Graph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning (2507.21892v1)
Abstract: Retrieval-Augmented Generation (RAG) mitigates hallucination in LLMs by incorporating external knowledge, but relies on chunk-based retrieval that lacks structural semantics. GraphRAG methods improve RAG by modeling knowledge as entity-relation graphs, but still face challenges in high construction cost, fixed one-time retrieval, and reliance on long-context reasoning and prompt design. To address these challenges, we propose Graph-R1, an agentic GraphRAG framework via end-to-end reinforcement learning (RL). It introduces lightweight knowledge hypergraph construction, models retrieval as a multi-turn agent-environment interaction, and optimizes the agent process via an end-to-end reward mechanism. Experiments on standard RAG datasets show that Graph-R1 outperforms traditional GraphRAG and RL-enhanced RAG methods in reasoning accuracy, retrieval efficiency, and generation quality.
Summary
- The paper introduces an agentic GraphRAG framework that leverages reinforcement learning for multi-turn, hypergraph-based retrieval and generation.
- It integrates lightweight knowledge hypergraph construction with dual-path retrieval to capture high-order relational semantics efficiently.
- Empirical results across six benchmarks demonstrate improved F1 scores, efficiency, and robust generalizability compared to chunk-based RAG methods.
Graph-R1: An Agentic GraphRAG Framework via End-to-End Reinforcement Learning
Introduction and Motivation
Graph-R1 addresses fundamental limitations in Retrieval-Augmented Generation (RAG) for LLMs, particularly the inability of chunk-based retrieval to capture complex knowledge structures and the inefficiency of existing graph-based RAG (GraphRAG) methods. Traditional RAG approaches rely on retrieving flat text chunks, which lack explicit relational semantics, while prior GraphRAG methods, though leveraging entity-relation graphs, are hampered by high construction costs, fixed one-shot retrieval, and dependence on prompt engineering and large LLMs for long-context reasoning. Graph-R1 introduces an agentic framework that models retrieval as a multi-turn interaction over a lightweight knowledge hypergraph, optimized end-to-end via reinforcement learning (RL). This design enables more expressive knowledge representation, adaptive retrieval, and tighter integration between structured knowledge and language generation.
Framework Overview
Graph-R1 consists of three principal components: (1) lightweight knowledge hypergraph construction, (2) multi-turn agentic reasoning over the hypergraph, and (3) outcome-directed end-to-end RL optimization.
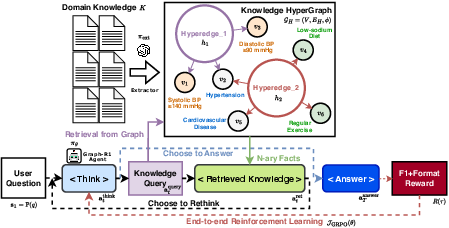
Figure 1: Overview of the Graph-R1 framework: an RL-enhanced reasoning trajectory over knowledge hypergraph, where the agent iteratively decides to think, query, retrieve knowledge, and answer.
Knowledge Hypergraph Construction
Graph-R1 employs an LLM-based extractor to parse raw text into n-ary relational facts, forming a hypergraph GH=(V,EH,ϕ), where V is the set of entities, EH the set of hyperedges (relations), and ϕ the embedding function. This approach encodes high-order relational structures, capturing richer semantics than binary graphs or flat chunks, while maintaining lower construction cost by omitting confidence scoring and using efficient semantic retrieval.
Multi-Turn Agentic Reasoning
The agent operates in a Markovian environment defined by the hypergraph, with an action space comprising four sub-actions: thinking (reflection), query generation, graph retrieval, and answering. At each step, the agent decides whether to continue reasoning (by generating a new query and retrieving knowledge) or to terminate and produce an answer. Retrieval is performed via a dual-path mechanism: entity-based hyperedge retrieval and direct hyperedge retrieval, with results fused by reciprocal rank aggregation. This multi-turn interaction enables the agent to iteratively refine its knowledge state, adaptively explore the graph, and balance exploration with answer generation.
