PruneRAG: Confidence-Guided Query Decomposition Trees for Efficient Retrieval-Augmented Generation
Abstract: Retrieval-augmented generation (RAG) has become a powerful framework for enhancing LLMs in knowledge-intensive and reasoning tasks. However, as reasoning chains deepen or search trees expand, RAG systems often face two persistent failures: evidence forgetting, where retrieved knowledge is not effectively used, and inefficiency, caused by uncontrolled query expansions and redundant retrieval. These issues reveal a critical gap between retrieval and evidence utilization in current RAG architectures. We propose PruneRAG, a confidence-guided query decomposition framework that builds a structured query decomposition tree to perform stable and efficient reasoning. PruneRAG introduces three key mechanisms: adaptive node expansion that regulates tree width and depth, confidence-guided decisions that accept reliable answers and prune uncertain branches, and fine-grained retrieval that extracts entity-level anchors to improve retrieval precision. Together, these components preserve salient evidence throughout multi-hop reasoning while significantly reducing retrieval overhead. To better analyze evidence misuse, we define the Evidence Forgetting Rate as a metric to quantify cases where golden evidence is retrieved but not correctly used. Extensive experiments across various multi-hop QA benchmarks show that PruneRAG achieves superior accuracy and efficiency over state-of-the-art baselines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
PruneRAG: A Simple, Teen-Friendly Explanation
What is this paper about?
This paper is about making AI better at answering tough questions that need information from many places. The authors built a new system called PruneRAG that helps an AI find the right facts, keep track of them, and use them correctly to get the final answer—faster and more accurately.
What problems are the authors trying to solve?
The authors noticed two big problems in many AI systems that look things up while they think (this is called “Retrieval-Augmented Generation,” or RAG):
- The AI often “forgets” important evidence it already found. It may retrieve the right documents but still give the wrong answer.
- The process can be slow and wasteful, because the AI keeps asking more and more questions or pulls in too many documents it doesn’t need.
They turned these ideas into simple research questions:
- Do AIs really forget evidence during multi-step reasoning?
- Can we design a method that reduces this forgetting and improves accuracy?
- Can we make the process faster and cheaper at the same time?
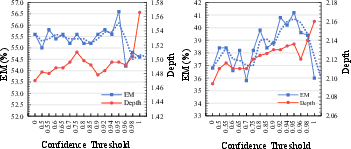
- How sensitive is this method to settings like “how deep to think” or “how confident an answer must be”?
How does the method work?
Imagine solving a big mystery. Instead of guessing all at once, you:
- break the mystery into smaller clues,
- check how sure you are about each clue,
- drop the weak paths,
- and then combine the strong clues at the end.
That’s what PruneRAG does, using a “question tree.” The AI starts with the main question at the top and then moves downward by creating sub-questions or targeted lookups. When it reaches the bottom, it moves back up, combining what it learned into a final answer.
Here are the key parts, explained simply:
- Adaptive node expansion: At each step, the AI decides one of three things:
- Answer now (if it’s confident).
- Split the question into two simpler sub-questions (like dividing a big math problem into two smaller ones).
- If it can’t split, extract key “entities” (important names, places, or terms) and use those to search more precisely.
- Confidence-guided pruning: The AI checks how sure it is about its answer (using how confident it is in each word it generates). If the confidence is high, it accepts the answer and stops expanding that branch. If confidence is low, it rejects the answer and either splits the question or switches to entity-based search. This prevents errors from “spreading downward.”
- Fine-grained retrieval with entities: When a question can’t be split further, the AI grabs the most important keywords (like “Danny Welch” and “employer”) and searches with those. This reduces noise and pulls in more relevant information.
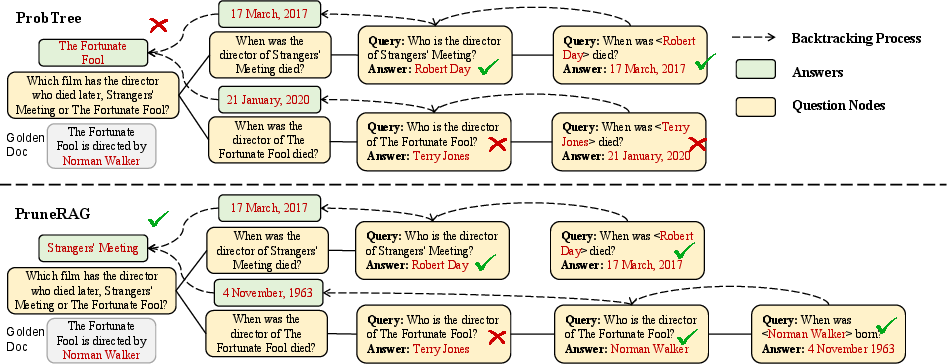
- Bottom-up backtracing: After building the tree, the AI goes back up, combining answers and evidence from the leaves to the root, so important facts don’t get buried or forgotten.
