- The paper introduces a novel training-free VGGT extension that replaces iterative IRLS with a single-shot SVD alignment, improving dense 3D reconstruction efficiency.
- It leverages reliability-guided point sampling and normalized encoder tokens for fast loop detection, eliminating the need for external VPR modules and drastically reducing computational cost.
- Empirical results on KITTI, Waymo Open, and Virtual KITTI show state-of-the-art camera tracking and dense mapping performance with significantly faster runtime and improved geometric precision.
SwiftVGGT: Efficient Training-Free Dense 3D Reconstruction at Kilometer Scale
Introduction
SwiftVGGT addresses the bottlenecks inherent in feed-forward transformer models for large-scale, dense 3D reconstruction from long monocular RGB sequences, particularly relevant to autonomous driving and mobile robotics. Contemporary SLAM and transformer-based models struggle to maintain a favorable trade-off between runtime scalability and geometric precision. Traditional SLAM methods produce only sparse representations or require complex, slow multi-stage pipelines, while large transformer backbones (e.g., VGGT, MASt3R, DUSt3R) are fundamentally limited by GPU memory and suffer runtime constraints during chunkwise global alignment and loop closure.
SwiftVGGT introduces a training-free architecture that extends the capabilities of VGGT. Two core innovations drive substantial acceleration and quality improvements: (1) a reliability-guided point sampling for chunk alignment, supplanting iterative IRLS-based Sim(3) optimization with a single-shot SVD alignment, and (2) a fast loop detection strategy leveraging normalized VGGT encoder tokens, eliminating the need for an external visual place recognition (VPR) module. These advances yield state-of-the-art camera tracking and dense reconstruction, outperforming prior approaches in speed and accuracy, while enabling scaling to kilometer-scale environments.
Pipeline and Algorithmic Contributions
SwiftVGGT processes thousands of input images by segmenting them into sliding-window temporal chunks, each independently reconstructed via VGGT. Overlapping frames between neighboring chunks define local regions for Sim(3) alignment. The chunk alignment pipeline bypasses IRLS by adopting Umeyama SVD for transformation, with robust correspondences selected by spatial and confidence-based filters in the depth domain.
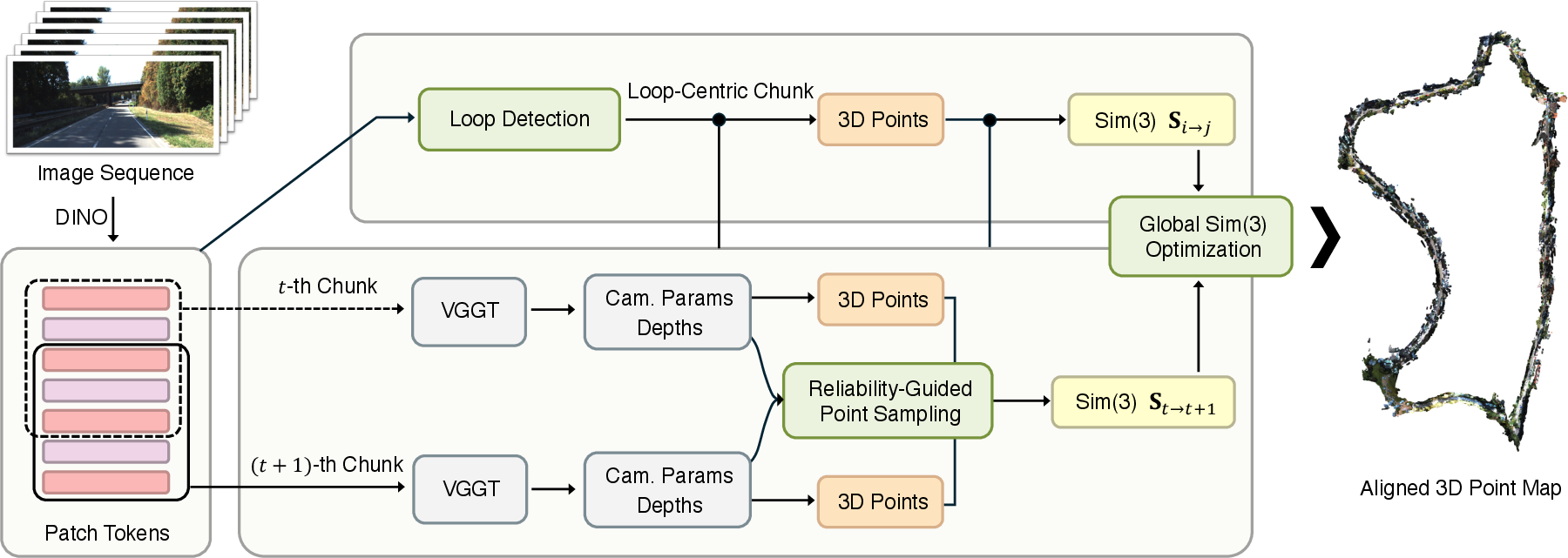
Figure 1: SwiftVGGT processes thousands of input images by dividing them into sliding-window chunks via VGGT, enabling scalable feed-forward dense reconstruction.
