Hyperagents
Abstract: Self-improving AI systems aim to reduce reliance on human engineering by learning to improve their own learning and problem-solving processes. Existing approaches to self-improvement rely on fixed, handcrafted meta-level mechanisms, fundamentally limiting how fast such systems can improve. The Darwin Gödel Machine (DGM) demonstrates open-ended self-improvement in coding by repeatedly generating and evaluating self-modified variants. Because both evaluation and self-modification are coding tasks, gains in coding ability can translate into gains in self-improvement ability. However, this alignment does not generally hold beyond coding domains. We introduce \textbf{hyperagents}, self-referential agents that integrate a task agent (which solves the target task) and a meta agent (which modifies itself and the task agent) into a single editable program. Crucially, the meta-level modification procedure is itself editable, enabling metacognitive self-modification, improving not only the task-solving behavior, but also the mechanism that generates future improvements. We instantiate this framework by extending DGM to create DGM-Hyperagents (DGM-H), eliminating the assumption of domain-specific alignment between task performance and self-modification skill to potentially support self-accelerating progress on any computable task. Across diverse domains, the DGM-H improves performance over time and outperforms baselines without self-improvement or open-ended exploration, as well as prior self-improving systems. Furthermore, the DGM-H improves the process by which it generates new agents (e.g., persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs. DGM-Hyperagents offer a glimpse of open-ended AI systems that do not merely search for better solutions, but continually improve their search for how to improve.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Read Summary of the Paper
What’s this paper about?
This paper is about building AI programs that can improve themselves over time—not just at doing tasks, but also at getting better at the way they improve. The authors introduce “hyperagents,” a kind of AI that can rewrite both its “how to do the task” part and its “how to improve myself” part. They show this works across different kinds of tasks, not just computer coding.
The Main Idea in Simple Terms
- Imagine a student who can study math problems. Now imagine that same student can also rewrite their own study plan, their note-taking habits, and even how they choose what to practice next. That’s the idea behind a hyperagent: it’s a program that can change both its skills and the method it uses to get better.
Previously, a system called the Darwin Gödel Machine (DGM) could improve a coding agent by trying lots of self-edits and keeping the good ones. But DGM had a fixed “rulebook” for how to improve, and that rulebook couldn’t be changed. This paper extends that idea with DGM-Hyperagents (DGM-H), where the “rulebook” itself can be rewritten by the AI.
What questions are they trying to answer?
Here are the goals, explained simply:
- Can an AI improve not only at tasks (like coding or reviewing papers) but also improve the process it uses to get better in the future?
- Can these “how to improve” tricks learned in one area (say, robotics) help the AI improve faster in a completely different area (like grading math solutions)?
- Do we really need both constant exploration (trying many versions) and self-improvement to see steady progress?
- Can this work safely and reliably across very different tasks?
How does their approach work?
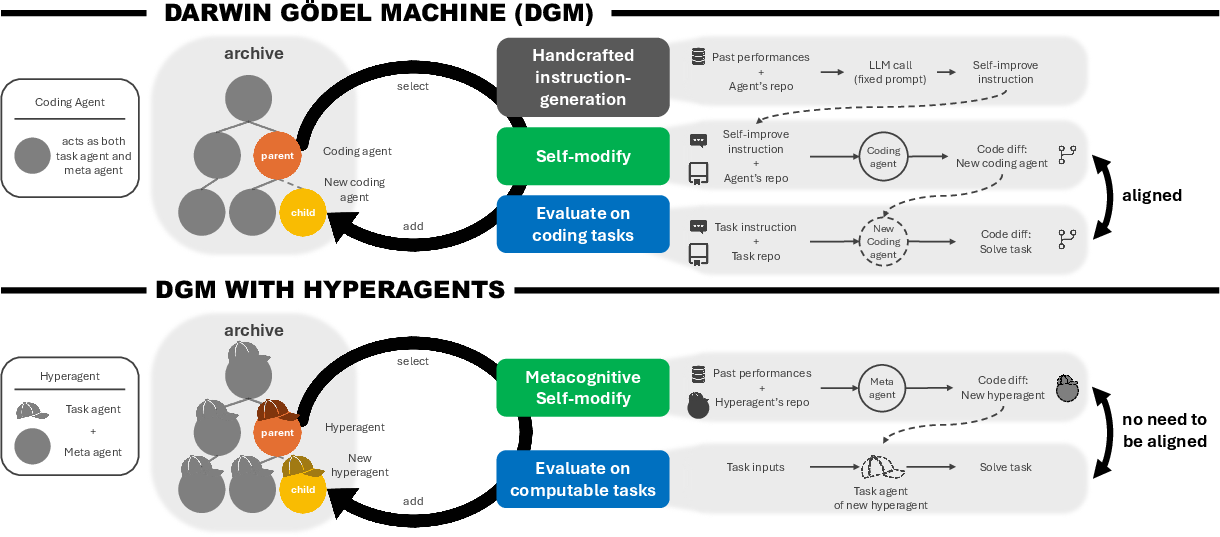
Think of the AI as two parts living inside one program:
- The “task agent” is the worker that tries to solve the problem (write code, review a paper, design a robot’s reward).
