TurboVGGT: Fast Visual Geometry Reconstruction with Adaptive Alternating Attention
Abstract: Recent feed-forward 3D reconstruction methods, such as visual geometry transformers, have substantially advanced the traditional per-scene optimization paradigm by enabling effective multi-view reconstruction in a single forward pass. However, most existing methods struggle to achieve a balance between reconstruction quality and computational efficiency, which limits their scalability and efficiency. Although some efficient visual geometry transformers have recently emerged, they typically use the same sparsity ratio across layers and frames and lack mechanisms to adaptively learn representative tokens to capture global relationships, leading to suboptimal performance. In this work, we propose TurboVGGT, a novel approach that employs an efficient visual geometry transformer with adaptive alternating attention for fast multi-view 3D reconstruction. Specifically, TurboVGGT employs an end-to-end trainable framework with adaptive sparse global attention guided by adaptive sparsity selection to capture global relationships across frames and frame attention to aggregate local details within each frame. In the adaptive sparse global attention, TurboVGGT adaptively learns representative tokens with varying sparsity levels for global geometry modeling, considering that token importance varies across frames, attention layers operate tokens at different levels of abstraction, and global dependencies rely on structurally informative regions. Extensive experiments on multiple 3D reconstruction benchmarks demonstrate that TurboVGGT achieves fast multi-view reconstruction while maintaining competitive reconstruction quality compared with state-of-the-art methods. Project page: https://turbovggt.github.io/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces TurboVGGT, a faster way for computers to turn many 2D photos of a place into a 3D model. It focuses on doing this quickly while keeping the 3D results accurate, even when there are lots of images (like long videos).
What questions does it try to answer?
In simple terms, the paper asks:
- How can we rebuild 3D scenes from many images more quickly without losing quality?
- Can we make the model “pay attention” only to the most important image parts, so it wastes less time and memory?
- Can this smarter attention adapt on the fly for different images and different layers of the network?
How does it work?
Think of making a 3D model like organizing a giant group project:
- Each image is a “team,” and each small patch of an image is like a “note” from a team member.
- To build the 3D scene, the system needs to figure out which notes match across teams (images of the same place from different angles) and also understand details within each team (each image).
TurboVGGT improves this process with two big ideas:
- Adaptive selection: choosing what matters most
- Analogy: A teacher asks teams to first pick their most important notes to share with the whole class.
- The model uses a small “gating” helper (like a traffic cop) to decide, for each image and for each step in the network, how many notes to keep. This “how many to keep” number can change across images and layers. That’s what “adaptive sparsity” means: keeping fewer, more important notes when possible.
- Alternating attention: switching between global and local focus
- Global attention = class-wide discussion: Images compare their important notes across all views to find matches and build the overall 3D shape.
- Frame (per-image) attention = team huddle: Each image refines its own details without being distracted by others.
- TurboVGGT alternates between these two, so it first shares essentials across images (global) and then polishes details within each image (frame).
How it’s done under the hood (in plain language):
- The model turns each image into “tokens” (small chunks of information, like sticky notes).
- A gating network decides, per image and per layer, how many tokens to keep as “representatives.”
- The model compresses each image’s tokens into a smaller set of “representative tokens” (like the team’s top notes).
- It then runs global attention using mostly these representative tokens to find cross-image correspondences, which saves a lot of compute.
- After that, it runs frame attention within each image to refine local details (like edges and depth).
- Finally, simple prediction heads turn the learned tokens into 3D outputs: camera poses, depth maps, and 3D points.
Why this is faster:
- Full global attention compares every token with every other token, which grows very fast and gets expensive.
- By adaptively keeping only the most useful tokens for the global step, TurboVGGT cuts down comparisons a lot, especially for long sequences.
What did they find?
