RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning
Abstract: Retrieval-Augmented Generation (RAG) integrates non-parametric knowledge into LLMs, typically from unstructured texts and structured graphs. While recent progress has advanced text-based RAG to multi-turn reasoning through Reinforcement Learning (RL), extending these advances to hybrid retrieval introduces additional challenges. Existing graph-based or hybrid systems typically depend on fixed or handcrafted retrieval pipelines, lacking the ability to integrate supplementary evidence as reasoning unfolds. Besides, while graph evidence provides relational structures crucial for multi-hop reasoning, it is substantially more expensive to retrieve. To address these limitations, we introduce \model{}, an RL-based framework that enables LLMs to perform multi-turn and adaptive graph-text hybrid RAG. \model{} jointly optimizes the entire generation process via RL, allowing the model to learn when to reason, what to retrieve from either texts or graphs, and when to produce final answers, all within a unified generation policy. To guide this learning process, we design a two-stage training framework that accounts for both task outcome and retrieval efficiency, enabling the model to exploit hybrid evidence while avoiding unnecessary retrieval overhead. Experimental results across five question answering benchmarks demonstrate that \model{} significantly outperforms existing RAG baselines, highlighting the benefits of end-to-end RL in supporting adaptive and efficient retrieval for complex reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces RouteRAG, a way to help AI models answer tough questions by looking things up as they think. It teaches the AI to decide:
- when to search for information,
- whether to search regular text or a knowledge graph (a map of how facts and people are connected),
- and when to stop and give the final answer.
It uses a training method called reinforcement learning (RL), which rewards the model for getting correct answers and for finding those answers efficiently.
What questions does the paper try to answer?
In simple terms, the researchers wanted to solve three problems:
- How can a smaller, open-source AI learn to plan its own searches while it reasons, instead of following a fixed script?
- When should the AI use text (like articles) and when should it use a graph (like a fact map) to find the best clues?
- How can we make the AI avoid unnecessary searches so it’s faster and cheaper, but still accurate?
How did they do it? (Methods explained simply)
Think of the AI as a detective solving a case:
- It reads the question.
- It starts thinking and can choose to:
- keep thinking,
- press a “search” button to look up information,
- or press an “answer” button to give the final result.
There are three ways it can search:
- Passage retrieval: finding relevant text passages (like searching articles).
- Graph retrieval: exploring a knowledge graph (like checking a map that shows how people, places, and facts connect).
- Hybrid retrieval: combining both lists using a method that boosts items that are ranked high in either list.
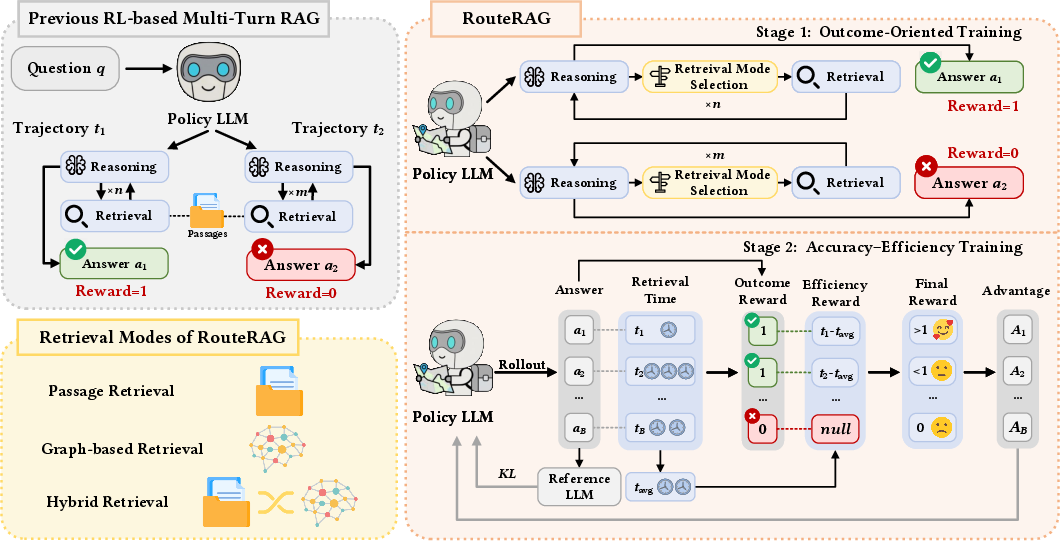
To train the detective, the authors use reinforcement learning (RL) in two stages:
- Stage 1: Reward only correct answers. This helps the model learn to be right first.
- Stage 2: Keep rewarding correct answers, but add an extra reward for efficiency. If the model reaches the right answer faster (with fewer or quicker searches), it gets bonus points. If it wastes time, it loses points.
An everyday analogy:
- RL is like coaching a player: they get points for winning (correct answers). Later, you also score them for winning quickly and with fewer moves (efficiency).
- Graphs are like friendship maps on social media: they show direct and indirect connections, which helps with multi-hop reasoning (questions that require linking several facts).
- The training method (GRPO) compares groups of the model’s attempts and nudges it toward better ones, while preventing it from changing too wildly.
What did they find and why does it matter?
Across five question-answering benchmarks (PopQA, Natural Questions, HotpotQA, 2Wiki, MuSiQue), RouteRAG:
- Beat other systems that only use text or only use graphs.
