Continual Harness: Online Adaptation for Self-Improving Foundation Agents
Abstract: Coding harnesses such as Claude Code and OpenHands wrap foundation models with tools, memory, and planning, but no equivalent exists for embodied agents' long-horizon partial-observability decision-making. We first report our Gemini Plays Pokemon (GPP) experiments. With iterative human-in-the-loop harness refinement, GPP became the first AI system to complete Pokemon Blue, Yellow Legacy on hard mode, and Crystal without a lost battle. In the hardest stages, the agent itself began iterating on its strategy through long-context memory, surfacing emergent self-improvement signals alongside human-in-the-loop refinement. Continual Harness removes the human fully from this loop: a reset-free self-improving harness for embodied agents that formalizes and automates what we observed. Starting from only a minimal environment interface, the agent alternates between acting and refining its own prompt, sub-agents, skills, and memory, drawing on any past trajectory data. Prompt-optimization methods require episode resets; Continual Harness adapts online within a single run. On Pokemon Red and Emerald across frontier models, Continual Harness starting from scratch substantially reduces button-press cost relative to the minimalist baseline and recovers a majority of the gap to a hand-engineered expert harness, with capability-dependent gains, despite starting from the same raw interface with no curated knowledge, no hand-crafted tools, and no domain scaffolding. We then close the loop with the model itself: an online process-reward co-learning loop, in which an open-source agent's rollouts through the refining harness are relabeled by a frontier teacher and used to update the model, drives sustained in-game milestone progress on Pokemon Red without resetting the environment between training iterations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1) What this paper is about (Overview)
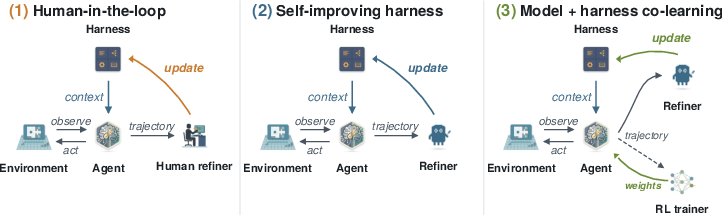
This paper is about teaching game-playing AIs to upgrade themselves while they are still playing, without restarting the game. The authors call their approach Continual Harness. Think of a “harness” like the AI’s toolbelt and playbook: instructions, helpful mini-programs, memories, and specialist helpers the AI can call on. The big idea is to let the AI automatically improve that toolbelt during one continuous run, so it gets smarter as it goes.
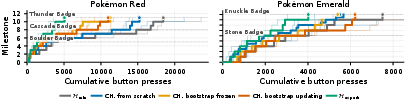
Before building this fully automatic system, the team first ran a project called Gemini Plays Pokémon (GPP). With humans guiding the harness updates between sessions, their AI became the first to finish multiple Pokémon role‑playing games (RPGs). They then removed the human from the loop, so the AI could refine its own harness by itself in real time.
2) What they wanted to find out (Key questions)
They set out to answer a few simple questions:
- Can an AI improve its own “toolbelt” (instructions, helpers, skills, and memory) while playing, without resetting the game?
- If yes, how close can this get to an expert, hand-crafted setup made by humans?
- Does this work depend on how capable the underlying AI model is?
- Can the same loop also train the model itself over time (not just its toolbelt), all while the game keeps going?
3) How it works (Methods and approach)
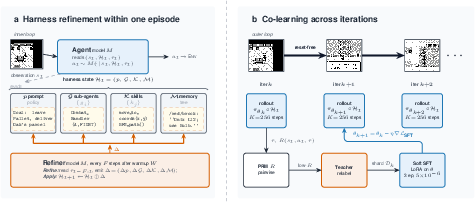
First, here’s what a harness is, in everyday language. It’s the layer around the AI that tells it how to act and gives it tools. The harness has four parts:
- System prompt: the AI’s core instructions and strategy notes (like its playbook).
- Sub‑agents: specialist helpers the AI can call, such as a “battle strategist” or “puzzle solver.”
- Skills: reusable tricks or tiny programs, like “walk to that door” or “press this button sequence.”
- Memory: a notebook that keeps facts, maps, and lessons learned for later.
The key trick is the Refiner, a role that acts like a coach and editor:
- While the AI plays, the Refiner looks at the recent history (what just happened), spots problems (getting stuck, looping in a hallway, making bad battle choices), and makes small edits to the harness.
