- The paper presents a novel agentic RAG framework that reduces token usage by up to 61% while enhancing QA accuracy.
- It details a five-module pipeline combining semantic and graph-based retrieval with Personalized PageRank filtering to optimize token efficiency.
- Empirical evaluations show improved Exact Match scores and concise, stable reasoning paths across multiple multi-hop QA benchmarks.
Token-Efficient Agentic RAG via TeaRAG
TeaRAG presents an agentic Retrieval-Augmented Generation (RAG) framework focused on maximizing token efficiency during both retrieval and reasoning phases for LLMs. This approach addresses redundant token consumption endemic in current agentic RAG architectures by compressing retrieved content, optimizing reasoning steps, and innovatively combining semantic and graph-based retrieval with efficient reward-driven learning protocols.
Motivation and Problem Analysis
Agentic RAG systems empower LLMs to autonomously plan, break down, and solve complex queries through multi-step retrieval and reasoning. However, extant agentic RAG implementations typically optimize for final accuracy, disregarding efficiency metrics such as total token usage. This results in excessive content retrieval (often entire document chunks with substantial irrelevant material) and redundant, overlong reasoning paths ("overthinking"), both of which incur significant computational and economic cost. In addition, reliance on outcome-based sparse reward signals during RL-based training further destabilizes optimization and impedes control over intermediate process efficiency.
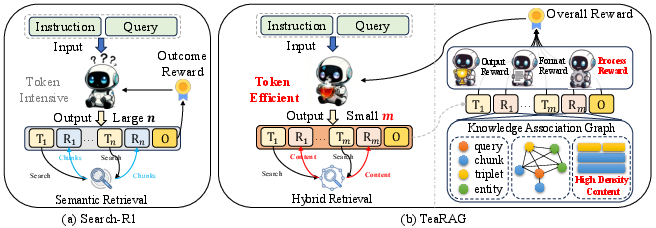
Figure 1: TeaRAG achieves higher token efficiency by compressing both retrieval content and reasoning steps via graph-based triplet retrieval and process-aware preference learning.
Framework Architecture and Pipeline
TeaRAG is realized as an agentic pipeline orchestrated by an LLM agent, encompassing five sequential modules:
- Important Entity Recognition: Identification of anchor entities guiding query decomposition and retrieval.
- Subquery Generation: Decomposition of the original task into entity-focused subproblems to promote targeted retrieval.
- Hybrid Context Retrieval: Parallel extraction of relevant content via (a) chunk-based semantic retrieval and (b) knowledge graph-driven triplet retrieval. A Knowledge Association Graph (KAG) is constructed over the union of these sources, integrating semantic similarity and co-occurrence signals.
- Token-Efficient Context Selection: KAG is filtered via Personalized PageRank (PPR), using a personalization vector and tradeoff parameter α to balance query relevance and graph topology, maximizing information density per retrieved token.
- Summary Generation and Termination: Iterative agentic rollouts are performed until a process-aware reward signal detects sufficient evidence accumulation, at which point the agent halts further reasoning and outputs the answer.
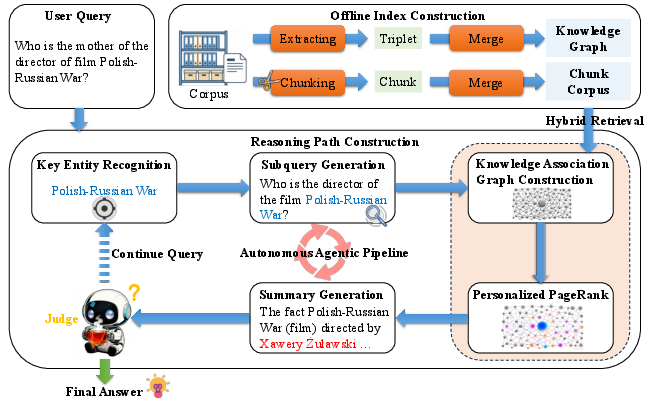
Figure 2: The TeaRAG pipeline interleaves LLM-driven entity recognition, subquery decomposition, hybrid chunk/triplet retrieval, and PPR-based content compression over a large-scale knowledge graph.
This workflow exploits complementary strengths of semantic chunks (contextual richness) and graph triplets (high factual density), leveraging co-occurrence as a robust filter for token-efficient evidence selection.
