FlashVGGT: Efficient and Scalable Visual Geometry Transformers with Compressed Descriptor Attention
Abstract: 3D reconstruction from multi-view images is a core challenge in computer vision. Recently, feed-forward methods have emerged as efficient and robust alternatives to traditional per-scene optimization techniques. Among them, state-of-the-art models like the Visual Geometry Grounding Transformer (VGGT) leverage full self-attention over all image tokens to capture global relationships. However, this approach suffers from poor scalability due to the quadratic complexity of self-attention and the large number of tokens generated in long image sequences. In this work, we introduce FlashVGGT, an efficient alternative that addresses this bottleneck through a descriptor-based attention mechanism. Instead of applying dense global attention across all tokens, FlashVGGT compresses spatial information from each frame into a compact set of descriptor tokens. Global attention is then computed as cross-attention between the full set of image tokens and this smaller descriptor set, significantly reducing computational overhead. Moreover, the compactness of the descriptors enables online inference over long sequences via a chunk-recursive mechanism that reuses cached descriptors from previous chunks. Experimental results show that FlashVGGT achieves reconstruction accuracy competitive with VGGT while reducing inference time to just 9.3% of VGGT for 1,000 images, and scaling efficiently to sequences exceeding 3,000 images. Our project page is available at https://wzpscott.github.io/flashvggt_page/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “FlashVGGT: Efficient and Scalable Visual Geometry Transformers with Compressed Descriptor Attention”
1) What this paper is about
This paper is about building fast and accurate 3D models from lots of photos or video frames. The authors introduce a new method, called FlashVGGT, that makes a powerful 3D reconstruction model (VGGT) much faster and more memory‑friendly, especially when you have hundreds or thousands of images.
2) The main questions the paper asks
- Can we keep the strong 3D understanding of VGGT while making it much faster on long image sequences?
- Do we really need every image patch to “talk” to every other patch (full self‑attention), or can we summarize the information and still get great results?
- How can we process very long videos in parts (chunks) without forgetting what came before?
3) How the method works (in everyday language)
First, a quick idea of the original model (VGGT):
- Each image is turned into many small “tokens” (like puzzle pieces).
- The model runs two kinds of attention:
- Frame attention: tokens inside the same image talk to each other (local details).
- Global attention: tokens across all images talk to each other (global consistency).
- The problem: global attention is slow because it tries to connect every token with every other token. As the number of images grows, the work explodes.
FlashVGGT keeps the good parts and fixes the slow part with two key ideas:
A) Compressed descriptor attention: “Talk to the class reps”
Imagine a huge classroom where every student (token) tries to talk to every other student. That’s noisy and slow. FlashVGGT instead:
- Summarizes each image into a much smaller set of “descriptor tokens” (like class representatives). It creates these summaries by gently shrinking the image grid with bilinear interpolation, which keeps nearby details smooth and clear.
- Now, instead of everyone talking to everyone, all the original tokens “ask questions” only to these descriptors. This is called cross‑attention. It keeps the global view but with far fewer conversations.
- Extra “anchor” tokens are added to avoid losing important details:
- Camera and special register tokens from all frames,
- All tokens from the first image (which sets the world frame),
- Tokens from a few key frames picked by quick clustering.
- Result: the heavy global attention becomes much lighter. For example, shrinking each image by 4× in height and 4× in width gives about 16× fewer descriptor tokens, saving a lot of time.
Analogy: Instead of every student chatting with everyone else, each student only talks to a few class reps who carry the important information for the whole group.
B) Chunk‑recursive inference: “Process videos in parts but keep smart notes”
For very long sequences (like 3,000+ images), you can’t fit everything into memory at once. FlashVGGT:
- Splits the sequence into chunks (small groups of images),
- Caches only the compressed descriptors from previous chunks (the “smart notes”),
- When processing the next chunk, it attends to both the new descriptors and the cached ones. This keeps a global memory without storing everything.
- A simple rule keeps memory small: keep descriptors from only every p‑th frame.
Analogy: You read a long book chapter by chapter, and you only keep summarized notes from earlier chapters. When reading a new chapter, you refer to those notes to stay consistent.
