- The paper introduces a training-free token merging mechanism that reduces the quadratic complexity of global attention in 3D vision transformers.
- It implements a VRAM-efficient strategy by discarding non-essential intermediate outputs, enabling robust processing of long sequences up to 1000 frames.
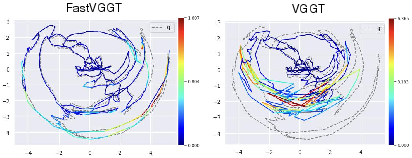
- The method preserves multi-view geometric consistency through reference token selection and deterministic unmerging, effectively mitigating error accumulation.
Introduction and Motivation
FastVGGT addresses the scalability bottlenecks of the Visual Geometry Grounded Transformer (VGGT), a state-of-the-art feed-forward model for 3D scene reconstruction and camera pose estimation. VGGT's transformer-based architecture achieves high-fidelity 3D reconstructions by leveraging dense global attention across all scene tokens. However, as the number of input frames increases, the quadratic time complexity of global attention (O(n2d)) and memory consumption severely limit VGGT's applicability to long-sequence inputs. FastVGGT introduces a training-free token merging mechanism, tailored for 3D vision tasks, to mitigate these computational constraints while preserving reconstruction accuracy.
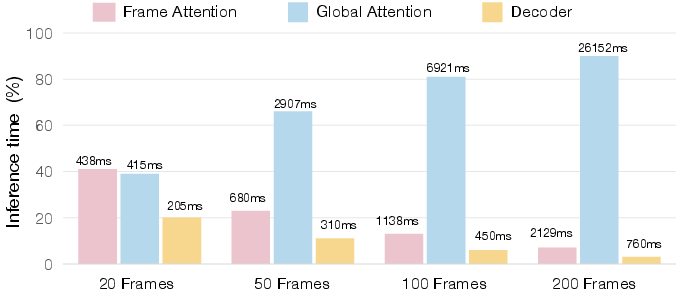
Figure 1: Component-wise analysis of VGGT inference time. As the number of input frames grows, the Global Attention module increasingly dominates the computational cost.
Analysis of VGGT Bottlenecks
Profiling VGGT reveals that the Global Attention module rapidly becomes the dominant contributor to inference time as input sequence length increases. While Flash-Attention reduces memory complexity, the time complexity remains quadratic. Visualization of attention maps demonstrates a pronounced token collapse phenomenon: attention patterns across tokens exhibit high similarity, indicating substantial redundancy in global computation.
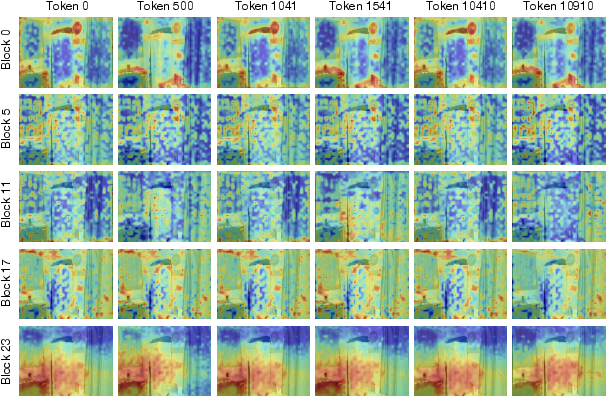
Figure 2: Visualizations of the Global Attention maps in VGGT, using six representative tokens (including the camera token and several image tokens), show that at every stage the attention patterns of different tokens exhibit a strong degree of similarity.
This redundancy motivates the application of token merging, a technique previously successful in 2D vision transformers, to the 3D domain. However, direct adoption of existing merging strategies degrades reconstruction quality due to the unique requirements of multi-view geometric consistency and dense prediction in 3D tasks.
FastVGGT: Token Merging for 3D Vision
FastVGGT introduces a principled token partitioning and merging strategy, specifically designed for feed-forward 3D reconstruction:
- Reference Token Selection: All tokens from the first frame, which serves as the global coordinate anchor, are designated as destination (dst) tokens and are exempt from merging. This preserves cross-frame spatial consistency.
- Salient Token Selection: A subset of distinctive tokens per frame, identified via fixed-stride sampling, are protected from merging to maintain key correspondences across views.
