LIR$^3$AG: A Lightweight Rerank Reasoning Strategy Framework for Retrieval-Augmented Generation
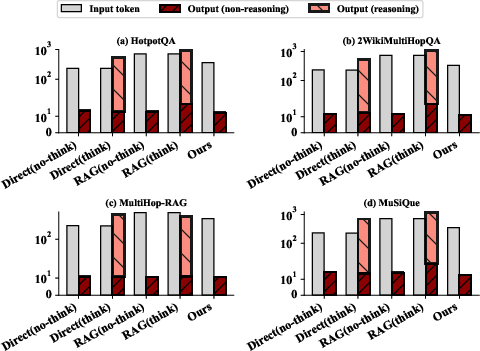
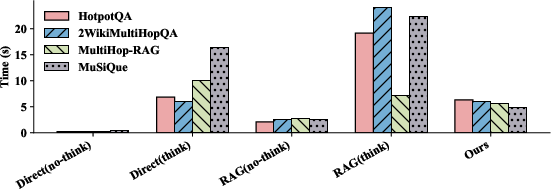
Abstract: Retrieval-Augmented Generation (RAG) effectively enhances LLMs by incorporating retrieved external knowledge into the generation process. Reasoning models improve LLM performance in multi-hop QA tasks, which require integrating and reasoning over multiple pieces of evidence across different documents to answer a complex question. However, they often introduce substantial computational costs, including increased token consumption and inference latency. To better understand and mitigate this trade-off, we conduct a comprehensive study of reasoning strategies for reasoning models in RAG multi-hop QA tasks. Our findings reveal that reasoning models adopt structured strategies to integrate retrieved and internal knowledge, primarily following two modes: Context-Grounded Reasoning, which relies directly on retrieved content, and Knowledge-Reconciled Reasoning, which resolves conflicts or gaps using internal knowledge. To this end, we propose a novel Lightweight Rerank Reasoning Strategy Framework for RAG (LiR$3$AG) to enable non-reasoning models to transfer reasoning strategies by restructuring retrieved evidence into coherent reasoning chains. LiR$3$AG significantly reduce the average 98% output tokens overhead and 58.6% inferencing time while improving 8B non-reasoning model's F1 performance ranging from 6.2% to 22.5% to surpass the performance of 32B reasoning model in RAG, offering a practical and efficient path forward for RAG systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces LiRAG, a new way to help AI models answer tough questions that need multiple pieces of information. The goal is to get accurate answers with clear reasoning, but without the extra cost and slowness that comes from using special “reasoning” models. LiRAG makes smaller, faster models behave more like big reasoning models by organizing the information they look up into neat, step-by-step reasoning chains.
Key Questions the Paper Tries to Answer
- Can we make regular AI models (that don’t “think out loud”) solve complex, multi-step questions more accurately?
- Can we do this while using fewer tokens (the text the model reads and writes) and less time than big reasoning models?
- What strategies do reasoning models use inside Retrieval-Augmented Generation (RAG), and can we transfer those strategies to simpler models?
How the Researchers Did It (Methods and Analogies)
Think of answering a complex question like solving a mystery:
- You need to find clues in different places (web pages, documents).
- You have to connect these clues in the right order to figure out the answer.
- Sometimes clues disagree, and you need to settle the conflict carefully.
Here’s what those ideas mean in AI terms:
- Retrieval-Augmented Generation (RAG): The AI first retrieves (looks up) text snippets from a large collection, then uses them to generate the answer. This helps reduce “hallucinations” (incorrect made-up facts).
- Multi-hop Question Answering: These are questions that need more than one piece of evidence, often from different sources (like connecting two Wikipedia pages).
- Tokens: Tiny chunks of text (words or parts of words) that models read and write. More tokens = more cost and time.
- Reasoning models vs. non-reasoning models: Reasoning models write out their thinking steps, which can be helpful but slow and expensive. Non-reasoning models jump straight to answers.
