- The paper introduces PAR2-RAG, a two-stage framework that decouples evidence coverage from reasoning commitment, achieving up to 42.4% accuracy gains over prior methods.
- It employs a Coverage Anchor stage for broad evidence gathering and an Iterative Chain stage with evidence sufficiency gating to iteratively refine answers.
- Empirical results across four MHQA benchmarks demonstrate robust improvements in accuracy and retrieval metrics, validating the framework’s modular and adaptive design.
Planned Active Retrieval and Reasoning RAG (PAR2-RAG) for Multi-Hop Question Answering
Introduction
PAR2-RAG presents a two-stage Retrieval-Augmented Generation (RAG) framework tailored for multi-hop question answering (MHQA), a scenario where models must gather and integrate evidence from multiple sources. Existing approaches, such as IRCoT and ReAct, often suffer from premature commitment driven by insufficient evidence retrieval in early steps, subsequently compounding reasoning errors during multi-hop reasoning. Methods favoring broad static query planning also face brittleness since evidence needs can shift as the system gathers information. PAR2-RAG addresses these bottlenecks with its coverage-before-commitment design, explicitly staging evidence breadth expansion and evidence-sufficiency-gated iterative refinement.
Methodology
The architecture of PAR2-RAG consists of two well-separated yet coordinated modules: the Coverage Anchor stage and the Iterative Chain stage (Figure 1).
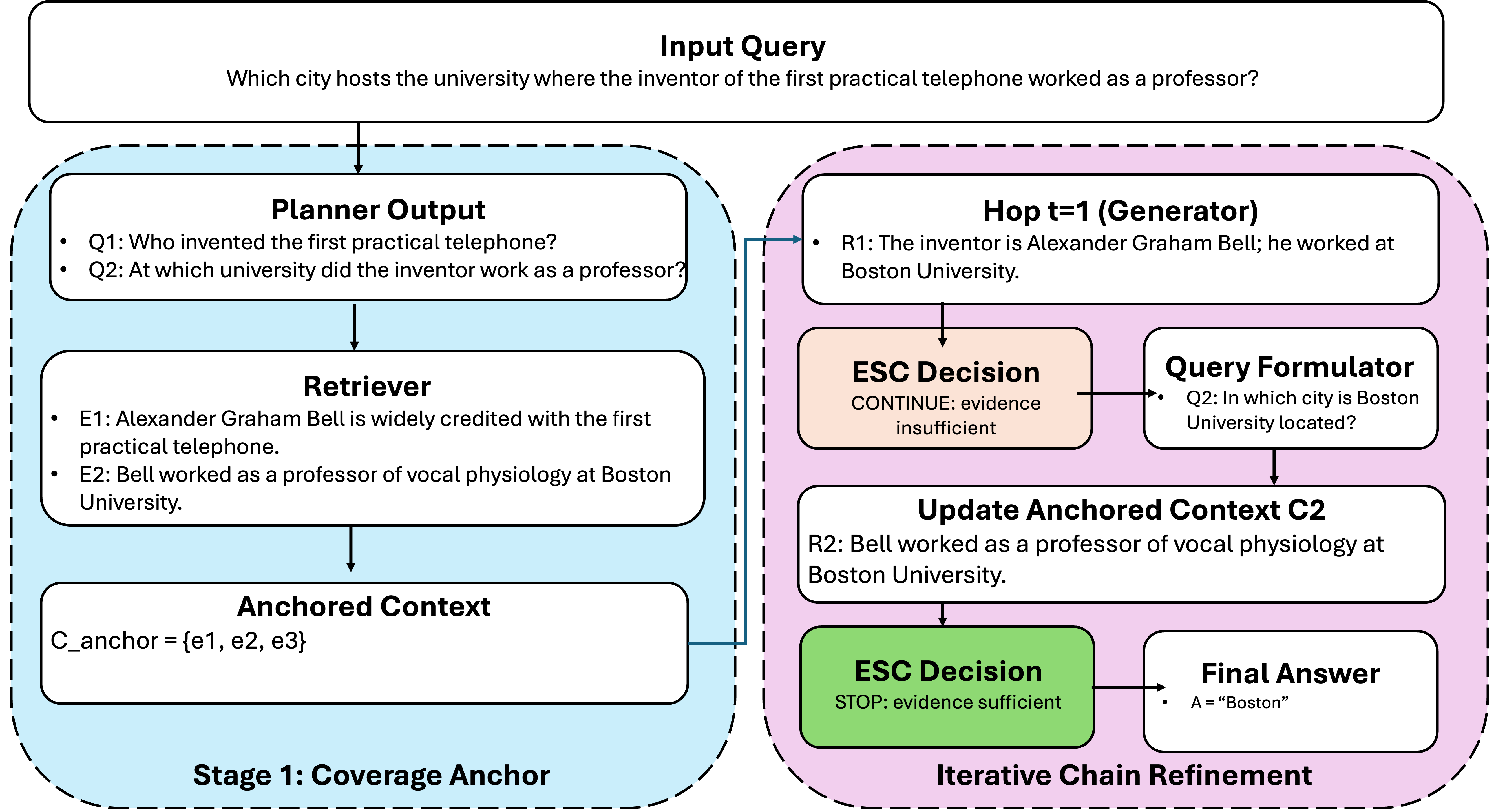
Figure 1: Stage 1 (Coverage Anchor) builds a broad evidence frontier, and Stage 2 (Iterative Chain) iteratively refines reasoning with explicit evidence sufficiency gating.
Coverage Anchor (Stage 1): This module employs a planning agent to decompose the main question into complementary sub-queries targeting diverse aspects of the problem. Each sub-query invokes a retriever-reranker to accumulate high-recall, deduplicated passages, forming an anchored evidence context. This approach maximizes the likelihood that downstream reasoning initiates from a rich evidence frontier, mitigating early retrieval failures endemic to strictly interleaved or shallow retrieval policies.