4) What they found and why it matters
Here are the main findings from their tests across many datasets and tasks (camera poses, depth maps, and dense 3D point clouds):
- Much faster on long sequences:
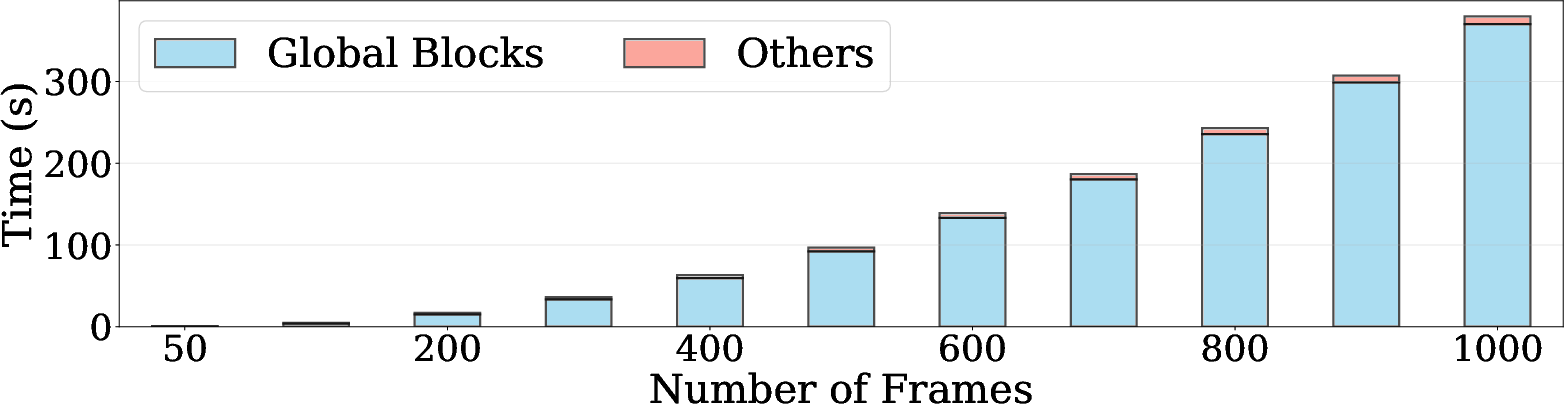
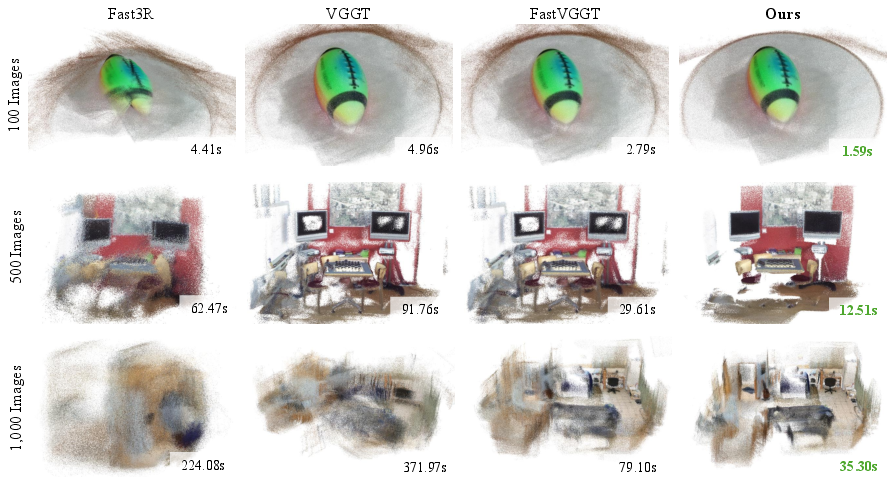
- For 1,000 images, FlashVGGT ran in about 35 seconds, while VGGT took about 373 seconds. That’s roughly 10× faster (about 9.3% of VGGT’s time).
- For 500 images, it was about 8× faster; for 100 images, over 3× faster.
- Similar or better accuracy:
- On camera pose estimation and depth prediction, FlashVGGT was very close to VGGT and usually better than other “fast” variants.
- On long, dense 3D reconstruction, it stayed accurate even as sequences got very long, avoiding the quality drop seen in VGGT on huge inputs.
- Scales to very long inputs:
- It can handle sequences beyond 3,000 images thanks to the chunk‑recursive memory.
- Memory friendly for online (streaming) use:
- In online mode (processing images as they arrive), it was both more accurate and much faster than other streaming methods, while using far less memory than models that cache everything.
Why this is important:
- It makes high‑quality 3D mapping from long videos practical, opening up uses in robotics, AR/VR, drones, and large‑scale scene scanning.
5) What this could change in the real world
FlashVGGT shows that we can keep strong 3D understanding while making models far faster and lighter. This means:
- Faster 3D maps from long video tours (think: scanning a house, a museum, or a city street).
- Better real‑time operation on limited hardware (like a robot or drone that must process video quickly without a giant GPU).
- More reliable results over long sequences, thanks to smarter global summaries and memory.
Limitations and future work:
- There’s a tiny accuracy dip on very short sequences compared to the original VGGT.
- The idea of “descriptor attention” has more room to explore—there may be even better ways to summarize and select tokens.
In short, FlashVGGT keeps the brains of VGGT but makes it faster and more scalable by talking to smart summaries (descriptors) and by remembering the past with compact notes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open questions that future work could address to strengthen and extend the contributions of FlashVGGT:
- Formal approximation guarantees: Derive theoretical bounds on the error introduced by descriptor-based cross-attention relative to full self-attention (as functions of compression ratio , descriptor size, and attention sparsity), and characterize regimes where the approximation is provably sufficient.
- Descriptor generation design space: Explore richer, content-adaptive or learned compression strategies (e.g., attention pooling, dynamic token selection, learned downsampling, multi-head routing) beyond bilinear interpolation and the tested lightweight compressor; quantify compute–accuracy trade-offs.
- Multi-scale descriptors: Investigate hierarchical (coarse-to-fine) descriptor sets and pyramidal resampling to better preserve long-range and fine-grained geometry simultaneously; ablate scale combinations and per-layer integration strategies.