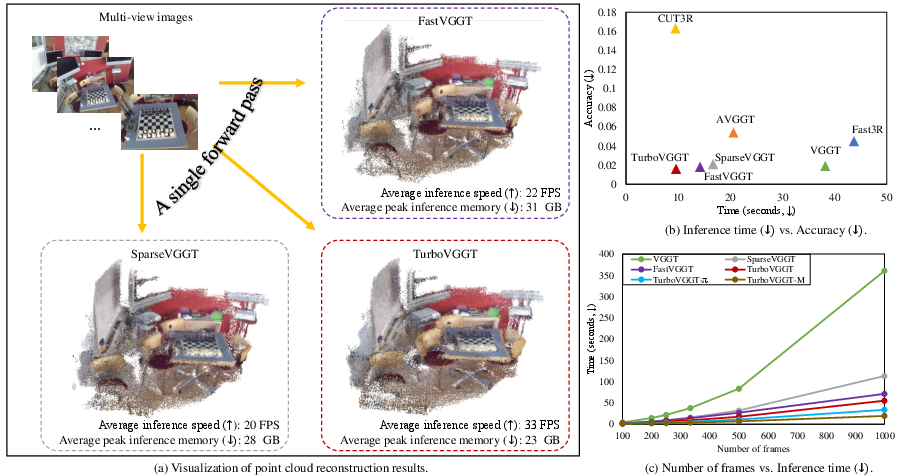
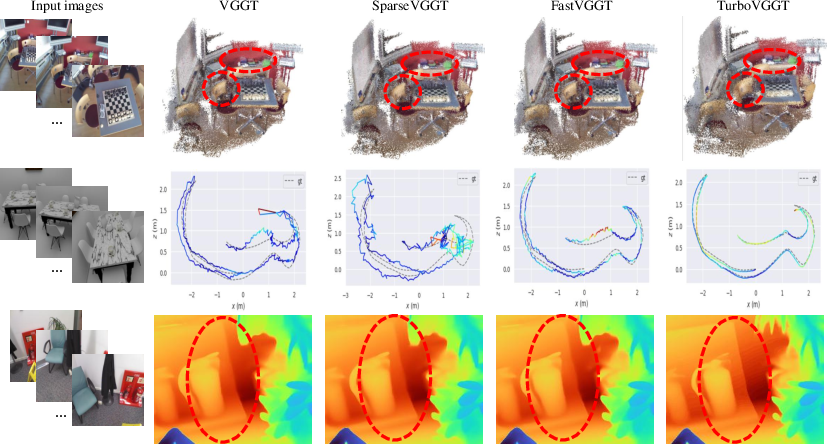
On several well-known datasets (like 7-Scenes, N-RGBD, and ScanNet), TurboVGGT:
- Runs much faster than earlier methods (often 2–4× faster than the popular VGGT on common settings).
- Scales better to long sequences (on 1000 frames, TurboVGGT and its variants reach about 7×, 11×, and 18× speedups compared to VGGT).
- Keeps or improves accuracy in key tasks:
- 3D point clouds: similar or better quality while being faster.
- Camera poses: higher or comparable accuracy, with much shorter time.
- Depth maps: best or near-best results on several tests, again with faster processing.
They also show the idea works with different base models (like π³ and MapAnything), not just one, which suggests it’s broadly useful.
Why does this matter?
- Faster 3D from video: This helps robots, AR/VR, and drones build 3D maps in near real time.
- Better use of memory and energy: Processing fewer, smarter tokens means less hardware strain and lower costs.
- Scales to long videos: The method remains efficient even when there are hundreds or thousands of frames.
Bottom line
TurboVGGT teaches a 3D reconstruction model to be picky and smart about where it spends its attention. By adaptively choosing fewer, more important pieces of information for the global steps—and alternating with detailed per-image refinement—it achieves a strong balance of speed and accuracy. This could make high-quality, real-time 3D understanding more practical for everyday applications like autonomous navigation and augmented reality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research:
- Lack of theoretical or formal complexity analysis
- No asymptotic compute/memory complexity is derived for adaptive sparsity selection or adaptive sparse global attention; only empirical runtimes are reported.
- No principled analysis of when the proposed cross-attention with compressed tokens is provably beneficial or its worst-case behavior.
- Memory footprint is not quantified
- Peak GPU memory is only qualitatively claimed to improve; exact memory usage and scaling with frames/resolution are not reported across methods and datasets.
- Training stability and routing details are under-specified
- The gating/routing mechanism (soft vs. hard assignment, gradient flow through non-selected branches, use of Gumbel-Softmax/straight-through estimators) is not described; stability and convergence properties are unclear.
- Potential collapse modes (e.g., over-selecting highest-sparsity branch) under the sparsity-encouraging regularizer are not analyzed or mitigated.
- Weight matrix construction for token compression is ambiguous
- The paper does not specify normalization of (e.g., row-/column-stochastic via softmax), non-negativity, orthogonality, or diversity constraints to avoid degenerate or redundant compressed tokens.
- Computational overhead of generating per frame and layer is not analyzed; net speed gains vs. this overhead are not quantified.
- Coverage/representativeness guarantees are missing
- There is no mechanism to ensure the compressed tokens cover diverse, structurally informative regions across frames; risks include losing fine details or missing low-texture but geometrically salient areas.
- No analysis of how compression affects small/thin structures or highly repetitive textures.
- Discrete, handpicked sparsity branches are not justified
- The choice of exactly three branches with fixed ratios {75%, 89%, 94%} lacks rationale and sensitivity analysis; it is unknown whether continuous sparsity or different ratios would perform better.
- The number of branches and per-layer/per-stage placement are not systematically ablated.
- Frame-level gating may be too coarse
- Gating uses frame-aggregated features (e.g., average pooling), potentially discarding spatial cues relevant to token importance; finer-grained (region-/token-level) or multi-scale gating remains unexplored.
- Interaction with permutation-equivariance is under-explored
- How adaptive sparsity and frame-wise routing interact with permutation-equivariant architectures (e.g., ) is not analyzed beyond a speed benchmark; potential equivariance violations or subtle accuracy trade-offs are unstudied.
- Robustness and generalization gaps
- No dedicated evaluation on dynamic scenes, severe motion blur, extreme illumination changes, or strong occlusions—despite training exposure to some dynamic datasets.
- Generalization to outdoor driving (e.g., KITTI, Waymo), large-scale urban benchmarks (e.g., Tanks and Temples, ETH3D), or handheld smartphone captures is not assessed.