- A new metric: Evidence Forgetting Rate (EFR). This measures how often the AI retrieved the right sources but still got the answer wrong. It’s a direct way to see whether the AI is actually using the evidence it found.
What did they find, and why is it important?
Across multiple tough, multi-step question-answering datasets (like HotpotQA, 2WikiQA, and MusiQue), PruneRAG:
- Gave more correct answers than other advanced systems. On average, the F1 score (a common accuracy measure) improved by about 5.45% over the strongest baseline.
- Was much faster—about 4.9× speedup compared to popular multi-retrieval methods.
- Forgot less. The new EFR metric went down by about 20.8% on average compared to other methods, meaning PruneRAG was much better at using the evidence it already had.
These results held across different LLMs, which suggests the idea is robust, not just a one-off trick.
Why does this matter?
- More trustworthy answers: When an AI actually uses the facts it found, you can rely on it more—especially for multi-step questions like “Compare the founders of two companies and say which one is older.”
- Faster and cheaper: By pruning weak paths and retrieving fewer but better documents, the system answers quicker and wastes less computing power.
- Better tools in the real world: This approach could improve research assistants, study helpers, customer support bots, and enterprise search tools that need to solve complex, multi-hop questions.
Key terms in plain language
- Retrieval-Augmented Generation (RAG): An AI that both thinks and looks things up in a library of documents while it’s thinking.
- Multi-hop reasoning: Answering a question that needs multiple steps (like first finding a person’s hometown, then comparing it to another city).
- Evidence forgetting: The AI found the right info earlier but didn’t use it properly later.
- Query decomposition tree: A branching plan that breaks a big question into smaller ones and later combines the answers.
- Confidence score: A measure of how sure the AI is about its answer; used to accept good answers and prune bad paths.
- Entity: A key word or phrase (name, place, event) that helps target the search.
In short: PruneRAG is like a careful detective. It splits tough questions into manageable parts, only trusts answers it’s confident about, searches smartly with key terms when needed, and then pieces everything together. That’s why it’s both more accurate and faster than many existing systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that the paper leaves open. Each point aims to be concrete so that future work can directly address it.
- Confidence calibration: The method relies on token-level log-probabilities from LLMs to estimate “Confidence(A)”, but the paper does not assess calibration quality, model-specific biases, or robustness to answer length/tokenization; how to calibrate or normalize confidence across models, tasks, and languages remains open.
- Threshold selection and adaptation: Confidence threshold τ_A is fixed (e.g., 0.95) and tuned empirically; there is no adaptive or learned strategy to set τ_A per node, query type, model, or dataset, nor analysis of dynamic thresholds under domain shift.
- Availability and cost of log-probs: Many production LLM APIs do not expose reliable token log-probs or charge extra/slow down for them; the paper does not evaluate how log-prob availability, latency, and cost affect practicality or propose fallback confidence proxies.
- “Ans(q)” and “Spl(q)” decision reliability: The predicates for answerability and decomposability are delegated to LLM judgments without measuring their accuracy, failure modes, prompts, or training; no policy learning or supervision is explored to improve these decisions.
- Aggregation/backtracing design: The bottom-up “aggregate results of children” is underspecified (e.g., conflict resolution, weighting by confidence, combining partial answers/evidence); a principled, auditable aggregation algorithm and its evaluation are missing.
- Fine-grained entity extraction details: The entity-node mechanism does not specify how entities are extracted (LLM prompting vs. NER/linking), how ambiguity/aliasing is resolved, or how entities are composed into retrieval queries; quality, errors, and disambiguation are not analyzed.
- Entity-only terminal nodes: Entity nodes are terminal “by design,” which limits deeper reasoning over relations; it is unclear whether relation/triple extraction or iterative entity refinement could improve evidence acquisition and reasoning.