- These edits can create new skills, fix broken ones, update instructions, add useful notes to memory, or even retire helpers that aren’t useful.
- All of this happens without resetting the game. The AI keeps playing with an updated toolbelt, improving mid‑run.
They also tested a “co‑learning” loop to train the model itself:
- A judge scores the AI’s behavior step by step (a “process reward,” like a referee giving points for good moves).
- Where the AI does poorly, a stronger “teacher” model shows better actions.
- The student model then trains on those improved examples and keeps playing from the same in‑game spot (still no resets).
4) What they found (Main results and why they matter)
Here are the main outcomes the paper reports:
- Human‑guided success first: With humans helping refine the harness (GPP), the AI finished Pokémon Blue, Pokémon Yellow (hard mode), and Pokémon Crystal. This proved that improving the harness over time really helps on long games.
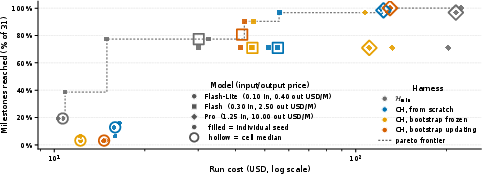
- Fully automatic self‑improvement works: The new Continual Harness (no human in the loop) reduced the number of button presses needed to reach goals in Pokémon Red and Emerald compared to a bare‑bones setup. It recovered most of the gap to a hand-made expert system, even though it started with no special Pokémon knowledge or tools.
- It depends on model strength: Stronger models benefited a lot. Mid‑strength models helped sometimes. Very small models didn’t benefit and sometimes did worse—there’s a “capability floor” below which the AI doesn’t use the toolbelt well enough to improve.
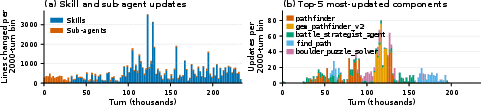
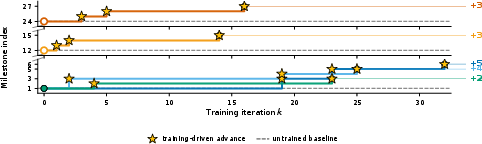
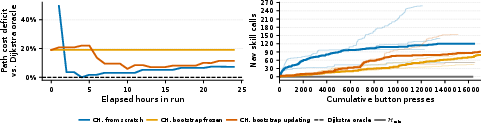
- Skills got better during play: For example, the AI’s pathfinding skills (how it navigates around obstacles) improved toward the best‑known routes over time, inside a single continuous run.
- The model itself can improve online: Using the co‑learning loop, an open‑source model made steady, real in‑game progress across training iterations without ever resetting the game. In other words, its “brain” and its “toolbelt” improved together, live.
Why this matters: Most real tasks—like robotics, operations, or long coding sessions—don’t allow easy resets. An AI that can notice its mistakes, update its tools, and learn while the task continues is more practical and powerful.
5) Why this is important (Implications and impact)
- Reset‑free learning: The AI can fix itself mid‑task instead of starting over. That’s closer to how humans improve in real life—learn, adjust, and keep going.
- Less hand‑crafting: Instead of humans building lots of custom tools up front, the AI can discover, write, and refine its own helpers and skills as needed.
- General idea beyond games: Although shown in Pokémon, the same approach could help coding agents, robots, customer support bots, or any long, multi‑step job where restarts are costly.
- Capability threshold: The method works best when the base model is strong enough to use and improve its toolbelt. Future work can raise weaker models up to that level or pair them with better teachers.
- Co‑learning future: Training the model and updating the harness at the same time looks promising. The authors saw steady progress, and there’s room to push further—more tasks, longer runs, and richer tools.
In short, this paper shows a practical path to self‑improving agents: let them carry a toolbelt, let them upgrade that toolbelt continuously while working, and let their “brains” learn from those live experiences—all without hitting the reset button.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list enumerates what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future research:
- Generalization beyond the Pokémon domain: verify Continual Harness on other embodied tasks (e.g., 3D navigation, continuous control, robotics, sandbox games) to assess portability of the refinement loop and meta-tooling.
