VGGT-$Ω$
Abstract: Recent feed-forward reconstruction models, such as VGGT, have proven competitive with traditional optimization-based reconstructors while also providing geometry-aware features useful for other tasks. Here, we show that the quality of these models scales predictably with model and data size. We do so by introducing VGGT-$Ω$, which substantially improves reconstruction accuracy, efficiency, and capabilities for both static and dynamic scenes. To enable training this model at an unprecedented scale, we introduce architectural changes that improve training efficiency, a high-quality data annotation pipeline that supports dynamic scenes, and a self-supervised learning protocol. We simplify VGGT's architecture by using a single dense prediction head with multi-task supervision and removing the expensive high-resolution convolutional layers. We also use registers to aggregate scene information into a compact representation and introduce register attention, which restricts inter-frame information exchange to these registers, in part replacing global attention. In this way, during training, VGGT-$Ω$ uses only about 30% of the GPU memory of its predecessor, allowing us to train with 15x more supervised data than prior work and to leverage vast amounts of unlabeled video data. VGGT-$Ω$ achieves strong results for reconstruction of static and dynamic scenes across multiple benchmarks, for example, improving over the previous best camera estimation accuracy on Sintel by 77%. We also show that the learned registers can improve vision-language-action models and support alignment with language, suggesting that reconstruction can be a powerful and scalable proxy task for spatial understanding. Project Page: http://vggt-omega.github.io/




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to quickly turn ordinary videos into 3D “maps” of the scene, including where the camera was and how far away things are (depth). The new system is called VGGT‑Omega. It works on both still scenes (nothing moving) and dynamic scenes (people, cars, etc. moving), and it gets better as you give it more data and a bigger model—much like how larger LLMs improve with scale.
What questions did the authors ask?
They set out to answer a few simple questions:
- Can we build a fast “feed‑forward” 3D reconstructor that doesn’t need slow, old‑fashioned optimization steps?
- If we make the model bigger and feed it much more data, does its 3D accuracy predictably improve?
- Can we handle moving objects in videos so we can learn from tons of real Internet videos?
- Can we make the model more memory‑efficient so training it at huge scale is practical?
- Do the model’s internal features help with other tasks, like connecting vision to language and actions?
How does the method work? (Explained with simple ideas)
Think of the model as a very smart “scene reader”:
- It takes several frames from a video and turns each frame into many small pieces of information (called “tokens”), like breaking a picture into puzzle pieces the computer can reason about.
- It uses a transformer (a type of neural network that “pays attention” to important pieces) to mix information within each frame and across different frames.
Here are the key ideas they added or changed:
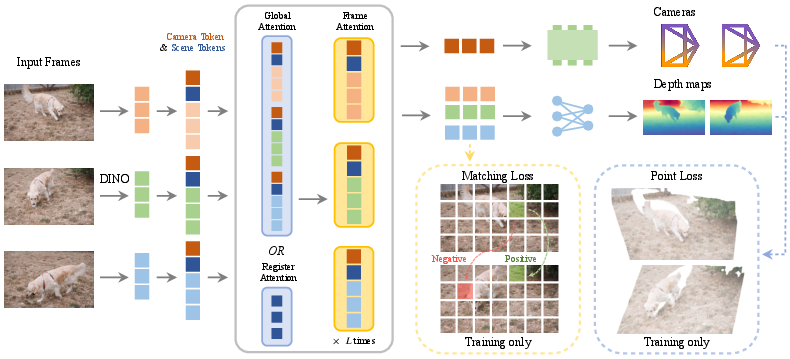
- Scene registers (special summary tokens): Imagine each frame also has a small set of “summary notes” that try to capture the big picture of the whole scene. The model learns these notes (called registers) and uses them to carry global scene info across frames.