Reliability-Guided Point Sampling
- Each depth map is normalized to a reference intrinsic to stabilize metric scale across chunks.
- Overlapping regions are filtered for reliable alignment by jointly thresholding depth difference and depth confidence. This precisely identifies pixels with high geometric consistency, excluding outliers at object edges or uncertain regions.
- The final point set for Sim(3) estimation achieves better alignment accuracy than naive dense correspondences, while reducing computational cost by over 90% compared to IRLS.
Loop Detection from VGGT Encoder Tokens
Loop closure is performed exclusively with normalized VGGT DINO patch tokens, eliminating the external VPR pipeline. The process comprises:
- Patch-wise ℓ2 normalization and signed power normalization to decorrelate dominant scene biases and suppress hubness.
- PCA whitening removes coarse shared structure, sharpening the feature space for discriminative place recognition.
- Cosine similarity over the resulting global descriptors identifies candidate loop pairs, with non-maximum suppression to reject spurious detections.
- Loop-centric chunks are reconstructed and aligned, introducing non-local constraints for global Sim(3) optimization.
Global Optimization Strategy
A joint Sim(3) optimization is conducted over all temporal chunks and detected loops. Each transformation is mapped to Lie algebra and LM-based nonlinear least squares solves for globally consistent alignment subject to both sequential and loop-derived constraints.
Empirical Evaluation
Quantitative Analysis: Camera Tracking and Runtime
On KITTI Odometry, Waymo Open, and Virtual KITTI, SwiftVGGT achieves robust dense 3D reconstruction at a runtime that is at least three times faster than previous VGGT-based and SLAM-based systems. Notable numerical results include:
- KITTI Odometry: Average RMSE ATE (m) = 29.18 and FPS = 20.73; VGGT-Long achieves 29.41 and 6.91 FPS. DPV-SLAM and DROID-SLAM are significantly less accurate and slower.
- Waymo Open: Comparable accuracy and completeness to VGGT-Long and FastVGGT, but SwiftVGGT provides superior runtime scalability.
