- The paper introduces a novel S2G-Judge controller that explicitly assesses evidence sufficiency and identifies structured gap items to guide iterative retrieval.
- The methodology leverages trajectory distillation with a stronger teacher model to supervise the controller under realistic, multi-turn conditions.
- Empirical results demonstrate significant improvements in EM and F1 scores on benchmarks like HotpotQA, while efficiently compressing context to reduce noise.
S2G-RAG: Structured Sufficiency and Gap Judging for Iterative Retrieval-Augmented QA
Introduction: Problem Motivation and Limitations of Prior Approaches
Retrieval-Augmented Generation (RAG) has established itself as a dominant paradigm for knowledge-intensive NLP tasks, enabling LLMs to ground answers in external corpora. However, multi-hop QA continues to challenge existing RAG pipelines due to their inability to (1) explicitly determine when the currently gathered evidence is sufficient for final answering, and (2) reliably identify and retrieve information that is still missing. Prior approaches typically employ implicit control signals, query rewriting, or self-reflective critics, but these mechanisms are either entangled with free-form generation or lack standardized, auditable state representations. Furthermore, naive evidence accumulation strategies lead to unbounded context growth, exacerbating noise, redundancy, and distractor proliferation, which degrade both retrieval control and answer accuracy.
S2G-RAG Framework: Explicit and Modular Iterative Control
S2G-RAG (Structured Sufficiency and Gap-judging RAG) addresses the iterative control bottleneck by introducing a lightweight, explicit controller termed S2G-Judge. At each inference turn, S2G-Judge receives the input question and the currently accumulated evidence context, then predicts:
- A binary sufficiency decision indicating whether current evidence supports robust answering.
- A structured set of 'gap items' that specify, in a normalized schema, missing information required for successful multi-hop progress (fields: category, target, slot, description).
If the context is sufficient, the answer reasoner is invoked. Otherwise, gap items are deterministically mapped into retrieval queries to guide focused evidence acquisition. A sentence-level Evidence Extractor, aligned to the predicted gaps, selects compact, provenance-preserving evidence blocks for context update, reducing noise inheritance.
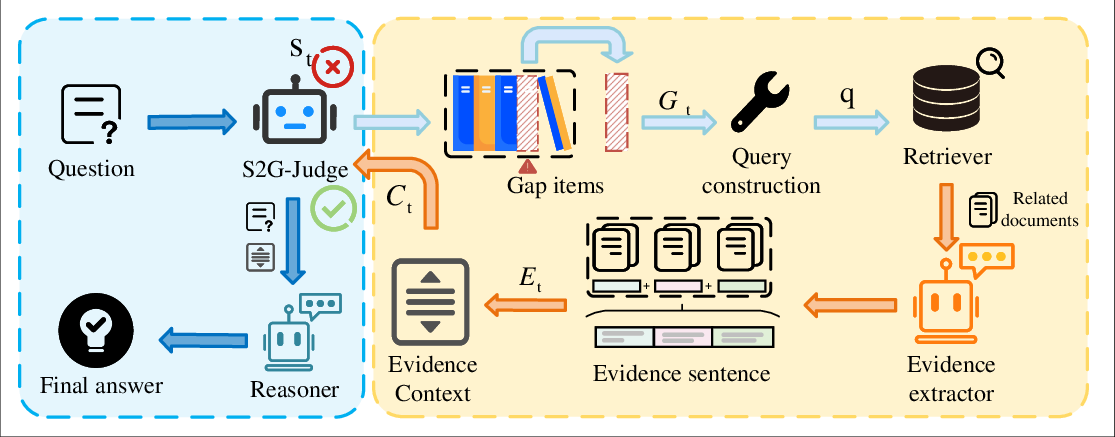
Figure 1: Overview of the S2G-RAG inference framework, highlighting explicit sufficiency decisions, structured gap extraction, and sentence-level evidence context construction by the Evidence Extractor.
This explicit and modular decomposition ensures that retrieval control is auditable, minimizes interaction between control and answer generation, and stabilizes multi-turn evidence chains against traditional pitfalls of context drift and distractor accumulation.