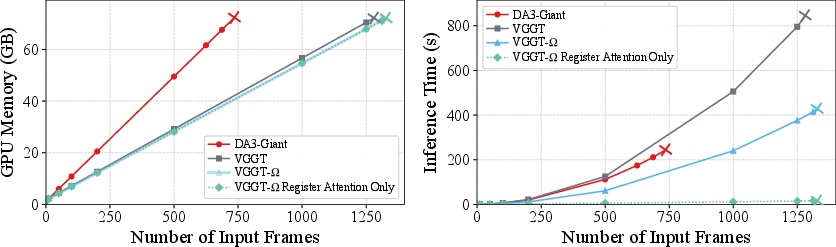
- Register attention (a faster way to share information): Normally, mixing info across all frames is expensive (every token looks at every other token). They introduce “register attention,” where only the summary notes talk to each other across frames. Then these notes pass the useful info back to each frame. It’s like having team captains meet to share strategies, then returning to coach their teams—much faster than having every player talk to every other player.
- Simpler output heads: The model predicts just two things directly: 1) depth maps (how far each pixel is), and 2) camera parameters (how the camera moved and its field of view). It still “learns” helpful extras like 3D points and matching features through training losses, but it doesn’t keep heavy extra prediction modules around. This saves a lot of memory.
- Lightweight depth upsampling: To turn coarse depth into full‑resolution depth with low memory, they replace heavy layers with a simple MLP (a small neural network) plus a “pixel shuffle” trick that neatly expands the image. Think of it as packing and unpacking information efficiently so you don’t have to carry big, heavy boxes.
- Multi‑task training without extra heads: They supervise depth, camera pose, 3D points, and feature matching, but only keep the small heads for depth and camera. You get the benefits of multi‑task learning without the memory cost.
- Self‑supervised learning at massive scale: They use a teacher‑student setup: the teacher is a slowly updated copy of the student. Both see the same frames with different random changes (color, blur, order). The student learns to match the teacher’s outputs. This lets the model learn from 18 million unlabeled videos. Picture a coach (teacher) and a player (student) watching the same game from different angles; the player trains to match the coach’s understanding.
- A big, careful data pipeline (including dynamic scenes):
- A vision‑LLM to toss out videos that are impossible to reconstruct (too blurry, watermarks, jump cuts).
- Detecting moving objects (like people, cars) so the system avoids using those regions when it shouldn’t.
- Building 3D with established tools, checking that depths agree across views (multi‑view consistency), and training a quality classifier to discard bad results.
- In the end, they gathered about 800,000 high‑quality labeled sequences from the web (roughly 200k dynamic, 600k static), and combined them with existing datasets for a total of about 4 million training sequences.
What did they find, and why is it important?
Main results, in simple terms:
- Better accuracy, both static and dynamic: Across six benchmarks, VGGT‑Omega beat previous methods, including ones that do slow optimization. On the challenging Sintel benchmark (dynamic scenes), it improved camera pose accuracy a lot: AUC@3° went from 22.5 to 40.0 (about 77% better). Depth accuracy also jumped (e.g., δ1.25 from 86.1% to 93.5%).
- Much faster: It’s about 50× faster than a popular optimization‑heavy method (MegaSaM) while being more accurate. Fast and accurate is a big deal when you want to process long videos or many cameras.
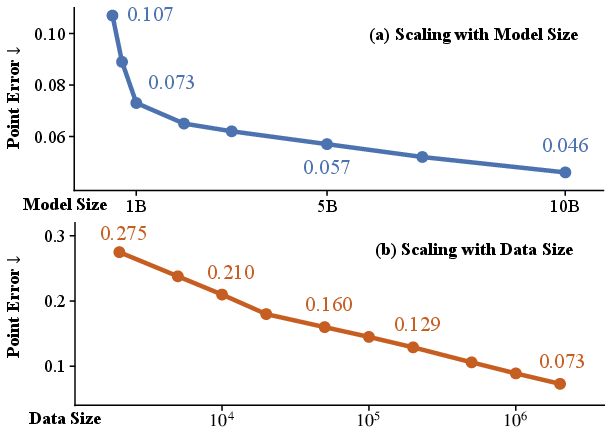
- Scales predictably: When they increased model size (up to 10 billion parameters) and training data (up to millions of sequences), performance kept improving in a smooth, predictable way. That’s a sign you can keep pushing scale for more gains, like we’ve seen with big LLMs.
- Big training efficiency boost: Thanks to register attention and simpler heads, training uses about 70% less GPU memory than before (only ~30% of the previous requirement). That makes huge‑scale training practical.