- Adaptive compression: Develop mechanisms to adapt per-frame, per-region, or per-layer based on scene texture, overlap, motion, or estimated uncertainty; evaluate gains versus static and analyze stability.
- Cross-layer descriptor reuse: Study whether descriptors should be recomputed for each global attention block or reused across layers; quantify effects on accuracy, latency, and memory.
- Auxiliary token selection: Systematically ablate the number, frequency, and selection criteria for auxiliary tokens (first-frame inclusion, keyframe cadence), and compare k-means on frame averages against alternatives (camera baseline coverage, view overlap, entropy/uncertainty-based selection).
- First-frame anchoring robustness: Assess failure modes when the first frame is uninformative, degraded, or not representative; test multi-anchor strategies or learned anchoring and measure downstream impact.
- Auxiliary token overhead modeling: Refine the complexity analysis to include auxiliary tokens (camera/register, full frames, keyframes) and provide empirical breakdowns of their compute/memory contribution; design cost-aware selection policies.
- Memory policy in chunk recursion: Replace uniform “every -th frame” retention with learned or importance-based eviction/retention (e.g., coverage, novelty, uncertainty, view-geometry diversity); evaluate drift control and accuracy–memory trade-offs.
- Long-horizon scaling limits: Benchmark sequences beyond 3,000 frames (e.g., 5k–10k) to map performance/resource scaling, latency, and failure modes under different and ; provide practical operating envelopes.
- Drift and error accumulation analysis: Quantify how chunk-recursive memory accrues errors over time (pose drift, triangulation error), and evaluate mitigation (periodic re-summarization, memory pruning, refresh via re-anchoring).
- Dynamic and low-overlap scenes: Test robustness on datasets with moving objects, low inter-frame overlap, motion blur, lighting changes (e.g., autonomous driving, aerial video), and analyze descriptor/memory behavior in these regimes.
- Camera intrinsics and distortion robustness: Measure accuracy of predicted intrinsics and sensitivity to varying intrinsics, rolling shutter, and lens distortion; include intrinsics error metrics and calibration experiments.
- Multi-view geometric consistency metrics: Complement current metrics with epipolar residuals, reprojection error distributions, and triangulation stability to substantiate claims about preserved global reasoning.
- Attention dilution diagnosis: Empirically analyze why VGGT degrades at 1k+ images using attention sparsity/entropy, token redundancy, and interaction statistics; compare against FlashVGGT under controlled token counts.
- Confidence calibration: Quantify calibration of aleatoric/confidence maps (e.g., ECE, NLL, Brier score), evaluate calibration-aware losses/training schemes, and study their effect on downstream filtering and reconstruction completeness.
- Frame attention interplay: Investigate compressing/restructuring frame attention (local windows, token pruning/merging) and its interactions with descriptor attention; determine optimal division of labor between local/global modules.
- Training curriculum effects: Analyze how causal-mask fine-tuning affects offline short-sequence accuracy; explore mixed causal/non-causal curricula, variable chunk sizes, and regularization to reduce short-sequence degradation noted in Limitations.
- Encoder dependence and patching: Test alternative backbones (e.g., DINOv2 variants, ConvNeXt features) and patch sizes; assess generality and sensitivity of descriptor attention to encoder characteristics.
- Anti-aliasing in resampling: Evaluate whether bilinear interpolation introduces aliasing or texture repetition artifacts; test anti-aliasing filters or learned resampling kernels and quantify impact on fine geometric details.
- Streaming latency and QoS: Report per-frame/ per-chunk latency profiles, jitter, and throughput for online settings; study behavior under memory pressure and propose back-off strategies (adaptive , , chunk size).
- Keyframe selection reproducibility: Detail k-means initialization, cluster count, and seeding; compare deterministic and incremental selection methods suitable for production deployments.
- Domain generalization: Expand evaluation to out-of-distribution domains (e.g., outdoor street-level, UAV, underwater) beyond RealEstate10K and analyze failure patterns; investigate domain adaptation strategies compatible with descriptor attention.
- Safety/fallback mechanisms: Develop degradation detectors (e.g., uncertainty/consistency checks) that trigger adaptive compression or fallback to denser attention when performance drops, and evaluate their reliability.
Practical Applications
Practical Applications of FlashVGGT
FlashVGGT introduces compressed descriptor attention and chunk-recursive inference to make multi-view 3D reconstruction significantly faster and more memory-efficient than dense global self-attention (e.g., VGGT), while maintaining competitive accuracy. Below are actionable applications and their feasibility, mapped to sectors, tools/workflows, and key dependencies.
