VGGT-SLAM 2.0: Real time Dense Feed-forward Scene Reconstruction
Abstract: We present VGGT-SLAM 2.0, a real time RGB feed-forward SLAM system which substantially improves upon VGGT-SLAM for incrementally aligning submaps created from VGGT. Firstly, we remove high-dimensional 15-degree-of-freedom drift and planar degeneracy from VGGT-SLAM by creating a new factor graph design while still addressing the reconstruction ambiguity of VGGT given unknown camera intrinsics. Secondly, by studying the attention layers of VGGT, we show that one of the layers is well suited to assist in image retrieval verification for free without additional training, which enables both rejecting false positive matches and allows for completing more loop closures. Finally, we conduct a suite of experiments which includes showing VGGT-SLAM 2.0 can easily be adapted for open-set object detection and demonstrating real time performance while running online onboard a ground robot using a Jetson Thor. We also test in environments ranging from cluttered indoor apartments and office scenes to a 4,200 square foot barn, and we also demonstrate VGGT-SLAM 2.0 achieves the highest accuracy on the TUM dataset with about 23 percent less pose error than VGGT-SLAM. Code will be released upon publication.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces VGGT-SLAM 2.0, a faster and more stable way for a robot (or phone) with a single RGB camera to build a 3D map of its surroundings while figuring out where the camera is in that map. This is the classic SLAM task: Simultaneous Localization And Mapping. The system uses a modern AI vision model called VGGT to turn regular images into a dense 3D point cloud, even when the camera’s exact settings (like lens details) aren’t known ahead of time.
What questions does the paper try to answer?
To keep things simple, the paper focuses on three big questions:
- How can we stitch together many small 3D maps (called submaps) made by VGGT into one big, accurate map without the map bending or stretching in weird ways?
- How can we tell if two images from far apart in time show the same place (a “loop closure”), so we can fix and improve the map?
- Can this mapping system run in real time and also be used to find objects a user asks for (like “find the backpack”) without being trained specifically for those objects?
How does the system work?
Think of making a big 3D map like building a giant puzzle:
- VGGT can process only a limited number of images at once, so the system builds several small puzzles (submaps), each from a short chunk of the video.
- These submaps overlap: the last image of one is the first image of the next. That overlapping image is the “anchor” that helps align the puzzles correctly.
Here are the key ideas, explained in everyday language:
- Submaps and overlapping frames:
- Each submap is a short sequence of images turned into a 3D chunk.
- Two neighboring submaps share the same real camera image. The system insists that these overlapping frames have the same position and direction (rotation) and the same camera settings (calibration). Then, it only solves for the scale (how “big” the reconstruction is), which is safer and more stable than trying to fix everything at once.
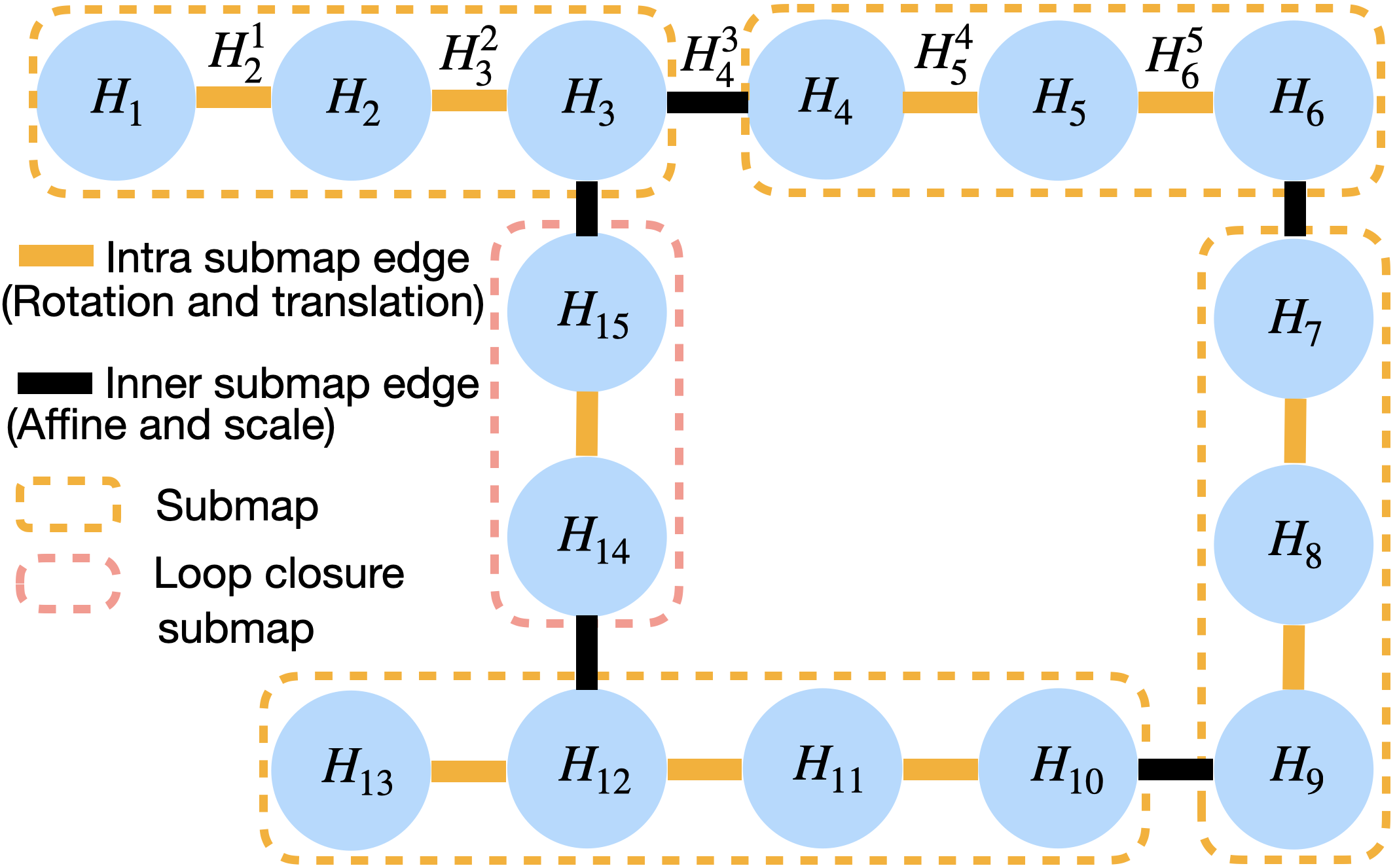
- Factor graph (a web of relationships):
- Imagine a web where every node is a key image (keyframe), and edges connect frames that should line up.