Process-Aware Learning via IP-DPO
The framework is trained in two distinct phases:
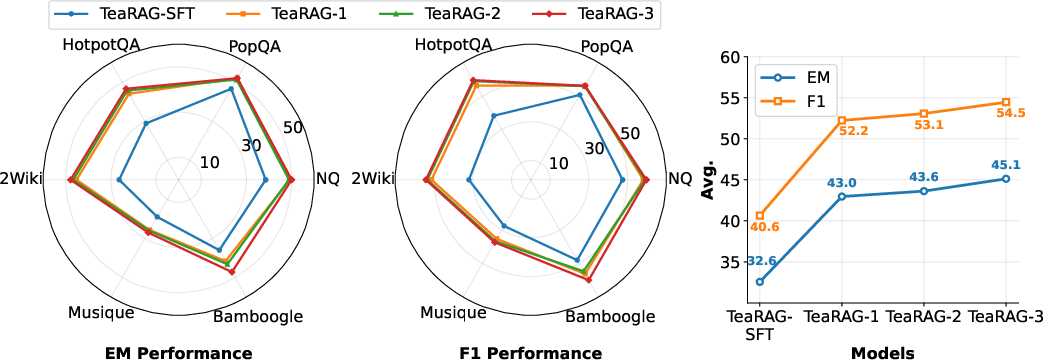
- Stage 1: Supervised Fine-Tuning (SFT): Leveraging multi-hop QA datasets (MuSiQue, HotpotQA, NQ), reasoning chains and ground-truth evidences are converted to natural language in a chain-of-thought format with aligned chunk/triplet context. SFT teaches the LLM agent to emulate agentic workflows and compositional reasoning.
- Stage 2: Iterative Process-aware Direct Preference Optimization (IP-DPO): To enforce token efficiency, process-aware rewards are crafted evaluating:
- Knowledge sufficiency (through memory vectors aggregating evidence coverage throughout reasoning steps)
- Format adherence
- Reasoning conciseness (steps required)
- Entity-subquery consistency
Preference pairs are constructed between ⟨chosen, rejected⟩ reasoning paths using outcome, format, and process rewards. DPO is performed iteratively, with each cycle resampling outputs using the latest model weights, progressively reinforcing concise and effective reasoning patterns while stabilizing alignment with ground-truth evidence distributions.
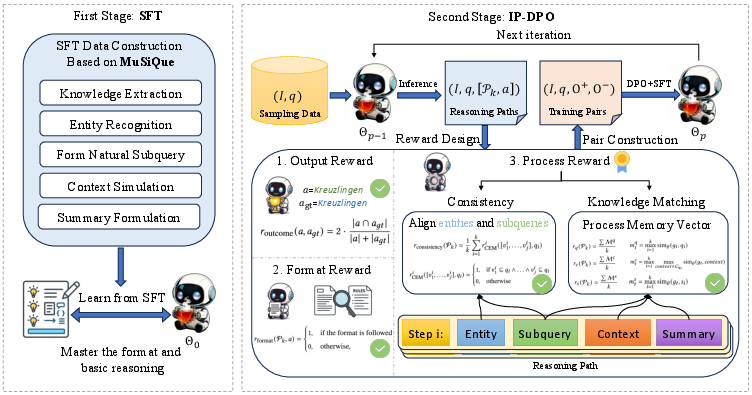
Figure 3: TeaRAG two-stage model training: initial SFT on structured multi-hop reasoning, followed by multi-round IP-DPO guided with process-aware rewards.
Empirical Evaluation
Experiments were conducted across six QA benchmarks (NQ, PopQA, HotpotQA, 2WikiMultiHopQA, MuSiQue, Bamboogle), using Llama3-8B and Qwen2.5-14B as backbone models. Baselines encompassed standard RAG, agentic RAG approaches (IRCoT, R1-Searcher, Search-R1), and hybrid retrieval variants.
