- The paper demonstrates that LLMs internalize low-dimensional value manifolds whose alignment with predictive entropy reflects Bayesian uncertainty.
- The paper employs PCA, key orthogonality, and attention entropy metrics across multiple models to validate the link between geometric structures and Bayesian evidence integration.
- The paper reveals that architectural choices and training data modulate manifold collapse, offering actionable insights for improving uncertainty representation in transformers.
Geometric Scaling of Bayesian Inference in LLMs
Overview
"Geometric Scaling of Bayesian Inference in LLMs" (2512.23752) investigates whether the geometric mechanisms that enable exact Bayesian inference in synthetic "wind-tunnel" settings persist in modern LLMs. The study systematically probes value-manifold structure, key orthogonality, and attention dynamics across representative architectures (Pythia, Phi-2, Llama-3, Mistral), and links these geometric signatures to Bayesian evidence integration both in training and inference. The findings directly address foundational questions in interpretability and uncertainty representation in transformer-based LLMs.
Prior work established that small transformers, when trained on synthetic tasks with analytically tractable posteriors (e.g., bijection learning, HMM inference), form highly structured geometric substrates. Three principal signatures emerge:
- Value manifolds: The last-layer value vectors align along low-dimensional trajectories parameterized by posterior entropy.
- Key orthogonality: Key matrices develop near-orthogonal columns representing hypothesis frames.
- Attention distributions: Attention aligns with posterior predictive distributions, serving as a geometric Bayes rule.
This geometry results from cross-entropy gradients, with value manifolds and key frames supporting inference, and attention focusing sharpening posterior precision. The core question posed is whether these same signatures arise naturally in production-scale LLMs, trained on heterogeneous data and subject to architectural optimizations (GQA, RoPE, sliding-window, MoE).
Experimental Design
The authors analyze four representative LLM families:
- Pythia (standard MHA, general-purpose training)
- Phi-2 (standard MHA, curated/high-quality training)
- Llama-3.2-1B (grouped-query attention, web-trained)
- Mistral family (GQA, sliding-window, and MoE)
The geometric substrate is interrogated via:
- PCA of last-layer value representations, under diverse ("mixed-domain") and restricted prompts (e.g., mathematics only)
- Quantification of key orthogonality against random and initialization baselines
- Layerwise attention entropy as a focusing metric
- Direct in-context learning (ICL) experiments with analytically known Bayesian posteriors (SULA task)
- Causal interventions ablating entropy-aligned manifold directions
Static and Dynamic Geometric Signatures
Domain Restriction and Value Manifold Collapse
A central wind-tunnel prediction is validated: domain restriction should collapse the value manifold toward one dimension, corresponding to posterior entropy. In Llama-3.2-1B, mathematics-only prompts increase the explained variance by the top two PCs from 51.4% to 73.6%, approaching the one-dimensional structure seen in synthetic tasks. Pythia-410M, however, exhibits near-complete manifold collapse (∼99.7% explained by PC1+PC2) even under mixed prompts, reflecting architectural or training-induced rigidity.
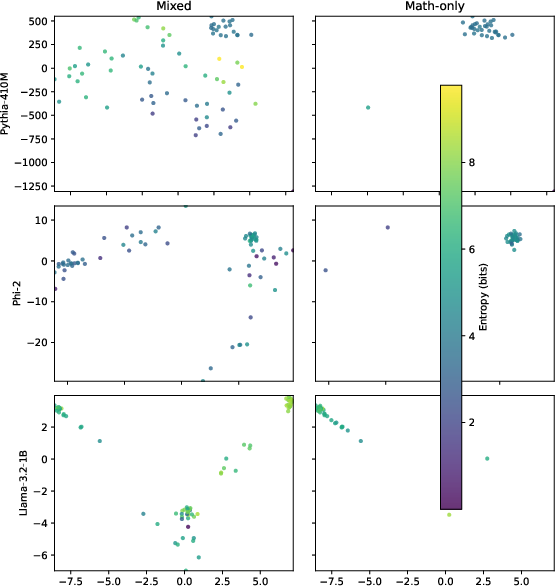
Figure 1: Domain restriction induces manifold collapse, especially in Llama-3.2-1B, as evidenced by PCA projections of last-layer value vectors with entropy coloring.
Value Manifolds, Entropy Alignment, and Posterior Evidence
Across models, final-layer value vectors align along axes that strongly correlate with predictive entropy (Spearman ∣ρ∣=0.14–$0.59$). During ICL experiments (SULA), model entropy closely tracks analytic Bayesian entropy (MAE 0.31–0.44 bits), and movement along the manifold is monotonic in supplied evidence. Controls demonstrate that this trajectory specifically reflects likelihood integration, not superficial prompt structure.
