse architectures and instruction‑tuning regimes (e.g., Llama, Mistral, GPT, Phi) and identify model characteristics that predict stronger sensory steerability.
- Encoder diversity: Vision/audio encoders are limited to DINOv2 and BEATs. Evaluate supervised vs. self‑supervised encoders (e.g., CLIP, EAT, AudioMAE, HTSAT, CNN‑based audio models) to understand which sensory features align best with language under prompting.
- Dataset coverage and scale: Image/audio‑caption datasets are small (≈1k pairs) and narrow in domain. Replicate with larger, more diverse, and controlled datasets (cross‑lingual, fine‑grained attributes, synthetic counterfactuals) to test robustness and reduce sampling bias.
- Cross‑modal confounds: Visual alignment gains may arise from shared semantic categories rather than true scene features. Use category‑controlled and attribute‑matched datasets to disentangle category semantics from low‑/mid‑level sensory structure.
- Prompt optimization at scale: The paper hints that prompt phrasing matters but does not explore systematic optimization due to evaluation cost. Develop efficient proxy objectives or bandit/search strategies to optimize sensory prompts without full kernel recomputation.
- Multi‑cue and mixed‑modality prompting: It remains unknown how combined or conflicting cues (“see and hear”, time‑varying cues) blend or compete in representation. Study compositionality, interference, and controllability in multi‑cue settings.
- Length vs. drift trade‑off: Alignment improves with longer generations but can decline due to semantic drift at 512 tokens. Characterize the length‑alignment curve, detect drift, and propose stopping/regularization strategies that maximize alignment while maintaining faithfulness.
- Default visual framing: Smaller models appear to default to visual framing under no cue. Test whether this bias holds beyond Qwen3, and investigate training or prompting methods that correct it in auditory or other sensory contexts.
- Downstream task transfer: VQA‑without‑V gains are modest and limited to certain categories. Evaluate broader downstream tasks (cross‑modal retrieval, audio event classification from captions, fine‑grained attribute QA, temporal auditory reasoning) to establish practical benefits.
- Independence of captioner and QA model: The VQA experiment uses captions from a Qwen‑family VL model and QA by Qwen3‑14B, risking family‑specific bias. Validate with human captions and independent captioners/QA models to avoid intra‑family artifacts.
- Cross‑lingual and stylistic robustness: The approach is only tested in English and Wikipedia‑style captions. Examine multilingual settings, varied writing styles, noisy transcriptions, and domain‑specific jargon to assess generality.
- Additional modalities: The study focuses on vision and audio. Extend to other senses (e.g., tactile, proprioception, olfaction) using appropriate encoders to test whether sensory prompting generalizes beyond sight and sound.
- Safety and reliability: Sensory prompting can induce plausible but incorrect perceptual details. Develop guardrails (calibration, uncertainty estimation, attribution to evidence) and evaluate failure modes in high‑stakes settings.
- Compute and efficiency: Generative representations require substantial token generation and kernel computations; the paper does not quantify cost. Profile runtime/energy and explore efficient approximations (e.g., subsetting layers, low‑rank kernels, streaming embeddings).
- Theoretical grounding: The “latent causes” hypothesis is posited but not formally tested. Design causal, counterfactual, and Bayesian inference experiments to validate whether prompts shift priors over sensory evidence rather than merely surface lexical patterns.
- Temporal audio structure: Audio encoders often capture low‑level temporal features (e.g., rhythm, timbre). Develop prompting schemes that elicit temporal reasoning (e.g., “hear a sequence…”) and measure whether alignment improves for time‑dependent audio phenomena.
- Evaluation under adversarial and stress tests: Probe robustness with adversarial captions, contradictory cues, incomplete or misleading descriptions, and out‑of‑distribution inputs to understand limits of steerability.
- Knowledge distillation potential: The paper suggests using LLM embeddings to distill into smaller sensory encoders, but does not attempt it. Test whether sensory‑prompted LLM kernels can supervise training of compact vision/audio models and measure downstream performance.
Practical Applications
Immediate Applications
Below are deployable uses you can build today by adopting the paper’s findings (prompting text-only LLMs with sensory cues and using generative representations) and the released code.