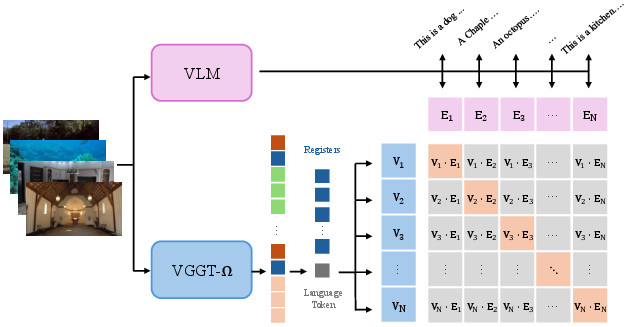
- Useful internal features: The learned scene registers carry global 3D knowledge that also helps with tasks connecting vision, language, and actions. In short, the model learns a strong sense of space that transfers to other AI systems.
Why does this matter?
- Better 3D understanding for everyday videos: Many real videos have moving objects. Being able to reconstruct these scenes accurately and fast opens the door to improved AR/VR, robotics, video editing, sports analysis, and more.
- A “foundation model” for 3D: The paper shows that scaling laws apply to 3D reconstruction too. That means we can treat 3D understanding more like a foundation capability: train big models on lots of data to get reliable, general‑purpose 3D skills.
- Practical at scale: Memory‑efficient design and a careful data pipeline let the researchers train on millions of sequences and tens of millions of unlabeled videos—key for building robust systems.
- Bridges to language and action: Because the model’s internal “scene notes” are so informative, they help other AI systems that need to connect what they see to what they read or do. This could improve embodied AI (robots), navigation, and multimedia assistants.
In one sentence
VGGT‑Omega is a faster, more accurate, and more scalable way to turn videos—including ones with moving objects—into 3D understanding, and its learned “sense of space” also helps other AI tasks that mix vision, language, and action.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to be actionable for follow-up research:
- Optimal use of register attention:
- How many global-attention layers can be replaced with register attention without loss, and where should they be placed? Explore learned routing/gating that adaptively chooses between full- and register-attention per layer and per input.
- Sensitivity to the number of registers per frame (currently 16): study accuracy/compute trade-offs, dynamic allocation, or shared registers across frames.
- Understanding and supervising registers:
- What information do registers encode (geometry, semantics, motion)? Provide interpretability analyses and diagnostic probes.
- Can lightweight, explicit supervision (e.g., language, object-level cues, scene graph targets) improve register utility and stability?
- Do registers provide persistent state for streaming/sequential processing? Evaluate temporal persistence and forgetting across long sequences.
- Camera model limitations and real-world effects:
- The model assumes centered principal point and no lens distortion; the data pipeline filters out high-distortion/zoom cases. Extend to non-centered principal point, skew, radial/tangential distortion, variable intrinsics, and zoom, and quantify benefits.
- Rolling-shutter and motion blur are not modeled; assess degradation and integrate rolling-shutter camera models or joint deblurring.
- Metric scale and calibration:
- Depth training uses relative scale; no metric scale guarantee. Investigate metricization via IMU/GPS priors, known-size object cues, or ground-plane constraints.
- No camera uncertainty estimates; develop calibrated uncertainty for camera and depth, and evaluate uncertainty calibration quality.
- Dynamic scene supervision and evaluation:
- Dynamic regions are largely excluded from dense supervision; the approach lacks explicit motion supervision. Create/curate datasets with dense 4D ground truth (depth in dynamic regions, scene flow, motion masks) and measure performance with 4D metrics (e.g., flow error, temporal consistency).
- No explicit motion segmentation or scene flow outputs; explore object-/part-level dynamic modeling, motion masks, or dynamic point/ray maps while retaining efficiency.
- Self-supervised learning (SSL) protocol clarity and robustness:
- Provide detailed ablations on the impact of each augmentation (frame reordering, masking), head freezing, EMA momentum, and unlabeled data volume/quality.
- Analyze teacher drift, collapse modes, and pseudo-label noise; introduce confidence-weighted distillation or consistency regularizers across temporal views.
