GPA-VGGT:Adapting VGGT to Large scale Localization by self-Supervised learning with Geometry and Physics Aware loss
Abstract: Transformer-based general visual geometry frameworks have shown promising performance in camera pose estimation and 3D scene understanding. Recent advancements in Visual Geometry Grounded Transformer (VGGT) models have shown great promise in camera pose estimation and 3D reconstruction. However, these models typically rely on ground truth labels for training, posing challenges when adapting to unlabeled and unseen scenes. In this paper, we propose a self-supervised framework to train VGGT with unlabeled data, thereby enhancing its localization capability in large-scale environments. To achieve this, we extend conventional pair-wise relations to sequence-wise geometric constraints for self-supervised learning. Specifically, in each sequence, we sample multiple source frames and geometrically project them onto different target frames, which improves temporal feature consistency. We formulate physical photometric consistency and geometric constraints as a joint optimization loss to circumvent the requirement for hard labels. By training the model with this proposed method, not only the local and global cross-view attention layers but also the camera and depth heads can effectively capture the underlying multi-view geometry. Experiments demonstrate that the model converges within hundreds of iterations and achieves significant improvements in large-scale localization. Our code will be released at https://github.com/X-yangfan/GPA-VGGT.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a computer to figure out where a camera is and how it’s moving (its “pose”), and how far away things are in a scene (their “depth”), by only looking at videos—no human-made labels needed. The authors build on a powerful model called VGGT (a Transformer for 3D vision) and create a new training method, called GPA-VGGT, that helps it work well in big, messy, real-world places like city streets. The key idea is to use simple physics and geometry rules as “self-supervision,” so the model can learn from raw video without answers provided.
What questions does the paper try to answer?
The paper focuses on three simple questions:
- How can we train a 3D vision model on unlabeled videos and still get accurate camera positions and depths?
- How can we make the model stay consistent over long trips (like a car driving for minutes), not just a few frames?
- How can we ignore parts of the scene that break the rules (like moving cars, people, or sudden lighting changes) so the model doesn’t get confused?
How does the method work? (Explained with everyday ideas)
Think of watching a short clip: five nearby frames are like pages in a flipbook. If your 3D understanding is correct, the same spot on a building should line up across pages, and it should look similar unless the light or visibility changes.
Here’s what the method does:
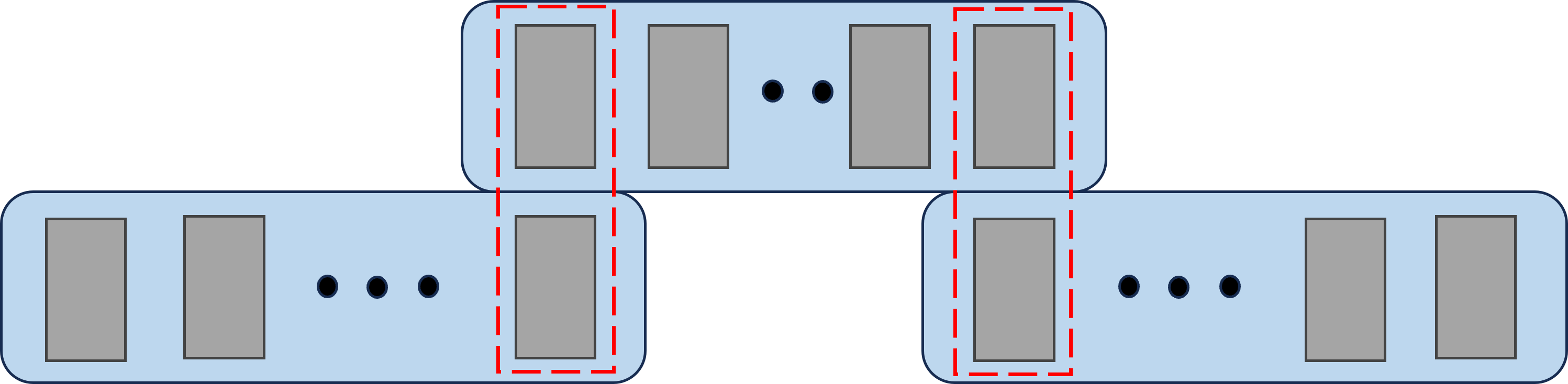
- Slide over the video in small windows: The model looks at a small group of consecutive frames at a time (like reading 5 pages at once), then moves forward and overlaps with the next group. This helps build a long, smooth path for where the camera went.
- Use multiple anchor frames: Instead of always picking one “main” frame, the method rotates which frames act as anchors. This spreads out the geometric checks so weak viewpoints (not much sideways motion) can be balanced by stronger ones later.
- Use physics and geometry rules as “teachers”:
- Photometric consistency: If you project a pixel from one frame into another using the predicted depth and camera motion, it should look about the same. In simple terms: the same spot should have a similar appearance when seen from another angle, if your 3D guess is right.