- The “meta agent” is the coach that changes the worker and even changes itself—like a coach who can redesign their own training plan.
The “hyperagent” combines both into one editable program. It runs in cycles:
- Try self-changes: The hyperagent edits its own code or instructions. This is like a student revising both their problem-solving steps and their study strategy.
- Test the new version: It runs tasks to see if the new version is better.
- Keep an archive: Every version is saved in a big “gallery” of past attempts, so future versions can build on different “stepping stones,” not just the latest one. This prevents getting stuck on one path.
To start, the authors give the hyperagent a very simple setup: a LLM that can use two tools (run shell commands and edit files). From there, the hyperagent must improve itself.
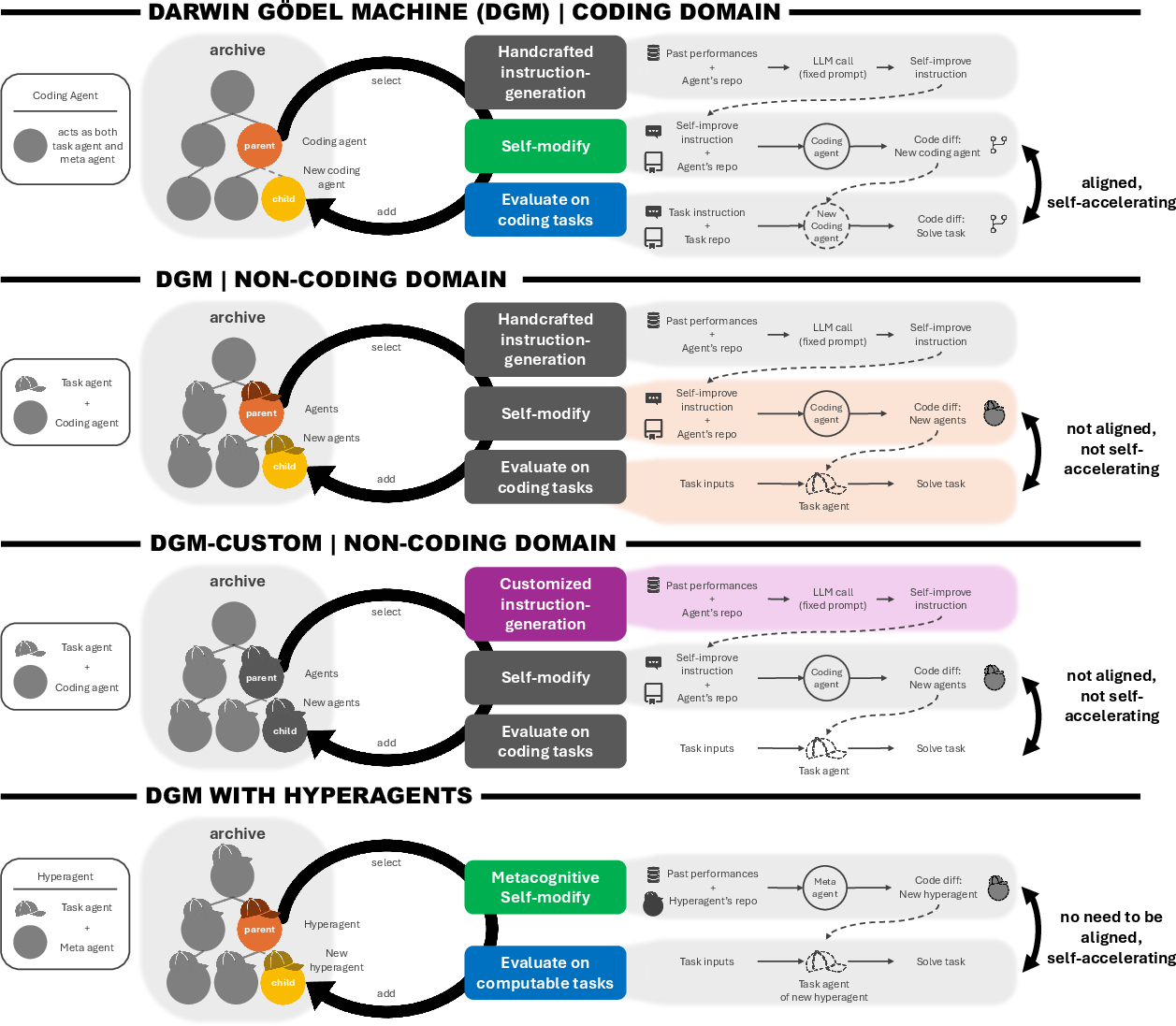
They compare DGM-H to:
- The original DGM (with a fixed improvement rulebook).
- A version without self-improvement (the coach can’t change).
- A version without open-ended exploration (no archive; each new version replaces the last).
- A hand-tuned version of DGM customized by people for each domain.
They test across four areas:
- Coding (editing code to meet instructions).
- Paper review (predict accept/reject decisions).
- Robotics reward design (write a reward function that teaches a robot to move as desired).