- Branching factor and dynamic width: Tree width is fixed at 2; the paper does not explore dynamic branching based on query complexity, evidence density, or confidence signals, nor analyze the trade-offs of wider branching.
- Depth constraint and scalability: Maximum depth is capped at 3; complexity, memory, and latency scaling with deeper trees are not analyzed, nor are techniques for safe deeper reasoning under longer contexts.
- Parallelization claims vs. measurement: The framework is presented as enabling parallel reasoning, but the experiments do not quantify parallel speed-ups, scheduling overhead, memory footprint, or contention under concurrent expansion.
- Efficiency accounting: Time cost comparisons do not break down components (retrieval, LLM inference, log-prob computation, aggregation), leaving open whether speed gains come from fewer tokens, fewer calls, or implementation choices (vLLM, batching).
- Fairness of baseline comparisons: Baselines differ in backbone models (e.g., Self-RAG on Llama-2 vs. Qwen/Llama-3.1), API behaviors, and retrieval dynamics; the paper does not normalize or control for these differences (e.g., max tokens, log-prob availability), raising questions about fairness.
- EFR metric completeness: EFR requires “golden documents” coverage, but gold sets can be incomplete, non-unique, or insufficient; the metric ignores partial evidence usage, evidence conflicts, and cases where correct answers need subsets of gold docs or non-gold evidence.
- EFR applicability gaps: EFR is reported as “not applicable” for single-retrieval baselines due to zero denominators; the paper does not propose alternative forgetfulness measures that are comparable across paradigms.
- Evidence usage auditing: Beyond EFR, there is no explicit evaluation of which retrieved passages were actually referenced/used (e.g., via citation grounding, attention-based attribution, or trace alignment).
- Retrieval hyperparameters and retriever choice: Top-k=5 and BGE-large-en-v1.5 on Wikipedia 2018 are fixed; sensitivity to k, retriever architecture, negative sampling, passage segmentation, and corpus freshness/domain shift is not studied.
- Generalization beyond Wikipedia QA: Experiments focus on English, Wikipedia-based multi-hop QA; the paper does not evaluate domain-specific corpora, multilingual settings, noisy/heterogeneous data, or tasks beyond QA (e.g., fact-checking, long-form generation, coding).
- Robustness to adversarial or conflicting evidence: How PruneRAG behaves under noisy, contradictory, or adversarial documents is not evaluated; mechanisms to detect and suppress spurious but high-confidence answers are missing.
- Decoding effects and variance: All runs use greedy decoding at temperature 0; the impact of typical sampling settings (temperature, top-p), multi-sample consistency checks, and statistical significance testing are not provided.
- Error analysis: There is no qualitative analysis of typical failure cases (e.g., wrong splits, premature acceptance, entity ambiguity, aggregation errors), making it hard to target improvements.
- Learnable policies: The expansion/pruning decisions are rule-based; learning a policy (e.g., via reinforcement learning or supervised signals from EFR) to optimize expansion, pruning, and aggregation is unexplored.
- Confidence misuse: High-confidence wrong answers due to LLM miscalibration are not addressed (e.g., temperature scaling, ECE minimization, conformal prediction), nor is there a secondary verification mechanism before accepting answers.
- Citation and grounding: The final answers are not accompanied by structured citations to supporting passages; how to systematically attach and verify evidence at each node remains open.
- Comprehensive dataset coverage: Although multiple datasets are mentioned (e.g., Bamboogle, GPQA, NQ, TriviaQA), main results table reports only three multi-hop datasets; full results and comparative analyses on the others are missing.
Practical Applications
Practical Applications of PruneRAG
Below are actionable applications that leverage the paper’s findings, methods, and innovations. They are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring further research, validation, or scaling). Each item maps to relevant sectors and notes potential tools, products, or workflows, along with assumptions and dependencies that affect feasibility.
Immediate Applications
- Enterprise knowledge copilots and search (software, enterprise IT)
- What to deploy: A “PruneRAG Orchestrator” layer integrated into existing RAG stacks (e.g., LangChain/LlamaIndex) that adds confidence-guided pruning, adaptive decomposition, and entity-level retrieval to internal Q&A over wikis, policy manuals, SOPs, and tickets.
- Workflow: For multi-hop questions, the orchestrator builds a query tree; accepts high-confidence answers early; prunes low-confidence branches; and falls back to entity anchors when decomposition stalls. Monitor Evidence Forgetting Rate (EFR) in a dashboard to catch “retrieved-but-unused” failures.