- Geometric consistency: The 3D point made from one frame should land at the right depth surface in the other frame. This checks the “shape” of the scene matches across views.
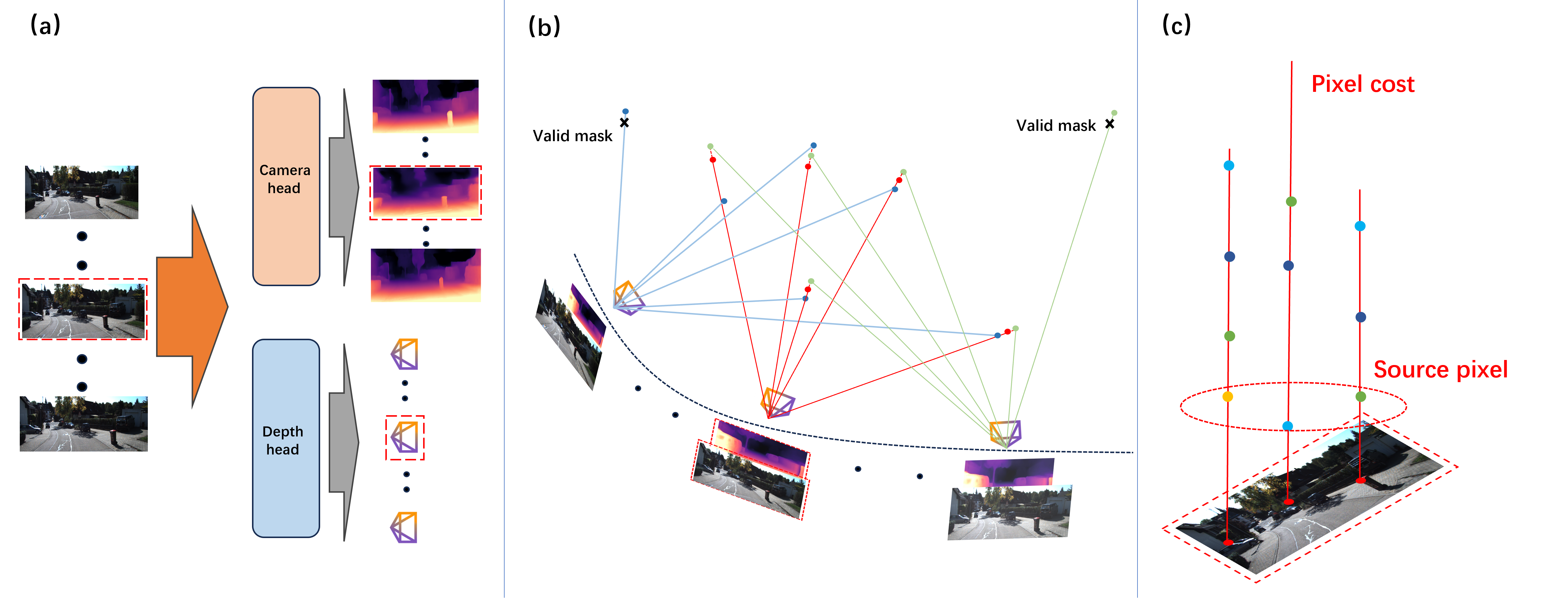
- Pick only the best views for each pixel: Real videos have problems—moving cars, people, occlusions (things blocking other things), and changing light. For each pixel, the method compares all possible source frames and only trusts the one that best follows the physics and geometry rules. This “hard selection” filters out bad matches automatically.
- Auto-masking for outliers: If pretending there’s no motion at all explains a pixel better than the 3D projection does, the method ignores that pixel. This is a simple way to avoid being tricked by moving objects or flat, textureless areas.
- Smooth where it makes sense: A small regularization encourages smooth depth in areas that should be smooth (like walls or roads), while keeping edges sharp.