- Olympiad-level math grading (grade solutions like a fair human judge would).
Key analogy:
- Open-ended exploration = trying many different approaches and keeping a library of them.
- Metacognitive self-modification = the AI improves its own way of improving, like a student upgrading their study habits, tracking progress, and adding memory tools.
What did they find, and why does it matter?
Here are the main results in plain language:
- It improves at tasks over time:
- Coding: DGM-H gets better at a well-known coding benchmark, reaching gains similar to the classic DGM—even though DGM-H wasn’t tailor-made for coding.
- Paper review: Starting from almost zero, DGM-H learned to predict accept/reject decisions much better than simple baselines and even beat a strong public reviewer agent in several runs.
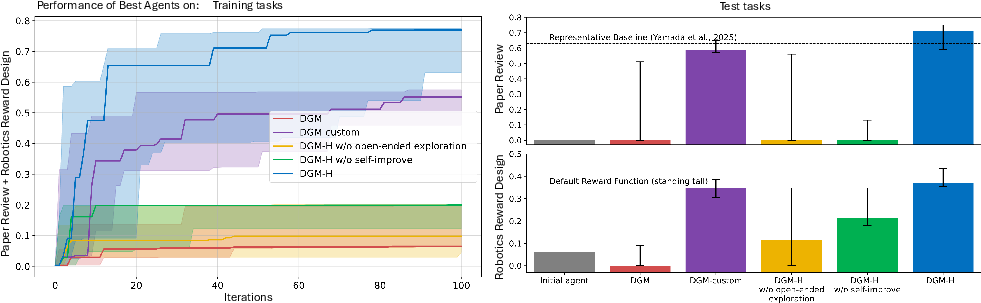
- Robotics reward design: DGM-H learned to write better reward functions for training a robot. It often discovered smarter strategies (like rewarding jumping when the goal is to maximize torso height) instead of getting stuck on simpler ideas (like just standing tall).
- It improves the way it improves:
- DGM-H didn’t just tweak task prompts; it developed better “coach” behaviors over time—like adding persistent memory, tracking which ideas worked, and building structured decision checklists. These are improvements to the improvement process itself.
