- The paper introduces GRIP, a framework that embeds retrieval within generation via explicit control tokens for coordinated evidence acquisition and answer finalization.
- It employs dynamic query reformulation and dual-phase training (SFT followed by RL) to effectively balance internal knowledge with external retrieval, enhancing multi-hop reasoning.
- GRIP achieves competitive performance with reduced retrieval calls and latency by adaptively adjusting retrieval depth based on task complexity and evidence sufficiency.
Introduction and Motivation
Retrieval-Augmented Generation (RAG) frameworks for LLMs have become central to open-domain QA, fact verification, and multi-hop reasoning, owing to their ability to amalgamate powerful generative modeling with grounded external evidence. However, the dominant paradigm relies on staged architectures—an initial query produces retrieved contexts in a static, one-shot fashion, followed by answer generation. This strict separation is both inflexible and suboptimal for compositional queries, ambiguous questions, or tasks where the information need surfaces incrementally as reasoning unfolds.
The paper "Retrieval as Generation: A Unified Framework with Self-Triggered Information Planning" (2604.11407) introduces GRIP, an architecture that casts retrieval as an inherent part of the generation process. Retrieval decisions, query reformulation, and answer finalization are embedded into the model’s autoregressive decoding through the emission of explicit control tokens, thus enabling fully end-to-end coordination between reasoning and evidence acquisition without external controllers.
At the core of GRIP is the notion of retrieval-as-generation. The model’s output space is augmented with special control tokens—[ANSWER], [INTERMEDIARY], [RETRIEVE], and [SOLVED]. The emission of these tokens governs retrieval and answer-planning behaviors, allowing the model to reason about sufficiency, plan multi-hop evidence acquisition, and dynamically adapt the inference trajectory.
The model's operational semantics are as follows:
- If the model's internal knowledge suffices, it emits [ANSWER] followed by the answer and concludes with [SOLVED].
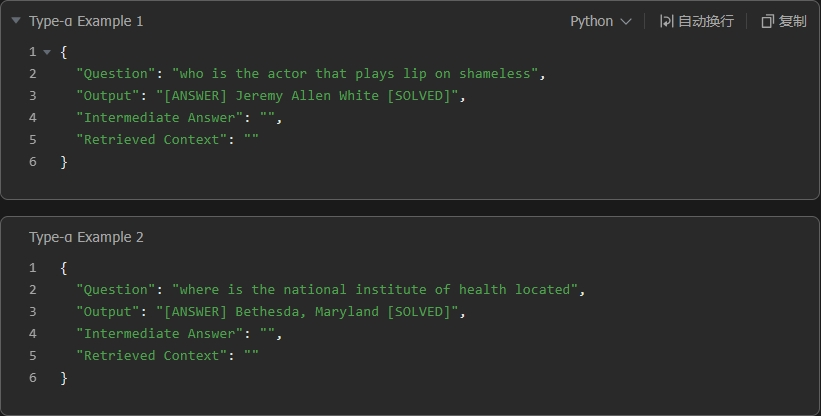
Figure 2: Type-α behavior: direct answering and termination via [ANSWER] and [SOLVED], without invoking retrieval.
- If uncertainty is detected or the answer is partial/disfluent with respect to the target, [INTERMEDIARY] is emitted. The model then triggers retrieval by emitting [RETRIEVE] and dynamically generates a sub-query.
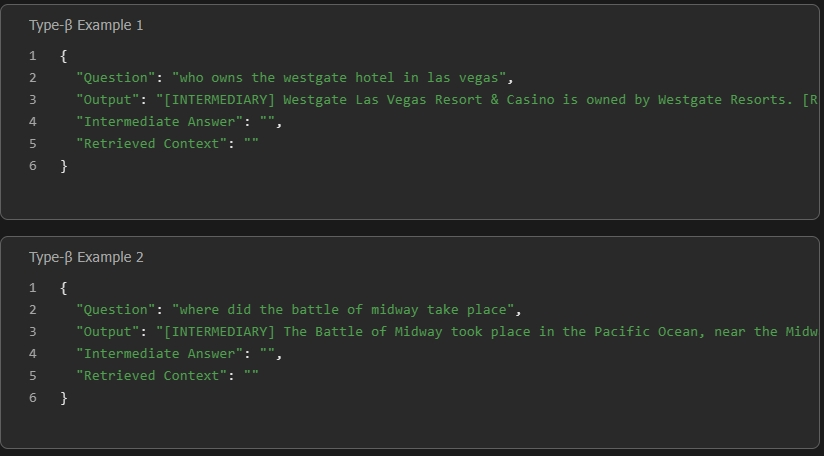
Figure 4: Type-β behavior: model reflects uncertainty, issues a retrieval action, and reformulates the query contextually.
