Emotions Where Art Thou: Understanding and Characterizing the Emotional Latent Space of Large Language Models
Abstract: This work investigates how LLMs internally represent emotion by analyzing the geometry of their hidden-state space. The paper identifies a low-dimensional emotional manifold and shows that emotional representations are directionally encoded, distributed across layers, and aligned with interpretable dimensions. These structures are stable across depth and generalize to eight real-world emotion datasets spanning five languages. Cross-domain alignment yields low error and strong linear probe performance, indicating a universal emotional subspace. Within this space, internal emotion perception can be steered while preserving semantics using a learned intervention module, with especially strong control for basic emotions across languages. These findings reveal a consistent and manipulable affective geometry in LLMs and offer insight into how they internalize and process emotion.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: where do emotions “live” inside LLMs like LLaMA? The authors look inside these models to see how feelings such as happiness, sadness, anger, and fear are represented. They discover that emotions form a consistent, low-dimensional “shape” (a kind of map) inside the model’s hidden layers, and that this map is similar across different kinds of text and even across multiple languages. They also show that you can gently “steer” the model’s internal emotional perception without changing the actual meaning of the text.
Key Questions
The paper explores three main questions in everyday terms:
- Do LLMs organize emotions in a simple, understandable way inside their “brain”?
- Is this internal emotion map similar across different datasets, writing styles, and languages?
- Can we carefully nudge the model’s internal sense of emotion (e.g., make “neutral” feel “happy”) while keeping the original meaning the same?
How They Studied It (Methods)
Think of an LLM’s hidden states (its internal activity) as points on a secret map. The researchers used a few tools to understand that map:
- Finding the main directions (SVD): Imagine looking at a big cloud of points on a map and trying to find the main “roads” that explain most of the movement. Singular Value Decomposition (SVD) does that: it finds the strongest directions along which emotions vary. If emotions are arranged along a few main roads (like “positive vs. negative” or “calm vs. excited”), then the model is using a simple emotional map.
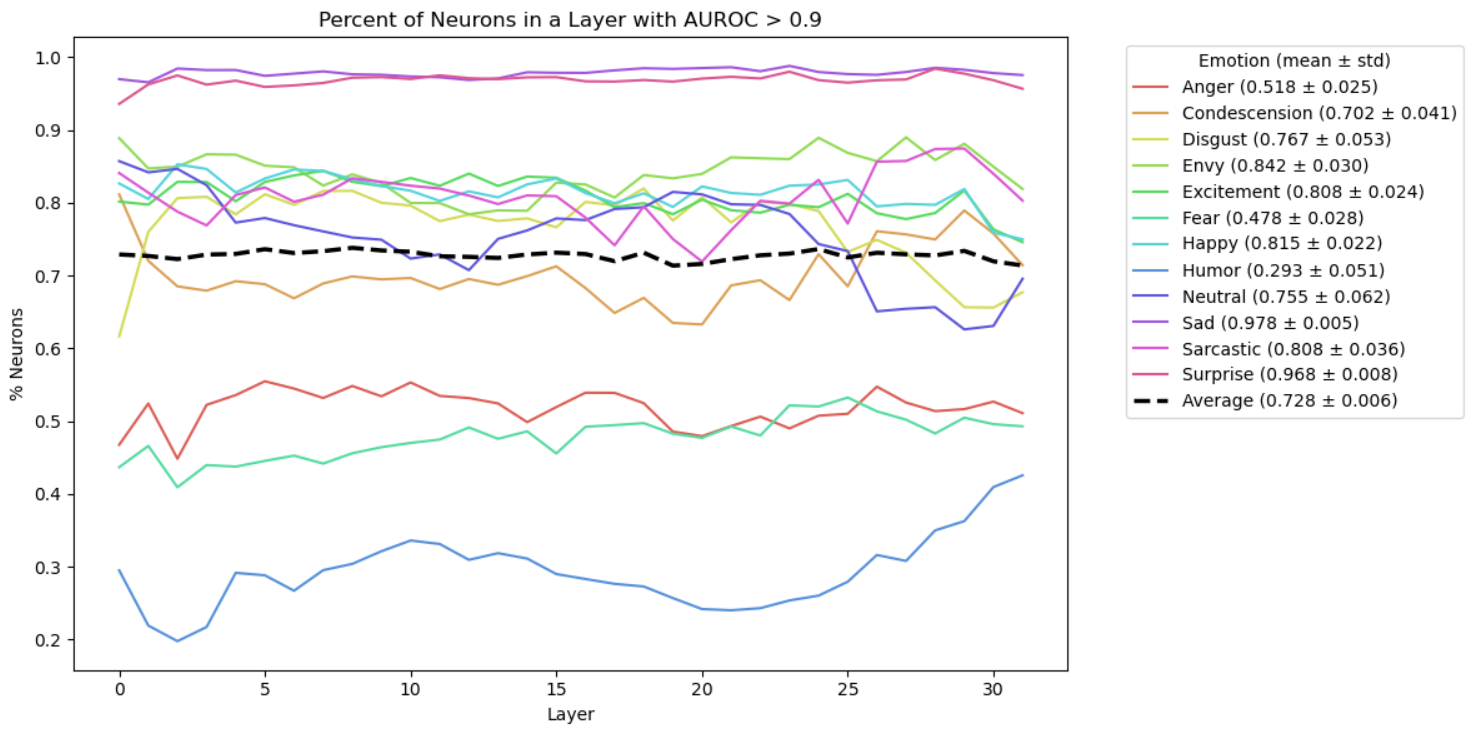
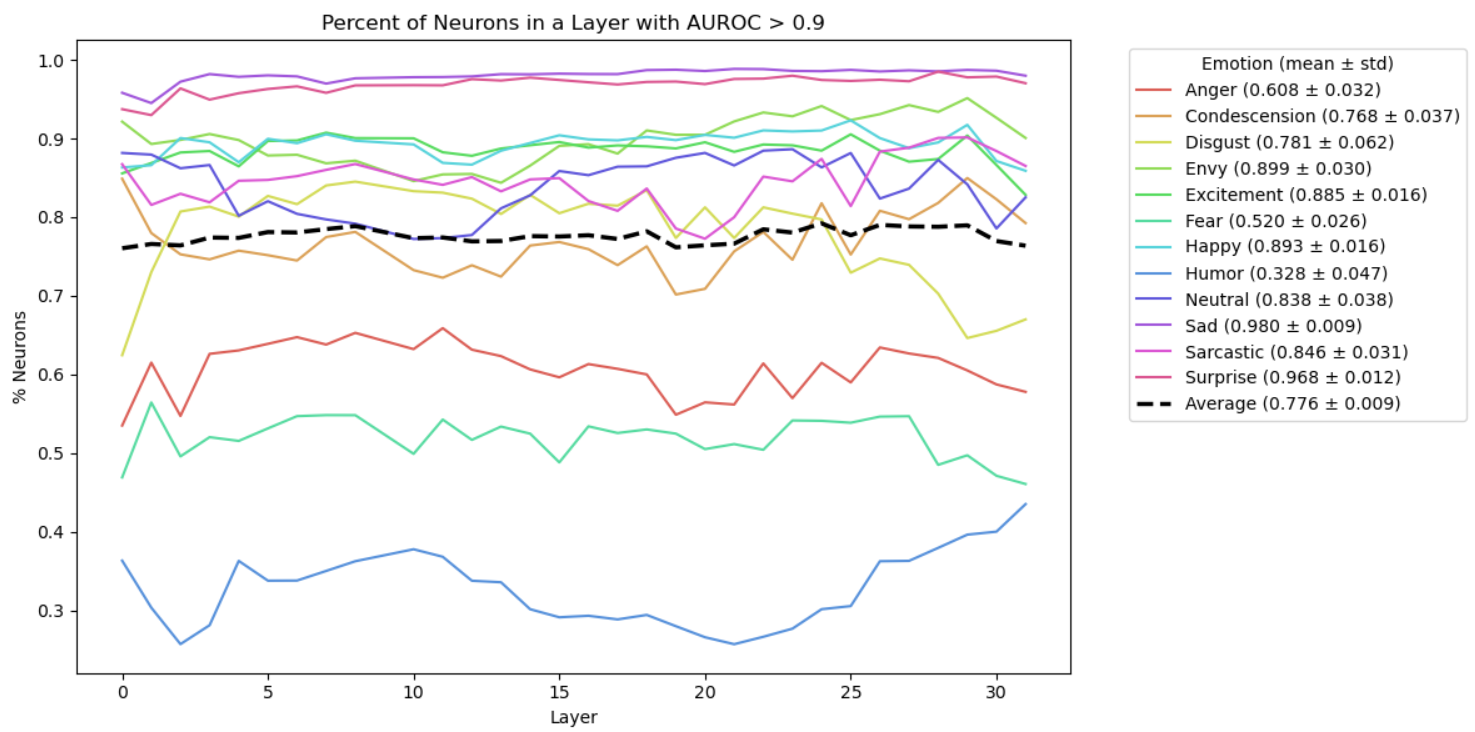
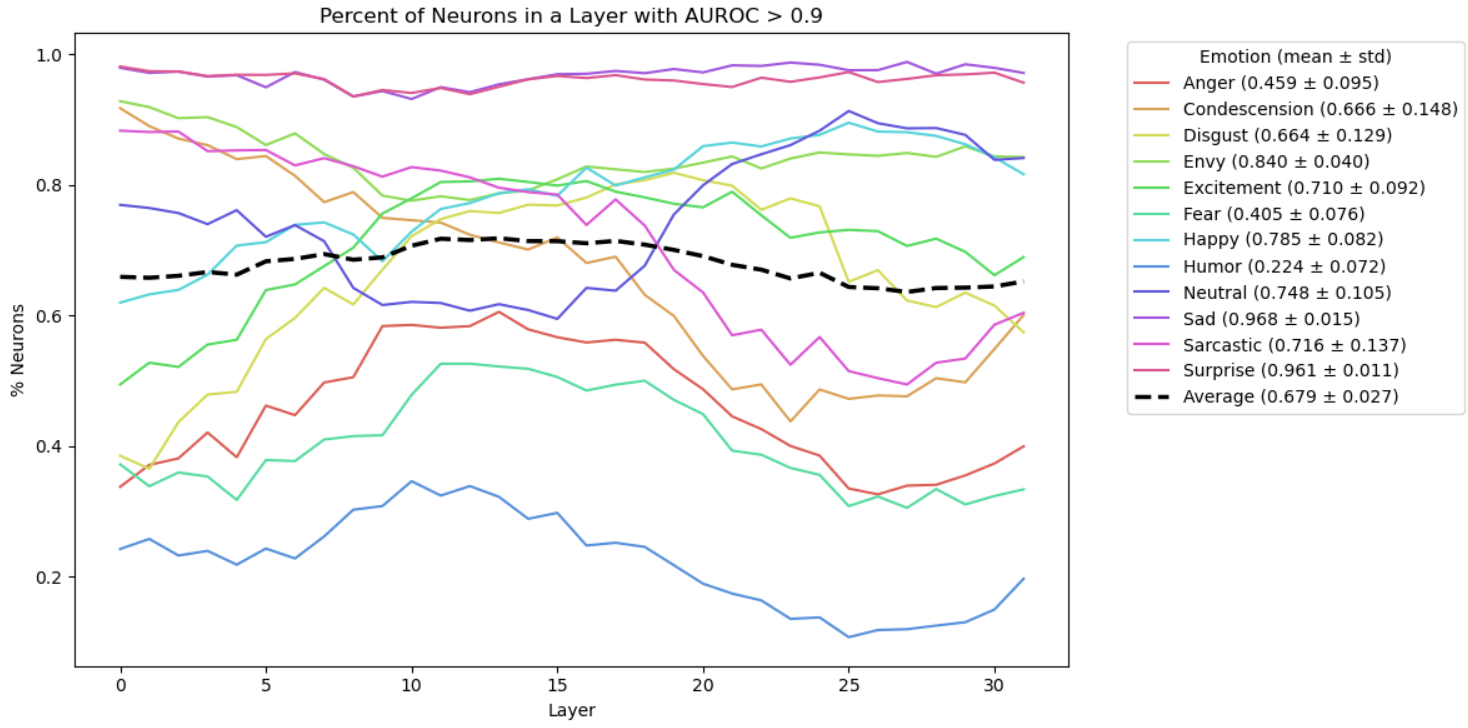
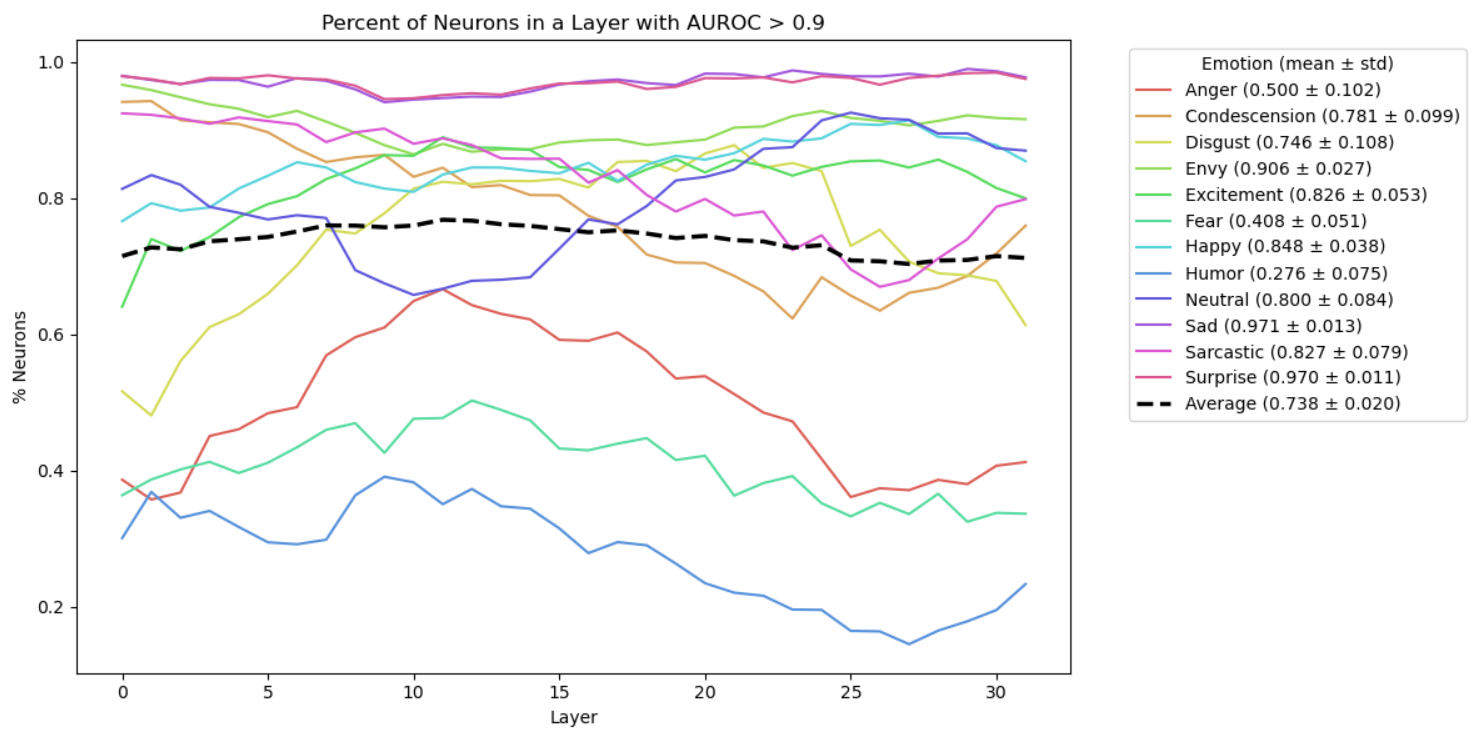
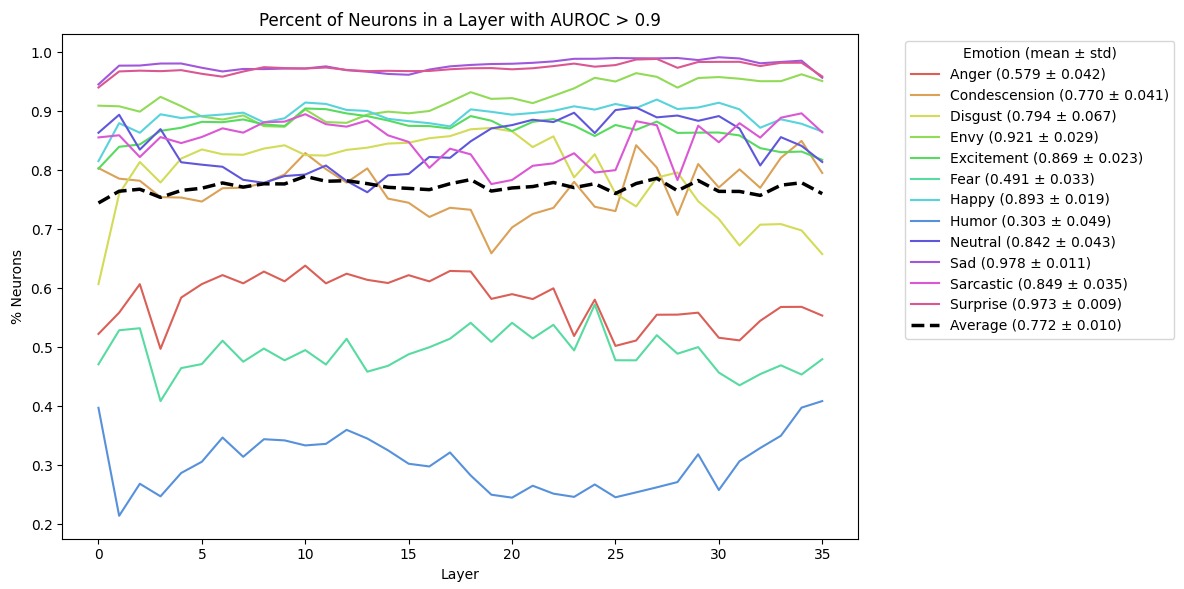