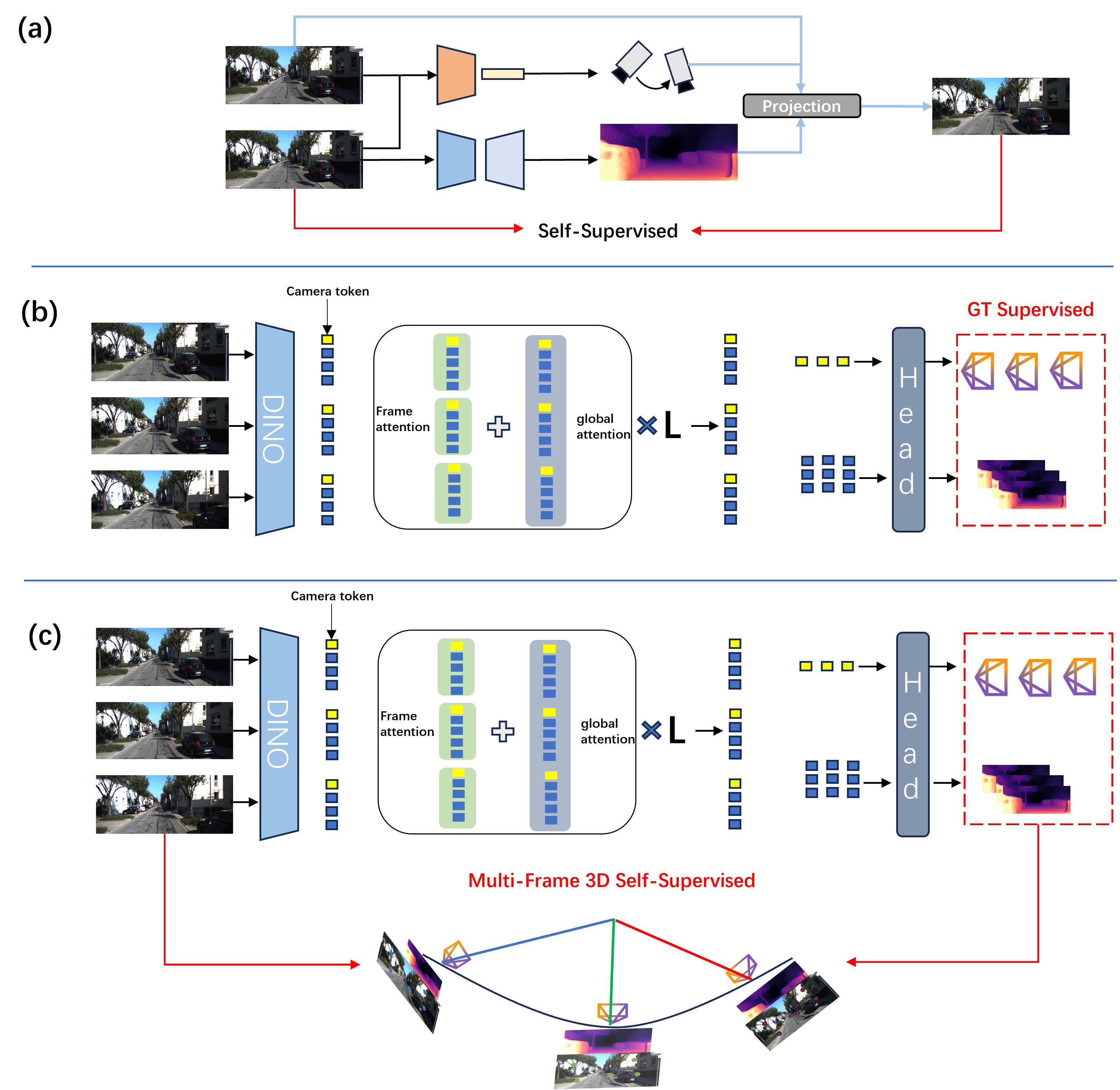
Importantly, the authors do not change the VGGT architecture. They change how it’s trained—by designing better rules (losses) that reflect the real world.
What did they find, and why does it matter?
Main results:
- Fast, stable learning from unlabeled video: The model learns good geometry in a few hundred training iterations—quick for this kind of task.
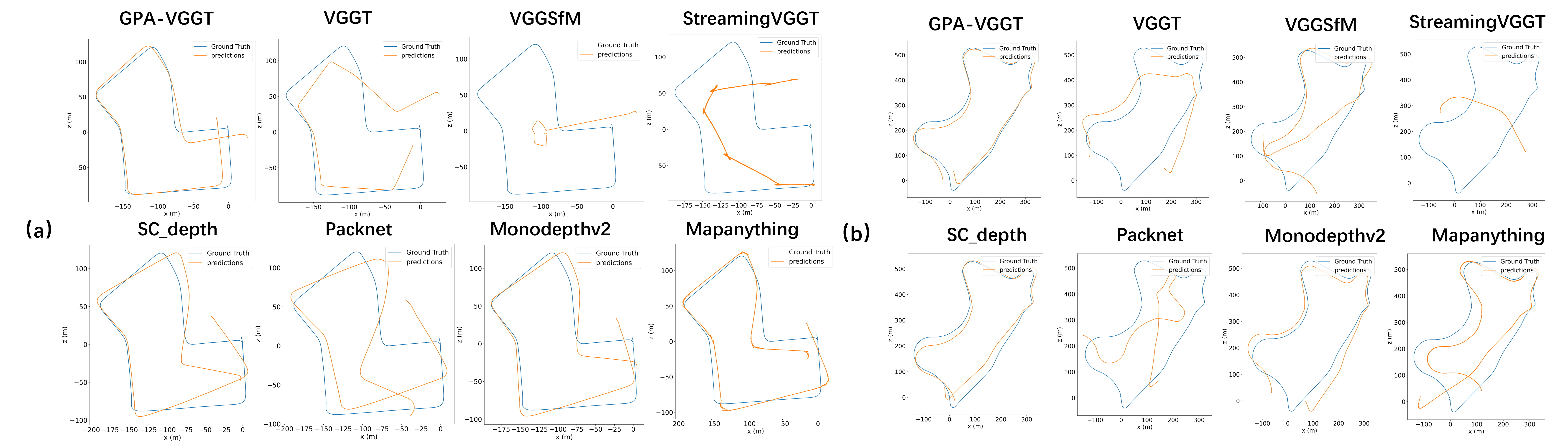
- Better long-distance localization: On a standard driving dataset (KITTI), the method produces more accurate camera paths over long sequences compared to classic self-supervised methods and even several large supervised models. In simple words: it “drifts” less and stays on track better.