Immediate Applications
- Accelerated offline photogrammetry for large scenes
- Sectors: AEC (architecture/engineering/construction), Cultural heritage, Mapping/GIS, Film/VFX
- Tools/products/workflows: Replace or augment SfM/MVS stages in COLMAP, OpenMVG, OpenMVS, Meshroom; batch “video-to-3D” pipelines; Cloud batch APIs that accept 100–3,000+ images and return camera poses, depth, and dense point clouds; pre-initialize classical pipelines with FlashVGGT’s poses/depth to cut bundle-adjustment and MVS time
- Assumptions/dependencies: High-VRAM workstation or cloud GPU (peak ≈ 60–70 GB for 1,000 frames in reported tests); sufficient view overlap and texture; domain alignment with training data; minor quality dip on short sequences acknowledged in paper
- Fast 3D capture for real estate and interior design
- Sectors: Real estate, Retail/interior design
- Tools/products/workflows: Smartphone capture app uploading frames to a cloud FlashVGGT service; automatic floor plans and room meshes; publishable 3D tours with confidence-based filtering for QA
- Assumptions/dependencies: Cloud inference recommended; privacy handling for indoor scenes; lighting/texture variability; sequence ordering improves performance
- On-robot/drones online mapping with descriptor caching
- Sectors: Robotics, Drones/UAV, Warehousing/logistics
- Tools/products/workflows: ROS/ROS2 node for chunk-recursive inference; descriptor-cache module to maintain global context while processing rolling camera buffers (e.g., 10-frame chunks); integration with SLAM stacks for rapid global map building or re-localization
- Assumptions/dependencies: GPU on edge compute (Jetson/desktop) or offboard link to a GPU server; ordered sequences; training with causal masking as in paper; dynamic scenes can degrade consistency
- High-throughput visual inspection and asset digitization
- Sectors: Energy (solar/wind), Utilities, Manufacturing QA
- Tools/products/workflows: Fleet workflows where long video streams of assets (racks/turbines/lines) are reconstructed into dense geometry; confidence maps to target re-capture or defect analysis; integration with existing inspection dashboards
- Assumptions/dependencies: Sufficient view coverage; motion blur control; domain adaptation may be needed for reflective/texture-poor surfaces
- VFX and virtual production set builds
- Sectors: Film/TV, Gaming
- Tools/products/workflows: On-set rapid set-scanning to produce geometry proxies for previs and blocking; DCC plugins (Unreal/Unity/Maya) that consume FlashVGGT outputs; confidence-guided cleanup steps
- Assumptions/dependencies: Variable lighting/props; offloading to GPU servers; pipeline integration for mesh texturing/hole-filling
- Street-level mapping from dashcams or backpack rigs (offline)
- Sectors: Mapping/GIS, Mobility, Smart cities
- Tools/products/workflows: Process hours of imagery in chunks, using descriptor memory to maintain global context across long drives; bootstrap HD map layers (poses, depth, structural point clouds)
- Assumptions/dependencies: Uniform intrinsics or robust intrinsics prediction; moving objects; strong lighting changes; potential need for geo-anchors/GNSS to stabilize scale/drift
- Faster initialization for NeRF/3DGS and radiance-field pipelines
- Sectors: Graphics, Simulation, Digital twins
- Tools/products/workflows: Use FlashVGGT camera poses and depth priors to warm-start NeRF/3D Gaussian Splatting; reduce optimization steps and failures due to bad initialization
- Assumptions/dependencies: Alignment between reconstruction and radiance-field coordinate frames; handling of specular/transparent surfaces
- E-commerce product scanning from videos
- Sectors: E-commerce, Advertising
- Tools/products/workflows: Studio or in-store workflows turning quick object videos into 3D assets for web/mobile viewers; automatic background suppression aided by confidence maps
- Assumptions/dependencies: Consistent lighting; occlusion handling; scale ambiguity for single-device scenarios
- Research and teaching: efficient multi-view transformer baseline
- Sectors: Academia, R&D
- Tools/products/workflows: Use FlashVGGT as a training/inference-efficient baseline for new attention variants, long-sequence benchmarks, or online mapping studies; ablation platforms for descriptor token design (compression ratio r, memory drop p, auxiliary tokens)
- Assumptions/dependencies: Access to training data and GPUs; codebase familiarity; reproducibility across hardware
- Confidence-driven QA in 3D pipelines
- Sectors: AEC, Mapping, Robotics, VFX
- Tools/products/workflows: Use spatially coherent confidence maps to keep high-quality points and flag weak regions for re-capture or algorithmic inpainting; automated acceptance criteria for deliverables
- Assumptions/dependencies: Threshold tuning per domain; downstream tools to act on confidence masks
Long-Term Applications
- City-scale, real-time mapping on vehicle fleets
- Sectors: Autonomous driving, Municipal mapping, Logistics
- Tools/products/workflows: On-vehicle inference with descriptor memory to maintain global context over hours; automatic HD map updates; streaming APIs to back-end map services
- Assumptions/dependencies: Significant model optimization (quantization, distillation) for edge NPUs; robust handling of dynamic objects and severe illumination/weather shifts; regulatory constraints on public-space scanning
- On-device XR room scanning and persistent AR anchors
- Sectors: AR/VR, Consumer devices
- Tools/products/workflows: XR headsets/phones performing chunked, on-device reconstruction to maintain persistent spatial maps; improved AR placement and occlusion