- In complex, multi-hop, or underdetermined cases, iterative cycles of [INTERMEDIARY]→[RETRIEVE] are repeated, allowing the model to refine sub-questions and accumulate sufficient context before finally emitting [ANSWER] and [SOLVED].
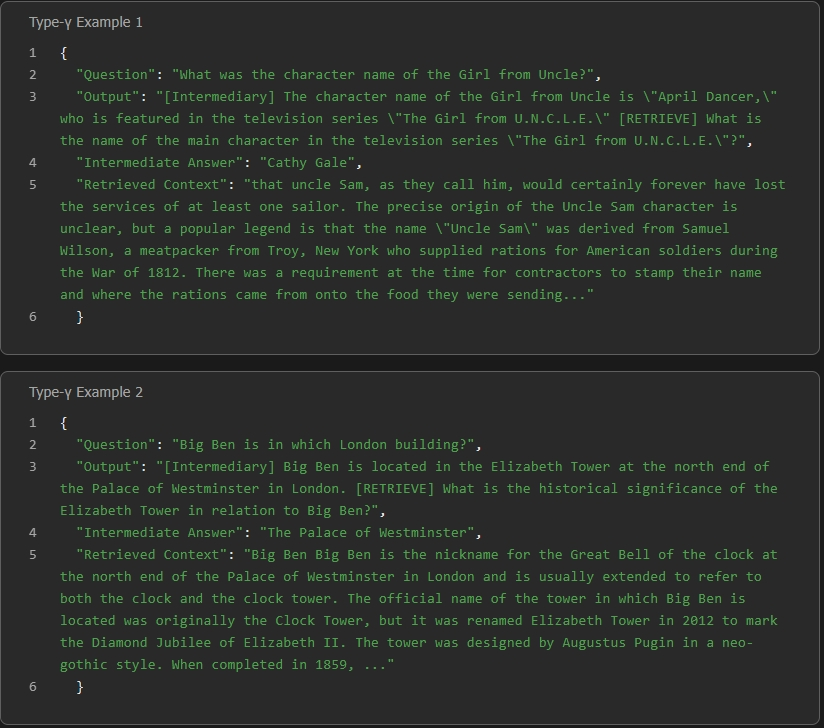
Figure 6: Type-γ behavior: multi-step planning and evidence integration for knowledge that is neither in parametric memory nor surfaced by naive retrieval.
- When retrieved passages are relevant but require synthesis, compression, or further reasoning beyond span extraction, the model continues to leverage [INTERMEDIARY] and [RETRIEVE] before resolving with an answer.
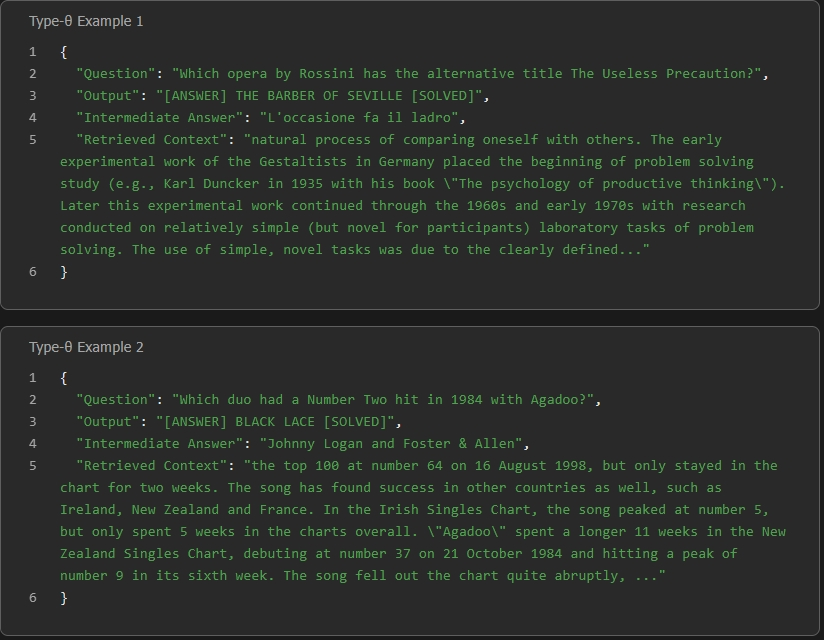
Figure 1: Type-θ behavior: retrieved content must be distilled and fused; answer is synthesized via controlled progression of token emissions.