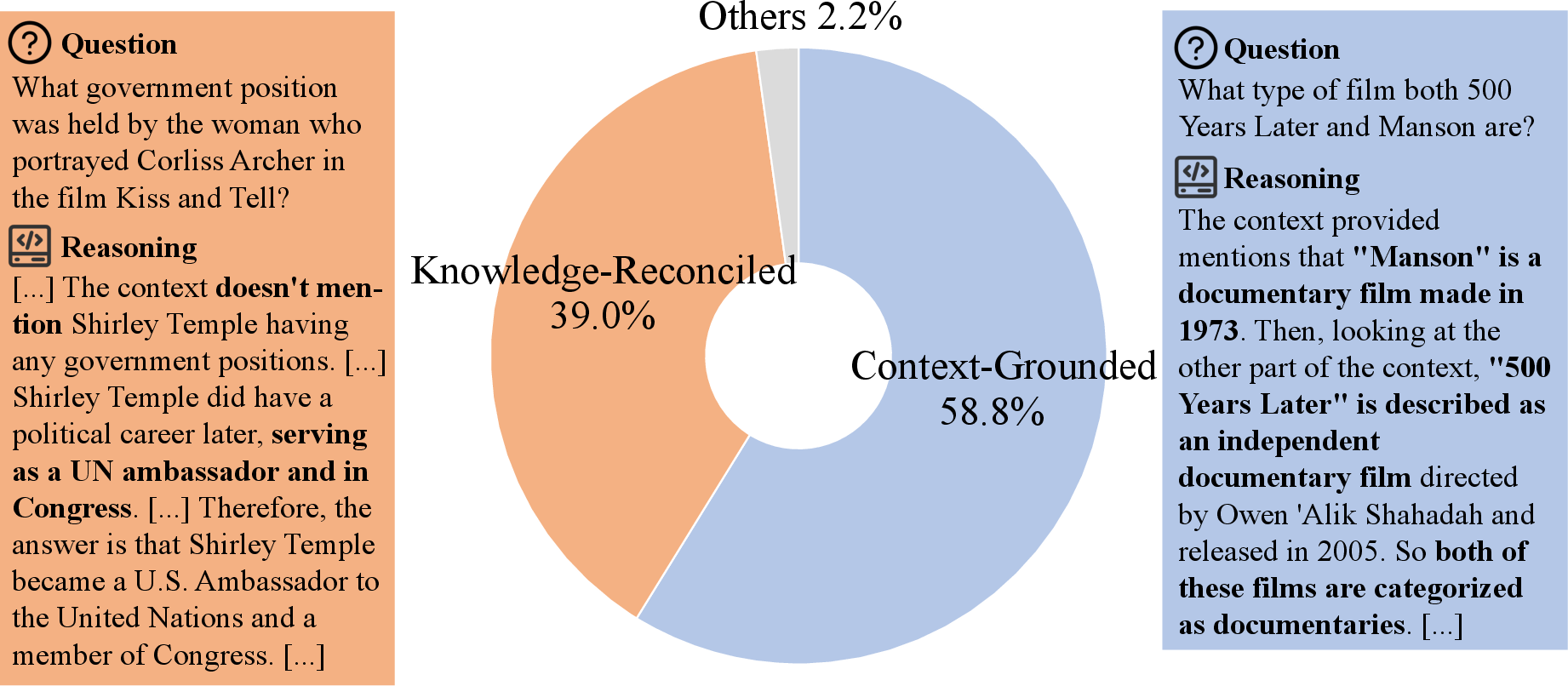
The authors first studied how reasoning models behave inside RAG and found two main strategies:
- Context-Grounded Reasoning: The model relies mostly on the retrieved documents to reason and answer.
- Knowledge-Reconciled Reasoning: The model compares the retrieved text with its own internal knowledge and resolves conflicts—this can get long and messy if the retrieved text is irrelevant.