- Assumptions/dependencies: Hardware acceleration for attention; thermal/power limits; privacy (on-device processing preferred); short-sequence performance gap to be minimized
- Cooperative multi-robot mapping via descriptor exchange
- Sectors: Robotics, Defense, Industrial automation
- Tools/products/workflows: Bandwidth-efficient sharing of compact descriptors across agents; global fusion server combining multiple descriptor memories; cross-agent loop closure
- Assumptions/dependencies: Communication constraints; descriptor compatibility and synchronization; robust global alignment across distinct trajectories/sensors
- Hybrid pipelines: FlashVGGT + NeRF/3DGS for photorealistic digital twins
- Sectors: Digital twins, Smart buildings, AEC
- Tools/products/workflows: Geometry-first fast reconstruction followed by neural rendering refinement; continual updates from streaming cameras; quality-for-time knobs
- Assumptions/dependencies: Stable pose/depth priors in challenging materials; scheduling and data management for continual updates
- Infrastructure inspection at scale (bridges, tunnels, rail)
- Sectors: Transportation, Energy, Public works
- Tools/products/workflows: Long-flight UAV scans processed in near-real-time; geometric deviation detection vs. CAD; confidence maps to triage human review
- Assumptions/dependencies: GPS-denied environments; repetitive/low-texture patterns; safety/regulatory clearances
- Medical endoscopy and surgical scene 3D reconstruction
- Sectors: Healthcare
- Tools/products/workflows: Domain-adapted models for monocular endoscopy to produce depth/maps for navigation; chunk-recursive inference for long procedures
- Assumptions/dependencies: Strict domain shift (specularities, fluids); regulatory approval; dataset availability; real-time constraints in OR
- Descriptor-based attention as a general pattern for multi-view/video transformers
- Sectors: Software/AI, Video analytics
- Tools/products/workflows: Integrate compressed descriptor attention in video understanding, multi-camera tracking, and 3D perception backbones; SDKs exposing “descriptor memory” as a primitive
- Assumptions/dependencies: Task-specific auxiliary tokens; careful tuning of compression ratio r to avoid accuracy cliffs
- Privacy-preserving and sustainable 3D capture programs
- Sectors: Public policy, Smart cities, Compliance
- Tools/products/workflows: Procurement standards emphasizing compute/memory efficiency (lower energy per scene); on-device or encrypted on-prem processing; redaction of faces/license plates in 3D outputs
- Assumptions/dependencies: Policy frameworks and auditing; impact assessment of reconstruction on privacy; alignment with data protection laws
- Continuous digital twin platforms for facilities
- Sectors: Enterprise IT, Real estate operations, Manufacturing
- Tools/products/workflows: Always-on cameras stream to a FlashVGGT service with rolling descriptor memory; automatic detection of layout changes; integration with CMMS/BIM
- Assumptions/dependencies: Network and storage budgets; robust change detection; governance for always-on sensing
- Retail/store analytics and space optimization
- Sectors: Retail, Hospitality
- Tools/products/workflows: Overnight or off-hours scans to reconstruct store layouts, shelf geometry, and planogram compliance; confidence maps to prioritize re-scan zones
- Assumptions/dependencies: Permissions; occlusions during open hours; domain adaptation for glossy/reflective packaging
Cross-cutting Dependencies and Assumptions
- Resource profile: Although far more efficient than dense global attention, large jobs still benefit from high-VRAM GPUs or cloud; edge deployment will require additional model compression and hardware acceleration.
- Data characteristics: Success hinges on adequate view overlap, texture, lighting stability, and roughly ordered sequences for online mode; dynamic scenes and severe domain shifts may degrade accuracy.
- Hyperparameters and design choices: Compression ratio r (typically 4) and memory drop p balance quality vs. speed/memory; auxiliary tokens (camera/register, first frame, keyframes) are important to maintain global consistency.
- Integration and interoperability: Best results often come from hybrid workflows (e.g., using FlashVGGT outputs to initialize classical SfM/MVS or NeRF/3DGS), plus ecosystem plugins (ROS, Unreal/Unity, photogrammetry toolchains).
- Governance: Scanning private or public spaces requires privacy and data handling measures (consent, redaction, secure storage) and, for public programs, energy/sustainability reporting.
Glossary
- Absolute Relative Error (Abs Rel): A scale-invariant depth error metric measuring the average relative difference between predicted and ground-truth depth. "For depth estimation, we report Absolute Relative Error (Abs Rel) and ratio."
- Absolute Rotation Error (ARE): A camera pose metric quantifying the absolute angular difference between predicted and ground-truth rotations. "For camera estimation, we report Absolute Translation Error (APE), Absolute Rotation Error (ARE), Relative Translation Error (RPE-Trans), and Relative Rotation Error (RPE-Rot)."
- Absolute Translation Error (APE): A camera pose metric measuring the absolute Euclidean distance between predicted and ground-truth translations. "For camera estimation, we report Absolute Translation Error (APE), Absolute Rotation Error (ARE), Relative Translation Error (RPE-Trans), and Relative Rotation Error (RPE-Rot)."
- Aleatoric uncertainty: Data-dependent uncertainty inherent in observations, used here to quantify confidence in depth predictions. "a DPT head~\cite{ranftl2021dpt} predicts a depth map and an aleatoric uncertainty map~\cite{kendall2016uncertainty}."