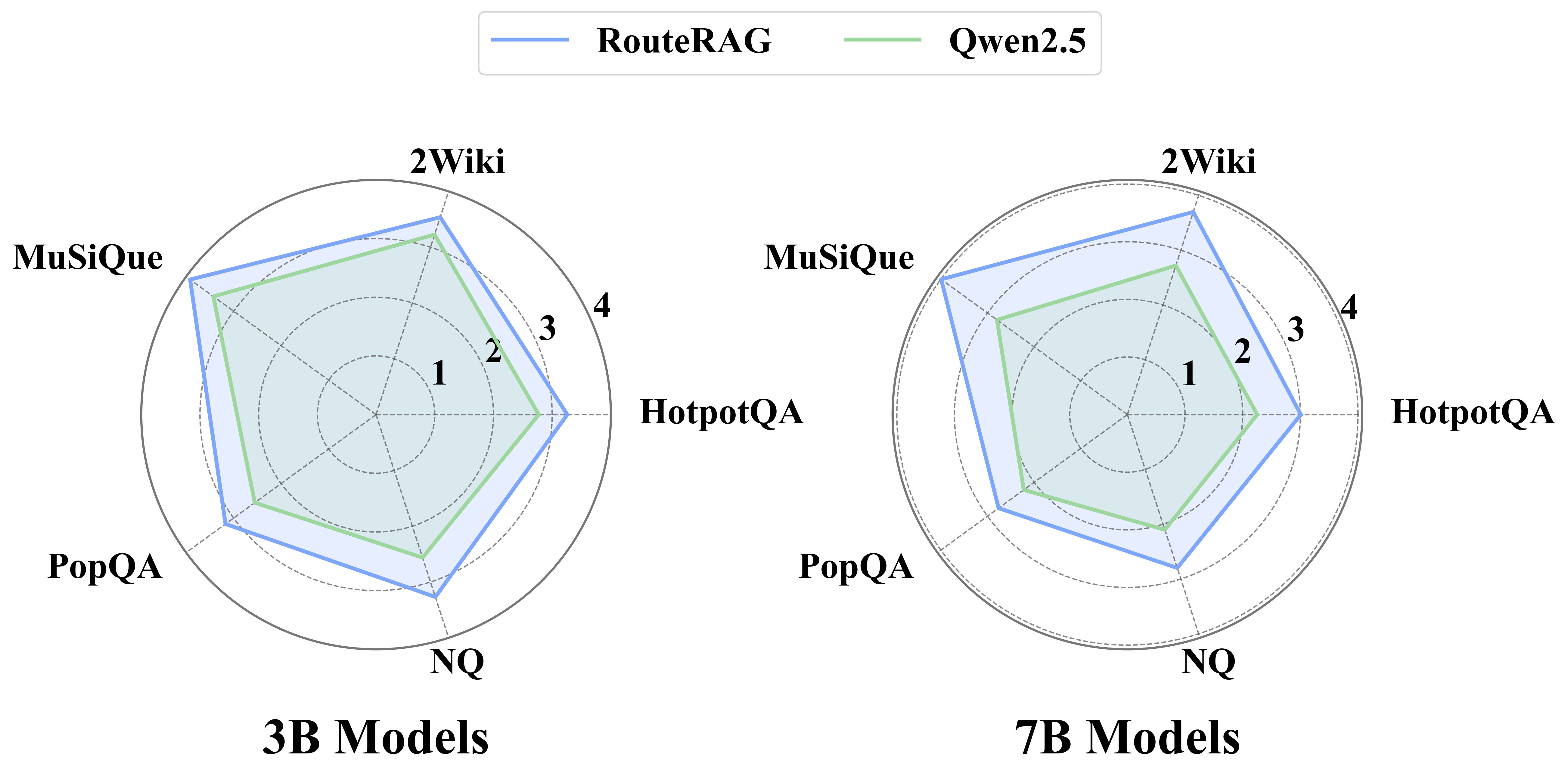
- Worked surprisingly well even with small models (3B and 7B parameters), sometimes approaching or outperforming systems powered by bigger models.