End-to-End RL Optimization
Graph-R1 is trained using Group Relative Policy Optimization (GRPO), an RL algorithm that stabilizes policy updates and supports scalable end-to-end training. The reward function is outcome-directed, combining a format reward (enforcing well-formed reasoning traces) and an answer reward (token-level F1 against ground truth), with answer correctness rewarded only if the reasoning structure is valid. This design tightly couples retrieval and generation, incentivizing the agent to produce both structurally coherent and semantically accurate answers.
Empirical Results
Performance Across Benchmarks
Graph-R1 is evaluated on six standard RAG datasets (2WikiMultiHopQA, HotpotQA, Musique, NQ, PopQA, TriviaQA) and compared against a comprehensive suite of baselines, including chunk-based RAG, prompt-based and RL-enhanced GraphRAG variants, and multi-turn RL agents with chunk retrieval.
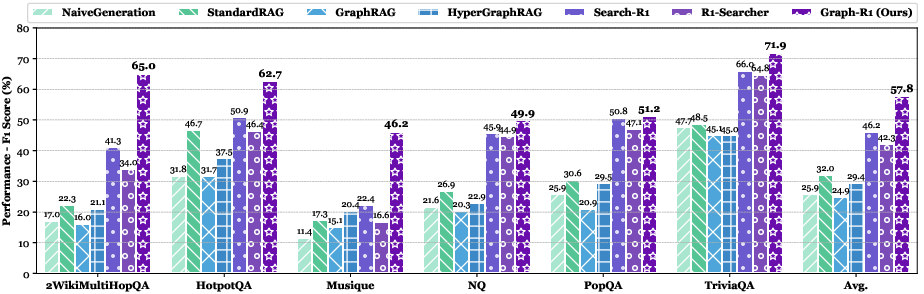
Figure 2: Comparison of F1 scores across RAG benchmarks. Using a graph as the knowledge environment enables RL to achieve a higher performance ceiling compared to chunk-based knowledge.
Graph-R1 consistently outperforms all baselines in F1, EM, retrieval similarity, and generation quality. Notably, the combination of graph-based knowledge and RL yields a substantial performance gap over both chunk-based RL agents (e.g., Search-R1) and prompt-based GraphRAG methods, especially as the base model size increases.
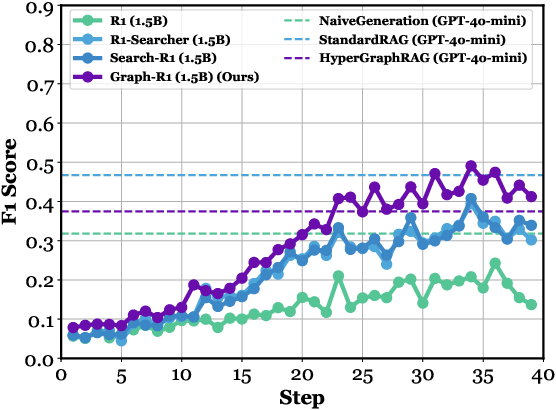
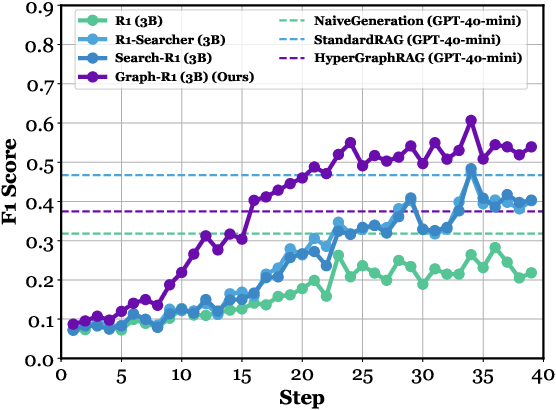
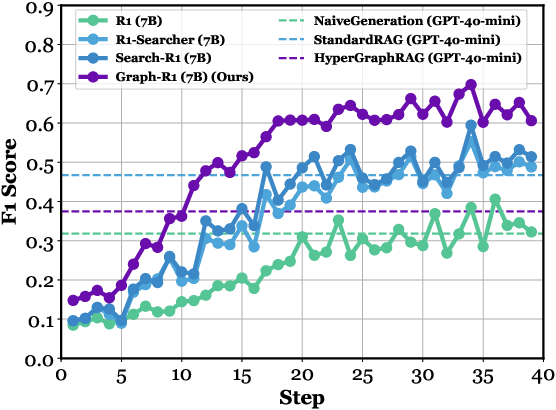
Figure 3: Step-wise F1 score on HotpotQA based on Qwen2.5 (1.5B, 3B, 7B), where Graph-R1 outperforms baselines and GPT-4o-mini variants (NaiveGeneration, StandardRAG, HyperGraphRAG).