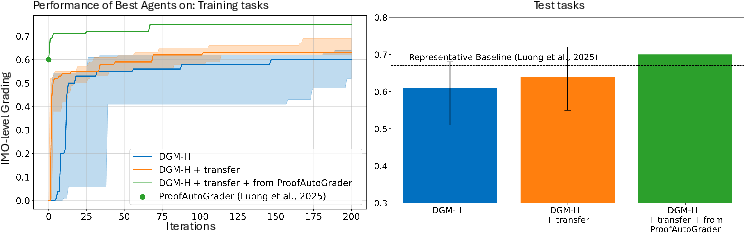
- These “coach” improvements transfer to new areas:
- The team tested whether the meta-level tricks learned in one domain help in another. For example, they measured “improvement@50,” which asks: “Within 50 tries, how much better can this coach make new task solvers?” Hyperagents that had learned in previous domains did much better at quickly improving agents in a new domain (like grading Olympiad math solutions), even when they hadn’t seen that type of task before.
- Both pieces are necessary:
- Without metacognitive self-improvement (the coach can’t change), progress was small or nonexistent.
- Without open-ended exploration (no archive of stepping stones), progress also stalled.
- The classic DGM needed manual, domain-specific customization to do well outside coding. DGM-H didn’t.
Why this matters:
- This shows an AI can learn general strategies for self-improvement that work across very different tasks. It’s a step toward AI that not only solves problems but gets better at learning how to get better—something humans do all the time.
What could this mean for the future?
- Faster progress: If AI can keep improving both its skills and its improvement methods, it might speed up research and engineering across many fields.
- Generality: Because the “coach” can be changed by the AI itself, we’re not stuck with human-written rules for improvement. That means fewer bottlenecks and more adaptability.
- Safety matters: The authors ran everything with safety steps like sandboxing and human oversight. As these systems get more capable, careful monitoring, testing, and safeguards will be essential.
- Big picture: This is a glimpse of AI systems that don’t just search for better answers—they continually get better at searching for better answers. If guided responsibly, that could help tackle complex challenges more quickly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes DGM-Hyperagents and reports promising results across several domains. Below is a single, concrete list of what remains uncertain or unexplored and where future work can act.
- Editable scope is incomplete: the parent-selection policy and evaluation machinery are largely fixed in the main experiments; enabling safe, learnable modification of selection pressure and evaluation while preventing gaming remains open.
- Limited toolset: the initial hyperagent only has bash and a file-edit tool; the impact and safety of richer toolboxes (retrieval, web, testing/CI, debuggers, unit-test synthesis, profilers) on self-improvement efficacy is unstudied.
- Frozen model weights: all improvements operate via code/prompt edits around a frozen FM; co-evolving model weights (e.g., via self-generated data) and studying the trade-offs between code- vs weight-level changes is not explored.
- Safety under self-modification: beyond sandboxing and oversight, the paper lacks a systematic threat model and red-team evaluation for capability escalation, tool misuse, persistence, and specification gaming in self-editing systems.
- Evaluation gaming risk: because agents read their own code and evaluation artifacts, methods to harden evaluations (e.g., blinded tests, held-out unseen evaluators, randomized criteria) and detect/penalize metric hacking are not established.
- Subjective-task validity: paper-review and grading rely on approximations to human judgment; there is no blinded human evaluation to quantify overfitting to AI judges or alignment with diverse human reviewer standards.
- Transfer breadth: cross-domain transfer of meta-skills is shown primarily to Olympiad-level grading; generality to other domains (vision-heavy, planning-heavy, multi-step interactive tasks) is untested.
- Meta-effect attribution: the paper claims meta-level features (e.g., persistent memory, performance tracking) emerge, but provides no causal ablations isolating which meta-changes drive gains and how much each contributes.
- Metrics for meta-improvement: imp@k freezes the meta-agent to isolate its ability to improve task agents; there is no complementary metric capturing coupled evolution (meta improves itself and task agents) without confounding exploration effects.