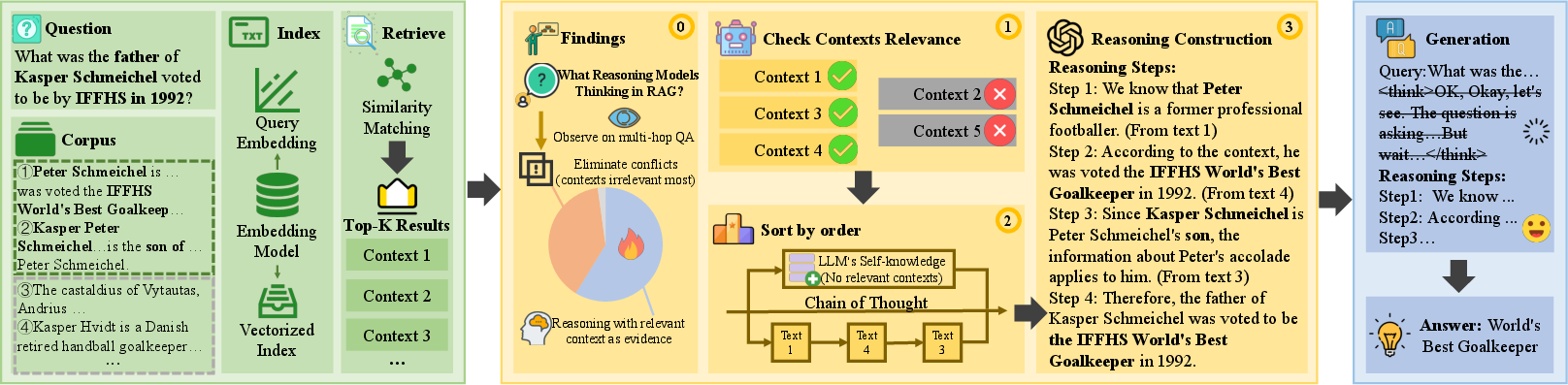
Then they built LiRAG to help regular models follow the effective parts of those strategies without the heavy costs. The framework has three parts:
- Retriever: Finds potentially relevant pieces of text.
- Reranker: Filters out irrelevant text and puts the remaining pieces in the best order for reasoning (like arranging clues in the right sequence).
- Reasoning Constructor: Builds a short, clear chain of reasoning steps from the selected clues and passes it to the model to generate the answer.
They tested LiRAG on several multi-hop QA datasets (like HotpotQA, 2WikiMultihopQA, MultiHop-RAG, and MuSiQue).
Main Findings and Why They Matter
- Better accuracy with smaller models: Using LiRAG, a small 8-billion-parameter (8B) non-reasoning model matched or beat a much larger 32B reasoning model on multi-hop tasks. In F1 score (a measure of answer quality), the improvements ranged from about 6% to 22.5%.
- Much lower cost:
- Output tokens dropped by about 98% on average (because the method avoids long, repetitive reasoning text).
- Inference time (how long the model takes to answer) decreased by about 58.6%.
- Clear reasoning without redundancy: By focusing on Context-Grounded Reasoning and cleaning up irrelevant context with the Reranker, LiRAG avoids the long, off-track thinking that reasoning models sometimes produce.
- Strategy insight: In their analysis, most answers (about 58.8%) from reasoning models were grounded directly in the retrieved context. LiRAG leans into that strength and transfers it to non-reasoning models.
What This Means Going Forward (Implications)
- Faster, cheaper AI systems: LiRAG lets teams build RAG systems that are both accurate and efficient, which is great for real-world apps where speed and cost matter—like customer support, research assistants, or educational tools.
- Less dependence on huge reasoning models: Smaller models can deliver strong performance if we organize retrieved evidence properly.
- More trustworthy answers: By grounding reasoning in the most relevant documents and ordering them like a logical chain, answers are clearer and easier to verify.
- Practical trade-offs: You can tune how many pieces of text to retrieve (Top-k). More context can boost accuracy but also increases cost. LiRAG helps balance this by filtering and ordering the best evidence.
- Future work: The authors plan to combine LiRAG with more advanced RAG methods, which could further improve accuracy while keeping costs low.
In simple terms: LiRAG is like giving a regular AI a smart detective’s playbook—find the right clues, sort them in the right order, and explain the solution briefly and clearly—so you get great answers quickly without buying the most expensive tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future researchers could act on:
- External validity of the reasoning-strategy analysis: results are based on Qwen3 and 500 HotpotQA queries; replicate across multiple reasoning/non-reasoning LLMs (e.g., o1, DeepSeek-R1, Llama, Mistral) and diverse multi-hop datasets to assess generality.
- Annotation rigor for strategy identification: reliance on GPT-4o-mini for labeling without human validation, inter-annotator agreement, or a released codebook; create a publicly available, human-annotated benchmark of “context-grounded vs knowledge-reconciled” reasoning with reliability statistics.
- Ambiguity handling in strategy labels: 2.2% of cases were “ambiguous” but excluded; define criteria for ambiguity and evaluate how ambiguous cases affect downstream system design and performance.
- Missing comparisons to strong RAG baselines: no head-to-head evaluation versus contemporary structured RAG methods (e.g., GraphRAG, LightRAG, ReAct-style RAG, iterative retrieval) and retriever–reranker pipelines (e.g., BM25+dense+cross-encoder).