- Assumptions/dependencies: Access to token-level probabilities from the LLM; quality embeddings/indexing (e.g., FAISS + BGE-large); clean and up-to-date enterprise corpora; appropriate confidence thresholds (e.g., τA ≈ 0.9–0.95); governance for data privacy.
- Customer support chatbots and helpdesk QA (software, customer service)
- What to deploy: Confidence-aware RAG bots that reduce latency and cost while maintaining accuracy on multi-turn troubleshooting across KB articles, historical tickets, and product docs.
- Workflow: If answer confidence is high, reply immediately; otherwise decompose into sub-queries or use entity-level anchors (e.g., product model, error code) for precise retrieval; prune uncertain branches to avoid bloating context.
- Assumptions/dependencies: LLM API supports logprobs; retriever tuned to domain taxonomies; escalation routing for low-confidence outcomes.
- Legal contract Q&A and clause comparison (legal, compliance)
- What to deploy: Contract analysis assistants that use query trees to link obligations across clauses and annexes, prune speculative reasoning, and surface precise evidence passages.
- Workflow: Multi-hop queries (e.g., “How does Clause 9 interact with Annex B termination?”) are decomposed; entity anchors (party names, dates, clause IDs) drive fine-grained retrieval; EFR monitoring ensures retrieved clauses were used.
- Assumptions/dependencies: High-quality, structured document sets with stable identifiers; human-in-the-loop review for low-confidence answers; confidentiality controls.
- Clinical guideline and protocol lookup (healthcare, clinical operations)
- What to deploy: A confidence-gated guideline navigator for clinicians’ on-the-spot questions (e.g., cross-referencing dosing guidelines with contraindications).
- Workflow: Accept answers only when confidence exceeds threshold; otherwise decompose or use entity anchors (drug, condition, patient age) to retrieve precise sections; route low-confidence outputs to humans.
- Assumptions/dependencies: Trusted, versioned medical sources; regulatory guardrails; logging for medico-legal audit; strict PII controls if integrated with patient data.
- Scholarly literature assistants (academia, education)
- What to deploy: Multi-hop literature review tools that aggregate findings across papers and use EFR to diagnose when relevant papers were retrieved but not used in synthesis.
- Workflow: Decompose complex research questions; use entity anchors (author names, methods, datasets) to get precise evidence; confidence-prune weak reasoning paths; summary generation via bottom-up backtracing.
- Assumptions/dependencies: Access to scholarly corpora and metadata; robust deduplication; citation management integration.
- Software engineering knowledge search (software, developer productivity)
- What to deploy: Dev support bots that connect code docs, issues, and commit history using confidence-guided decomposition; entity anchors (file names, class names, issue IDs) improve retrieval specificity.
- Workflow: Answer high-confidence queries quickly; for ambiguous queries, split into sub-queries (e.g., “interface change” and “affected modules”) and prune low-confidence branches.
- Assumptions/dependencies: Indexing of repos, tickets, CI logs; secure access to source; embeddings capable of handling technical nomenclature.
- Financial research copilot (finance, research/analysis)
- What to deploy: Confidence-aware assistance for cross-document queries over 10-Ks, earnings calls, and news; entity anchors (ticker, executive names, metric names) reduce noise.
- Workflow: Gate answers by confidence; decompose complex comparative queries; track EFR to flag “facts retrieved but not used”; escalate low-confidence outputs to analysts.
- Assumptions/dependencies: Timely ingestion; robust deduplication and normalization across sources; compliance with data licensing.
- Public policy and legislative analysis (government, policy)
- What to deploy: Cross-reference assistants for bills, regulations, and prior rulings that prune speculative paths and highlight precise evidence passages; EFR dashboards for auditability.
- Workflow: Decompose policy questions; use entity anchors (bill numbers, agency names, dates) to pull authoritative sources; backtrace to show evidence chains.
- Assumptions/dependencies: Access to authoritative, versioned legislative repositories; bias and provenance tracking; stakeholder review for low-confidence cases.
- Cost/latency reduction in existing RAG services (software, MLOps)
- What to deploy: Drop-in “Confidence Pruner + Entity Anchor Retriever” middleware that reduces redundant retrieval and context assembly.
- Workflow: Apply adaptive node expansion and confidence gating; set depth limits (2–3); report time savings and EFR in observability stacks (e.g., Prometheus/Grafana).