Structured Supervision and Optimization Paradigm
GRIP's training paradigm is anchored in structured supervision. Training instances are categorized by answerability type, each mapped to a unique target sequence of control tokens and natural language, enabling precise supervision of when to retrieve, how to reformulate queries, and when to stop.
The authors employ a two-phase optimization:
- Supervised Fine-Tuning (SFT): Cross-entropy minimization over generated sequences (language plus control tokens) instills the basic behavioral policy.
- Reinforcement Learning (RL, DAPO-algorithm): Fine-tuning employs answer fidelity (BLEU-based) and control-token accuracy rewards, steering the model toward retrieval-frugal and answer-faithful policies. RL here corrects the SFT’s tendency to over-retrieve.
Empirical Evaluation
Quantitative Results
GRIP is extensively benchmarked on five QA datasets (HotpotQA, PopQA, NQ, WebQ, TriviaQA), evaluated with EM, ROUGE, and F1. GRIP outperforms all open-source RAG baselines and is competitive with closed GPT-4o, despite using an order-of-magnitude smaller base model (LLaMA3-8B). In particular, GRIP’s gains are accentuated on multi-hop datasets (HotpotQA, TriviaQA), underscoring the benefits of dynamic, context-sensitive retrieval planning.
Retrieval Depth Adaptivity
GRIP displays context-aware retrieval budgeting, suppressing unnecessary retrieval on answerable questions, and deepening search only when evidence is manifestly insufficient. In contrast, alternative training-based RAGs exhibit near-constant retrieval depth. RL-induced policies further reduce mean retrievals per example (from 1.60 to 1.24), supporting practical deployment with low latency-cost tradeoff.
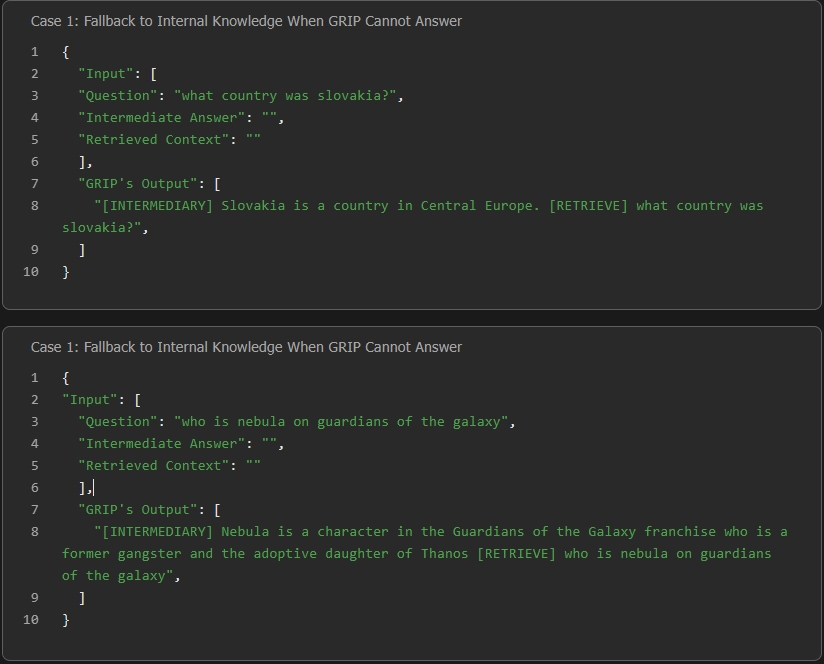
Figure 3: GRIP avoids retrieval and relies on internal knowledge where possible, contrasting with fixed-schedule baselines.
Iterative Query Refinement and Planning
Unlike prior approaches, GRIP excels in generating high-quality, contextually targeted queries in later search steps, iteratively reformulating questions based on partially retrieved evidence, which substantially increases the likelihood that gold answer spans are covered in the top retrieved documents.