Controller Training via Trajectory Distillation
S2G-Judge's structured outputs demand reliable supervision at the execution trace level. The training data is gathered by executing the iterative retrieval loop using an unfine-tuned judge, logging per-turn (q,Ct) pairs. A much stronger teacher (GPT-4o-mini) labels each snapshot under a context-only constraint, indicating sufficiency and enumerating gaps, independent of any parametric knowledge. Supervision signals are filtered for conflicts/format violations and distilled into S2G-Judge using LoRA-based SFT.
This trajectory-level distillation resolves supervision mismatch with respect to realistic, distractor-heavy intermediate evidence states and enables the controller to learn fine-grained sufficiency and gap recognition under actual multi-turn pipeline conditions.
Empirical Results
S2G-RAG delivers strong improvements over a range of baselines on diverse open-domain QA benchmarks, including TriviaQA, HotpotQA, and 2WikiMultiHopQA, under both sparse (BM25) and dense (E5) retrieval settings.
- On HotpotQA (BM25), S2G-RAG achieves 43.3 EM and 56.5 F1, representing gains of +10.6 EM / +13.2 F1 over SIM-RAG. On 2WikiMultiHopQA, gains are +7.6 EM / +8.4 F1 over the best prior.
- With dense retrievers, S2G-RAG remains superior, outperforming RAG-Critic and ReSP.
The framework is robust to retriever choice, per-turn retrieval breadth, and evidence sentence cap variation.
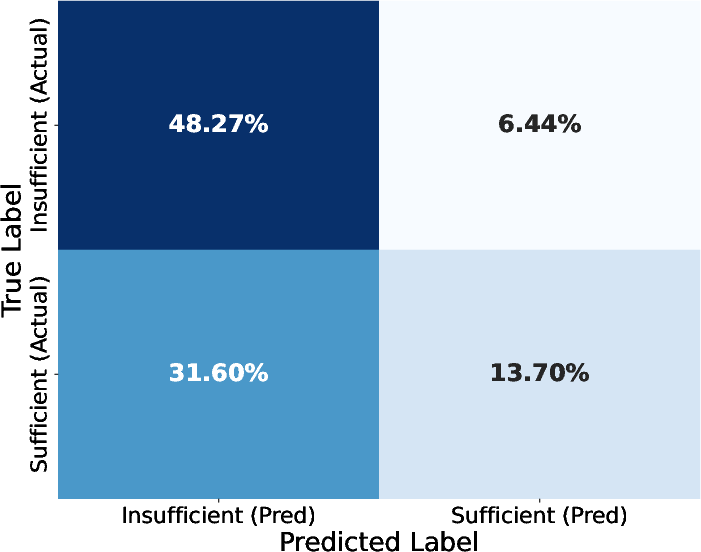
Figure 2: Confusion matrix of S2G-Judge sufficiency predictions, showing a low false-positive rate (<7%) and a conservative bias that reduces premature answering.
Comprehensive ablation studies reveal the sufficiency/gap controller contributes the bulk of the improvement, while sentence-level extraction yields substantial context compression and efficiency gains.
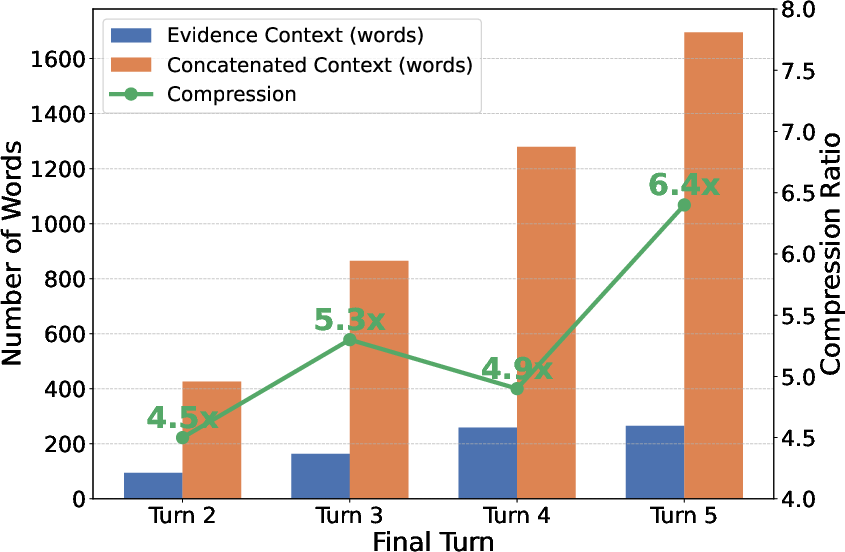
Figure 3: Evidence Context remains succinct (compression ratio up to 6.4×) compared to naive document concatenation, controlling context growth and limiting distractor propagation.