- Inside a submap, edges adjust rotation and translation (where you are and which way you’re facing).
- Between overlapping frames from different submaps, edges adjust camera calibration and scale so the shared frame is identical in both submaps.
- This design greatly reduces “drift” (the map slowly warping or sliding) and avoids failures when the scene is mostly flat (like walls or floors), a common problem.
- Loop closures (recognizing places you’ve been before):
- The system uses an image retrieval tool (SALAD) to find past frames that look similar to the current frame. If they match, it creates a “loop closure” that improves the whole map.
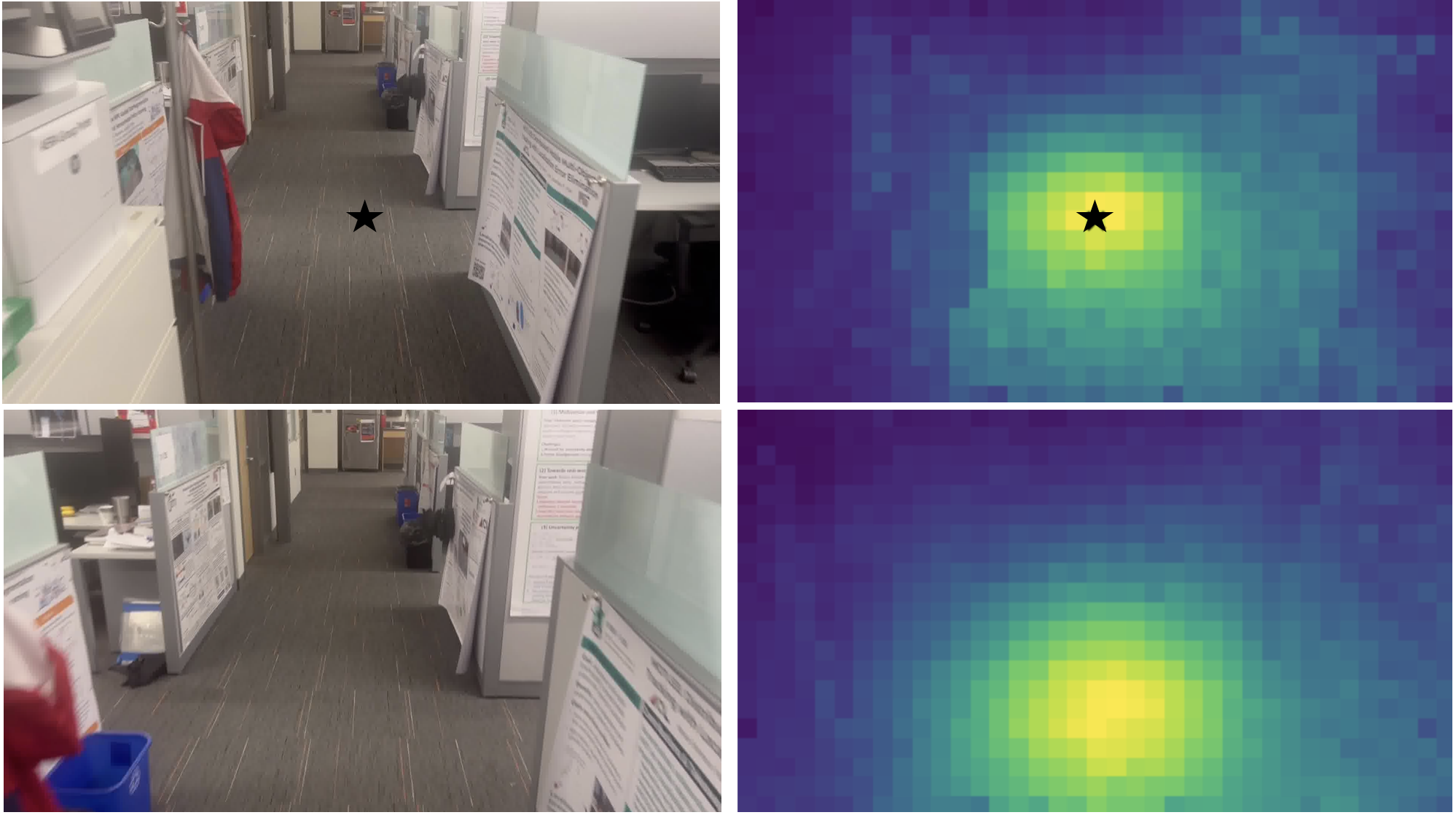
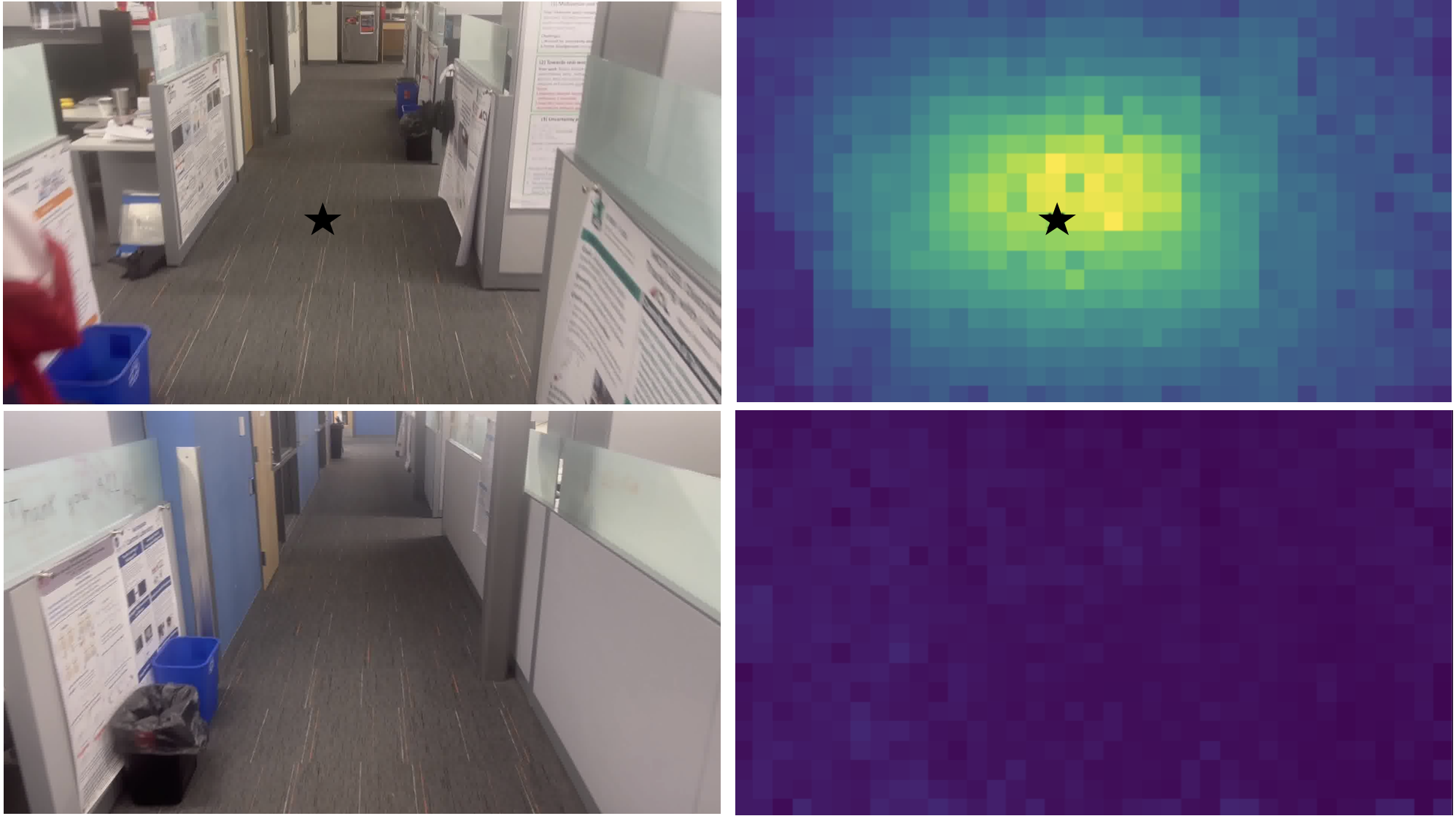
- To avoid false matches (like two different office cubicles that look alike), the authors discovered that a specific “attention layer” inside VGGT (layer 22) behaves like a spotlight: it shines on corresponding parts in the two images if they truly overlap. They turn this into a simple score to verify matches without extra training.
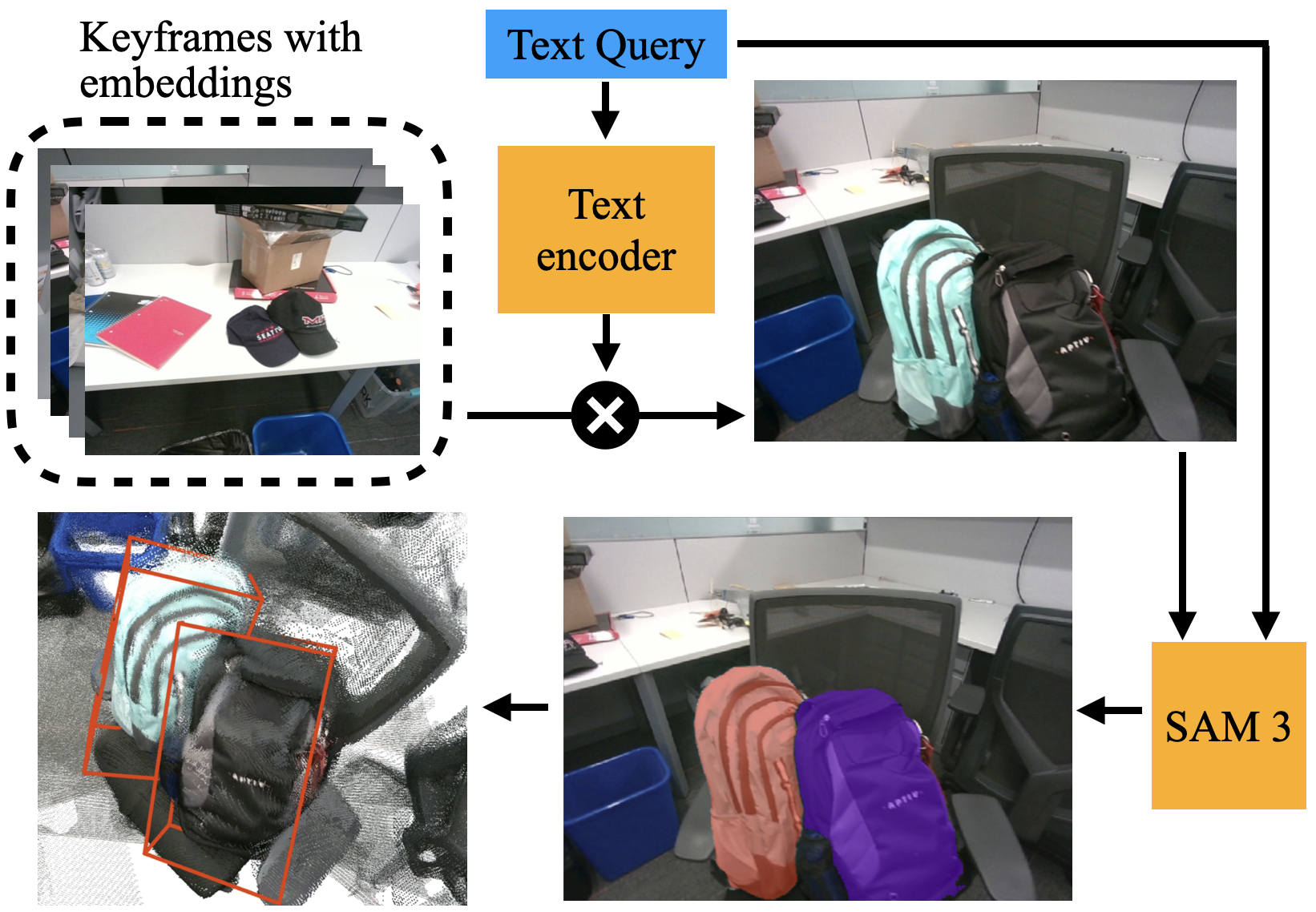
- Open-set object detection (finding things by name):
- The system attaches a text-image model (CLIP) and a segmentation tool (SAM 3).