- Under-specified retriever setup: the main experiments do not report the exact retrieval model(s), index type, chunking strategy, corpus preprocessing, and hyperparameters; provide detailed retrieval configs to enable reproducibility and ablation on retrieval quality.
- Reranker method details are vague: no explicit scoring function, thresholding scheme, training objective, or calibration approach for filtering and ordering evidence; evaluate LLM-based reranking against trained cross-encoders and supervised rerankers.
- Lack of quantitative evaluation of reranking quality: measure evidence selection and ordering accuracy (e.g., supporting-fact recall/precision, MAP/MRR, order correctness vs. ground-truth evidence chains).
- Reasoning Constructor is template-based and linear: investigate graph-structured or programmatic reasoning (e.g., DAGs, program-of-thought) to handle branching, cycles, or dependencies beyond linear step lists.
- Faithfulness of constructed reasoning not assessed: add evidence-level faithfulness metrics (e.g., evidence attribution F1, step-level support checks) to ensure each reasoning step is grounded in the selected contexts.
- Hallucination and error robustness not quantified: run stress tests with noisy, misleading, or conflicting retrieved content; measure robustness, hallucination rates, and the system’s ability to abstain under uncertainty.
- Handling Knowledge-Reconciled Reasoning remains ad hoc: LiR3AG primarily filters irrelevant evidence rather than safely incorporating internal knowledge when retrieval is insufficient; design controlled, verifiable mechanisms to reconcile model knowledge with external evidence.
- Adaptive decision policy is missing: develop a gating mechanism to decide when to use context-grounded vs. knowledge-reconciled reasoning, when to increase top-k, or when to abstain due to insufficient evidence.
- Scalability to large corpora and long contexts: evaluate performance and latency with much larger indices, longer documents, and higher hop counts; report memory footprint and throughput under realistic enterprise workloads.
- Efficiency accounting lacks granularity: clarify whether token/time costs include the reranker and constructor LLM calls; report hardware specs, batching/parallelism settings, and breakdown by module to enable fair comparisons.
- Statistical rigor of reported gains: include confidence intervals, significance testing, multiple seeds, and variance analysis to substantiate claims (e.g., “98% output token reduction” and surpassing 32B reasoning models).
- Dataset coverage is narrow: extend evaluation beyond Wikipedia-style multi-hop QA to domain-specific corpora (medical, legal, financial), conversational settings, and multilingual/cross-lingual scenarios.
- Error analysis is absent: provide qualitative categorization of LiR3AG failure modes (e.g., entity linking, coreference, comparison errors, temporal reasoning) to guide targeted improvements.
- Choice of LLMs for Reranker/Constructor is limited: assess open-source small models (e.g., 3–7B class) and non-LLM rerankers for cost-effective deployments; quantify trade-offs between capability and latency/cost.
- End-to-end training opportunity: explore supervised or RL-based training for the reranker and constructor to learn task-specific evidence selection and reasoning chains rather than relying purely on prompting.
- Iterative retrieval and reasoning not explored: evaluate multi-step retrieval loops where intermediate reasoning steps trigger targeted follow-up retrieval to refine evidence chains.
- Optimal top-k selection is static: design adaptive top-k selection based on uncertainty/calibration to balance accuracy with token/time cost; analyze sensitivity beyond k={1,5,10}.
- Prompt sensitivity not analyzed: perform prompt ablations for the reranker and reasoning constructor to quantify robustness to template changes and instruction styles.
- Evidence ordering correctness unmeasured: introduce metrics that quantify whether the constructed reasoning order matches the actual causal/logic sequence needed for the answer.
- Safety and privacy considerations: assess risks of using proprietary LLMs in the pipeline (e.g., data leakage), propose privacy-preserving variants, and evaluate secure deployment strategies.
- Integration with knowledge graphs is only referenced: empirically test combining LiR3AG with KG-based retrieval and reasoning (entity linking, path finding) to enhance multi-hop evidence chaining.
- Calibration and confidence reporting: add mechanisms to produce confidence scores and abstentions, and evaluate calibration (ECE/Brier) for deployment in high-stakes settings.
- Comparisons across question types: stratify results by reasoning type (bridging, comparison, compositional, temporal) to identify where LiR3AG helps most and where it struggles.