- Architectural choices and ablations:
- Single-pass camera head vs iterative refinement: benchmark on extreme baselines/wide-FoV scenes; explore hybrid refinement with minimal overhead.
- MLP + pixel-shuffle head may introduce blockiness in distant/unbounded regions; quantify edge fidelity/thin structure preservation and test anti-aliasing/deblocking variants.
- Scalability beyond quadratic costs:
- Although register attention reduces cost, global attention is still quadratic in remaining layers. Investigate adaptive token pruning/merging, KV-caching, windowed/global hybrids, or fully linear-time scene memory while preserving accuracy.
- Evaluate causal/streaming variants with persistent state for very long videos (>10k frames) and measure latency/accuracy drift.
- Data pipeline biases and reproducibility:
- Heavy VLM pre-filtering and COLMAP-based quality filters may bias against hard cases (fast zoom, extreme motion, heavy blur, highly dynamic scenes). Quantify selection bias and its impact on OOD robustness; introduce targeted “hard case” training sets.
- Internal datasets and unlabeled videos are not publicly available; provide a public subset, detailed metadata, or synthetic proxies to enable reproducibility and fair comparison.
- Fairness of comparisons and contribution disentanglement:
- Many baselines are trained on far less data. Run controlled experiments with matched data/compute to isolate architectural gains from data scale gains.
- Provide scaling-law fits (exponents, variance) and compute-optimal analyses (model vs data scaling trade-offs) to guide resource allocation.
- Robustness and OOD generalization:
- Systematically evaluate on stress tests: low light, strong HDR, severe motion blur, repetitive/textureless scenes, specular/transparent materials, fisheye/ultra-wide optics, underwater turbidity, rain/snow/fog.
- Report failure modes and implement automatic reliability detectors (e.g., confidence thresholds, outlier scores) for deployment.
- Outputs for correspondence/tracking:
- Tracks/point maps are not explicitly predicted at inference, though supervised via losses. Quantify token-based correspondence quality vs explicit track heads and provide optional lightweight heads for tasks that need explicit tracks.
- Dynamic attention scheduling:
- Replace the fixed “25% register-attention” rule with input-adaptive scheduling based on measured sparsity/entropy of attention or parallax estimates, and quantify FLOP/accuracy improvements.
- Evaluation breadth:
- Complement AUC and depth metrics with 4D metrics (temporal depth consistency, scene flow), camera stability on long sequences, and robustness under degenerate motions (pure forward motion, low parallax).
- Include benchmarks with variable intrinsics, rolling shutter, and handheld stabilization to test real camera effects.
- Efficiency on commodity hardware:
- 10B models are impractical for many users. Explore knowledge distillation, pruning, quantization, LoRA, and MoE routing to retain accuracy at 200–500M scales; publish accuracy–latency–memory trade-off curves on consumer GPUs.
- Ethical, privacy, and licensing aspects:
- Large-scale mining of web videos raises privacy/copyright concerns. Document consent, anonymization, and licensing; release a datasheet with demographic/content breakdowns and discuss potential downstream harms.
- Release and reproducibility:
- Clarify plans for releasing code, weights, training recipes (including matching loss pair construction details), and data curation scripts to enable full reproduction of results.
- Multimodal and downstream integration:
- Claims about register utility for VLA/language alignment are promising but under-quantified. Provide standardized tasks and metrics (e.g., zero-shot spatial QA, embodied navigation with geometry priors), and test lightweight language supervision on registers.
- Integration with additional sensors:
- Explore fusion with IMU/LiDAR/depth sensors to improve metric scale, robustness in low-texture scenes, and resilience to dynamic occlusions, with benchmarks on sensor-fusion datasets.
- Occlusion reasoning:
- Current losses do not explicitly model occlusions. Incorporate occlusion-aware photometric/geometry consistency and evaluate improvements in dynamic and cluttered scenes.
- Data augmentation scope:
- Only 90° rotations and standard color jittering are used. Study continuous rotations, camera roll, photometric extremes, and realistic sensor noise models to improve invariance without harming geometric consistency.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be built today from the paper’s findings, methods, and engineering contributions.
