Retrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
Abstract: Retrieval-Augmented Generation (RAG) has become a standard approach for knowledge-intensive question answering, but existing systems remain brittle on multi-hop questions, where solving the task requires chaining multiple retrieval and reasoning steps. Key challenges are that current methods represent reasoning through free-form natural language, where intermediate states are implicit, retrieval queries can drift from intended entities, and errors are detected by the same model that produces them making self-reflection an unreliable, ungrounded signal. We observe that multi-hop question answering is a typical form of step-by-step computation, and that this structured process aligns closely with how code-specialized LLMs are trained to operate. Motivated by this, we introduce \pyrag, a framework that reformulates multi-hop RAG as program synthesis and execution. Instead of free-form reasoning trajectories, \pyrag represents the reasoning process as an executable Python program over retrieval and QA tools, exposing intermediate states as variables, producing deterministic feedback through execution, and yielding an inspectable trace of the entire reasoning process. This formulation further enables compiler-grounded self-repair and execution-driven adaptive retrieval without any additional training. Experiments on five QA benchmarks (PopQA, HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle) show that \pyrag consistently outperforms strong baselines under both training-free and RL-trained settings, with especially large gains on compositional multi-hop datasets. Our code, data and models are publicly available at https://github.com/GasolSun36/PyRAG.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
What is this paper about?
This paper introduces PyRAG, a new way to help AI answer tricky, multi-step questions by writing and running short pieces of code. Instead of asking an AI to “think in sentences,” PyRAG has the AI write a tiny Python “recipe” that looks things up and combines the facts step by step. This makes the process clearer, easier to check, and more accurate.
Imagine solving a mystery by gathering clues one at a time and writing down each step. PyRAG does that for question answering: it plans, looks up information, stores intermediate results, and then combines them to get the final answer.
Objectives
What questions are the researchers trying to answer?
- Can we make AI better at multi-step (multi-hop) questions—ones that need several lookups and reasoning steps—by having it write and run code instead of explaining its reasoning in a paragraph?
- Will representing the steps as a program make the process more reliable, easier to inspect, and easier to fix when something goes wrong?
- Do code-focused AI models work better when the task is actually set up like programming?
Approach
How does PyRAG work (in everyday terms)?
Think of PyRAG like following a cooking recipe:
- First, the AI breaks a big question into small sub-questions (like listing ingredients).
- Then it writes a short “program” (like a recipe) with clear steps that say:
- look up facts,
- store them in variables,
- combine them to get the answer.
- Finally, it runs that program and checks the results.
To do this, PyRAG uses three cooperating parts (agents):
- Decompose Agent: breaks the big question into bite-sized sub-questions.
- Plan Agent: writes a small Python program that uses two simple tools:
retrieve(query, topk)to find the most relevant documents,answer(query, docs)to extract a short answer from those documents.
- Answer Agent: reads the retrieved documents and produces short, direct answers (like a fact).
Because it’s executable code, PyRAG can do two helpful things automatically:
- Self-repair: If the program has an error (like a typo or wrong variable), running it throws a clear error, so the system fixes the code and tries again—like a spellcheck for programs.
- Adaptive retrieval: If a step doesn’t find enough evidence, PyRAG increases how much it searches (e.g., from
topk=5totopk=10) just for that step, instead of redoing everything.
Why is this different from typical systems?
Many systems ask the AI to “explain its thoughts” in natural language, which can be vague and hide mistakes. PyRAG instead uses an explicit, step-by-step program with variables you can inspect. It’s like the difference between saying “I did some math and got 42” and showing the exact calculation.
Results
What did they test on?
The team evaluated PyRAG on five question-answering benchmarks, including well-known multi-step datasets like HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle.
What did they find (in simple terms)?
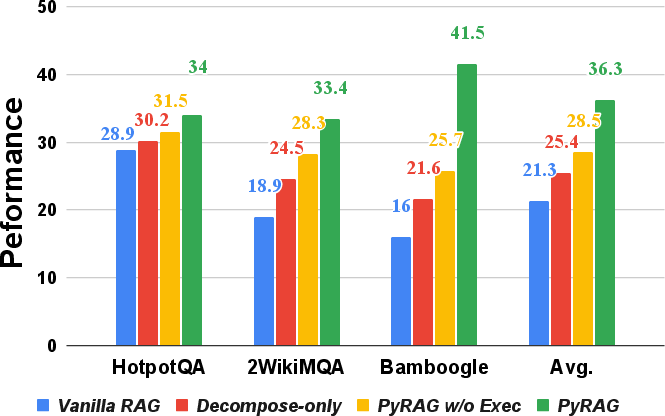
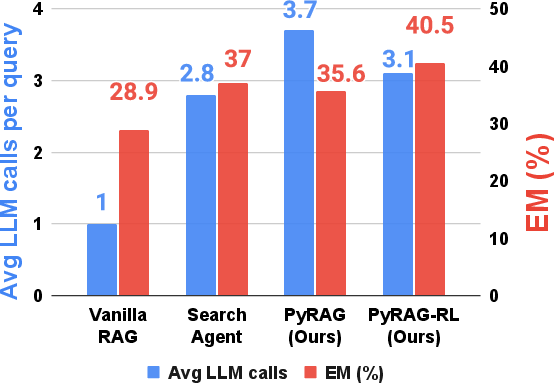
- PyRAG beats strong baselines, especially on hard, multi-step questions.