Iterative Chain (Stage 2): Conditioned on the anchored context, chain-of-thought reasoning proceeds in a step-wise, ESC-gated (Evidence Sufficiency Controller) manner. The ESC agent leverages an instruction-tuned LLM to assess, at each step, whether retrieved evidence adequately supports further reasoning or additional targeted retrieval is necessary. The system thus adaptively balances between continuing retrieval or finalizing the answer, depending on evidence sufficiency.
Agent Decomposition: Five modular agents orchestrate the workflow: (1) Planner (P), (2) Retriever (R), (3) Query Formulator (Q), (4) ESC (E), and (5) Writer (W). This design clarifies functional boundaries, enabling robust ablations and the systematic study of how evidence coverage and commitment control influence final answer quality.
Experimental Evaluation
Extensive evaluations on four established MHQA benchmarks—MuSiQue, 2WikiMultiHopQA, MoreHopQA, and FRAMES—demonstrate consistent superiority for PAR2-RAG across answer correctness, NDCG, recall, and all-pass metrics. Both non-reasoning (few-shot) and reasoning-intensive (chain-of-thought) settings are explored using state-of-the-art LLMs (GPT-4.1, GPT-o3, GPT-5.2).
Answer Quality: PAR20-RAG attains the highest accuracy on all four benchmarks, with up to 23.5% higher accuracy than IRCoT (notably a 42.4% gain on MuSiQue relative to ReAct). Average improvements span all generator settings.
Retrieval Quality: On NDCG, Recall, and the stricter All-Pass metric, PAR21-RAG robustly outperforms both IRCoT and ablated module variants, with up to 10.5% gains in NDCG, validating that coverage-first anchoring reliably improves evidence acquisition.
Step Robustness: Across step-count budgets (3, 5, 7, 10), the model delivers stable and strong answer quality, with performance gains saturating or declining at higher step counts, emphasizing the efficacy of adaptive sufficiency checks.