- Visualized search and cross-modal retrieval without multimodal training
- Sectors: software, media/creative, e-commerce, enterprise knowledge management
- What: Use a text-only LLM’s generative embeddings (with
SEE/HEARsensory prefix) to index captions, product descriptions, transcripts, or alt-text so that text-only queries better align with image/audio encoders’ neighborhoods. Enables “CLIP-like” retrieval behavior using only text at inference time. - Workflow: For each item, generate 128–256 tokens under a sensory cue and average hidden states to form embeddings; build a vector index; at query time, use the same cue to embed the query and retrieve.
- Tools/products: “Sensory-embeddings” vector service; retrieval plugin for vector DBs; content management system add-on for media libraries.
- Assumptions/dependencies: Needs quality captions/transcripts; 128–256 token generation per item (compute cost); alignment depends on target encoder (e.g., DINOv2, BEATs); larger models work better; audio alignment is weaker than vision in current results.
- Caption enhancement for richer, scene-appropriate descriptors
- Sectors: media/creative, accessibility, e-commerce
- What: Prompt with
SEEto expand existing captions/descriptions into visually grounded text that improves downstream search, clustering, and accessibility. - Workflow: Caption →
SEE-prompted continuation → use enriched text for alt-text, product pages, or asset tagging. - Tools/products: Caption “grounding” API; authoring assistant that suggests visual attributes.
- Assumptions/dependencies: Must avoid generic “visual word stuffing” (paper shows it reduces alignment); use guardrails and scene-appropriateness checks.
- Privacy-preserving proxy for visual Q&A (“VQA without V”)
- Sectors: compliance/regulated enterprise, accessibility, education, e-commerce
- What: When images can’t be processed for privacy or policy reasons, answer visual questions from captions only. The paper shows
SEEframing improves accuracy on text-projected VQA. - Workflow: Generate or ingest captions → ask LLM with
SEEframing to answer yes/no or short-form questions. - Tools/products: Helpdesk bots for image-based products using descriptions only; classroom assistants explaining images via text.
- Assumptions/dependencies: Requires reliable captions; does not replace true pixel-grounded VQA in safety-critical contexts.
- Sensory-aware assistance in writing and marketing
- Sectors: media/creative, marketing, education
- What: Use
SEEorHEARcues to elicit copy with concrete sensory detail (e.g., product pages, story outlines, ad copy) that aligns with how humans perceive scenes or sounds. - Workflow: Add explicit sensory framing to prompts for drafts; enforce “scene-appropriate” constraints.
- Tools/products: Prompt libraries and templates for “visual” and “auditory” copy; editorial copilots.
- Assumptions/dependencies: Instruction-style prompts outperform non-instructional variants; monitor hallucinations and off-topic drift for long outputs.
- Better clustering and deduplication of media assets via captions
- Sectors: DAM (digital asset management), media/creative, enterprise knowledge
- What: Cluster and deduplicate images/audio through text-only LLM embeddings that are steered to visual/auditory geometry, improving organization without handling raw media.
- Workflow: Generate
SEE/HEARgenerative embeddings for asset captions → cluster/index → deduplicate or auto-folder. - Tools/products: DAM plug-ins, asset miners, corpus cleaning utilities.
- Assumptions/dependencies: Needs consistent captioning quality; compute for autoregressive embedding.
- Lightweight multimodal evaluation probes for LLMs
- Sectors: AI research/ML ops, QA for foundation-model deployments
- What: Use mutual-kNN alignment versus reference encoders (e.g., DINOv2, BEATs) as an acceptance test that a model’s “visual/auditory” framing is elicitable.
- Workflow: Build small paired datasets; compute generative kernels with and without sensory prompts; monitor alignment shifts.
- Tools/products: “Alignment meter” CI checks; model cards with recommended sensory prompts and observed alignment scores.
- Assumptions/dependencies: Requires paired datasets; evaluation is computationally heavier than single-pass embedding.
- Prompt-time control in existing LLM products
- Sectors: software, productivity, customer support
- What: Insert sensory cues when tasks benefit from perceptual framing (e.g., image-like reasoning from descriptions, sound-like reasoning from transcripts).
- Workflow: Router decides when to prepend
SEE/HEAR; generate 128–256 tokens for embedding or reasoning; cap at lengths that avoid semantic drift. - Tools/products: Inference-time “sensory router”; chain-of-thought style prompt augmenters.
- Assumptions/dependencies: Gains increase with generation length up to a point; too long can drift; larger models show stronger separation.