- Path dependence and initialization sensitivity: how outcomes depend on the initial hyperagent’s design, toolset, prompts, or FM choice/size is not quantified.
- Statistical power and robustness: results are reported over 5 seeds with staged evaluations; broader runs, variance analyses, and sensitivity to stochastic RL training and FM randomness are missing.
- Compute and scaling laws: cost is mentioned in the appendix, but there’s no systematic study of compute/iteration scaling, sample-efficiency vs baselines, or asymptotic behavior as budgets grow.
- Baseline strength: comparisons omit strong domain-specific SOTA systems (e.g., advanced code-repair agents, specialized peer-review predictors, state-of-the-art reward-design systems like enhanced Eureka variants); relative competitiveness is unclear.
- Real-world grounding: robotics experiments are in simulation with a single morphology and narrow tasks; sim-to-real, safety in physical settings, and tasks with richer constraints (contact, partial observability) are unaddressed.
- Reward misspecification analysis: while DGM-H sometimes escapes local optima (standing vs jumping), systematic detection/mitigation of reward hacking and failure modes across diverse tasks is not presented.
- Archive management and diversity: how archive size, diversity-maintenance strategies, and stepping-stone descriptors affect exploration vs convergence and long-horizon compounding is not analyzed.
- Selection-pressure design: the heuristic that downweights parents with many compilable children is unvalidated; alternative credit assignment and its impact on exploration/exploitation balance is unexplored.
- Curriculum and multi-domain scheduling: joint optimization over domains is attempted, but strategies for curriculum design, domain weighting, avoidance of negative transfer, and automatic task selection remain open.
- Long-horizon compounding: claims of across-run accumulation are qualitative; rigorous longitudinal studies showing sustained, monotonic compounding over much longer horizons are absent.
- Edit safety and isolation: formal containment guarantees for self-editing code (e.g., capability whitelisting, system-call guards, policy sandboxes with proofs) are not provided.
- Generality claim (“any computable task”): practical preconditions (tool availability, verifiability, compute, observability) for when hyperagents will self-improve are not formalized.
- Interpretability and governance: there is no framework for auditing, summarizing, and approving self-modifications (e.g., diff classifiers, human-readable change rationales, risk scoring) or for rollback policies and provenance tracking.
- Data contamination and leakage: potential overlap between FM pretraining data and evaluation sets (e.g., public paper decisions, Olympiad solutions) is not controlled; time-split and leak-check protocols are missing.
- Fairness and ethics in peer review: the system may entrench existing biases in accept/reject predictions; bias analysis, subgroup performance, and mitigation strategies are not evaluated.
- Robustness to evaluation scarcity: methods for tasks with extremely sparse, delayed, or expensive feedback (e.g., real-world experiments) and how to incorporate human-in-the-loop signals safely and efficiently are not developed.
- Expansion to multi-agent or cooperative settings: whether hyperagents can co-evolve via collaboration/competition, share meta-knowledge, or compose improvements remains unexplored.
- Failure recovery: strategies for detecting regressions, preventing catastrophic self-edits, and implementing safe fallbacks/rollbacks or checkpoints are not detailed.
- Reproducibility: nondeterminism in FM calls and RL training can affect results; reproducibility aids (fixed seeds, prompts, exact environments, deterministic decoding) and their impact are not thoroughly documented.
Practical Applications
Overview
This paper introduces hyperagents and the DGM-Hyperagents (DGM-H) framework: self-referential agents that can modify not only their task-solving code but also the mechanism that generates future improvements (metacognitive self-modification). Built on an open-ended, archive-based exploration process, DGM-H demonstrates compounding gains and cross-domain transfer in coding, paper-review triage, robotics reward design, and Olympiad-level math grading. The authors open-source logs and provide the safety envelope (sandboxing, human oversight). Below are concrete applications, organized by deployment horizon, with sector links, candidate products/workflows, and feasibility dependencies.
Immediate Applications
The following can be prototyped now with current foundation models and the released codebase, provided they run in sandboxes with human-in-the-loop review.