- Uniform Token Sampling: Within each frame, region-based random sampling ensures spatially balanced selection of src and dst tokens, preventing local over-compression and loss of detail.
The merging procedure computes cosine similarity between src and dst tokens, merging each src token into its most similar dst counterpart via average pooling. This reduces the token count for global attention computation, yielding substantial acceleration.
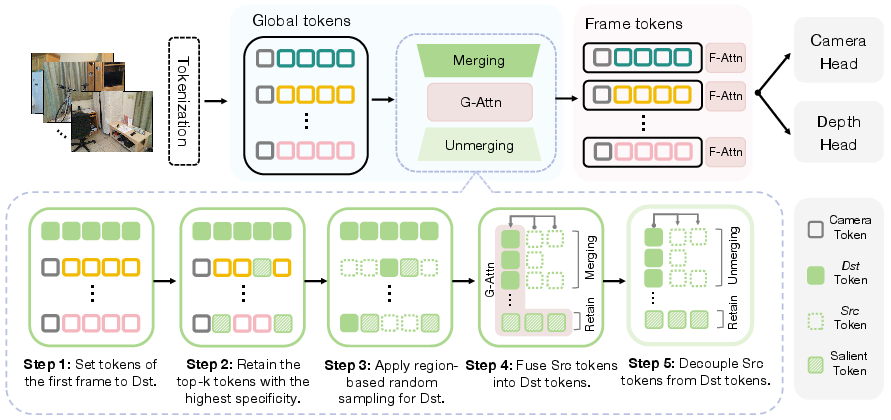
Figure 3: Visualizations of the Global Attention maps in VGGT, using six representative tokens (including the camera token and several image tokens), show that at every stage the attention patterns of different tokens exhibit a strong degree of similarity. G-Attn and F-Attn denote Global Attention and Frame Attention, respectively.
To maintain compatibility with dense prediction requirements, FastVGGT implements a deterministic unmerging operation post-attention, restoring the original token resolution for per-patch outputs.
VRAM-Efficient Implementation
The original VGGT implementation stores intermediate outputs from all 24 encoder blocks, resulting in out-of-memory errors for sequences longer than 300 frames. FastVGGT introduces a VRAM-efficient variant (VGGT∗) that discards unused intermediate results during inference, enabling processing of up to 1000 frames without compromising reconstruction quality.
Experimental Results
FastVGGT is evaluated on ScanNet-50, 7 Scenes, and NRGBD benchmarks for both 3D reconstruction and camera pose estimation. Key findings include:
Ablation studies confirm the necessity of the tailored token partitioning strategy: naive random or fixed-stride sampling degrades performance, while the combination of reference, salient, and uniform sampling yields optimal results. Aggressive merging ratios (up to 90\%) applied from the initial block maximize acceleration with minimal impact on reconstruction fidelity.
Theoretical and Practical Implications
FastVGGT demonstrates that training-free token merging, when carefully adapted to the structural and task-specific demands of 3D vision transformers, can substantially improve scalability without sacrificing accuracy. The observed attention redundancy in global modules is not merely a flaw but an exploitable property for computational efficiency. The approach is immediately applicable to large-scale 3D scene understanding, enabling real-time or near-real-time inference on long video sequences and large image sets.
Theoretically, the work suggests that feature collapse in global attention can be leveraged for model compression in dense prediction tasks, provided that local variability is reintroduced downstream (e.g., via frame attention). This insight may inform future transformer designs for other domains with similar redundancy patterns.
Future Directions
Potential avenues for further research include:
- Adaptive Merging Ratios: Dynamic adjustment of merging ratios based on input scene complexity or attention map entropy.
- Integration with Streaming Architectures: Combining FastVGGT with streaming or chunked processing for kilometer-scale or continuous 3D reconstruction.
- Generalization to Other Modalities: Extending the token merging paradigm to multi-modal transformers (e.g., vision-language, video-audio) where redundancy is prevalent.
Conclusion
FastVGGT provides a training-free, principled solution for accelerating transformer-based 3D vision models. By exploiting attention map redundancy through strategic token merging and efficient memory management, FastVGGT achieves significant speedups and scalability improvements while maintaining high reconstruction and pose estimation accuracy. The methodology is broadly applicable to large-scale 3D perception tasks and sets a precedent for future research in efficient transformer architectures for geometric vision.