- Neuron specialists (ML-AURA): Neurons are tiny units inside the model. ML-AURA is a way to check if some neurons act like “special detectors” for certain emotions. For example, does a neuron light up especially for “sadness”? The method scores how well individual neurons pick out one emotion versus others.
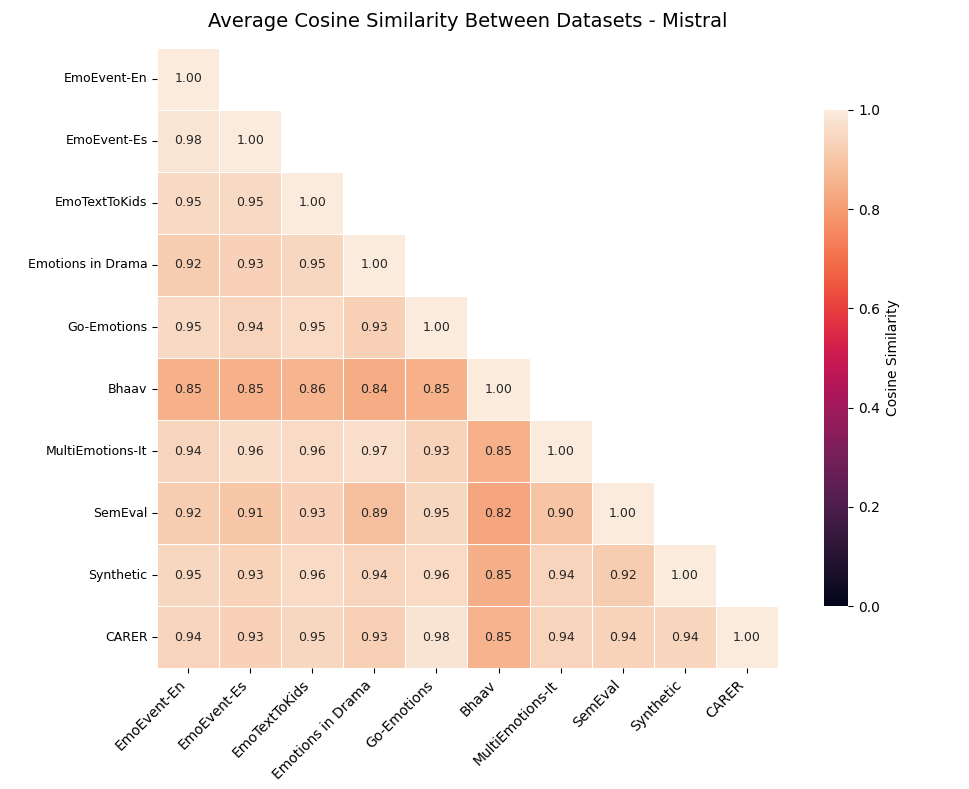
- Lining up different maps (Alignment): Text from different sources and languages might create slightly different emotional maps. The authors use simple math (linear alignment) to line up one map with another and see if they match well. If they do, it suggests a universal emotional structure across domains.
- Simple readers (Linear probes): A “linear probe” is like a basic quiz that reads the internal map and tries to guess the emotion from it. If a simple probe can predict emotions well, it means the emotional information is easy to read out from the model’s hidden states.
- Gentle nudging (Steering module): The team builds a small add-on that operates on the emotional subspace (the main roads found by SVD). It shifts the internal representation toward a target emotion (like “happy”) while trying to keep the meaning of the original text intact. Think of it as turning the emotional dial without changing the facts.
What They Found (Results)
- Emotions live in a small, consistent space: The model’s internal representation of emotion sits on a low-dimensional “emotional manifold” (a simple shape/map). Emotions are encoded directionally—moving along certain directions increases or decreases specific feelings.