Software and Media
- Real-time 3D-aware video editing and VFX (media/entertainment)
- Use fast feed-forward depth and camera trajectories for rotoscoping, relighting, object insertion, background replacement, and 3D-aware stabilization on consumer GPUs.
- Potential products: NLE plugins (Premiere/Resolve/Nuke) offering “Instant Depth + Camera Solve” from monocular clips.
- Dependencies/assumptions: Robustness may degrade on extreme motion blur, reflective/transparent surfaces; best results at ~512p–720p inputs unless models are distilled/optimized.
- Monocular 3D scanning for creators and e-commerce (software/retail)
- Turn short handheld videos into metric(ish) meshes/point clouds for product pages, room previews, and try-on scenes.
- Workflow: Phone capture → VGGT depth+pose → mesh fusion (TSDF/Poisson) → lightweight texture bake.
- Dependencies/assumptions: Absolute scale requires priors (e.g., known object size) or auxiliary sensors; challenging glossy/textureless items may need multi-view coverage.
- 3D-consistent video generation conditioning (media/AI-graphics)
- Use the “scene register tokens” and geometry outputs to condition or post-correct video diffusion models for fewer 3D artifacts (ghosting/duplication).
- Tools: A “Geometry ControlNet” variant that ingests VGGT depth/pose and scene tokens.
- Dependencies/assumptions: Requires access to model internals or adapters for popular video-gen models; training alignment needed.
AR/VR and Robotics
- Instant AR relocalization and occlusion (software/AR)
- Feed-forward pose+depth from a few frames enables stable AR anchoring and correct occlusions without full SLAM.
- Integration: Unity/Unreal plugin that exposes monocular depth, camera intrinsics/extrinsics per frame.
- Dependencies/assumptions: Persistent mapping still benefits from lightweight map fusion; mobile deployment needs distillation/quantization.
- Robotics perception booster via geometry-aware tokens (robotics)
- Plug geometry tokens/scene registers into VLA/LLM-policy stacks to improve spatial grounding for manipulation and navigation.
- Workflow: Front-end VGGT → tokens to policy backbone → better affordance detection and 3D-referenced language grounding.
- Dependencies/assumptions: Onboard compute or edge offload; safety validation under motion/lighting domain shifts.
Mapping, Inspection, and Operations
- Rapid site capture from drones/handhelds (construction, energy, mining, agriculture)
- Use fast, optimization-free reconstruction to triage inspections (cracks, clearance, progress tracking) when time or compute is limited.
- Workflow: Batch inference on collected video → coarse 3D → flag anomalies → optional later refinement (SfM/MVS) on flagged segments.
- Dependencies/assumptions: Wide-baseline scenes and dynamic objects handled well, but highly specular/transparent assets still hard; regulatory flight constraints remain.
- Claims, surveying, and property documentation (insurance/real estate/finance)
- Rapid 3D recon from walkthrough videos for claims assessment, floor-plan validation, and inventorying.
- Dependencies/assumptions: Scale calibration and quality control standards; privacy-safe handling of personally identifiable dynamic content.
Healthcare and Science
- Monocular endoscopy/surgical scene depth and camera estimation (healthcare)
- Provide per-frame depth and instrument-relative camera motion to assist navigation and tool tracking.
- Dependencies/assumptions: Requires domain-adapted fine-tuning and sterilized pipelines; reflectance/specularities common in endoscopy need augmentation.
Academic and Data Engineering
- Scalable dynamic-scene annotation pipelines (academia/industry R&D)
- Reuse the VLM pre-filtering + robust COLMAP stage + multi-view consistency + supervised filtering to curate millions of high-quality training samples.
- Tools: “AutoAnnotator” pipeline template; drop-in for institutional video corpora.
- Dependencies/assumptions: VLM prompts and class lists should be tuned to domain; careful privacy review for Internet-sourced data.
- Cost-effective dense prediction heads (ML engineering)
- Adopt the MLP + pixel-shuffle decoder to cut memory without accuracy loss in depth/segmentation networks.
- Dependencies/assumptions: Keep some low-res conv features to avoid blockiness on distant/unbounded regions.
Policy and Governance
- Procurement and evaluation guidelines for 3D/4D perception (public sector/standards bodies)
- Establish test protocols emphasizing dynamic scenes, strict camera AUC@3° thresholds, and multi-view depth consistency checks when certifying systems for public deployment (e.g., drones, public safety cameras).