- Software engineering and DevOps (Software)
- Continuous self-improving code maintenance bot
- Use DGM-H to propose small repository edits (e.g., bug fixes, refactorings, documentation updates) as pull requests; archive retained for stepping-stone reuse; CI gates accept/reject.
- Tools/workflows: Hyperagent PR Assistant integrated with GitHub/GitLab, unit/integration test harness, static analysis, A/B deployment behind feature flags, lineage/trace viewer.
- Assumptions/dependencies: Good test coverage; robust CI checks; sandboxed tool access (bash/file editor); compute budget; permissioned repos; human code review policies.
- Continuous prompt/agent optimization for internal tools
- Hyperagent refines prompts, tool-invocation logic, and memory for internal LLM agents (e.g., code search, knowledge assistants); metacognitive changes (persistent memory, performance tracking) improve future iterations.
- Tools/workflows: MLOps integration (experiment tracker, model registry), imp@k evaluation harness, offline eval suites.
- Assumptions: Stable metrics and offline evaluations; change control; observability.
- Publishing and R&D operations (Academia/Publishing)
- Peer-review triage and consistency checker
- Decision-support agent predicts accept/reject (calibrated to venue), surfaces rubric-based checklists and rationales; flags borderline or inconsistent cases for senior reviewers.
- Tools/workflows: Editorial system plug‑ins (OpenReview/CMT/TPCS), explanation templates, audit logs.
- Assumptions: Human-in-the-loop final decisions; de-identified submissions; venue-specific calibration; bias/COI controls; legal/ethical compliance.
- Robotics and industrial automation (Robotics)
- Reward-design assistant in simulation
- Hyperagent proposes RL reward functions and iteratively improves them using simulators (e.g., Genesis) before deployment; meta-level improvements reduce compilation failures and reward misspecification.
- Tools/workflows: “Reward Design Studio” with simulator-in-the-loop, automated training/evaluation, reward-linting, reward-hacking diagnostics.
- Assumptions: High-fidelity simulators; compute for RL; sim-to-real validation; safety gating before physical deployment.
- Education and assessment (Education)
- Auto-grading and rubric refinement for STEM problems
- Decision-support grader for math/CS assignments; learns/edits grading rubrics and checklists while preserving consistency with expert labels.
- Tools/workflows: LMS plug‑ins (Moodle/Canvas), explanation-first grading with uncertainty thresholds, sampling for manual review.
- Assumptions: Clear rubrics; curated training/validation sets; privacy controls; educator oversight.
- Enterprise operations and analytics (Cross-industry)
- Process-improvement agent for SOPs and playbooks
- Hyperagent proposes incremental edits to scripts (e.g., customer support flows, QA checklists), tracks performance, and refines both policies and the improvement mechanism (e.g., better memory, tracking).
- Tools/workflows: KPI dashboards, staged rollouts, archive-based A/B testing, change management integration.
- Assumptions: Reliable KPIs; offline testing; risk controls; auditability.
- Security and compliance (Policy/Software)
- Safety harness and certification for self-improving systems
- imp@k-based evaluation suite certifies self-improving agents; audit logs and lineage tracking satisfy governance and change-control requirements.
- Tools/workflows: Capability tokens/permissions, sandboxing, red-team test suites, differential testing pre‑merge.
- Assumptions: Organizational policy for autonomous changes; secure isolation; incident response plans.
- Developer tooling and research enablement (Software/Academia)
- Hyperagent SDK and archive viewer
- Packaged framework to run DGM-H locally/ in the cloud; includes archive visualization, parent-selection configuration, and safety presets.
- Assumptions: FM access with tool-use; containerized sandboxes; cost monitoring.
Long-Term Applications
These require advances in evaluation reliability, safety frameworks, real-world integration, and/or more capable foundation models.
- Autonomous scientific discovery platforms (Academia/Pharma/Materials)
- Closed-loop systems that design experiments, run simulators or lab robots, analyze results, and self-improve both methods and meta-level strategies.
- Dependencies: High-quality simulators/lab automation, robust scientific metrics, biosafety/ethics review, data provenance, interpretability.