- Dataset curation and synthetic supervision
- Sectors: ML data engineering, vision/audio model development
- What: Use
SEE/HEARprompting to enrich sparse captions with modality-appropriate attributes that help curate or stratify datasets (e.g., by scene, object, or event type). - Workflow: Caption expansion → cluster by enriched descriptors → sample for labeling/fine-tuning.
- Tools/products: Data curation pipelines; stratified sampling tools.
- Assumptions/dependencies: Ensure edits remain scene-appropriate; add QA to mitigate hallucinations.
- Accessibility upgrades: more useful alt-text and Q&A from text
- Sectors: accessibility/DEI, education, public sector
- What: Generate detailed, visually grounded alt-text or answer questions about images described in text (e.g., museum guides, public websites).
- Workflow: Ingest descriptions →
SEEprompting → alt-text/Q&A generation. - Tools/products: CMS plugins for accessible content; conversational museum/galley guides.
- Assumptions/dependencies: Quality of initial descriptions determines ceiling; include human review for public deployments.
- Policy and privacy operations: data minimization with text proxies
- Sectors: policy/compliance, legal, healthcare administration
- What: Substitute media with text proxies when policies prohibit processing raw images/audio; maintain useful retrieval/reasoning via sensory embeddings.
- Workflow: Replace or redact media → retain captions/transcripts → apply sensory prompting for retrieval or triage.
- Tools/products: Privacy-by-design knowledge bases; PHI-reduced triage tools.
- Assumptions/dependencies: Not a clinical or legal decision tool; maintain clear disclosures that system does not “see/hear” the original media.
- Developer tooling: sensory-embedding SDKs
- Sectors: software/ML infra
- What: Provide simple SDKs to compute
z_ggenerative embeddings with sensory cues, cache them, and integrate with vector stores and RAG. - Workflow: Batch generation with streaming/caching; version prompts/lengths; store embeddings alongside standard ones.
- Tools/products: Open-source libraries based on the paper’s code; vector database integrations.
- Assumptions/dependencies: Token cost and latency; caching and batch pipelines reduce overhead.
Long-Term Applications
These opportunities are promising but need further research, scaling, or engineering before broad deployment.
- Training-free cross-modal retrieval at web scale
- Sectors: search, media platforms, e-commerce
- What: Replace or complement CLIP-style infrastructure with text-only LLMs using sensory generative embeddings for cross-modal search over billions of items.
- Why long-term: Requires optimized, low-latency embedding generation, robust prompt tuning, drift management, and strong evaluations across domains/languages.
- Distillation of sensory-grounded embeddings into compact encoders
- Sectors: ML model compression, edge computing
- What: Use LLM’s sensory-steered kernels as targets to train small vision/audio encoders or dual-encoders.
- Why long-term: Needs robust teacher signals, large-scale paired data, and proof that distilled models retain alignment and transfer.
- Multisensory control axes beyond vision/audio
- Sectors: robotics, XR, education, creative tools
- What: Extend prompting to other latent factors (e.g., haptics, spatial layout, temperature, motion) to elicit richer grounded representations from text.
- Why long-term: Requires new benchmarks, reference encoders, and careful evaluation to avoid superficial word correlations.
- Safety- and reliability-grade “perceptual reasoning from text”
- Sectors: healthcare, autonomous systems, public sector
- What: Use sensory prompting to reason about media described in clinical notes, incident reports, or maintenance logs when raw media is restricted.
- Why long-term: Demands rigorous validation, bias analysis, and regulatory approval; the paper notes hallucination risks and lower audio alignment.
- Caption-to-vision/audition agents for retrieval-augmented generation (RAG)
- Sectors: enterprise search, customer support
- What: Agents that dynamically adopt
SEE/HEARmodes to query media stores via text proxies, improving answers with perceptual grounding. - Why long-term: Needs reliable routing, cost-effective generation at scale, and strong guardrails.
- Prompt optimization and auto-tuning for maximal alignment
- Sectors: ML tooling, MLOps
- What: Automated search over verbs, templates, and lengths to maximize mutual-kNN alignment for a given domain.
- Why long-term: Alignment estimation is compute-heavy; requires proxy metrics or distillation of alignment objectives.
- Curriculum data generation for multimodal pretraining
- Sectors: foundation model training
- What: Generate staged, sensory-rich textual curricula aligned to reference encoders, then pretrain models to accelerate true multimodal grounding.