- Assumptions/dependencies: Instrumentation for timing and retrieval counts; retriever and LLM cost models; proper threshold tuning.
- EFR as a QA and observability metric (software, MLOps, evaluation)
- What to deploy: An “EFR Monitor” that complements accuracy metrics, signaling when golden evidence was retrieved but not used—useful for regression tests and deployment gates.
- Workflow: Compute EFR pre-release and in production; alert on spikes; use EFR to prioritize prompt/agent workflow fixes or retriever tuning.
- Assumptions/dependencies: Availability of golden evidence labels or proxy signals; data pipelines to log retrieval sets and outputs.
Long-Term Applications
- Clinical decision support integrated with EHRs (healthcare)
- What to build: End-to-end systems that combine patient context with multi-hop medical knowledge using confidence gating and entity anchors (conditions, meds, labs).
- Why research is needed: Rigorous clinical validation, safety cases, bias and fairness audits, regulatory approvals (e.g., FDA), and robust human-in-the-loop protocols.
- Assumptions/dependencies: Secure EHR integration; domain-specific retrievers; continual guideline updates; traceable evidence chains.
- Large-scale legal e-discovery and investigation (legal, enterprise)
- What to build: PruneRAG-based systems that scale multi-hop queries across millions of documents, ensuring reliable evidence transmission and cost control.
- Why research is needed: Scalability under high corpus churn, robust entity normalization, chain-of-custody tracking, and defensible audit trails.
- Assumptions/dependencies: Distributed indexing; advanced deduplication; privilege and privacy controls.
- Autonomous research agents for scientific discovery (academia, R&D)
- What to build: Agents that iteratively decompose research questions, retrieve cross-disciplinary evidence, and self-prune low-confidence lines of inquiry.
- Why research is needed: Reliability under open-web noise, EFR-based training signals, multi-agent coordination, and reproducibility standards.
- Assumptions/dependencies: Curated corpora; evaluation benchmarks with golden evidence; long-horizon planning across query trees.
- Regulatory technology (RegTech) monitoring and compliance tracking (finance, policy)
- What to build: Systems that continuously ingest new rules, decompose compliance queries, and highlight evidence paths with confidence thresholds to reduce false positives.
- Why research is needed: High-volume updates, multilingual sources, jurisdictional variations, and explainability requirements.
- Assumptions/dependencies: Source authenticity; multilingual retrieval; auditability of decisions.
- Systematic review and meta-analysis automation (academia, healthcare policy)
- What to build: Pipelines that support query decomposition, evidence aggregation, and EFR-based safeguards for meta-analyses.
- Why research is needed: Formal methodologies, bias control, deduplication at scale, and alignment with clinical review standards (e.g., PRISMA).
- Assumptions/dependencies: Gold-standard labeling for EFR; domain-specific retrieval models; expert oversight.
- Safety-critical AI knowledge retrieval for operations/maintenance (energy, manufacturing, robotics)
- What to build: Confidence-aware assistants that retrieve procedures and hazard advisories for technicians; prune low-confidence steps and escalate to experts.
- Why research is needed: Integration with IoT/CMMS, multimodal retrieval (text, diagrams), and safety certification.
- Assumptions/dependencies: High-quality technical manuals; device-level context; multimodal retrievers.
- Managed “Confidence-Aware RAG Engine” and “EFR Dashboard” (software, cloud platforms)
- What to build: A commercial service providing plug-and-play orchestration, adaptive tree reasoning, entity anchoring, and EFR observability across domains.
- Why research is needed: Cross-model support for logprobs, robust autoscaling, SLA-backed latency, and data governance.
- Assumptions/dependencies: Vendor-agnostic LLM APIs; privacy and residency configurations; cost-based optimization.
- Training-time alignment using EFR-driven objectives (ML research)
- What to build: Fine-tuning approaches that penalize high EFR (retrieved-but-unused) and optimize confidence thresholds and tree policies via reinforcement learning.
- Why research is needed: Labeled datasets with golden evidence, stable objectives, and generalization across tasks.
- Assumptions/dependencies: Open training corpora; stable retriever-LM interfaces; reproducible benchmarks.
- Multilingual and multimodal PruneRAG (global enterprise, education)
- What to build: Extensions for cross-lingual retrieval and multimodal evidence (text, tables, images, diagrams) within query trees.