- Reproducibility artifacts missing: release code, prompts, retrieval configs, and annotated data to enable independent verification and extension of the framework.
Practical Applications
Immediate Applications
Below is a set of actionable, sector-linked use cases that can be deployed now, leveraging the LiR³AG framework’s retriever–reranker–reasoning-constructor pipeline to achieve multi-hop, evidence-grounded responses with markedly lower token and latency costs.
- Industry — Enterprise Knowledge Bases (Software/IT)
- Use case: Multi-hop QA across product docs, release notes, tickets, and design specs (e.g., “Which API deprecations affect feature X introduced in v3.2, and what’s the migration path?”).
- Workflow/tools: Integrate hybrid retrieval (BM25 + dense), add LiR³AG reranking to filter and order evidence, feed structured reasoning steps to a non-reasoning generator; expose concise “evidence-first” answers with citations.
- Dependencies/assumptions: High-quality document chunking and indexing, tuned Top-k; a capable non-reasoning LLM; regular doc updates; guardrails for outdated content.
- Industry — Customer Support and Self-Service Portals
- Use case: Stepwise troubleshooting and policy answers that require chaining multiple sources (manuals, FAQs, internal change logs).
- Workflow/tools: Plug LiR³AG modules into existing chatbot stacks (e.g., LangChain/LlamaIndex), present compact reasoning chains with linked steps; optimize latency to meet SLAs.
- Dependencies/assumptions: Complete and current manuals; precise retrieval over heterogeneous sources; A/B testing to calibrate Top-k/citation strategy.
- Healthcare (Information Services, Non-Diagnostic)
- Use case: Evidence-grounded answers to guideline and policy questions (e.g., “Which contraindications in the latest guideline apply to medication Y given condition Z?”).
- Workflow/tools: Curated corpus ingestion; pretrained reranker; reasoning constructor templates that include per-step source attribution.
- Dependencies/assumptions: Authoritative, vetted content; human-in-the-loop validation; HIPAA/privacy constraints; clear disclaimers.
- Finance (Research and Compliance)
- Use case: Tie earnings call remarks to SEC filings and analyst notes; multi-hop Q&A for risk and compliance checks (e.g., “Does the updated 10-K reflect the CFO’s stated capital plan?”).
- Workflow/tools: Real-time document feeds; LiR³AG reranking for conflict detection; compact reasoning traces for audit trails.
- Dependencies/assumptions: Up-to-date filings and transcripts; compliance review workflow; provenance logging.
- Legal (eDiscovery and Knowledge Retrieval)
- Use case: Link case law, statutes, and prior filings to answer multi-faceted queries with an evidentiary chain.
- Workflow/tools: Domain-tuned retrieval/reranking; structured reasoning steps with citations and reasoning order; exportable audit trail.
- Dependencies/assumptions: Jurisdiction-specific coverage; confidentiality and access controls; practitioner oversight.
- Education (Course Support and Study Assistants)
- Use case: Multi-step explanations grounded in textbooks, lecture notes, and problem sets (e.g., “Derive theorem X using sections A and B, then apply it to exercise Y”).
- Workflow/tools: Educator-curated corpora; templated reasoning steps with references; adjustable verbosity to reduce token usage.
- Dependencies/assumptions: High-quality materials; alignment to curriculum; controls to avoid over-reliance without critical thinking.
- Scientific R&D (Literature Review and Methods Synthesis)
- Use case: Connect findings across papers to explain a methodology or reconcile contradictory results.
- Workflow/tools: Dense retrieval on full-text PDFs; reranking for multi-hop plausibility; structured reasoning chains with DOIs.
- Dependencies/assumptions: Full-text access; domain-specific embeddings; handling of paywalled content.
- Cybersecurity (Threat Intelligence Triage)
- Use case: Link CVEs, advisories, and internal asset inventories to produce evidence-based mitigation steps.
- Workflow/tools: Streamed intel ingestion; reranker to filter noise; concise reasoning traces for SOC workflows.
- Dependencies/assumptions: Timely feeds; accurate asset mapping; risk prioritization rules.
- Government and Public Policy (Citizen Portals and Staff Tools)
- Use case: Evidence-backed answers that chain statutes, directives, and notices (e.g., “Which local ordinance applies and what is the filing procedure?”).
- Workflow/tools: Authority-ranked retrieval; transparent reasoning steps; exportable logs for accountability.