- Reliance on privileged state via the ASCII text map: quantify how much the text map (derived from emulator memory) contributes; evaluate purely pixel-only agents, alternative state encoders, and robustness when the text map is noisy, partial, or absent.
- Full-game completion under automated Continual Harness: demonstrate end-to-end completions (not just early milestones) on Red/Emerald with the automated refiner, including late-game, dialogue-heavy, and multi-turn battle segments.
- Head-to-head comparison with reset-based optimization: directly compare reset-free Continual Harness with episode-reset prompt/harness optimization on the same tasks for sample efficiency, wall-clock time, and final performance.
- Refinement stability and convergence: characterize whether harness edits (prompt, sub-agents, skills, memory) converge or oscillate; design and evaluate rollback/guardrail mechanisms to prevent catastrophic edits and regressions.
- Failure-signature detection formalization: specify, implement, and benchmark the algorithm that detects navigation loops, tool-call failures, stalled objectives, and missed exploration, including precision/recall and latency trade-offs.
- Component-wise ablations beyond navigation: quantify contributions of prompt rewrites, sub-agent CRUD, memory edits, and executable skill repairs separately (as done for pathfinding), including cross-component interactions.
- Dialogue-heavy objectives and multi-turn battle strategy: develop and evaluate methods that reliably synthesize these components (e.g., dialogue parsing, hint extraction, battle policy induction) and measure their impact on gym interiors and elite battles.
- Hyperparameter sensitivity: study the effect of refinement frequency F, warm-up W, trajectory window length, and CRUD thresholds on performance, stability, and cost.
- Non-stationarity induced by in-episode edits: analyze the learning dynamics when the harness changes mid-trajectory; explore theoretical guarantees (e.g., online learning/regret bounds) and practical mitigations.
- Agent–Refiner role sharing: assess whether using the same model for both roles impairs performance; compare to specialized refiners (smaller model, rule-based, or separate architecture) and multi-model orchestration.
- Capability floor characterization: precisely define the minimum model capability needed for Continual Harness to yield gains; test whether co-learning can lift sub-threshold models (e.g., Flash-Lite) above the floor.
- Process-reward model (PRM) design and calibration: detail component weights, validation metrics, and reliability of pairwise scoring; ablate PRM variants and study sensitivity to reward shaping.
- Teacher dependence in co-learning: reduce reliance on a frontier teacher (Gemini 3.1 Pro) by testing open-source teachers, ensembling, confidence-filtering, or teacher-free relabeling (self-critique, verification).
- Co-learning sample efficiency and scaling: measure token/step efficiency (e.g., improvement per 1k steps), compare DAgger+PRM to offline RL or standard SFT/RLHF, and study scaling with K, iteration count, and batch size.
- Reset-free vs reset-based training regimes: run a controlled comparison where the same model, harness, and PRM are trained with and without environment resets to isolate regime-specific benefits.
- Memory management policies: evaluate memory growth, retrieval quality, deduplication, aging/importance demotion, and forgetting; design metrics and algorithms for preventing stale or noisy memories from harming behavior.
- Cost, time, and compute reporting: standardize and expand cost metrics beyond API spend (e.g., wall-clock, energy, tool-call frequency), include statistical significance tests, and increase seed counts for robust comparisons.
- Robustness to environment stochasticity: test with randomized maps, NPC randomness, and altered game mechanics to assess robustness/generalization under distribution shift.
- Safety and security of meta-tools (run_code, define_agent): specify sandboxing, resource limits, injection defenses, and rollback protocols; test adversarial prompts and code to identify vulnerabilities.
- Tooling correctness and verification: add automated tests for newly authored skills/sub-agents (unit tests, property checks) and measure how verification affects reliability and edit acceptance rates.
- Transfer and reuse of refined harnesses: study cross-game, cross-environment, and cross-model transfer of harness components; measure zero-shot and few-shot reuse benefits.
- Comparative baselines: include RL/planning agents (e.g., Voyager, ReAct variants, expert planners) and prompt-optimization systems (GEPA, Meta-Harness) in unified evaluations on the same milestones.
- Late-game battle evaluation: develop standardized, reproducible battle benchmarks (type coverage, status effects, inventory management) and quantify harness-driven improvements.
- Edit governance and provenance: track, attribute, and audit CRUD edits (who/what/when) to enable reproducibility and post-hoc analysis; release edit logs and trajectories for the community.