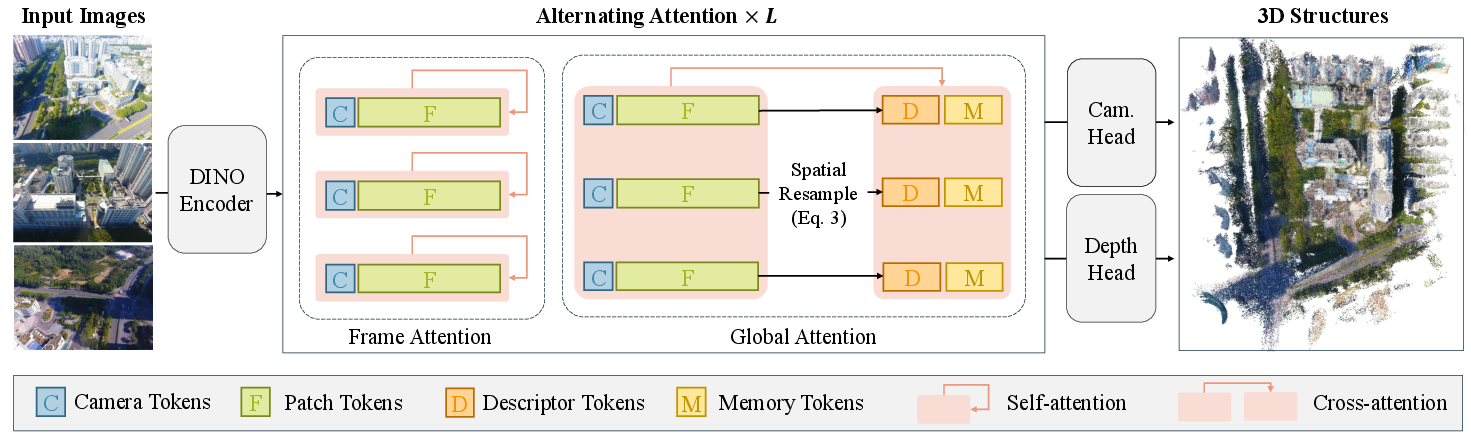
- Alternating attention: A transformer design that alternates between intra-frame and inter-frame attention to aggregate local and global context. "VGGT’s success stems from an alternating attention backbone that combines frame-wise and global attention blocks~\cite{vaswani2017attention, dosovitskiy2020vit}, enabling effective aggregation of frame and global context."
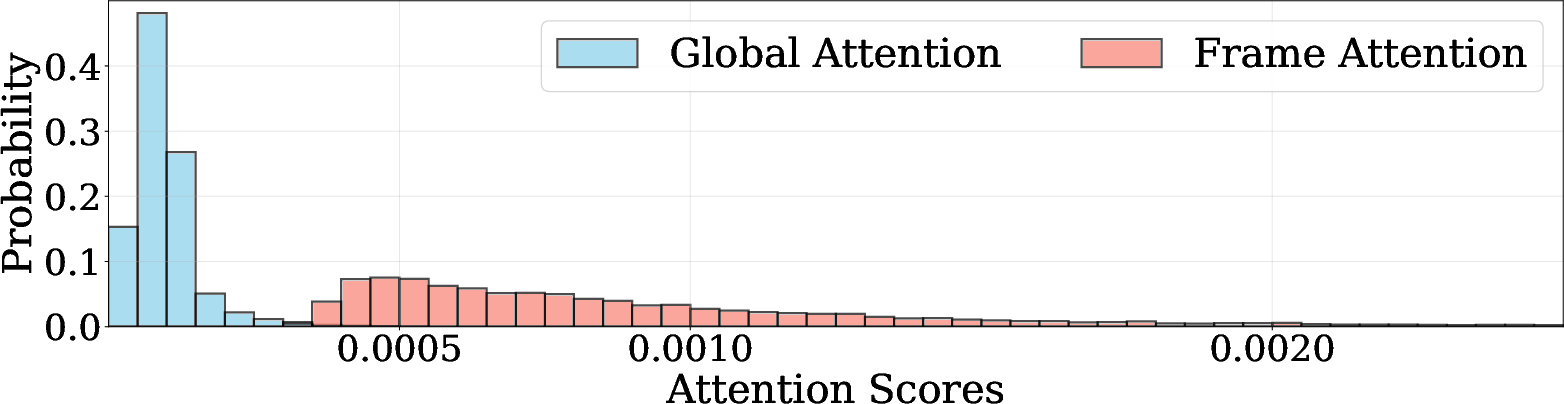
- Attention dilution: Degradation in attention effectiveness when too many tokens are attended, leading to reduced performance. "Notably, VGGT suffers from noticeable performance degradation due to attention dilution across excessive tokens, whereas FlashVGGT maintains high accuracy with over 10 faster inference."
- AUC (Area Under the Curve): Here, the area under the accuracy-threshold curve for pose accuracy metrics. "we report standard metrics: RRA (Relative Rotation Accuracy) and RTA (Relative Translation Accuracy), and AUC, the area under the accuracy-threshold curve for the minimum of RRA and RTA."