- Dependencies/assumptions: Access to dynamic benchmarks; mandate privacy-preserving dynamic-mask handling for people/vehicles.
Daily Life
- Consumer apps for room scans and DIY filmmaking (consumer software)
- One-tap “3D room capture” and “pro camera motion” overlays for hobbyists.
- Dependencies/assumptions: On-device variants must be compressed; UX should signal confidence and failure cases (e.g., mirrors, glass).
Long-Term Applications
These applications are plausible with further research, scaling, and productization, building on the paper’s scaling laws, register attention, and dynamic-scene competence.
Embodied AI and Autonomy
- Feed-forward SLAM replacement with persistent scene tokens (robotics, AR)
- Causal processing that maintains compact registers as scene memory, enabling long-horizon mapping with linear-time updates.
- Dependencies/assumptions: Robustness under illumination/weather changes; calibration drift handling; formal safety guarantees.
- Monocular-first autonomy in cost-constrained platforms (automotive, drones)
- Reduce reliance on LiDAR by leveraging high-fidelity depth+pose from video where regulations and conditions allow.
- Dependencies/assumptions: Extensive validation in edge cases (night, rain, snow, glare); regulatory approval and redundancy requirements.
Planet-Scale 4D Mapping and Digital Twins
- City/country-scale dynamic reconstructions from public and fleet videos (mapping/urban planning)
- Build time-varying 3D maps that capture traffic patterns, construction progress, vegetation cycles.
- Dependencies/assumptions: Data rights, privacy-by-design (face/license blurring); distributed compute; bias/fairness audits across regions.
- Infrastructure monitoring at scale (energy/transportation)
- Continuous 4D digital twins of bridges, turbines, rails from routine inspection videos with automated change detection.
- Dependencies/assumptions: Precision calibration, controlled capture policies; integration with asset management systems.
Advanced Content Creation and Telepresence
- Commodity single-camera volumetric telepresence (communications/entertainment)
- Near-live 4D reconstructions of people/spaces from monocular webcams, enabling holographic calls and immersive streaming.
- Dependencies/assumptions: Strong priors for non-rigid humans; low-latency inference on edge; privacy/security controls.
- Fully 3D-consistent video generation/editing stacks (media/AI-graphics)
- Geometry-aware diffusion models natively guided by scene registers for editing with physical consistency (lighting, occlusion, parallax).
- Dependencies/assumptions: Co-training of generative models on geometry supervision at scale; standardized geometry control interfaces.
Foundation Models for Spatial Reasoning
- Multi-modal agents with native 3D grounding (education, assistive tech, enterprise)
- LLMs infused with scene registers for robust spatial language understanding (“put the mug left of the laptop,” “what’s behind the couch?”).
- Dependencies/assumptions: Alignment data that couples language with geometry; safety layers to avoid hallucinated affordances.
- Universal 3D pretraining standards and benchmarks (academia/standards)
- Community datasets and leaderboards emphasizing dynamic scenes, causal processing, and cross-domain generalization.
- Dependencies/assumptions: Shared annotation protocols; compute/resource-sharing initiatives.
Heritage, Archives, and Earth Sciences
- 4D reconstruction from historical/archival footage (culture/science)
- Recover changing structures (glaciers, coastlines, architecture) across decades of monocular video.
- Dependencies/assumptions: Domain adaptation for film artifacts; reference scale via known landmarks.
Governance and Sustainability
- Policy frameworks for 4D data rights and safety (public policy)
- Standards for consent, de-identification in reconstructed scenes, and environmental reporting for large-scale 3D model training.
- Dependencies/assumptions: Cross-jurisdictional privacy harmonization; lifecycle analyses for compute and storage.
- Green 3D AI through architecture/data efficiency (industry policy)
- Incentivize adoption of register attention and lighter decoders that reduce FLOPs/memory, decreasing carbon footprint of training/inference.
- Dependencies/assumptions: Transparent reporting of efficiency metrics; third-party audits.