Key findings:
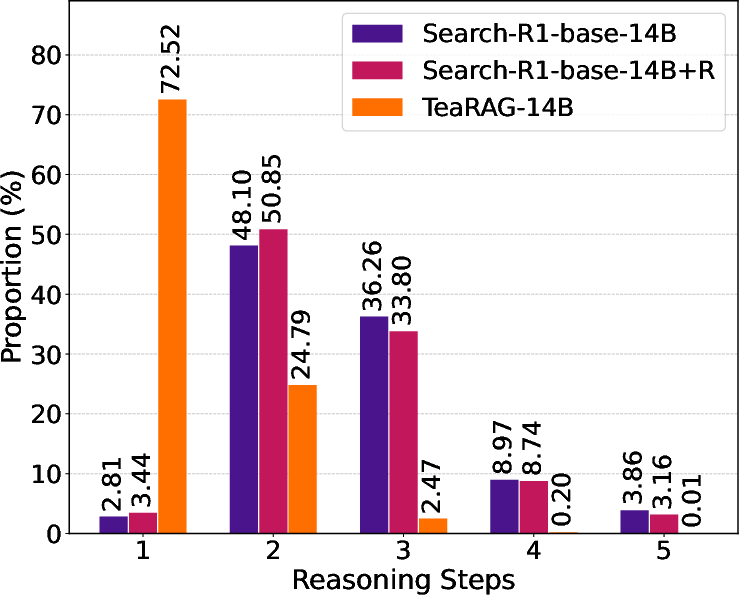
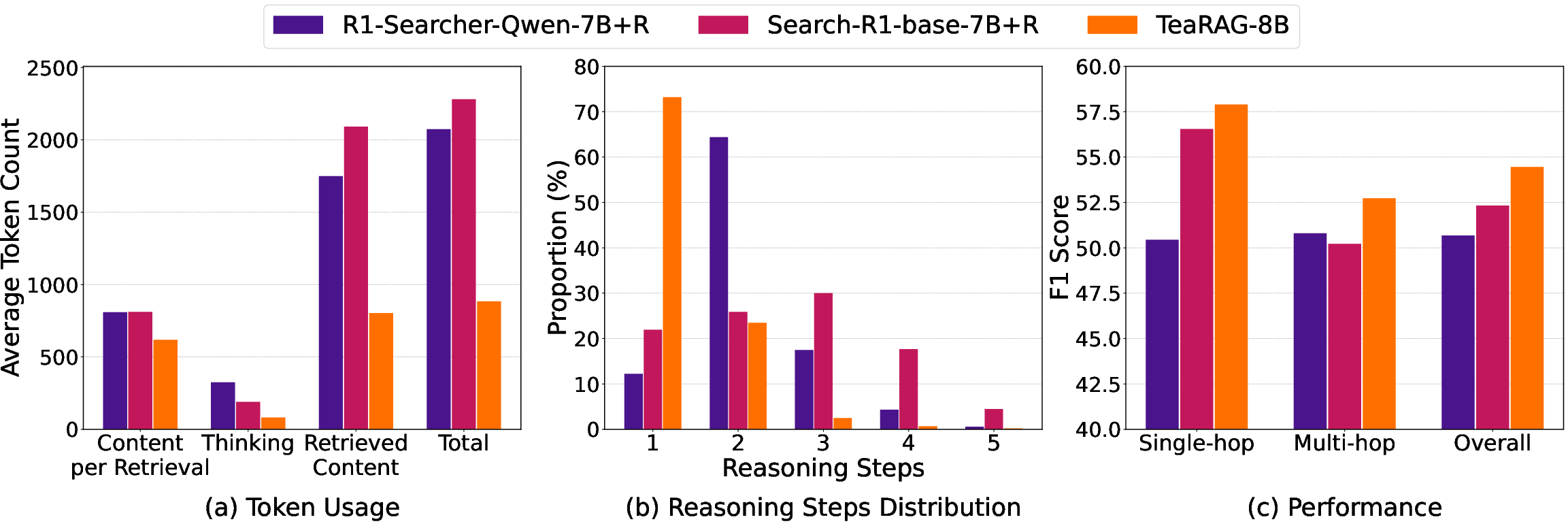
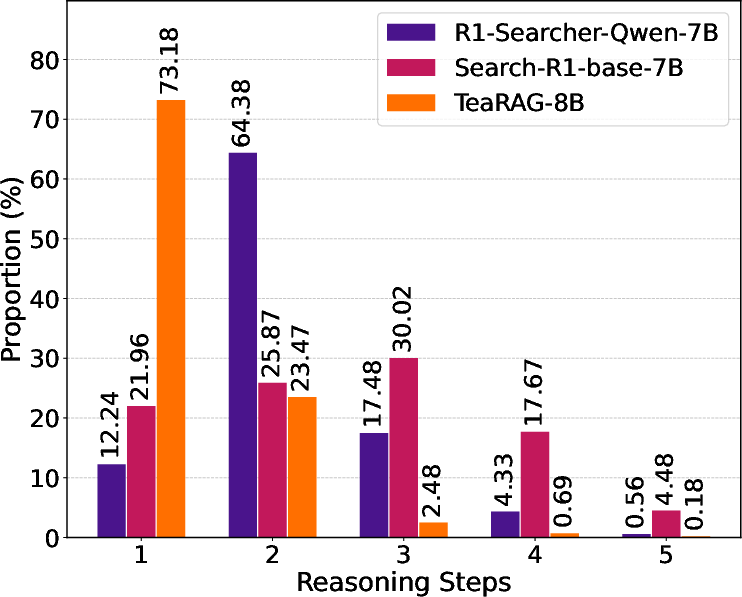
Figure 5: Comparing TeaRAG with baselines, TeaRAG produces shorter, more efficient reasoning paths across model scales.