- Without extra training, PyRAG improved average accuracy by about +11.8 points over a standard RAG system, and by +25.5 points on one very challenging dataset (Bamboogle).
- When PyRAG is further fine-tuned with reinforcement learning (RL), it reaches top scores among similar-sized models on several datasets.
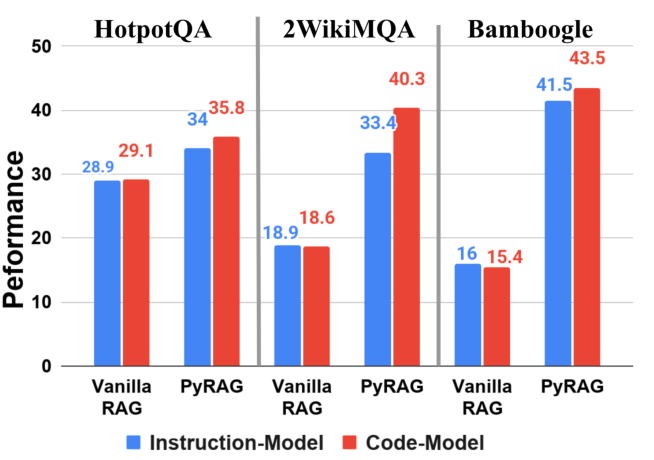
- Code-focused LLMs don’t help much in normal “text-only” setups—but they do give consistent gains when the task is framed as writing and running code. In other words, code models shine when you actually let them use code.
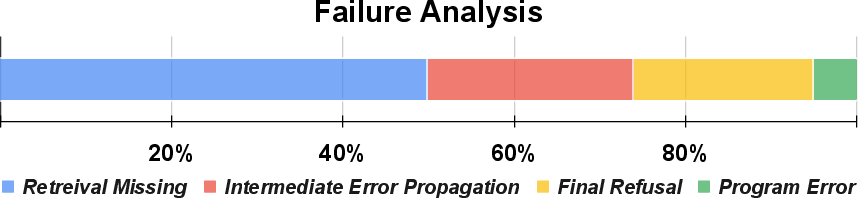
- The biggest remaining source of mistakes wasn’t the code—it was missing or weak retrieval (not finding the right documents) or the answer module not extracting the answer from the text.
Why is this important?
- Clarity: You can see every step the AI took, what it looked up, and how it combined facts.
- Reliability: Program errors produce clear, fixable messages, so the system can correct itself.
- Better on hard questions: Explicit steps and variables help chain facts together correctly.
Implications
What does this mean going forward?
- For tough, multi-step questions, it’s better to have AI write and run a plan (code) than to rely on free-form “thinking in text.”
- Pairing the right model (code-specialized) with the right interface (programs to execute) matters. The interface and the model should be designed together.
- This approach could be used in education, research assistants, or any tool where traceable, checkable reasoning is important.
In short: PyRAG shows that “show me the code” is a powerful way to make AI reasoning clearer and more accurate—especially when answering questions that need several steps and sources.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces PyRAG, an executable program–based framework for multi-hop RAG, and reports strong gains on several QA benchmarks. The following aspects remain missing, uncertain, or underexplored:
- Retrieval recall as the dominant bottleneck: Quantify and reduce retrieval misses (≈50% of failures), e.g., by integrating stronger retrievers (Contriever/ColBERTv2/SPLADE), hybrid sparse+dense, iterative/bridging retrieval, or query reformulation within the program.
- Corpus scope and domain generalization: Assess PyRAG on web-scale, non-Wikipedia, up-to-date, and domain-specific corpora (biomed, law); examine robustness to temporal drift and low-resource settings.
- Only two tools (retrieve, answer): Extend the API set to include entity linking, KB/SQL queries, table parsers, calculators, web browsing, and verification tools; study how richer tools affect plan quality and failure modes.
- Heuristic “insufficient evidence” detection: Replace sentinel-based triggers (“unknown/cannot answer”) with calibrated uncertainty, entailment checks, or confidence scores to decide when to expand top‑k or reformulate queries.