Notes on Feasibility and Assumptions
- Model scale vs. deployment: The 10B variant offers the best accuracy but requires substantial compute; 200M–1B distilled variants are better suited for edge/mobile with quantization.
- Dynamic-scene handling: The approach predicts depth+camera and relies on learned priors rather than explicit motion masks; extreme non-rigid motion or severe specular/transparent surfaces remain challenging.
- Data dependence: Generalization quality reflects training distribution; domain-specific fine-tuning is recommended for medical, industrial, or nighttime driving.
- Legal/ethical constraints: Internet-sourced training and reconstruction of people/places must comply with privacy, consent, and data governance policies; consider on-device processing where possible.
- Safety-critical use: For autonomy/robotics, rigorous validation, redundancy, and certification are mandatory before replacing established pipelines.
Glossary
- AbsRel: Mean absolute relative error for depth estimation; lower values indicate better performance. "AbsRel is the mean absolute relative error (lower is better)."
- AUC: Area Under the Curve; here, measures accuracy of camera pose estimation across angular thresholds (higher is better). "The metric AUC is higher-is-better."
- aleatoric uncertainty: Data-dependent noise modeled by the network to weigh residuals in regression losses. "the depth loss uses aleatoric uncertainty and a gradient consistency term."
- alternating-attention: Transformer design that alternates between within-frame attention and across-frame attention. "VGGT uses alternating-attention~\cite{wang25vggt}, interleaving between frame-wise self-attention within each image and global self-attention across all images"
- bundle adjustment: Nonlinear optimization that jointly refines camera parameters and 3D structure from feature correspondences. "then run COLMAP~\cite{schonberger16structure-from-motion} for iterative bundle adjustment and filtering"
- camera extrinsics: Parameters describing a camera’s pose (rotation and translation) relative to a world coordinate system. "estimated both scene geometry and camera parameters (extrinsics and intrinsics) directly from images."
- camera intrinsics: Parameters describing a camera’s internal calibration (e.g., focal length, principal point). "estimated both scene geometry and camera parameters (extrinsics and intrinsics) directly from images."
- camera token: A special token appended per image that aggregates information for predicting that image’s camera parameters. "we also append one camera token "
- CatBoost: Gradient boosting library optimized for categorical features. "and CatBoost~\cite{prokhorenkova18catboost:}."
- COLMAP: Widely used Structure-from-Motion and Multi-View Stereo pipeline. "then run COLMAP~\cite{schonberger16structure-from-motion} for iterative bundle adjustment and filtering"
- δ_{1.25}: Depth metric; percentage of pixels with predicted-to-true depth ratio within 1.25 (higher is better). "The metric denotes the percentage of predicted depths within a factor of the ground truth (higher is better)"
- DINOv3: Self-supervised vision transformer pretraining method used to initialize the backbone. "We tokenize each image with a DINOv3-initialized vision transformer"
- Dense Prediction Transformer (DPT): Transformer-based architecture for dense prediction tasks like depth estimation. "In VGGT, all dense decoders are implemented with Dense Prediction Transformer (DPT) layers~\cite{ranftl21vision}."
- dynamic reconstruction: Recovering time-varying 3D scene geometry (4D) and camera motion from videos. "VGGT-$ supports reconstructing dynamic scenes, which, among other benefits, unlocks orders-of-magnitude more training data"</li> <li><strong>essential matrix</strong>: Matrix encoding relative rotation and translation between two calibrated views, used for pose estimation. "when RANSAC-based essential matrix estimation yields too few inliers"</li> <li><strong>exponential moving average</strong>: Momentum update that smooths parameter estimates over training iterations. "the teacher is updated via an exponential moving average of the student."</li> <li><strong>FLOPs</strong>: Floating-point operations; proxy for computational cost. "saving around 23\% FLOPs and 16\% memory in the backbone during training"</li> <li><strong>FSDP</strong>: Fully Sharded Data Parallel; memory-saving distributed training technique. "Techniques like FSDP or gradient checkpointing cannot eliminate the cost of storing these activations."</li> <li><strong>frame-wise attention</strong>: Self-attention applied independently within each frame’s tokens, without cross-frame mixing. "Frame-wise attention is similar, but applied independently to $z_iI_i$"</li> <li><strong>global attention</strong>: Self-attention across all tokens from all frames to aggregate multi-frame information. "Global attention is the standard attention layer applied to all tokens $z$"
- gradient checkpointing: Memory-saving technique that recomputes activations during backpropagation. "Techniques like FSDP or gradient checkpointing cannot eliminate the cost of storing these activations."