- Auxiliary tokens: Additional tokens added to compressed descriptors (e.g., camera, first image, and key-frame tokens) to preserve geometric fidelity. "we augment the compressed descriptors with three types of auxiliary tokens:"
- Bilinear interpolation: A smooth resampling method using linear interpolation in two dimensions to downsample feature grids. "We employ bilinear interpolation to resample each frame's spatial dimensions to a lower resolution "
- Block sparsity: A sparsity pattern structured in blocks within matrices to reduce computation in attention. "FasterVGGT~\cite{wang2025fastervggt} introduces block sparsity into the attention matrix to reduce computation."
- Bundle adjustment: Nonlinear optimization refining 3D structure and camera parameters jointly by minimizing reprojection error. "These methods rely on per-scene, iterative optimization pipelines that include feature detection, matching, triangulation, and bundle adjustment."
- Camera extrinsics: Parameters defining a camera’s position and orientation in the world. "a camera head predicts camera extrinsics and intrinsics"
- Camera intrinsics: Parameters defining a camera’s internal characteristics (e.g., focal length, principal point). "a camera head predicts camera extrinsics and intrinsics"
- Causal mask: An attention mask that restricts tokens to attend only to previous tokens in sequence order. "applying a causal mask to the global attention block that restricts each image to attend only to previous frames in the sequence."
- Chamfer Distance (CD): A symmetric distance between point sets used to evaluate reconstructed point clouds. "For point cloud reconstruction, we report Accuracy (Acc), Completeness (Comp), Chamfer Distance (CD), and Normal Consistency (NC)."
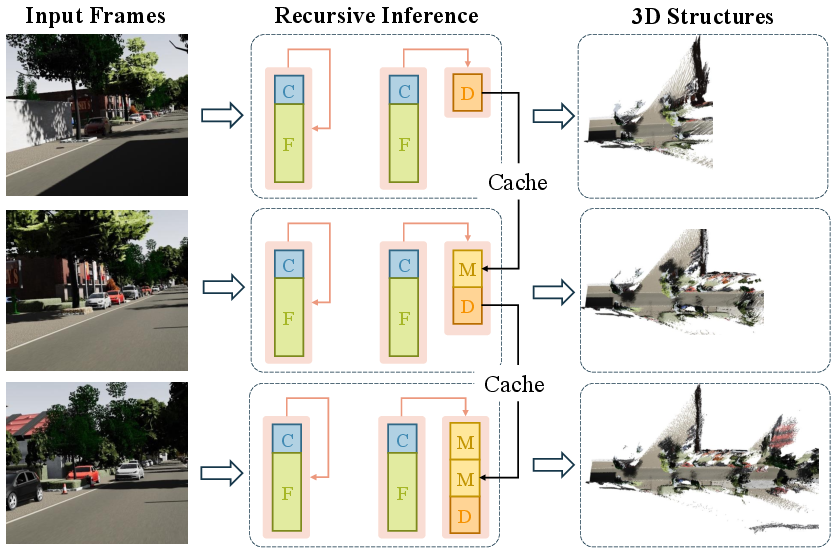
- Chunk-recursive inference: An online processing scheme that divides long sequences into chunks while reusing cached descriptors to maintain global context. "we propose a chunk-recursive inference scheme."
- Completeness (Comp): A point cloud metric measuring how completely the predicted points cover the ground-truth surface. "For point cloud reconstruction, we report Accuracy (Acc), Completeness (Comp), Chamfer Distance (CD), and Normal Consistency (NC)."
- Cross-attention: An attention mechanism where one set of tokens (queries) attends to another set (keys/values). "We reformulate the global attention operation from Eq.~(2) as a cross-attention layer."
- Depth-wise convolution: A convolutional operation applied channel-wise to reduce computation while preserving spatial locality. "a lightweight learnable compressor consisting of a depth-wise convolution followed by a point-wise linear layer (Table \ref{tab:spatial_compression})."
- Descriptor tokens: Compact tokens produced by spatially compressing per-frame features to summarize global context. "generate a compact set of descriptor tokens via spatial resampling"
- DINO: A self-supervised vision transformer backbone used for image tokenization. "Our framework encodes input images into tokens using DINO~\cite{caron2021dino}"
- DPT head: A prediction head (Dense Prediction Transformer) used to produce dense outputs like depth and uncertainty. "a DPT head~\cite{ranftl2021dpt} predicts a depth map and an aleatoric uncertainty map~\cite{kendall2016uncertainty}"
- Feed-forward paradigm: Direct prediction without per-scene optimization, typically via a single network pass. "This feed-forward paradigm eliminates the need for sequential post-processing and per-scene optimization."
- Frame Attention: Self-attention restricted within each frame to refine local features. "Frame Attention processes tokens within each frame independently."
- Global Attention: Attention across tokens from all frames to model inter-frame relationships. "Global Attention models interactions across all frames."
- Global receptive field: The ability of a model or layer to aggregate information across the entire input sequence. "Crucially, the operation maintains a global receptive field, preserving the model's ability to capture long-range dependencies across all input images."
- k-means clustering: An unsupervised algorithm that partitions data into k clusters, used here for key-frame selection. "key-frames selected via k-means clustering~\cite{lloyd1982kmeans} on average frame tokens."