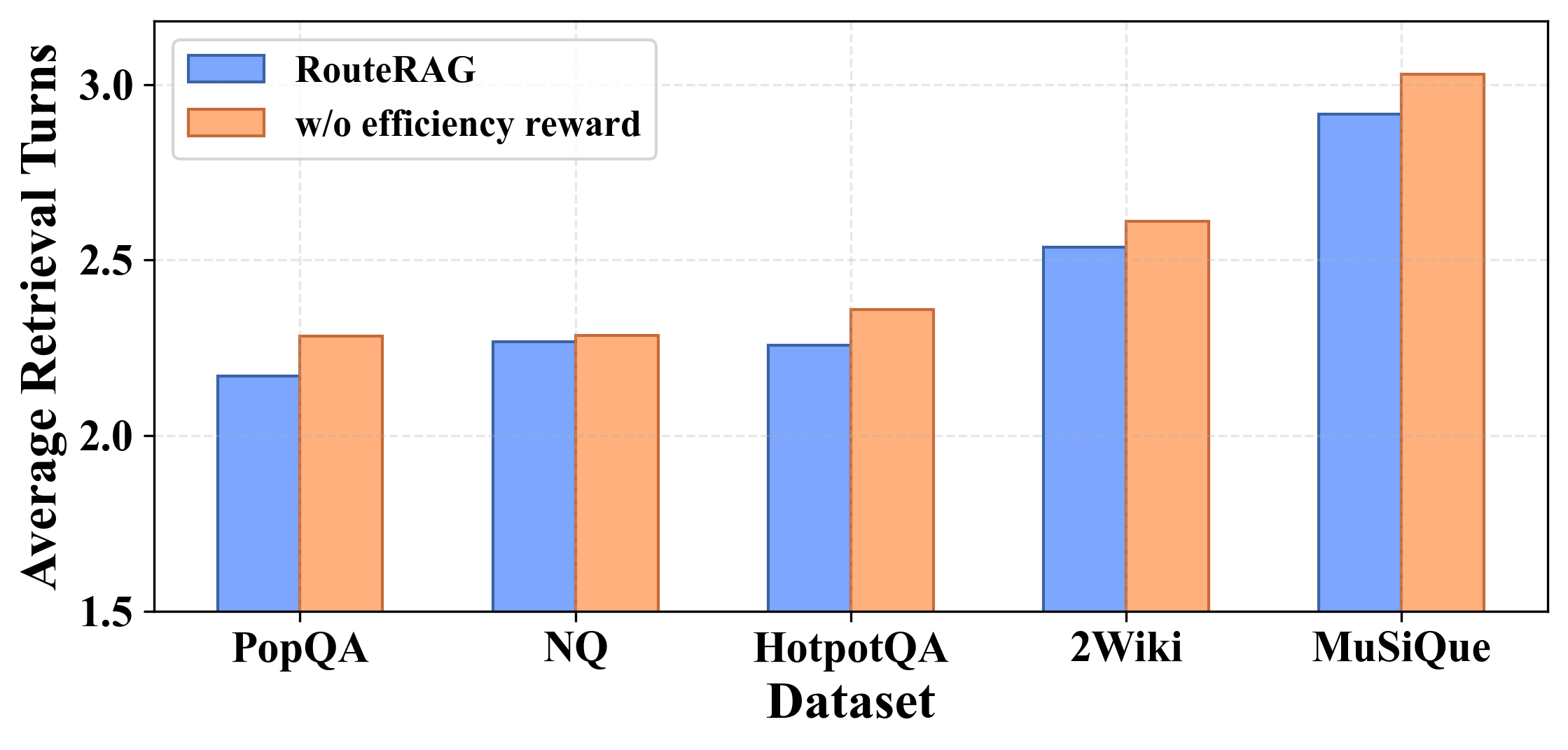
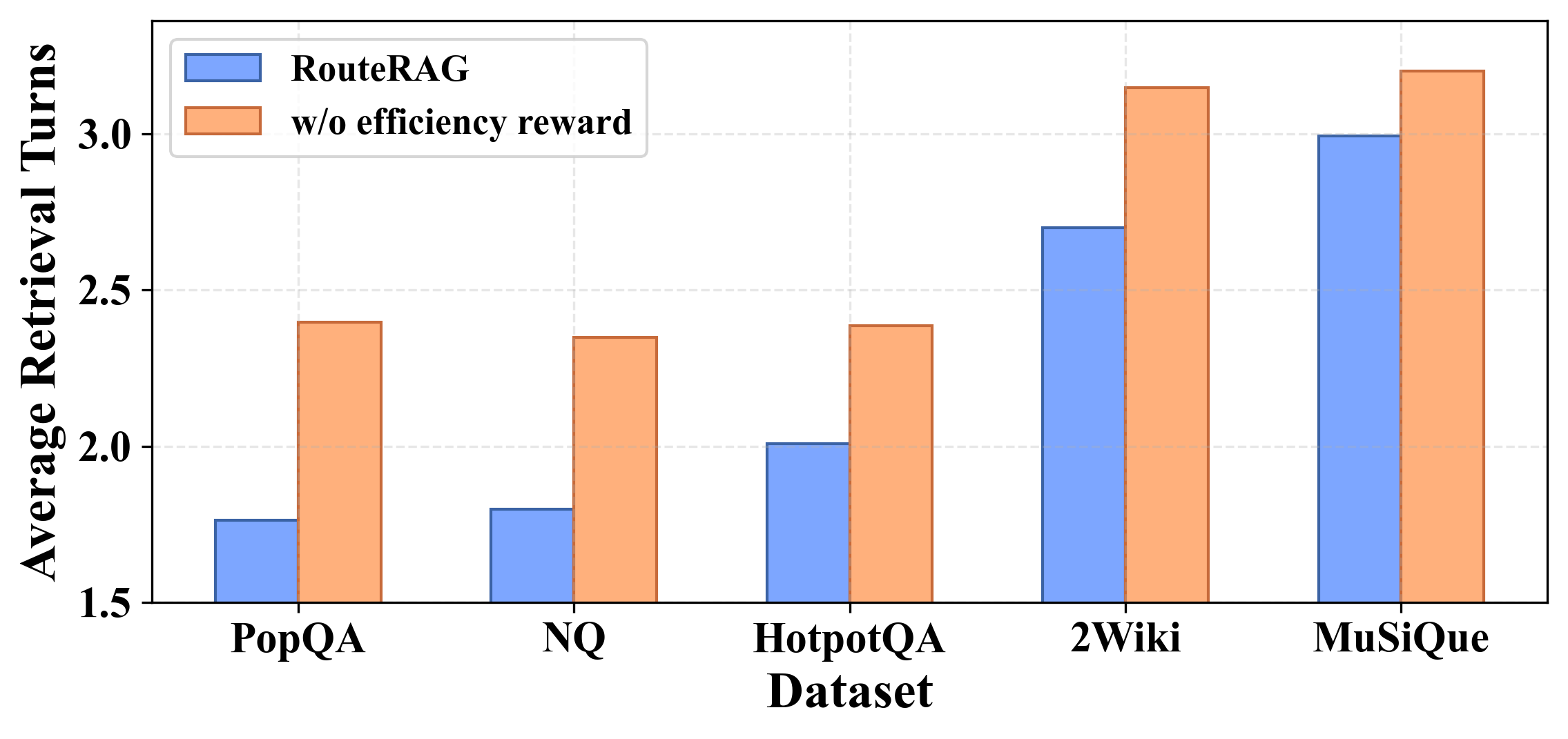
- Needed fewer search steps on average, thanks to the efficiency reward, without losing accuracy.
