- The paper introduces a block-sparse global attention mechanism that reduces the quadratic complexity of VGGT for efficient multi-view 3D reconstruction.
- It leverages pooled queries and keys with block selection via cumulated density functions, offering significant speed-ups while preserving performance.
- Experimental results demonstrate robust performance with minimal degradation at over 75% sparsity, validating improved scalability in transformer models.
Faster VGGT with Block-Sparse Global Attention
Introduction to VGGT
The paper "Faster VGGT with Block-Sparse Global Attention" addresses the scalability challenges inherent in transformer-based models for 3D geometry reconstruction from multi-view image sets. VGGT, a Visual Geometry Grounded Transformer, achieves state-of-the-art performance in multi-view geometry estimation tasks, but its quadratic complexity in the global attention layers poses significant runtime bottlenecks as the number of input images grows.
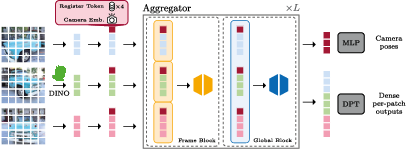
Figure 1: Architecture overview of VGGT, illustrating the use of alternating global and frame-wise attention blocks.
Observation of Sparse Attention Patterns
A critical observation highlighted is the sparse nature of VGGT's global attention matrix, where meaningful attention is concentrated on a small subset of token interactions. This sparsity suggests that comprehensive scene-level reasoning can be achieved without the computational burden of dense global attention maps.
The attention map analyses show that the middle layers in VGGT's aggregator are pivotal for cross-view reasoning, concentrating geometric matches that can be exploited for accelerating computation.


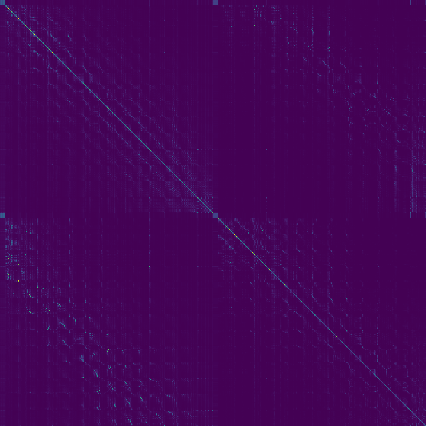
Figure 2: Visualization of VGGT's global attention matrix, showing sparse activations and patch-level attention localization.
Adaptive Block-Sparse Attention Mechanism
Building upon the analysis, the paper proposes replacing VGGT's dense global attention mechanism with an adaptive block-sparse attention approach. This retrofit leverages block-sparse kernels to estimate low-resolution attention maps through average pooling of queries and keys, facilitating efficient block selection based on cumulated density functions (CDFs) and sparsity ratios.
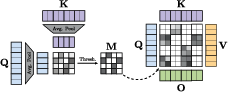
Figure 3: Overview of the training-free adaptive sparse attention mechanism formed by pooling keys and queries.
Experimental Results
The empirical evaluations confirm that the proposed block-sparse attention mechanism maintains task performance comparable to original VGGT while achieving inference speed-ups of up to 400% across a range of multi-view benchmarks. Experiments exhibit robustness to varying sparsity levels, illustrating minimal performance degradation even at sparsity ratios exceeding 75%.










Figure 4: Qualitative example from the ETH3D dataset, showcasing stable reconstruction quality under increased sparsity.
Implications and Future Directions
This work underscores the potential of applying sparse attention mechanisms not only in vision transformers but broadly in architectures where scalability is constrained by quadratic complexity in dense operations. By validating block-sparse attention in VGGT, this study posits a generalizable framework that can drive efficiency in high-resolution imaging tasks and larger-scale input sequences.
Further research could explore integrating learned attention masks during training to refine block selection dynamically, enhancing adaptation to sparsity in dense regions versus structured attention patterns.
Conclusion
The introduction of a block-sparse attention architecture to VGGT demonstrates a pragmatic approach to mitigating computational bottlenecks in transformer models for multi-view reconstruction, reaffirming the feasibility of sparse mechanisms in maintaining accuracy while enabling substantial efficiency improvements.