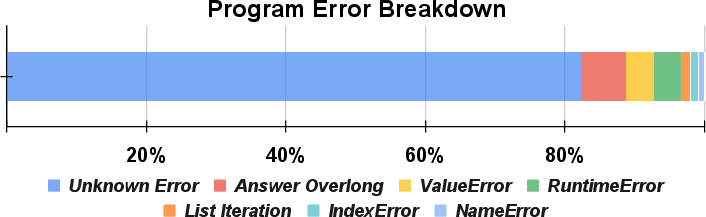
- Limited self-repair capability: Current compiler-grounded repair handles syntax/runtime exceptions but not silent semantic errors (e.g., wrong entity binding). Develop semantic checks (type systems, assertions, invariants, unit tests) and static analysis to catch and fix non-exception failures.
- Program expressivity: Explore richer control flow (conditionals, loops, branching, backtracking), typed variables, and a DSL that enforces schemas for tool I/O to reduce semantic mismatches and error propagation.
- Error propagation mitigation: Introduce verification or cross-checks for intermediate variables (e.g., entailment, dual retrieval, n-best hypotheses with re-ranking) before they are consumed downstream.
- Planning quality measurement: Create metrics/datasets to evaluate sub-query decomposition correctness, dependency ordering, and compositional coverage; analyze how decomposition errors translate to final EM.
- Component-level attribution: Provide fine-grained ablations quantifying the separate contributions of compiler-grounded self-repair vs. adaptive retrieval vs. decomposition vs. planning to EM and cost.
- RL training details and credit assignment: Clarify which agents are RL-trained, the reward design (per-step vs. terminal, evidence-grounding), and conduct ablations on RL objectives; investigate multi-agent RL or hierarchical RL for better credit assignment across Decompose/Plan/Answer.
- Budgeted reasoning and stopping: Learn policies for when to increase top‑k, reformulate, or stop; formalize compute–accuracy trade-offs (e.g., constrained MDPs) and evaluate under strict call/token budgets.
- Scaling with hop count and task types: Analyze performance as a function of hops and composition types (comparisons, intersections, temporal reasoning); identify failure patterns on longer or more complex chains.
- Faithfulness and attribution: Add and evaluate citation/attribution for each intermediate variable and the final answer (e.g., evidence spans, entailment verification), beyond EM.
- Robustness to entity ambiguity and drift: Integrate canonicalization/entity linking and co-reference to reduce query drift; evaluate on adversarially ambiguous queries.
- Non-determinism and reproducibility: Study variability due to retrieval/LLM stochasticity; introduce caching, deterministic seeds, and stability metrics for the program pipeline.
- Safety and sandboxing: Specify and evaluate sandbox protections for executing LLM-generated code (even if tool-restricted), including defenses against prompt/code injection via retrieved text and side-effect containment.
- Data and prompt contamination: Control and report potential overlap between model pretraining and evaluation data; assess how parametric knowledge vs. retrieval contributes to performance in PyRAG.
- Token/latency cost profiling: Report token usage, wall-clock latency, and memory overhead (not just call counts) across datasets; quantify interpreter/execution overhead vs. unstructured agents.
- Context management limits: Analyze how retrieved passage lengths/top‑k interact with context windows; study in-program reranking/selection to prevent context overflow and dilution.
- Extensibility and standardization: Define an interface/DSL for plugging in new tools with typed contracts; study planner generalization when the toolset changes.
- Adversarial and noisy environments: Evaluate robustness to noisy/poisoned retrieval results and prompt-injection content; add defenses (content filters, robust retrieval, verification).
- Cross-lingual and non-English settings: Test PyRAG when queries and/or corpora are multilingual, including cross-lingual retrieval and answer synthesis.
- Human-centered evaluation: Conduct user studies to measure whether executable traces improve interpretability, debuggability, and trust compared to free-form agents.
- Learning from traces: Use execution traces for supervised or self-improvement of retrievers (query reformulation, negative mining) and planners (imitation learning from successful repairs), which is not explored here.
Practical Applications
Immediate Applications
The paper introduces PyRAG: an executable, program-synthesis interface for multi-hop Retrieval-Augmented Generation (RAG) with explicit variables, compiler-grounded self-repair, and adaptive retrieval. The following use cases can be deployed now using the released code, models, and standard vector stores.
- Bold, auditable enterprise knowledge assistants
- Sectors: software, consulting, finance, energy
- What it enables: Multi-hop Q&A over enterprise wikis/Confluence/SharePoint with an inspectable execution trace (variables, sub-queries, documents used). Reduces hallucinations and supports internal audits/QA escalation.
- Tools/products/workflows: PyRAG + enterprise vector store (e.g., E5/DPR + Milvus/FAISS), sandboxed Python runner, dashboards showing execution traces and evidence.
