- The paper introduces a novel retrieval-as-reasoning paradigm that compiles documents into interlinked Wiki pages, enabling iterative multi-hop reasoning.
- It details a methodology combining compilability, composability, and a persistent error correction mechanism to overcome limitations of flat-chunk RAG systems.
- Empirical results reveal significant improvements over traditional baselines in multi-hop question answering, affirming the benefits of structured knowledge organization.
Retrieval as Reasoning via LLM-Wiki: Agent-Native Compilable, Composable, and Self-Evolving Retrieval
Motivation and Problem Statement
The paper addresses a central challenge in agent-driven retrieval: flat-chunk RAG (Retrieval-Augmented Generation) systems constrain retrieval to embedding-based, one-shot similarity lookup over independent document fragments, impeding iterative reasoning and compositional evidence gathering required for multi-hop QA and agentic workflows. Specifically, agents increasingly adopt ReAct-style tool-calling loops, demanding knowledge that supports search, read, traversal, and sufficiency checks. Current RAG paradigms degrade on complex queries due to limitations in knowledge organization—not merely retrieval algorithmic performance.
LLM-Wiki: Architectural Innovations
LLM-Wiki implements the Retrieval-as-Reasoning paradigm via three foundational principles:
- Compilability: Documents are compiled into persistent, interlinked Wiki pages with rich metadata, bidirectional links, tags, structured key facts, and explicit provenance, rather than segmented into flat, semantically opaque chunks.
- Composability: Retrieval is operationalized as a sequence of compositional atomic actions (search, read, link-following) exposed via standard tool-calling interfaces. Agents iteratively search, judge evidence sufficiency, traverse links, and re-plan based on intermediate findings.
- Evolvability: A persistent Error Book records systematic compilation errors (dangling links, malformed references, unsupported facts, cross-page contradictions), attributes root causes, and injects constraint-based repair at both code and LLM-instructional levels, enabling the knowledge base to self-correct and avoid degradation.
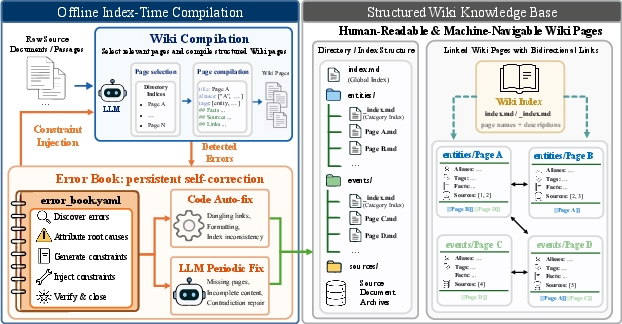
Figure 1: Index-time construction and structured Wiki knowledge base in LLM-Wiki; raw documents are compiled into linked Wiki pages, while the Error Book records validation failures and drives repair, yielding a human-readable, machine-traversable Wiki.
Retrieval-as-Reasoning vs Retrieval-as-Lookup
The paper formalizes the critical distinction between retrieval-as-lookup and retrieval-as-reasoning:
- Retrieval-as-lookup: Retrieval is a fixed, single-shot matching step; agents consume top-k chunks without compositional traversal or iterative re-planning. This paradigm is brittle for reasoning tasks requiring relational following, entity comparison, or evidence aggregation.
- Retrieval-as-reasoning: Agents traverse knowledge structures via search-first and browse-first routes, adaptively reading indices or pages, following explicit links, and terminating upon evidence sufficiency. Retrieval becomes an explicit reasoning process rather than a hidden ranking step.
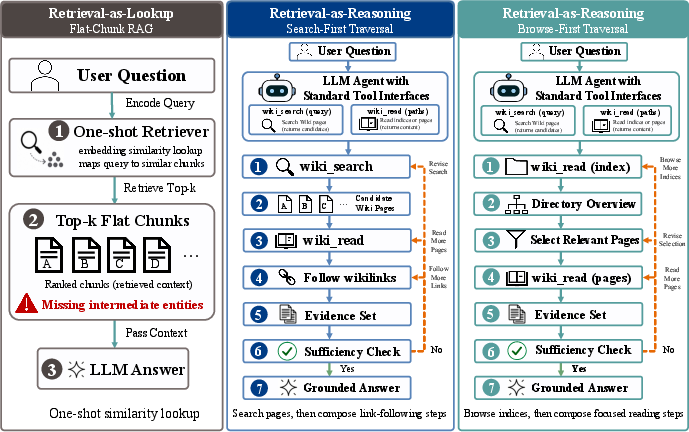
Figure 2: Retrieval-as-lookup versus retrieval-as-reasoning. LLM-Wiki enables agents to perform compositional traversal, evidence sufficiency checks, and re-planning, unlike traditional RAG's one-shot context fetching.