- Theoretical framing of co-learning: formalize the coupled dynamics of model weights and harness state, including credit assignment and identifiability, and explore conditions for stability or monotonic improvement.
- Open-source model limits: identify which Gemma-4 configurations succeed or fail and why; test larger/different architectures and investigate whether architecture changes (MoE vs dense) affect co-learning efficacy.
- Ethical, licensing, and data-release considerations: clarify the legality and ethics of using frontier outputs for training open-source models; release code, harness state diffs, and PRM specifications to enable independent replication.
Practical Applications
Immediate Applications
The paper’s methods enable reset-free, in-episode self-improvement of agent scaffolding (prompt, sub-agents, skills, memory) and an online co-learning loop with process rewards. These capabilities can be deployed today in software and simulated environments where observability is available and actions can be sandboxed.
- AI game QA and playtesting automation (sector: gaming)
- What: Self-refining test agents that learn new “test skills” mid-run (e.g., puzzle solvers, route checkers) to discover regressions, softlocks, and balance issues in long-horizon games without resetting save files.
- Workflow/product: “Continual Game Tester” harness that ingests build telemetry (the “text map” analog), periodically runs a Refiner pass, and logs CRUD diffs to harness components; PRM-based triage of failure windows.
- Assumptions/dependencies: Access to emulator/instrumented builds to derive structured state; guardrails for tool calls; capable frontier/model tier (capability floor).
- Self-improving RPA for complex GUI workflows (sector: software/enterprise)
- What: Desktop/web automations (claims entry, reconciliation, configuration wizards) that adapt their prompts, macros, and sub-agents mid-session instead of restarting when encountering novel screens or errors.
- Workflow/product: “Continual Desktop Autopilot” integrating with Win32/UIA/Selenium; Refiner runs every F steps to repair brittle selectors and generate reusable skills; memory stores per-app playbooks.
- Assumptions/dependencies: Stable UI observability (DOM/UIA), safe sandboxing for code execution (run_code), change-management for self-edits, approval gates for high-impact actions.
- SRE/DevOps incident co-pilot with live runbook refinement (sector: software/ops)
- What: Incident bots that alternate between actions (e.g., kubectl, Terraform plans) and runbook updates mid-incident; PRM scores from run health (error rates, saturation) prioritize refactoring weak steps.
- Workflow/product: “Continuous Runbook Refiner” for PagerDuty/Datadog/Kubernetes; DAgger+PRM loop where low-reward windows are relabeled by a human senior/teacher model, with soft SFT updates to the incident agent.
- Assumptions/dependencies: Fine-grained observability, strict RBAC and human-approval checkpoints, audit trails for CRUD diffs, mature rollback.
- Customer support copilot that adapts mid-conversation (sector: customer service)
- What: Agents that refine prompts, escalation criteria, and tool-use skills based on conversation trajectory, reducing loops and improving first-contact resolution without resetting threads.
- Workflow/product: “Continual CX Harness” with sub-agents for billing/tech triage, memory of customer context, PRMs from CSAT/QA rubrics; teacher relabel from gold transcripts.
- Assumptions/dependencies: Safety filters, compliance templates, high-quality labeling rubric for PRM, PII handling.
- Coding agent auto-refiner plugin for existing harnesses (sector: software engineering)
- What: Add a Refiner to Claude Code/OpenHands-like agents to periodically edit the system prompt, project-specific skills (scripts, devtools wrappers), and persistent memory over long coding sessions.
- Workflow/product: “HarnessRefiner” SDK that plugs into agent frameworks, triggers edits based on failure signatures (failing tests, build errors), and uses PRM from unit/integration test outcomes.
- Assumptions/dependencies: Sandboxed execution, reliable test signal, repository/write permissions governance, model capability sufficient to benefit from added structure.
- Open-source model improvement via reset-free DAgger+PRM (sector: ML engineering/academia)
- What: Train small/OS models by rolling them inside a live-refining harness, relabel low-reward windows with a teacher (frontier or human), and apply soft SFT—improving performance without environment resets.
- Workflow/product: “Co-Learning Trainer” pipeline (batch size = 1) for language agents; supports iterative checkpoints and replay of persistent environment state.
- Assumptions/dependencies: Teacher availability/cost, robust PRM design, deterministic resume of environment state, data governance for generated trajectories.