Latency measurements confirm that evidence compression not only improves answer accuracy but also reduces per-sample runtime relative to uncompressed accumulation.
Analysis of Control and Compression
S2G-Judge's sufficiency signal is highly reliable—it rarely over-claims and prefers conservatism, as quantified by confusion matrix analysis (see above). This reduces the risk of producing answers from incomplete evidence, though there is capacity to improve calibration for edge cases where sufficiency is borderline but answerable.
The sentence-level Evidence Extractor ensures multi-hop retrieval does not introduce uncontrolled context growth, yielding compact supporting contexts even as the number of retrieval turns increases.
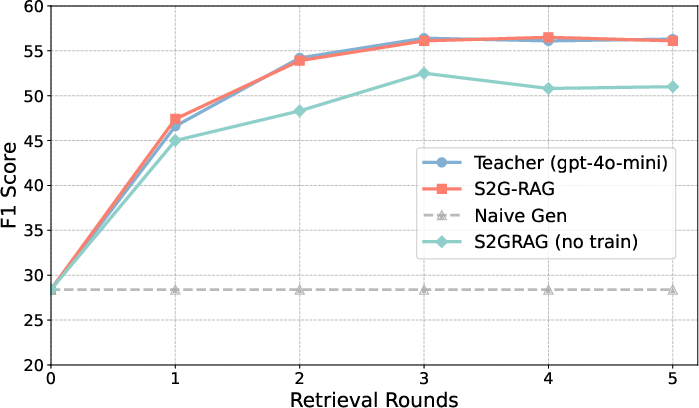
Figure 4: F1 accuracy as a function of retrieval budget, demonstrating S2G-RAG's robust scaling and close teacher-student performance alignment via trajectory distillation.
Comparative experiments with extractive and abstractive compression baselines highlight a superior accuracy-to-compression trade-off for pointer-based selection: S2G-RAG's extractor outperforms both LLM summarization and ReComp, while achieving substantial context reduction without loss of provenance.
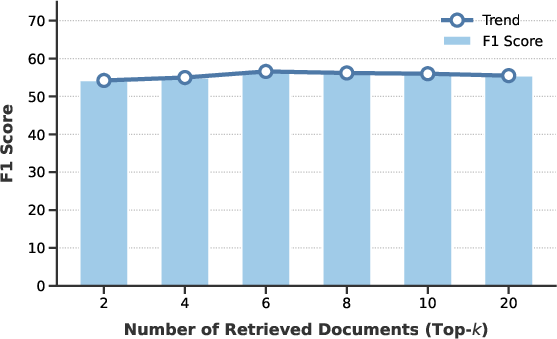
Figure 5: S2G-RAG demonstrates robust QA performance across a wide sweep of per-turn retrieval breadths k, unaffected by increases in candidate distractor input size due to effective sentence-level selection.
Implications and Future Directions
The explicit, structured, and modular approach of S2G-RAG represents a significant step towards reliable, diagnosable multi-hop QA pipeline design. The decoupling of evidence sufficiency and gap recognition from answer reasoning formalizes turn-level control and streamlines error identification and system inspection. The sentence-level extraction paradigm further resolves critical context bloat vulnerabilities, enabling both high answer recall and efficient inference at scale.
The S2G-Judge interface is compatible with advances in downstream generator/reasoner architectures; integrating more expressive gap schemas (e.g., multi-entity operations, temporal compositions) or coupling with direct policy optimization regimes (RL, actor-critic) are promising extensions. Improved calibration for sufficiency and more adaptive evidence selection strategies represent concrete frontiers to refine performance on ambiguous or compositional queries.
Conclusion
S2G-RAG systematically addresses the iterative retrieval control bottleneck in RAG pipelines via explicit, structured sufficiency and information gap judgment. Experiments confirm strong gains on multi-hop QA, with robust improvements in effectiveness, context compression, and efficiency. The methodology supports modular integration, rigorous auditing, and paves the way for next-generation, self-diagnosing, and adaptive retrieval-augmented reasoning systems.