- Sensitivity to sparse, long-baseline, or low-overlap view sets is not explicitly studied.
- Resolution scaling and high-res regimes are not evaluated
- Training caps resolution at 518 px; scalability of accuracy/speed to higher resolutions (e.g., 1–2K) remains unknown.
- Streaming and online inference are not addressed
- The approach assumes batch processing of all frames; incremental/streaming variants (compute reuse, cached representations) are not discussed or benchmarked.
- Edge deployment and energy footprint are unexplored
- No measurements on mobile/edge hardware, mixed precision/quantization robustness, or energy-per-frame are provided.
- Baseline and measurement fairness are unclear
- Hardware specs, batch sizes, image resolutions, and preprocessing are not fully standardized across methods; reproducibility and fair-speed comparisons need clearer documentation.
- Incomplete evaluation of long-sequence scaling limits
- Claims of 7–18× speedups at 1000 frames are shown qualitatively; accuracy and drift behavior on very long sequences (e.g., >2K frames) and failure cases are not deeply analyzed.
- Loss design and hyperparameter sensitivity are thinly ablated
- The impact of the sparsity-regularization weight , the entropy term, and alternative regularizers (e.g., coverage/diversity) on quality/speed trade-offs is not reported.
- How performance varies with the number of adaptive blocks or their placement is not reported.
- Limited comparison to alternative efficient attention paradigms
- No direct comparisons to low-rank, Nyström, Performer-/linear-attention, Perceiver-style latent queries, or learned landmarks as alternative global modeling strategies.
- Potential quality trade-offs are not deeply characterized
- Where TurboVGGT underperforms (e.g., some N-RGBD metrics), the failure modes and which structures degrade under compression are not investigated or visualized.
- Camera parameter metrics and absolute scale are not analyzed
- While metric scaling factors are predicted, absolute scale errors, intrinsics estimation robustness, and sensitivity to calibration noise are not reported.
- Dataset bias and domain shift risks
- Training uses a curated multi-dataset mixture; robustness to new capture devices, compression artifacts, HDR scenes, or fisheye/wide-angle intrinsics is not evaluated.
- Mesh/surface reconstruction is out of scope
- The method outputs point/depth/pose; downstream meshing fidelity, normals consistency at surfaces, and artifacts post-surface reconstruction are not evaluated.
- Code-level clarity and mathematical specification issues
- Some equations appear inconsistent or partially specified (e.g., dimensions and brackets for and , loss notation), hindering exact reproduction; a more precise mathematical specification would help.
- Interpretability of learned sparsity and tokens
- There is no analysis of what regions/tokens the model prefers across datasets, how these align with classical keypoints, and how selections evolve across layers.
- Failure-case exploration and safety bounds
- No systematic study of worst-case scenarios where dense global attention is necessary (i.e., when most tokens are “important”), or of fallback mechanisms to maintain accuracy when compression harms performance.
Practical Applications
Immediate Applications
Below are concrete, deployable-now use cases that leverage TurboVGGT’s faster, scalable multi-view 3D reconstruction (adaptive alternating attention, adaptive sparsity selection, and adaptive sparse global attention). Each item includes sector alignment and feasibility notes.
- Robotics: faster on-robot 3D mapping and navigation
- Use case: Drop-in replacement for slow feed-forward 3D recon modules (e.g., VGGT) in SLAM-lite pipelines for mobile robots, AMRs, and drones to produce depth, point clouds, and poses with lower latency.
- Tools/workflows: ROS node wrapping TurboVGGT; on-robot pipeline (camera → TurboVGGT → pose/depth → local planner); fallback to frame attention-only when bandwidth is limited.
- Dependencies/assumptions: Sufficient on-board GPU (e.g., RTX/Jetson-class), multi-view RGB input, generalization to deployment domain; performance subject to lighting/motion blur.
- AR/VR/XR: room-scale scanning and live scene understanding
- Use case: Rapid room scanning from smartphone video for AR content placement or VR environment synthesis with shorter cloud processing times.
- Tools/workflows: Mobile app uploads video → cloud TurboVGGT inference → mesh via Poisson reconstruction → AR anchor export to Unity/Unreal.
- Dependencies/assumptions: Reliable multi-view capture, server-side GPU; privacy/consent for indoor scans.
- AEC (Architecture, Engineering, Construction): as-built updates and progress monitoring
- Use case: Rapid turn-around 3D recon from site walk-throughs to update BIM models or progress dashboards.
- Tools/workflows: Site video ingestion → TurboVGGT camera poses/depth → meshing → BIM diff tool to highlight changes.
- Dependencies/assumptions: Consistent site coverage, material reflectance challenges; alignment to BIM coordinates may require external control points.
- Media, VFX, and Gaming: faster asset capture from video
- Use case: Quicker reconstruction of sets/props from multi-view videos for previsualization and environment prototyping.
- Tools/workflows: Studio pipeline plug-in (DCC tools) calling TurboVGGT → mesh cleanup → texturing.
- Dependencies/assumptions: Textureless surfaces and shiny objects remain challenging; artistic cleanup still needed.