- Why long-term: Needs careful study to prevent mode collapse, confirm transfer, and quantify benefits over standard pipelines.
- Privacy-first content moderation and compliance audits via text projections
- Sectors: platforms, policy/compliance
- What: Moderate and audit media via high-fidelity text projections augmented with sensory prompting to preserve perceptual relationships.
- Why long-term: Must validate coverage/false negatives, build legal frameworks for “proxy moderation,” and standardize caption quality.
- Cross-lingual perceptual alignment for low-resource languages
- Sectors: global education, cultural heritage, public-interest tech
- What: Use sensory prompting to better align multilingual captions with perception, improving retrieval and learning resources in low-resource languages.
- Why long-term: Depends on multilingual LLM strengths, multilingual reference encoders, and caption availability.
- Human-in-the-loop systems for scene-appropriate grounding
- Sectors: media production, education, scientific communication
- What: Editorial workflows that flag generic or hallucinated sensory terms and iteratively refine toward scene-appropriate detail.
- Why long-term: Requires UX, metrics for “scene-appropriateness,” and scalable annotation/feedback loops.
Notes on Feasibility and Dependencies
- Model scale: Larger LLMs show stronger modality separation and alignment. Smaller models may default to visual framing without cues.
- Generation length: 128–256 tokens generally improves alignment; >256 risks semantic drift. Budget tokens and add early-stopping criteria.
- Prompting style: Instructional prompts (“Imagine seeing…”) outperform non-instructional phrasing; verbs matter (“describe” may beat “imagine”).
- Modality mismatch:
SEEhelps vision alignment;HEARhelps audio, but audio alignment is weaker. Choose cue based on task and consider audio-optimized encoders for evaluation. - Data quality: Scene-appropriate sensory details are necessary; random “visual words” degrade alignment. Caption accuracy gates performance.
- Metrics and targets: Mutual-kNN alignment depends on chosen encoders (e.g., DINOv2, BEATs); validate across multiple reference models for robustness.
- Safety and disclosure: The system does not truly “see/hear.” Disclose the proxy nature; avoid use where pixel/temporal precision is critical (e.g., diagnosis, safety-critical perception).
- Compute and latency: Autoregressive embedding is costlier than single-pass; mitigate with caching, batching, and selective routing (turn sensory mode on only when beneficial).
- Generalization: Paper evaluates Qwen3; expect broader applicability but verify for your model family (Llama, Phi, etc.) before production.
- Open-source resources: Start from the project code repo to reproduce embedding pipelines and alignment measurements.
Glossary
- Autoregressive: A generation process where each token is produced sequentially, conditioning on previously generated tokens. "We observe that these autoregressive steps yield a representation that is more similar in geometry to an encoder that was trained on the corresponding modality."
- BEATs: A self-supervised audio encoder trained on natural sounds, used as the specialist auditory model. "For audio, we use BEATs-Iter3 \citep{Chen2022beats}, a self-supervised model trained only on natural sounds (AudioSet)."
- Bootstrap standard error: An uncertainty estimate computed by resampling with replacement and recomputing a statistic across replicates. "Error bars in paper figures denote ± 1 bootstrap standard error (), obtained by resampling paired rows with replacement from the dataset to form bootstrap replicates and recomputing the mutual-NN alignment score."
- Cosine neighbors: Nearest neighbors determined by cosine similarity between embedding vectors. "For each prompt condition and dataset, we embed all samples, construct kernels from cosine neighbors, and compute alignment between the LLM and the corresponding sensory encoder."
- Cross-modal convergence: The phenomenon where models trained on different modalities develop increasingly similar representation structures as they scale. "While such cross-modal convergence emerges with scale, it raises an interesting question."