- Key-frames: Selected representative frames that act as anchors for global geometry. "all tokens from key-frames selected via k-means clustering~\cite{lloyd1982kmeans} on average frame tokens."
- KV-caching: Storing keys and values from attention layers to reuse across chunks/steps for efficiency. "Our chunk-recursive scheme achieves substantial memory efficiency gains over the naive KV-caching in StreamVGGT~\cite{zhuo2025streamvggt}."
- Low-rank approximations: Techniques that approximate matrices (e.g., attention) with lower-rank factors to reduce complexity. "or low-rank approximations~\cite{jaegle2021perceiver, han2024agent} into the attention computation."
- Memory tokens: Cached descriptor tokens that accumulate global context across processed chunks. "We maintain a set of memory tokens that accumulates global information from all chunks processed up to step "
- Multi-View Stereo (MVS): Methods that reconstruct 3D geometry from multiple overlapping images. "Traditional pipelines such as Structure-from-Motion (SfM)~\cite{schoenberger2016sfm, ullman1979interpretation, koenderink1991affine, pan2024glomap} and Multi-View Stereo (MVS)~\cite{seitz2006mvs, schoenberger2016mvs, moulon2016openmvg} have dominated this task for decades."
- Nearest-neighbor interpolation: A fast, non-smooth resampling method that assigns values from the nearest source pixel/token. "nearest-neighbor interpolation, bilinear interpolation, and a lightweight learnable compressor consisting of a depth-wise convolution followed by a point-wise linear layer (Table \ref{tab:spatial_compression})."
- Normal Consistency (NC): A point cloud quality metric evaluating alignment of surface normals between prediction and ground truth. "For point cloud reconstruction, we report Accuracy (Acc), Completeness (Comp), Chamfer Distance (CD), and Normal Consistency (NC)."
- Register tokens: Special tokens used to stabilize and structure transformer representations. "Each sequence includes a special learnable camera token that stores camera information and several register tokens~\cite{darcet2023register}."
- Relative Pose Error (RPE-Rot): A metric measuring relative rotational drift between consecutive camera poses. "For camera estimation, we report Absolute Translation Error (APE), Absolute Rotation Error (ARE), Relative Translation Error (RPE-Trans), and Relative Rotation Error (RPE-Rot)."
- Relative Pose Error (RPE-Trans): A metric measuring relative translational drift between consecutive camera poses. "For camera estimation, we report Absolute Translation Error (APE), Absolute Rotation Error (ARE), Relative Translation Error (RPE-Trans), and Relative Rotation Error (RPE-Rot)."
- Relative Rotation Accuracy (RRA): A pose accuracy metric evaluating rotation estimation quality under thresholds. "we report standard metrics: RRA (Relative Rotation Accuracy) and RTA (Relative Translation Accuracy), and AUC, the area under the accuracy-threshold curve for the minimum of RRA and RTA."
- Relative Translation Accuracy (RTA): A pose accuracy metric evaluating translation estimation quality under thresholds. "we report standard metrics: RRA (Relative Rotation Accuracy) and RTA (Relative Translation Accuracy), and AUC, the area under the accuracy-threshold curve for the minimum of RRA and RTA."
- Self-attention: An operation where tokens attend to each other within a sequence to aggregate information. "Standard self-attention is then computed over all tokens:"
- Spatial compression ratio: The factor by which spatial dimensions (and thus tokens) are reduced during descriptor creation. "where is the spatial compression ratio."
- Structure-from-Motion (SfM): A classical pipeline that estimates 3D structure and camera motion from images. "Traditional pipelines such as Structure-from-Motion (SfM)~\cite{schoenberger2016sfm, ullman1979interpretation, koenderink1991affine, pan2024glomap} and Multi-View Stereo (MVS)~\cite{seitz2006mvs, schoenberger2016mvs, moulon2016openmvg} have dominated this task for decades."
- Token merging: An efficiency technique that merges similar tokens to reduce sequence length before attention. "FastVGGT~\cite{shen2025fastvggt} employs token merging to reduce the number of tokens fed into global attention."
- Triangulation: Estimating 3D points by intersecting rays from multiple camera views. "These methods rely on per-scene, iterative optimization pipelines that include feature detection, matching, triangulation, and bundle adjustment."
- Visual Geometry Grounding Transformer (VGGT): A transformer model for large-scale, multi-view 3D reconstruction using alternating attention. "A recent milestone in this direction is the Visual Geometry Grounding Transformer (VGGT)~\cite{wang2025vggt}, which performs high-fidelity 3D reconstruction from hundreds of views in a single forward pass."
- Vision Transformers: Transformer architectures applied to vision tasks, leveraging self-attention over image tokens. "Vision Transformers~\cite{dosovitskiy2020vit, liu2021swintransformer, arnab2021vivit} have become a pivotal component in modern computer vision, powered by the self-attention mechanism."
- World coordinate system: The global reference frame used to express 3D points and camera poses. "all tokens from the first image (which defines the world coordinate system)"
Collections
Sign up for free to add this paper to one or more collections.