- Distributed across layers: Emotion isn’t stored in just one place. Many neurons and many layers contribute, with lots of overlap. This looks more like a “constructionist” view (emotions emerge from many parts working together) than isolated emotion modules.
- Interpretable emotion axes: The main directions found by SVD line up with well-known psychological dimensions:
- Valence (positive vs. negative): happy/surprise on one end; anger/fear on the other.
- Dominance/control: feelings of lower control (like fear/sadness) are separated from more autonomous states.
- Approach vs. avoidance: excitement/happy/envious vs. anger/fear.
- Arousal (calm vs. energized): surprise/fear often high; neutral/happy lower.
- These axes aren’t perfectly labeled by the model, but they closely resemble classic emotion theories.
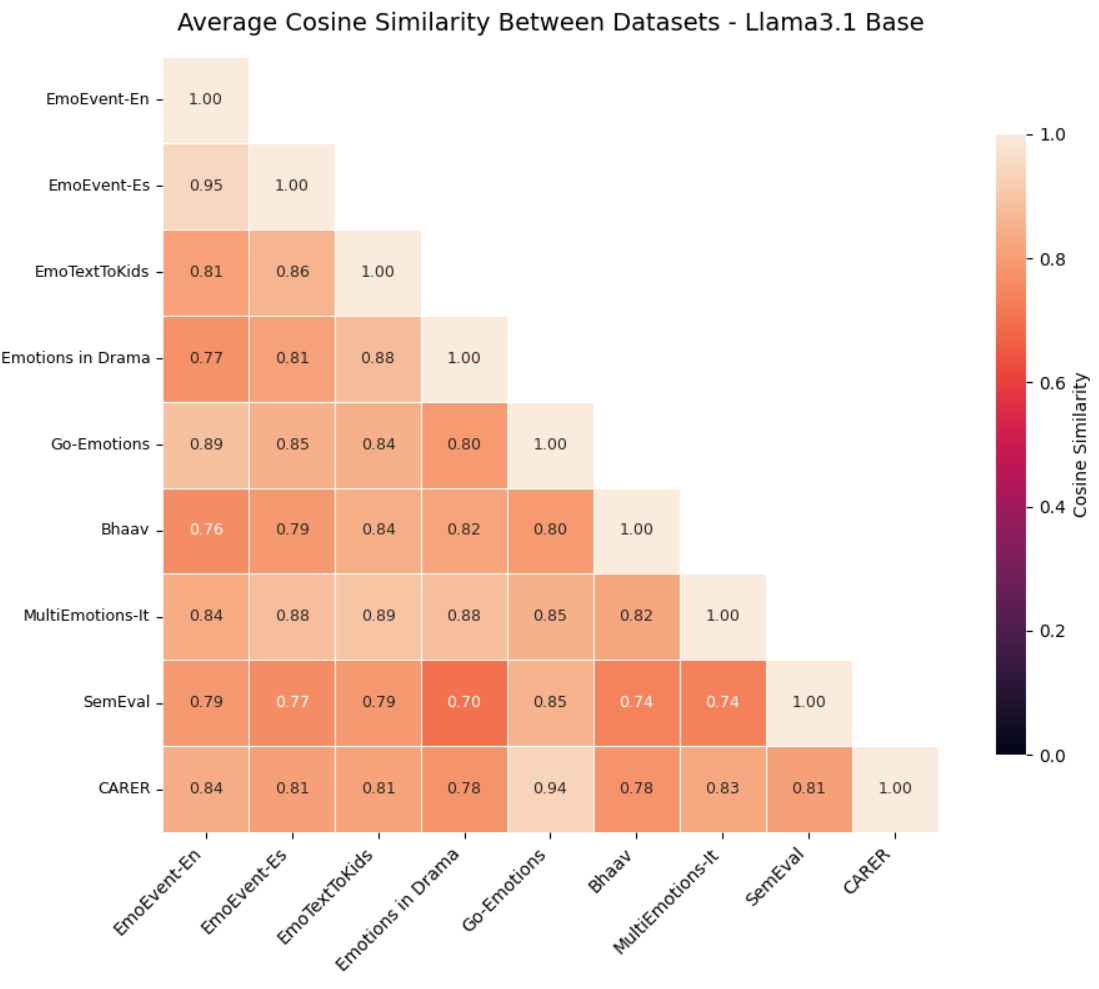
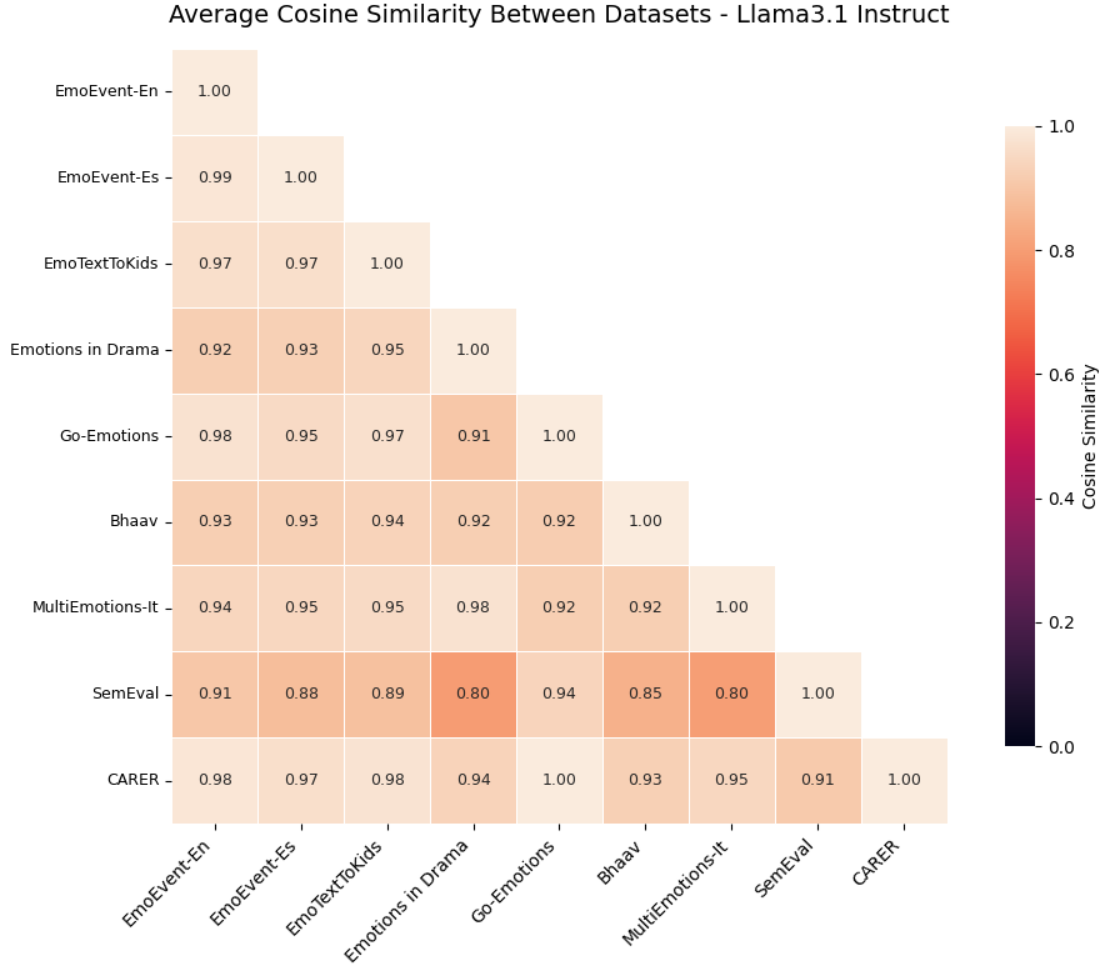
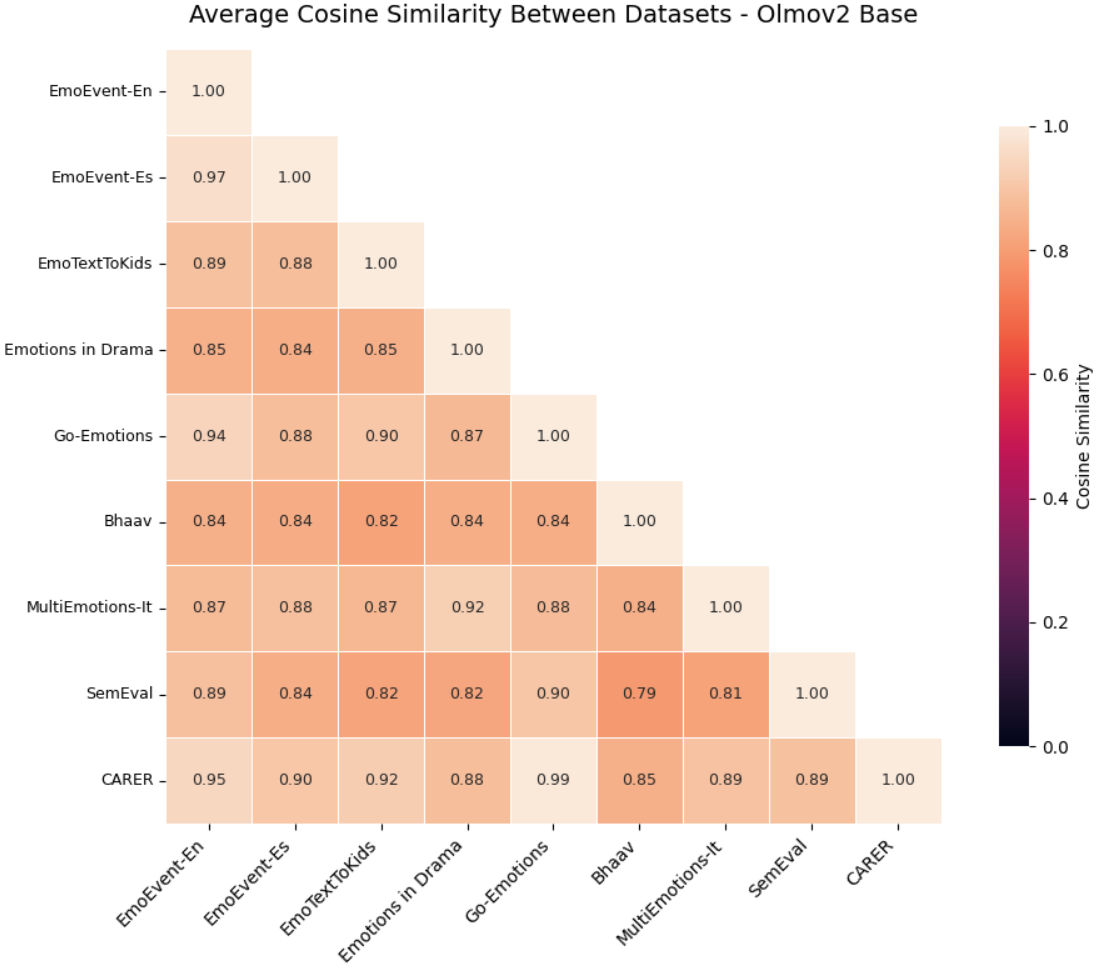
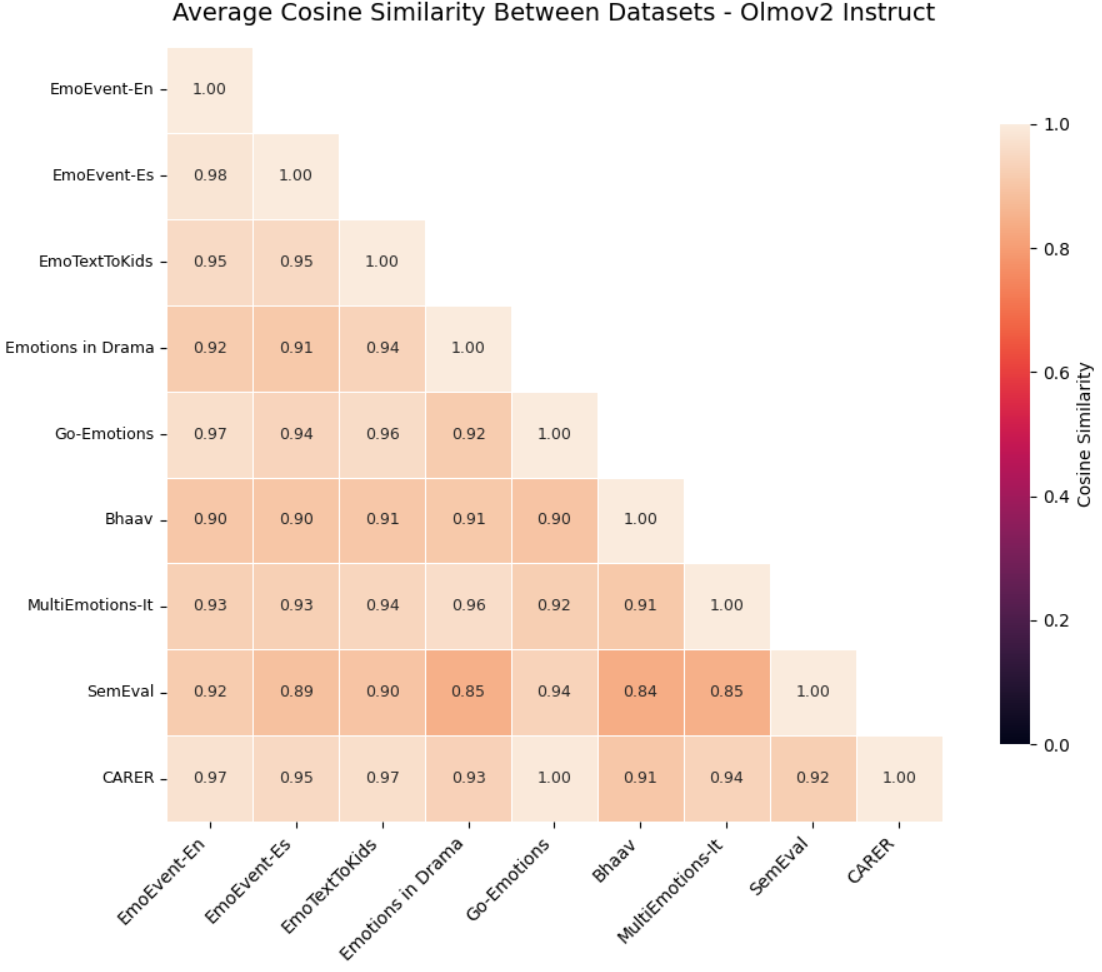
- Universal across datasets and languages: The emotional map aligns well across eight different datasets in five languages (English, Spanish, German, Hindi, French). Simple alignment methods show the maps are very similar, and linear probes can decode emotions above chance, often strongly. Some model versions (like instruction-tuned ones) align even better, though a few families show more distortion.