- E-commerce and Retail: 3D product digitization at scale
- Use case: Turntable or handheld capture pipelines with higher throughput due to reduced inference time.
- Tools/workflows: Turntable capture rig → TurboVGGT → automatic background segmentation/meshing → GLB export for web viewers.
- Dependencies/assumptions: Lighting control, capture consistency; small objects with fine features may need higher-res captures.
- Cultural Heritage and Museums: digitization of artifacts and spaces
- Use case: Faster backlog processing for multi-view photo collections, enabling larger collections to be reconstructed on a fixed compute budget.
- Tools/workflows: Batch processing queue leveraging TurboVGGT → mesh → archiving and public dissemination.
- Dependencies/assumptions: Delicate/reflective artifacts may need multi-illumination strategies; metadata standards adherence.
- Insurance and Real Estate: rapid interior scans for claims and listings
- Use case: Near-real-time turnaround of room scans to support claim triage or listing walkthroughs.
- Tools/workflows: Client app capture → TurboVGGT processing → automatic room measurements and floor plan derivation.
- Dependencies/assumptions: Sufficient coverage, network connectivity; regulatory compliance for data handling.
- Infrastructure and Energy: drone-based inspection with quicker feedback
- Use case: Faster 3D recon of towers, solar farms, or turbines from inspection flights, enabling same-day reporting.
- Tools/workflows: Flight plan → video capture → TurboVGGT → defect localization via 3D differencing against previous inspections.
- Dependencies/assumptions: Wind-induced motion blur, scale ambiguity outdoors; GPS/IMU can help global alignment.
- Research and Dataset Creation (Academia/Industry): higher-throughput 3D ground-truth generation
- Use case: Faster generation of camera pose/depth/point maps for benchmarks or as weak labels for training NeRFs or 3D-aware models.
- Tools/workflows: Dataset curation pipeline with TurboVGGT → QC dashboards → export to Open3D/COLMAP/NeRF trainers.
- Dependencies/assumptions: Domain shift handling; quality checks for long-tail scenarios.
- Software acceleration: cost- and memory-efficient cloud services
- Use case: Reduce GPU-hours and peak memory for 3D reconstruction services; support longer videos (hundreds–thousands of frames) per job.
- Tools/workflows: Replace global attention with TurboVGGT adaptive sparse global attention; autoscaling microservices; budget-aware gating policies.
- Dependencies/assumptions: Integration effort with existing backends; consistent performance for varying sequence lengths.
- Developer tools: SDKs and plug-ins
- Use case: Provide a TurboVGGT SDK and engine plug-ins (Unity/Unreal/Blender) for developers to embed fast 3D recon in apps and pipelines.
- Tools/workflows: PyTorch/C++ inference APIs; ONNX export with custom attention kernels; Unity/Unreal wrappers.
- Dependencies/assumptions: Availability of optimized kernels (e.g., FlashAttention), GPU support on target platforms.
- Education: rapid creation of curricular 3D assets
- Use case: Teachers and students convert lab/classroom scenes into 3D assets quickly for interactive lessons.
- Tools/workflows: Classroom capture → TurboVGGT → simplified meshes → web deployment (glTF).
- Dependencies/assumptions: School device capture quality; simple UI for non-experts.
Long-Term Applications
These opportunities need additional research, scaling, or engineering (e.g., on-device optimization, robustness in edge cases, regulatory frameworks).
- On-device real-time AR glasses SLAM alternative
- Sector: AR/XR, Consumer Electronics
- Potential: TurboVGGT-inspired adaptive sparse attention in low-power packages for continuous, low-latency 3D understanding on wearables.
- Dependencies/assumptions: Hardware acceleration of attention, quantization/pruning, thermal constraints, monocular metric scale handling.
- City-scale mapping and live digital twins
- Sector: Smart Cities, Public Works, Mobility
- Potential: Swarms of drones/vehicles stream frames for near-real-time, city-block reconstructions driving urban planning and traffic simulations.
- Dependencies/assumptions: Distributed compute, networking, GPS/IMU fusion, multi-agent coordination, data governance and privacy.
- Real-time teleoperation and remote inspection with 3D map streaming
- Sector: Robotics, Energy, Manufacturing
- Potential: Operators receive continuously updated 3D maps with low latency for safer remote control in hazardous sites.
- Dependencies/assumptions: Robustness to motion blur/dynamics, bandwidth-aware streaming of tokens/meshes, safety certifications.
- Surgical theater and intraoperative 3D guidance
- Sector: Healthcare
- Potential: Fast, feed-forward 3D recon from endoscopic/multi-camera rigs to overlay depth and poses for navigation.
- Dependencies/assumptions: Medical-grade validation, domain-specific training, strict precision/latency requirements, regulatory clearance.
- Consumer-grade room scanning entirely on mobile
- Sector: Consumer Apps, Real Estate
- Potential: Native on-phone processing with minimal cloud reliance for privacy and instant results.
- Dependencies/assumptions: Mobile GPU/NPUs with optimized attention kernels; thermal and battery constraints; robust performance on handheld jitter.