- Higher-quality depth: The depth maps are smoother where they should be, sharper at object boundaries, and stay consistent across frames, even with lighting changes.
Why this matters:
- No labels needed: Gathering ground-truth camera poses and depths is expensive and limited. Learning directly from raw video opens the door to using huge amounts of data from new places.
- Works at scale: Many methods work on short clips but fall apart over long trips. This one stays consistent across long distances, which is critical for navigation, mapping, and AR.
- Robust in the real world: The physics-aware filtering makes the method ignore dynamic distractions like traffic and handle challenging lighting, making it more reliable outdoors.
What’s the bigger impact?
This work shows that smart training rules can be as important as a big, fancy model. By teaching a Transformer to respect physical and geometric consistency across many frames, we can:
- Adapt powerful 3D vision models to new cities or environments without labels.
- Improve robot and self-driving car localization using only their onboard cameras.
- Build better, larger-scale 3D maps for AR/VR or city modeling.
In short, GPA-VGGT is a step toward 3D vision systems that learn directly from the world, scale to long journeys, and stay accurate without hand-made answers. The authors plan to release their code, which should help others build on this approach.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concrete list of gaps and unresolved issues that future work could address to strengthen, generalize, and clarify the proposed GPA-VGGT framework.
- Absolute scale recovery remains unclear: the paper claims metric depth and cross-window scale alignment, but does not specify how absolute scale is established in a purely monocular, self-supervised setting or how trajectories are scaled when computing ATE in meters.
- Missing formalization of “cross-window scale alignment”: no algorithmic description, objective, or proof that scale is consistent across chained windows.
- Incomplete and malformed loss equations: several LaTeX expressions for geometric and photometric losses are syntactically broken (e.g., missing braces, undefined variables), preventing precise reproduction; a formal derivation and complete notation is needed.
- Hard-view selection via per-pixel argmin is not analyzed: potential issues like gradient starvation, bias toward nearest frames, and instability from non-differentiable selection are not quantified or contrasted against soft weighting, robust aggregation (e.g., median/trimmed mean), or learned source-view weighting.
- Valid-pixel coverage is unreported: no statistics on how many pixels survive masking and hard-view selection, nor analysis of how supervision density varies across scenes and impacts convergence and quality.
- Sensitivity to hyperparameters is unstudied: no ablations for μ (SSIM vs L1 balance), λ_geo, λ_smooth, δ (auto-masking margin), ε (stability term), window length S, number of anchors N, temporal stride, or overlap; tuning strategies and robustness are unknown.
- Scaling behavior with window length S is not evaluated: inference uses S=5, but the trade-off curves for accuracy, drift, and latency vs. S (and stride) are missing.
- No loop closure or global optimization: the chained sliding windows rely on rigid alignment from overlaps without pose-graph optimization or loop closure; long-range drift behavior and mechanisms to correct it are left unexplored.
- Alignment procedure between windows is unspecified: how the rigid transform is estimated (e.g., least-squares on shared poses, PnP on features, ICP on point maps) and its failure modes are not detailed.
- KITTI-only evaluation limits generality: no cross-dataset tests (e.g., TUM RGB-D, 7-Scenes, ScanNet, ETH3D, Waymo/nuScenes) or indoor/handheld domains to substantiate “generalization” claims.
- Depth evaluation is solely qualitative: no quantitative metrics (e.g., Abs Rel, RMSE, δ thresholds) against LiDAR/stereo ground truth; scale consistency and temporal stability are not quantified.
- Rotation errors are not reported: RPE is given only in meters; rotational RPE/ATE, yaw/pitch/roll drift, and orientation stability are absent.
- Some baselines outperform in RPE: MonoDepth2 shows lower RPE than GPA-VGGT on both sequences, but this discrepancy is not analyzed; conditions under which GPA-VGGT yields lower translation drift but higher local error remain unknown.