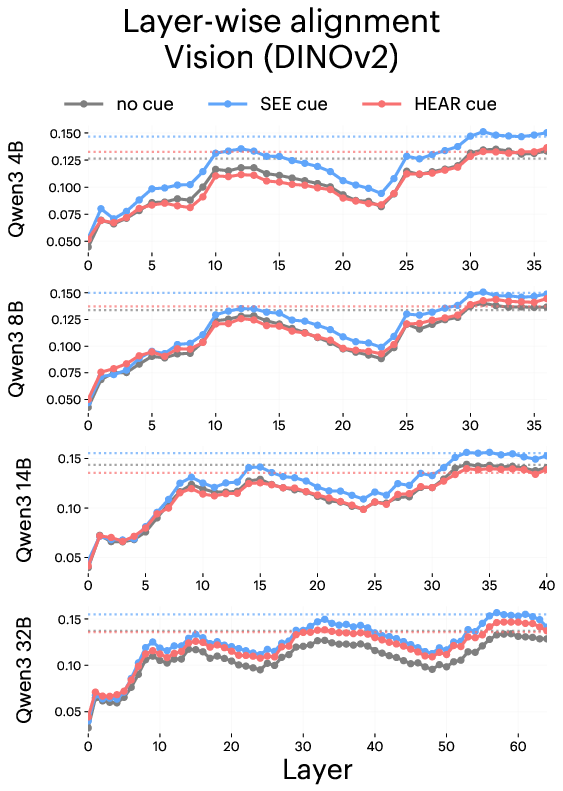
- DINOv2: A self-supervised vision encoder (ViT-based) used as the specialist visual model. "For vision, we use DINOv2-Base (ViT-B/14, 768-dim) \citep{oquab2023dinov2}, a self-supervised model trained only on images."
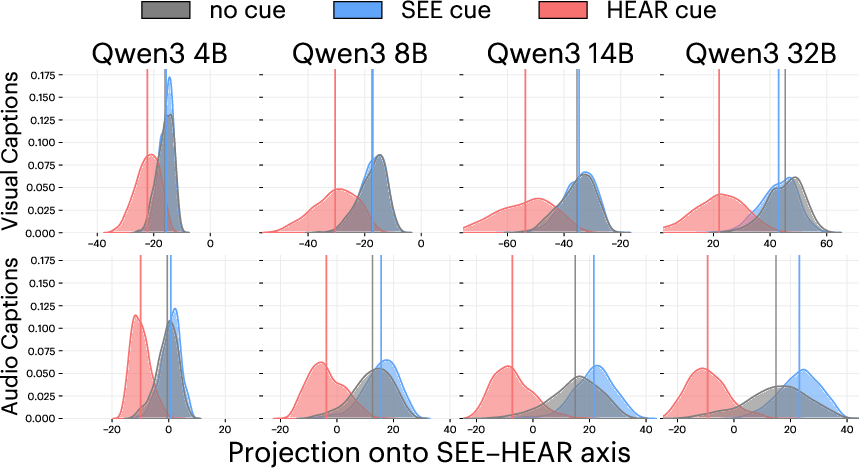
- Embedding projections: Mapping high-dimensional embeddings onto a lower-dimensional axis to analyze structure (e.g., modality separation). "Embedding projections onto visualâauditory axis show clearer modality separation in larger models."
- Frozen (model): A model evaluated without any parameter updates or fine-tuning. "All models are kept frozen during evaluation."
- Generative representations: Representations computed by aggregating hidden states over the tokens produced during generation, not just the initial pass. "In this work, we introduce the notion of generative representations: when an LLM is asked to generate, each output token involves another forward pass, which recursively builds a representation that is not only a function of the prompt, but also of the sequence generated so far."
- Kernel: The pairwise similarity matrix over a set of embeddings, often using cosine similarity. "Following the Platonic Representation Hypothesis framework \citep{huh2024platonic}, we define a representation as the set of embeddings a model produces on a dataset, and its induced kernel as the similarity structure among these embeddings."
- Kernel density estimation: A nonparametric method to estimate the probability density function of a random variable. "We estimate the distribution of using kernel density estimation."
- Latent structure: Underlying shared representational organization that different models or modalities can converge to. "They argue that this convergence reflects the existence of a shared latent structure underlying different modalities."
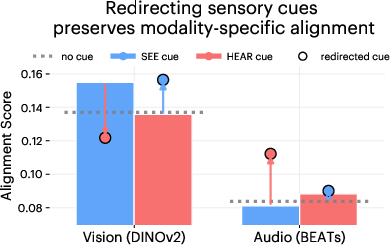
- Modality: A specific type of sensory information or data channel (e.g., vision, audio). "These results indicate that a single sensory cue in the prompt can steer the internal representations of the LLM to better match the geometry of the modality the cue invokes."