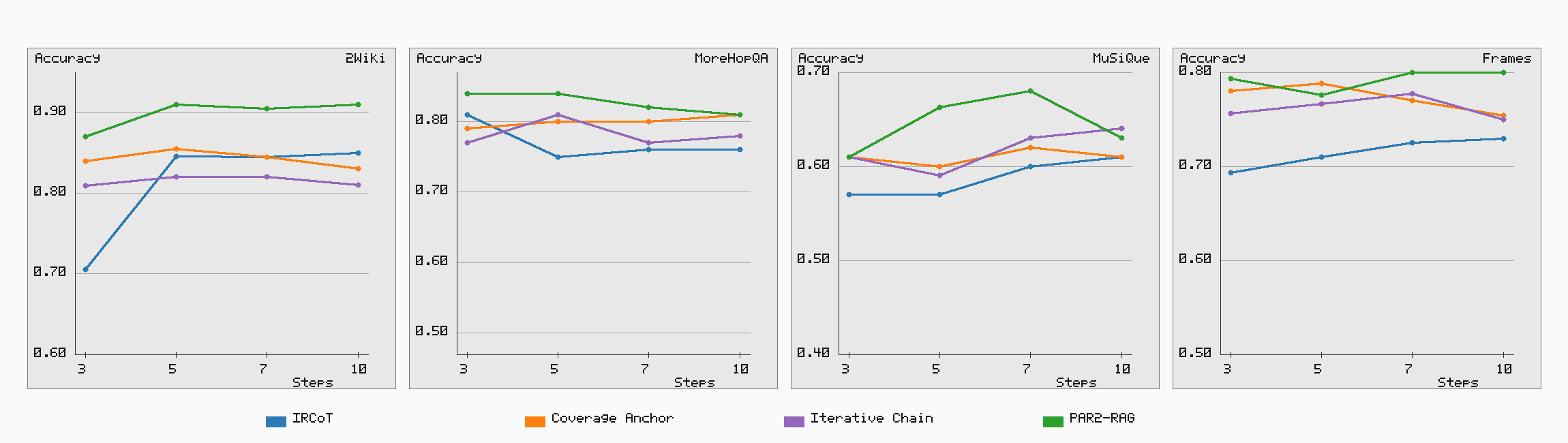
Figure 2: Answer quality as a function of step count, demonstrating that PAR22-RAG maintains the highest robustness and quality across various retrieval budgets.
Empirical Analysis
Ablation studies dissect the complementary value of the Coverage Anchor and Iterative Chain modules. The results indicate that:
- Coverage Anchor predominantly boosts global evidence recall and is most critical under generators with strong internal reasoning.
- Iterative Chain yields maximal benefit when generation is less capable, emphasizing local refinement.
- Their combination in PAR23-RAG systematically outperforms either in isolation, corroborating the thesis that coverage breadth must precede commitment.
The empirical gains persist across multiple model sizes and reasoning settings (e.g., OpenAI GPT-5.2), confirming the design’s transferability and robustness.
Theoretical and Practical Implications
PAR24-RAG advances the state of MHQA methodology in several dimensions:
- Modular agentic design enables explicit interventions, interpretable error tracing, and fine-tuning of the evidence acquisition versus reasoning trade-off.
- Coverage sufficiency gating invites the future study of meta-reasoning criteria for adaptive depth control or dynamic step-budget allocation.
- Industry implications are immediate: for high-stakes MHQA (e.g., compliance, legal search), the explicit decoupling of evidence coverage and path commitment can directly translate to improved factual robustness and traceability.
The theoretical underpinning—delaying commitment until sufficient evidence coverage is established—generalizes beyond QA, suggesting utility for other retrieval-augmented, multi-stage reasoning tasks such as scientific hypothesis generation or agent-based planning.
Conclusion
PAR25-RAG establishes a new paradigm for retrieval-augmented multi-hop question answering by separating coverage breadth from reasoning commitment and imposing explicit sufficiency checks during iterative chain construction. Across a range of challenging MHQA tasks, this design delivers strong accuracy and retrieval robustness, substantially outperforming prior training-free RAG baselines. The framework’s modularity, empirical resilience, and clear alignment with theory suggest it will be foundational for future advances in robust, evidence-grounded LLM-based agents.