- Why research is needed: Robust entity anchoring across languages/scripts, multimodal embeddings, and confidence calibration across modalities.
- Assumptions/dependencies: Multilingual corpora; multimodal LLMs with logprob support; cross-lingual entity resolution.
- Adaptive retrieval budgets and dynamic policy learning (software, ML ops)
- What to build: Systems that learn to adjust depth/branching thresholds (τA, tree depth) based on task difficulty and cost constraints.
- Why research is needed: Online learning under concept drift, budget-aware inference, and stable exploration-exploitation trade-offs.
- Assumptions/dependencies: Telemetry pipelines; feedback loops (human ratings, task success); robust policy evaluation.
Notes on dependencies applicable across many applications:
- LLMs must expose token-level probability/logprob APIs to enable confidence-guided pruning.
- Retriever quality and indexing matter (e.g., FAISS + strong embeddings like BGE-large); domain adaptation may be needed.
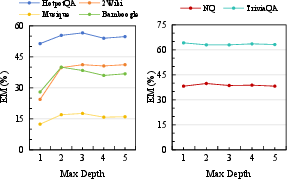
- Confidence thresholds and tree depth require tuning; the paper reports robust ranges (e.g., τA ≈ 0.9–0.95; depth ≈ 2–3) for multi-hop QA.
- Accurate EFR tracking requires golden evidence labels; where unavailable, proxies (human review, weak labels) may be needed.
- Privacy, security, and regulatory compliance must be addressed when working with sensitive or proprietary corpora.
Glossary
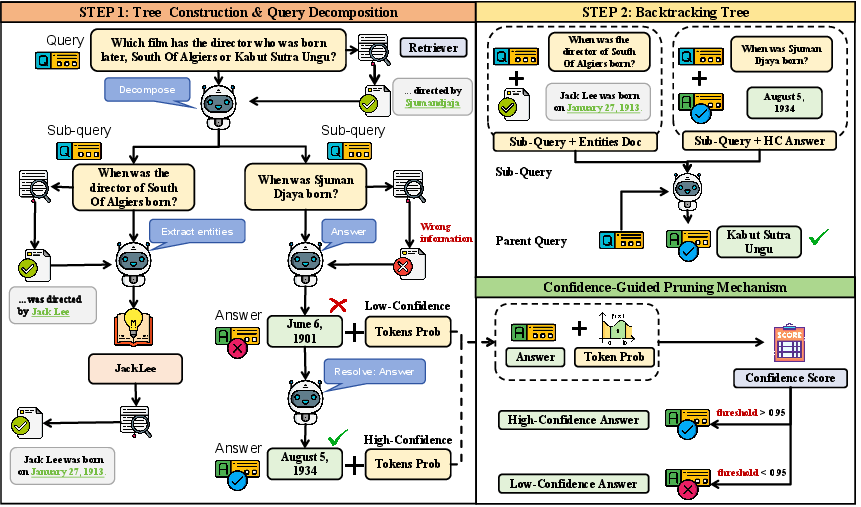
- Adaptive node expansion: A mechanism that dynamically controls how many child nodes are added to a reasoning tree based on current context. "adaptive node expansion that regulates tree width and depth"
- Autoregressive: A generation process where each token is produced conditioned on previously generated tokens. "LLMs typically produce an answer sequence in an autoregressive manner"
- Backtracing (bottom-up backtracing): The process of aggregating results from leaf nodes up to the root to form a final answer. "the system performs a systematic bottom-up backtracing process"
- Branching factor: The maximum number of children a node can have in the reasoning tree. "we set the tree maximum branching factor to 2"
- Chain-of-Thought (CoT): A prompting strategy that encourages models to generate intermediate reasoning steps to improve accuracy and interpretability. "Chain-of-Thought (CoT) \cite{wei2022chain} prompting enhances reasoning interpretability"
- Confidence-guided decision mechanism: A control module that accepts or rejects answers based on their predicted confidence. "we design a confidence-guided decision mechanism based on the model's prediction certainty."