- Fairness and protocol parity are unclear: it is not stated whether baselines were retrained/adapted on the same unlabeled KITTI clips, intrinsics, window protocol, and augmentation choices; domain gaps and training differences may confound comparisons.
- Robustness to intrinsics uncertainty is not tested: the method assumes fixed intrinsics K and synchronized augmentation adjustment; sensitivity to calibration errors, focal length drift, lens distortion, or rolling shutter is not addressed.
- Dynamic-scene handling is rudimentary: auto-masking and hard-view selection are adopted from monocular SSL but lack quantitative analysis under varying motion densities, occlusions, specularities, motion blur, and adverse weather.
- Brightness constancy limitations: reliance on SSIM+L1 without learned photometric invariants or feature-space consistency may falter under strong illumination changes; no alternatives (e.g., photometrically robust features) are explored.
- Attention mechanism interpretability is absent: claims that cross-view attention captures multi-view geometry are not supported by probing, visualization, or layer-wise analyses.
- Resource and efficiency profiling is missing: training/inference FLOPs, memory footprint, throughput, latency, and scalability on commodity GPUs/edge devices are not reported.
- Convergence generality is uncertain: “hundreds of iterations” convergence is claimed without learning curves, variance across seeds, different data sizes, or sensitivity to optimizer settings; potential overfitting to KITTI distributions is not ruled out.
- Training from scratch is not tested: dependence on VGGT pretraining is strong; it is unknown whether the proposed losses alone suffice to learn global geometry from random initialization.
- N=3 anchors are fixed without ablation: the benefit of triangular constraints is asserted but not validated across N values or different anchor selection strategies.
- Sliding-window chaining robustness: failure modes when overlaps are weak (fast motion, low texture, heavy occlusion) or when temporal ordering is disrupted are not examined.
- No comparison to SLAM with bundle adjustment: baselines include learned geometry models, but classical or hybrid SLAM systems (with BA, loop closure) are not compared under the same window-chaining protocol.
- Failure-case analyses are missing: scenarios with severe dynamics, low parallax, textureless regions, or repeated patterns are not isolated to understand when hard-view selection and masking break down.
- Unclear handling of rolling shutter and motion blur: physical modeling for these common artifacts is absent; their impact on geometric consistency is unmeasured.
- Multi-camera and sensor fusion are unexplored: applicability to stereo, multi-view rigs, IMU fusion, or depth priors is not discussed.
- Pose-graph consistency and drift bounds: no theoretical or empirical bounds on accumulated drift across long chains or on the stability of rigid alignment over multiple windows.
- Reproducibility gaps: some implementation details (e.g., precise loss weights, selection thresholds, alignment algorithm, training clip sampling distribution) are not fully specified; code release is promised but absent in the paper.
- Evaluation breadth is limited: only sequences 07 and 09 are reported, omitting the rest of KITTI odometry, which may conceal variability or failure modes across different routes and conditions.
- Robustness to extreme viewpoint changes and wide baselines: while wide-baseline supervision is claimed, no controlled study quantifies performance vs. baseline magnitude or field-of-view overlap.
Glossary
- 6-DoF: Six degrees of freedom describing a rigid body's 3 translational and 3 rotational motion parameters. "the model predicts the relative 6-DoF poses between frames."
- AdamW: An optimizer combining Adam with decoupled weight decay for better generalization. "The model is optimized using the AdamW optimizer"
- ATE: Absolute Trajectory Error, a metric measuring drift of an estimated trajectory against ground truth. "ATE (m)"
- Auto-Masking: A technique that masks pixels where motion-based reconstruction does not improve over a no-motion baseline, filtering dynamic or ambiguous regions. "Outlier Rejection via Auto-Masking"
- Bilinearly sampled: Sampling image or depth values using bilinear interpolation over neighboring pixels. "depth bilinearly sampled from the source's predicted depth map."
- Brightness constancy: The assumption that surface appearance remains constant across views, enabling photometric matching. "Based on the brightness constancy assumption,"
- Camera intrinsic matrix: The matrix of internal camera parameters (focal length, principal point, etc.) used for projection. "utilize the shared camera intrinsic matrix ."
- Chained Sliding Window strategy: An inference approach that uses overlapping temporal windows and aligns them through shared frames. "we employ a Chained Sliding Window strategy."