- Training accelerators for NeRFs and 3D generative models
- Sector: AI/ML, Content Creation
- Potential: TurboVGGT outputs serve as high-quality initializations (poses, depth) to shorten training time of NeRFs or 3D diffusion models; token sparsity ideas reused in 3D-aware backbones.
- Dependencies/assumptions: Tight integration with training loops; proven reductions in overall convergence time across datasets.
- Continuous inventory and layout monitoring in retail/warehouses
- Sector: Retail, Logistics
- Potential: Overhead/mast cameras reconstruct shelves/aisles to detect stock-outs, planograms, and obstacles in near real time.
- Dependencies/assumptions: Fixed camera networks, occlusion handling, domain adaptation to reflective packaging, systems integration.
- Agricultural phenotyping and yield estimation
- Sector: Agriculture
- Potential: Faster plant/canopy reconstructions from drone or rover video to support growth monitoring and trait analysis.
- Dependencies/assumptions: Outdoor lighting variability, texture sparsity in crops, integration with agronomic analytics.
- Integrated 3D privacy and compliance frameworks
- Sector: Policy/Government, Legal
- Potential: Standards and auditing tools to ensure responsible 3D capture (consent, redaction of sensitive content) as 3D scanning becomes ubiquitous due to lower compute costs.
- Dependencies/assumptions: Cross-industry consensus, technical tooling for 3D de-identification (face/object anonymization), enforcement mechanisms.
- Carbon-aware compute scheduling for 3D recon services
- Sector: Cloud/IT, Sustainability
- Potential: Because TurboVGGT reduces inference time and memory, services can batch workloads in low-carbon windows; add dynamic sparsity budgets to meet carbon constraints.
- Dependencies/assumptions: Carbon accounting integration, SLA-aware schedulers, validation of quality under higher sparsity.
- New research directions: adaptive attention for multimodal geometry
- Sector: Academia/Research
- Potential: Extend adaptive sparsity and representative token learning to fuse LiDAR, event cameras, and thermal imagery for robust 3D in adverse conditions.
- Dependencies/assumptions: Multimodal datasets, architectural changes for heterogeneous tokens, synchronization across sensors.
- Standards for interoperable 3D outputs
- Sector: Policy/Standards Bodies
- Potential: Define minimal metadata and quality metrics for fast, feed-forward 3D recon outputs (poses, depths, confidences) to ensure interchangeability across tools.
- Dependencies/assumptions: Industry collaboration, alignment with existing formats (glTF, USD), QA protocols.
Notes on Feasibility and Dependencies Across Applications
- Model characteristics: TurboVGGT is trained on diverse scenes and shows strong generalization, but domain-specific tuning may be necessary (e.g., medical, retail).
- Compute: Significant speedups (2–4× vs. VGGT in benchmarks; up to 7–18× on 1000-frame sequences) reduce GPU costs; however, real-time edge deployment still requires careful optimization (kernel fusion, mixed precision, quantization).
- Inputs: Multi-view RGB sequences and adequate coverage are assumed; monocular scale ambiguity may need external cues (IMU, known object sizes) in some settings.
- Outputs and post-processing: Depth/poses/point maps typically need meshing and optional texture baking; integration with mapping and alignment tools (e.g., Open3D, COLMAP) is common.
- Ethics and compliance: Faster, cheaper scanning increases volume and sensitivity of 3D data; privacy, consent, and secure storage must be planned from the outset.
Glossary
- AdamW: An optimizer that combines Adam with decoupled weight decay for stable, efficient training. "We train our TurboVGGT on 8 GPUs for 10 epochs using AdamW optimizer with a cosine annealing learning rate and a 1-epoch warm-up schedule."
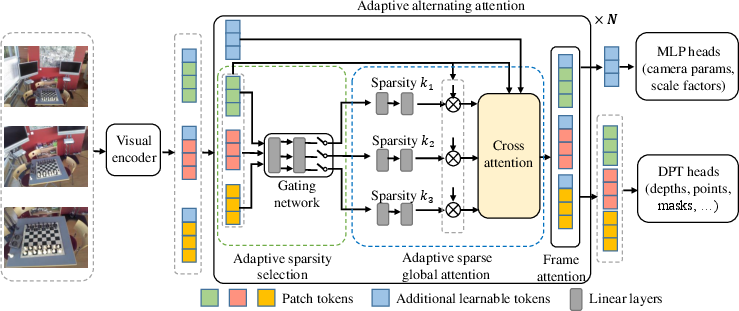
- Adaptive alternating attention: A transformer design that alternates between global and per-frame attention, with adaptively chosen sparsity, to balance efficiency and accuracy. "a novel approach that employs an efficient visual geometry transformer with adaptive alternating attention for fast multi-view 3D reconstruction."
- Adaptive sparse global attention: A global attention mechanism that selects and attends to a learned subset of representative tokens per frame to reduce computation while modeling cross-view geometry. "Specifically, TurboVGGT employs an end-to-end trainable framework with adaptive sparse global attention guided by adaptive sparsity selection to capture global relationships across frames and frame attention to aggregate local details within each frame."