- Dependencies/assumptions: Authoritative sources maintained; oversight and appeal mechanisms; plain-language rendering.
- Energy and Cloud Operations (Cost/Carbon Reduction)
- Use case: Substitute high-cost reasoning LLMs with LiR³AG to meet accuracy while lowering tokens and latency, reducing spend and energy use.
- Workflow/tools: Drop-in replacement for existing RAG stacks; monitoring dashboards to track token/time savings.
- Dependencies/assumptions: Compatibility with current pipelines; tuning Top-k for optimal savings; governance for performance regressions.
- Daily Life (Personal Document Assistants)
- Use case: On-device QA across personal notes, PDFs, and emails with evidence-grounded, concise answers.
- Workflow/tools: Local embeddings; lightweight reranker; compact reasoning chain prompting for non-reasoning LLMs.
- Dependencies/assumptions: Device resource limits; privacy requirements; periodic index updates.
Long-Term Applications
These opportunities require further research, scaling, or productization beyond the current scope, including robustness, multimodal extensions, and standardization.
- Cross-Modal RAG (Healthcare Imaging, Industrial IoT, Media)
- Application: Extend LiR³AG to link text with images/audio (e.g., radiology reports + images), structuring evidence across modalities.
- Dependencies/assumptions: Multimodal retrievers/rerankers; evaluation protocols; domain safety validations.
- Autonomous Agents and Tool-Use Planning
- Application: Use LiR³AG chains as planning substrates for agents (e.g., selecting tools/queries in multi-step workflows).
- Dependencies/assumptions: Integrated tool APIs; memory/state management; benchmarks for planning faithfulness.
- Knowledge-Conflict Arbitration Engines (Policy/Compliance)
- Application: Systematically reconcile internal model knowledge with external sources; flag inconsistencies and propose resolution paths.
- Dependencies/assumptions: Conflict detection metrics; source-of-truth governance; human review loops.
- Auditable AI and RegTech Products
- Application: Standardized, exportable reasoning chains and citations for audit, certification, and regulatory reporting.
- Dependencies/assumptions: Interoperable logging formats; chain verifiability; conformance to standards (e.g., ISO/IEC AI).
- Distillation and Training Data Generation
- Application: Distill LiR³AG-style reasoning chains into smaller LLMs; generate supervised datasets of ordered evidence chains.
- Dependencies/assumptions: High-quality labeled corpora; domain diversity; evaluation for generalization and robustness.
- Multilingual and Cross-Corpus RAG at Scale
- Application: Support multilingual retrieval and reasoning across heterogeneous, global datasets.
- Dependencies/assumptions: Language-specific embeddings; cross-lingual reranking; dataset coverage and normalization.
- Real-Time and Streaming RAG (Finance/Newsrooms)
- Application: Dynamic reranking and reasoning over streaming sources; live conflict resolution and updates.
- Dependencies/assumptions: Low-latency indexing; drift detection; near-real-time evaluation.
- Safety and Adversarial Retrieval Defense
- Application: “Rerank Guard” to suppress manipulative or poisoned context, reduce strategic hallucinations.
- Dependencies/assumptions: Adversarial retrieval benchmarks; anomaly detection; incident response protocols.
- DataOps/MLOps Integration
- Application: End-to-end pipelines with connectors to data lakes, observability for retrieval quality, autoscaling, and SLAs.
- Dependencies/assumptions: Enterprise platform integration; performance monitoring; governance and access control.
- Reasoning-Chain-as-a-Service (RCaaS)
- Application: APIs or managed services that provide ordered evidence chains and concise reasoning for downstream generators.
- Dependencies/assumptions: Standard interfaces; billing/cost controls; ecosystem-level interoperability.
Notes on Feasibility and Assumptions
- Retrieval quality is the primary determinant of success; irrelevant or stale contexts reduce gains and can reintroduce redundant reasoning.
- The reranker and reasoning constructor benefit from capable (but still non-reasoning) LLMs; model size and Top-k tuning trade off accuracy and cost.
- Provenance and citation handling should be explicit for trust and compliance; audit logs enhance adoption in regulated sectors.
- Privacy and data governance (e.g., healthcare, legal, personal assistants) require local processing or secure endpoints; avoid sending sensitive data to external services.
- Domain adaptation (embeddings, prompts, templates) is often necessary; general-purpose setups may underperform in specialized fields.