- Huber loss: Robust regression loss less sensitive to outliers than L2; compared against L1 here. "more stable than the Huber loss used in VGGT"
- inliers: Matches that are consistent with a geometric model (e.g., essential matrix) under RANSAC. "when RANSAC-based essential matrix estimation yields too few inliers"
- multi-view consistency: Cross-view validation ensuring depths/cameras agree when reprojected between views. "Multi-view consistency."
- multi-view geometry: Geometry relating multiple images of a scene; basis for SfM and stereo. "videos that are unlikely to be reconstructed using multi-view geometry."
- multi-view stereo: Estimation of dense depth from multiple calibrated images. "we estimate per-frame dense depth maps using patch-based multi-view stereo"
- non-rigid structure from motion: Recovering deforming 3D shapes and camera motion from images. "Classical non-rigid structure from motion~\cite{bregler00recovering, dai14a-simple,taylor10non-rigid} imposes hand-designed low-rank or local-rigidity constraints"
- parallax: Apparent displacement of scene points across views due to camera translation; crucial for depth estimation. "due to insufficient parallax"
- pixel-shuffle operator: Deterministic rearrangement that upsamples feature maps by reshaping channels into spatial resolution. "a single MLP followed by a pixel-shuffle operator."
- point maps: Per-pixel 3D coordinates (in a reference camera frame) corresponding to image pixels. "Point maps assign to each pixel the coordinates of the corresponding 3D point in the frame of the reference camera."
- power-law-like improvement: Empirical scaling trend where performance improves as a power law with model/data size. "we observe a consistent power-law-like improvement in reconstruction accuracy"
- principal point: The point where the optical axis intersects the image plane; often assumed at the image center. "we assume that the principal point is at the center of the image."
- quaternion: 4D representation of 3D rotation used for camera orientation. "the {rotation} quaternion "
- RANSAC: Robust estimation method that fits models by iteratively sampling and selecting inliers. "when RANSAC-based essential matrix estimation yields too few inliers"
- ray maps: Per-pixel camera rays (directions) used to decouple depth from camera parameters in some models. "Another option is to predict depth and ray maps~\cite{lin25depth}."
- register attention: Attention mechanism where only register tokens communicate across frames to reduce cost. "we therefore replace 25\% of the global attention layers with register attention"
- registers: Learnable tokens that aggregate global scene information across frames. "we also use registers to aggregate scene information into a compact representation"
- scene tokens: Register tokens intended to carry global information about the entire scene. "sixteen registers (scene tokens) ."
- self-supervised learning: Learning without labeled data by enforcing invariances or predictive consistency. "a self-supervised learning protocol."
- SfM: Structure-from-Motion; pipeline estimating camera motion and 3D structure from images. "traditional structure-from-motion (SfM) pipelines~\cite{hartley00multiple,snavely06photo,schonberger16structure-from-motion}."
- teacher-student strategy: Training scheme where a student network learns to match a teacher (EMA) network’s outputs. "we use a teacher-student strategy for self-supervised learning with unlabeled videos."
- tokenization: Converting images into a sequence of patch tokens for transformer processing. "We tokenize each image with a DINOv3-initialized vision transformer"
- unprojection: Mapping depth and camera parameters back to 3D point coordinates. "where denotes unprojection"
- ViT (Vision Transformer): Transformer model operating on image patches rather than pixels or convolutional features. "vision transformers (ViTs) spontaneously use a small number of image tokens to carry global information"
- Vision-LLM (VLM): Model that processes images and text jointly, often for classification or captioning. "We prompt a Vision-LLM (VLM) to discard videos that are unlikely to be reconstructed"
- Vision-Language-Action (VLA): Models integrating visual, language, and action modalities for embodied tasks. "they provide useful features for vision-language-action (VLA) models and language alignment."
Collections
Sign up for free to add this paper to one or more collections.