- The paper demonstrates that visual key-value tokens gradually build perceptual details, but artifact tokens later degrade performance.
- The study compares MLMs with standalone visual encoders, revealing inefficiencies in tasks like semantic segmentation.
- Interventions such as blocking input-agnostic tokens improve performance, underscoring the need to refine visual processing in MLMs.
Visual Representations inside the LLM
Introduction
The study of visual representations in Multimodal LLMs (MLMs) highlights the evolving understanding of how these models process visual information. Despite advancements, MLMs still exhibit limitations in handling perception-intensive tasks such as object localization, spatial reasoning, and semantic segmentation. This paper examines the flow and role of visual key-value tokens in prominent MLM architectures, including LLaVA-OneVision, Qwen2.5-VL, and Llama-3-LLaVA-NeXT, providing insights into their impact on the model's perceptual abilities.
Visual Token Processing and Representation
MLMs comprise a visual encoder coupled with a LLM. The visual encoder transforms image patches into representations that the LLM processes as key-value tokens. These tokens play a pivotal role in zero-shot task execution—segmentation, correspondence, and expression detection—demonstrating the encoded sufficiency of visual information despite MLMs' perceptual struggles.
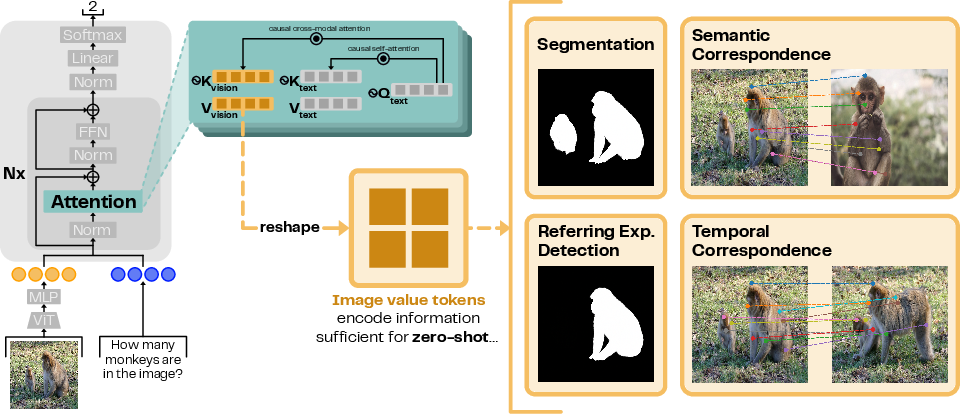
Figure 1: We study visual representations in the key-value cache within Mutimodal LLMs (MLMs), as they are uninfluenced by text (due to the causal nature of cross-modal attention) and directly contribute to the MLM output. Despite MLMs struggling on perception tasks, image value tokens still encode rich visual information.
Significantly, the distinction between input-dependent and input-agnostic key tokens becomes apparent in later LLM layers, with the latter introducing artifacts detrimental to perception performance.
Key Findings and Implications
The key-value mechanism is instrumental in visual information propagation across the MLM's layers, with image values incrementally building perceptual details before a sharp decline. This serves as an analogous observation to semantic layer activations in text-only transformers.
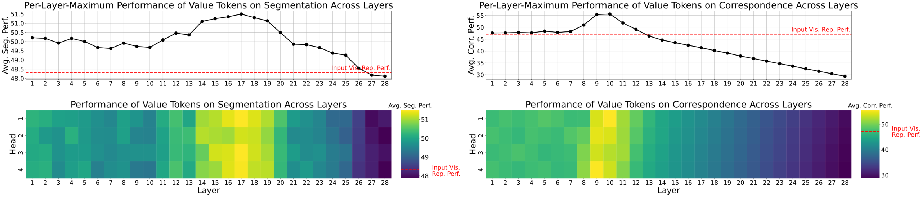
Figure 2: Performance of each image value (bottom), and maximum per-layer image value performance (top). On segmentation tasks, visual information builds gradually in the first two-thirds of the LLM, then drops steeply.
Comparison with Visual Encoders
While MLMs' language components enrich visual data, their performance on vision tasks like semantic correspondence sees a noticeable shortfall when compared to standalone visual encoders without MLM tuning, such as SigLIP. This contrast points to potential inefficiencies in MLMs' internal handling and refinement of visual features.
Careful examination of PCA visualizations of image keys and the identification of input-agnostic tokens further elucidates these inefficiencies.

Figure 3: PCA visualization of all image keys in LLaVA-OneVision 7B for two COCO images. The input-agnostic image keys displayed are nearly constant across different images.
Interventions and Scalability
Interventions to mitigate artifact introduction—such as blocking text queries to input-agnostic keys—yielded improved perceptual performance. Further, adding textual prefixes to image inputs allowed models to dynamically harness and enhance visual representation fine-tuned to task-specific needs, a process leveraging causal attention inherent in transformer architectures.
Conclusion
This exploration into MLMs' visual token representation provides a foundational understanding of their mechanistic limits in perceptual tasks. Despite technological strides, MLMs' perceptual potential is constricted by artifact-prone visual representations and their suboptimal integration into LLMs. Future work should focus on refining these visual processes, possibly through enhanced training paradigms and dynamic attention mechanisms that better capture and utilize visual information. These steps will considerably advance MLMs' capability to bridge the perceptual reasoning gap, with implications extending across varied AI applications.