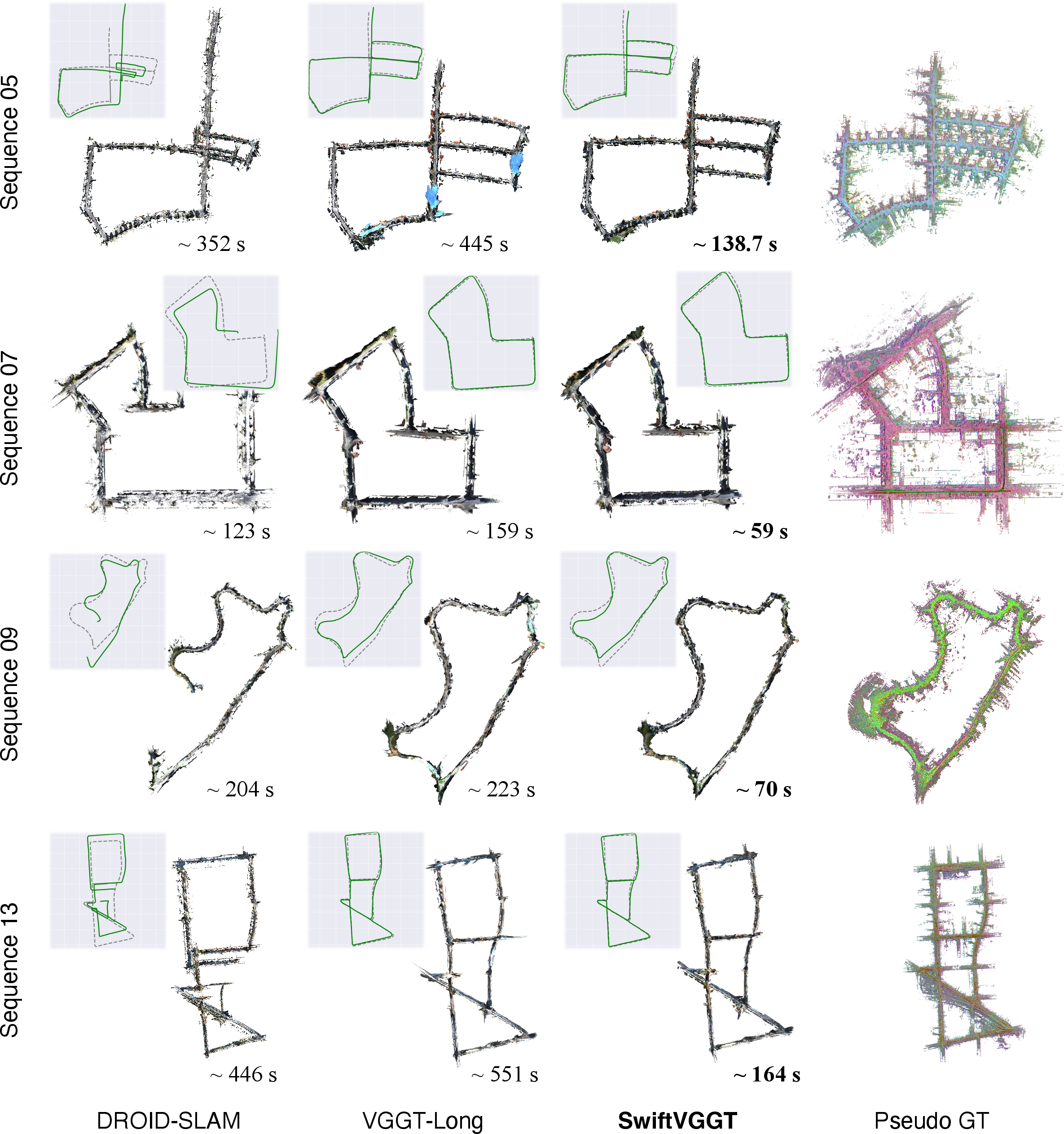
Figure 2: Comparison of dense 3D reconstruction on KITTI scenes containing loops, demonstrating precise camera tracking and high-fidelity geometry.
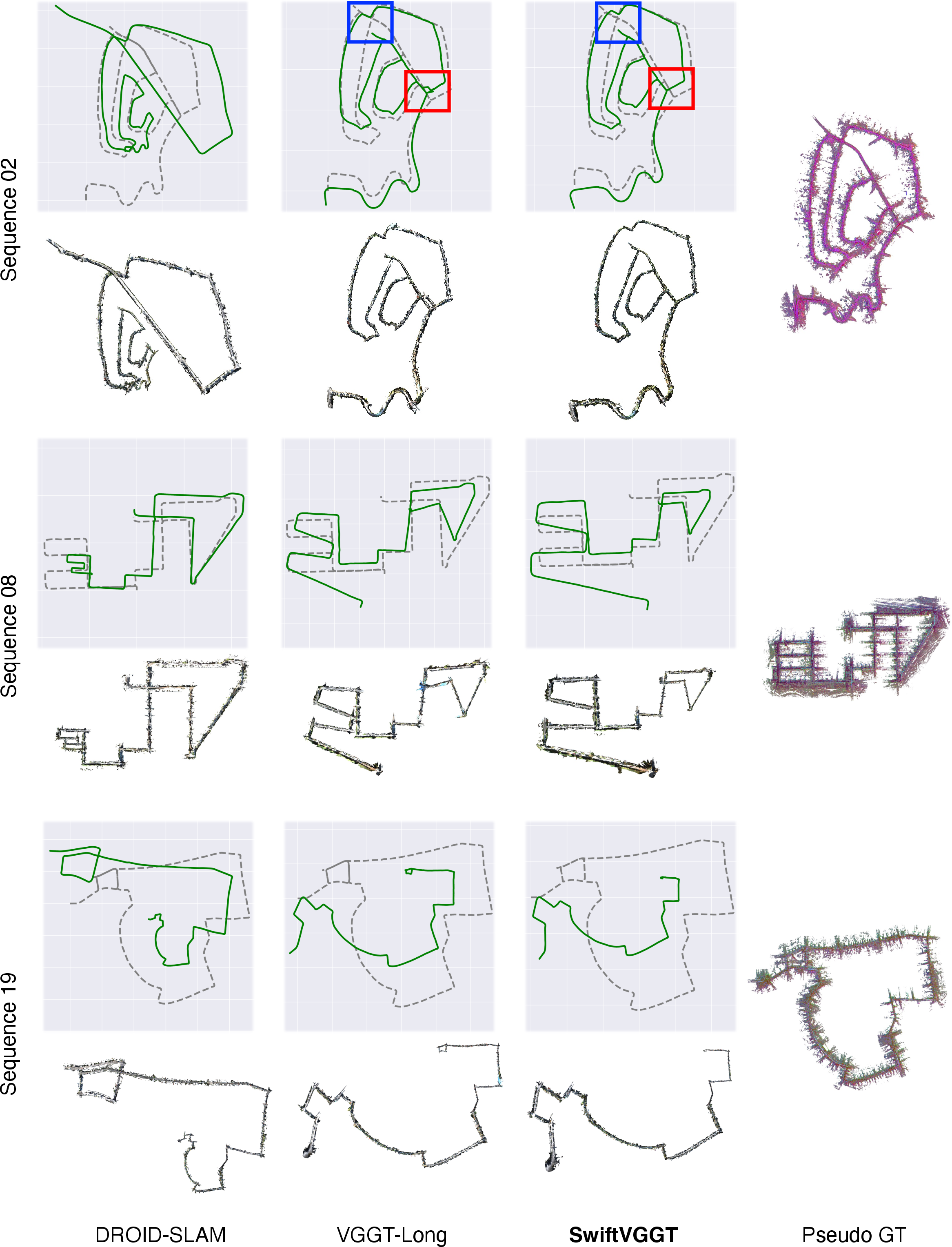
Figure 3: Failure cases in KITTI scenes; SwiftVGGT avoids hallucinated loops yet still faces challenges in missed closures under certain thresholds.
Ablation: Alignment and Loop Detection
Rigorous ablation demonstrates that reliability-guided point sampling offers optimal trade-offs for Sim(3) alignment, outperforming both IRLS and dense correspondence alternatives. Loop detection accuracy using normalized VGGT tokens matches explicit VPR models, further decreasing inference time.
Point Cloud Visualization
High-quality dense reconstructions are visualized for the KITTI (Figure 4), Waymo Open (Figure 5), and Virtual KITTI (Figure 6) datasets. SwiftVGGT yields detailed, contiguous structural geometry and robust trajectory alignment across dynamic driving scenarios.