- Strong neuron selectivity: Many neurons respond selectively to certain emotions. Basic emotions like sadness and surprise have especially strong signals, and selectivity appears across the whole depth of the model.
- Controllable internal emotion: The steering module can shift the model’s internal emotional perception (e.g., toward “happy” or “sad”) while preserving the semantics. Control is particularly strong for basic emotions and works across languages. In many cases, post-steering accuracy for the target emotion is very high (often above 85%), and the meaning stays close to the original.
Why It Matters (Implications)
- Better understanding and safer AI: Knowing how emotions are internally represented helps researchers make models more transparent and trustworthy. It’s easier to monitor, explain, and improve how models handle sensitive emotional content.
- Cross-language robustness: The discovery of a shared emotional subspace across languages supports building multilingual systems that understand and manage emotion consistently.
- Useful control without rewriting meaning: The ability to steer internal emotion while preserving the original facts can help in applications like tutoring, mental health support (with caution), and customer service—where tone matters.
- Bridges to psychology: The model’s emergent emotion axes resemble classic emotion dimensions, suggesting LLMs naturally learn meaningful affective structures from language. This could inspire new tools for studying or measuring emotion in text.
In short, this paper shows that emotions in LLMs aren’t random or hidden behind opaque labels—they form a clear, stable, and steerable map inside the model. This opens the door to more interpretable, reliable, and emotionally aware AI systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points identify what remains missing, uncertain, or unexplored in the paper and suggest concrete directions for future research:
- Derivation of the emotional manifold from synthetic rewrites risks imprinting artifacts specific to synthetic generation; validate manifold extraction using only human-authored corpora and compare to synthetic-derived manifolds.
- Potential lexical confounds: many datasets contain explicit emotion words; assess whether geometry persists when emotion lexemes are masked/removed or replaced with neutral synonyms, and when evaluating on lexicon-free corpora.
- Mean-pooling of token activations may discard crucial positional or contextual signals; compare against alternative pooling schemes (e.g., last-token, CLS-like proxies, learned attention pooling, per-head attention-weighted pooling) and per-token analyses.
- Linear SVD captures only first-order structure; test whether nonlinear methods (kernel PCA, UMAP/Isomap, autoencoders, contrastive subspace discovery) reveal additional or different affective geometry.
- Intrinsic dimensionality is not estimated; compute layer-wise intrinsic dimension (e.g., participation ratio, MLE dimension estimators) and quantify how many dimensions are needed for stable emotion decoding across datasets.
- Interpretation of principal components as valence/dominance/approach/arousal is qualitative; quantify correlations with human VAD/approach-avoidance ratings, report effect sizes and confidence intervals, and test across layers and models.
- Alignment across datasets uses linear regression without detailed generalization controls; add cross-validation, held-out datasets, and report out-of-domain alignment error to prevent overfitting to alignment pairs.
- Distortion metrics lack precise definitions and calibration baselines (e.g., sigma-distortion formula, scaling); provide formal definitions, unit scaling, bootstrapped nulls, and sanity checks (e.g., permutation baselines) to interpret magnitudes.
- Extremely large distortion values (e.g., OLMo-v2-Instruct in 50D) suggest numerical instability or metric pathology; diagnose causes (conditioning, scaling, sample size) and stabilize with normalization/regularization or robust metrics.
- Universality is claimed despite many “outlier” layers/datasets; predefine operational criteria for universality and statistically test across layers/datasets with corrections for multiple comparisons.
- ML-AURA adaptation reports remarkably high neuron selectivity (e.g., >75%); rule out spurious selectivity via controls: label shuffling, frequency-matched neutral controls, removal of emotion lexemes, and cross-dataset replication with strict splits.
- Causality of identified directions/neurons is not established; perform activation patching, causal mediation analysis, and targeted ablations to test necessity/sufficiency of directions and units for emotion decoding and downstream behavior.
- Topic/content confounds may drive clusters; control for topic by balancing topics within emotion labels, residualizing topic embeddings, or evaluating on topic-neutral synthetic paraphrases.
- Multi-label, intensity, and continuous affect are underexplored; extend analyses and steering to mixtures of emotions, graded intensities, and continuous VAD spaces, including calibration of intensity control.
- Sarcasm, irony, and figurative language are not tested; evaluate manifold stability and steering under pragmatic phenomena that invert or obfuscate surface cues.
- Cross-lingual coverage is limited (five languages) and culturally nuanced emotions are absent; expand to typologically and culturally diverse languages (e.g., Arabic, Japanese, Yoruba), dialects, and code-switching settings, and test culture-specific taxonomies.
- Tokenization differences across languages/models are not controlled; analyze how subword segmentation affects emotional directions and cross-lingual alignment robustness.
- Model diversity and scaling laws are not examined; probe multiple sizes per family and training recipes to identify emergence and scaling of the emotional manifold.
- Instruction tuning sometimes degrades geometric consistency (e.g., OLMo-v2-Instruct), but mechanisms are unclear; run controlled tuning experiments varying data (SFT, RLHF) and objectives to isolate causes of geometric drift.
- Temporal/narrative dynamics are ignored by sentence-level pooling; study emotion trajectories within longer texts and dialogues, and how emotions evolve across tokens and layers.
- Steering evaluation focuses on internal token logits and hidden-state similarity; add external validators (frozen third-party emotion classifiers), human judgments on generated continuations, and task-level metrics (e.g., persuasion, safety).
- Semantic preservation is measured only via hidden-state cosine/L2; include text-level metrics (e.g., BERTScore, BLEURT), factuality checks, and human evaluations for meaning preservation and unintended style/topic shifts.
- Risk of “gaming” via emotion-token margins; verify that steering changes perceived emotion without overfitting to specific tokens by using adversarial synonym sets, paraphrase-based evaluations, and lexicon-free judges.
- Layer selection for steering is heuristic (centroid-induced AUROC gains); ablate selection criteria, test unified controllers across layers, and quantify compute overhead and latency impacts in deployment scenarios.
- Interactions among emotions are not studied; investigate multi-target and compositional steering (e.g., bittersweet, anxious-joyful), and continuous trajectories along the manifold with controllable intensity.
- Generalization of the steering module across datasets and languages is not fully quantified; evaluate zero-shot transfer to unseen domains/emotions and report degradation curves with domain shift.
- Downstream behavioral effects of internal steering remain unknown; measure impacts on decisions, refusals, helpfulness, or bias under emotionally framed prompts.
- Safety and misuse risks are not analyzed; assess robustness to adversarial steering, potential for manipulative or harmful affective control, and develop mitigation/guardrails.
- Mapping across heterogeneous label sets (e.g., dataset-specific taxonomies) is under-specified; document and evaluate label harmonization procedures and test sensitivity to alternative mappings.
- Visualization relies on t-SNE, which can be misleading; complement with UMAP and quantitative separability metrics (e.g., silhouette, Davies–Bouldin) and report stability across random seeds/perplexities.
- Preprocessing choices (centering, standardization, dimensionality cutoffs: 50D for analysis vs 40D for steering) may affect results; perform sensitivity analyses and justify selected hyperparameters.