- Assumptions/dependencies: Up-to-date indexed corpora; access controls; PII/PHI redaction; secure code sandboxing of the
retrieve/answertool APIs.
- Customer support deflection with evidence-linked answers
- Sectors: SaaS, telecom, consumer electronics
- What it enables: Step-by-step retrieval across manuals, FAQs, and release notes to resolve multi-hop tickets (e.g., “feature availability by plan and version”), with traceable sources for agent review.
- Tools/products/workflows: Help center bot integrating PyRAG; escalation with trace artifacts; adaptive retrieval for hard cases.
- Assumptions/dependencies: High-quality KB; latency budgeting; content freshness; privacy compliance.
- Developer documentation and API troubleshooting assistant
- Sectors: software, cloud
- What it enables: IDE/chat assistant that decomposes queries (e.g., API differences across versions), retrieves relevant docs and code snippets, and compares results via explicit variables.
- Tools/products/workflows: IDE extension; docset indexers; PyRAG-based planner using code-specialized LMs.
- Assumptions/dependencies: Comprehensive doc indexing; repository access; secure execution environment.
- Scientific literature assistant for multi-paper synthesis
- Sectors: academia, pharma R&D
- What it enables: Programmatic decomposition of research questions to retrieve papers, extract key facts (dates, metrics, interventions), and compose grounded summaries with a reproducible trace.
- Tools/products/workflows: Connectors to PubMed/arXiv; citation capture in the execution trace; exportable provenance.
- Assumptions/dependencies: Legal access to literature; accurate metadata extraction; domain-tuned “answer” prompts.
- Legal e-discovery and brief support with provenance
- Sectors: legal services, corporate counsel
- What it enables: Multi-hop retrieval over case law, contracts, and statutes; comparison of clauses or precedents with explicit evidence chains suitable for attorney review.
- Tools/products/workflows: Integration with legal databases; trace packages added to matter files.
- Assumptions/dependencies: Licensed access (e.g., Westlaw/Lexis); strict human-in-the-loop review; accuracy and completeness requirements.
- Compliance and policy Q&A with explicit cites
- Sectors: finance, healthcare, energy
- What it enables: Answers grounded in regulatory texts and internal policies, showing each step/query and the specific sections used.
- Tools/products/workflows: Compliance Copilot with traceable outputs; dashboards for audit inspections.
- Assumptions/dependencies: Current regulations; jurisdiction scoping; governance policies for answer acceptance.
- Journalism and fact-checking workflows
- Sectors: media, OSINT
- What it enables: Cross-source comparisons (e.g., dates, quotes) with transparent evidence trails and intermediate variables to avoid entity drift.
- Tools/products/workflows: Newsroom assistant integrated with curated source indices; editorial review UI for traces.
- Assumptions/dependencies: Source credibility management; archival indexing; editorial oversight.
- Education: step-by-step, source-backed tutoring
- Sectors: education technology, libraries
- What it enables: Tutors that show decomposition, retrievals, and evidence citations, teaching research skills alongside answers.
- Tools/products/workflows: LMS plugins; curated academic content stores; exportable reasoning traces.
- Assumptions/dependencies: Age-appropriate sources; guardrails to discourage over-reliance; content licensing.
- Business intelligence Q&A over internal knowledge
- Sectors: enterprise operations
- What it enables: Multi-hop queries across strategy docs, org charts, and policy pages (e.g., “which teams own X and who approves Y”), with resolvable, auditable traces.
- Tools/products/workflows: Connectors to Confluence/Notion/Google Drive; role-based access; trace logging for governance.
- Assumptions/dependencies: Data connectors; permissioning; content hygiene.
- RAG pipeline debugging and MLOps observability
- Sectors: AI tooling, platform engineering
- What it enables: Compiler-grounded error signals (e.g., NameError, insufficient evidence) to systematically debug retrieval chains and tune prompts/top-k policies.
- Tools/products/workflows: “RAG Debugger” that surfaces runtime exceptions, adaptive retrieval triggers, and per-step success rates.
- Assumptions/dependencies: Consistent logging; integration with retrievers and LLM telemetry.
- Public information portals with transparent answers
- Sectors: government, NGOs
- What it enables: Citizen-facing Q&A where every step and document used is recorded, aiding trust and FOIA compliance.
- Tools/products/workflows: PyRAG-based portal over agency publications; downloadable evidence traces.
- Assumptions/dependencies: Open, accessible document repositories; accessibility standards; oversight.
- Model evaluation/research reproducibility
- Sectors: academia, applied ML
- What it enables: Benchmark harnesses where every run is traceable and re-executable, improving reproducibility of multi-hop QA experiments.