- Got better at “multi-hop” reasoning, meaning it could connect several facts across documents to answer more complex questions.
This matters because:
- Smaller, cheaper models can perform complex tasks well if they’re trained to search smartly.
- Adaptive retrieval (choosing text, graph, or both at the right time) is more powerful than fixed, one-size-fits-all pipelines.
- Reducing unnecessary searches saves time and computing cost, which is important in real-world applications.
What’s the impact and what’s next?
Implications:
- RouteRAG shows that teaching an AI how to search while it thinks makes it both smarter and more efficient.
- It can help build more reliable assistants for research, customer support, education, and other fields that need accurate, up-to-date information.
- It makes open-source models more competitive without needing massive training datasets.
Limitations and future directions:
- The training was done on relatively small models (3B and 7B). Larger models might behave differently.
- The graph retriever used (HippoRAG 2) is strong, but testing other graph tools would help generalize the results.
- Future work could explore more datasets, different types of graphs, and other tasks like long-form summarization or complex planning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances multi-turn, hybrid (text+graph) RAG via RL, but leaves several important aspects unaddressed. Future work can target the following concrete gaps:
- Scalability and generalization of the RL policy to larger LLMs and diverse architectures
- The approach is only trained/evaluated on Qwen2.5 3B/7B; it is unclear how RouteRAG behaves with larger backbones (e.g., 13B–70B) or different families (e.g., Llama, Mistral), especially under identical retrieval settings.
- Apples-to-apples comparisons across backbones and retrievers
- Baselines use different backbones (GPT-4o-mini vs. Qwen2.5) and different retrievers; the paper does not provide controlled experiments where all methods share the same backbone and retrieval components, making it hard to isolate the contribution of RL vs. model scale vs. retriever choice.
- Dependency on HippoRAG 2 for graph retrieval
- The system is only paired with HippoRAG 2; no sensitivity analysis is provided for alternative graph builders (e.g., entity linking strategies, heterogeneous graphs, KG embeddings) or retrievers (e.g., subgraph expansion heuristics, path-based search), nor is the impact of graph construction quality/noise assessed.
- Fusion strategy limited to RRF
- Hybrid retrieval relies on Reciprocal Rank Fusion; the paper does not explore learned fusion (e.g., RL-controlled weights, gating networks, meta-rankers) or adaptive fusion strategies conditioned on query state, nor ablate RRF hyperparameters (k) or alternative fusion methods (e.g., Borda count, Condorcet, learning-to-rank).
- Efficiency reward design and measurement
- Efficiency is measured as total retrieval time with batch-centered scaling; it is hardware/implementation dependent, ignores context-length cost (tokens added), latency variability across retrieval modes, and does not penalize inefficient query formulations (e.g., overly broad queries). No analysis is given on how the reward scales across graph sizes or retriever latencies, or how sensitive training is to the normalization constant T.
- Outcome reward uses EM only
- Exact Match overlooks partial correctness and answer variability; the paper does not evaluate using F1 or faithfulness-sensitive metrics in the reward, nor consider graded or step-wise rewards (evidence coverage, attribution correctness) to reduce sparse-reward issues.
- Step budget and halting policy
- The maximum step budget B and halting conditions are not analyzed for sensitivity; no exploration of learned stopping criteria, penalties for premature answering, or performance vs. budget curves across datasets.
- Action-space expressivity
- Retrieval actions are restricted to mode selection (Passage/Graph/Hybrid) and a single sub-query q′; there is no control over top-k, retrieval depth, graph expansion radius, or fusion parameters. It is unknown whether learning fine-grained retrieval knobs could further improve efficiency/accuracy.
- Robustness of token interface and query parsing
- The paper relies on special action tokens and ParseQuery(y_b) but does not specify robust parsing, tokenization behavior, or error handling for malformed actions; no analysis of mode-selection errors, spurious triggers, or recovery strategies.
- Training data scope and domain generalization
- The policy is trained on 10k HotpotQA samples and the retrieval corpus is “built from their associated documents”; the effect on generalization to out-of-domain corpora (PopQA, MuSiQue, NQ), larger open-domain corpora, non-English data, or noisy web data remains unclear.
- Graph scale and construction costs
- The paper does not quantify the cost of building/maintaining the knowledge graph (time, memory, storage) or evaluate RouteRAG on very large/dynamic graphs; no strategies for incremental updates, streaming insertions, or pruning are proposed.
- Evidence attribution and faithfulness
- Evaluation focuses on EM/F1; there is no measurement of factual grounding (e.g., attribution accuracy, citation completeness), nor analysis of whether answers are supported by retrieved evidence, particularly for multi-hop chains.
- Latency, token, and end-to-end cost accounting
- “Efficiency” considers retrieval turns/time but not end-to-end serving metrics (end-to-end latency, GPU/CPU utilization, memory footprint, context token expansion, truncation rates), leaving practical deployment cost-benefit unclear.
- Policy interpretability and behavior analysis
- The paper does not report distributions of retrieval-mode choices, typical switching patterns, or qualitative audits of route selection; no tools are provided to interpret why the policy chooses graph vs. text vs. hybrid at specific steps.
- Adversarial and noisy-query robustness
- The system is not stress-tested under ambiguous, adversarial, or noisy queries (e.g., typos, entity collisions), nor evaluated for calibration, abstention, or uncertainty-aware routing.