- Human-in-the-loop validation is advised for high-stakes decisions; LiR³AG reduces hallucinations but does not eliminate the need for oversight.
Glossary
- Ablation Study: A controlled analysis that removes or disables components to assess their individual contributions to overall performance. "Ablation Study (RQ3)"
- BM25: A probabilistic ranking function used in sparse retrieval to score document relevance based on term frequency and inverse document frequency. "algorithms such as BM25 to perform lexical matching"
- Chain-of-Thought (CoT): A reasoning technique where models explicitly generate intermediate steps to solve complex problems. "often termed Chain-of-Thought (CoT) reasoning"
- Context-Grounded Reasoning: A strategy that derives answers directly and primarily from retrieved external evidence without relying on internal knowledge. "Context-Grounded Reasoning, which relies directly on retrieved content"
- Corpus: A large collection of documents or text used as the source from which information is retrieved. "from corpus:"
- Cosine Similarity: A measure of similarity between two vectors based on the cosine of the angle between them, commonly used in semantic matching. "(e.g., cosine similarity)"
- Dense Retrieval: A retrieval approach that encodes text into embeddings and matches queries to passages via semantic similarity. "dense retrieval encodes text into vector representations"
- Exact Match (EM): An evaluation metric that checks if the predicted answer exactly matches the ground-truth answer. "Exact Match (EM) and F1 Score."
- F1 Score: An evaluation metric that combines precision and recall to assess token-level overlap between predicted and true answers. "8B non-reasoning model's F1 performance"
- Hallucinations: Fabricated or unsupported outputs generated by a model that do not align with factual or retrieved evidence. "By mitigating hallucinations"
- Hybrid Retrieval: A retrieval strategy that combines sparse and dense methods, often with post-retrieval reranking, to improve relevance. "Hybrid retrieval combines both sparse and dense retrieval methods"
- Inference Latency: The time delay incurred during model inference, including processing of inputs and generation of outputs. "including increased token consumption and inference latency."
- Inference-Time Scaling: Allocating more computational resources during inference to enable deeper or more deliberate reasoning. "introduced inference-time scaling to allocate more computational resources"
- Knowledge Graph: A structured representation of entities and relationships used to leverage global information for retrieval and reasoning. "In addition to introducing knowledge graphs"
- Knowledge-Reconciled Reasoning: A strategy that resolves conflicts or gaps between retrieved evidence and internal model knowledge via reasoning. "Knowledge-Reconciled Reasoning, which resolves conflicts or gaps using internal knowledge."
- LLM: A generative neural model trained on massive text corpora that produces natural language outputs. "LLMs"
- Multi-hop Question Answering (QA): A task requiring retrieval and reasoning across multiple pieces of evidence from different sources to answer a question. "multi-hop Question Answering (QA)"
- Parametric Knowledge: Information stored in a model’s parameters learned during pretraining, used alongside retrieved context. "parametric knowledge"
- ReAct: A framework that interleaves reasoning steps with actions (e.g., tool use) to gather information dynamically during inference. "ReAct is a notable reasoning approach"
- Reasoning Constructor: A module that assembles filtered contexts into structured, step-by-step reasoning chains for generation. "Reasoning Constructor assembles these contexts into structured reasoning steps"
- Reranker: A component that filters out irrelevant contexts and orders relevant ones according to a reasoning-consistent sequence. "Reranker examines their relevance to the question"
- Retriever: The component that selects top-ranked relevant passages from a corpus given a query. "Retriever Module"
- Retrieval-Augmented Generation (RAG): A framework that enhances LLMs by integrating retrieved external knowledge into the generation process. "Retrieval-Augmented Generation (RAG) has become a powerful paradigm"
- Semantic Matching: Matching based on meaning using embeddings and similarity functions rather than exact lexical overlap. "performs semantic matching based on similarity functions"
- State-of-the-Art (SOTA): The best reported performance level achieved by a method at the time of evaluation. "LiRAG achieves the SOTA performance"
- Top-k: The selection of the k highest-scoring items (e.g., contexts) according to a retrieval or ranking function. "top- relevant contexts"
- Vanilla RAG: A baseline RAG setup without specialized modules beyond standard retrieval and generation. "Vanilla RAG adopts the standard RAG framework"
- Vector Representations: Numerical embeddings of text used for dense retrieval and semantic similarity computations. "vector representations"
Collections
Sign up for free to add this paper to one or more collections.