- Adaptive sparsity selection: A mechanism that routes each frame to a branch with a different sparsity ratio, chosen per layer and per frame, to match token importance. "We propose an adaptive sparsity selection mechanism for visual geometry transformers, which adaptively selects different sparsity ratios for different frames across different layers."
- Absolute Relative Error (AbsRel): A depth metric measuring the mean absolute difference between predicted and true depths relative to ground truth. "For depth estimation, we report Absolute Relative Error (AbsRel, ) and ratio () on 7-Scenes, N-RGBD, and Sintel."
- Area Under the accuracy-threshold Curve (AUC@30): Camera-pose metric computed as the area under the accuracy-threshold curve (up to 30) for the minimum of rotation and translation accuracies. "the Area Under the accuracy-threshold Curve for the minimum of RRA and RTA (AUC@30, ) on 7-Scenes, N-RGBD, and RealEstate10K."
- Block-sparse attention: An attention variant that limits computations to predefined blocks to reduce complexity. "there have been some recent efforts employing token merging~\cite{shen2026fastvggt}, block-sparse attention~\cite{wang2025faster}, subsampling global attention~\cite{sun2025avggt}, and compressed descriptors~\cite{wang2025flashvggt} to accelerate visual geometry transformers."
- Bundle adjustment: Nonlinear optimization that jointly refines camera parameters and 3D structure to minimize reprojection error. "The traditional paradigm consists of multiple stages, such as feature extraction and matching, camera pose estimation, triangulation, and bundle adjustment."
- Camera extrinsics: Parameters describing a camera’s pose in the world (rotation and translation). "They can directly predict camera intrinsics, camera extrinsics, depth maps, point maps, and other geometric properties from multi-view images in a single forward pass."
- Camera intrinsics: Parameters describing a camera’s internal geometry (e.g., focal length, principal point). "They can directly predict camera intrinsics, camera extrinsics, depth maps, point maps, and other geometric properties from multi-view images in a single forward pass."
- Camera tokens: Learnable tokens that encode per-frame camera information within the transformer input. "we also append additional learnable tokens, such as camera tokens and register tokens, to the sequence of patch tokens as the input to the subsequent modules."
- Chamfer Distance (CD): A symmetric distance between two point sets used to evaluate reconstructed point clouds. "and Chamfer Distance (CD, ) on ScanNet."
- Compressed representative tokens: Aggregated token set that summarizes informative regions per frame for efficient global attention. "we propose to learn compressed representative tokens for each frame and employ cross-attention between the compressed tokens and the dense tokens to capture global correspondences across frames."
- Confidence maps: Per-pixel estimates indicating the reliability of predictions such as depth or point maps. "DPT heads~\cite{ranftl2021vision} are used to predict depth maps, point maps, confidence maps, etc."
- Completeness (Comp): A point cloud metric measuring how completely the reconstructed geometry covers the ground truth. "For point cloud reconstruction, we report Accuracy (Acc, ), Completeness (Comp, ), and Normal Consistency (NC, ) on 7-Scenes and N-RGBD"
- Cosine annealing learning rate: A schedule that decreases the learning rate following a cosine curve. "We train our TurboVGGT on 8 GPUs for 10 epochs using AdamW optimizer with a cosine annealing learning rate and a 1-epoch warm-up schedule."
- Cross-attention: An attention mechanism where queries attend to keys/values from a different token set. "We then perform cross-attention between and all dense tokens to capture global correspondences across frames"
- Depth map: An image where each pixel encodes the scene depth along the camera’s viewing ray. "DPT heads~\cite{ranftl2021vision} are used to predict depth maps, point maps, confidence maps, etc."
- DINOv2: A pretrained vision transformer backbone used for feature extraction. "we first employ a visual encoder (e.g., DINOv2~\cite{oquab2024dinov2}) to extract patch tokens from each image"
- DPT heads: Dense Prediction Transformer heads used for high-resolution per-pixel predictions. "DPT heads~\cite{ranftl2021vision} are used to predict depth maps, point maps, confidence maps, etc."
- Entropy term: A regularization that encourages confident (low-entropy) routing decisions in branch selection. "Additionally, we can add an entropy term to the sparsity regularization loss to push each frame in each layer to route decisively to a specific branch,"
- Feed-forward 3D reconstruction: Direct prediction of 3D geometry in a single network pass without per-scene iterative optimization. "Recent feed-forward 3D reconstruction methods, such as visual geometry transformers, have substantially advanced the traditional per-scene optimization paradigm"
- FlashAttention: A memory- and speed-optimized attention algorithm for transformers. "To make vision transformers more efficient, various strategies have been used, such as FlashAttention~\cite{dao2022flashattention,dao2023flashattention}, sparse attention~\cite{wei2023sparsifiner,zhang2025spargeattention}, token merging~\cite{bolya2023token,zeng2022not}, and low-rank approximation~\cite{jaegle2021perceiver,han2024agent}."
- Frame attention: Self-attention applied within each frame to aggregate local, intra-frame details. "and frame attention to aggregate local details within each frame."
- Gating network: A small network (e.g., MLP) that produces routing scores to select sparsity branches per frame. "TurboVGGT employs a gating network to adaptively assign different sparsity ratios for different frames across global attention layers."