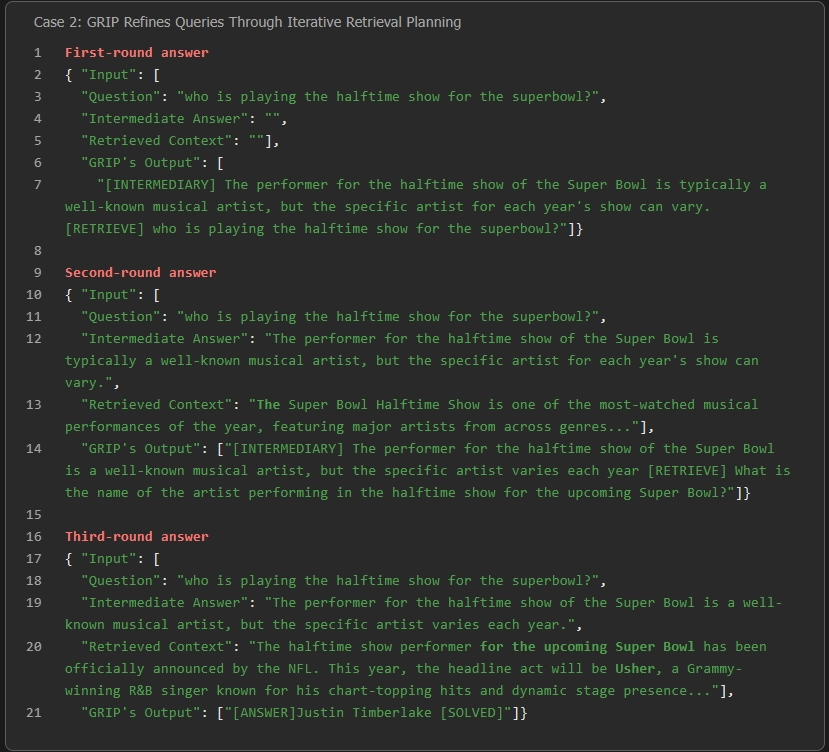
Figure 5: Multi-round, on-the-fly reformulation and improvement of retrieval queries for hard examples.
Compositional and Compression-Oriented Reasoning
For settings where retrieval results require synthesis or implicit reasoning, GRIP leverages the [INTERMEDIARY]→[RETRIEVE]→[ANSWER] transition to selectively distill and compress evidence, surpassing extractive approaches.
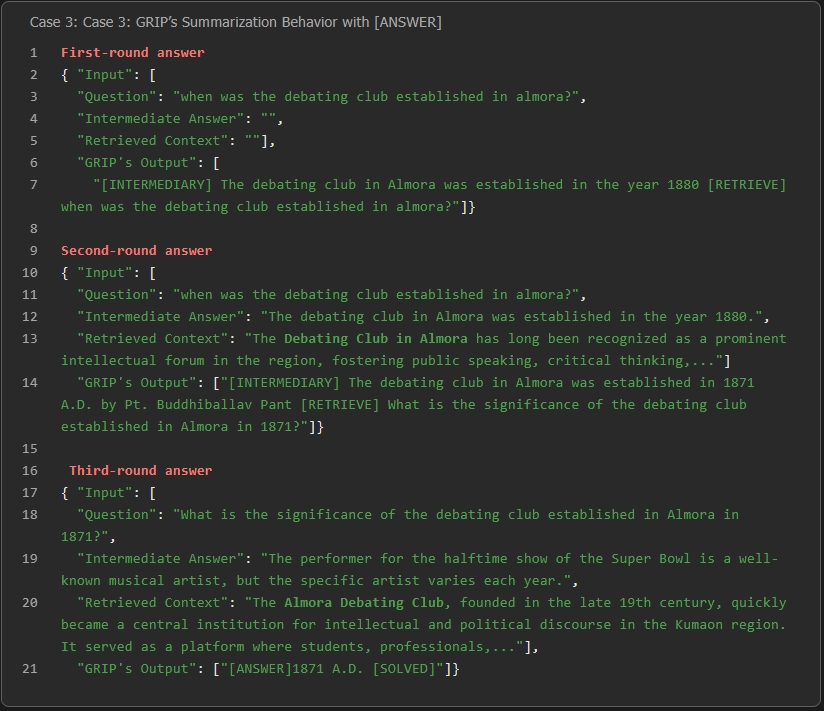
Figure 7: The model compresses, summarizes, and integrates the retrieved content into a concise, correct answer.
Latent State Analysis
PCA projections of the model’s hidden states immediately before control-token emissions in QA show clear, separable clusters for [ANSWER] vs. [RETRIEVE], indicating robust internalization of retrieval and answer control policies.