- When you type a text query (like “backpack”), the system picks the best frame to look at, segments the object in 2D, and then projects those pixels into the 3D map to draw a 3D box around the object.
What did they find, and why does it matter?
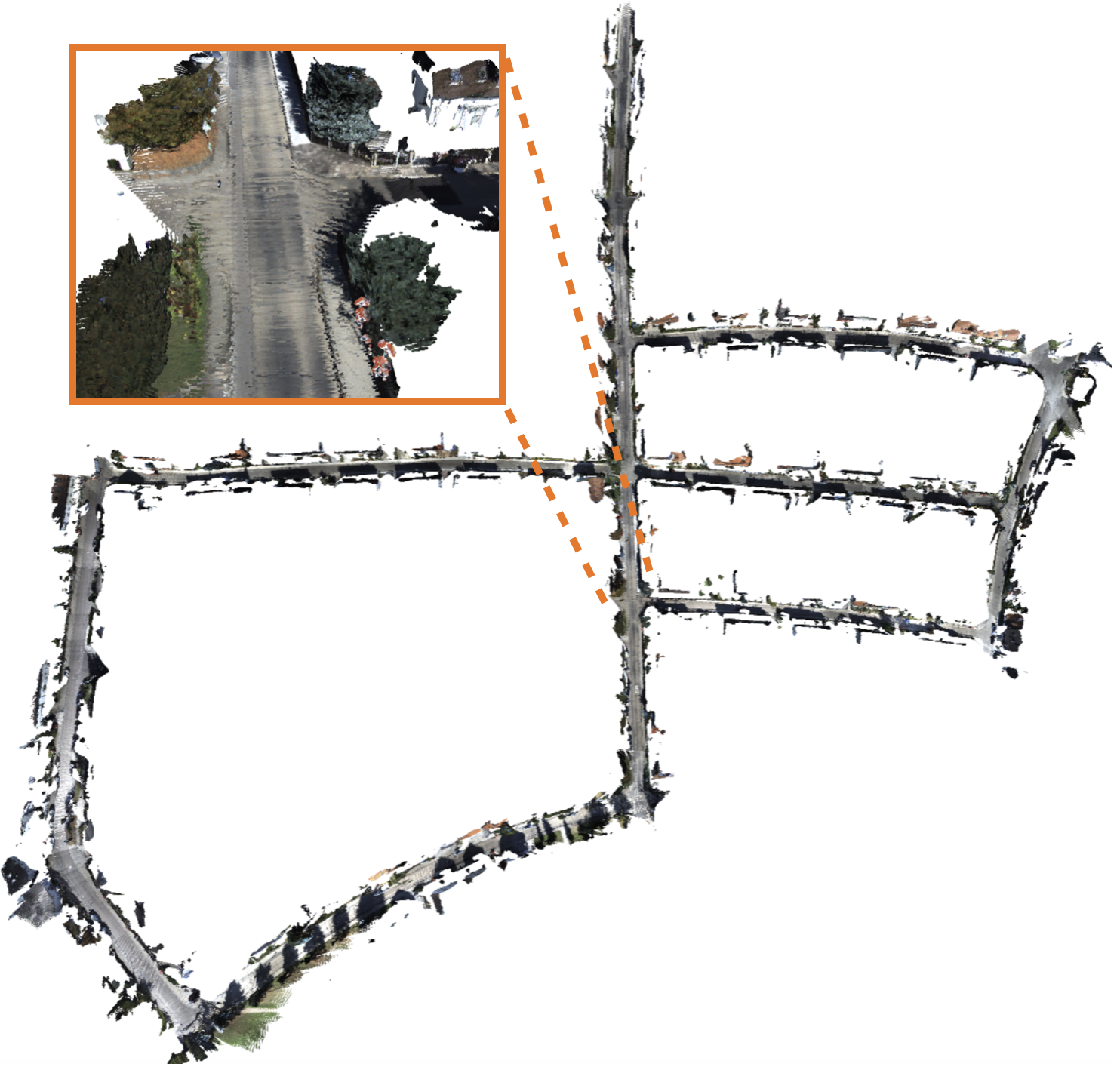
The authors tested VGGT-SLAM 2.0 in many places: apartments, offices, a big barn, and driving sequences.
Main results:
- More accurate mapping: On the TUM RGB-D benchmark, VGGT-SLAM 2.0 had about 23% less error in camera poses than the previous VGGT-SLAM, and it beat other recent learning-based methods.