- Simulation-based operator training with evolving playbooks (sector: safety-critical training)
- What: In simulators (grid ops, plant control, airside operations), agents refine procedures mid-scenario to surface failure modes and alternative playbooks, aiding human trainees.
- Workflow/product: “Playbook Explorer” that records CRUD diffs and explains refinements; PRM tied to safety and KPI thresholds.
- Assumptions/dependencies: High-fidelity simulation with structured telemetry; human oversight; policy-compliant use of AI suggestions.
- Research testbed for reset-free adaptation and memory management (sector: academia)
- What: A standardized platform to study in-context, mid-episode edits across prompt/sub-agents/skills/memory and their learning dynamics without resets.
- Workflow/product: Open “Continual Harness SDK” + benchmark suites (navigation, multi-step puzzles) with logging for diffs and ablations.
- Assumptions/dependencies: Community datasets, clear evaluation metrics (e.g., button-press cost analogs), reproducible seeds.
- Process reward model authoring and evaluation tools (sector: ML tooling)
- What: Tooling to define, visualize, and tune PRMs from process telemetry (logs, traces, partial objectives) that drive in-loop refinement.
- Workflow/product: “PRM Studio” with declarative reward specs, windowed scoring, and label-budget allocation for teacher relabeling.
- Assumptions/dependencies: Access to high-signal telemetry; domain-rubric design; budget for teacher labels.
- Harness governance and observability (sector: compliance/tooling)
- What: Versioning, diffing, and policy enforcement for self-modifying agents; alerts for risky edits; rollback to last known-good harness state.
- Workflow/product: “HarnessOps” with CRUD audit logs, policy-as-code for allowed edits, and review workflows.
- Assumptions/dependencies: Integration with org IAM/policy systems; clear edit-safety taxonomy; reproducible state snapshots.
- Personal productivity assistants that evolve workflows (sector: daily life/software)
- What: Desktop/email/task agents that create and refine personal scripts and heuristics during a session (e.g., smarter batching rules), without losing progress.
- Workflow/product: “Continual Personal Copilot” with editable memory and user-approved skill creation; PRM proxy from user corrections and time saved.
- Assumptions/dependencies: User consent for memory storage, strong sandboxing, lightweight observability signals.
Long-Term Applications
These require further research, scaling, or domain integration—especially robust perception/actuation, safety assurances, and high-capability models. They map the paper’s reset-free self-improvement and co-learning to physical and high-stakes environments.
- Warehouse and logistics robots with in-mission skill refinement (sector: robotics)
- What: Mobile manipulators that add/repair navigation and handling skills mid-shift from trajectory failures (e.g., occlusions, pallet variance) instead of returning to a training bay.
- Potential workflow/products: Onboard Refiner with CRUD to task prompts, local skills (grasp heuristics), and map memory; PRM from task completion, path cost, safety margins; teacher relabel in simulation.
- Assumptions/dependencies: Reliable perception-to-“text map” abstraction, safety cages/guards, certification of self-edits, robust fallbacks.
- Home service robots that personalize routines without resets (sector: consumer robotics)
- What: Devices that learn household-specific navigation and task recipes on the fly and persist them across days.
- Tools/workflows: Continual memory of home layout and user preferences; PRM from task success and user feedback; periodic human-in-the-loop review.
- Assumptions/dependencies: Privacy-preserving memory, user consent, strong safety constraints, local execution.
- Autonomous drones for inspection and SAR with online playbook construction (sector: robotics/energy/public safety)
- What: Drones that adapt search patterns, sensor-fusion skills, and failover procedures mid-flight as conditions change.
- Tools/workflows: Tightly bounded Refiner cadence, PRM from coverage metrics and detection reliability, geofencing and no-fly policy enforcement.
- Assumptions/dependencies: Regulatory approvals, robust telemetry, weather/comm loss resilience, certified autonomy stack.
- Industrial process control and chemical plant ops assistants (sector: manufacturing/energy)
- What: Control-room copilots that refine alarm triage and mitigation steps mid-incident using process rewards tied to stability and safety constraints.
- Tools/workflows: PRM from constraint violations, rate-of-change limits, and recovery time; co-learning in a digital twin before staged deployment.
- Assumptions/dependencies: High-fidelity twins, strict approval workflows, ISA/IEC safety standards compliance.