- Tools/products/workflows: Open datasets + PyRAG runners; saved execution traces and seeds for replication.
- Assumptions/dependencies: Standardized corpora and retrieval settings; versioning.
Long-Term Applications
The following applications are promising but require further research, domain adaptation, stronger retrievers, or regulatory/compliance advances beyond the current paper’s scope.
- Clinical decision support with multi-evidence synthesis
- Sectors: healthcare
- What it enables: Chain guidelines, labs, and patient history to form evidence-backed suggestions with auditable traces for clinicians.
- Dependencies/assumptions: Integration with EHRs; HIPAA/GDPR compliance; high-recall domain retrievers; rigorous validation; regulatory approval.
- Financial analysis and due diligence automation
- Sectors: finance, fintech, audit
- What it enables: Multi-source analyses across filings, research, and regulations with clear provenance; KYC/AML case narratives with evidence links.
- Dependencies/assumptions: Real-time data connectors; data licensing; strict human oversight; liability and compliance frameworks.
- Multi-modal and structured-tool programmatic RAG
- Sectors: data analytics, BI, scientific computing
- What it enables: Extend
retrieve/answerto include SQL, API calls, table/figure parsing, and graph queries; robust composition of heterogeneous evidence. - Dependencies/assumptions: Tool ecosystem and type-safe interfaces; training for context utilization; security reviews for tool execution.
- Autonomous research agents for literature reviews and meta-analyses
- Sectors: academia, R&D
- What it enables: Long-horizon planning to survey, cluster, and synthesize findings across large literatures with reproducible traces.
- Dependencies/assumptions: Scalable retrieval; improved answer agents; deduplication/citation normalization; expert validation.
- Cross-lingual, cross-domain retrieval at enterprise scale
- Sectors: global enterprises, public sector
- What it enables: Multi-hop reasoning across multilingual corpora with reliable entity disambiguation and consistent variable binding.
- Dependencies/assumptions: Multilingual retrievers and NER; alignment of query generation; translation-quality management.
- Regulatory “executable explanations” as a compliance standard
- Sectors: policy, regulated industries
- What it enables: Auditable, step-by-step traces accepted by regulators as evidence of process transparency and control in AI-assisted decisions.
- Dependencies/assumptions: Engagement with standards bodies; legal acceptance; governance procedures; tamper-evident logging.
- Workflow automation with safe action execution (beyond QA)
- Sectors: enterprise IT, operations, RPA
- What it enables: After reasoning, invoke actions (e.g., raise tickets, draft emails, trigger pipelines) with traceable preconditions and guardrails.
- Dependencies/assumptions: Secure tool APIs; policy enforcement; rollback mechanisms; robust failure handling.
- RL specialization for domain policies and efficiency
- Sectors: ML ops, platform teams
- What it enables: Train PyRAG-RL on domain corpora to reduce calls and improve retrieval targeting; policy optimization for latency/cost trade-offs.
- Dependencies/assumptions: Reward design tied to provenance and correctness; curated feedback; compute resources.
- Knowledge graph construction with provenance-first extraction
- Sectors: data engineering, analytics
- What it enables: Use program traces to extract entities/relations with source citations, feeding ETL and KG pipelines.
- Dependencies/assumptions: Canonicalization; confidence calibration; human curation; scalable storage.
- Privacy-preserving and federated retrieval
- Sectors: healthcare, finance, defense
- What it enables: On-prem or federated PyRAG with privacy guarantees (e.g., on-device retrievers, secure enclaves, differential privacy).
- Dependencies/assumptions: Federated IR infrastructure; security audits; performance–privacy trade-offs.
- Edge/on-device deployment for low-latency scenarios
- Sectors: mobile, field operations
- What it enables: Compressed models and lightweight retrievers to deliver traceable multi-hop answers offline or with weak connectivity.
- Dependencies/assumptions: Model distillation/quantization; device constraints; content packaging and updates.
- Educational curricula and assessments for code-style reasoning
- Sectors: education, workforce training
- What it enables: Teaching programmatic reasoning and source-grounded research using executable traces; assessments that grade both process and result.
- Dependencies/assumptions: Curriculum development; content acquisition; alignment with learning standards.
Common Assumptions and Dependencies Across Applications
- Retrieval quality and coverage are critical; many failure cases stem from missing evidence rather than planning errors.
- Secure, sandboxed code execution is mandatory, even if the “program” only calls restricted tools like
retrieveandanswer. - Freshness and licensing of corpora significantly affect feasibility and accuracy.
- Human-in-the-loop review is advised for high-stakes domains (healthcare, legal, finance).
- Latency and cost must be managed (e.g., limit adaptive retrieval frequency, cache results, optimize
top-k). - Model availability and specialization: code-specialized LMs show benefits under the program-synthesis interface; domain-adapted answerers improve performance.