- Reproducibility details (data splits, seeds, code/artifacts) are incomplete; release code, alignment/metric implementations, and standardized evaluation scripts to enable verification and extension.
Practical Applications
Practical Applications Derived from the Paper’s Findings
This paper reveals a low-dimensional, manipulable emotional manifold inside LLMs that is directionally encoded, distributed across layers, and broadly consistent across datasets and languages. It also demonstrates that emotions can be linearly decoded and causally steered within this subspace while preserving semantic content. The following applications translate these findings into actionable, real-world scenarios.
Immediate Applications
The items below can be piloted or deployed with current open-weight models and standard ML tooling, assuming access to hidden states and inference-time hooks.
- Multilingual emotion detection and routing for customer support and moderation (software, customer service)
- Use linear probes trained in the identified emotional subspace to triage tickets/chats by emotions (e.g., anger, sadness, fear) across English, Spanish, French, German, Italian, Hindi.
- Tools/workflows: probe training on mean-pooled hidden states; cross-domain alignment for new datasets; dashboards for agent routing.
- Assumptions/dependencies: access to hidden states or a model with introspection hooks; per-model calibration (LLaMA 3.1 shows stronger universality than some OLMo variants); human-in-the-loop escalation.
- Tone-consistent content generation and brand voice control (marketing, media, product UX)
- Integrate the learned steering module to produce emotionally targeted copy (e.g., reassuring, excited) while preserving semantics.
- Tools/products: “tone sliders” in copy editors; A/B testing pipelines; plugins for open-source LLMs.
- Assumptions/dependencies: steering requires mid-layer interventions; semantic preservation should be validated on domain-specific content.
- Adaptive tutoring assistants that respond to learner affect (education)
- Detect frustration/confusion (e.g., low valence, high arousal) and steer responses towards encouragement and clarity.
- Tools/workflows: real-time emotional probes; response policies that modulate tone; analytics for educator oversight.
- Assumptions/dependencies: text is a reliable proxy for student emotion; guardrails to avoid undue persuasion; privacy controls for minors.
- Clinical triage signals in helplines and care navigation (healthcare)
- Monitor valence–arousal–dominance-like axes to flag potential crises or distress for faster human review.
- Tools/products: “risk flags” in intake platforms; multilingual triage support.
- Assumptions/dependencies: non-diagnostic use; rigorous oversight; strong privacy/GDPR compliance; domain-specific calibration to reduce false positives.
- Public sentiment and social listening at scale (policy, finance, media)
- Leverage cross-dataset, cross-language alignment to build comparable emotion indices for regions/communities.
- Tools/workflows: alignment pipelines; temporal dashboards; alerts for spikes in anger/fear.
- Assumptions/dependencies: representativeness of sources; corrections for cultural expression differences; careful interpretation to avoid spurious market/policy decisions.
- Safety and compliance guardrails via emotion-aware filtering (software safety)
- Detect high-arousal, aggressive or manipulative emotional frames and steer internal perception towards neutral/low-arousal states before response generation.
- Tools/workflows: pre-response emotion screening; steering policies; red-teaming hooks.
- Assumptions/dependencies: consistent mapping from internal state to output behavior; evaluation for side effects on helpfulness/fidelity.
- Model interpretability and QA using ML-AURA and distortion audits (ML/AI ops, academia)
- Identify emotion-selective neurons/layers and audit layer-wise geometric distortion to choose robust intervention points.
- Tools/workflows: ML-AURA scoring; stress/distortion dashboards; layer selection for steering.
- Assumptions/dependencies: open-weight access; compute for layer-by-layer analysis; reproducible pipelines across model families.
- Dataset alignment and rapid transfer learning for emotion tasks (academia, NLP tooling)
- Align a synthetic emotional subspace to new human-authored datasets to reduce labeling effort and bootstrap probes across domains.
- Tools/workflows: linear alignment (regression/rigid transforms); probe training; taxonomy mapping.
- Assumptions/dependencies: universality holds for target domains; tune per-language; monitor stress/distortion metrics to detect misalignment.
- Personal writing assistants for tone control (daily life, productivity)
- Provide “warmth,” “neutral,” “concise but kind” sliders that steer tone without changing intent.
- Tools/products: email and messaging plugins; journaling mood analysis.
- Assumptions/dependencies: consent and privacy; clear user controls and transparency about tone manipulation.
- Multilingual customer feedback analytics with unified emotion metrics (retail, product)
- Normalize emotional signals across regions/languages for comparable product sentiment tracking.
- Tools/workflows: cross-language alignment; periodic indices; drill-down by emotion clusters.
- Assumptions/dependencies: cultural calibration; dataset coverage; ongoing validation against human ratings.
Long-Term Applications
These require further research, scaling, or standardization (e.g., robust APIs for hidden-state access, cultural calibration, multimodal integration, clinical trials).
- Standardized emotion APIs for LLMs (software platforms)
- Expose affective subspace endpoints (probe, project, steer) in model-serving stacks.
- Tools/products: model-agnostic SDKs; “emotional layer” adapters; governance logs.
- Dependencies: vendor support; secure, auditable intervention interfaces.
- Cultural calibration and fairness benchmarks for affect (policy, academia)
- Expand datasets, human ratings, and calibration methods to reflect diverse cultural norms in emotion expression.
- Tools/workflows: benchmark suites; cross-cultural axes mapping; bias/fairness audits.
- Dependencies: sociolinguistic research; multilingual data; consensus metrics.
- Emotional resilience modules to reduce exploitability by manipulative prompts (AI safety)
- Steer internal states away from high-compliance under emotionally charged inputs; evaluate with red-teaming.
- Tools/workflows: resilience policies; attack frameworks; behavior–geometry correlation studies.
- Dependencies: robust causal links between internal geometry and compliance; monitoring for unintended impacts on helpfulness.
- Therapeutic-grade chatbots with controlled affect and semantic fidelity (healthcare)
- Deliver consistent, validated emotional tone with guardrails and longitudinal tracking; integrate into care pathways.
- Tools/products: clinical-grade steering modules; outcome dashboards; supervision portals.
- Dependencies: clinical trials; regulatory approvals; ethical frameworks; crisis handoff protocols.
- Emotion-aware robotics and multimodal assistants (robotics, IoT)
- Extend subspace discovery and steering to speech prosody, vision, and embodied interaction; modulate robot behavior by detected human affect.
- Tools/workflows: multimodal fusion; low-latency projection kernels; policy learning tied to affect.
- Dependencies: real-time constraints; multimodal datasets; safety certification for human-robot interaction.
- Market risk and trading analytics from cross-market emotion indices (finance)
- Build predictive signals linking aggregate emotions to volatility or event risk; incorporate cross-language streams.
- Tools/workflows: factor construction; backtesting; compliance review.
- Dependencies: rigorous causal validation to avoid overfitting; regulatory scrutiny; data provenance.
- Longitudinal education personalization based on affect trajectories (education)
- Track student-level emotional baselines and adapt curricula, pacing, and feedback over semesters.
- Tools/workflows: consent-based analytics; teacher oversight; adaptive content engines.
- Dependencies: privacy-by-design; equitable access; avoidance of stigmatization.
- Hardware/software optimization for emotional subspace operations (computing, edge AI)
- Develop efficient kernels for projection/steering on edge devices; enable on-device affect-aware assistants.
- Tools/products: optimized operators; inference graphs with emotion modules.
- Dependencies: adoption in serving stacks; measurable latency/energy benefits.