- Power grid operations planning with reset-free scenario adaptation (sector: energy)
- What: Planning agents that iteratively refine contingency playbooks during live scenarios (e.g., N-1 outages) rather than restarting studies.
- Tools/workflows: PRM from reliability indices (SAIDI/SAIFI), congestion costs; co-learning across sequential events; harness diffs audited by operators.
- Assumptions/dependencies: Secure SCADA/EMS integration, regulatory oversight, cyber-safe tool execution, explainability.
- Clinical administrative automation and, later, decision support (sector: healthcare)
- What: Start with prior-auth and documentation agents that refine templates and tool use mid-case; long-term, carefully supervised protocol adaptation assistants in clinics.
- Tools/workflows: PRM from denial rates, turnaround time, documentation completeness; gated teacher relabel by clinicians; memory scoped per patient/episode.
- Assumptions/dependencies: HIPAA/GDPR compliance, rigorous validation, clear liability boundaries; for decision support, FDA/EMA regulatory approvals.
- Autonomy in vehicles with simulation-first co-learning (sector: automotive)
- What: Offline/live simulation agents that refine planning prompts/sub-agents across long scenarios without resets, then transfer to on-road under shadow mode.
- Tools/workflows: PRM from safety envelopes and comfort metrics; teacher relabel from human driver traces; staged deployment with strict disengagement policies.
- Assumptions/dependencies: Highly capable models, robust perception abstraction, certification pathways, formal safety cases.
- Financial operations and risk-response copilots (sector: finance)
- What: Agents that adapt fraud triage, settlement exception handling, and reconciliation playbooks mid-incident with auditability.
- Tools/workflows: PRM from loss avoidance, latency, false-positive rates; HarnessOps governance with immutable diffs.
- Assumptions/dependencies: Regulatory compliance (SOX/GLBA), segregation of duties, strict approval workflows, thorough logging.
- Cybersecurity SOC assistants with evolving detection/response (sector: security/policy)
- What: SOC agents that refine detection heuristics and response runbooks during live incidents using process rewards derived from containment progress.
- Tools/workflows: Co-learning with red-team/teacher relabel; memory of TTPs; policy guards for irreversible actions.
- Assumptions/dependencies: Strong isolation, forensics-grade logging, human-in-the-loop for high-impact steps, adversarial robustness.
- Longitudinal personalized education (sector: education)
- What: Tutors that refine scaffolding, sub-skills, and memory across months without “resetting” a student’s context, using process rewards from mastery trajectories.
- Tools/workflows: Curriculum co-learning with teacher relabel on low-reward segments; transparent harness diffs for educators.
- Assumptions/dependencies: Privacy and data minimization, bias/equity audits, educator oversight, calibrated evaluations.
- Policy and governance frameworks for self-modifying agents (sector: policy)
- What: Standards and audits for mid-episode self-edits (prompts/skills/memory) in operational AI systems, including change control and rollback.
- Tools/workflows: Certification regimes for Refiner cadence and scope, mandatory HarnessOps logs, PRM transparency requirements.
- Assumptions/dependencies: Cross-industry consensus, regulator capacity to evaluate process rewards and edit safety, incident reporting norms.
Cross-cutting assumptions and dependencies observed in the paper
- Capability floor: Gains depend on model competence; weak models can underperform minimal baselines (as with Flash-Lite).
- Observability layer: Success relied on an engineered “text map”; real deployments need structured telemetry/APIs that expose environment state at the right level of abstraction.
- Safety and governance: Self-edits require audit trails, approval gates, RBAC, and rollback; high-stakes domains demand strict oversight.
- Cost/latency: PRM scoring and teacher relabels add compute and monetary cost; careful budget and cadence design are needed.
- Reset-free statefulness: Best suited to domains where resets are costly/unavailable and state can persist across iterations.
- Data privacy and compliance: Memory and trajectory logs must respect privacy/regulatory constraints.
Glossary
- A pathfinding: A heuristic graph-search algorithm that finds cost-efficient paths; used here as an expert navigation baseline/tool. "A pathfinding, type chart, damage calculator, and curated objectives."