- Global full attention: Standard all-to-all attention across tokens from all frames, incurring high cost. "State-of-the-art visual geometry transformers~\cite{wang2025vggt,keetha2026mapanything} typically employ alternating attention blocks consisting of frame-wise self-attention and cross-frame global full attention."
- Keypoint detection and matching: Traditional technique to find and correlate salient image features across views for geometry estimation. "Traditional multi-view 3D reconstruction methods~\cite{schonberger2016structure,schonberger2016pixelwise} typically capture global correspondences across frames by keypoint detection and matching rather than dense pixel-wise matching."
- Learnable tokens: Parameterized tokens added to the token sequence to encode auxiliary information. "we also append additional learnable tokens, such as camera tokens and register tokens, to the sequence of patch tokens as the input to the subsequent modules."
- Low-rank approximation: Approximating matrices with low-rank factors to reduce computation and memory in attention. "To make vision transformers more efficient, various strategies have been used, such as FlashAttention~\cite{dao2022flashattention,dao2023flashattention}, sparse attention~\cite{wei2023sparsifiner,zhang2025spargeattention}, token merging~\cite{bolya2023token,zeng2022not}, and low-rank approximation~\cite{jaegle2021perceiver,han2024agent}."
- Metric scaling factors: Scalars used to convert relative outputs into metric (absolute) scale. "MLP heads~\cite{wang2025vggt,keetha2026mapanything} are used to predict camera parameters and metric scaling factors"
- Multi-View Stereo (MVS): A pipeline that reconstructs dense 3D geometry from multiple images using known or estimated camera poses. "Traditional methods, such as Structure-from-Motion (SfM)~\cite{schonberger2016structure} and Multi-View Stereo (MVS)~\cite{schonberger2016pixelwise}, typically employ a multi-stage paradigm to estimate camera poses and reconstruct 3D geometry."
- Multi-view 3D reconstruction: Recovering 3D scene geometry from a set of images captured from different viewpoints. "Multi-view 3D reconstruction is a long-standing problem in computer vision."
- Normal Consistency (NC): A point cloud metric assessing consistency of surface normals between prediction and ground truth. "For point cloud reconstruction, we report Accuracy (Acc, ), Completeness (Comp, ), and Normal Consistency (NC, ) on 7-Scenes and N-RGBD"
- Patch tokens: Tokenized image patches produced by the visual encoder for transformer processing. "we first employ a visual encoder (e.g., DINOv2~\cite{oquab2024dinov2}) to extract patch tokens from each image"
- Peak GPU memory usage: The maximum GPU memory consumed during inference or training. "TurboVGGT significantly improves computational efficiency in terms of inference time and peak GPU memory usage."
- Permutation-equivariant architecture: A model whose outputs are consistent under permutations of the input order. "~\cite{wang2025pi} is a subsequent work that introduces a fully permutation-equivariant architecture to eliminate the reliance on a fixed reference view in VGGT."
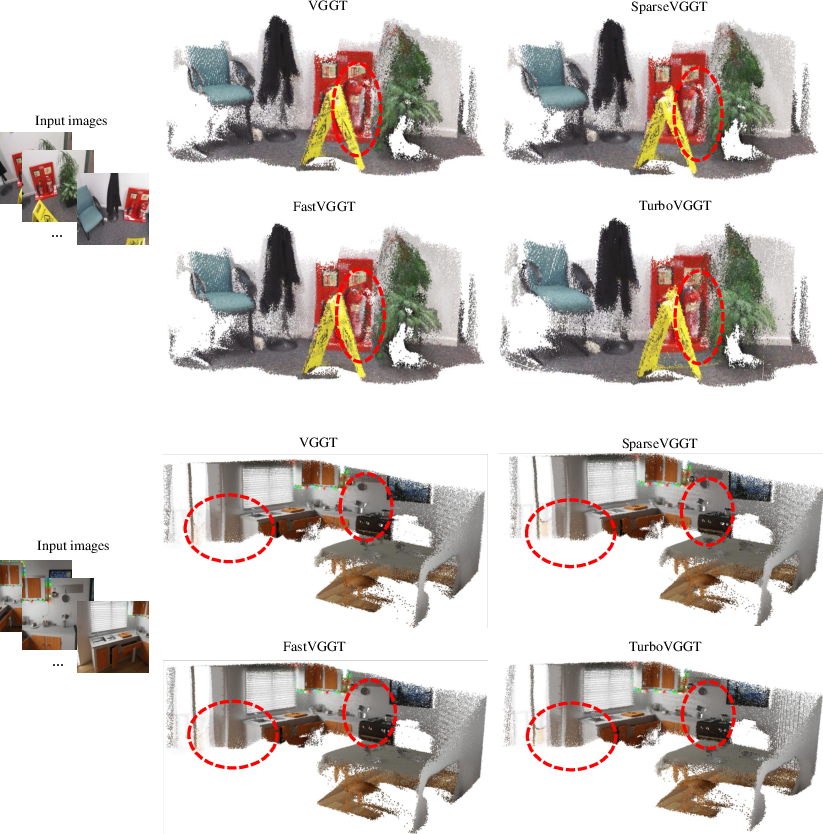
- Point cloud: A set of 3D points representing the geometry of a scene, often used to evaluate reconstruction quality. "(a) Visualization of point cloud reconstruction results."