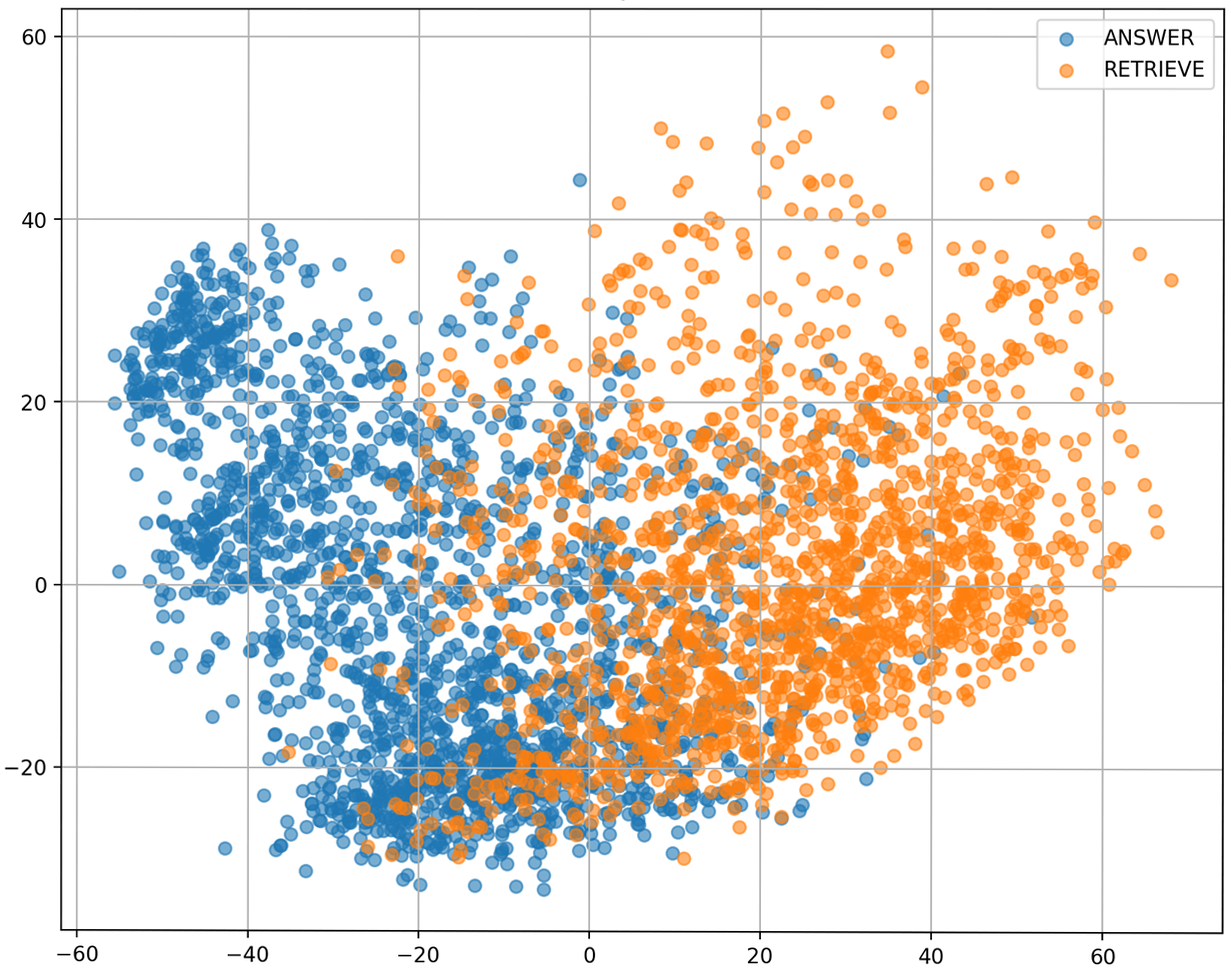
Figure 12: Model latent representations cluster distinctly by control token, confirming internal separation of retrieval and answer emission behaviors.
Implications and Future Directions
The GRIP framework eliminates the necessity for auxiliary retrieval controllers, ad hoc uncertainty heuristics, or rigid prompt chaining. By structuring retrieval as a generative, token-level skill, it facilitates direct and interpretable learning of context-sensitive policies, enables dynamic adjustment to task complexity, and generalizes beyond training-time retrieval budgets.
The mechanism by which GRIP integrates retrieval, reasoning, and answer finalization as compositional generative actions offers new tools for transparent error analysis and policy debugging. Additionally, the structured supervision paradigm is robust to the use of different teacher models for complex cases—closed-source distillation is not essential.
Future work may extend in several directions:
- Joint retriever-generator training for further optimization of end-to-end answer coverage and retrieval efficiency.
- Application to multimodal RAG and instruction-following agents.
- Automated curriculum generation for more challenging, deeper, or open-ended task suites.
Conclusion
GRIP represents a conceptually elegant and empirically validated framework for bridging the gap between fixed retrieval pipelines and the nuanced, information-seeking behaviors required for advanced QA and reasoning tasks. Its ability to internalize retrieval policies, adaptively control evidence acquisition, and preserve general generative capability with minimal parameter overhead sets a new standard for controllable, transparent retrieval-augmented generation.