- Ablated: An experimental practice of systematically varying or removing components to assess their contributions. "ablated across Gemini 3.1 Pro, Flash, and Flash-Lite"
- Agentic harness: The scaffolding layer that wraps a foundation model with tools, memory, and planning to mediate its interaction with an environment. "Agentic harnesses, the scaffolding that wraps a foundation model with tools, memory, and planning, are now standard infrastructure for autonomous coding agents."
- Co-learning: Jointly improving the model and its surrounding harness using the same online data stream. "Both loops operate on the same trajectory data; together they produce continual model-harness co-learning."
- CRUD: The set of Create, Read, Update, Delete operations used to iteratively edit components of the harness. "applying CRUD edits to system prompt, sub-agents, skills, and memories."
- DAgger: An imitation learning algorithm (Dataset Aggregation) that collects learner trajectories and relabels them with expert guidance to improve policy. "Each training iteration is a -step DAgger~\citep{ross2011reduction,karten2026smallexperts} rollout through the full Continual Harness"
- Dijkstra oracle: Using Dijkstra’s shortest-path algorithm as an idealized reference to score or compare learned navigation skills. "We score refined navigation skills by their path cost relative to a Dijkstra oracle."
- Embodied agent: An agent that perceives and acts in a situated environment through sensory inputs and discrete actions. "We consider an embodied agent that interacts with its environment through a minimal interface."
- Frontier model: A state-of-the-art, highest-capability model used as performer or teacher in evaluation/training. "On Pok\ne mon Red and Emerald across frontier models, Continual Harness starting from scratch substantially reduces button-press cost"
- GEPA: A reflective prompt-evolution method that optimizes prompts between episodes. "prompt-optimization methods such as GEPA~\citep{agrawal2025gepa} that run complete episodes and reset between updates"
- GRPO: Group Relative Policy Optimization, a reinforcement learning objective used here in an offline stage with process rewards. "an offline GRPO stage on a per-step process reward"
- In-context learning: Adapting behavior by leveraging context (prompts, memory, tools) rather than updating model weights. "through online in-context learning over the harness state"
- Meta-harness: A harness variant that equips the model with meta-level tools so it can construct its own sub-agents, skills, and memory during play. "A meta-harness gives the model meta-tools (define_agent, run_code, etc.) to construct its own sub-agents, skills, and memory entries during play"
- Meta-tools: System-level operations (e.g., define agents, run code, edit memory) that enable live editing of the harness components. "the harness exposes a fixed set of meta-tools (define_agent, run_code, process_memory, and similar primitives)"
- Pareto-dominant: Strictly better on at least one objective without being worse on any others in multi-objective comparisons. "Continual Harness is strictly Pareto-dominant on Pro"
- Pareto frontier: The set of non-dominated trade-offs in multi-objective evaluation (e.g., cost vs. completion). "Dashed staircase: cost-monotone Pareto frontier."
- Partially observable: An environment property where the agent lacks access to full state information, seeing only observations. "The environment is partially observable since the agent cannot access internal state"
- Process reward model (PRM): A model that assigns dense scores to intermediate steps of a trajectory to guide learning. "A pairwise process reward model (PRM) scores each transition"
- Refiner: The role/module that reads recent trajectory windows to edit and improve the harness mid-episode. "Every steps, a Refiner reads the recent trajectory for failure signatures"
- Reset-free: A training or adaptation regime that continues within a single ongoing episode without environment resets. "a reset-free framework that automates the manual harness refinement of GPP"
- Rollout: A sequence of environment interactions generated by a policy during evaluation or training. "Each training iteration is a -step DAgger~\citep{ross2011reduction,karten2026smallexperts} rollout through the full Continual Harness"
- Supervised fine-tuning (SFT): Updating model weights using labeled data (e.g., expert trajectories or relabeled steps). "The model is first primed by supervised fine-tuning on frontier Continual Harness trajectories"
- Soft SFT: A tempered or weighted form of SFT update, often blending targets or using lower update strength. "and a soft SFT update on the relabeled shard produces "
- Sub-agents: Specialized modules invoked by the orchestrator to handle particular tasks (e.g., battle strategy, navigation). "Sub-agents : specialized modules that can be invoked by the orchestrator for specific tasks"
- Vision-LLM (VLM): A multimodal model that processes both visual inputs and text. "Because vision-LLMs have known difficulties with fine-grained spatial reasoning over pixel grids"
Collections
Sign up for free to add this paper to one or more collections.