Ablation and Comparative Analysis
Ablation studies confirm that each core component—hypergraph construction, multi-turn interaction, and RL optimization—contributes significantly to final performance. Removing any module leads to marked degradation, with the absence of RL resulting in the most severe drop.
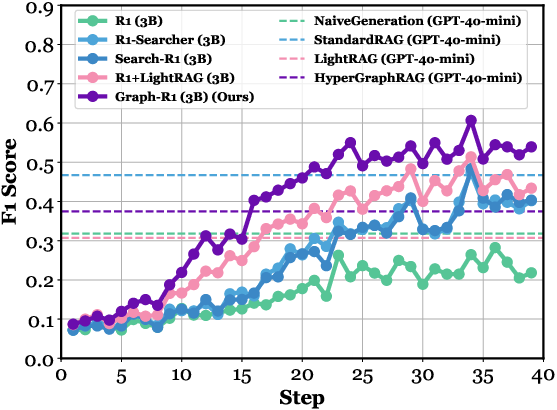
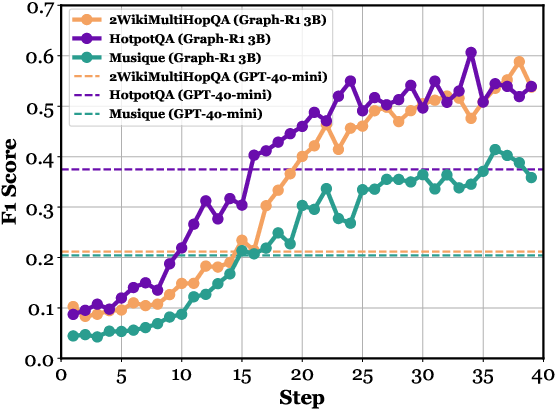
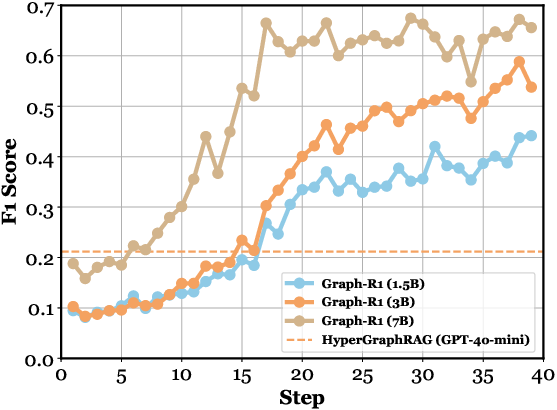
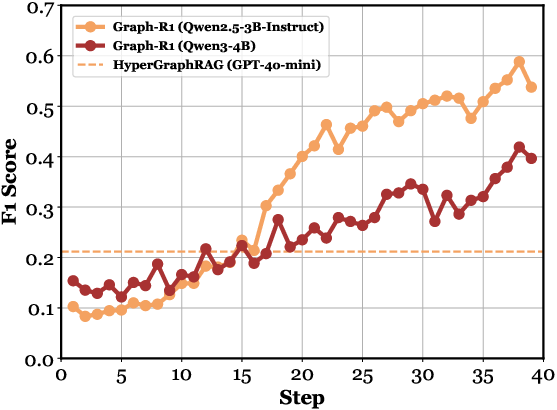
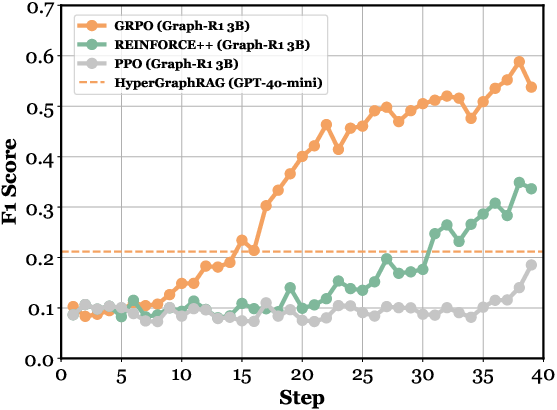
Figure 4: (a) Ablation paper of Graph-R1. (b-f) Performance comparison across different kinds of knowledge representations, RAG datasets, model parameters, Qwen versions, and RL algorithms.