Key projection matrices in all models show 2–10× enhanced orthogonality relative to random baselines, especially in early/mid layers (mean off-diagonal cosine 0.034–0.18). This structured frame supports clean hypothesis discrimination, as predicted by cross-entropy gradient analysis.
Attention Focusing: Architectural Dependence
Layerwise attention entropy decreases most strongly in standard MHA (up to 86% in Phi-2), modestly in GQA (31% in Llama-3.2-1B), and is notably attenuated or non-monotonic in Mistral models (sliding-window/MoE). Thus, dynamic focusing is modulated by routing capacity, but static geometric invariants persist.
Cross-Model Geometric Summary
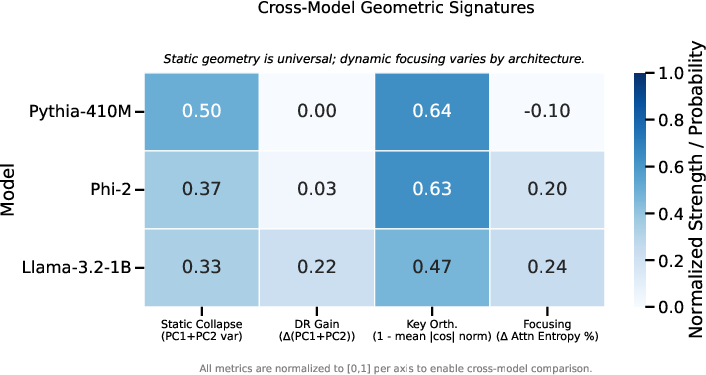
Figure 3: Normalized comparison of geometric metrics (manifold collapse, domain-restriction gain, key orthogonality, attention focusing) across model families highlights static invariants and dynamic variability.
Causal Probes: Entropy-Axis Ablations
Entropy-aligned manifold directions are ablated in Pythia-410M to test computational necessity. While projection removal destroys the geometry-entropy correlation, Bayesian calibration is minimally affected. This result indicates that the value manifold serves as a privileged readout of uncertainty, not a computational bottleneck; inference representations are distributed across layers and dimensions.
Depth, Training Data, and Representational Richness
Deeper or highly curated models (e.g., Phi-2) exhibit richer and clearer geometric signatures (2D manifolds, sharper orthogonality, stronger focusing). Mixed-domain prompts in deeper models can produce multi-lobed or higher-dimensional value structures, which collapse under domain restriction. Training on curated data enhances geometric clarity and likely supports more robust uncertainty modeling.
Architectural Trade-offs and Scaling Implications
Grouped-query attention architectures (e.g., Llama-3.2-1B) achieve efficiency gains but at the expense of diminished orthogonality and focusing clarity. Mistral-family models further attenuate focusing via sliding-window and MoE routing but retain static manifolds and hypothesis frames. This demonstrates a separation between universal representational substrates and mechanism-specific dynamics, matching the frame–precision dissociation predicted by gradient analyses.
Robustness, Limitations, and Open Directions
Bayesian geometric invariants (value manifolds, hypothesis frames) are robust across architecture, depth, and training regime, while layerwise focusing is sensitive to routing capacity. The emergence of multidimensional manifolds in large/deep models, the causes of architecture-dependent variability, and the precise triggering conditions for manifold collapse require further analysis—particularly at frontier model scales and in more diverse architectural regimes.
Implications and Future Research
This study provides direct evidence that transformers internalize a geometric coordinate system for representing uncertainty, and that evidence integration during inference leverages this substrate. Manifold coordinates offer a scalable, architecture-agnostic axis for uncertainty tracking and may support new diagnostics for interpretability, safety, and reliability estimation. Establishing causal roles and developing interventional methods remain open avenues. The findings motivate architectural choices (favoring standard MHA for interpretability) and curriculum learning strategies (curated-to-diverse data for geometric clarity).
Conclusion
Modern LLMs, regardless of scale or architectural optimization, develop low-dimensional geometric manifolds aligned with Bayesian uncertainty representation and update these representations during inference. However, the geometric substrate functions as a stable representational readout, not a singular computational pathway. The study opens a lens for principled mechanistic interpretability grounded in geometric invariants, with significant implications for architecture design, model analysis, and uncertainty quantification in next-generation AI.