- Governance and audit requirements: storing immutable execution traces enables compliance but requires secure logging and access control.
Glossary
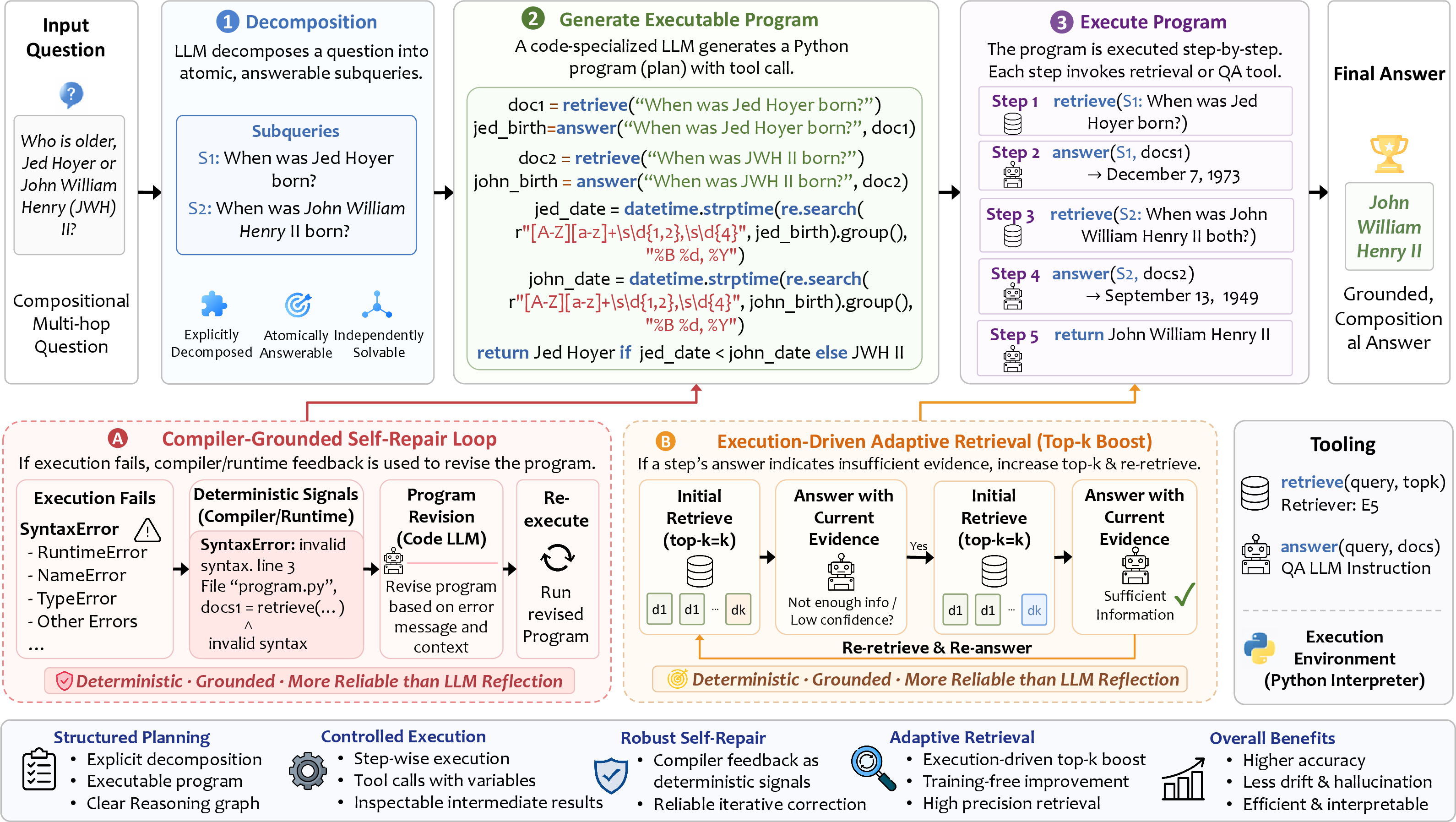
- Adaptive Retrieval: A mechanism that increases the retrieval scope when evidence is insufficient for a sub-step. "Execution-Driven Adaptive Retrieval, which boosts the top- retrieval budget for sub-steps whose answer indicates insufficient evidence."
- Answer Agent: An LLM component that produces short answers from retrieved documents for a given sub-query. "The answer agent takes a sub-query and a set of retrieved documents as input, and produces a short answer."