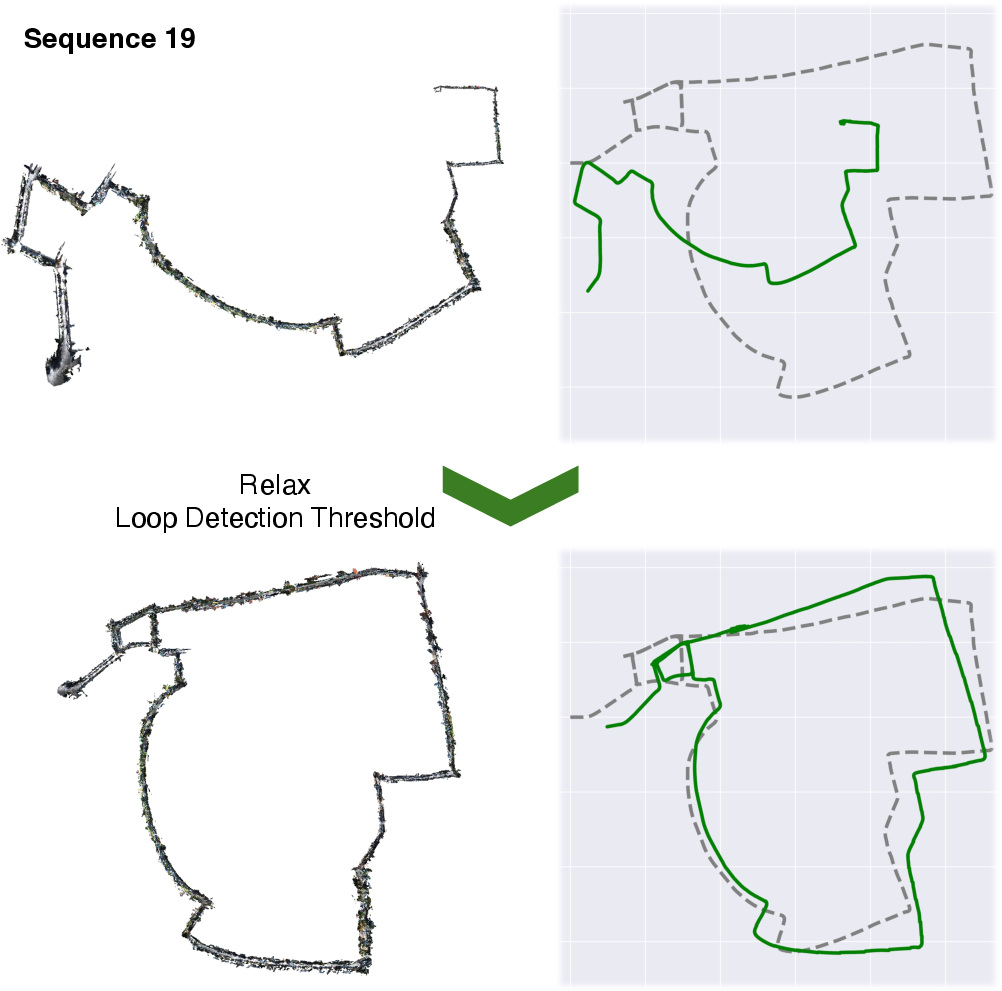
Figure 4: Point cloud visualization of KITTI dataset.

Figure 5: Point cloud visualization of Waymo Open dataset.

Figure 6: Point cloud visualization of Virtual KITTI dataset.
Limitations and Outlook
SwiftVGGT omits bundle adjustment, prioritizing feed-forward scalability over incremental pose refinement. Accumulated drift remains a limitation in certain long or loop-deficient trajectories. Extending SwiftVGGT with differentiable, lightweight BA modules could correct residual drift without compromising scalability. Furthermore, investigating hybrid loop closure strategies (feature-level or trajectory-level) may improve robustness in challenging scenarios.
Implications and Future Developments
SwiftVGGT establishes a paradigm whereby transformer-based feed-forward models deliver fast, precise large-scale 3D perception independent of heavy retraining or external auxiliary networks. The training-free approach, enabled primarily by reliable correspondence selection and encoder feature normalization, can generalize to other transformer foundation models for 3D vision. In practice, this framework is viable for real-time autonomous navigation, loop-aware mapping in GPS-denied environments, and rapid, detailed urban scene understanding. The approach unlocks scalability for kilometer-scale RGB-only mapping without substantial memory or runtime overhead.
Anticipated developments include integration of learned bundle adjustment, robust dynamic scene modeling, explicit global optimization for city-scale mapping, and fusion with non-RGB sensor modalities. Feed-forward, training-free dense 3D reconstruction using foundation transformer models is positioned as a critical direction for the future of scalable 3D computer vision.
Conclusion
SwiftVGGT sets a benchmark for fast, accurate, and memory-efficient dense 3D reconstruction at kilometer scale, leveraging two algorithmic innovations to bypass bottlenecks of existing transformer-based systems. The training-free loop detection and point sampling strategy drive significant runtime and accuracy improvements. The outlined global optimization and evaluation confirm the efficacy and practicality of the method for large-scale scene understanding, with demonstrable implications for future research in 3D vision and autonomous systems.