- Confidence-guided pruning mechanism: A strategy that prunes low-confidence branches in the reasoning tree to reduce errors and cost. "owing to its confidence-guided pruning mechanism that effectively reduces redundant and wrong expansions"
- Confidence score: A numeric measure of certainty computed from token probabilities for a generated answer. "This mechanism computes a confidence score based on the token-level log probability of the generated answer sequence"
- Confidence threshold τ_A: A cutoff value for deciding whether a generated answer is confident enough to accept. "Impact of confidence threshold on answer accuracy"
- ConTReGen: A tree-structured retrieval method that expands a query along multiple semantic facets. "ConTReGen hierarchically expands semantic facets of a query"
- Conditional likelihood probability: The probability of a token given previous tokens and inputs during generation. " is the conditional likelihood probability of token "
- Dense Passage Retrieval (DPR): A neural retrieval approach that encodes queries and passages into dense vectors for similarity search. "Representative methods such as REALM \cite{guu2020retrieval}, RAG \cite{lewis2020retrieval}, and DPR \cite{karpukhin2020dense} incorporate document retrieval during inference"
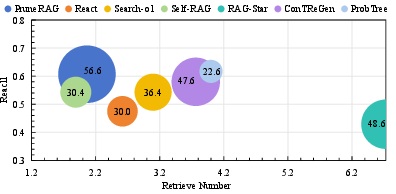
- Document Recall (Recall): A metric indicating whether the system successfully retrieved the ground-truth supporting documents. "Efficiency is evaluated through Document Recall (Recall)"
- Entity nodes: Leaf nodes that store key entities for targeted retrieval when further decomposition or direct answering is not possible. "Entity nodes handle fallback cases where a query is neither directly answerable nor further decomposable."
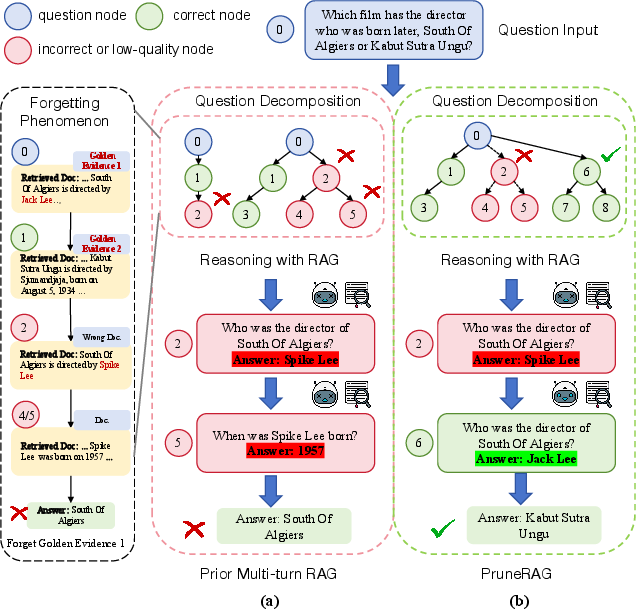
- Evidence forgetting: A failure mode where retrieved evidence is not used effectively in later reasoning steps. "evidence forgetting, where the model retrieves key evidence but fails to leverage it in later steps"
- Evidence Forgetting Rate (EFR): The proportion of cases where golden evidence was retrieved but the final answer is still incorrect. "we introduce the Evidence Forgetting Rate (EFR), which measures the proportion of cases where golden evidence has been retrieved but the answer is still incorrect."
- Exact Match (EM): A strict accuracy metric that checks if the predicted answer exactly matches the ground truth. "Effectiveness is measured by Exact Match (EM) and F1"
- FAISS: A library for efficient similarity search and vector indexing used to build retrieval indices. "employing FAISS \cite{johnson2019billion} for indexing"
- Fine-grained retrieval: A retrieval strategy that extracts entities or minimal semantic units to guide precise evidence lookup. "fine-grained retrieval that extracts entity-level anchors to improve retrieval precision"
- F1: A harmonic mean of precision and recall used as a softer accuracy metric than EM. "Exact Match (EM) and F1, which assess answer correctness at both strict and token-overlap levels."
- Greedy search: A decoding strategy that selects the most probable token at each step without sampling. "decoding is performed via greedy search with temperature 0."