- Less drift and more reliable closures: The new alignment strategy (same pose/calibration for overlapping frames + solve for scale) avoids the map bending badly before loop closures. Using VGGT’s attention layer to verify matches reduces false positives and increases the number of helpful loop closures.
- Real-time performance: It runs at about 8 frames per second on a desktop GPU and 3.5 frames per second on a Jetson Thor computer mounted on a robot—good enough for online mapping.
- Flexible and practical: The system easily supports open-set object search. For example, you can ask for “glasses” or “tractor,” and it draws a 3D box around the found object, even though it wasn’t specifically trained for those items.
Why this is important:
- You don’t need to know the camera’s exact calibration beforehand, which makes the system easier to use with phones or simple robot cameras.
- The map is dense and colorful (RGB point clouds), which is handy for robots navigating, inspecting rooms, or for AR/VR applications.
- The loop-closure verification trick is smart and cheap: it reuses VGGT’s internal understanding to avoid bad matches without training another model.
What’s the impact and what could come next?
VGGT-SLAM 2.0 lowers the barrier to getting high-quality 3D maps from regular video. That’s useful for:
- Home robots that need to understand and search their environment.
- Industrial robots and drones mapping large spaces.
- AR/VR apps that need accurate, detailed reconstructions.
- Anyone wanting quick 3D maps without complex calibration or heavy engineering.
Because VGGT-SLAM 2.0 doesn’t require extra training, future improvements to VGGT (like faster or more robust versions) can plug in directly. The authors note some limits—like failures in very plain scenes (e.g., large white walls) and that they optimize poses rather than every 3D point—but their design makes SLAM simpler, more stable, and more practical across many environments.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise list of the key knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Lack of theoretical guarantees that enforcing identical rotation/translation/calibration for overlapping frames fully removes planar degeneracies and high-dimensional drift across diverse scene geometries; a formal analysis or proofs are missing.
- No quantitative evaluation isolating the impact of the new factor-graph design (intra vs. inner edges) on drift reduction and failure rates, beyond qualitative figures; ablation studies on edge types and weighting are needed.
- Scale estimation via median ratios of corresponding 3D point distances (after calibration normalization) is heuristic; the bias/variance, robustness to low depth variation, and behavior under noisy/confident depth masks remain uncharacterized.
- The method does not estimate metric scale, limiting downstream robotics tasks requiring physically meaningful scale; integrating scale sources (IMU, GNSS, object-size priors, floor-height priors) is unexplored.
- Calibration handling is local (only enforced identical for overlapping frames) and does not jointly estimate consistent intrinsics across all frames/submaps; global intrinsics synchronization and time-varying intrinsics (e.g., smartphone zoom, rolling shutter) are not addressed.
- Backend optimization is exclusively over pose-level variables and homographies (on ); point-level refinement, joint optimization of 3D points, and robust correspondence modeling are omitted, leading to persistent misalignment artifacts in challenging scenes.
- Uncertainty modeling is absent: VGGT outputs (poses, intrinsics, depths) are treated as deterministic, with no covariance estimates or robust loss functions; factor weights and noise models are unspecified and not validated.
- The reliance on VGGT attention layer 22 for retrieval verification is empirical; no theoretical justification, cross-architecture generalization, or large-scale cross-dataset validation exists to confirm its reliability under viewpoint changes, illumination shifts, occlusions, and texture scarcity.
- Retrieval verification thresholds (e.g., ≥ 0.85, “top 25%” pooling in the score) are heuristic and not systematically tuned or stress-tested across datasets; sensitivity analysis and calibration procedures are missing.
- Computational overhead of verification is underreported: verification requires VGGT runs on loop-closure pairs; a detailed breakdown of verification cost and its trade-offs with retrieval recall/precision is absent.
- Inconsistent claims about SALAD “threshold relaxation”: the paper states 0.95 is “more relaxed” than 0.80, which is contradictory; precise definitions and controlled comparisons of retrieval threshold settings and their effects are needed.
- Loop-closure evaluation is limited (three Clio scenes and one LaMAR subset) and lacks comprehensive metrics (precision/recall, false-positive rates, ROC curves) at scale; comparisons to other verification strategies (geometric checks, RANSAC) are missing.
- Kitti results are qualitative only; quantitative odometry metrics (e.g., KITTI odometry benchmark scores) and failure mode characterization on long outdoor sequences are not provided.
- Dynamic-scene robustness is not studied; moving objects, pedestrians, and vehicles can degrade feed-forward reconstructions—no experiments or extensions (e.g., motion segmentation, dynamic masking) are presented.
- Low-texture failure modes (e.g., plain walls) are acknowledged, but recovery mechanisms (lost-tracking modules, adaptive keyframe insertion, fusion with inertial cues) are not implemented or evaluated.
- Submap size selection is fixed (e.g., 16/32) without adaptive strategies; the impact of submap size on drift, loop-closure frequency, accuracy, and runtime is not analyzed.
- The “first frame” dependence is identified but unresolved: methods for robustly selecting or re-anchoring the first frame to improve scale estimation and reduce VGGT failures are not provided or tested.
- Rolling-shutter effects, lens distortion models beyond simple pinhole intrinsics, and stabilization artifacts (common in smartphones) are not modeled; their impact on calibration alignment and reconstruction quality is unknown.
- Scalability limits (memory footprint, graph size growth, optimization time) for very large maps (thousands of keyframes) are not quantified; strategies for hierarchical/global synchronization or map partitioning are absent.
- Dense map quality (completeness, noise, fidelity) is not benchmarked against alternatives (Gaussian splatting, NeRF-based reconstructions); quantitative map metrics (point density, coverage, alignment error) are missing.
- Open-set 3D object detection is demonstrated qualitatively only; quantitative evaluation (IoU of 3D boxes, localization error, success rates, false positives) and multi-view fusion of masks are unexplored.