- Self-improving robotic fleets (Robotics/Logistics/Manufacturing)
- On-device or edge-orchestrated hyperagents that adapt control/reward policies and their own improvement procedures across tasks and environments with strong safety monitors.
- Dependencies: Verified safety shields, real-time constraints, sim-to-real transfer reliability, regulatory compliance, fleet A/B gating.
- Clinical workflow optimization and decision support (Healthcare)
- Systems that iteratively improve care pathways, triage rules, or documentation tooling, with meta-level oversight to prevent drift and bias amplification.
- Dependencies: Regulatory approval (e.g., FDA/CE), HIPAA/GDPR compliance, clinician oversight, clinically validated endpoints, fairness audits.
- Energy and infrastructure optimization (Energy/Utilities)
- Self-improving control of building HVAC, microgrids, or industrial processes via evolving objectives/reward functions and controllers.
- Dependencies: Digital twins/simulators, safety constraints, stability guarantees, cyber-physical security, grid reliability standards.
- Finance and risk management (Finance)
- Self-improving backtest‑to‑paper‑to‑live strategies with meta-level risk controls, automated guardrails, and continuous evaluation.
- Dependencies: Regulatory constraints (e.g., MiFID/SEC), robust backtesting, strict sandboxing, model risk management (SR 11‑7), audit trails.
- Personalized, continually improving tutors (Education)
- Agents that refine pedagogy for each learner while meta-improving how they adapt (e.g., memory, pacing strategies).
- Dependencies: Privacy-preserving learning, content alignment, parental/educator oversight, longitudinal evaluation.
- Organizational policy engines and governance (Policy/Enterprise)
- Self-modifying governance playbooks (e.g., incident response, compliance checks) that improve their own improvement process under human oversight and audit regimes.
- Dependencies: Strong change control, legal/regulatory frameworks, explainability, fail‑safe defaults.
- Cross-domain capability transfer marketplaces (Cross-industry)
- Curated archives of hyperagents with proven transfer (via imp@k) for rapid adaptation to new domains/tasks.
- Dependencies: Standardized benchmarks and metrics, licensing/IP regimes, provenance and safety attestations.
- AI safety research and standards (Policy/Research)
- Benchmarks and methodologies for auditing self-modifying systems, including interpretability of meta-changes, catastrophe-avoidance tests, and standardized reporting.
- Dependencies: Community standards, measurement infrastructure, third-party certification mechanisms.
Common Assumptions and Dependencies
- Task computability and measurable proxies: Tasks must be instrumented with reliable metrics or judges; noise-tolerant evaluation is critical.
- Foundation model access and cost: Tool-using FMs with sufficient reasoning; budget and latency constraints.
- Safety envelope: Sandboxing, permissioned tools, capability scoping, human oversight, and rollback mechanisms.
- Data governance: Privacy, consent, and compliance; secure handling of code and documents.
- Versioning and auditability: Full lineage tracking, reproducibility, and change-control gates to prevent unintended drift.
- Domain integration: Simulators/digital twins for high-risk domains; sim-to-real validation; domain-expert involvement.
By productizing the DGM-H workflow (archive-based exploration, editable meta-level, safety harnesses) and aligning it with strong evaluation protocols, organizations can begin deploying narrowly scoped, auditable self-improving agents today while preparing for broader, cross-domain autonomous improvement in the longer term.
Glossary
- Ablation: An experimental comparison where specific components are removed to assess their contribution. "Ablations without self-improvement or without open-ended exploration show little to no progress"
- AI judges: Automated evaluators used to approximate human judgments for training/validation. "For domains where we create AI judges to reflect human data"
- Archive: A maintained collection of prior agents or solutions used as seeds for future exploration. "retained in an archive as stepping stones for further improvement"
- Bootstrap confidence intervals: Statistical intervals estimated by resampling the data to quantify uncertainty. "We report medians with 95% bootstrap confidence intervals"
- Darwin G\"odel Machine (DGM): A self-improving system that iteratively modifies and evaluates its own code, retaining successful variants. "The Darwin G\"odel Machine (DGM) \citep{zhang2025darwin} demonstrates that open-ended self-improvement is achievable in coding."