- Hyperparameter sensitivity of GRPO
- Group size G, clip range ε, and KL penalty β are not ablated; there is no comparison to PPO or other RL methods (e.g., off-policy RL, actor-critic variants) to assess stability, variance, and sample efficiency.
- Step-wise reward shaping and credit assignment
- The framework rewards only final correctness and (conditional) efficiency; it does not investigate per-step rewards (e.g., query quality, useful evidence acquisition, reasoning coherence) or curriculum strategies for credit assignment in long reasoning chains.
- Potential reward hacking and unintended biases
- Efficiency rewards may bias the policy toward cheaper passage retrieval or premature answering; the paper does not examine failure modes where the model forgoes necessary graph retrieval, nor propose safeguards (e.g., minimum-evidence constraints).
- Handling context-length limits
- RouteRAG appends retrieved evidence to the prompt but does not disclose strategies for context management (chunk selection, summarization, deduplication, re-ranking, truncation) or measure the effect on downstream reasoning when contexts approach model limits.
- Reproducibility and equation clarity
- Several equations appear malformed and some parameters (e.g., T in efficiency normalization) are underspecified; exact reward computations, parsing templates, and token conventions need clearer documentation to ensure reproducibility.
- Extension beyond text and graphs
- The approach does not consider other structured modalities (tables, relational DBs) or multimodal evidence (images, charts); it is unknown how the policy would route across heterogeneous knowledge sources.
- Human evaluation of reasoning quality
- No human studies evaluate chain-of-thought coherence, explanation quality, or user-perceived grounding, which are central for complex, multi-hop reasoning systems.
- Evidence caching and cross-session memory
- The system does not explore caching retrieved evidence across steps/queries, nor persistent memory mechanisms (e.g., recall of previously used facts), which could improve efficiency and consistency.
- Statistical robustness
- Results are reported without significance testing, seed variance, or confidence intervals; sensitivity to random initialization and training data sampling is unexamined.
Glossary
- Accuracy--Efficiency Reward: A reward design combining answer correctness with a penalty/bonus for retrieval cost to encourage efficient evidence use. "Stage 2: Accuracy--Efficiency Reward."
- Chain-of-thought reasoning: A prompting and reasoning technique where models generate intermediate reasoning steps before final answers. "emulate chain-of-thought reasoning"
- Dense Passage Retrieval (DPR): A neural retrieval method that embeds queries and passages into a shared vector space and retrieves via similarity. "The passage retriever is implemented with Dense Passage Retrieval (DPR)~\citep{Karpukhin2020dense}"
- Exact Match (EM): A strict evaluation metric that counts an answer correct only if it exactly matches the ground truth string. "We report Exact Match (EM) and F1 scores as evaluation metrics."
- Group Relative Policy Optimization (GRPO): An RL algorithm that stabilizes training by comparing and rewarding trajectories within a sampled group. "we adopt a two-stage Group Relative Policy Optimization (GRPO)~\citep{Shao2024deepseekmath} training framework."
- group-relative advantage: The advantage signal computed relative to other trajectories in the same group to reduce variance in policy updates. " denotes the group-relative advantage for the -th trajectory"
- Hybrid Retrieval: A retrieval mode that fuses results from text and graph retrievers to leverage complementary strengths. "Hybrid Retrieval. The hybrid retriever combines passage and graph retrieval using Reciprocal Rank Fusion (RRF)~\citep{Cormack2009reciprocal}."
- KL penalty: A regularization term using KL divergence to prevent the new policy from straying too far from the old policy during RL updates. "and the KL penalty regularizes the new policy against deviating excessively from the old policy."
- Knowledge graph: A structured representation of entities and relations enabling multi-hop reasoning over connected information. "constructs a knowledge graph over passages."
- Multi-hop reasoning: Reasoning that requires combining information across multiple steps or sources to reach an answer. "graph evidence provides relational structures crucial for multi-hop reasoning"
- Non-parametric knowledge: External information not stored in model parameters but accessed at inference time via retrieval. "Retrieval-Augmented Generation (RAG) integrates non-parametric knowledge into LLMs"
- Personalized PageRank: A graph algorithm that propagates relevance from query-linked nodes to rank connected nodes by importance. "applies personalized PageRank over the graph to propagate relevance"
- Proximal Policy Optimization (PPO): A widely used policy gradient algorithm that stabilizes updates with clipped objective terms. "Proximal Policy Optimization (PPO)~\citep{Schulman2017proximal} remains the predominant algorithm for achieving these goals."
- Reciprocal Rank Fusion (RRF): A rank aggregation method that merges multiple ranked lists by summing reciprocal ranks to promote items highly ranked in any list. "using Reciprocal Rank Fusion (RRF)~\citep{Cormack2009reciprocal}"
- Reinforcement Learning from Human Feedback (RLHF): An RL paradigm where a reward model trained on human preferences guides policy optimization. "RL from Human Feedback (RLHF)~\citep{Christiano2017deep, Ouyang2022training} has established a standard paradigm"
- Retrieval-Augmented Generation (RAG): A framework that augments LLMs with retrieved external evidence to improve factuality and coverage. "Retrieval-Augmented Generation (RAG) integrates non-parametric knowledge into LLMs"
- step budget: The maximum number of reasoning/retrieval iterations allowed in a multi-turn process. "where is the maximum step budget."
- unified generation policy: A single learned policy that interleaves reasoning, retrieval decisions, and answer generation within one framework. "all within a unified generation policy."