Wiki Structure and Compositional Traversal
LLM-Wiki provides a schema for directory indices, structured pages, and source digests. Agents use:
- wiki_search(query): Locates pages via names, aliases, tags, and descriptions, mitigating limitations of pure embedding indexing.
- wiki_read(paths): Batch-reads structured pages and indices, exploiting explicit links for traversal.
- Traversal strategies: Direct access, bridge queries, exploratory browsing—all governed by explicit link-following and evidence sufficiency checks.
Algorithmic details highlight incremental compilation and validation, sustaining Wiki consistency in dynamic, evolving knowledge bases.
Error Book: Persistent Self-Correction
The Error Book systematically addresses recurring structural and semantic failures, operationalizing a constraint-based repair loop:
- Structural errors: Dangling links, malformed references, incomplete pages, index inconsistencies
- Content errors: Unsupported facts (not grounded in cited sources), cross-page contradictions
- Repair mechanisms: Code-level deterministic fixes maintain traversability; periodic LLM-based constraint injection minimizes semantic degradation
The persistent tracking and propagation of constraints ensure that knowledge organization scales across batches, avoiding silent drift into inconsistency or factual unreliability.
Empirical Results
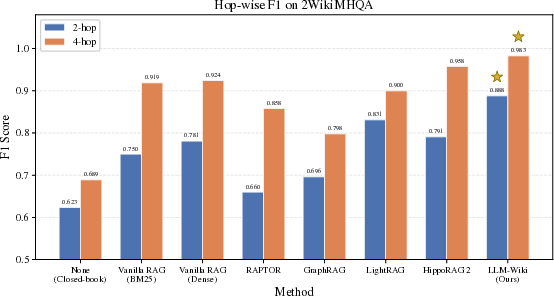
LLM-Wiki is evaluated against seven baselines, including BM25/Dense RAG, RAPTOR, GraphRAG, LightRAG, and HippoRAG 2, on HotpotQA, MuSiQue, 2WikiMultiHopQA, and AuthTrace.
Fine-Grained and Additional Analyses
- Type-wise F1: LLM-Wiki maintains ceiling performance on comparison/bridge-comparison questions and substantial increases on compositional/inference questions. The benefits persist across answer LLMs (GLM-5.1, GPT-4o), showing that improvements derive from knowledge organization and retrieval design rather than idiosyncratic model capabilities.
- Efficiency: Despite additional traversal steps, query-time latency is comparable to or faster than strong baselines (BM25/Dense/GraphRAG), due to amortized compilation and targeted link-based navigation.
Theoretical and Practical Implications
The results empirically validate that agent-native, structured knowledge organization—rather than embedding-based ranking or graph-based summary compression—constitutes the bottleneck for iterative, compositional reasoning. Pre-compiled, bidirectional links transform multi-hop queries into tractable traversal paths, enabling agents to explicitly discover and aggregate intermediate entities, relations, and evidence units.
The Error Book's persistent repair loop mitigates recurrent construction errors, providing a scalable solution to knowledge degradation as Wiki size and semantic complexity increase. Compilation-based organization amortizes query cost and grounds retrieval in persistent, auditable structure, facilitating both human and agentic inspection.
Practically, LLM-Wiki's paradigm extends to evidence synthesis, entity-centric reasoning, and dynamic knowledge maintenance. The agent-tool interface and self-correction design provide a blueprint for robust, scalable retrieval in agentic workflows, especially as LLMs transition toward increasingly complex, multi-step environment interaction.
Future Directions
Challenges remain in scaling LLM-Wiki to web-scale corpora: hierarchical indexing, sharding, stale-fact resolution, and global directory management are needed as page counts rise. Multi-modal and cross-corpus transfer will require schema extension and maintenance strategies for dynamic updates. Integration with autonomous agent planning and tool orchestration can further enhance evidence construction in open-domain scenarios.
Conclusion
LLM-Wiki establishes Retrieval-as-Reasoning as a viable agent-native paradigm, substantiating that compiling knowledge into navigable structure, compositional traversal, and closed-loop self-correction yield consistent performance gains for knowledge-intensive agentic tasks. The synergy between knowledge organization, agent-controlled traversal, and persistent error mitigation points toward robust, scalable designs for next-generation retrieval systems.