- Chain-of-Thought Prompting: A prompting technique where models generate intermediate reasoning steps in natural language to improve problem solving. "including chain-of-thought prompting~\citep{wei2022chain}"
- Code-Specialized LLMs: LLMs tuned to produce and reason with code, emphasizing variables, control flow, and step-by-step execution. "We further observe that code-specialized LLMs are explicitly trained for this exact pattern of behavior"
- Compiler-Grounded Self-Repair: A refinement loop where runtime errors from program execution guide revisions to the plan deterministically. "This formulation further enables compiler-grounded self-repair and execution-driven adaptive retrieval without any additional training."
- Compositional Multi-Hop Datasets: Benchmarks designed to require chaining multiple facts across sources to answer questions. "with especially large gains on compositional multi-hop datasets."
- Data Flow: The explicit passing and dependency of intermediate variables across steps in a program. "connected by data flow."
- Decomposition Agent: An LLM component that breaks a question into atomic, independently answerable sub-queries. "Given a question , the decomposition agent produces a sequence of sub-queries"
- Dense Retriever: A retrieval model that uses dense vector embeddings to find relevant passages in a corpus. "an E5-base dense retriever over the Wikipedia 2018 dump"
- Exact Match (EM): An evaluation metric measuring whether the predicted answer string exactly matches the ground truth. "Exact Match (EM) is used as the primary metric for all benchmarks."
- Executable Interface: An approach where reasoning is represented as code that can be run, yielding deterministic feedback and traces. "a framework that provides a verifiable execution interface for multi-hop RAG."
- Executable Program: A program synthesized to represent the reasoning process with tool calls and variables that can be run in an interpreter. "represents the reasoning process as an executable Python program over retrieval and QA tools"
- Execution-Guided Refinement: Mechanisms that improve the reasoning program during or after execution based on its outcomes. "Two execution-guided refinement mechanisms refine this pipeline"
- Execution Trace: A record of all intermediate queries, retrieved documents, and answers produced during program execution. "This execution process yields an execution trace, which records all intermediate queries, retrieved documents, and answers."
- Inductive Bias: Model predispositions that make certain solutions or representations more natural or effective. "we can directly leverage the inductive bias of code models"
- In-Domain Evaluation: Assessing methods on data similar to or from the same distribution as the training set. "HotpotQA serves as the in-domain training set for RL-trained variants"
- Instruction-Following LLM: A LLM tuned to follow task instructions and produce concise, targeted outputs. "It is implemented using an instruction-following LLM"
- Instruction-Tuned Model: An LLM trained or fine-tuned to follow instructions rather than code synthesis tasks. "under Vanilla RAG, replacing the instruction-tuned model with a code-specialized counterpart yields negligible differences"
- Multi-Hop Question Answering (QA): QA tasks that require chaining multiple retrieval and reasoning steps across sources. "We observe that multi-hop question answering is a typical form of step-by-step computation"
- Open-Domain QA: Question answering where evidence must be retrieved from broad, unconstrained sources like the web or Wikipedia. "Such questions are pervasive in open-domain QA"
- Planning Agent: An LLM component that generates an executable program specifying the sequence of retrieval and answer operations. "it generates a program that specifies how to solve the task through a sequence of retrieval and answering operations."
- Program-Guided Reasoning: Approaches that use executable code to structure and verify reasoning steps. "a parallel line of program-guided reasoning work~\citep{gao2023pal, chen2022program, cheng2022binding, lyu2023faithful, pan2023logic, pan2023fact} does leverage executable code"
- Program Synthesis: Automatically generating code that embodies a reasoning or computational process. "reformulates multi-hop RAG as program synthesis and execution"
- Reinforcement Learning (RL): A learning paradigm where models are trained via rewards to optimize behavior, including search and retrieval policies. "reinforcement learning variants of a standard RAG pipeline."