Practical Applications
Overview
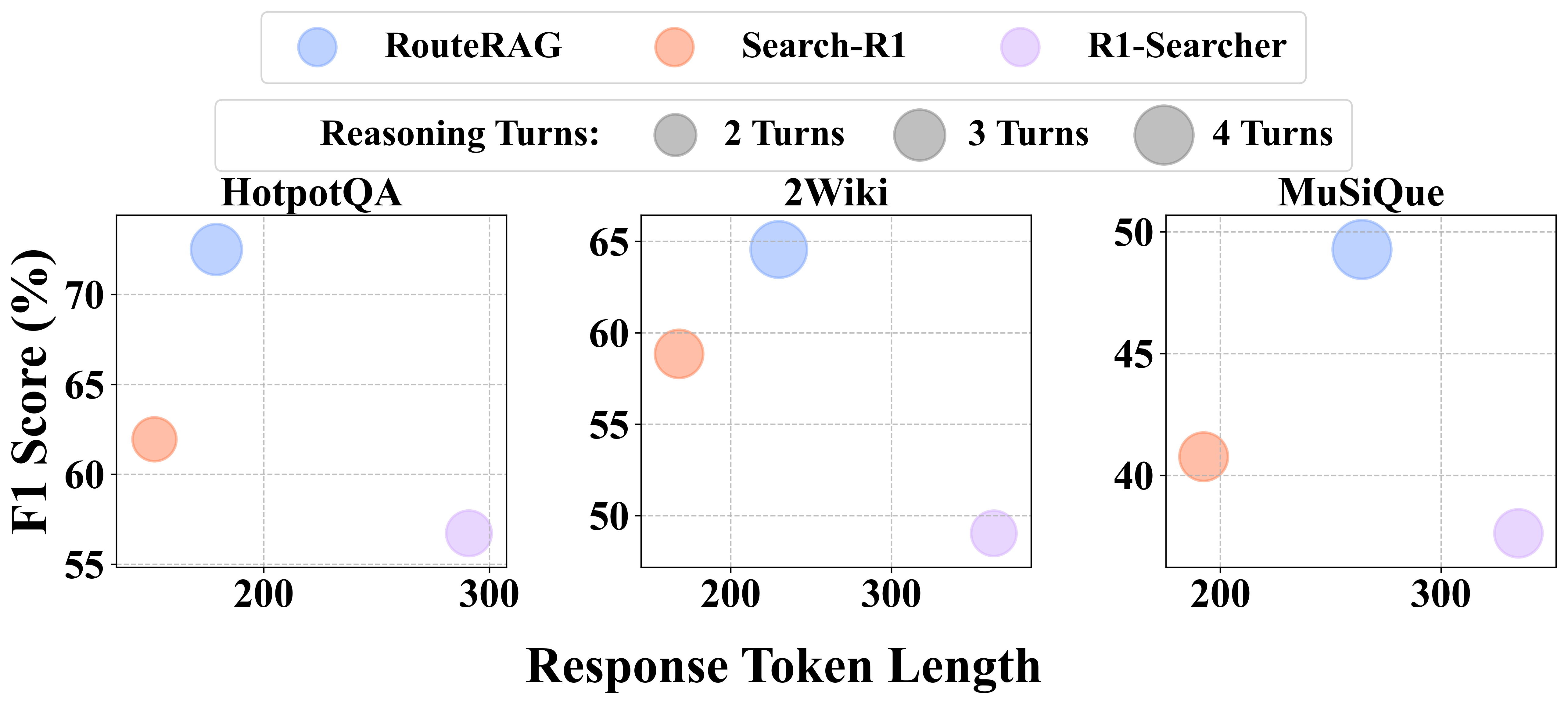
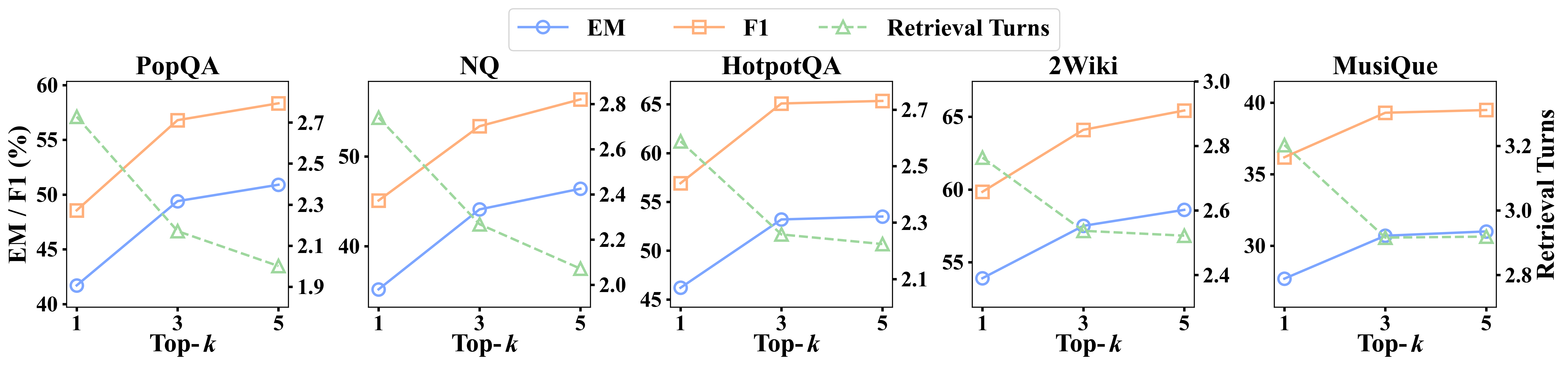
RouteRAG introduces a reinforcement-learning (GRPO) trained, multi-turn Retrieval-Augmented Generation system that adaptively chooses among passage, graph, and hybrid retrieval while interleaving retrieval with reasoning. A two-stage reward design first optimizes answer correctness, then adds an efficiency reward to reduce unnecessary retrieval without sacrificing accuracy. Empirically, RouteRAG improves multi-hop QA on small, open-source backbones (3B/7B) and reduces retrieval turns (e.g., up to ~20% on 7B) while maintaining or improving F1.