- Regulatory standards for transparency in emotional manipulation (policy, governance)
- Require disclosures when tone steering is applied; watermarking of emotionally steered outputs; audit trails.
- Tools/workflows: compliance SDKs; standardized reporting; third-party audits.
- Dependencies: regulator consensus; industry coalitions; enforcement mechanisms.
- Generalized steerable controllers for socio-linguistic attributes (software, academia)
- Extend methods to politeness, empathy, toxicity, assertiveness; build multi-attribute controllers with semantic preservation.
- Tools/workflows: subspace discovery across attributes; joint steering policies; evaluation suites.
- Dependencies: attribute datasets; interaction effects analysis; safe combination policies.
- Population-scale public health monitoring with ethical safeguards (public health, policy)
- Aggregate multilingual emotion signals for early detection of community distress (e.g., disasters, epidemics).
- Tools/workflows: privacy-preserving analytics; alert governance; stakeholder review boards.
- Dependencies: robust consent frameworks; bias mitigation; clear benefit–risk assessments.
- Emotion ontology building and cross-taxonomy reconciliation (academia, NLP)
- Use manifold geometry to derive or align emotion taxonomies, bridging discrete categories with dimensional models.
- Tools/workflows: axis interpretation pipelines; dataset harmonization; links to VAD/circumplex frameworks.
- Dependencies: interdisciplinary collaboration with psychology; validation against human judgments.
General Assumptions and Dependencies Across Applications
- Access to hidden states and mid-layer intervention is typically required; closed APIs may not permit steering.
- Universality is stronger in some models (e.g., LLaMA 3.1 base/instruct) than others (some OLMo variants); per-model audits are necessary.
- Cultural variation in emotion expression persists; alignment and calibration should be validated per language and domain.
- Steering aims to preserve semantics but requires domain-specific testing to avoid subtle meaning shifts.
- Ethical considerations are central: transparency, user consent, privacy, and avoidance of manipulative or discriminatory uses are mandatory.
Glossary
- Affective geometry: The structured, spatial organization of affective (emotional) representations within model hidden states. "These findings reveal a consistent and manipulable affective geometry in LLMs"
- Anchor-relative representations: Latent representations defined with respect to fixed reference points (“anchors”) to reduce variability across spaces. "lift these spaces into anchor-relative representations"
- Approach–avoidance: A psychological dimension indicating motivation to move toward or away from stimuli or goals. "PC3 maps onto approach–avoidance motivation."
- Area under the precision-recall curve (AUC-PR): A performance metric summarizing precision-recall tradeoffs across thresholds. "area under the precision-recall curve"
- AUROC: Area under the receiver operating characteristic curve; a measure of binary classification performance. "evaluated by AUROC"
- Centered-SVD: Applying singular value decomposition to centered activation data to extract principal directions. "Centered-SVD."
- Centroid: The mean vector representing the central tendency of a class in embedding space. "emotion centroids"
- Centroid cosine similarity: The cosine similarity between class centroids, indicating directional alignment across spaces. "average centroid cosine similarity"
- Cosine schedule: A learning rate schedule that follows a cosine function over training steps. "using a cosine schedule with 50 warm-up steps."
- Decoder-only LLMs: LLMs that generate output token-by-token without a separate encoder. "we study decoder-only LLMs"
- Embedding distortion metrics: Quantitative measures of how distance relationships are preserved across embeddings. "three high-dimensional embedding distortion metrics are reported"
- Frobenius norm: A matrix norm (sqrt of sum of squares of all entries) used to quantify transformation magnitude. "Frobenius norm values"
- GELU: Gaussian Error Linear Unit; an activation function used in neural networks. "one-layer MLP with a GELU activation"
- Hidden-state geometry: The geometric structure formed by model hidden-state vectors. "hidden-state geometry"
- Instruction-tuned: Models further trained on instruction following data to improve task adherence. "instruction-tuned models"
- Isometric variance: Variability in latent spaces that preserves distances (isometries) but changes orientation. "to handle isometric variance"
- Kendall’s Tau: A rank correlation coefficient assessing ordinal association between variables. "Kendall’s Tau values are $0.82$, $0.77$, and $0.74$."
- L2-distortion: A distortion metric based on ℓ2 norms assessing how pairwise distances change after mapping. "-distortion"
- Latent directions: Axes in representation space associated with interpretable semantic or affective variation. "latent directions align with these classic dimensions."
- Latent space: The internal, typically high-dimensional representation space of a model. "low-dimensional latent space"
- Linear probe: A simple linear classifier trained on fixed representations to test decodability of information. "Linear probes trained on activations projected into the synthetic emotional latent space"
- Linear regression: A linear mapping used to align one latent space to another. "we use linear regression to align the emotional subspace derived from synthetic data with that derived from human-authored emotion classification datasets."
- Manifold (emotional manifold): A low-dimensional, curved subspace capturing emotional variation. "low-dimensional emotional manifold"
- Margin loss: A loss that enforces a minimum score difference between target and non-target classes. "The margin loss enforces that the logit for the target emotion token exceeds its synonyms by a margin (0.5)"
- Mean-pooling: Averaging token-level activations to obtain a sentence-level representation. "mean-pooling token activations."
- ML-AURA: A method to quantify neuron selectivity by treating neurons as threshold detectors and scoring via AUC-based metrics. "ML-AURA quantifies how selectively a neuron responds to a specific concept"
- One-vs-all: A classification setup where one class is contrasted against all other classes. "We apply ML-AURA in a one-vs-all setup for each emotion"
- Principal Component (PC1): The first principal axis from SVD/PCA capturing maximum variance. "PC1 strongly resembles a valence dimension."
- Probe accuracy: The performance of a linear probe trained on representations to predict labels. "high cross-domain probe accuracy"
- Rigid transformations: Transformations preserving distances and angles (e.g., rotations, reflections). "linear or rigid transformations"
- Sammon: Sammon mapping distortion; a metric evaluating preservation of pairwise distances in low-dimensional embeddings. "Sammon"
- Semantic consistency loss: A loss encouraging similarity between original and steered representations. "The semantic consistency loss combines cosine and distance between the original and shifted final-layer hidden states:"
- Spectral flatness: A measure indicating how uniform a spectrum is; used here to characterize alignment transformations. "spectral flatness and Frobenius norm values"
- Sigma-distortion: A distortion metric assessing proportional stability of relative distances after mapping. "-distortion"
- Spearman correlation: A rank-based correlation coefficient measuring monotonic association. "the average Spearman correlation in emotion rankings is $0.87$"
- Singular Value Decomposition (SVD): A matrix factorization that extracts orthogonal components capturing variance. "we apply singular value decomposition (SVD) to hidden state activations."
- Stress-1: A multidimensional scaling (MDS) stress measure quantifying embedding distortion. "Stress-1 below 0.2 as acceptable"
- Stress-2: An alternative MDS stress measure with a different normalization of residuals. "Stress-2"
- t-SNE: t-distributed Stochastic Neighbor Embedding; a method for visualizing high-dimensional data in 2D/3D. "a 2D t-SNE projection"
- Valence-Arousal-Dominance (VAD): A continuous emotion model with axes for pleasure, activation, and control. "valence-arousal-dominance (VAD) model"
- Weight decay: Regularization adding a penalty proportional to parameter magnitude during optimization. "weight decay "
Collections
Sign up for free to add this paper to one or more collections.