- Retrieval-Augmented Generation (RAG): A paradigm where generation is grounded in retrieved external evidence. "Retrieval-Augmented Generation (RAG) has become a standard approach for knowledge-intensive question answering"
- Runtime Exceptions: Errors that occur during program execution, used as signals to revise the reasoning program. "runtime exceptions provide deterministic signals for the Plan Agent to revise the program"
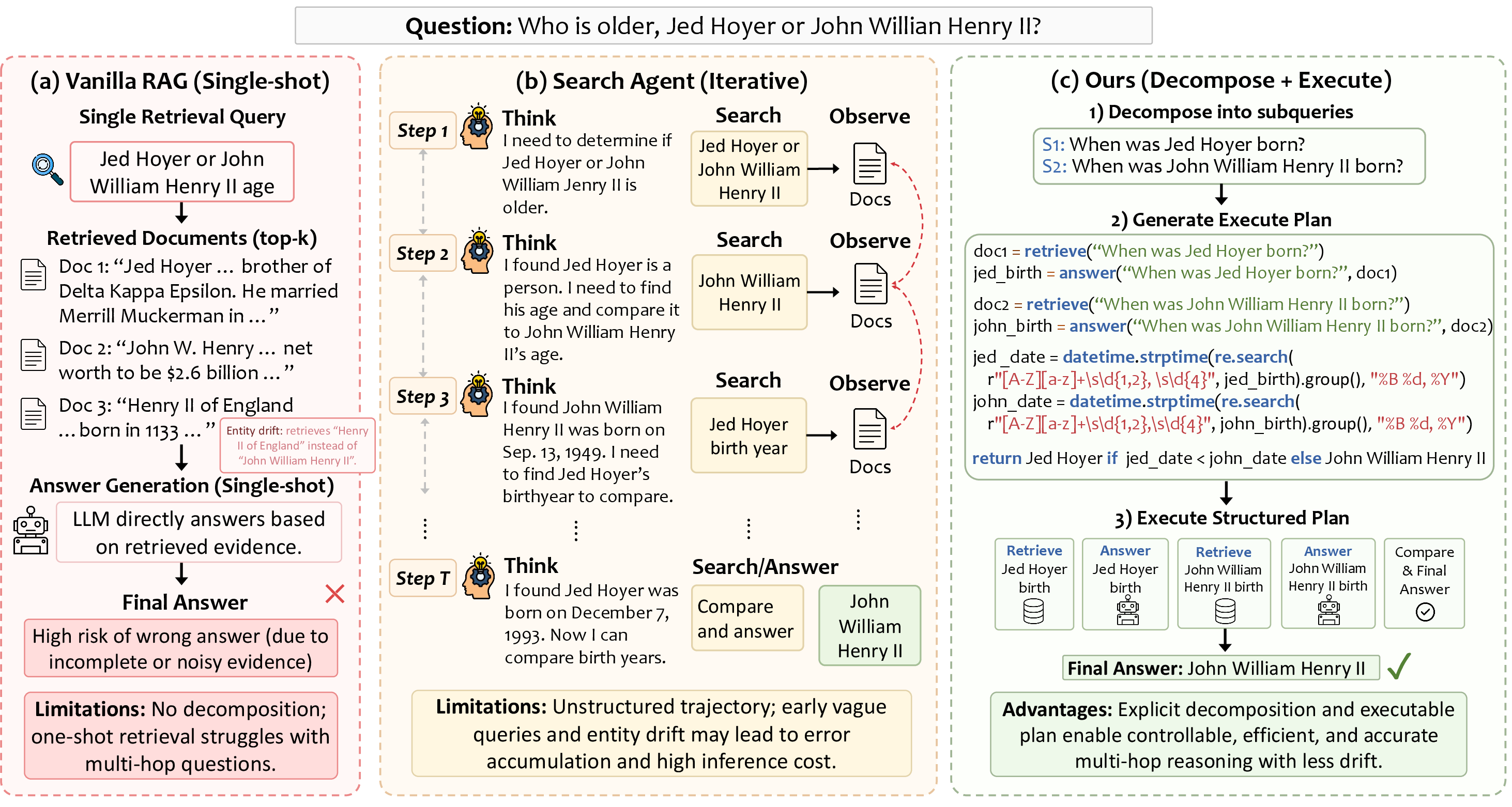
- Search Agents: LLM-driven systems that iteratively plan and execute retrieval actions in free-form trajectories. "Search Agents follow an unstructured iterative trajectory where vague queries and entity drift (e.g., retrieving
Henry II of England'' instead ofJohn William Henry II'') accumulate errors across steps;" - Sentinel Response: A special placeholder output indicating failure to extract an answer, often triggering refinement. "returns a sentinel response (e.g., ``unknown'') because it fails to compose an answer from the retrieved evidence"
- Structured Planning: Explicitly materializing a plan as an inspectable artifact rather than relying on implicit, reactive traces. "five key dimensions: multi-hop capability, interpretability, structured planning, reflection, and executable interface"
- Top-k Retrieval: Limiting retrieval to the k most relevant documents, often adapted based on execution feedback. "top- retrieval budget"
- Tool Primitives: Minimal APIs exposed to programs for retrieval and answering operations. "two tool primitives, retrieve(query, topk) and answer(query, docs)"
- Vanilla RAG: The single-shot retrieve-then-read baseline without iterative or multi-hop reasoning. "Vanilla RAG performs single-shot retrieve-then-read."
- Variable Assignments: Binding intermediate results to named variables for reuse and composition in later steps. "The planning agent generates a program that composes these APIs through variable assignments."
- Verifiable Execution Interface: An execution setup that yields deterministic feedback (e.g., errors, traces) for validation and debugging. "a framework that provides a verifiable execution interface for multi-hop RAG."
Collections
Sign up for free to add this paper to one or more collections.