Below are practical applications of these findings, organized by time horizon.
Immediate Applications
These can be deployed now using existing vector databases, graph stores, and small open-source LLMs (e.g., Qwen2.5-3B/7B) with RouteRAG’s open-source implementation.
- Sector: Software/IT (Enterprise Knowledge Assistants)
- Use case: Enterprise Q&A over intranet documents and organizational knowledge graphs (e.g., org charts, data lineage, service dependency graphs).
- Tools/workflow: Vector DB (FAISS, Milvus, Weaviate) + Graph DB (Neo4j, TigerGraph) + RouteRAG policy; hybrid RRF ranking; two-stage GRPO training on domain QA.
- Benefits: Better multi-hop answers across docs and relations; fewer retrieval calls and lower latency/cost due to efficiency reward.
- Assumptions/dependencies: Availability/quality of a knowledge graph; domain QA data for stage-1/2 RL; infra to measure retrieval-time for efficiency rewards.
- Sector: Research & Academia (Literature Review Assistant)
- Use case: Multi-hop synthesis across papers by combining text retrieval and citation graphs to answer “What evidence connects A to B through C?”-type queries.
- Tools/workflow: DPR/Contriever for abstracts/full-text; citation/venue graphs; RouteRAG’s hybrid mode to traverse citations + read passages.
- Assumptions/dependencies: Access to structured citation graphs; legal access to full-text; ground-truth answers for initial RL or use weak labels.
- Sector: Legal (E-Discovery and Case-law Research)
- Use case: Link arguments across statutes, precedents, and party/case citation graphs; reduce irrelevant document pulls.
- Tools/workflow: Case-law text retrieval + legal citation graph; RouteRAG with efficiency reward for budget-aware retrieval.
- Assumptions/dependencies: Licensed legal corpora and structured citation networks; strict audit trails and provenance logging.
- Sector: Customer Support (Technical Support Copilot)
- Use case: Troubleshooting by combining product manuals (text) and device/component graphs (e.g., parts hierarchies, dependency graphs).
- Tools/workflow: Vector search over manuals; asset/parts graph; RouteRAG to adaptively retrieve graph vs. text when multi-hop linking is needed.
- Assumptions/dependencies: Maintained product/asset graph; up-to-date documentation.
- Sector: Finance (Research & Compliance Copilot)
- Use case: Compliance mapping across regulations (text) and control frameworks/ownership graphs; multi-step reasoning to trace impact.
- Tools/workflow: Retrieval over regulatory texts + control/ownership graphs; RouteRAG for cost-efficient, stepwise analysis; RRF to fuse signals.
- Assumptions/dependencies: Curated graph of entities/controls; compliance review; human-in-the-loop sign-off.
- Sector: Healthcare (Non-clinical Information and Knowledge Ops)
- Use case: Medical literature and guideline aggregation; linking drug–disease–mechanism paths in knowledge graphs (e.g., UMLS) with matched passages.
- Tools/workflow: Vector DB for clinical texts; biomedical KG; RouteRAG’s hybrid retrieval for multi-hop grounding.
- Assumptions/dependencies: Not for direct clinical decision support without validation; data governance for PHI; high-quality biomedical KGs.
- Sector: Security (Threat Intelligence & SOC Triage)
- Use case: Connect IOCs and TTPs across CTI reports (text) and attack graphs; answer “What lateral movement is likely given observed IOCs?”
- Tools/workflow: TI text retrieval + ATT&CK/attack graphs; RouteRAG to limit costly graph expansions to necessary steps.
- Assumptions/dependencies: Up-to-date IOC/attack graphs; latency-tolerant SOC pipeline; red-teaming and false-positive controls.
- Sector: Data/Analytics (Data Catalog & Lineage Assistant)
- Use case: Answer lineage and impact questions that require multiple hops across datasets, schemas, and lineage graphs plus documentation.
- Tools/workflow: Data catalog text + lineage graph; RouteRAG hybrid retrieval; cost-aware retrieval for speed.
- Assumptions/dependencies: Accurate lineage metadata; standardization across catalogs.
- Sector: Education (Tutor & Courseware Assistant)
- Use case: Multi-step concept linking using text from textbooks and a concept/prerequisite graph; generate explanations grounded in both.
- Tools/workflow: Curriculum text corpus + concept graph; RouteRAG’s dynamic choice of passages vs. concept graph hops.
- Assumptions/dependencies: Quality of concept graph; alignment with curricula; content licensing.
- Sector: News/Media (Fact-Checking)
- Use case: Multi-hop claims verification by linking entities in a KG and corroborating with passages; fewer extraneous retrievals.
- Tools/workflow: Entity/relation KG; news/article retrieval; RouteRAG with efficiency reward for rapid verification workflows.
- Assumptions/dependencies: Up-to-date KGs; handling evolving claims and ambiguous entities.
- Sector: Software Engineering (Code/Search Assistant)
- Use case: Answer “where is this behavior implemented?” by retrieving across documentation and code graphs (call graphs, dependency graphs).
- Tools/workflow: Embedding search over repo docs; code graph extraction (e.g., LSP, static analysis); RouteRAG hybrid retrieval.
- Assumptions/dependencies: Reliable code graph generation; token budget constraints for large repos.