- Cross-view attention layers: Attention mechanisms that aggregate information across different camera views or frames. "not only the local and global cross-view attention layers"
- Cross-window scale alignment: Enforcing consistent scale across overlapping temporal windows to reduce drift. "enforcing cross-window scale alignment"
- DINO: A self-supervised vision transformer backbone used for feature extraction. "the DINO visual backbone"
- Disparity map: The inverse-depth representation indicating pixel-wise depth differences relative to viewpoint. "on the disparity map"
- Ego-motion: The camera’s motion relative to the scene, estimated jointly with depth in monocular settings. "monocular depth and ego-motion"
- Edge-aware smoothness regularization: A depth prior that enforces smoothness while respecting image edges to preserve boundaries. "We apply an edge-aware smoothness regularization"
- Geometric anchors: Selected frames treated as keyframes to enforce multi-view geometric constraints. "serve as geometric anchors (keyframes)"
- Geometry aggregator: A module that aggregates features for global geometric reasoning across views. "the geometry aggregator,"
- Global attention mechanisms: Transformer attention that captures long-range dependencies across the entire input sequence. "these models leverage global attention mechanisms"
- Identity loss: A photometric error computed assuming zero motion, used to detect non-informative or dynamic pixels. "We compute an identity loss"
- Inverse warping: Reconstructing a target view by sampling from a source image using predicted depth and pose. "synthesised via inverse warping"
- KITTI Odometry Benchmark: A standard autonomous driving dataset for evaluating large-scale visual localization. "the KITTI Odometry Benchmark"
- Minimum-Cost Selection Strategy: Selecting, per pixel, the source view with the lowest combined photometric–geometric cost for robust supervision. "Minimum-Cost Selection Strategy."
- Parallax: The apparent displacement of scene points between views that provides depth cues. "low parallax"
- Photometric consistency: The constraint that corresponding pixels across views should have similar appearance if geometry is correct. "Physical Photometric Consistency."
- Photometric reconstruction: Rebuilding a target image from a source view using predicted geometry to supervise learning. "via photometric reconstruction"
- Photometric reconstruction loss: A loss combining SSIM and L1 terms to enforce appearance consistency between synthesized and real images. "We formulate this via a robust photometric reconstruction loss:"
- Photometricâgeometric cost: A combined per-pixel cost that mixes photometric and geometric errors for robust view selection. "photometricâgeometric cost"
- Pose regression: Learning to predict camera pose directly from images with a regression network. "Learning-Based Pose Regression"
- Reprojection relationships: Multi-view constraints formed by projecting 3D points across frames to enforce geometric consistency. "multi-view 3D reprojection relationships"
- Rigid transformation: A rotation and translation used to align coordinate frames or trajectories without scaling. "via a rigid transformation computed from these shared anchor frames."
- RPE: Relative Pose Error, a metric measuring local frame-to-frame pose accuracy. "RPE (m)"
- Scale-invariant geometric consistency term: A depth consistency measure normalized to be insensitive to absolute scale. "a scale-invariant geometric consistency term:"
- SfM (Structure-from-Motion): A pipeline that reconstructs 3D structure and camera motion from multiple images. "Structure-from-Motion (SfM)"
- SLAM: Simultaneous Localization and Mapping, estimating a map while localizing within it. "SfM and SLAM"
- Sliding temporal window: A fixed-length sequence segment used for training/inference that moves along the video. "a sliding temporal window of length "
- SSIM (Structural Similarity): A perceptual similarity metric used in photometric loss to capture structural differences. "SSIM (Structural Similarity)"
- Temporal strides: The step size between selected frames in a sequence to vary temporal spacing. "varying temporal strides"
- Trajectory drift: The cumulative deviation of an estimated trajectory from true motion over time. "trajectory drift"
- Triangular constraint system: Using three keyframes to form robust multi-view geometric constraints within a window. "a robust triangular constraint system"
- Uniform Geometric Coverage Strategy: A sampling strategy that diversifies anchor frames to maximize geometric observability. "a Uniform Geometric Coverage Strategy."
- Validity mask: A mask indicating pixels valid for supervision after projection and occlusion checks. "validity mask construction."
- VGGT: Visual Geometry Grounded Transformer, a transformer-based framework for depth and pose estimation. "Visual Geometry Grounded Transformer (VGGT)"
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the paper’s self-supervised, physics- and geometry-aware adaptation of VGGT today.
- Adaptive visual localization for new cities and routes
- Sectors: Automotive, Mobility, Mapping
- Use case: Rapidly fine-tune pre-trained VGGT models on fresh, unlabeled dashcam video to improve odometry and reduce drift in new geographies (e.g., new fleet deployments).
- Tools/products/workflows: “Unlabeled domain adaptation” training job using sliding windows, multi-anchor supervision, hard-view selection; chained inference for long trajectories; optional GPS/IMU for scale anchoring.
- Assumptions/dependencies: Known or estimated camera intrinsics; contiguous video with overlap; largely rigid scenes; compute for a short fine-tune; policy-compliant data capture.
- Warehouse and factory robot navigation without labels
- Sectors: Robotics, Logistics, Manufacturing
- Use case: Few-hour self-supervised fine-tuning on site video to adapt localization to warehouse layouts and lighting, improving path tracking and map maintenance.
- Tools/products/workflows: On-prem training pipeline integrated with existing SLAM; automatic robust view selection to filter occlusions/forklifts; periodic re-adaptation as layouts change.