Comparisons across knowledge representations show that hypergraph-based retrieval with RL achieves the highest performance ceiling, surpassing both chunk-based and binary graph-based methods. GRPO is empirically superior to REINFORCE++ and PPO for multi-turn graph reasoning.
Efficiency and Cost
Graph-R1 achieves lower knowledge construction and generation costs than prior GraphRAG methods, with faster response times and zero generation cost per query due to efficient localized retrieval and RL-driven reasoning.
Retrieval Efficiency
Graph-R1 produces more concise responses and conducts more interaction turns per query, leading to stable and accurate retrieval with moderate input lengths.
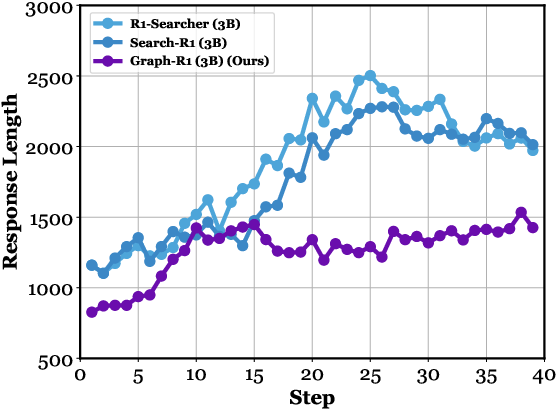
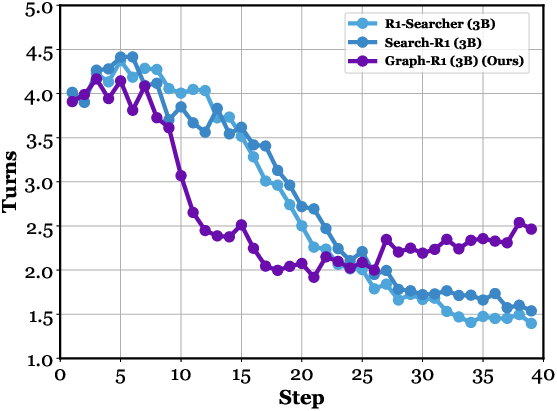
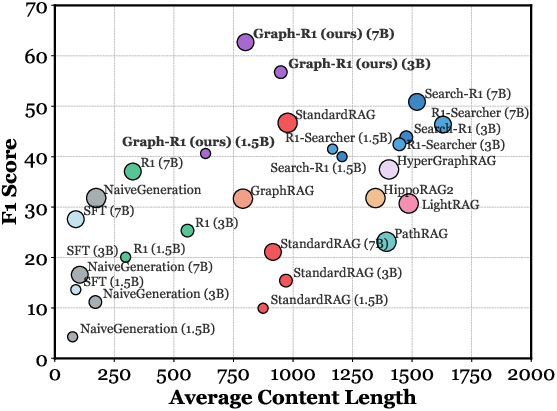
Figure 5: Step-wise response length, turns of interaction, and efficiency comparison on HotpotQA.
Generation Quality
Graph-R1 achieves high scores in correctness, relevance, and logical coherence, outperforming both RL-based chunk agents and prompt-based graph methods. The RL objective effectively bridges the gap between graph-structured knowledge and natural language generation.
Generalizability
O.O.D. cross-validation demonstrates that Graph-R1 generalizes robustly across datasets, maintaining high F1 and O.O.D.-to-I.I.D. performance ratios, attributable to its multi-turn, graph-grounded reasoning and end-to-end RL alignment.