- Cross-cutting (Cost/Latency Optimization for RAG Systems)
- Use case: Plug RouteRAG’s efficiency reward into existing RAG agents to reduce retrieval turns and API spend while preserving accuracy.
- Tools/workflow: Use retrieval-time as a proxy for cost; GRPO stage-2 finetuning on in-domain tasks; dynamic stopping.
- Assumptions/dependencies: Stable and meaningful retrieval-time measurements; monitoring to avoid over-aggressive stopping.
Long-Term Applications
These require further research, scaling, regulatory approval, or ecosystem maturation (e.g., high-quality graphs, broader tool-use).
- Sector: Healthcare (Clinical Decision Support)
- Use case: Hybrid retrieval from EHR-structured graphs (e.g., FHIR) and guidelines for complex cases and differential diagnoses.
- Potential product: FDA-regulated clinical assistant with provenance and path explanations via graph hops.
- Dependencies: Clinical validation trials; bias/risk management; certified data pipelines; on-prem deployments.
- Sector: Finance (Risk, Audit, and M&A Due Diligence)
- Use case: Automated multi-hop analysis across filings, news, and ownership/control graphs for risk/benefit synthesis.
- Potential product: “Graph-aware diligence engine” with audit trails and reproducibility of reasoning chains.
- Dependencies: High-fidelity corporate/ownership KGs; model risk management; compliance sign-off; extensive RL on domain tasks.
- Sector: Public Policy & Government (Regulatory Impact Analysis)
- Use case: Multi-hop tracing of policy changes through regulation text and inter-agency dependency graphs.
- Potential product: Policy scenario simulator that reveals graph paths, sources, and affected stakeholders.
- Dependencies: Trusted, current regulation KGs; interpretability standards; rigorous evaluation frameworks.
- Sector: Robotics & IoT (Knowledge-Grounded Planning)
- Use case: Agents that combine procedural text (manuals) and device/component graphs for multi-step planning and recovery procedures.
- Potential product: On-device, cost-aware assistants with local graph stores and adaptive retrieval budgets.
- Dependencies: Real-time graph construction/updates; latency constraints; safety and verification.
- Sector: Scientific Discovery (Hypothesis Generation)
- Use case: Linking distant concepts through biomedical or materials KGs and literature, enabling multi-hop hypothesis formation.
- Potential product: “Discovery copilot” that outputs graph-based rationales and supporting passages.
- Dependencies: High-coverage domain KGs; evaluation protocols for novelty/validity; human-in-the-loop curation.
- Sector: Supply Chain & Manufacturing (Resilience Analytics)
- Use case: Multi-hop risk tracing across supplier graphs and document repositories; “what-if” scenario evaluation.
- Potential product: RouteRAG-powered risk console with cost-aware retrieval to scale across large supplier graphs.
- Dependencies: Accurate supplier/part graphs; real-time event integration; governance for sensitive data sharing.
- Sector: Education (Personalized Learning Paths)
- Use case: Dynamic tutoring that adapts retrieval and reasoning to a learner’s concept graph, generating custom paths.
- Potential product: Graph-informed adaptive learning platform with explainable multi-hop rationales.
- Dependencies: Rich learner model/graphs; content alignment; fairness audits.
- Sector: Multimodal RAG (Text–Table–Image–Graph Integration)
- Use case: Answering multi-hop questions requiring tables and figures linked through graph structures (e.g., financial reports).
- Potential product: Multimodal hybrid retriever with RL policies that price-in retrieval cost across modalities.
- Dependencies: Robust multimodal retrievers and embeddings; unified tool-use framework; larger context windows.
- Cross-cutting (Dynamic KG Construction In-Loop)
- Use case: Agents that build/refine knowledge graphs on-the-fly during reasoning and reuse them for subsequent retrieval.
- Potential product: “Self-growing memory” systems that merge RAG with continual graph construction.
- Dependencies: Reliable entity/linking at scale; deduplication/quality control; catastrophic error safeguards.
- Cross-cutting (Standardized Efficiency-Aware RAG Benchmarks and Tooling)
- Use case: Industry benchmarks and MLOps tools that track accuracy, retrieval turns, latency, and cost jointly.
- Potential product: Efficiency-aware RL toolkits with plug-and-play rewards, simulators, and budget controllers.
- Dependencies: Community consensus on metrics; logging standards; reproducibility infrastructure.
Notes on Feasibility and Deployment
- Data and infrastructure:
- High-quality knowledge graphs are pivotal; their construction/maintenance remains a primary cost and risk.
- Vector + graph infra integration (and monitoring of retrieval-time) is required to leverage efficiency rewards.
- Training and evaluation:
- Stage-1/2 RL requires domain tasks with clear correctness signals (EM or robust matchers); free-form tasks may need alternative rewards (e.g., learned reward models or semantic equivalence).
- Generalization may degrade out-of-domain; staged fine-tuning and continual learning are recommended.
- Compliance and governance:
- Provenance tracking is essential (graph paths + passages) for auditability in regulated sectors.
- Guardrails for privacy, bias, and safety are required; RouteRAG’s adaptive retrieval can surface sensitive content if not constrained.
- Cost and latency:
- Efficiency rewards can materially reduce retrieval turns and API costs, but benefits depend on stable, measurable retrieval-time signals and caching strategies; monitor for over-pruning that may harm recall on rare cases.
These applications leverage RouteRAG’s core contributions—adaptive graph-text retrieval, multi-turn reasoning under a unified policy, and efficiency-aware RL—to deliver better multi-hop performance and lower retrieval overhead in real-world systems.
Collections
Sign up for free to add this paper to one or more collections.