- The semantics pipeline uses single-frame segmentation via SAM 3 and CLIP matching; multi-frame semantic consistency, temporal instance tracking, disambiguation among similar instances, and failure handling (e.g., mis-segmentation) are not addressed.
- Integration of additional sensors (IMU, GNSS) for robustness and functionality (e.g., metric scale, drift control) is not explored, despite citing relevant works; a unified multi-sensor VGGT-SLAM 2.0 variant remains an open direction.
- Generalization to other Geometric Foundation Models (MASt3R, DUSt3R, CUT3R) is asserted as plug-and-play but not empirically validated; attention-layer verification behavior and factor-graph compatibility across models are untested.
- Reproducibility gaps: code is “to be released upon publication,” and several parameters (factor weights, robust losses, exact graph configuration) lack detailed reporting; end-to-end pipelines and datasets for replication are limited.
Glossary
- Absolute trajectory error (ATE): A standard SLAM metric quantifying the difference between estimated and ground-truth camera trajectories, often reported as RMSE in meters. "Root mean square error~(RMSE) of Absolute trajectory error (ATE (m)) on TUM RGB-D~\cite{Sturm12iros-TUM-RGB-D}."
- Affine: The linear (non-projective) part of a transformation that can model camera calibration and shear; in this paper it refers to the calibration-related degrees of freedom within a homography. "The homography matrix has 15 degrees of freedom: 3 for translation, 3 for rotation, 1 for scale, 5 for affine (i.e., camera calibration), and 3 for projective components~\cite{Hartley04book}."
- Attention matrix: The matrix of attention scores in a transformer indicating how strongly tokens attend to each other; used here to identify image correspondences. "we visualize the attention matrix of a selected key token (shown with a black star), with respect to all other query tokens."
- Back projection: The operation of mapping pixel coordinates and depths back to 3D points in the camera frame using intrinsics. "are computed through back projection using only and ."
- Camera intrinsics: The internal parameters of a camera (e.g., focal length, principal point) required to interpret image measurements geometrically. "while still addressing the reconstruction ambiguity of VGGT given unknown camera intrinsics."
- Cosine similarity: A measure of similarity between embedding vectors based on the cosine of the angle between them; used for text-image retrieval. "locate the corresponding keyframe with the highest cosine similarity."
- Factor graph: A bipartite graph representing variables and constraints for probabilistic inference and optimization; used to structure SLAM optimization. "the factor graph in VGGT-SLAM only attempts to estimate the homography between submaps."
- Gaussian Splatting: A scene representation and rendering technique using 3D Gaussian primitives to approximate surfaces and appearance. "enable Gaussian Splatting~\cite{Kerbl23Ttog-GaussianSplatting} reconstructions~\cite{Chen24arxiv-pref3r}."
- Geometric foundation models (GFM): Large, feed-forward models trained to perform geometric vision tasks like multi-view reconstruction directly from images. "there has been a paradigm shift towards using Geometric foundation models (GFM) for SLAM."
- GTSAM: A library for factor graph optimization widely used in robotics and vision, supporting manifold-based solvers. "The optimization solver has since been added to the official GTSAM release, making installation simpler with just a pip install."
- Homography: A projective transformation relating points between views or coordinate frames; here a 4×4 matrix mapping 3D points between frames. "The homography matrix which expresses the relationship between corresponding points is:"
- Homogenous coordinates: A representation of points that enables projective transformations via linear algebra by augmenting with an extra coordinate. "we use overloaded notation such that is in homogenous coordinates when multiplied by a homography."
- Image retrieval verification: A step that confirms whether a candidate retrieved image truly overlaps the query image, reducing false positives. "assist in image retrieval verification for free without additional training, which enables both rejecting false positive matches and allows for completing more loop closures."
- Jetson Thor: An embedded NVIDIA compute platform used for onboard, real-time robotics processing. "demonstrating real time performance while running online onboard a ground robot using a Jetson Thor."
- Keyframe: A selected frame used as a node in the map/graph that anchors optimization and storage for SLAM. "All submaps have keyframes, except for the loop closure submaps (\Cref{sec:loop_closures}) which have 2 frames."
- Loop closure: The detection and use of revisiting a previously seen place to reduce drift and enforce global consistency. "allows for completing more loop closures."
- Open-set object detection: Detecting objects specified by arbitrary text queries without a fixed label set, leveraging multimodal models. "VGGT-SLAM 2.0 can easily be adapted for open-set object detection."
- Oriented bounding box: A 3D bounding box aligned with the object’s orientation, not restricted to axis alignment. "showing estimated 3D oriented bounding boxes and SAM 3 segmentation masks on the queried keyframe."
- Overlapping frames: The shared image between consecutive submaps used to align and stitch local reconstructions. "The overlapping frame is a common image between submaps which is used for alignment."
- Perception Encoder: A CLIP-based vision encoder used to produce image embeddings for semantic retrieval tasks. "we compute an image embedding vector using the Perception Encoder~\cite{Bolya25neurips-perceptionEncoder} CLIP model."
- Pose graph: A graph whose nodes are camera poses and edges are relative constraints; optimized to produce globally consistent trajectories. "uses a lightweight model for two-view association combined with a $$ pose graph."</li> <li><strong>Projective ambiguity</strong>: The ambiguity in reconstruction arising when only projective information is available, exceeding similarity ambiguity. "higher dimensional projective ambiguity."</li> <li><strong>Projective components</strong>: The degrees of freedom in a homography beyond similarity and affine parts that capture general projective transformations. "and 3 for projective components~\cite{Hartley04book}."</li> <li><strong>Recall@1</strong>: Retrieval metric indicating the percentage of queries whose top-ranked result is correct. "Recall@1 scores on LaMAR HGE phone dataset showing improved recall with our proposed retrieval verification."</li> <li><strong>SALAD</strong>: A visual place recognition method based on optimal transport aggregation used for image retrieval. "VGGT-SLAM and VGGT-Long~\cite{Deng25arxiv-vggtlong} for example both use SALAD~\cite{Izquierdo24cvpr-SALAD} to retrieve frames."</li> <li><strong>Scale factor</strong>: A scalar parameter resolving relative scale between submaps when absolute scale is unknown. "We then solve for the scale factor, $s$."</li> <li><strong>Similarity transformation</strong>: A transformation composed of rotation, translation, and uniform scaling. "simply aligning the submaps with a similarity transformation (rotation, translation, and scale) is not always sufficient"</li> <li><strong>SL(4) manifold</strong>: The Lie group of 4×4 real matrices with unit determinant; used here as the optimization domain for projective homographies. "allows for factor graph optimization on the manifold~\cite{Maggio25neurips-VGGT-SLAM}."</li> <li><strong>Submap</strong>: A local set of frames processed together by VGGT and later aligned into a global map. "To create a submap, $S_iIKTDC$."