- Assumptions/dependencies: Moderate texture/structure; occasional static segments; intrinsics stability; safety sandboxing during adaptation runs.
- Drone-based infrastructure inspection and mapping
- Sectors: Energy (grid, wind, solar), Transportation, Public works
- Use case: Use unlabeled inspection flights to adapt localization and depth, stabilizing 3D reconstructions of towers, bridges, and substations.
- Tools/products/workflows: Pre-flight adaptation pass; photometric/geometric loss-driven training; export poses/depth to downstream MVS/meshing tools.
- Assumptions/dependencies: Gimbal/camera intrinsics; handling specular surfaces and motion via auto-masking; wind-induced motion mitigated by the hard-view selection.
- Construction/AEC site updates from casual video
- Sectors: AEC, Geospatial
- Use case: Daily walk-through videos produce improved site localization and depth for progress tracking and as-built documentation without ground-truth labels.
- Tools/products/workflows: Batch adaptation jobs; chained sliding-window inference; alignment to survey control points or GNSS for metric scale; export depth/poses to BIM-integrated pipelines.
- Assumptions/dependencies: Frequent occlusions/dynamics (machinery) filtered by the loss; sufficient viewpoint change across days; scale anchoring via control points.
- Consumer AR session robustness via background adaptation
- Sectors: Software, Mobile, AR/VR
- Use case: On-device background self-supervised tuning from recent sessions to improve localization in a user’s home/store (persistent anchors, less drift).
- Tools/products/workflows: Lightweight, periodic fine-tune with windowed supervision; privacy-preserving on-device training; inference plugged into AR frameworks.
- Assumptions/dependencies: Power/thermal budgets; privacy and consent; intrinsics stability; some rigid content in scenes.
- Retail store digital twin creation from walkthroughs
- Sectors: Retail, Operations, Geospatial
- Use case: Staff capture simple aisle videos; the system adapts and outputs consistent poses/depth for shelf analytics, planogram compliance, and navigable digital twins.
- Tools/products/workflows: Store-specific adaptation job; export to point clouds/meshes; scheduled re-capture to track changes.
- Assumptions/dependencies: Reflective/transparent packaging handled with robust selection; re-shelving introduces dynamics—auto-masking helps but doesn’t solve all cases.
- Video stabilization and VFX pre-visualization
- Sectors: Media, Post-production, Mobile video apps
- Use case: Use improved camera trajectories and depth to stabilize footage and enable depth-aware effects from handheld video without markers.
- Tools/products/workflows: Offline adaptation to a shoot’s footage; pose/depth export to NLE/compositor; automated bad-view filtering.
- Assumptions/dependencies: Sufficient parallax; brightness constancy approximates; rolling shutter not explicitly modeled.
- GIS augmentation with vehicle/bodycam video
- Sectors: Geospatial, Smart Cities
- Use case: Produce pose priors and dense depth from unlabeled patrol/maintenance videos to enrich maps and detect changes.
- Tools/products/workflows: Batch adaptation per district; chained windows for long-range odometry; align to GPS for metric scale and georegistration.
- Assumptions/dependencies: GPS availability for scale; illumination changes handled by SSIM/robust cost; privacy compliance in public spaces.
- Pseudo-label generation for research and product teams
- Sectors: Academia, Software R&D
- Use case: Generate depth/pose pseudo-labels from raw video to bootstrap model training (distillation, data curation, simulation).
- Tools/products/workflows: Automated pipelines to produce and QC pseudo-labels; confidence metrics from per-pixel minimum-cost selection.
- Assumptions/dependencies: Quality varies by scene dynamics and texture; downstream training should account for uncertainty.
- Privacy-preserving on-device or federated adaptation
- Sectors: Policy/Privacy Tech, Mobile, Robotics
- Use case: Improve localization without uploading raw video, sharing only model deltas or summaries.
- Tools/products/workflows: Federated fine-tuning with geometry/physics-aware losses; secure enclaves; periodic aggregation.
- Assumptions/dependencies: Edge compute; robust aggregation against drift; compliance with privacy regulations.
Long-Term Applications
These opportunities are promising but need further research, scaling, or engineering to reliably deploy in production.
- Lifelong, self-supervised autonomy in open-world environments
- Sectors: Automotive (L3–L4), Robotics
- Use case: Continuous on-vehicle adaptation to seasonal, construction, and sensor aging changes with minimal supervision.
- Tools/products/workflows: Always-on adaptation with safety monitors; rollback/guardrails; uncertainty-aware planners.
- Assumptions/dependencies: Verified safety cases for self-supervised updates; robust detection of failure modes and drift; regulatory approval.
- City-scale AR cloud and crowd-sourced mapping from unlabeled video
- Sectors: AR/VR, Geospatial, Smart Cities
- Use case: Aggregate consumer/vehicle videos to maintain large-scale maps and anchors without manual labels.