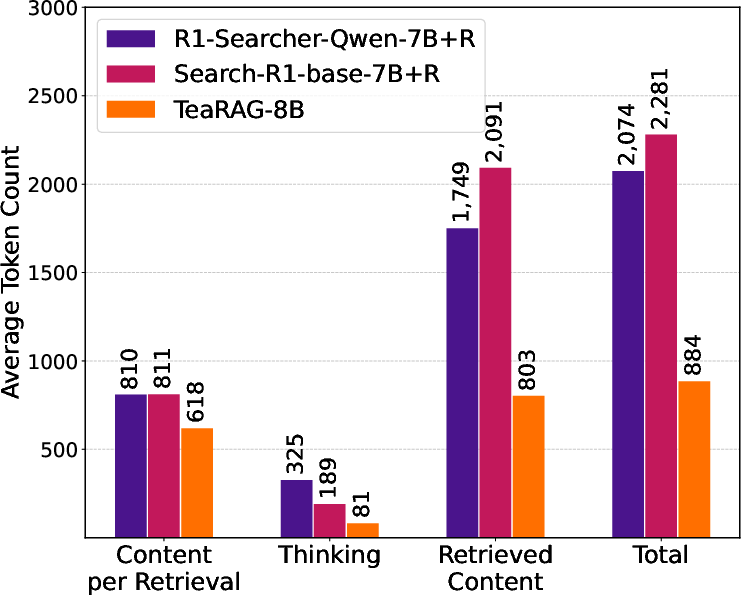
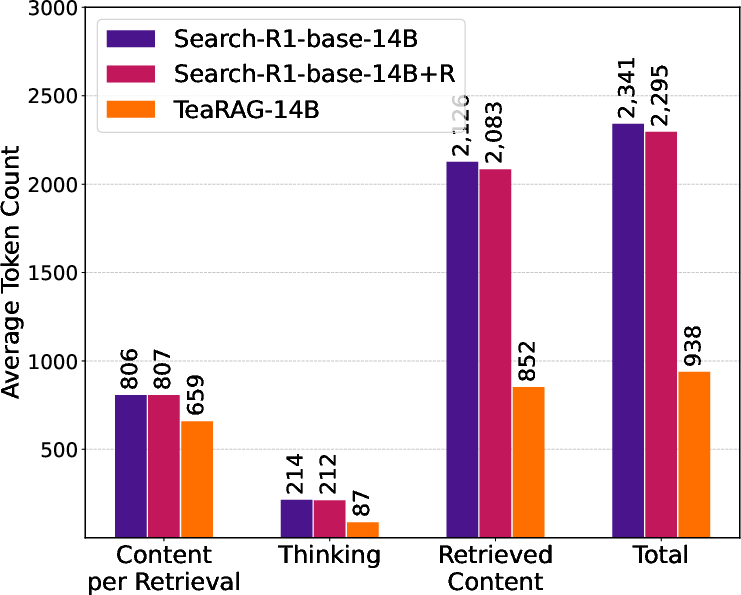
Figure 6: TeaRAG reduces overall output token usage and per-retrieval token count, confirming effectiveness of graph-based filtering.
Ablations and Analysis
Detailed ablations confirm:
Engineering and Deployment Considerations
- Computational Resources: TeaRAG’s training and inference runtimes are substantially lower than PPO-based RL baselines, with lower per-GPU memory profiles attributed to LoRA parameter-efficient finetuning and decoupled sample/train workflow.
- Graph Scale: Scalable KAG construction over millions of Wikipedia-derived entities and triplets is validated; PPR can be performed efficiently within practical inference pipelines.
- Domain Transferability: Out-of-domain generalization is strong, supporting cross-corpus and multi-hop QA transfer.
- Reproducibility: Codebase is open-sourced for full pipeline replication.
Future Directions
Future work can focus on extending KAG construction to dynamically update knowledge graphs under streaming corpora, incorporating more granular process supervision (e.g., cross-step causal alignment), generalizing to retrieval with multi-modal evidence sources, and further coupling token efficiency with fine-grained latency profiling for real-world production deployment (e.g., cloud LLMs with strict cost constraints).
Conclusion
TeaRAG establishes a robust foundation for scalable, process-efficient agentic RAG. By integrating hybrid, graph-enhanced retrieval with process-aware preference modeling, TeaRAG achieves state-of-the-art results in QA accuracy and token efficiency, advancing both the theoretical understanding and practical deployment of retrieval-augmented LLM systems.