- Modality separation: The degree to which representations corresponding to different modalities are distinct from each other. "Larger models exhibit higher alignment under sensory prompting and stronger modality separation."
- Mutual-NN alignment: A measure of representational similarity based on the overlap of mutual k-nearest neighbors across two kernels. "To compare two kernels , we use mutual-NN alignment, "
- Platonic Representation Hypothesis: A framework proposing that models across modalities share convergent representational structures at scale. "Following the Platonic Representation Hypothesis framework \citep{huh2024platonic}, we define a representation as the set of embeddings a model produces on a dataset, and its induced kernel as the similarity structure among these embeddings."
- Prompt engineering: The practice of crafting input prompts to steer model behavior or internal representations. "Our findings reveal that lightweight prompt engineering can reliably activate modalityâappropriate representations in purely textâtrained LLMs."
- Qwen3: A family of LLMs evaluated as the text-only LLMs in this study. "We evaluate frozen Qwen3 LLMs \citep{yang2025qwen3} across scales (0.6B, 1.7B, 4B, 8B, 14B, 32B)."
- Residual connections: Architectural links that add inputs to outputs of layers to stabilize training and preserve information. "Residual connections in the LLM architecture make this averaging a meaningful summary of the modelâs overall state, which we evaluate in Appendix~\ref{app:layerwise_evaluation}."
- Representational alignment: The degree to which two models’ induced similarity structures over the same dataset are similar. "LLMs trained purely on text ostensibly lack any direct perceptual experience, yet their internal representations are implicitly shaped by multimodal regularities encoded in language. We test the hypothesis that explicit sensory prompting can surface this latent structure, bringing a textâonly LLM into closer representational alignment with specialist vision and audio encoders."
- Representational similarity: Quantitative comparison of how similarly two models encode relationships among inputs. "By defining the meaning of a symbol through the relationships it maintains with others \citep{wittgenstein1953pi}, alignment can be quantified through kernel-based representational similarity metrics (e.g., mutual -nearest neighbors)."
- Self-supervised model: A model trained without explicit labels by leveraging structure in the data itself. "For audio, we use BEATs-Iter3 \citep{Chen2022beats}, a self-supervised model trained only on natural sounds (AudioSet)."
- Sensory axis: A one-dimensional axis in embedding space that contrasts modalities (e.g., visual vs. auditory) by mean differences. "we project embeddings onto a sensory axis defined by the mean difference between prompt conditions."
- Sensory prompting: Adding explicit sensory cues (e.g., “see”, “hear”) to prompts to steer internal representations toward a modality. "We quantify how sensory prompting steers the representation of an LLM by comparing them to frozen unimodal encoders in vision and audio domains."
- Semantic drift: The tendency of long generations to deviate from the original prompt’s meaning over time. "However, we note that alignment can decline as you continue to increase output tokens due to semantic drift from the prompt (Appendix~\ref{app:extension})."
- Symbol-grounding problem: The challenge of how symbols gain intrinsic meaning without direct perceptual grounding. "This tension echoes the symbol-grounding problem, which asks how purely textual symbols can acquire intrinsic meaning without being anchored in direct perceptual experience \citep{harnad1990symbol}."
- Unimodal encoder: A model trained on and specialized for a single modality (e.g., vision-only or audio-only). "We quantify how sensory prompting steers the representation of an LLM by comparing them to frozen unimodal encoders in vision and audio domains."
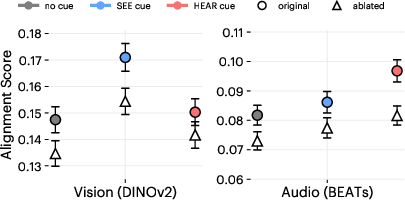
- Visual framing: Instructing a LLM to adopt a visual perspective or to imagine seeing content before answering. "We then evaluate Qwen3-14B as the question-answering model under two prompt conditions: a neutral instruction and a visual framing, which explicitly asks the model to imagine seeing the caption before answering."
- Visual Question Answering (VQA): A task where models answer questions about images; here evaluated via captions instead of images. "Visual cues allow LLMs to perform better on VQA in the text modality."
- VQA without V: A setup where the model answers visual questions using only captions (text), not images. "we adopt the ``VQA without V'' setting from \citet{chan2025on,chai2024auroracap}."
Collections
Sign up for free to add this paper to one or more collections.