- Tools/products/workflows: Map backend ingesting adapted poses/depth; global alignment with GPS/IMU/landmarks; change detection.
- Assumptions/dependencies: Privacy-by-design ingestion; quality control at scale; multi-sensor anchoring for metric consistency.
- Fully learned SLAM with physics-aware supervision and near-zero drift
- Sectors: Robotics, Software
- Use case: Replace/augment BA-heavy pipelines with transformer-based modules trained via multi-sequence consistency and robust view selection.
- Tools/products/workflows: Hybrid learned-classical pipelines; online masks and view selection; joint optimization with loop closure modules.
- Assumptions/dependencies: Handling rolling shutter, non-Lambertian surfaces, and strong dynamics; real-time guarantees.
- Multimodal self-supervised geometry (vision + IMU/LiDAR/GNSS)
- Sectors: Automotive, Drones, Geospatial
- Use case: Train cross-sensor fusion models with physics-aware objectives that exploit each sensor’s constraints.
- Tools/products/workflows: Co-training with inertial pre-integration, LiDAR reprojection losses, GNSS priors for scale.
- Assumptions/dependencies: Time sync and calibration; unified differentiable sensor models; robust cross-modal weighting.
- Web-scale self-supervised 3D foundation models
- Sectors: AI Platforms, Cloud
- Use case: Train general visual-geometry models on massive unlabeled video with sequence-wise constraints, reducing reliance on curated labels.
- Tools/products/workflows: Distributed training with geometry-aware losses; auto-curation by physical consistency; scalable view selection.
- Assumptions/dependencies: Efficient curriculum over viewpoint baselines; failure detection at scale; compute and energy costs.
- Disaster response and rapid 3D situational awareness
- Sectors: Public Safety, Defense, NGOs
- Use case: Turn ad hoc drone/bodycam footage into coherent 3D maps without pre-existing labels or maps.
- Tools/products/workflows: Field-adaptation kits; quick alignment to GNSS; uncertainty maps for responders.
- Assumptions/dependencies: Challenging dynamics/occlusions, smoke/dust; intermittent GPS; robust failure handling.
- Indoor positioning without beacons via persistent self-adaptation
- Sectors: Retail, Healthcare, Enterprise
- Use case: Maintain indoor localization for navigation and asset tracking using only cameras and self-supervision.
- Tools/products/workflows: Periodic adaptation as interiors change; optional floorplan constraints; map maintenance.
- Assumptions/dependencies: Repetitive textures and low parallax; lighting variations; privacy in sensitive spaces.
- Energy and industrial asset digital twins with continual updates
- Sectors: Energy, Oil & Gas, Manufacturing
- Use case: Ongoing, label-free updates to plant/site twins using inspection video, keeping geometry fresh for maintenance planning.
- Tools/products/workflows: Scheduled adaptation; cross-shift consistency checks; integration with CMMS.
- Assumptions/dependencies: Hazardous environments induce dynamics; reflective/metallic surfaces; safety certification.
- Edge-optimized hardware/software stacks for self-supervised geometry
- Sectors: Semiconductors, Edge AI
- Use case: Low-power accelerators and runtimes supporting photometric/geometric losses and warping ops for on-device adaptation.
- Tools/products/workflows: Kernel libraries for differentiable warping/SSIM; memory-efficient attention over sliding windows.
- Assumptions/dependencies: Co-design with model architectures; thermal constraints; vendor ecosystem adoption.
- Standards, evaluation, and governance for self-supervised localization
- Sectors: Policy, Standards Bodies, Safety
- Use case: Benchmarks, test protocols, and governance covering self-supervised updates, drift detection, and rollback.
- Tools/products/workflows: Scenario libraries with controlled dynamics/occlusions; audit trails for on-device training events.
- Assumptions/dependencies: Multi-stakeholder alignment; incident reporting frameworks; legal clarity on continuous learning.
Cross-cutting assumptions and dependencies (common to many applications)
- Photometric and static-scene assumptions are only partially relaxed via auto-masking and hard-view selection; heavy dynamics, severe non-Lambertian effects, and rolling shutter can degrade results.
- Camera intrinsics should be known or estimated; consistent intrinsics across training/inference windows improve stability.
- Monocular scale: absolute metric scale typically requires an external cue (e.g., GNSS/IMU/wheel odometry, ground plane priors, or post-hoc alignment).
- Data: contiguous, overlapping video segments are needed; viewpoint diversity strengthens geometric signals.
- Compute: short fine-tuning is feasible, but edge/on-device scenarios may need optimized runtimes and scheduling.
- Compliance: unlabeled video still contains personal/sensitive data—privacy, consent, and retention policies apply.
- Licensing and ecosystem: availability and licensing of VGGT checkpoints and the released GPA-VGGT code will influence adoption.
Collections
Sign up for free to add this paper to one or more collections.