- DGM-Hyperagents (DGM-H): An extension of DGM where both task and meta-level mechanisms are editable within a single program. "We instantiate this framework by extending DGM to create DGM-Hyperagents (DGM-H)."
- Discounting by lineage depth: A weighting scheme that reduces credit for improvements that occur many generations after the original agent. "discounted by lineage depth"
- Foundation models (FMs): Large, general-purpose models used as components or tools within agents. "optionally including calls to foundation models (FMs), external tools, or learned components."
- Held-out test tasks: Evaluation tasks not seen during training, used to measure generalization. "with gains transferring to held-out test tasks"
- Hyperagent: A self-referential, editable program that unifies a task agent and a meta agent, enabling modification of both task behavior and the improvement process. "We introduce hyperagents, self-referential agents that integrate a task agent (which solves the target task) and a meta agent (which modifies itself and the task agent) into a single editable program."
- Improvement@k (imp@k): A metric measuring the performance gain achieved by the best agent produced within k generation steps. "we introduce the improvement@k (imp@k) metric."
- Infinite regress: A conceptual problem where adding higher meta-levels to improve a system leads to an unending chain of meta-levels. "ultimately leads to an infinite regress of meta-levels."
- Local optima: Suboptimal solutions that are better than nearby alternatives but not globally best, potentially trapping search processes. "avoid getting trapped in local optima."
- Meta agent: A subsystem whose task is to generate and modify agents, including itself, to improve future performance. "A meta agent is an agent whose only task is to modify existing agents and generate new ones."
- Metacognitive self-modification: The process by which an agent improves not only its task performance but also the mechanisms it uses to generate future improvements. "We refer to this process as metacognitive self-modification"
- Open-ended exploration: An exploratory process that continually generates and evaluates diverse variants without a fixed end, enabling sustained innovation. "retains the open-ended exploration structure of the DGM"
- Open-endedness: The capability of a system to indefinitely produce novel and increasingly complex artifacts beyond predefined objectives. "Open-endedness refers to the ability of a system to continually invent new, interesting, and increasingly complex artifacts"
- Parent selection mechanism: The procedure for choosing which existing agents produce new variants during exploration. "Parent selection is probabilistic and proportional to a hyperagent's performance"
- Population-based exploration: Search that maintains and evolves a set (population) of candidates in parallel to promote diversity and progress. "an open-ended, population-based exploration process"
- Premature convergence: Early settling on suboptimal solutions due to insufficient exploration. "to support sustained progress and avoid premature convergence"
- Quality-diversity algorithms: Methods that seek a diverse set of high-quality solutions rather than a single optimum. "quality-diversity algorithms"
- Reinforcement learning (RL): A learning paradigm where agents learn policies by receiving feedback in the form of rewards from interactions. "training algorithms (e.g., reinforcement learning (RL))"
- Reward misspecification: Errors where a designed reward function fails to capture the intended behavior, leading to undesirable outcomes. "reducing reward misspecification."
- Sandboxing: Executing code in a restricted environment to limit potential harm or unintended side effects. "All experiments were conducted with safety precautions (e.g., sandboxing, human oversight)."
- Staged evaluation protocol: A multi-phase assessment strategy that first tests on a small subset before expanding to a larger set based on initial effectiveness. "the same staged evaluation protocol (i.e., first evaluating each agent on 10 tasks to estimate effectiveness before expanding to 50 additional tasks)"
- Stepping stones: Intermediate solutions that, while not final goals, provide useful paths for further improvements. "retained in an archive as stepping stones"
- Task agent: The component responsible for solving the target tasks directly. "A task agent is an agent instantiated to solve a set of tasks."
- Turing-complete: Capable of performing any computation given adequate resources, equivalent in power to a universal Turing machine. "We use Python, which is Turing-complete"
- Wilcoxon signed-rank test: A nonparametric statistical test used to assess differences between paired samples. "Statistical significance is assessed using the Wilcoxon signed-rank test."
- Zero-shot: Performing a task in a new setting without any additional task-specific training. "agents must zero-shot generate new reward functions"
Collections
Sign up for free to add this paper to one or more collections.