- Golden evidence: The set of ground-truth documents necessary to answer a question. "where golden evidence is retrieved early"
- Hallucination problem: The tendency of models to produce confident but factually incorrect outputs. "To further mitigate the hallucination problem \cite{roy-etal-2024-contregen}"
- HotpotQA: A multi-hop question answering dataset used to evaluate reasoning systems. "Figure~\ref{fig1}(a) illustrates the forgetting phenomenon on HotpotQA"
- Indicator function: A function that takes value 1 when a condition holds and 0 otherwise, used in metric definitions. "The indicator function takes value 1 if"
- Inference latency: The time taken by the system to produce an answer. "Comparison of answer accuracy, inference latency, and evidence forgetting rate across RAG methods"
- LLMs: Neural models trained on large text corpora capable of performing a wide range of language tasks. "enhancing LLMs on knowledge-intensive and reasoning tasks"
- Llama-3.1-8B-Instruct: A specific instruction-tuned LLM used as a backbone in experiments. "we conduct experiments with two models: Qwen-3-8B \cite{yang2025qwen3technicalreport} and Llama-3.1-8B-Instruct \cite{grattafiori2024llama3herdmodels}"
- Monte Carlo Tree Search: A heuristic search algorithm that explores decision trees via random simulations to find high-value paths. "RAG-Star utilizes the Monte Carlo Tree Search algorithm to explore the optimal reasoning path."
- Multi-hop question answering (QA): Tasks requiring reasoning over multiple pieces of evidence across documents. "We conducted experiments on four representative multi-hop question answering (QA) datasets"
- Multi-turn retrieval: Iterative retrieval across multiple reasoning steps in a session to gather additional evidence. "In the multi-turn retrieval paradigm, iterative methods consistently exhibit high EFR across datasets"
- Parametric knowledge: Information stored within model parameters rather than retrieved externally. "to compensate for limited parametric knowledge"
- ProbTree: A tree-based RAG baseline method for comparison. "ProbTree\cite{DBLP:conf/emnlp/probtree_cao}"
- PruneRAG: The proposed confidence-guided query decomposition tree framework for efficient RAG. "We propose PruneRAG, a tree-structured RAG framework for stable and efficient parallel reasoning"
- Query decomposition tree: A tree structure that breaks a complex query into sub-queries for modular reasoning and retrieval. "builds a structured query decomposition tree"
- Query node: A node representing a sub-query, its retrieved documents, and (optionally) its answer. "Formally, a query node is defined as:"
- Qwen-3-8B: A specific LLM backbone used in experiments. "we conduct experiments with two models: Qwen-3-8B \cite{yang2025qwen3technicalreport}"
- RAG (Retrieval-augmented generation): A framework that integrates external retrieval with generation to improve factuality and reasoning. "Retrieval-augmented generation (RAG) has become a powerful framework for enhancing LLMs"
- RAG-Star: A tree-based RAG method that uses Monte Carlo Tree Search to navigate reasoning paths. "RAG-Star utilizes the Monte Carlo Tree Search algorithm to explore the optimal reasoning path."
- REALM: A retrieval-augmented model that integrates retrieval during inference. "Representative methods such as REALM \cite{guu2020retrieval}, RAG \cite{lewis2020retrieval}, and DPR \cite{karpukhin2020dense} incorporate document retrieval during inference"
- ReAct: A method that interleaves reasoning and retrieval actions in a loop. "ReAct \cite{yao2023react} alternates between reasoning and retrieval in a closed loop"
- Retrieval Number (RN): The number of times the retriever is invoked for a question. "Retrieval Number (RN), indicating how often the retriever is invoked"
- Search-o1: A RAG method that selects and integrates relevant content at a fine-grained level. "Search-o1 \cite{li2025search} selects and integrates relevant content at a fine-grained level."
- Self-RAG: A method where the model uses reflection tokens to assess retrieved content and adapt retrieval. "Self-RAG \cite{DBLP:conf/iclr/AsaiWWSH24} generates intermediate queries to retrieve supporting evidence"
- Semantic facets: Different meaningful aspects or angles of a query explored during tree expansion. "hierarchically exploring multiple semantic facets of queries"
- Token-level log probability: The logarithm of the probability assigned to each generated token, used to assess answer confidence. "based on the token-level log probability of the generated answer sequence"
- Top-k documents: The k highest-ranked documents returned by the retriever for a query. "Retrieve top- documents using given "
- Tree-based Retrieval-Augmented Generation: RAG methods that organize reasoning as a tree to explore multiple paths. "In existing tree-based Retrieval-Augmented Generation methods"
- vLLM: A high-throughput inference framework used to run LLMs efficiently. "all inference is conducted using the vLLM framework\cite{DBLP:journals/corr/ultraled,DBLP:conf/sosp/vllm_kwon}"
Collections
Sign up for free to add this paper to one or more collections.