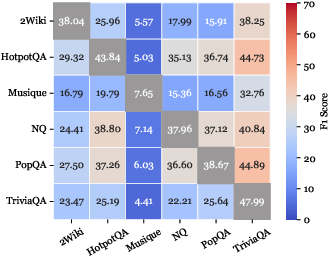
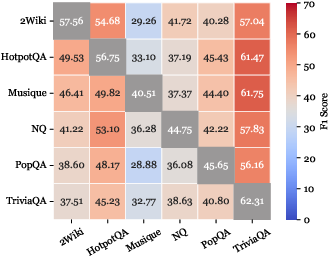
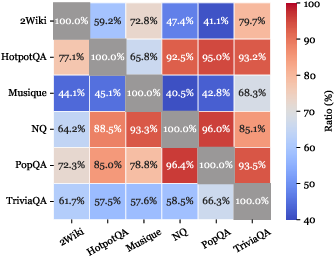
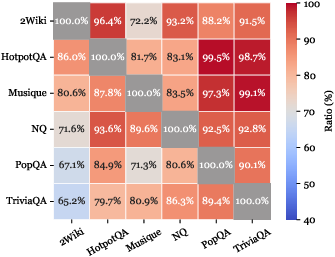
Figure 6: F1 comparison and performance ratios across six datasets under O.O.D. cross-validation.
Theoretical Implications
The paper provides formal proofs that (1) graph-structured knowledge increases information density and accelerates belief convergence, (2) multi-turn interaction enables more efficient and accurate retrieval by adaptively focusing on informative graph regions, and (3) end-to-end RL aligns graph retrieval with answer generation, reducing conditional entropy and error rates.
Implementation Considerations
- Hypergraph Construction: Requires an LLM-based extractor and semantic encoder; construction cost is lower than prior GraphRAGs due to streamlined extraction and omission of confidence scoring.
- Agentic Reasoning: The agent policy can be implemented as a hierarchical LLM prompt or as a modular neural policy; dual-path retrieval leverages vector similarity over entity and hyperedge embeddings.
- RL Training: GRPO is recommended for stability and scalability; reward shaping is critical to enforce both structural and semantic objectives.
- Scalability: All components are parallelizable; retrieval is localized to compact hypergraph subsets, supporting large-scale deployment.
- Limitations: Hypergraph construction cost, lack of structural reasoning in retrieval, and restriction to textual knowledge are noted; future work may explore GNN-based retrieval, multi-modal extension, and domain-specific applications.
Conclusion
Graph-R1 establishes a new paradigm for agentic RAG by integrating lightweight hypergraph knowledge representation, multi-turn agentic reasoning, and end-to-end RL optimization. Empirical and theoretical results demonstrate that this approach achieves superior accuracy, efficiency, and generalizability compared to both chunk-based and prior graph-based RAG methods. The framework provides a scalable and robust foundation for knowledge-intensive LLM applications, with promising avenues for further research in efficient knowledge extraction, structural retrieval, and multi-modal reasoning.
Follow-up Questions
- How does the agentic reasoning process improve retrieval accuracy in Graph-R1?
- What are the benefits of using a lightweight hypergraph over traditional text chunk retrieval?
- How does end-to-end reinforcement learning enhance both retrieval and generation in this framework?
- What limitations does Graph-R1 address compared to previous GraphRAG methods?
- Find recent papers about graph-based retrieval in natural language processing.
Related Papers
- GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning (2024)
- Graph Retrieval-Augmented Generation: A Survey (2024)
- Retrieval-Augmented Generation with Graphs (GraphRAG) (2024)
- A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models (2025)
- Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning (2025)
- HiRAG: Retrieval-Augmented Generation with Hierarchical Knowledge (2025)
- R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning (2025)
- Towards Agentic RAG with Deep Reasoning: A Survey of RAG-Reasoning Systems in LLMs (2025)
- GraphRAG-R1: Graph Retrieval-Augmented Generation with Process-Constrained Reinforcement Learning (2025)
- Beyond Chunks and Graphs: Retrieval-Augmented Generation through Triplet-Driven Thinking (2025)
YouTube
HackerNews
- Graph-R1: Towards Agentic GraphRAG Framework via End-to-End RL (1 point, 0 comments)
alphaXiv
- Graph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning (61 likes, 0 questions)