Practical Applications
Immediate Applications
Below are concrete, deployable uses that can be realized now by leveraging VGGT‑SLAM 2.0’s contributions (reduced drift and planar degeneracy via new factor-graph design, attention-based loop-closure verification without training, uncalibrated RGB operation, and real-time performance with open-set 3D querying).
- Mobile robotics: robust indoor mapping and navigation with uncalibrated cameras (Robotics)
- Workflow: Run VGGT‑SLAM 2.0 on-board AMRs or quadrupeds in offices/warehouses to build dense maps, then localize and plan on them. Use the attention-based loop-closure verification to avoid false positives in repetitive layouts (e.g., similar cubicles/aisles).
- Tools/products: ROS 2 node wrapping VGGT‑SLAM 2.0 and GTSAM SL(4) solver (pip-installable), Jetson-ready container.
- Assumptions/dependencies: GPU (e.g., Jetson Thor-class) for real-time; sufficient scene texture; moderate speed to match 3–8 FPS; static or quasi-static scenes.
- On-device facility mapping and asset localization using a phone (Software, Facilities/Construction)
- Workflow: Walk-through capture with a smartphone; generate dense RGB point clouds without prior calibration; search “fire extinguisher/exit sign” via open-set text queries to get 3D bounding boxes.
- Tools/products: Mobile capture app + cloud/offline processing; CLIP + SAM 3 + VGGT‑SLAM 2.0 pipeline.
- Assumptions/dependencies: Good coverage/overlap; CLIP text prompts aligned to target objects; SAM 3 segmentation quality; privacy-compliant storage.
- Warehouse inventory and loss prevention audits (Retail, Logistics)
- Workflow: Periodic cart/robot sweeps with uncalibrated RGB; open-set 3D search for SKUs (“pallet jack”, “carton”, “damaged box”), verify placement compliance.
- Tools/products: Robot SKU-audit dashboard with 3D semantic search and loop-closure verification to handle repetitive aisles.
- Assumptions/dependencies: Adequate lighting/texture; SKU text prompts aligned with CLIP vocabulary; controlled robot speed.
- Real estate and property documentation (Real estate, Insurance/Finance)
- Workflow: Create dense indoor scans from a quick walk-through; generate searchable 3D maps to verify fixtures/furnishings; expedite claims or underwriting inspections.
- Tools/products: Agent/adjuster app for rapid 3D capture; web viewer with “find: smoke detector/handrail” queries.
- Assumptions/dependencies: Coverage of all rooms; user privacy/PII handling; legal consent for 3D scans.
- Security/forensics scene capture and evidence triage (Public safety)
- Workflow: First responders scan a scene; later query “knife”, “backpack”, “phone” to obtain precise 3D locations and bounding boxes for documentation.
- Tools/products: Field kit (phone + laptop/edge GPU); chain-of-custody export of map + query logs.
- Assumptions/dependencies: Scene relatively static during capture; privacy and evidentiary standards; compute availability.
- AR/VR-ready dense mapping for interactive experiences (Media/AR/VR)
- Workflow: Fast uncalibrated RGB scanning of rooms to generate dense reconstructions suitable for occlusion and physics; open-set queries to anchor content to objects (“place AR note on the backpack”).
- Tools/products: Content creation plugin that ingests VGGT‑SLAM 2.0 maps; object-anchoring via 3D bounding boxes.
- Assumptions/dependencies: Sufficient map density for occlusion; runtime conversion to target engines; lighting robustness.
- Education and research labs: teach SLAM with modern GFMs (Academia)
- Workflow: Use the open-source code and GTSAM SL(4) optimizer to teach factor graphs, submap alignment, and loop-closure verification from attention.
- Tools/products: Course labs, tutorials, benchmark scripts (TUM, KITTI).
- Assumptions/dependencies: GPU access; datasets with textured scenes.
- Robust loop-closure verification module for existing VPR pipelines (Software)
- Workflow: Insert the “layer-22 attention” verification stage after SALAD/NetVLAD retrieval to reject false positives and improve Recall@1.
- Tools/products: Lightweight verification microservice exposing α_match; drop-in to existing SLAM/VPR stacks.
- Assumptions/dependencies: Access to VGGT attention tokens; candidate pairs from a retrieval engine.
- Construction progress snapshots and punch-list support (Construction)
- Workflow: Frequent RGB scans to maintain a dense, navigable 3D map; open-set search for “ladder”, “missing guardrail”, “fire stop” for compliance checks.
- Tools/products: Field tablet app with text-to-3D search over time-stamped maps.
- Assumptions/dependencies: Scene coverage; object visibility; text query specificity.
- Agricultural indoor asset mapping (Agriculture)
- Workflow: Map barns/outbuildings using a phone or robot, then query “tractor”, “baler”, “generator” to locate and inventory assets.
- Tools/products: Farm asset inventory portal with 3D search; outdoor/indoor hybrid runs for large footprints.
- Assumptions/dependencies: Adequate overlap; object visibility; outdoor sequences may still challenge scale/drift.