- Point map: Per-pixel predictions of 3D point coordinates in camera space or a global frame. "enabling efficient and robust estimation of camera poses, depth maps, and point maps in a single forward pass."
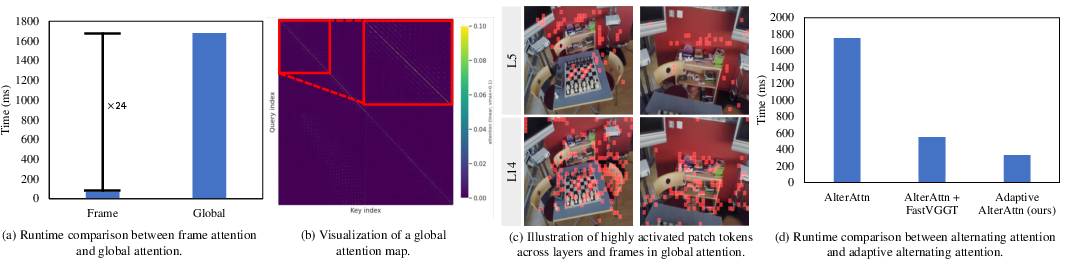
- Quadratic complexity: Computational cost that scales with the square of the number of tokens, typical of dense attention. "the dense global token interactions within global attention layers, which involve quadratic complexity with respect to the number of input tokens."
- Register tokens: Auxiliary learnable tokens used to stabilize or align token representations across frames. "we also append additional learnable tokens, such as camera tokens and register tokens, to the sequence of patch tokens as the input to the subsequent modules."
- Relative Rotation Accuracy (RRA@30): Fraction of pose estimates whose relative rotation error is within a 30-threshold. "For camera pose estimation, we report Relative Rotation Accuracy (RRA@30, ), Relative Translation Accuracy (RTA@30, ), and the Area Under the accuracy-threshold Curve for the minimum of RRA and RTA (AUC@30, )"
- Relative Translation Accuracy (RTA@30): Fraction of pose estimates whose relative translation error is within a 30-threshold. "For camera pose estimation, we report Relative Rotation Accuracy (RRA@30, ), Relative Translation Accuracy (RTA@30, ), and the Area Under the accuracy-threshold Curve for the minimum of RRA and RTA (AUC@30, )"
- Sparsity ratio: The proportion of tokens retained (or pruned) in sparse attention, controlling computation. "they typically use the same sparsity ratio across layers and frames."
- Sparse attention: Attention computed over a subset of token pairs to reduce cost. "To make vision transformers more efficient, various strategies have been used, such as FlashAttention~\cite{dao2022flashattention,dao2023flashattention}, sparse attention~\cite{wei2023sparsifiner,zhang2025spargeattention}, token merging~\cite{bolya2023token,zeng2022not}, and low-rank approximation~\cite{jaegle2021perceiver,han2024agent}."
- Sparsity regularization loss: A loss term encouraging the model to choose higher sparsity (fewer tokens) during routing. "For the sparsity regularization loss $\mathcal{L}_{\text{reg}$, it is used to encourage the model to select larger sparsity levels for different layers and frames"
- Structure-from-Motion (SfM): A pipeline that estimates camera poses and reconstructs sparse 3D structure from multiple views. "Traditional methods, such as Structure-from-Motion (SfM)~\cite{schonberger2016structure} and Multi-View Stereo (MVS)~\cite{schonberger2016pixelwise}, typically employ a multi-stage paradigm to estimate camera poses and reconstruct 3D geometry."
- Token merging: Combining similar tokens to reduce the number of tokens processed by attention. "existing methods typically use token merging, sparse attention or token subsampling strategies to reduce the number of tokens involved in the global attention."
- Token subsampling: Selecting a subset of tokens to participate in attention to lower computational cost. "existing methods typically use token merging, sparse attention or token subsampling strategies to reduce the number of tokens involved in the global attention."
- Visual encoder: The front-end network that converts images into a sequence of tokens for transformer processing. "we first employ a visual encoder (e.g., DINOv2~\cite{oquab2024dinov2}) to extract patch tokens from each image"
- Visual geometry transformer: A transformer model designed to infer multi-view geometric quantities like poses, depth, and point maps in a single pass. "Visual geometry transformers~\cite{wang2025vggt,keetha2026mapanything,wang2025pi,zhuo2026streaming} have recently emerged as powerful models for feed-forward multi-view 3D reconstruction."
- Warm-up schedule: A brief initial phase where the learning rate is gradually increased to stabilize training. "We train our TurboVGGT on 8 GPUs for 10 epochs using AdamW optimizer with a cosine annealing learning rate and a 1-epoch warm-up schedule."
- Weight matrix: A learned matrix used to aggregate patch tokens into a smaller set of representative tokens. "we employ an MLP to generate a weight matrix for tokens of each frame"
Collections
Sign up for free to add this paper to one or more collections.