- Hospital/clinic space digitization and asset findability (Healthcare)
- Workflow: Generate dense maps of corridors/wards with uncalibrated RGB; query “IV pole”, “defibrillator” for quick retrieval.
- Tools/products: Facilities dashboard tied to clinical operations.
- Assumptions/dependencies: Privacy compliance (PHI, staff/public); restricted areas; moving people introduce dynamics.
- Developer SDK for semantic 3D search (Software)
- Workflow: Expose APIs that accept a text prompt and return a 3D bounding box and confidence; integrate into internal tools (QA, support, ops).
- Tools/products: SDK wrapping CLIP+SAM 3+VGGT‑SLAM 2.0; Docker images and reference pipelines.
- Assumptions/dependencies: GPU for inference; text queries aligned with training distribution; cache and storage for submaps/keyframes.
Long-Term Applications
The following opportunities require further research, scaling, or productization (e.g., handling dynamics, higher FPS on edge, broader outdoor robustness, privacy/policy frameworks).
- Multi-robot collaborative dense mapping with uncalibrated cameras (Robotics)
- Vision: Robots exchange submaps and align overlapping frames using the calibration-consistency+scale scheme; attention-based verification guards against cross-robot false loop closures.
- Dependencies: Cross-device time/pose priors, comms bandwidth, map merge and conflict resolution, security.
- Parking-garage/indoor valet navigation without pre-calibration (Automotive)
- Vision: Vehicle performs uncalibrated RGB mapping and localization in feature-sparse structures, leveraging reduced planar degeneracy and robust loop closures.
- Dependencies: Higher FPS and robustness at speed; integration with wheel odometry/IMU (e.g., MASt3R-Fusion-like); lighting extremes.
- Assistive AR glasses that can “find my…” in 3D (Consumer, Healthcare)
- Vision: Wearable device maintains a persistent dense map of the home/clinic and supports real-time open-set 3D queries (“glasses”, “keys”).
- Dependencies: On-device or near-edge acceleration; long-term map persistence/updates; privacy and consent management.
- Enterprise digital twin with semantic 3D search at building scale (Facilities, Energy/Industrial)
- Vision: Continuous scanning populates a searchable 3D twin (“valve”, “gauge”, “spill kit”) for operations and safety workflows.
- Dependencies: Large-scale map management, change detection, safety certifications, integration with CMMS/EAM.
- Emergency response: rapid indoor mapping from bodycams with object-of-interest queries (Public safety, Policy)
- Vision: Units stream monocular RGB; command center gets an evolving 3D map and can query “exit”, “extinguisher”, “victim’s backpack”.
- Dependencies: Real-time edge/cloud pipeline; handling motion blur/dynamics; strict policies for storage, access, and redaction.
- Dynamic-scene feed-forward SLAM (e.g., people, moving objects) (Robotics, Software)
- Vision: Combine VGGT‑SLAM 2.0 with dynamic-scene GFMs (e.g., MegaSAM, TTT3R) and point-level optimization to maintain consistent maps in crowded spaces.
- Dependencies: Runtime and memory budget; reliable motion segmentation; tighter back-end optimization beyond pose-only.
- High-speed embedded deployments (drones, autonomous floor scrubbers) (Robotics)
- Vision: 20–30 FPS dense SLAM on edge SoCs enabling fast flight/drive; attention loop-closure verification keeps repetitive environments stable.
- Dependencies: Lighter/faster VGGT variants; hardware acceleration; robust keyframe selection; power/battery constraints.
- Standardization and policy for consumer 3D home scans (Policy, Finance/Insurance)
- Vision: Guidelines for consent, retention, and usage of dense indoor maps for claims, underwriting, and smart-home services.
- Dependencies: Cross-industry working groups; privacy-by-design tooling; legal frameworks.
- Semantic maintenance planning and automated inspections (Energy, Infrastructure)
- Vision: Periodic scans of plants/substations; open-set queries linked to checklists (“corroded pipe”, “leak detector”) triggering work orders.
- Dependencies: Robust recognition under harsh conditions; integration with sensors (thermal, gas); auditing and traceability.
- Education at scale: cloud labs for SLAM with GFMs (Academia)
- Vision: MOOC-scale hands-on labs where students run factor-graph SLAM with uncalibrated RGB and analyze attention-based verification.
- Dependencies: Managed GPU backends; datasets and grading pipelines.
- Retail autonomy at large scale with semantic inventory control (Retail)
- Vision: Nightly 3D scans with open-set search for planogram compliance across thousands of stores; roll-up analytics.
- Dependencies: Scalable orchestration, data pipelines, human-in-the-loop verification, continuous fine-tuning of prompts.
- Forensic-grade 3D documentation and courtroom-ready exhibits (Public safety, Legal)
- Vision: Turn scans into validated, queryable 3D evidence with provenance and immutability guarantees.
- Dependencies: Standards for accuracy/uncertainty; certification of toolchains; secure storage.
- Cross-modal augmentation: IMU/GNSS + feed-forward SLAM in outdoor campuses (Smart cities)
- Vision: Fuse inertial/positioning to extend to campus-scale while retaining feed-forward simplicity.
- Dependencies: Sensor integration, calibration on-the-fly, drift/scale handling across long routes.
Notes on common dependencies/assumptions across applications:
- Performance depends on the VGGT backbone (inference time, memory; submap size limited by GPU). Future lighter/robuster VGGTs will directly improve feasibility.
- Robustness remains challenged by textureless scenes, extreme dynamics, and very large-scale outdoor environments; careful keyframe selection, auxiliary sensing (IMU), or fallback tracking may be needed.
- Open-set object detection hinges on CLIP text alignment and SAM 3 segmentation; failure modes include occlusions, tiny objects, or domain shift.
- The current back-end optimizes poses (not points); some artifacts may require extending to point-level optimization or adding photometric/feature constraints.
- Data governance (privacy, security, consent) is essential for residential and sensitive environments.
Collections
Sign up for free to add this paper to one or more collections.